使用binutils工具分析目标文件(贰)
目录
1.前言
2.目标文件的其他段
3.目标文件结构
4.目标文件中的文件头和魔数
5.目标文件中的段表
6.目标文件中的段总体信息
前言
通过博客《使用binutils工具分析目标文件(壹)》我们知道了目标文件的主要段的含义,以及代码经过汇编这一阶段后存储在目标文件的哪一个段中,而对于本篇博客则会深入讲解目标文件的总体结构(PS:以Linux下的ELF文件为例,因为作者使用Windows偏多,所以大多数的实验截图是在Windows上进行的,读者如果使用Linux偏多可以在Linux中实验)
目标文件的其他段
除了.text,.data,.bss等一些比较常用的段之外,目标文件还包含以下其他的段:
| 段名称 | 说明 |
| .rodata1 | Read only Data,这种段里存放的是只读数据,例如字符串常量,全局const变量 |
| .comment | 该段存储的是编译器的版本信息,例如"GCC:(GNU)4.2.0" |
| .debug | 调试信息 |
| .dynamic | 动态链接信息 |
| .hash | 符号哈希表 |
| .line | 调试时的行号表,即源代码的行号与编译后指令的对应表 |
| .note | 额外的编译器信息,比如程序的公司名称,分布版本号 |
| .strtab | String Table字符串表,用于存储目标文件中用到的各种字符串 |
| .symtab | Symbol Table符号表 |
| .shstrtab | Section String Table段名表 |
| .plt .got | 动态链接的跳转表和全局入口表 |
| .init .fini | 程序初始化与终结代码段 |
表1.目标文件中的其它段
目标文件结构
目标文件格式的最前部是目标文件的文件头(Header),包含了描述整个文件的基本属性,比如目标文件的版本,目标机器型号,程序入口地址等。紧接着则是目标文件的各个段,其中目标文件中与段有光的重要结构就是段表,该表描述了目标文件包含的所有段的信息,比如每一个段的段名,段的长度,在文件中的偏移,读写权限及段的其他属性。具体参考下图:
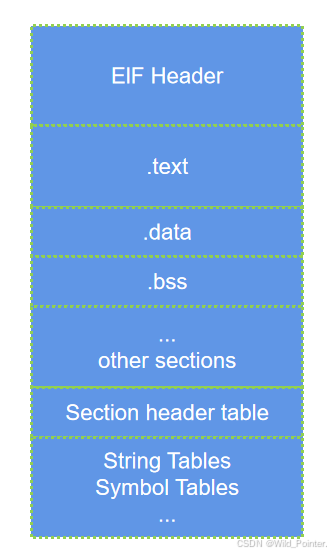
图1.目标文件结构
目标文件中的文件头和魔数
在Linux中我们可以使用以下命令来查看目标文件的信息
readelf -h xxx.o在Windows中我们可以使用以下命令查看目标文件的信息
objdumo -f xxx.o由于作者的实验主要是在Windows中进行的,所以以下截图是位于Windows中的。
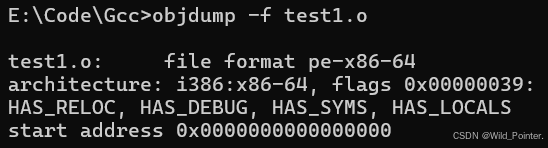
图2.Windows中目标文件信息
区别于Windows中输出的信息,Linux下输出的目标文件信息更多,并且Linux中的目标文件会输出有魔数。魔数的作用主要是确认文件的类型,操作系统在加载可执行文件的时候会确认魔数是否正确,不正确会拒绝加载。由于Windows平台下,GCC生成的目标文件遵循COFF或PE,而非Linux的ELF格式,而readelf命令仅支持ELF格式的目标文件,无法解析COFF/PE文件,会报错魔数不匹配,对于Linux中的ELF格式魔数为7f454c46c\XFELE,而Windows中的魔数为4D5ACMZ。
为了方便讲解目标文件头中定义的信息,我们参考Linux中输出的ELF文件的信息:
ELF Header:Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00Class: ELF32Data: 2`s complement, little endianVersion: 1(current)OS/ABI: UNIX - System VABI Version: 0Type: REL(Relocatable file)Machine: Intel 80386Version: 0x1Entry point address: 0x0Start of program headers: 0(bytes into file)Start of section headers: 280(bytes into file)Flags: 0x0Size of this header: 52(bytes)Size of program headers: 0(bytes)Number of program headers: 0Size of section headers: 40(bytes)Number of section headers: 11Section header string table index: 8以上这些是通过readelf指令输出Linux中目标文件(ELF)的信息,最前面的“Magic”的16个字节用于标识ELF文件的平台属性,具体如下图:
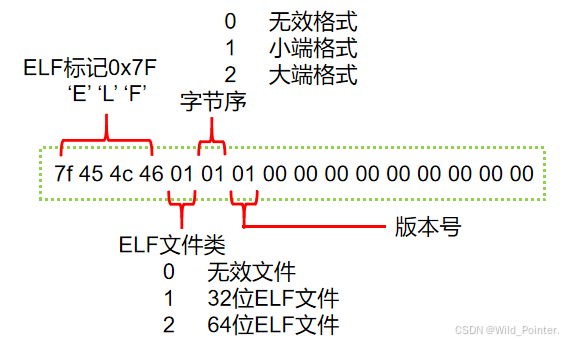
图3.ELF中魔数含义
我们只知道在强语言类型中定义一些数据都需要先为这些数据定义类型,比如是字符串string类型,还是整型int。而对于ELF文件中存储的这些数据也有对应的类型,这里我们以32位版本的目标文件头来作为例子,以下是该类型的ELF的结构
typedef struct{unsigned char e_ident[16]; // ELF魔数,文件类别,字节序,ELF版本号和操作系统/ABI标识Elf32_Half e_type; // 文件类型Elf32_Half e_machine; // ELF文件的CPU平台属性Elf32_Word e_version; // ELF版本号Elf32_Addr e_entry; // 入口地址Elf32_off e_phoff; // 程序头表文件偏移Elf32_off e_shoff; // 段表在文件中的偏移Elf32_Word e_flags; // ELF标志位Elf32_Half e_ehsize; // ELF文件头本身的大小Elf32_Half e_phentsize; // 程序头表项大小Elf32_Half e_phnum; // 程序头表项数量Elf32_Half e_shentsize; // 段表描述符的大小Elf32_Half e_shnum; // 段表描述符的数量Elf32_Half e_shstrndx; // 段表字符串表所在的段在段表中的下标
} Elf32_Endr;对于这些类型都有对应的长度,具体参考下表:
| 类型 | 描述 | 原始类型 | 长度(字节) |
| Elf32_Half | 32位版本的无符号短整型 | uint16_t | 2 |
| Elf32_Word | 32位版本无符号整型 | int32_t | 4 |
| Elf32_Addr | 32位版本程序地址 | uint32_t | 4 |
| Elf32_off | 32位版本的偏移地址 | uint32_t | 4 |
表2.32位程序的类型描述
目标文件中的段表
由于目标文件中存在很多的段,而在运行的时候需要检索这些段信息,为了方便检索这些信息则产生了段表,即存储这些段的基本属性,并且描述了目标文件中的各个段的信息。也就是说目标文件的段结构就是由段表决定的,编译器,链接器和装载器都是依靠段表来定位和访问各个段的属性的,而段表在目标文件的具体位置则是由目标文件头中的e_shoff成员决定的。
为了输出目标文件中的段表信息,我们在Linux中可以使用以下命令:
readelf -S xxx.o为了方便分析段表的各个类型和代表的含义,以下是输出的段表信息:
There are 11 section headers,starting at offset 0x118:
Section Headers:[Nr] Name Type Addr off Size Es Flg Lk Inf Al[0] NULL 00000000 000000 000000 00 0 0 0[1] .text PROGBITS 00000000 000034 00005b 00 AX 0 0 4[2] .rel.text REL 00000000 000428 000028 08 9 1 4[3] .data PROGBITS 00000000 000090 000008 00 WA 0 0 4[4] .bss NOBITS 00000000 000098 000004 00 WA 0 0 4[5] .rodata PROGBITS 00000000 000098 000004 00 A 0 0 1[6] .comment PROGBITS 00000000 00009c 00002a 00 0 0 1[7] .note.GNU-stack PROGBITS 00000000 0000c6 000000 00 0 0 1[8] .shstrtab STRTAB 00000000 0000c6 000051 00 0 0 1[9] .symtab SYMTAB 00000000 0002d0 0000f0 10 10 10 4[10] .strtab STRTAB 00000000 0003c0 000066 00 0 0 1
Key to Flags:W(write),A(alloc),X(execute),M(merge),S(strings)I(info),L(link order),G(group),X(unknown)O(extra OS processing required),O(OS specific),p(processot specific)类似于目标文件中的文件头,段表中的数据存储也是通过定义结构体的形式来实现的,具体的定义如下:
typedef struct{Elf32_Word sh_name; // 段名Elf32_Word sh_type; // 段的类型Elf32_Word sh_flags; // 段的标志位Elf32_Addr sh_addr; // 段的虚拟地址Elf32_Off sh_offset; // 段偏移Elf32_Word sh_size; // 段的长度Elf32_Word sh_link; // 段链接信息Elf32_Word sh_info; // 段链接信息Elf32_Word sh_addralign; // 段地址对齐Elf32_Word sh_entsize; // 项的长度
} Elf32_Shdr;对于段的类型,可以参考下表:
| 常量 | 值 | 含义 |
| SHT_NULL | 0 | 无效段 |
| SHT_PROGBITS | 1 | 程序段。代码段,数据段都是这种类型 |
| SHT_SYMATB | 2 | 标识该段的内容为符号表 |
| SHT_STRTAB | 3 | 标识该段的内容为字符串表 |
| SHT_RELA | 4 | 重定位表,该段包含了重定位信息 |
| SHT_HASH | 5 | 符号表的哈希表 |
| SHT_DYNAMIC | 6 | 动态链接信息 |
| SHT_NOTE | 7 | 提示性信息 |
| SHT_NOBITS | 8 | 标识该段在文件中没有内存,例如.bss段 |
| SHT_REL | 9 | 该段包含了重定位信息 |
| SHT_SHLIB | 10 | 保留段 |
| SHT_DNYSYM | 11 | 动态链接的符号表 |
表3.段的类型
对于段的标志为,主要标识该段在进程虚拟地址空间中的属性,比如是否可写,是否可执行等信息,具体参考下表:
| 常量 | 值 | 含义 |
| SHF_WRITE | 0 | 标识该段在进程空间可写 |
| SHF_ALLOC | 2 | 标识该段在进程空间中要分配空间 |
| SHF_EXECINSTR | 4 | 标识该段在进程空间中可以被执行,一般指代码段 |
表4.段的标志位
对于一些系统保留的段的类型和标志位,可以参考下表了解:
| 段名 | 段的类型 | 段的标志位 |
| .bss | SHT_NOBITS | SHF_ALLOC + SHF_WRITE |
| .comment | SHT_PROGBITS | none |
| .data | SHT_PTOGBITS | SHF_ALLOC + SHF_WRIRE |
| .data1 | SHT_PTOGBITS | SHF_ALLOC + SHF_WRIRE |
| .debug | SHT_PTOGBITS | none |
| .dynamic | SHT_DYNAMIC | SHF_ALLOC + SHF_WRIRE |
| .hash | SHT_HASH | SHF_ALLOC |
| .line | SHT_PTOGBITS | one |
| .note | SHT_NOTE | none |
| .rodata | SHT_PROGBITS | SHF_ALLOC |
| .rodata1 | SHT_PROGBITS | SHF_ALLOC |
| .shstrtab | SHT_STRTAB | none |
| .strtab | SHT_STRTAB | 如果该目标文件有可装载的段须要用到该字符串表,那么该字符串表也得被装载到进程空间,则有SHF_ALLOC标志位 |
| .symtab | SHT_STRTAB | 同字符串表 |
| .text | SHT_PROGBITS | SHF_ALLOC + SHF_EXECINSTR |
表5.系统保留段的类型和标志位
对于段的链接信息,如果段的类型是与链接相关的(无论是动态链接还是静态链接),比如重定位表,符号表等,那么sh_link和sh_info则可以参考下表:
| sh_type | sh_link | sh_info |
| SHT_DYNAMIC | 该段所使用的字符串表在段表中的下标 | 0 |
| SHT_HASH | 该段所使用的符号表在段表的下标 | 0 |
| SHT_REL | 该段所使用的相应符号表在段表中的下标 | 该重定位表所作用的段在段表中的下标 |
| SHT_RELA | ||
| SHT_SYMTAB | 操作系统相关的 | 操作系统相关的 |
| SHT_DYNSYM | ||
| other | SHN_UNDEF | 0 |
表6.段的链接信息
目标文件中的段总体信息
由于CPU的物理访问机制,每次访问4/8/16字节的整数倍地址,而0x167是439,不是4/8/16的整数倍。如果不填充字节的话会导致在访问Section Table时,第一次读取的地址位0x164到0x167但只有0x167属于Section Table的有效地址,导致后续的访问都需要进行数据的拼接处理。所以最终的目标文件中段的分布如下图:
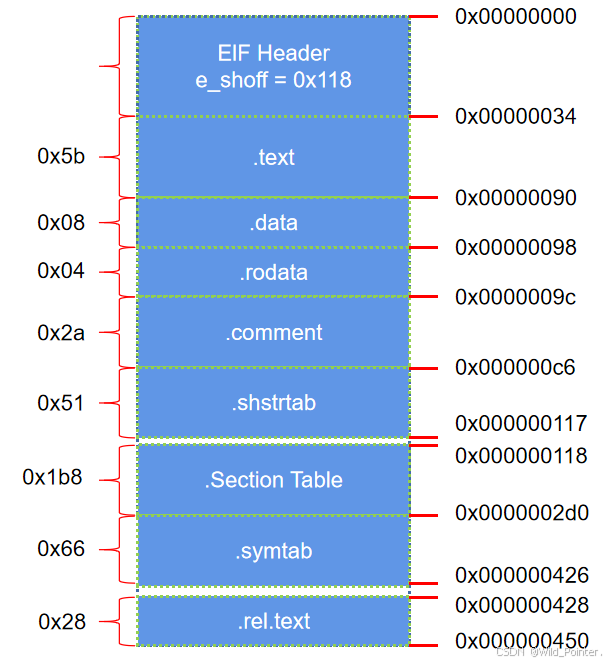
图4.目标文件中段的分布