【大模型框架】LangChain入门:从核心组件到构建高级RAG与Agent应用
本文旨在为开发者提供一份详尽、深入且与时俱进的LangChain入门教程。我们将从LangChain的设计哲学与核心问题出发,系统性地解析其现代化的架构与核心组件,并通过LangChain表达式语言(LCEL)这一强大工具,手把手带领您构建一个完整的、基于检索增强生成(RAG)的问答应用。最后,我们将一同探索Agent(智能体)与自定义工具的广阔天地,为您开启构建复杂、自主的AI应用的大门。
第一部分:LangChain 入门:从核心理念到现代架构
在深入代码之前,理解一个框架的“初心”至关重要。LangChain为何诞生?它解决了什么根本问题?它的生态系统又是如何组织的?本部分将为您奠定坚实的理论基础。
1.1 LangChain 为何而生?核心问题与设计哲学
大型语言模型(LLM)的爆发带来了前所未有的机遇,但同时也给开发者带来了巨大的挑战。模型、工具和数据源的数量激增,每一个都有其独特的API和集成方式。开发者不得不在各种迥异的接口之间挣扎,这使得切换供应商或组合不同组件变得异常困难和低效。
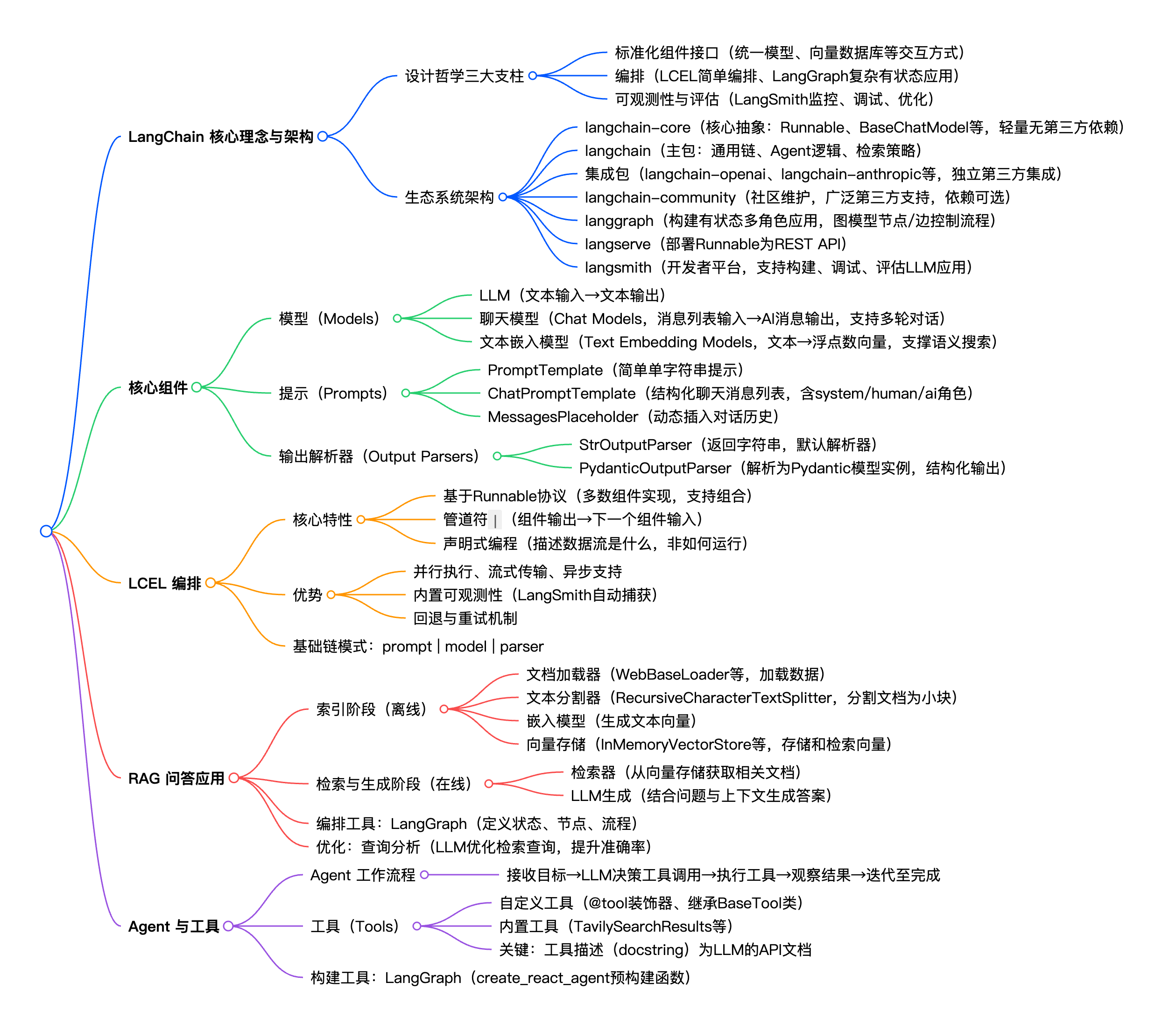
LangChain的诞生正是为了解决这一核心痛点:让开发者能够尽可能轻松地构建可以进行推理的应用程序。它并非仅仅是一个工具集,而是在混乱且迅速演变的LLM生态之上,构建了一个标准化的抽象层。这个抽象层是LangChain最根本的价值主张,它通过以下三个核心支柱来实现其设计哲学 :
- 标准化组件接口 (Standardized Component Interfaces)
LangChain为AI应用中的关键组件(如聊天模型、向量数据库、检索器等)提供了通用的、标准化的接口。例如,所有的聊天模型都实现了BaseChatModel接口,无论底层是OpenAI的GPT-4还是Anthropic的Claude,开发者都可以用同样的方式与之交互,包括调用、工具绑定和获取结构化输出等。这种标准化极大地降低了学习成本,并赋予了应用极高的灵活性和可移植性。
- 编排 (Orchestration)
现代AI应用往往不是单一的LLM调用,而是涉及多个模型、工具和数据处理步骤的复杂工作流。LangChain通过其强大的编排能力,帮助开发者将这些独立的组件高效地连接成一个有机的整体。早期,这通过“Chains”实现,而现在,LangChain强烈推荐使用LangChain表达式语言(LCEL)进行简单编排,以及使用LangGraph来构建更复杂的、包含循环和分支的 stateful(有状态)应用。这种编排能力是构建“认知型应用”的骨架。
- 可观测性与评估 (Observability and Evaluation)
当应用变得复杂时,理解其内部行为、调试错误以及评估性能(在准确性、延迟和成本之间权衡)就成了一个巨大的挑战。LangChain生态中的LangSmith平台专为此而生。它为AI应用提供了强大的可观测性(Observability)和评估工具,帮助开发者监控应用的每一步执行,从而充满信心地进行提示工程、模型选择和性能优化。
1.2 现代 LangChain 生态系统架构
为了实现上述目标并适应快速发展的AI领域,LangChain的架构已经演变成一个高度模块化、可扩展的生态系统。这种架构设计反映了一种成熟的软件工程哲学,专注于解耦、可维护性和社区规模化。将核心抽象、主要逻辑和第三方集成拆分到不同的包中,不仅使核心框架更加稳定,也使得整个生态系统能够以更快的速度、更稳健的方式发展。
以下是现代LangChain生态系统的主要组成部分 :
- langchain-core: 这是整个生态系统的基石。它包含了所有核心组件的基础抽象(如
Runnable接口、BaseChatModel、BaseRetriever等)和组合它们的方法。这个包被设计得极其轻量,刻意减少了依赖,并且不包含任何第三方集成,确保了其稳定性和通用性。 - langchain: 这是LangChain的主包。它包含了应用程序的“认知架构”,例如各种通用的链(Chains)、代理(Agents)逻辑和检索策略(Retrieval Strategies)。这些组件是通用的,可以与任何第三方集成配合使用。
- 集成包 (Integration Packages): 为了保持主包的轻量和依赖清晰,流行的第三方集成被拆分到了各自独立的包中,例如
langchain-openai、langchain-anthropic、langchain-google-genai等。这种分离策略使得版本管理更加清晰,开发者只需安装他们需要的集成。 - langchain-community: 这是一个由社区维护的、包罗万象的第三方集成包。它为各种模型、数据库和工具提供了广泛的支持。为了保持其轻量级设计,
langchain-community中的所有依赖都是可选安装的。 - langgraph: 作为LangChain的扩展,
langgraph专为构建健壮、有状态的多角色(multi-actor)应用而设计。它通过将应用流程建模为图(Graph)中的节点(Nodes)和边(Edges),提供了对复杂工作流(如循环和条件分支)的精确控制。它是构建高级Agent的首选工具。 - langserve: 这个包可以帮助开发者轻松地将任何LangChain的可运行对象(Runnable)部署为生产级的REST API,极大地简化了从开发到部署的流程。
- langsmith: 这是一个开发者平台,为构建、调试、测试、评估和监控LLM应用提供了全方位的支持。它是确保AI应用可靠性和性能的关键工具。
这种分层和解耦的架构,使得LangChain不仅仅是一个库,更是一个可持续发展和扩展的平台。它为开发者提供了一个既稳定又灵活的基础,去构建下一代AI应用。
第二部分:LangChain 核心组件深度解析
掌握了LangChain的宏观架构后,我们现在深入其内部,逐一解构构建AI应用所需的核心“乐高积木”。
2.1 模型 (Models): 与大语言模型的交互
模型是任何AI应用的核心引擎。LangChain将与模型的交互抽象为三种主要类型 :
- LLMs: 这是最基础的模型接口,遵循“文本输入,文本输出”的模式。
- 聊天模型 (Chat Models): 这是目前更常用、更强大的接口,它以一个消息列表(
list of messages)作为输入,并输出一个AI消息。这种结构天然支持多轮对话。 - 文本嵌入模型 (Text Embedding Models): 这类模型接收文本作为输入,输出一个浮点数向量(vector)。这些向量是实现语义搜索和RAG应用的基础。
与 OpenAI 模型交互
与 OpenAI 模型交互通常使用langchain-openai包。
# 安装必要的包
# pip install langchain-openaiimport os
from langchain_openai import ChatOpenAI# 建议将API密钥设置为环境变量
# os.environ = "sk-..."# 初始化聊天模型
# model_name可以指定不同版本的模型,如 "gpt-4", "gpt-3.5-turbo"
chat_model = ChatOpenAI(model="gpt-4")# 调用模型
# 输入是一个消息列表
from langchain_core.messages import HumanMessageresponse = chat_model.invoke([HumanMessage(content="用一句话描述宇宙的浩瀚。")])print(response.content)
与 Hugging Face 模型交互
Hugging Face是开源模型的重要平台。LangChain提供了多种方式与之集成,主要通过langchain-huggingface包实现。选择哪种方式取决于您的具体需求:是在本地运行模型还是通过API调用云端服务。
方式一:本地推理 (HuggingFacePipeline)
当您希望在自己的硬件(CPU或GPU)上运行开源模型时,HuggingFacePipeline是最佳选择。这给予您完全的控制权,无需API依赖,非常适合实验或处理私有数据。
# 安装必要的包
# pip install langchain-huggingface transformers torch sentence-transformers acceleratefrom langchain_huggingface import HuggingFacePipeline
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline# 选择一个模型ID
model_id = "gpt2"# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)# 创建一个transformers的pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, max_new_tokens=50)# 将transformers pipeline包装成LangChain的LLM
hf_local = HuggingFacePipeline(pipeline=pipe)# 调用模型
question = "什么是人工智能?"
result = hf_local.invoke(question)
print(result)
方式二:API 推理 (HuggingFaceEndpoint)
当您不想或不能在本地部署大型模型时,可以使用HuggingFaceEndpoint来调用托管在Hugging Face上的推理服务。这需要一个Hugging Face的API令牌。
import os
from langchain_huggingface import HuggingFaceEndpoint# 设置Hugging Face Hub API Token
# 建议设置为环境变量
# os.environ = "hf_..."# 初始化Endpoint,指定仓库ID
# repo_id 指向Hugging Face Hub上的一个模型
repo_id = "mistralai/Mistral-7B-Instruct-v0.2"
hf_api = HuggingFaceEndpoint(repo_id=repo_id,max_length=128,temperature=0.7,
)# 调用模型
question = "请写一首关于上海的短诗。"
result = hf_api.invoke(question)
print(result)
为了帮助您更好地选择,下表总结了在LangChain中集成Hugging Face模型的主要方式:
| Class | 主要用途 | 核心优势 | 引用 |
|---|---|---|---|
HuggingFacePipeline | 在本地硬件(CPU/GPU)上运行开源模型 | 完全控制,无API依赖,适合实验和私有数据 | |
HuggingFaceEndpoint | 通过API调用Hugging Face托管的推理服务 | 无需本地硬件,可扩展,可使用大型模型 | |
HuggingFaceEmbeddings | 在本地生成文本嵌入 | 免费,适合离线批处理嵌入任务 |
2.2 提示 (Prompts): 精准指导模型的艺术
如果说模型是引擎,那么提示(Prompt)就是方向盘。一个好的提示能够精确地指导模型,产出我们期望的、高质量的、格式一致的输出。在LangChain中,我们不直接拼接字符串,而是使用提示模板(Prompt Templates)。
将提示视为可序列化、可版本化的对象,而非简单的f-string,是理解LangChain设计哲学的关键一步。在LLM应用中,提示本身就是一种“代码”。通过将提示对象化,LangChain允许我们像管理传统软件代码一样,对提示进行管理、测试和部署,这对于构建可靠、可维护的AI应用至关重要。
LangChain提供了几种提示模板:
PromptTemplate: 用于创建简单的、基于单个字符串的提示。
from langchain_core.prompts import PromptTemplateprompt_template = PromptTemplate.from_template("给我讲一个关于 {animal} 的有趣事实。"
)# 格式化模板
filled_prompt = prompt_template.format(animal="章鱼")
print(filled_prompt)
# 输出: 给我讲一个关于章鱼的有趣事实。
ChatPromptTemplate: 用于创建结构化的聊天消息列表,包含不同的角色(如system, human, ai)。这是与聊天模型交互的标准方式。
from langchain_core.prompts import ChatPromptTemplatechat_template = ChatPromptTemplate.from_messages([("system", "你是一位知识渊博的历史学家。"),("human", "请问 {dynasty} 的首都是哪里?")
])# 格式化消息
messages = chat_template.format_messages(dynasty="唐朝")
print(messages)
# 输出:
MessagesPlaceholder: 这是一个特殊的模板,用于在提示中动态地插入一个消息列表,通常用于注入对话历史。
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import AIMessage, HumanMessage# 假设这是我们的对话历史
history = [HumanMessage(content="你好,我正在学习LangChain。"),AIMessage(content="太棒了!有什么可以帮你的吗?")
]chat_template_with_history = ChatPromptTemplate.from_messages([("system", "你是一个乐于助人的AI助手。"),MessagesPlaceholder(variable_name="chat_history"), # 动态插入历史记录("human", "{user_input}")
])messages = chat_template_with_history.format_messages(chat_history=history,user_input="它有哪些核心组件?"
)
print(messages)
2.3 输出解析器 (Output Parsers): 结构化模型的响应
LLM的原始输出通常是无结构的文本字符串。然而,在实际应用中,我们常常需要结构化的数据,如JSON对象、列表或特定的数据类型。**输出解析器(Output Parsers)**正是连接LLM的非结构化世界与传统软件的结构化世界的桥梁。
它们负责两件事:
- 向提示中注入格式化指令,告诉LLM应该如何构造其输出。
- 解析LLM返回的字符串,并将其转换为Python中的数据结构。
通过将带有格式化指令的提示与输出解析器相结合,开发者可以有效地“强制”LLM充当一个可靠的结构化数据生成器,这是将LLM集成到大型软件系统中的关键能力。
- StrOutputParser: 最简单的解析器,它只是将LLM的输出作为字符串返回。这是许多链中的默认解析器。
PydanticOutputParser: 一个非常强大的解析器,可以将LLM的输出解析为一个Pydantic模型实例。这对于需要可靠的JSON结构化输出的场景至关重要。
from typing import List
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import PydanticOutputParser# 1. 定义你期望的Pydantic数据结构
class Actor(BaseModel):name: str = Field(description="演员的姓名")films: List[str] = Field(description="该演员出演的电影列表")# 2. 初始化解析器,并传入Pydantic模型
parser = PydanticOutputParser(pydantic_object=Actor)# 3. 创建一个提示模板,并包含解析器提供的格式化指令
prompt = PromptTemplate(template="请根据以下查询,提取所需信息。\n{format_instructions}\n{query}\n",input_variables=["query"],partial_variables={"format_instructions": parser.get_format_instructions()},
)# 4. 创建链并调用
model = ChatOpenAI(temperature=0)
chain = prompt | model | parserquery = "请告诉我关于演员汤姆·汉克斯的信息,以及他主演的三部电影。"
actor_info = chain.invoke({"query": query})print(type(actor_info))
print(actor_info)
# 输出: <class '__main__.Actor'>
# name='汤姆·汉克斯' films=['阿甘正传', '拯救大兵瑞恩', '荒岛余生']
第三部分:使用 LCEL 编排你的 AI 应用
掌握了核心组件后,下一步就是将它们“链接”起来,构建成一个完整的应用。LangChain的现代方法是使用LangChain 表达式语言(LCEL)。
3.1 LCEL:新一代的“链”式编程
LCEL是一种用于组合LangChain组件的声明式语法。它基于
Runnable协议,LangChain中的大多数对象(模型、提示、解析器、检索器等)都实现了这个协议。LCEL的核心是管道符|,它将一个组件的输出“管道”到下一个组件的输入。
LCEL的出现代表了LangChain从命令式编程到声明式编程的范式转变。传统的LLMChain等链是命令式的:你实例化一个类,然后调用它的方法,你告诉框架_如何_执行。而LCEL是声明式的:你用
prompt | model | parser这样的语法来描述数据流是_什么_,而不是如何运行它。
这种声明式的方法使得LangChain框架可以在底层对执行过程进行优化。因为它在执行前就了解了整个数据流图,所以它可以自动地实现以下高级功能 :
- 并行执行: 自动并行运行链中的独立部分。
- 流式传输 (Streaming): 可以轻松地从链中流式获取最终响应的每一个令牌(token)。
- 异步支持: 天然支持异步操作,与现代Python的
asyncio无缝集成。 - 内置可观测性: 所有LCEL链的执行过程都可以自动被LangSmith捕获和追踪,极大地简化了调试。
- 回退与重试: 可以轻松地为链的任何部分配置回退(fallbacks)或重试逻辑。
这种抽象不仅让代码更简洁、更直观,也使其更强大、性能更优。对于任何希望严肃构建LangChain应用的开发者来说,掌握LCEL是至关重要的一步。
3.2 从零构建 LCEL 链
让我们来构建一个最基础但也是最重要的LCEL链。这个prompt | model | parser的组合是现代LangChain应用的“hello, world”,是构成几乎所有复杂应用的原子单元。
# 安装必要的包
# pip install langchain-openai langchain-corefrom langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser# 1. 定义提示模板
# 这是一个ChatPromptTemplate,适用于聊天模型
prompt = ChatPromptTemplate.from_template("请用一句话回答:为什么天空是 {color} 的?"
)# 2. 初始化模型
# 我们使用ChatOpenAI模型
model = ChatOpenAI(model="gpt-3.5-turbo")# 3. 初始化输出解析器
# StrOutputParser将模型的输出(一个AIMessage对象)转换为字符串
output_parser = StrOutputParser()# 4. 使用管道符 | 创建LCEL链
# 数据流: dict -> prompt -> model -> output_parser -> str
chain = prompt | model | output_parser# 5. 调用链
# invoke方法接收一个字典作为输入,key对应提示模板中的变量
response = chain.invoke({"color": "蓝色"})print(response)
# 输出可能为: 天空是蓝色的,因为地球大气层中的气体分子散射太阳光时,蓝光比其他颜色的光散射得更多。
这个简单的三步链展示了LCEL的核心思想:将可组合的组件通过统一的接口连接起来,形成一个清晰、可读且功能强大的数据处理流水线。掌握了这个基础模式,您就掌握了构建更复杂应用的钥匙。
第四部分:实战演练:从零开始构建 RAG 问答应用
理论知识已经齐备,现在是时候将它们付诸实践了。本部分将指导您从零开始,构建一个完整的检索增强生成(Retrieval Augmented Generation, RAG)应用。RAG是一种强大的技术,它通过连接外部知识库,让LLM能够回答其训练数据之外的、特定领域的问题。
4.1 RAG 概念与工作流
一个典型的RAG应用包含两个主要阶段:
- 索引 (Indexing): 这是一个离线过程。我们加载原始数据(如文档、网页),将其分割成小块,使用嵌入模型将这些块转换为向量,最后将这些向量存储在一个向量数据库中以便快速检索。
- 检索与生成 (Retrieval and Generation): 这是一个在线过程。当用户提问时,我们首先使用用户的查询去向量数据库中检索最相关的文本块(上下文),然后将这些上下文和原始问题一起打包成一个提示,交给LLM生成最终的答案。
这个流程中的关键组件包括 :
- 文档加载器 (Document Loaders): 从各种来源(网页、PDF、CSV等)加载数据。
- 文本分割器 (Text Splitters): 将长文档分割成适合检索的小块。
- 嵌入模型 (Embedding Models): 将文本块转换为数值向量。
- 向量存储 (Vector Stores): 存储和高效检索向量。
- 检索器 (Retrievers): 根据查询从向量存储中获取相关文档的接口。
4.2 步骤一:索引流程
我们将以一篇关于LLM Agent的博客文章为例,构建一个针对该文章内容的问答机器人。
# 安装必要的包
# pip install langchain-community langchain-openai beautifulsoup4 langchain-text-splittersimport bs4
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import InMemoryVectorStore# 1. 加载 (Load)
# 使用WebBaseLoader从URL加载文档内容
# bs4_strainer用于过滤HTML,只保留文章标题和正文内容
loader = WebBaseLoader(web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_=("post-title", "post-header", "post-content"))),
)
docs = loader.load()# 2. 分割 (Split)
# 使用RecursiveCharacterTextSplitter将文档分割成小块
# chunk_size定义了每块的最大字符数
# chunk_overlap定义了块之间的重叠字符数,以保持上下文连续性
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)# 3. 存储 (Store)
# 初始化OpenAI的嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")# 初始化一个内存中的向量存储,并添加分割后的文档
# add_documents方法会自动处理嵌入和存储过程
vectorstore = InMemoryVectorStore(embeddings)
vectorstore.add_documents(splits)print(f"文档已加载、分割并索引。共创建了 {len(splits)} 个文本块。")
至此,我们的知识库已经准备就绪。vectorstore对象现在包含了文章内容的向量化表示。
4.3 步骤二:检索与生成流程
接下来,我们构建接收用户查询并生成答案的实时流程。对于这种包含多个步骤的有状态应用,LangGraph是一个理想的编排工具。
# 安装LangGraph
# pip install langgraphfrom typing import List
from typing_extensions import TypedDict
from langchain_core.documents import Document
from langgraph.graph import StateGraph, START, END# 1. 定义应用状态 (State)
# State是一个TypedDict,用于在图的各个节点之间传递数据
class GraphState(TypedDict):question: str # 用户问题context: List # 检索到的上下文文档answer: str # LLM生成的答案# 2. 定义图的节点 (Nodes)
# 每个节点都是一个Python函数,接收state作为输入,并返回一个包含更新后字段的字典def retrieve_context(state: GraphState) -> dict:"""检索节点:根据问题从向量存储中检索上下文。"""print("---正在检索上下文---")question = state["question"]# similarity_search是向量存储的核心方法,它返回与查询最相似的文档retrieved_docs = vectorstore.similarity_search(question, k=3) # 检索3个最相关的块return {"context": retrieved_docs}def generate_answer(state: GraphState) -> dict:"""生成节点:结合问题和上下文,调用LLM生成答案。"""print("---正在生成答案---")question = state["question"]context = state["context"]# 这里我们再次看到了LCEL的核心模式:prompt | model | parserfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_openai import ChatOpenAIfrom langchain_core.output_parsers import StrOutputParser# 使用一个预设的RAG提示模板# from langchain import hub# prompt = hub.pull("rlm/rag-prompt")# 为了教程的独立性,我们在此处手动定义一个简单的模板rag_template = """请仅根据以下上下文信息来回答问题。如果上下文中没有相关信息,请直接说“我不知道”。上下文:{context}问题:{question}"""prompt = ChatPromptTemplate.from_template(rag_template)llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)parser = StrOutputParser()rag_chain = prompt | llm | parser# 将上下文文档的内容拼接成一个字符串context_str = "\n\n".join(doc.page_content for doc in context)# 调用RAG链answer = rag_chain.invoke({"context": context_str, "question": question})return {"answer": answer}# 3. 构建图 (Graph)
# 初始化一个StateGraph,并传入我们定义的状态对象
graph_builder = StateGraph(GraphState)# 添加节点
graph_builder.add_node("retrieve", retrieve_context)
graph_builder.add_node("generate", generate_answer)# 定义图的流程(边)
graph_builder.add_edge(START, "retrieve") # 从开始节点流向retrieve节点
graph_builder.add_edge("retrieve", "generate") # 从retrieve节点流向generate节点
graph_builder.add_edge("generate", END) # 从generate节点流向结束节点# 编译图,得到一个可执行的应用
app = graph_builder.compile()
4.4 完整应用与进阶优化
现在,我们的RAG应用已经构建完成,可以开始提问了。
# 运行RAG应用
inputs = {"question": "What are the four components of an agent system?"}
result = app.invoke(inputs)print("\n---最终答案---")
print(result["answer"])
进阶优化:查询分析 (Query Analysis)
这个RAG应用已经相当不错,但我们还可以优化它。一个常见的优化点是查询分析。有时用户的原始问题可能不是最佳的检索查询。我们可以利用LLM的推理能力,对用户的原始问题进行改写或分析,生成一个更适合向量检索的查询。
这个过程本身就揭示了现代AI工程中的一个深刻模式:使用LLM来优化LLM应用流程的其他部分。LLM不再仅仅是应用的终点(生成答案),它也可以作为流程中的一个智能组件,用于数据预处理、路由决策或查询优化。这标志着开发者思维的转变——将LLM视为可以部署在系统多个节点上的通用推理引擎,而不仅仅是最后的“大脑”。
例如,我们可以增加一个analyze_query节点,让LLM判断用户问题是否需要改写,或者从中提取关键词,然后再将优化后的查询用于检索。这会显著提升复杂问题下的检索准确率。
第五部分:进阶之路:初探 Agent 与自定义工具
RAG应用让LLM变得“博学”,而**Agent(智能体)**则让LLM变得“能干”。Agent能够使用LLM作为其核心推理引擎,来决定采取一系列行动以完成更复杂的任务。
5.1 Agent:赋予 LLM 行动的能力
Agent通过与外部世界交互来完成任务,而这种交互是通过**工具(Tools)**实现的。工具可以是任何东西:一个搜索引擎、一个计算器、一个数据库查询接口,或者一个调用其他API的函数。
Agent的工作流程通常是这样的:
- 接收用户的高级目标。
- LLM进行思考,决定第一步需要使用哪个工具,以及需要为该工具提供什么参数。
- Agent执行该工具调用。
- Agent观察工具返回的结果。
- LLM根据观察结果,决定下一步行动(调用另一个工具,或生成最终答案)。
- 重复此过程,直到任务完成。
现代的LangChain Agent推荐使用LangGraph来构建,create_react_agent是一个方便的预构建函数,可以快速创建一个遵循ReAct(Reasoning and Acting)框架的Agent。
5.2 创建并使用自定义工具
虽然LangChain提供了许多内置工具,但在实际开发中,我们经常需要创建自定义工具来连接我们自己的API、数据库或执行特定逻辑。
创建自定义工具最简单、最推荐的方式是使用@tool装饰器。
# 安装必要的包
# pip install langchain-anthropic tavily-pythonfrom langchain_core.tools import tool# 使用@tool装饰器定义一个简单的乘法工具
@tool
def multiply(a: int, b: int) -> int:"""一个可以计算两个整数乘积的工具。"""return a * b# 检查工具的属性
print(f"工具名称: {multiply.name}")
print(f"工具描述: {multiply.description}")
print(f"工具参数: {multiply.args}")
这里有一个至关重要的、非显而易见的点:工具的描述(即函数的docstring)是写给LLM看的API文档16。Agent的LLM推理引擎会根据工具的
name和description来决定何时以及如何使用这个工具。一个清晰、准确、详尽的描述,对于Agent能否正确使用该工具至关重要。这对于习惯了只为人类同事写文档的传统开发者来说,是一个思维上的转变。
除了使用装饰器,您还可以通过继承BaseTool类来创建更复杂的、面向对象的工具。
from langchain_core.tools import BaseTool
from math import pi
from typing import Unionclass CircumferenceTool(BaseTool):name = "圆周长计算器"description = "当你需要根据圆的半径计算周长时,使用此工具。"def _run(self, radius: Union[int, float]) -> float:"""同步执行工具逻辑。"""return float(radius) * 2.0 * piasync def _arun(self, radius: Union[int, float]) -> float:"""异步执行工具逻辑。"""# 对于这个简单计算,同步和异步实现相同return self._run(radius)
将工具提供给 Agent
创建好工具后,您可以将它们放入一个列表中,并在初始化Agent时提供给它。
# 这是一个概念性示例,展示如何将工具列表传递给Agent
# 实际的Agent创建会更复杂,通常使用LangGraph
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_anthropic import ChatAnthropic
from langgraph.prebuilt import create_react_agent# 1. 初始化你需要的工具
search_tool = TavilySearchResults(max_results=2)
# 将我们自定义的工具和内置工具放在一个列表中
tools = [multiply, search_tool]# 2. 初始化一个支持工具调用的模型
model = ChatAnthropic(model="claude-3-5-sonnet-latest")# 3. 使用预构建函数创建Agent执行器
# agent_executor = create_react_agent(model, tools)# 4. 调用Agent
# query = "25乘以42的结果是多少?同时搜索一下关于LangChain的最新消息。"
# for s in agent_executor.stream({"messages": [("user", query)]}):
# print(s)
这个例子展示了如何将自定义的multiply工具和内置的TavilySearchResults工具结合起来,赋予Agent同时进行计算和网络搜索的能力。
第六部分:总结与后续学习路径
恭喜您!通过本指南的学习,您已经从LangChain的基础理念出发,掌握了其核心组件、现代化的编排语言LCEL,并亲手构建了一个实用的RAG问答应用,同时对更高级的Agent范式有了初步的了解。
我们回顾一下本次旅程的核心要点:
- 模块化架构: LangChain通过解耦的包结构提供了一个稳定且可扩展的开发平台。
- LCEL与Runnable协议: 这是现代LangChain应用的基石,它以声明式、可组合的方式构建数据流,并带来了流式处理、并行执行等诸多好处。
- RAG模式: 连接LLM与外部知识是构建事实准确、领域专属AI应用的关键。
- Agent与工具: 这是让LLM从一个“对话者”转变为一个“行动者”的核心范式,其关键在于为LLM提供清晰、准确的工具描述。
LangChain的世界远比本教程所展示的更为广阔。为了继续您的学习之旅,我们推荐以下路径:
- 深入可观测性: 访问 LangSmith 网站 (
https://smith.langchain.com/),注册一个账户,并为您刚刚构建的应用配置跟踪。亲眼观察每一步的输入输出,是提升调试和优化能力的最快方式。 - 学习应用部署: 查阅 LangServe 的官方文档 (
https://python.langchain.com/docs/langserve/),学习如何将您的RAG应用或Agent一键部署为可供其他服务调用的API。 - 精通高级Agent: 深入学习 LangGraph 的文档。掌握如何构建包含循环、分支和持久化状态的复杂Agent,这是通往构建真正自主AI系统的必经之路。
- 探索广阔生态: 浏览LangChain的“Integrations”文档部分和
langchain-community包的源码。您会发现一个由社区共同构建的、包含数百个模型、数据库、工具和数据加载器的庞大生态系统,它们将极大地加速您的开发进程。
AI应用开发的浪潮才刚刚开始,而LangChain为您提供了立于潮头的坚固冲浪板。祝您在构建智能未来的旅程中一帆风順!