MySQL的底层原理--InnoDB数据页结构
上一章节讲述完innodb存储的结构,本章我们则来讲述一下innodb的数据页结构。我们知道innodb每次读取数据则是取出一页进行读取,那么页的结构则是有多个部分组成:文件头部,页头部,页目录,用户记录,空闲空间,文件尾部,页中最大和最小记录。
| 部分名称 | 大小(字节) | 作用 |
|---|---|---|
| File Header(文件头) | 38 | 记录页的基本元数据(如页类型、校验值、前后页指针等) |
| Page Header(页头) | 56 | 记录页的内部管理信息(如记录数量、空闲空间偏移量、索引相关信息等) |
| Infimum + Supremum | 26 | 页内的虚拟最小 / 最大记录,作为 B+ 树索引的边界哨兵 |
| User Records(用户记录) | 动态 | 实际存储的用户数据记录(或索引记录),大小随数据量变化 |
| Free Space(空闲空间) | 动态 | 页内未使用的空间,用于新记录插入,随记录增删动态变化 |
| Page Directory(页目录) | 动态 | 记录用户记录的偏移量索引,加速页内记录查找(类似 “目录” 功能) |
| File Trailer(文件尾) | 8 | 用于页的完整性校验(校验和 + LSN),保障数据写入可靠性 |
下面我们来看看各部分的作用
用户记录&&空闲空间
在一个页中最开始是不会存放数据的,也就是说刚开始一个页中没有用户记录,所有的用户记录都是从空闲空间中分割出去的。
对于空闲空间和用户记录的回收和利用机制如下:
1. 标记删除机制
- 记录删除时,InnoDB 仅标记
deleted_flag=1,记录头被保留,实际数据未立即清除。 - 被删除记录的空间加入
PAGE_FREE指向的空闲链表,供后续插入复用。
2. 空间合并与整理
- purge 操作:后台线程定期清理标记删除的记录(purge),合并连续空闲空间,减少碎片。
- 页分裂 / 合并:当页空间使用率过低(如 <50%),InnoDB 可能触发页合并(将记录迁移至其他页)
页目录
在讲页目录之前,我们首先看一看上一章节所讲述的行记录的头信息字段。
在头信息字段中存放着多个有关行记录的属性
delete_flag:这个主要是用来标记当前记录是否删除,当删除之后则会进入到空闲链表中等待被复用
heap_no:在堆中的编号主要一般编号的大小对应着主键id,用来标识该记录在堆中的位置
next_record:是一个指向下一个行记录的指针
n_owned:则是重头戏,正式因为有了n_owned才会有了页目录的结构
当一个页中的数据过多的时候,我们进行访问的时候则可能需要从头开始访问,那么这样的访问方式往往是低效的,因此设计innodb的人就将一页数据进行分组,当数据为当前最后一组的时候n_owned的值则是当前组的数据个数,因为每个数据进行存放的时候都是按照主键的大小依次存放的,那么我们如果知道这组的最后一位主键大小和n_owned字段就能知道这组数据主键的位置,因此为了更好的查询数据,设计innodb的人则利用了n_owen字段将n_owned字段不为0的数据的地址放置到页目录中的插槽中去,这样页目录则存放着每组最后一个数据的偏移地址,当进行查询的时候采用二分法能快速的查询到想要的地址
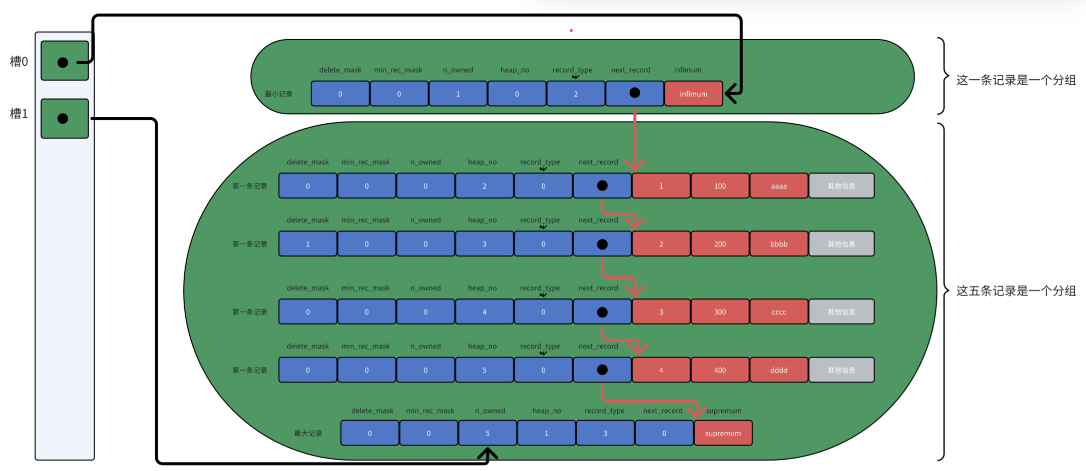
Infimum + Supremum
在innodb中的Infimum + Supremum表示着一页的最小记录和最大记录。其中Infimum则会单独分为一组,而Supremum则是存在最后一组一般为6-8个数据。在页生成的时候就会生成Infimum + Supremum这两条记录。
页头
Page Header则是存放着有关页专属的基本信息
| 字段名称 | 占用字节 | 说明 |
|---|---|---|
| PAGE_N_DIR_SLOTS | 2 | 页目录中存储的槽数量 |
| PAGE_HEAP_TOP | 2 | 未使用的最小空间地址,该地址往后为空闲空间 |
| PAGE_N_HEAP | 2 | 本页中的总记录数(包含正常记录、最大 / 最小记录、已删除记录) |
| PAGE_FREE | 2 | 第一个已标记为删除的记录地址,已删除记录通过next_record形成单链表可复用 |
| PAGE_GARBAGE | 2 | 已删除记录占用的总字节数 |
| PAGE_LAST_INSERT | 2 | 最后插入记录的位置 |
| PAGE_DIRECTION | 2 | 最后一条记录的插入方向(如主键值比上一条大则为 “右边”,反之 “左边”) |
| PAGE_N_DIRECTION | 2 | 同一方向连续插入的记录数量,方向改变时该值清空 |
| PAGE_N_RECS | 2 | 当前页的业务记录数量(不含最小 / 最大记录、已删除记录) |
| PAGE_MAX_TRX_ID | 8 | 修改当前页的最大事务 ID,仅在二级索引中定义 |
| PAGE_LEVEL | 2 | 当前页在 B + 树中所处的层级(叶子节点通常为 0,根节点层级最高) |
| PAGE_INDEX_ID | 8 | 索引 ID,标识当前页所属的索引 |
| PAGE_BTR_SEG_LEAF | 10 | B + 树叶子段的头部信息,仅在 B + 树的 Root 页中定义 |
| PAGE_BTR_SEG_TOP | 10 | B + 树非叶子段的头部信息,仅在 B + 树的 Root 页中定义 |
文件头
文件头则是存放着页的通用信息,也就是说每个页都必须含有的属性
| 字段名称 | 占用字节 | 说明 |
|---|---|---|
| FIL_PAGE_SPACE | 4 | 页所属的表空间 ID(space id) |
| FIL_PAGE_OFFSET | 4 | 页号,即页在表空间中的偏移值 |
| FIL_PAGE_PREV | 4 | 当前页的上一页 |
| FIL_PAGE_NEXT | 4 | 当前页的下一页 |
| FIL_PAGE_LSN | 8 | 日志序列号,代表该页最后被修改的日志序列位置 |
| FIL_PAGE_TYPE | 2 | 页类型,如 0x45BF 代表 B + 树叶子节点(存放数据的数据页) |
| FIL_PAGE_FILE_FLUSH_LSN | 8 | 文件的日志序列号,仅文件的第一页的此字段有效 |
| FIL_PAGE_ARCH_LOG_NO | 4 | 归档日志文件号 |
文件尾部
文件尾部的作用主要是用来校验页是否完整,如果修改完一个页想要把他写入磁盘中,那么写到一般断电了就会导致数据错误,文件尾部有一个专门的校验码与文件头部的校验码一致,当读取页的时候如果发现文件头和文件尾部的校验码不一致则证明页出现了问题。