Triton源代码分析 - 目录
torch.compile简介
Triton相对其他DL Compiler的主要优点就是Pytorch Native + Open Source。因此在介绍Triton之前,先简单介绍一下Pytorch的torch.compile。
在Pytorch 2.x中,引入了torch.compile特性,主要包含如下4个部分:
TorchDynamo:基于Python Frame Evaluation Hook技术,实现安全的Pytorch的计算图捕获。
AOTAutograd: AOT生成计算图的反向图。
PrimTorch:规范化2000+ PyTorch Operators为250+ Primitive Operators, 极大降低了开发Pytorch后端的难度。
TorchInductor:一个Deep Learning Compiler,为多种加速器生成高性能代码。对NVIDIA和AMD GPUs, 使用OpenAI Triton编译器作为Backend。
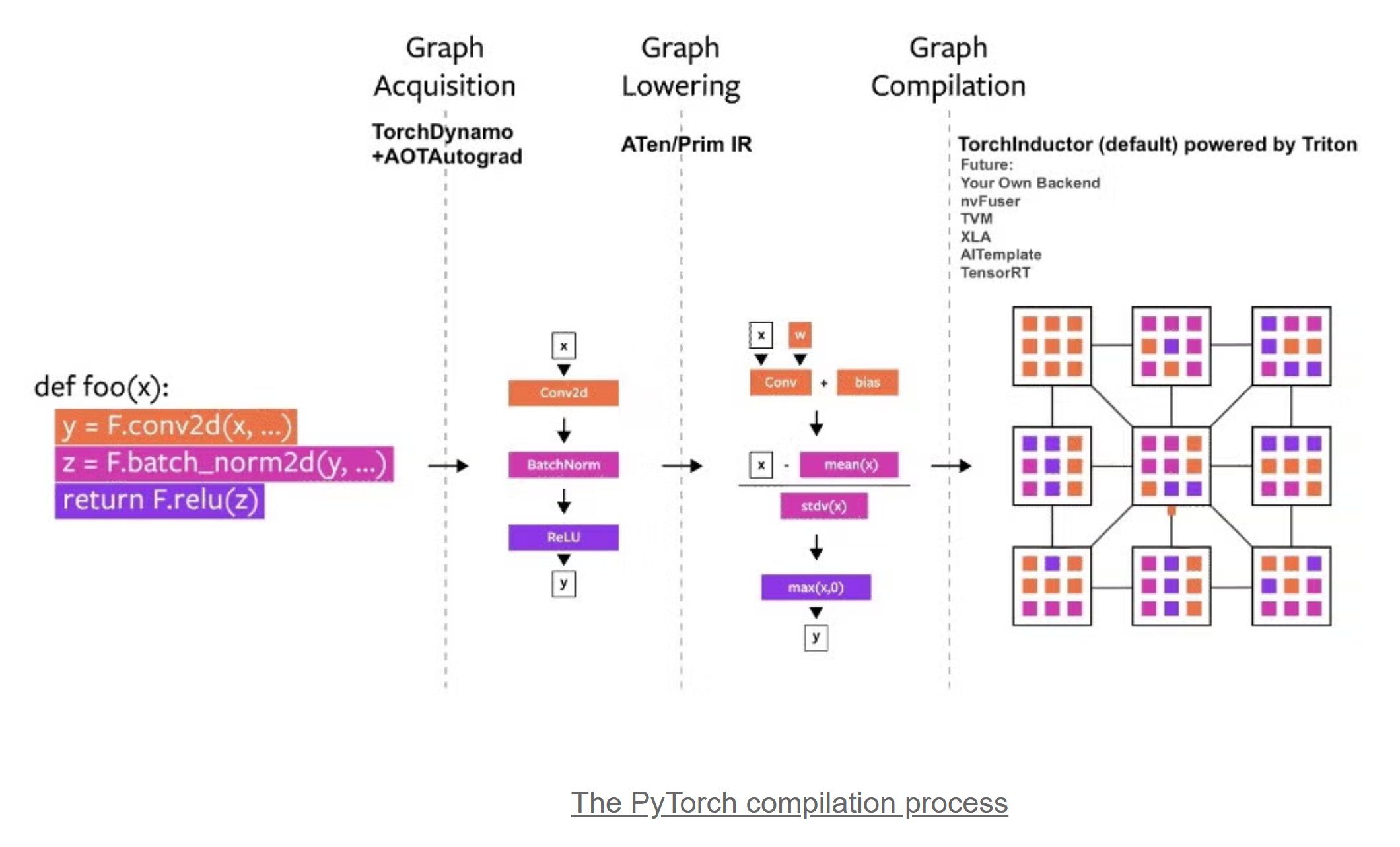
torch.compile编译过程如下:
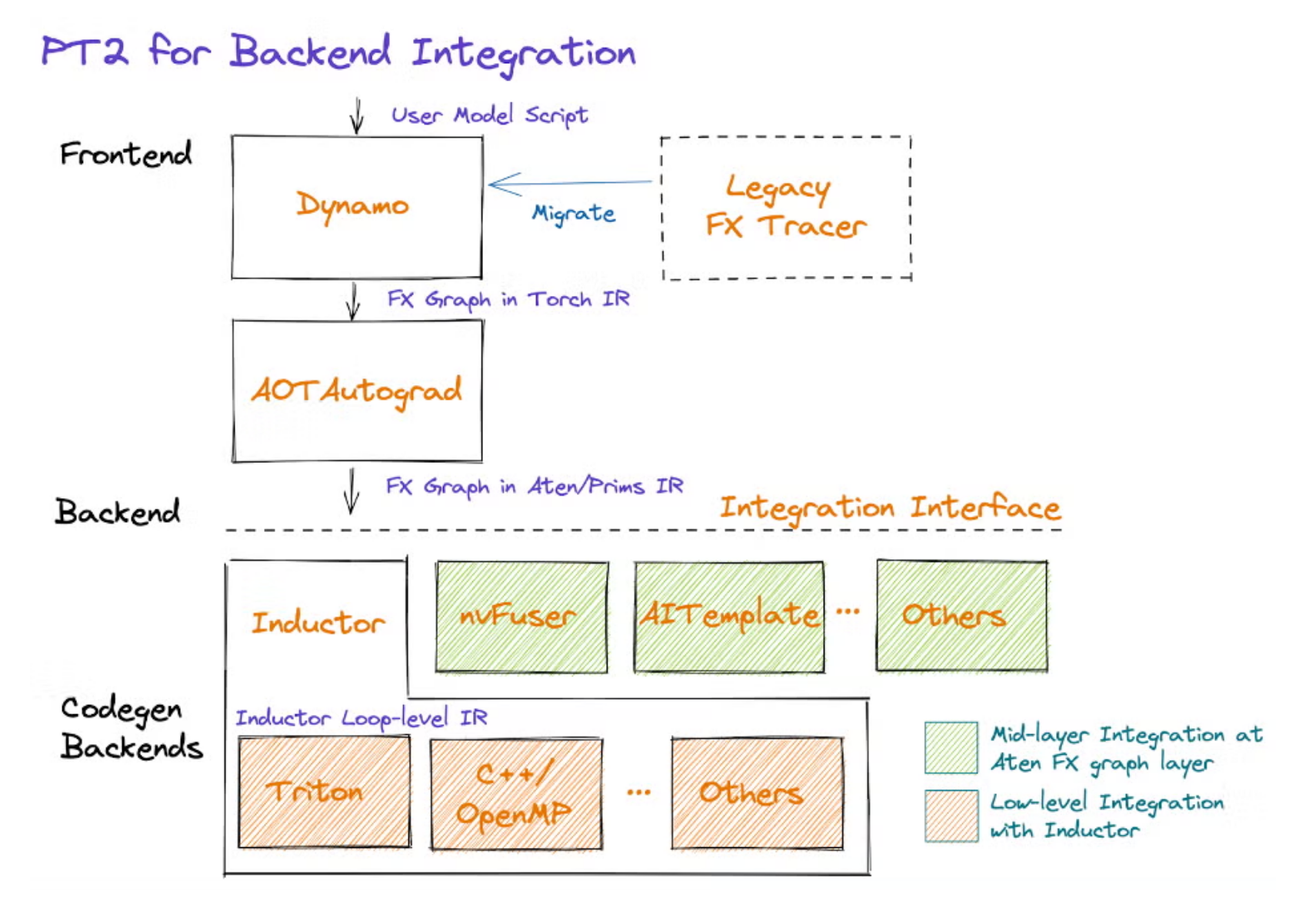
在图编译视角下,Pytorch的软件栈如下,Triton是Inductor的一个Codegen Backend:
Triton简介
编程模型
Triton是一种为并行编程设计的语言和编译器,旨在提供一个Python-based编程环境,提升DNN compute kernels的开发效率的同时,也能最大化利用现代GPU硬件的计算吞吐能力。
Triton的编程模型抽象基于Block,和GPU传统的基于Thread的编程模型对比:

Triton在基于基于Block的编程模型上解决了如下问题:
- automatic coalescing
- thread swizzling
- pre-fetching
- automatic vectorization
- tensor core-aware instruction selection
- shared memory allocation/synchronization
- asynchronous copy scheduling
设计哲学
在triton之前,DL Compiler的主流技术路线有2种:
-
Polyhedral Compilation:多面体编译,业界实践:Tiramisu,Tensor Comprehensions。
-
Scheduling Languages:调度语言(计算与调度分离),业界实践:Halide,TVM。
Polyhedral Compilation
传统编译器(如LLVM)的IR设计,使用(un)conditional branches来编码控制流,导致静态分析程序动态行为十分困难(如flow-sensitive的数据流分析等)。为了解决这个问题,多面体编译器采用了一种控制流静态可预测的IR形式,使能了编译期更激进的data locality和parallelism优化。但这种方法也有一系列的局限性。
多面体编译器主要聚焦在一类称为Static Control Parts (SCoP)的程序,这种程序需要满足连续语句的条件判断和循环边界是外围循环索引以及全局不变参数的仿射(affine)函数。这种程序的迭代域被放射不等式限定,代数定义如下:
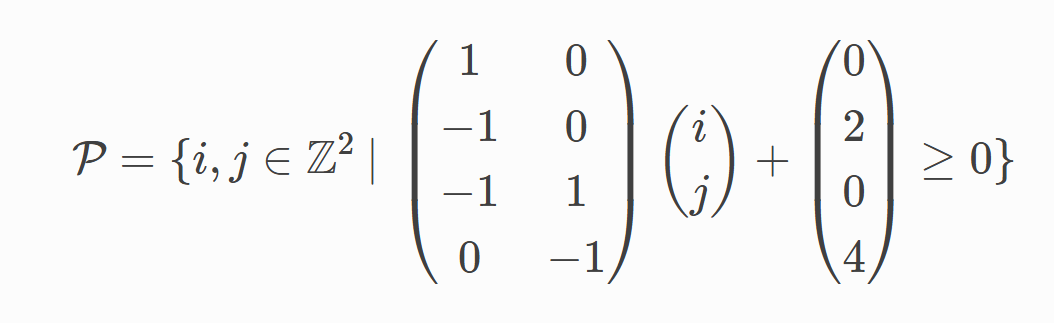
P中的每个点(i,j)代表了一个多面体语句(statement),该语句的属性:
1)不会导致控制流的side effect,即不能包含for,if,break之类的语句。
2)数组访问的索引表达式,是只包含循环索引和全局参数的仿射函数。
为了方便Alias Analysis,数组访问使用access function的数学形式抽象,即A[i][j]被写作A[f(i,j)]的形式,其中f被定义为:
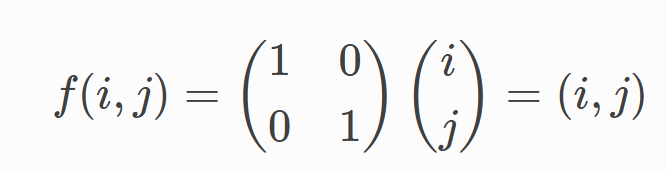
SCoP并未规定语句的执行顺序,意味着迭代域可以采用所有的合法序进行遍历,这就为一些优化如schedule提供了机会。schedule被形式化地定义为一个对循环索引loop indices x和全局不变量g的,p维的仿射变换。
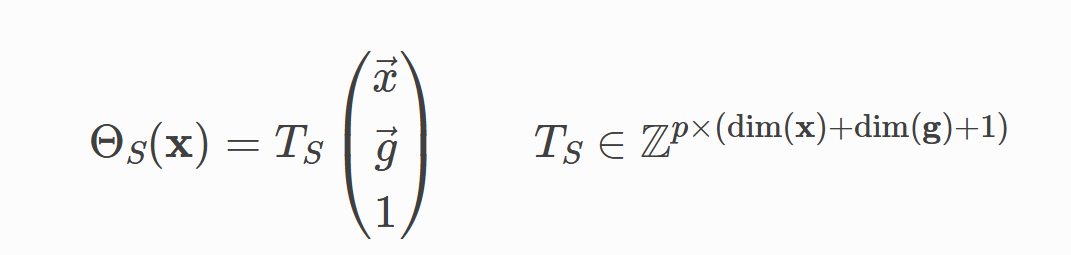
其中ΘS(x) 是一个p维的向量,从左到右依次是包裹语句S的变化从慢到快的循环索引。对上述示例,初始的schedule表达:
![]()
再举个例子,对如下程序,包裹语句S的σ=(i j k)T。
for (i = 0; i < N; ++i) // 变化最慢for (j = 0; j < M; ++j) // for (k = 0; k < K; ++k) // 变化最快S: A[i][j][k] = ...;满足多面体编译形式的程序可以很好地被变换和优化,通过产生新的schedule(语句执行的顺序)和迭代域(即循环索引的范围和结构),来使能循环优化(fusion/interchange/tiling/parallelization/...),提升并行性以及数据的空间/时间局部性。
对如下程序:
for (i = 0; i < N; ++i)for (j = 0; j < M; ++j)A[i][j] = B[i][j] + C[i][j];通过tiling变换为:
for (ii = 0; ii < N; ii += TILE)for (jj = 0; jj < M; jj += TILE)for (i = ii; i < min(ii + TILE, N); ++i)for (j = jj; j < min(jj + TILE, M); ++j)A[i][j] = B[i][j] + C[i][j];变换的结果是:
-
调度变了:原来是逐行逐列,现在是块状处理;
-
迭代域变了:原来是
(i, j),现在是(ii, jj, i, j);
带来的效果是:
-
并行性:每个块可以并行处理;
-
空间/时间局部性:块内数据在缓存中连续使用。
Polyhedral Compilation的优点:
- 不需要程序员在源代码中手动添加hint
- 自动完成程序语义变换前后的正确性验证
- 支持绝大多数常见的循环变换(在矩阵乘上可以获得媲美手写库的性能)
Polyhedral Compilation的局限性:
- 程序可能的变换集合Ω={ΘS | S∈program}过大,随Statement数量和迭代域(循环索引范围)增长,导致对程序变换的正确性验证需要求解复杂的整数线性规划问题。此外,硬件特性(cache size/SM数量/...),程序上下文特征(input tensor shapes)等也要被纳入这个框架计算,进一步加剧了该问题。
- 常规的稠密计算通常能满足SCoP形式,但(结构化)稀疏计算则不一定能满足。
Scheduling Languages
Halide和TVM通过scheduling language在语法层面分离了计算和调度.。在下面的矩阵乘示例中,计算的定义 (1-7行) 和调度(8-16行)完全正交, 意味着两者可以独立进行维护和优化。
注意到调度代码和硬件相关,所以不能被迁移,这个问题需要通过auto-scheduling机制(如TVM 中的AutoTVM/AutoScheduler/MetaSchedule)来解决。

Scheduling Languages的优点:
- 允许程序员只编写一次算法(计算),然后再通过调度优化性能,理论优化上限高于polyhedral。
Scheduling Languages的局限性:
- 开发效率较低
- 调度语言的循环界限和步长通常不能依赖外层循环索引,否则会严重限制调度空间,甚至导致系统崩溃,这对稀疏计算来说是个严重的问题。
循环界限依赖于外层循环索引的示例(k的上界依赖外层循环索引i):

Triton Shared
原生的Triton编译器的编译管线与GPU深度绑定,微软在原生Triton的基础上,在社区贡献了triton-shared项目,对接到了MLIR的linalg Dialect,方便支持其他类型的AI加速器。
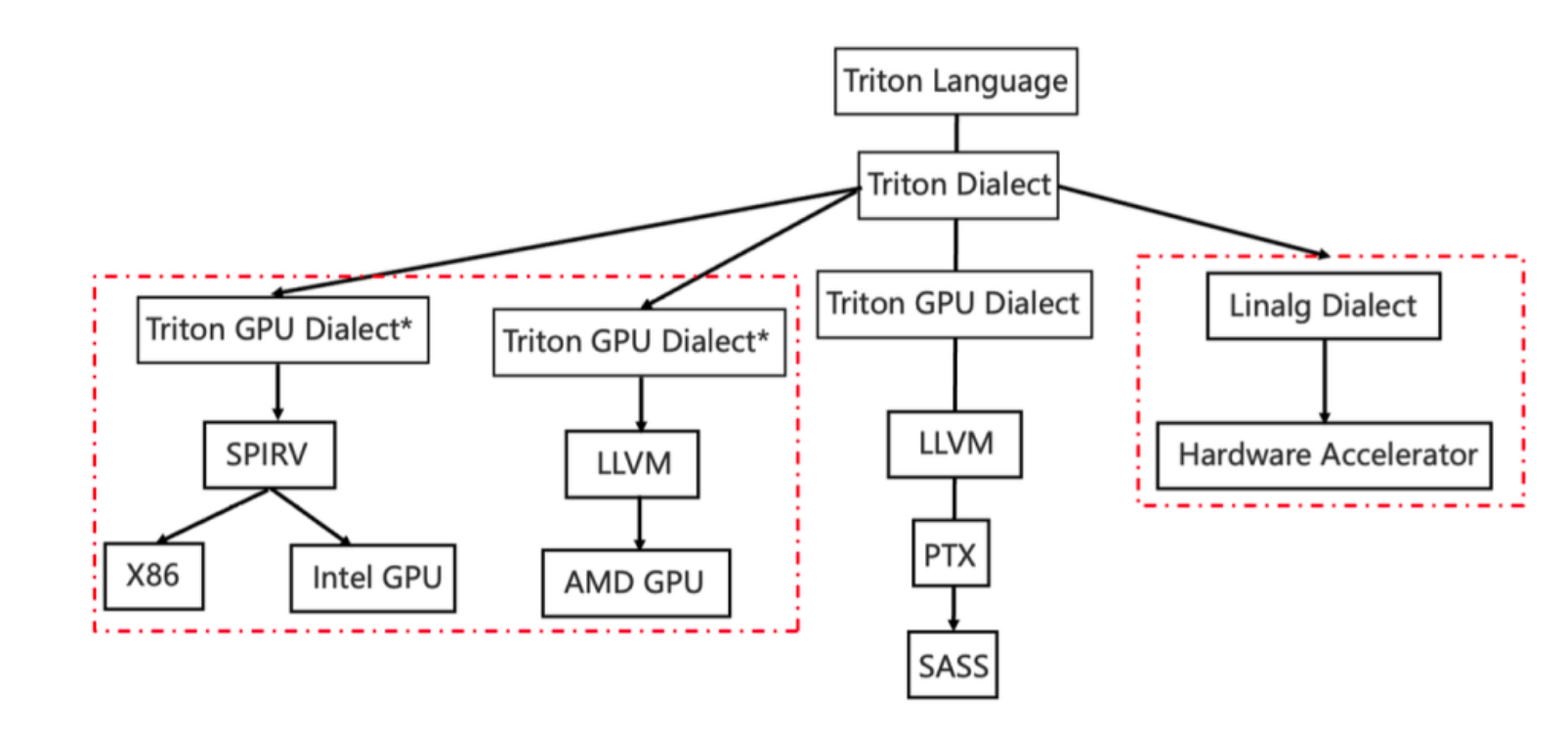
本系列文章先分析Triton-shared编译管线相关内容,后续视情况添加NVIDIA GPU编译管线相关内容,文章整理按照Dialect/Pass结构组织。
Triton Shared编译管线
待补充
Dialect目录
待补充
Pass目录
待补充
参考资料:
PyTorch 2.0: Our next generation release that is faster, more Pythonic and Dynamic as ever – PyTorch
TorchDynamo: An Experiment in Dynamic Python Bytecode Transformation - compiler - PyTorch Developer Mailing List
PyTorch 2.x
Welcome to Triton’s documentation! — Triton documentation
https://github.com/microsoft/triton-shared