昇思学习营-【模型推理和性能优化】学习心得_20250730
一、权重的加载
模型包含两部分:
base model 和 LoRA adapter
其中base model的权重在微调时被冻结,
推理时加载原权重即可,LoRA adapter可通过PeftModel.from_pretrained进行加载。
二、启动推理
通过model.generate,启动推理。
三、效果比较
“DeepSeek-R1”,而在加载LoRA adapter之后,回答为“甄嬛”。
在微调多轮后的LoRA权重,在加载LoRA adapter之后,回答为“甄嬛”
在generate_kwargs中添加 repetition_penalty=1.2减少重复文本输出
四、性能测试
凡是在推理过程中涉及采样(do_sample=True)的案例,可以通过配置如下变量,
注释掉之前添加的同步模式代码,再运行代码,即可获取每个token的推理时长和平均时长。
export INFERENCE_TIME_RECORD=True
此时,从终端的运⾏⽇志可以看到,平均推理时间为0.727秒,
可通过禁用多线程将推理速度适当提升为平均单token推理时长0.674秒。
五、性能优化
通过上述禁用多线程的方式,可以适当减少平均单token的推理时长,但效果不明显。
在此基础上,还可以通过jit即时编译的方式进一步加速
jit即时编译通过jit修饰器修饰Python函数或者Python类的成员函数使其被编译成计算图,通过图优化等技术提高运行速度。
jit修饰器应该修饰模型decode的函数,但由于原代码将模型的logits计算、解码等过程整体封装成了一个
model.generate函数,不好进行优化,所以需要手动实现解码逻辑。
六、实操
6.1 访问云上Jupyter
6.1.1 点击“打开Jupyter在线编程”
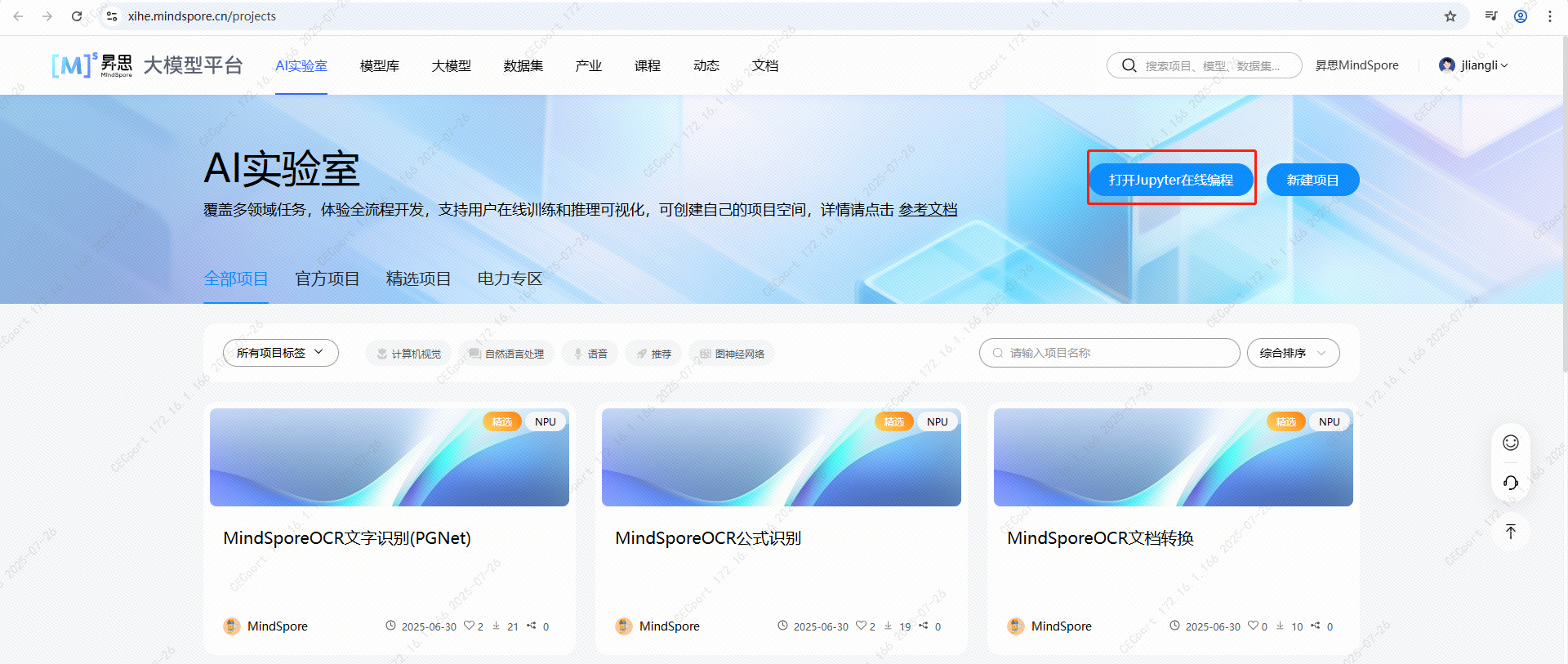
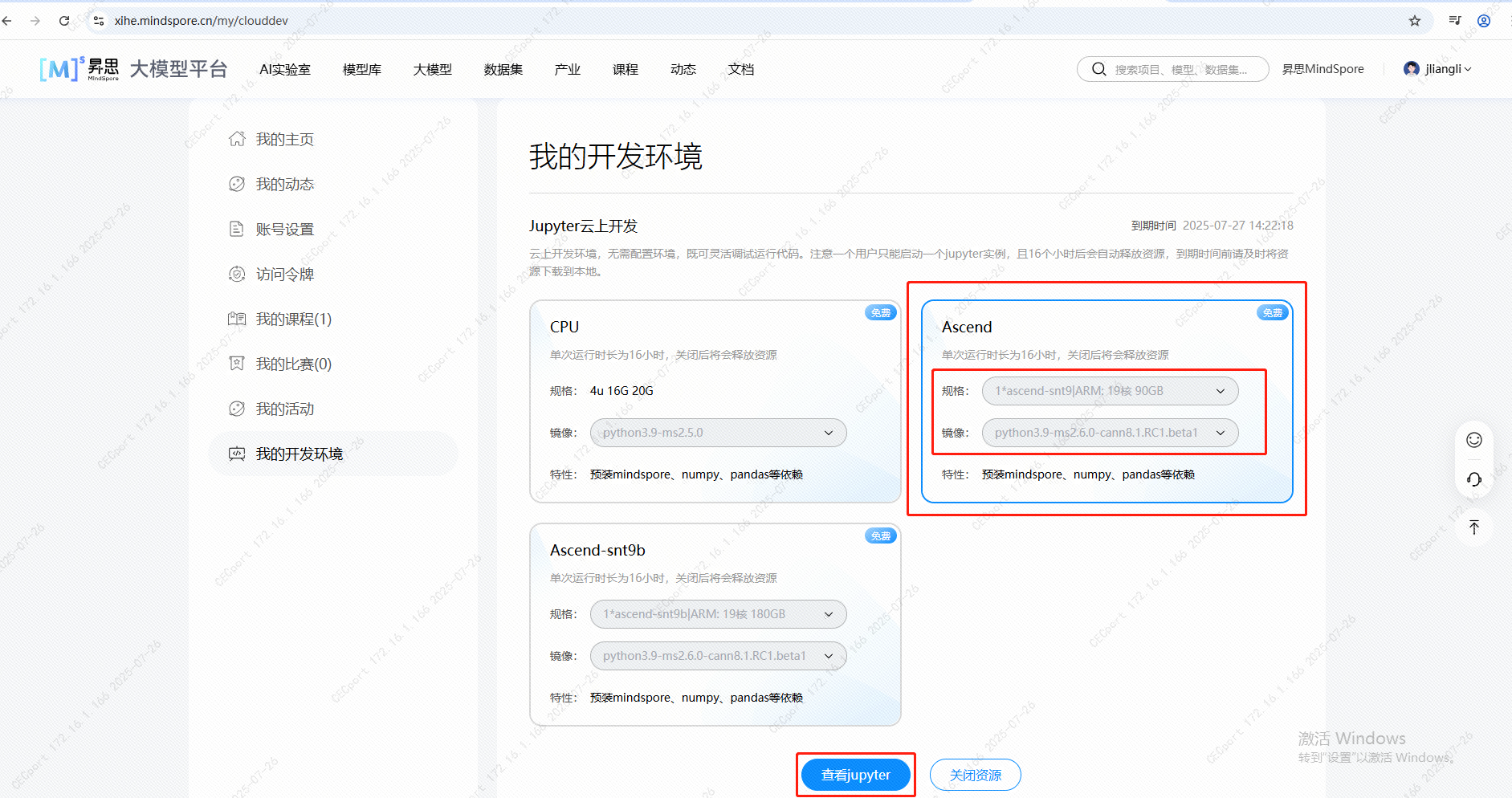
6.1.2 选择如下红框中的来运行起来:
6.1.3 进入后,选择“应用实际”、“昇腾开发板”
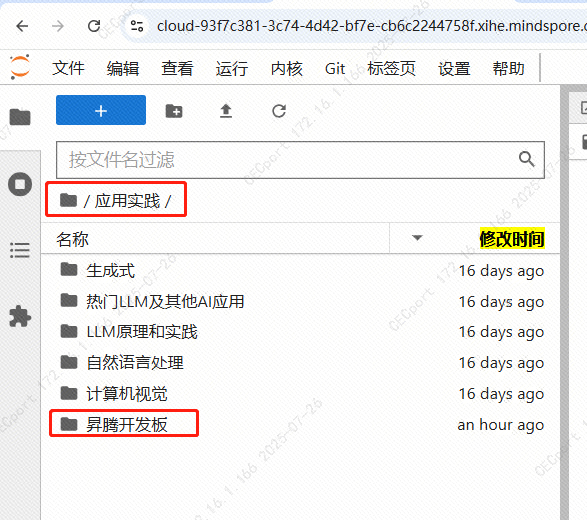
6.1.4 进入后,选择“deepdeek-r1-distill-qwen-1.5b-jit.ipynb**”并运行它
七、代码的逻辑
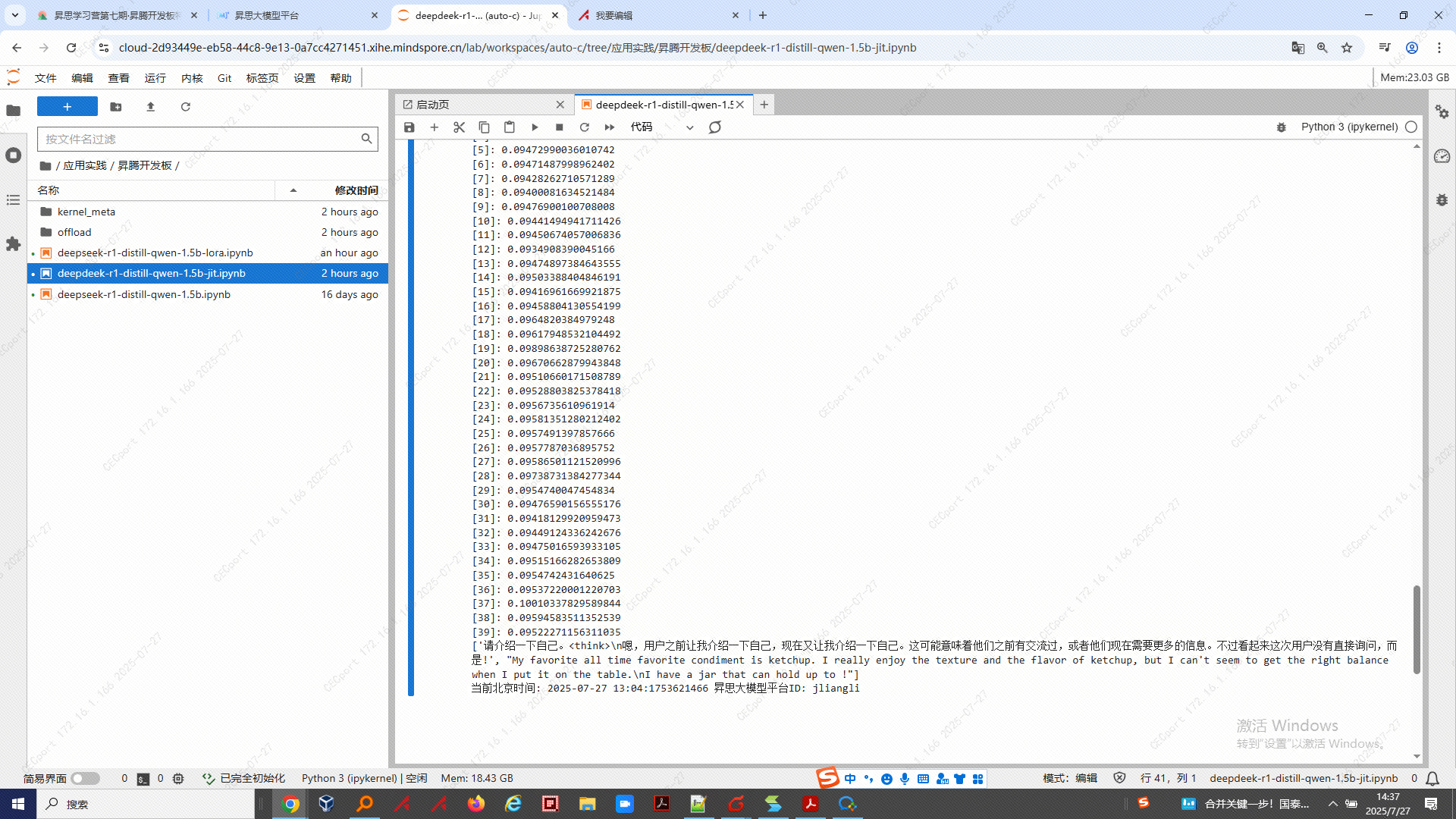
7.1 每一步执行推理的时间都打印了出来,较之前有提升
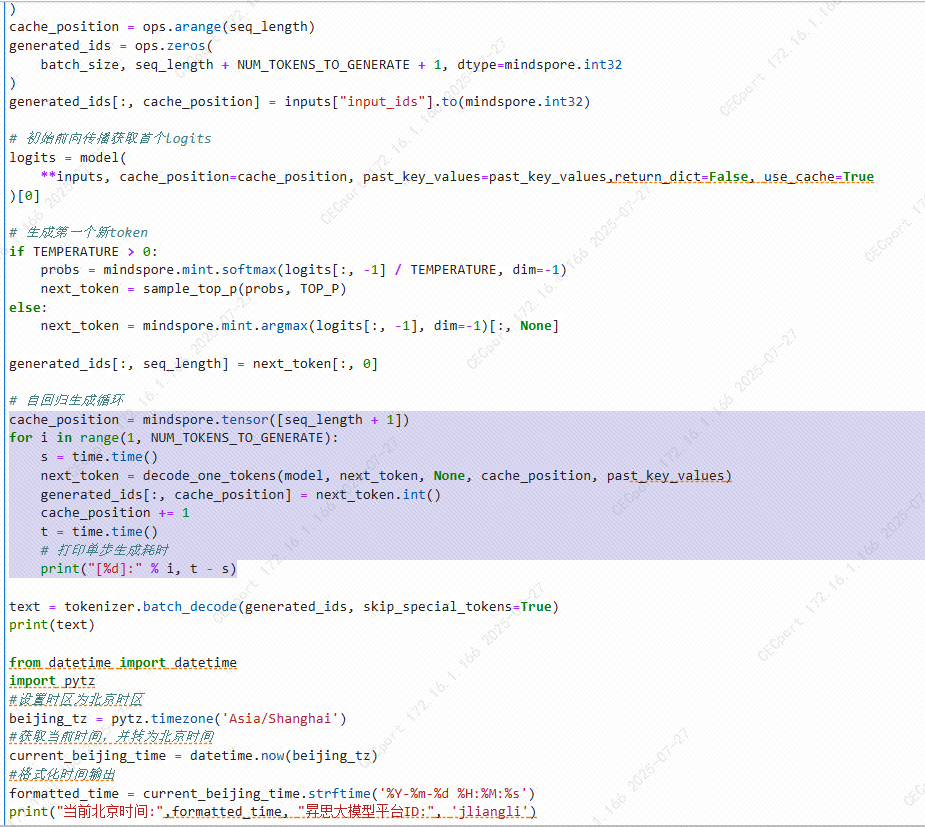
7.2 运行结果