(二)使用 LangChain 从零开始构建 RAG 系统 RAG From Scratch
为了提高RAG系统的效果,我们在索引,检索和生成阶段有各种有趣的方式方法
首先在索引阶段
Qurey translation
-
查询翻译的定位与目标:查询翻译处于高级检索管道的第一阶段,目标是接收用户问题并进行翻译,以提高检索效果。
-
用户查询存在的问题及解决思路:用户查询可能含糊不清或表述不当,导致无法从索引中检索到正确文档。解决方法可分为查询重写(如多查询、RAG 等)、将问题分解为子问题、将问题变得更抽象(如后退提示法)等。
-
多查询方法的原理:多查询方法是将一个问题分解为从不同角度表达的几个问题。因为原问题嵌入后可能与需检索文档在高维嵌入空间中不接近,而重新表述问题能增加检索到所需文档的可能性,提高检索的准确性和可靠性。如下图:
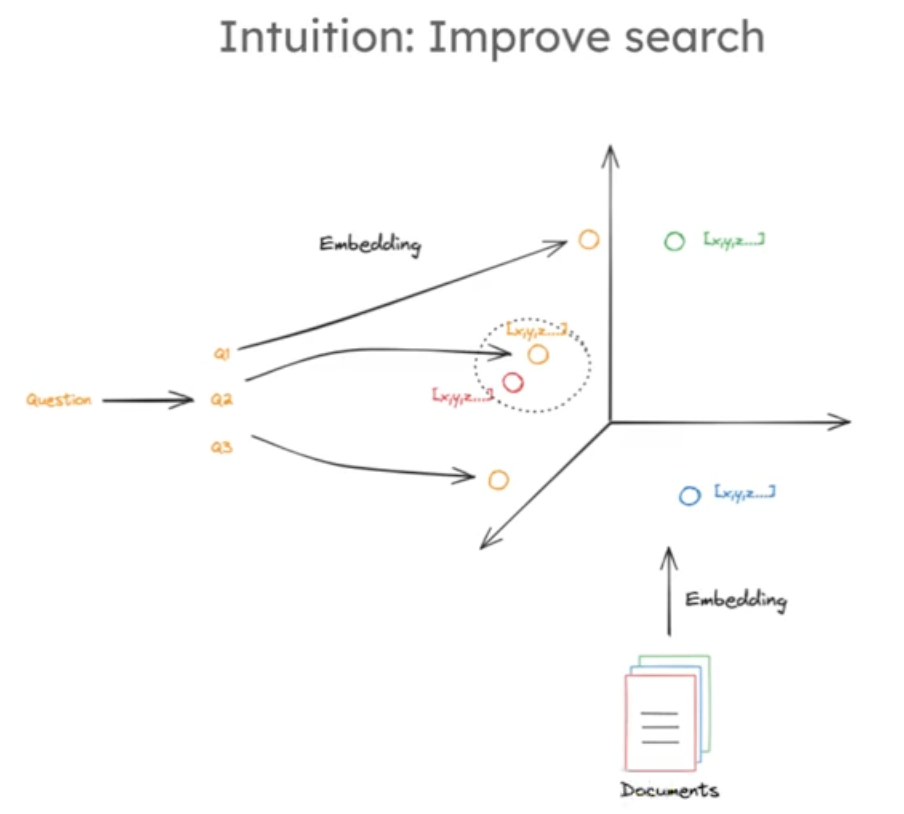
-
多查询方法的实现步骤:首先定义多查询提示,将其传递给 LLM,解析转换为字符串后按新行分割得到问题列表;然后将每个问题应用到检索器进行独立检索;最后取所有检索中唯一的并集文档,放入最终的 rag 提示上下文,传递给 lm 并解析输出。如下图:
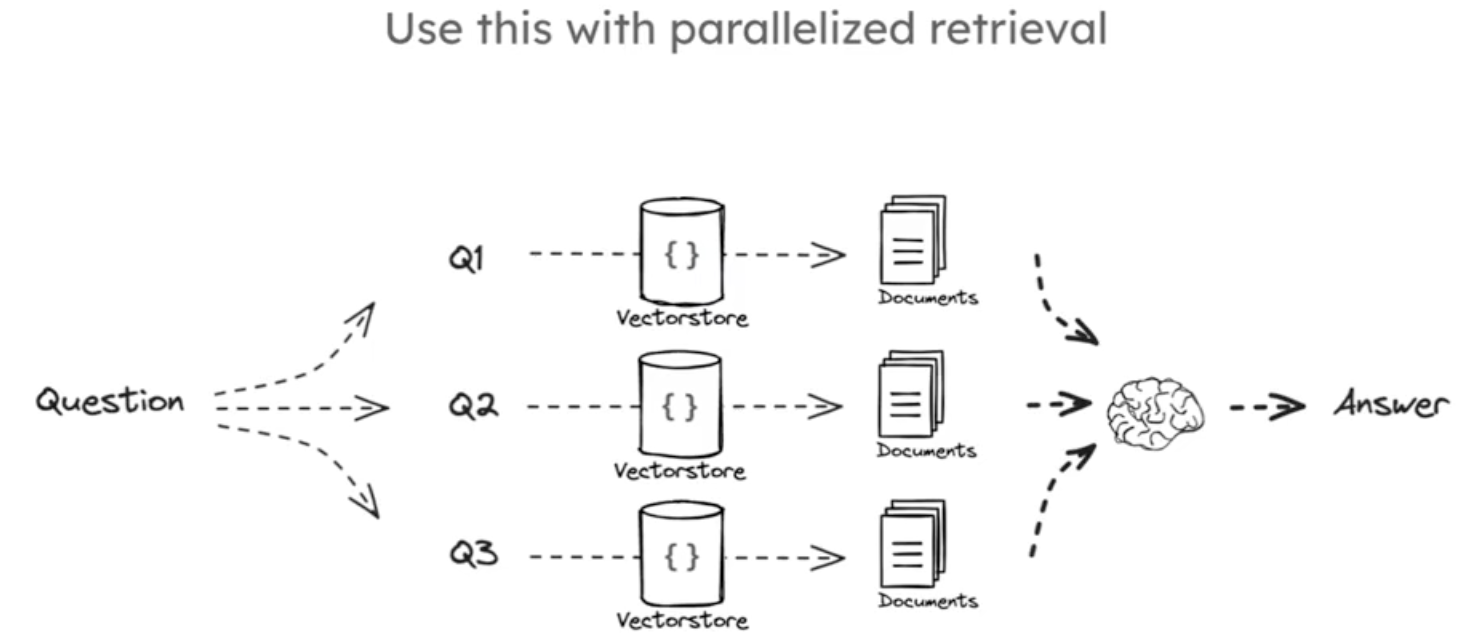
RAG 融合方法,该方法是查询翻译中重写的一种特定方法,而查询翻译是高级 RAG 流水线的第一阶段,用于将用户问题翻译以便检索。
**
Multi Query
**
RAG-Fusion多次检索后,合并检索然后让大模型生成一个答案
from langchain_openai import ChatOpenAI
import os# 先验证环境变量是否加载成功
ali_api_key = os.getenv("DASHSCOPE_API_KEY")
llm = ChatOpenAI(model="qwen-max",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",openai_api_key = ali_api_key,temperature = 0,
)respons = llm.invoke("你是谁,能帮我解决什么问题")
print(respons.content)
#加载网页
import bs4
from langchain import hub
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings#### INDEXING ##### Load Documents
loader = WebBaseLoader(web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_=("post-content", "post-title", "post-header"))),requests_kwargs={"headers": {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"}}
)
docs = loader.load()
print(docs[0])#拆分存储索引
from langchain_community.embeddings import DashScopeEmbeddings
# 确保正确初始化 embedding 模型
embedding_model = DashScopeEmbeddings(model="text-embedding-v4",dashscope_api_key=os.getenv("DASHSCOPE_API_KEY") # 显式传递 API 密钥
)
# Split
from langchain_chroma import Chroma
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=50)
splits = text_splitter.split_documents(docs)# 创建空集合
vectorstore = Chroma(embedding_function=embedding_model)# 手动分批次添加文档(每次最多10个)
for i in range(0, len(splits), 10):batch = splits[i:i+10]vectorstore.add_documents(documents=batch)retriever = vectorstore.as_retriever()from langchain.prompts import ChatPromptTemplate# Multi Query: Different Perspectives
template = """You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from a vector
database. By generating multiple perspectives on the user question, your goal is to help
the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines. Original question: {question}"""
prompt_perspectives = ChatPromptTemplate.from_template(template)from langchain_core.output_parsers import StrOutputParsergenerate_queries = (prompt_perspectives | llm| StrOutputParser() | (lambda x: x.split("\n"))
)
from langchain.load import dumps, loadsdef get_unique_union(documents: list[list]):""" Unique union of retrieved docs """# Flatten list of lists, and convert each Document to stringflattened_docs = [dumps(doc) for sublist in documents for doc in sublist]# Get unique documentsunique_docs = list(set(flattened_docs))# Returnreturn [loads(doc) for doc in unique_docs]# Retrieve
question = "What is task decomposition for LLM agents?"
retrieval_chain = generate_queries | retriever.map() | get_unique_union
docs = retrieval_chain.invoke({"question":question})
len(docs)
print(docs)from operator import itemgetter
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough# RAG
template = """Answer the following question based on this context:{context}Question: {question}
"""prompt = ChatPromptTemplate.from_template(template)final_rag_chain = ({"context": retrieval_chain, "question": itemgetter("question")} | prompt| llm| StrOutputParser()
)final_rag_chain.invoke({"question":question})
**
RAG-Fusion
**
构建检索链,先通过 generate_queries 生成多个查询,
再使用 retriever.map() 对每个查询进行文档检索,
最后使用 reciprocal_rank_fusion 函数对多个检索结果进行融合排序
然后生成答案
from langchain.prompts import ChatPromptTemplate# RAG-Fusion: Related
template = """You are a helpful assistant that generates multiple search queries based on a single input query. \n
Generate multiple search queries related to: {question} \n
Output (4 queries):"""
prompt_rag_fusion = ChatPromptTemplate.from_template(template)from langchain_core.output_parsers import StrOutputParser# 构建一个链式处理流程,用于根据给定的提示生成多个搜索查询
generate_queries = (# 首先,将输入传递给 prompt_rag_fusion 对象# prompt_rag_fusion 通常是一个提示模板,它会根据输入生成适合大语言模型的提示文本prompt_rag_fusion # 将生成的提示文本传递给大语言模型 llm 进行推理# llm 会基于提示文本生成相应的输出| llm# 使用 StrOutputParser 对大语言模型的输出进行解析# 该解析器会将模型的输出转换为字符串类型| StrOutputParser() # 使用 lambda 函数对解析后的字符串进行处理# 通过 split("\n") 方法将字符串按换行符分割成一个字符串列表# 这样可以将大语言模型输出的多个查询按行分离出来| (lambda x: x.split("\n"))
)from langchain.load import dumps, loadsdef reciprocal_rank_fusion(results: list[list], k=60):"""实现互惠排名融合(Reciprocal Rank Fusion, RRF)算法,该算法将多个排好序的文档列表融合成一个新的排序结果。参数:results (list[list]): 包含多个排好序的文档列表的列表,每个子列表代表一个检索结果集。k (int, 可选): RRF 公式中的一个常量,默认值为 60。返回:list: 重新排序后的结果列表,每个元素是一个元组,包含文档对象和其融合后的得分。"""# 初始化一个字典,用于存储每个唯一文档的融合得分fused_scores = {}# 遍历每个排好序的文档列表for docs in results:# 遍历列表中的每个文档,同时获取其排名(在列表中的位置,从 0 开始)for rank, doc in enumerate(docs):# 将文档对象序列化为字符串,以便作为字典的键(假设文档对象可以序列化为 JSON)doc_str = dumps(doc)# 如果该文档还未在 fused_scores 字典中,将其添加并初始得分设为 0if doc_str not in fused_scores:fused_scores[doc_str] = 0# 获取该文档当前的得分previous_score = fused_scores[doc_str]# 使用 RRF 公式更新文档的得分:1 / (排名 + k)fused_scores[doc_str] += 1 / (rank + k)# 根据文档的融合得分对文档进行降序排序,得到最终的重新排序结果reranked_results = [(loads(doc), score)for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)]# 返回重新排序后的结果列表,每个元素是一个元组,包含文档对象和其融合后的得分return reranked_results# 构建检索链,先通过 generate_queries 生成多个查询,
# 再使用 retriever.map() 对每个查询进行文档检索,
# 最后使用 reciprocal_rank_fusion 函数对多个检索结果进行融合排序
retrieval_chain_rag_fusion = generate_queries | retriever.map() | reciprocal_rank_fusion
# 调用检索链,传入包含问题的字典,执行检索和融合排序操作,得到最终的文档列表
docs = retrieval_chain_rag_fusion.invoke({"question": question})
# 打印最终文档列表的长度
print(len(docs))
from langchain_core.runnables import RunnablePassthrough# RAG
template = """Answer the following question based on this context:{context}Question: {question}
"""prompt = ChatPromptTemplate.from_template(template)final_rag_chain = ({"context": retrieval_chain_rag_fusion, "question": itemgetter("question")} | prompt| llm| StrOutputParser()
)final_rag_chain.invoke({"question":question})**
Decomposition 问题分解 Answer recursively 递归的回答
**
将问题分解成小问题,递归回答
比如将如下问题
What are the main components of an LLM-powered autonomous agent system?"
转化成以下三个问题
[‘1. What is LLM technology and how does it work in autonomous agent systems?’,
‘2. What are the specific components that make up an LLM-powered autonomous agent system?’,
‘3. How do the main components of an LLM-powered autonomous agent system interact with each other to enable autonomous functionality?’]
from langchain.prompts import ChatPromptTemplate
# Decomposition
template = """You are a helpful assistant that generates multiple sub-questions related to an input question. \n
The goal is to break down the input into a set of sub-problems / sub-questions that can be answers in isolation. \n
Generate multiple search queries related to: {question} \n
Output (3 queries):"""
prompt_decomposition = ChatPromptTemplate.from_template(template)from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser# Chain
generate_queries_decomposition = ( prompt_decomposition | llm | StrOutputParser() | (lambda x: x.split("\n")))# Run
question = "What are the main components of an LLM-powered autonomous agent system?"
questions = generate_queries_decomposition.invoke({"question":question})# Prompt
template = """Here is the question you need to answer:\n --- \n {question} \n --- \nHere is any available background question + answer pairs:\n --- \n {q_a_pairs} \n --- \nHere is additional context relevant to the question: \n --- \n {context} \n --- \nUse the above context and any background question + answer pairs to answer the question: \n {question}
"""decomposition_prompt = ChatPromptTemplate.from_template(template)from operator import itemgetter
from langchain_core.output_parsers import StrOutputParserdef format_qa_pair(question, answer):"""Format Q and A pair"""formatted_string = ""formatted_string += f"Question: {question}\nAnswer: {answer}\n\n"return formatted_string.strip()q_a_pairs = ""
for q in questions:rag_chain = ({"context": itemgetter("question") | retriever, "question": itemgetter("question"),"q_a_pairs": itemgetter("q_a_pairs")} | decomposition_prompt| llm| StrOutputParser())answer = rag_chain.invoke({"question":q,"q_a_pairs":q_a_pairs})q_a_pair = format_qa_pair(q,answer)q_a_pairs = q_a_pairs + "\n---\n"+ q_a_pair
**
Answer individually
**
单独检索得到答案,然后将答案合并去重
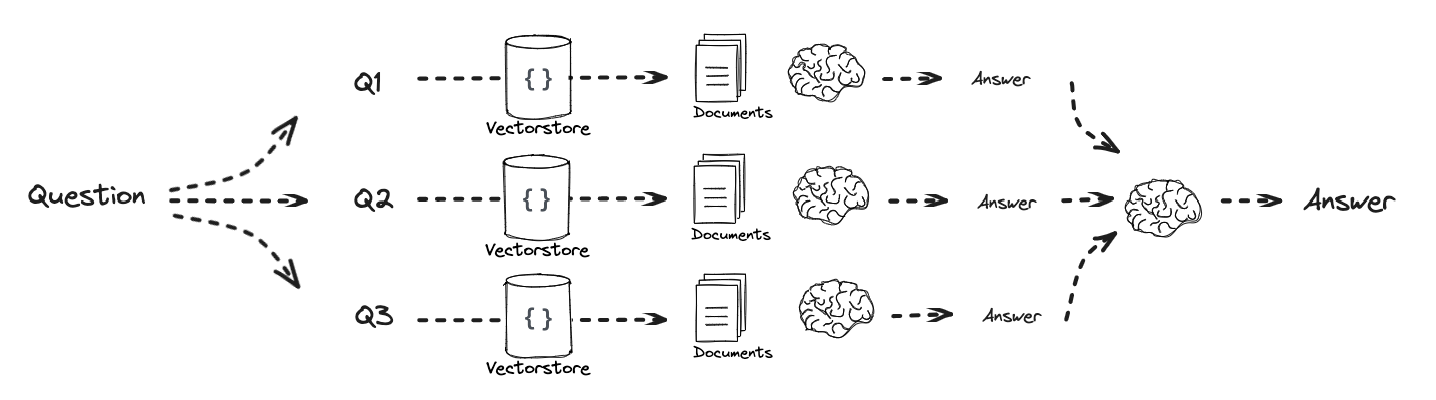
检索回答
# 从 langchain 库中导入 hub 模块,用于获取预定义的提示模板
from langchain import hub
# 从 langchain_core.prompts 模块导入 ChatPromptTemplate 类,用于创建聊天提示模板
from langchain_core.prompts import ChatPromptTemplate
# 从 langchain_core.runnables 模块导入 RunnablePassthrough 和 RunnableLambda 类
# RunnablePassthrough 用于将输入直接传递给下一个组件,RunnableLambda 用于封装自定义函数
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
# 从 langchain_core.output_parsers 模块导入 StrOutputParser 类,用于将模型输出解析为字符串
from langchain_core.output_parsers import StrOutputParser
# 从 langchain_openai 模块导入 ChatOpenAI 类,用于使用 OpenAI 的聊天模型
from langchain_openai import ChatOpenAI# 从 langchain hub 中拉取预定义的 RAG(检索增强生成)提示模板
prompt_rag = hub.pull("rlm/rag-prompt")def retrieve_and_rag(question, prompt_rag, sub_question_generator_chain):"""对每个子问题执行 RAG(检索增强生成)操作。参数:question (str): 原始问题。prompt_rag (ChatPromptTemplate): RAG 提示模板。sub_question_generator_chain (Runnable): 用于生成子问题的链。返回:tuple: 包含两个元素,第一个元素是一个列表,包含每个子问题的 RAG 结果;第二个元素是一个列表,包含生成的所有子问题。"""# 使用子问题生成链,根据原始问题生成一系列子问题sub_questions = sub_question_generator_chain.invoke({"question": question})# 初始化一个空列表,用于存储每个子问题的 RAG 结果rag_results = []# 遍历每个子问题for sub_question in sub_questions:# 为每个子问题从检索器中获取相关文档# 注释掉的代码是旧的获取文档方式,新代码使用 invoke 方法# retrieved_docs = retriever.get_relevant_documents(sub_question)retrieved_docs = retriever.invoke(sub_question)# 使用获取的文档和子问题,通过 RAG 链生成答案# 先将文档和子问题输入到提示模板,再传递给大语言模型,最后使用输出解析器得到字符串答案answer = (prompt_rag | llm | StrOutputParser()).invoke({"context": retrieved_docs, "question": sub_question})# 将每个子问题的答案添加到 RAG 结果列表中rag_results.append(answer)# 返回 RAG 结果列表和子问题列表return rag_results, sub_questions# 调用 retrieve_and_rag 函数,传入原始问题、RAG 提示模板和子问题生成链
# 得到每个子问题的答案列表和子问题列表
answers, questions = retrieve_and_rag(question, prompt_rag, generate_queries_decomposition)def format_qa_pairs(questions, answers):"""Format Q and A pairs"""formatted_string = ""for i, (question, answer) in enumerate(zip(questions, answers), start=1):formatted_string += f"Question {i}: {question}\nAnswer {i}: {answer}\n\n"return formatted_string.strip()context = format_qa_pairs(questions, answers)# Prompt
template = """Here is a set of Q+A pairs:{context}Use these to synthesize an answer to the question: {question}
"""prompt = ChatPromptTemplate.from_template(template)final_rag_chain = (prompt| llm| StrOutputParser()
)final_rag_chain.invoke({"context":context,"question":question})**
Step Back
**
- 核心思想:通过抽象过程从包含具体细节的实例中推导出高层概念和基本原理,再利用这些概念和原理指导推理,减少中间推理步骤中的错误,提高 LLMs 在复杂推理任务中的表现。
- 两个步骤:
- 抽象(Abstraction):不直接解决问题,而是提示 LLM 提出一个关于更高层次概念或原则的通用退一步问题,并检索关于该高层概念或原则的相关事实。每个任务的退一步问题都是独特的,以检索最相关的事实。
- 推理(Reasoning):基于高层概念和原则进行推理,得出问题的解决方案。
比如以下问题
What is task decomposition for LLM agents?"
抽象成问题
What does task decomposition involve for AI agents?
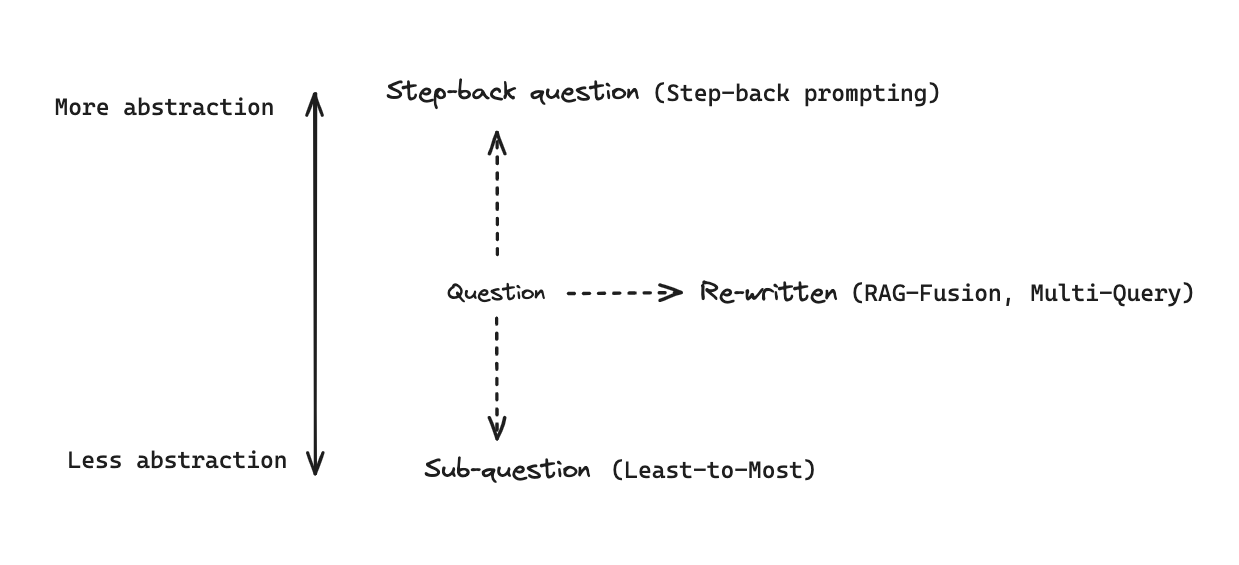
# Few Shot Examples
from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate
examples = [{"input": "Could the members of The Police perform lawful arrests?","output": "what can the members of The Police do?",},{"input": "Jan Sindel’s was born in what country?","output": "what is Jan Sindel’s personal history?",},
]
# We now transform these to example messages
example_prompt = ChatPromptTemplate.from_messages([("human", "{input}"),("ai", "{output}"),]
)
few_shot_prompt = FewShotChatMessagePromptTemplate(example_prompt=example_prompt,examples=examples,
)
prompt = ChatPromptTemplate.from_messages([("system","""You are an expert at world knowledge. Your task is to step back and paraphrase a question to a more generic step-back question, which is easier to answer. Here are a few examples:""",),# Few shot examplesfew_shot_prompt,# New question("user", "{question}"),]
)print(few_shot_prompt)#question = "What is task decomposition for LLM agents?" 抽象问题
generate_queries_step_back = prompt | llm | StrOutputParser()
question = "What is task decomposition for LLM agents?"
generate_queries_step_back.invoke({"question": question})# Response prompt
response_prompt_template = """You are an expert of world knowledge. I am going to ask you a question. Your response should be comprehensive and not contradicted with the following context if they are relevant. Otherwise, ignore them if they are not relevant.# {normal_context}
# {step_back_context}# Original Question: {question}
# Answer:"""
response_prompt = ChatPromptTemplate.from_template(response_prompt_template)chain = ({# Retrieve context using the normal question"normal_context": RunnableLambda(lambda x: x["question"]) | retriever,# Retrieve context using the step-back question"step_back_context": generate_queries_step_back | retriever,# Pass on the question"question": lambda x: x["question"],}| response_prompt| llm| StrOutputParser()
)chain.invoke({"question": question})**
Part 9: HyDE
**
生成假设文档,然后使用假设文档检索答案
原理是假设文档在高维度空间检的空间距离比用问题检索更近
- 提出方法:提出 Hypothetical Document Embeddings(HyDE)方法,具体步骤如下:
a.给定查询时,先通过零样本方式指示遵循指令的语言模型(如 InstructGPT)生成一个假设文档,该文档能捕捉相关模式但可能包含虚假细节。
b.使用无监督对比学习编码器(如 Contriever)将假设文档编码为嵌入向量。
c.基于向量相似性,在语料库嵌入空间中检索与该向量相似的真实文档,编码器的密集瓶颈会过滤掉假设文档中的错误细节。
根据提示写一篇论文,然后根据论文在检索器中检索,然后根据检索生成答案
from langchain.prompts import ChatPromptTemplate# HyDE document generation
template = """Please write a scientific paper passage to answer the question
Question: {question}
Passage:"""
prompt_hyde = ChatPromptTemplate.from_template(template)from langchain_core.output_parsers import StrOutputParsergenerate_docs_for_retrieval = (prompt_hyde | llm | StrOutputParser()
)# Run
question = "What is task decomposition for LLM agents?"
generate_docs_for_retrieval.invoke({"question":question})# Retrieve
retrieval_chain = generate_docs_for_retrieval | retriever
retrieved_docs = retrieval_chain.invoke({"question":question})
retrieved_docs# RAG
template = """Answer the following question based on this context:{context}Question: {question}
"""prompt = ChatPromptTemplate.from_template(template)final_rag_chain = (prompt| llm| StrOutputParser()
)final_rag_chain.invoke({"context":retrieved_docs,"question":question})