基于HMM的词性标注方法详解(HMM+Viterbi,例题分析)
摘要:在自然语言处理领域,词性标注作为文本分析的基础任务,旨在为句子中的每个词语判定其语法范畴并赋予相应的词性标签(如名词、形容词等),从而简洁有效地表示词语在句子中的语法角色。词性信息对于命名实体识别、信息抽取等下游任务至关重要。本文重点介绍并深入探讨了基于隐马尔可夫模型(HMM)的词性标注方法。该方法将词性标注视为序列标注问题,利用HMM建模词语序列(观测序列)与词性序列(隐藏状态序列)之间的概率关系。文章系统阐述了HMM的核心概念(初始状态概率、状态转移概率、观测概率)、模型参数估计方法,并详细解析了利用维特比(Viterbi)算法进行解码以寻找最可能词性序列的动态规划过程。在人民日报语料库上的实验表明,HMM词性标注模型在标准分词结果上取得了97.93%的准确率,但分词错误会显著影响词性标注性能。分析表明,HMM模型具有模型直观、训练和解码效率较高等优点,但其强观测独立性假设也构成了一定的局限性。
关键词:词性标注;隐马尔可夫模型(HMM);维特比(Viterbi)算法
1.引言
随着人工智能技术的飞速发展,自然语言处理(NLP)作为其核心领域之一,正深刻改变着我们的生活和工作方式,从智能语音助手到搜索引擎和机器翻译,NLP的应用无处不在。传统自然语言处理将语言理解与分析视为一个层次化过程,包括词法分析、句法分析与语义分析三个层面。词法分析作为基础层面,涵盖词性标注(POS Tagging)、词义消歧(WSD)与命名实体识别(NER)等任务,为上层任务提供帮助[1]。
词性标注作为词法分析中极具代表性的一项任务,其目的在于判定句子中每个词语的语法范畴并赋予相应的词性标签。如对于句子:
![]()
通过词性标注可以得到相应的词性标签序列:
![]()
其中
![]()
即是词语
![]()
所对应的词性标签,示例如图1所示,其中“watch”的词性为“NN”,即名词[1]。词性标注作为自然语言处理中一个重要的研究课题,具有深刻的意义。它广泛应用于:机器翻译、文本分类、语音识别 、信息检索等领域[2]。
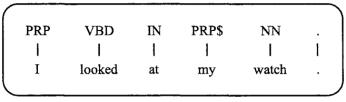
图 1 词性标注示例
目前,词性标注模型大多是基于统计方法的,常见的方法包括隐马尔科夫模型,条件随机场模型,最大熵模型等等。与其他模型相比。隐马尔科夫模型相对更简洁明了,易于实现,复杂度较低,同时具有不错的效果,在词性标注问题下是一个比较合适的模型[5]。因此,本文选择基于隐马尔科夫模型的词性标注问题来进行研究。
2.基于HMM的词性标注
2.1 HMM模型
隐马尔可夫模型是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测从而产生观测随机序列的过程。隐藏的马尔可夫链随机生成的状态的序列,称为状态序列(state sequence);每个状态生成一个观测,而由此产生的观测的随机序列,称为观测序列(observation sequence)。序列的每一个位置又可以看作是一个时刻[3]。
隐马尔可夫模型由初始概率分布、状态转移概率分布以及观测概率分布确定。隐马尔可夫模型的形式定义如下:
设Q是所有可能的状态的集合,V是所有可能的观测的集合:
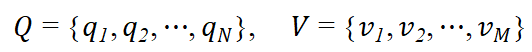
其中,N是可能的状态数,M是可能的观测数。
I是长度为T的状态序列,O是对应的观测序列:
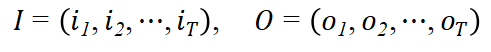
A是状态转移概率矩阵:

其中,
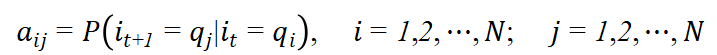
是在时刻t处于状态
![]()
的条件下在时刻t+1转移到状态
![]()
的概率。
B是观测概率矩阵:
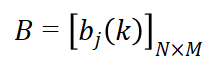
其中,
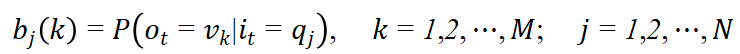
是在时刻t处于状态
![]()
的条件下生成观测
![]()
的概率。
π是初始状态概率向量:
![]()
其中,
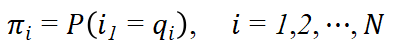
是时刻t=1处于状态
![]()
的概率。
隐马尔可夫模型由初始状态概率向量π、状态转移概率矩阵A和观测概率矩阵B决定。π和A决定状态序列,B决定观测序列。因此,隐马尔可夫模型λ可以用三元符号表示,即
![]()
A,B,π,称为隐马尔可夫模型的三要素。
状态转移概率矩阵A与初始状态概率向量π确定了隐藏的马尔可夫链,生成不可观测的状态序列。观测概率矩阵B确定了如何从状态生成观测,与状态序列综合确定了如何产生观测序列。
从定义可知,隐马尔可夫模型作了两个基本假设:
(1)齐次马尔可夫性假设,即假设隐藏的马尔可夫链在任意时刻t的状态只依赖于其前一时刻的状态,与其他时刻的状态及观测无关,也与时刻t无关:
![]()
(2)观测独立性假设,即假设任意时刻的观测只依赖于该时刻的马尔可夫链的状态,与其他观测及状态无关:
![]()
隐马尔可夫模型可以用于标注,这时状态对应着标记。标注问题是给定观测的序列,预测其对应的标记序列。可以假设标注问题的数据是由隐马尔可夫模型生成的。这样我们可以利用隐马尔可夫模型的学习与预测算法进行标注。
为了加深对前面定义的理解,下面看一个隐马尔科夫的例子:
假设有4个盒子,每个盒子里都装有红、白两种颜色的球,盒子里的红、白球数由表1列出。
表 1 各个盒子的红、白球数

按照下面的方法抽球,产生一个球的颜色的观测序列:
-
开始,从4个盒子里以等概率随机选取1个盒子,从这个盒子里随机抽出1个球,记录其颜色后,放回;
-
然后,从当前盒子随机转移到下一个盒子,规则是:如果当前盒子是盒子1,那么下一盒子一定是盒子2;如果当前是盒子2或3,那么分别以概率0.4和0.6转移到左边或右边的盒子;如果当前是盒子4,那么各以0.5的概率停留在盒子4或转移到盒子3;
-
确定转移的盒子后,再从这个盒子里随机抽出1个球,记录其颜色,放回;
-
如此下去,重复进行5次,得到一个球的颜色的观测序列:
O=(红,红,白,白,红)
在这个过程中,观察者只能观测到球的颜色的序列,观测不到球是从哪个盒子取出的,即观测不到盒子的序列。
在这个例子中有两个随机序列,一个是盒子的序列(状态序列),一个是球的颜色的观测序列(观测序列)。前者是隐藏的,只有后者是可观测的。这是一个隐马尔可夫模型的例子。根据所给条件,可以明确状态集合、观测集合、序列长度以及模型的三要素。
盒子对应状态,状态的集合是:
Q={盒子1,盒子2,盒子3,盒子4}, N=4
球的颜色对应观测。观测的集合是:
V={红,白}, M=2
状态序列和观测序列长度T=5。
初始概率分布为:
![]()
状态转移概率分布A和观测概率分布B分别如下:
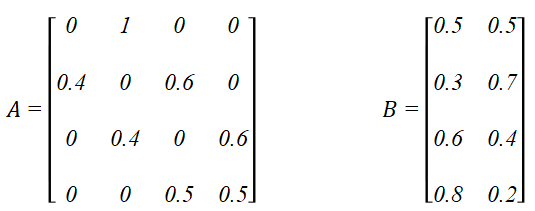
2.2 HMM的三个基本问题
隐马尔可夫模型有3个基本问题[3]:
1.概率计算问题。给定模型
![]()
和观测序列
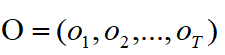
,计算在模型λ 下观测序列O出现的概率
![]()
2.学习问题。已知观测序列
![]()
,估计模型
![]()
参数,使得在该模型下观测序列概率
![]()
最大。即用极大似然估计的方法估计参数。
3.预测问题,也称为解码(decoding)问题。已知模型
![]()
和观测序列
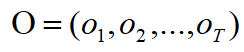
,求对给定观测序列条件概率
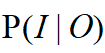
最大的状态序列
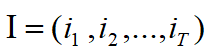
。即给定观测序列,求最有可能的对应的状态序列。
2.3基于HMM的词性标注过程
基于HMM得词性标注主要思想是利用λ、I、O这三个参数来解决词性的预测问题。将每个词语的词性集{nr(人名),ns(地名),nt(机构名),t(时间),uv(连词)…}作为HMM模型的状态值集合Q,将状态值集合与训练语料进行计算得到λ中的三个参数,然后将待标注语句作为观测序列O,通过λ和观测序列O求解
![]()
的最大值得到状态序列I,从而得到词性标注结果[4]。词性标注流程如图2所示。
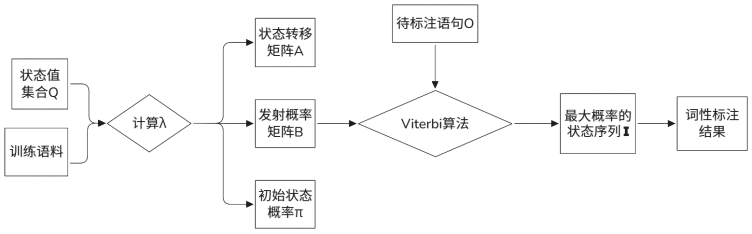
图 2 词性标注流程图
在求解状态序列时采用维特比(Viterbi algorithm,Viterbi)算法,关于Viterbi算法会在2.4节进行详细介绍,这里我们只需要知道我们将计算得到的λ和待标注语句O输入到Viterbi算法后将会得到最大概率状态序列的输出I,这个I就是待标注语句对应的词性序列。
2.4 维特比算法(Viterbi)
维特比算法实际是用动态规划(dynamic programming)解隐马尔可夫模型预测问题,即用动态规划求概率最大路径(最优路径)。这时一条路径对应着一个状态序列。 
首先导入两个变量
![]()
定义在时刻t状态为i的所有单个路径
![]()
中概率最大值为
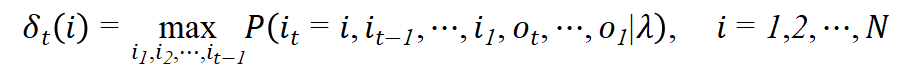
这里的
![]()
是观测序列O。
由定义可得变量
![]()
的递推公式:
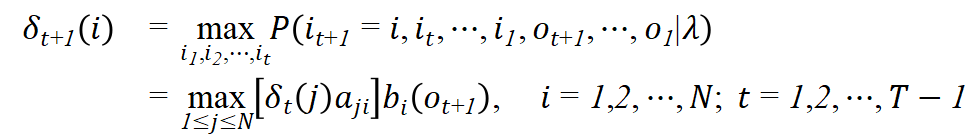
定义在时刻t状态为i的所有单个路径
![]()
中概率最大的路径的第t-1个结点为
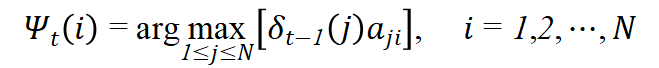
下面介绍维特比算法:
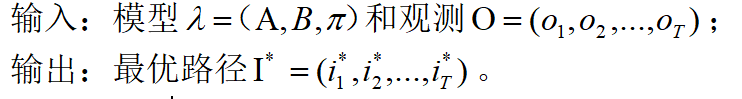

由于公式有些复杂,下面通过一个例子来说明维特比算法。

解:按照维特比算法计算:
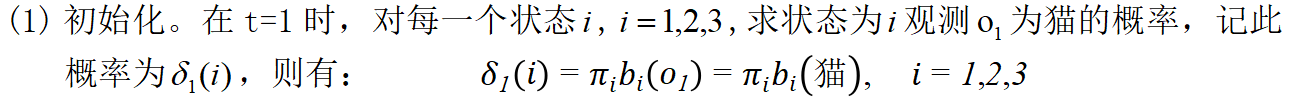


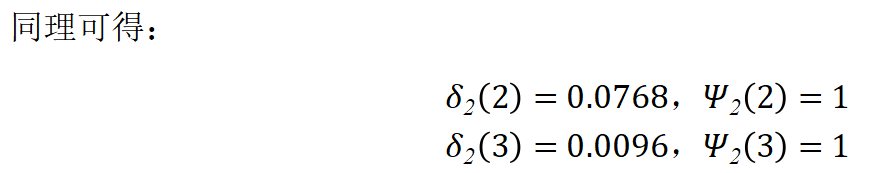
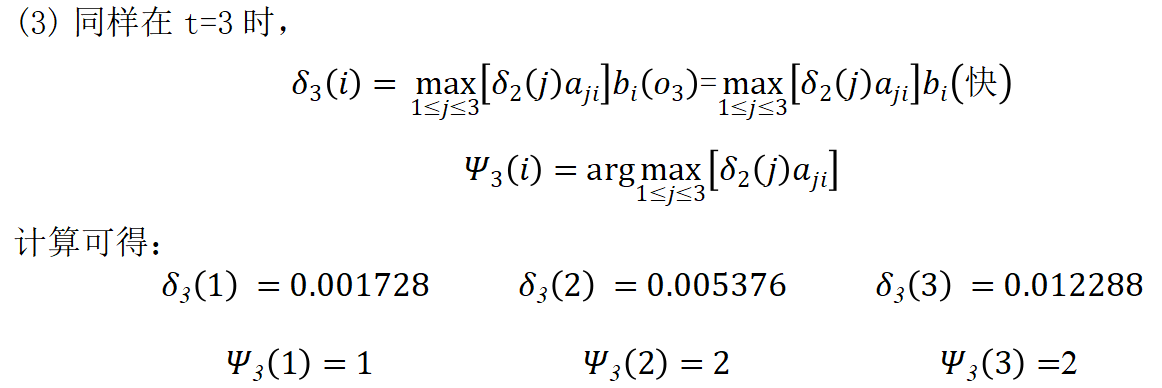
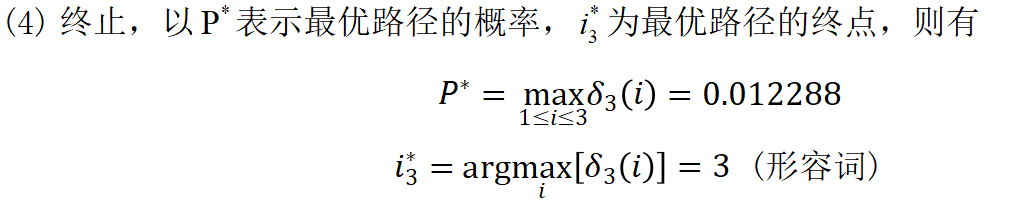


3.实验
参考博客地址:基于Hmm模型和Viterbi算法的中文分词和词性标注_bmes分词模型-CSDN博客
3.1 实验设计
在本项目中,设计了最大概率分词模型和基于隐马尔可夫模型+维特比算法的词性标注模型,并使用人民日报语料库作为训练集进行了训练和测试。
3.2 实验数据
本次实验使用的是中文语料库,具体为人民日报语料库。人民日报语料库采用的词性标签有26个基本词类标记,例如:形容词a、副词d和动词v等。语料库中还有 74 个扩充标记,对于语素(语言中最小的意义单位,是构成词语的基本元素),有Ag(形容词性语素)、Mg(名词性语素)等。
参考博客:
3.3实验结果
1.词性标注效果展示
输入句子:中国 的 改革 开放 和 现代化 建设 继续 向前 迈进
输出的词性标注结果:
['中国/n', '的/u', '改革/v', '开放/v', '和/c', '现代化/v', '建设/v', '继续/v', '向前/v', '迈进/v']

图 3 词性标注结果运行图
2.对分词模型进行评估
选取语料库中的6000行数据进行评估,运行结果如下图:

图 4 最大概率分词模型评估
由评估结果可知,最大概率分词模型效果很好,在精确率、召回率和F1分数上都表现良好,说明模型具有较高的准确性和鲁棒性。
3.对基于HMM词性标注模型进行评估
选取语料库中的2000行数据进行评估,运行结果如下图:

图 5 标准分词结果的词性标注评估
图 6 使用最大概率分词模型的预测结果的词性标注评估
使用标准分词的词性标注评估结果(97.93%)远高于使用最大概率分词的预测结果的词性标注评估(94.14%),这说明了词性标注本身准确率较高,但分词环节引入了错误,并且分词错误会传导到词性标注环节,导致整体准确率下降。
4.结语
本文系统探讨了基于隐马尔可夫模型(HMM)的词性标注方法,通过理论分析与实验验证,证实了HMM在序列标注任务中的有效性。实验结果表明,在标准分词的人民日报语料库上,HMM模型取得了97.93%的标注准确率,凸显了其作为经典概率图模型在词法分析中的实用价值。然而,研究也揭示了HMM的局限性:强观测独立性假设削弱了对上下文复杂依赖的建模能力,且分词错误会显著降低标注性能(如最大概率分词导致准确率下降至94.14%)。
HMM的核心优势在于模型简洁性与计算高效性。其通过状态转移概率矩阵A、观测概率矩阵B和初始状态概率向量π三要素,清晰建模词性与词语的联合概率分布,配合维特比算法的动态规划解码,实现了线性时间复杂度的高效标注[3]。这一特性使其在小规模语料或实时场景中仍具竞争力。
尽管如此,当前主流研究已转向能捕捉长距离依赖的模型(如CRF、BiLSTM)。例如,融合HMM与CRF的混合模型可兼顾局部特征与全局约束,提升实体抽取效果[4]。而低资源场景下的无监督词性标注[1]也代表了重要发展方向。
未来工作可从以下方面推进:
- 增强上下文建模:引入神经网络(如Transformer)改进发射概率计算,弱化独立性假设。
- 分词-标注联合优化:设计端到端管道,减少错误传导[6]。
- 跨语言迁移:探索多语言词性标签的统一表示,提升资源稀缺语言的标注性能。
词性标注作为NLP的基础环节,其技术进步将持续为语义理解、信息抽取等高层任务提供支撑。HMM虽非当前最优解,但其概率框架与动态规划思想仍为后续研究奠定了重要基础。
参考文献
[1]李扬.基于条件随机场自编码器的无监督与低资源词性标注[D].苏州大学,2023.DOI:10.27351/d.cnki.gszhu.2023.001654.
[2]牛秀萍.基于隐马尔科夫模型词性标注的研究[D].太原理工大学,2013.
[3]李航. 统计学习方法. 北京:清华大学出版社,2012.
[4]张航,文斌.基于HMM+CRF词性标注的实体抽取方法[J].计算机与数字工程,2023,51(12):2929-2933.
[5]张雄翼.隐马尔科夫模型在词性标注问题中的应用[D].清华大学,2017.DOI:10.27266/d.cnki.gqhau.2017.000034.
[6] Manning C D, Schütze H. Foundations of Statistical Natural Language Processing[M]. Cambridge: MIT Press, 1999.