抖音短视频矩阵系统源码搭建---底层框架5年开发分享
短视频矩阵系统的源码搭建,这是一个技术性很强的话题。用户提到"底层框架5年开发分享",表明他们希望了解构建这样一个系统的底层技术框架,并且是来自有5年开发经验的专业人士的分享。
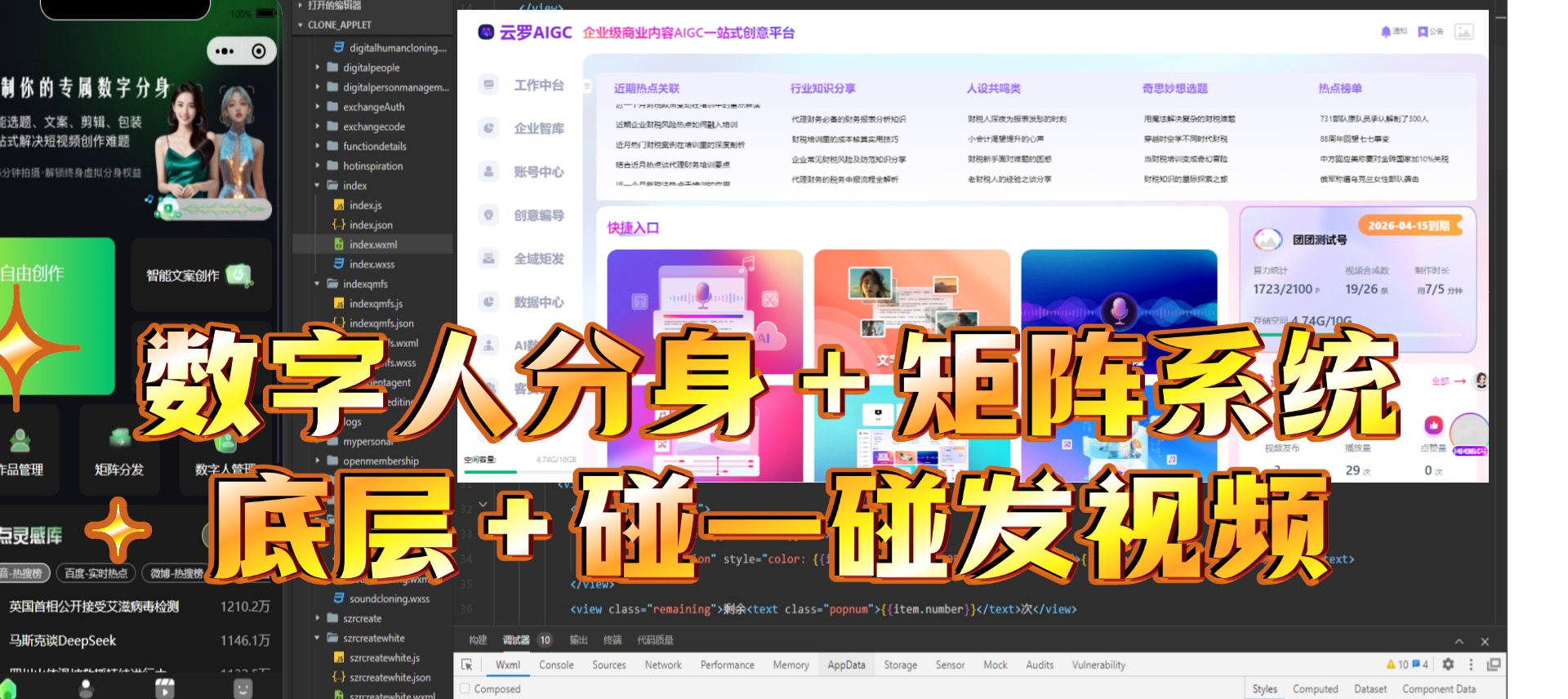
短视频矩阵的核心价值
- 多账号管理:集中管理抖音、快手、B 站、TikTok 等平台账号,支持批量操作。
- 内容分发自动化:一键发布视频至多个平台,提升运营效率。
- 数据聚合分析:实时监控播放量、点赞、评论等核心指标。
- 流量协同:通过矩阵账号互相引流,放大内容曝光。
系统架构设计
采用微服务架构与前后端分离模式,结合多语言技术栈实现高扩展性。核心模块设计如下:
账号管理服务(Spring Boot + Redis)
对接抖音开放平台API,实现多平台账号授权(OAuth2.0)
Redis缓存Session及Token,支持分布式锁防止并发冲突
多账号状态同步(通过定时任务刷新Token)
内容处理引擎(Python + FFmpeg + OpenCV)
视频批量剪辑:基于FFmpeg实现视频切片、转码、拼接
AI去重算法:帧哈希比对(OpenCV) + 随机帧混剪
元数据注入:动态添加水印、标题、地理位置信息
分发调度服务(Go + Kafka)
协程池管理高并发任务,支持抖音/快手/B站多平台适配
Kafka队列实现定时发布、失败重试、流量削峰
动态路由策略:根据账号权重分配发布任务
数据监控面板(Vue3 + ECharts)
实时统计播放量、点赞率、粉丝增长趋势
SQL动态查询优化(MyBatis-Plus分页插件)
异常告警:API调用失败率超过阈值触发邮件通知
核心模块代码实现
多平台账号授权(Java示例)
// 抖音Token刷新服务
public class DouyinTokenService {
@Autowired
private RedisTemplate<String, String> redisTemplate;
@Scheduled(fixedDelay = 3600000) // 每小时刷新一次
public void refreshAccessToken() {
List<Account> accounts = accountRepository.findAll();
accounts.forEach(acc -> {
String newToken = fetchTokenFromAPI(acc.getRefreshToken());
redisTemplate.opsForValue().set(
"douyin:token:" + acc.getId(),
newToken,
1, TimeUnit.HOURS
);
});
}
}
AI写代码
视频去重算法(Python示例)
import cv2
import numpy as np
def generate_video_fingerprint(video_path):
cap = cv2.VideoCapture(video_path)
fingerprints = []
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 帧处理:灰度化 + 缩放到16x16
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
resized = cv2.resize(gray, (16, 16))
# 计算均值哈希
avg = np.mean(resized)
hash_str = ''.join(['1' if x > avg else '0' for x in resized.flatten()])
fingerprints.append(hash_str)
cap.release()
return fingerprints
# 相似度比对(汉明距离)
def is_duplicate(hash1, hash2, threshold=0.85):
mismatch = sum(c1 != c2 for c1, c2 in zip(hash1, hash2))
return mismatch / len(hash1) < (1 - threshold)
AI写代码
高并发任务调度(Go示例)
func ScheduleTasks(ctx context.Context, tasks []VideoTask) {
// 协程池控制并发数
workerPool := make(chan struct{}, 100) // 最大100并发
var wg sync.WaitGroup
for _, task := range tasks {
wg.Add(1)
workerPool <- struct{}{}
go func(t VideoTask) {
defer func() {
<-workerPool
wg.Done()
}()
// 任务执行逻辑
if err := PublishVideo(t); err != nil {
log.Printf("任务 %s 执行失败: %v", t.ID, err)
RetryQueue.Push(t) // 加入重试队列
}
}(task)
}
wg.Wait()
}
AI写代码
关键技术难点与解决方案
高并发任务调度
分级队列:紧急任务使用内存队列(Redis Streams),普通任务持久化到Kafka
负载均衡:基于账号权重动态分配任务,避免单账号频繁调用触发风控
重试机制:指数退避策略(1s/5s/30s) + 死信队列人工处理
平台风控绕过
设备指纹伪装:动态生成设备ID、MAC地址、GPS偏移坐标
行为模拟:
随机化发布时间间隔(30-120秒)
模拟用户滑动操作(Selenium自动化)
混合真实评论内容(NLP文本生成)
视频去重优化
多层哈希校验:帧哈希(OpenCV) + 音频波形哈希(librosa) + 元数据混淆
动态修改策略:
随机插入转场特效(FFmpeg滤镜)
调整视频播放速度(0.9x-1.1x)
添加随机画中画图层
数据库与存储设计
核心表结构
-- 账号表(支持多平台)
CREATE TABLE account (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
platform VARCHAR(20) NOT NULL, -- 平台类型
open_id VARCHAR(255) NOT NULL, -- 开放平台ID
access_token VARCHAR(512) NOT NULL,
refresh_token VARCHAR(512) NOT NULL,
last_sync_time DATETIME DEFAULT CURRENT_TIMESTAMP
);
-- 视频任务表
CREATE TABLE video_task (
task_id VARCHAR(64) PRIMARY KEY,
account_id BIGINT NOT NULL,
video_path VARCHAR(1024) NOT NULL,
status ENUM('pending', 'processing', 'published', 'failed') NOT NULL,
publish_time DATETIME NOT NULL,
retry_count INT DEFAULT 0,
FOREIGN KEY (account_id) REFERENCES account(id)
);
AI写代码
存储优化方案
冷热数据分离:
热数据:Redis缓存账号状态、任务队列
冷数据:MySQL归档历史任务记录
视频分片存储:
使用MinIO对象存储,按日期分片(如/2023/08/20/video001.mp4)
预签名URL实现临时访问授权
部署与监控
服务器配置建议
组件 配置要求
应用服务器 8核16GB + SSD(部署K8s Pod)
消息队列 Kafka 3节点集群 + 副本因子=3
数据库 MySQL 8.0主从集群 + ProxySQL路由
监控指标
系统层面:CPU/Memory使用率、网络IO、磁盘吞吐量
业务层面:
账号日均发布成功率(>95%)
视频去重率(动态阈值调整)
API平均响应时间(<500ms)
完整源码结构
douyin-matrix/
├── account-service/ # 账号管理服务
│ ├── src/main/java/
│ │ ├── controller/ # 接口层
│ │ ├── service/ # 业务逻辑
│ │ └── config/ # Redis/MySQL配置
├── video-processor/ # 视频处理
│ ├── src/
│ │ ├── main.py # 入口脚本
│ │ └── utils/ # FFmpeg/OpenCV工具类
├── task-scheduler/ # 任务调度
│ ├── go.mod # Go依赖管理
│ └── internal/
│ ├── kafka/ # 生产者/消费者
│ └── taskmgr/ # 协程池实现
└── web-admin/ # 管理后台
├── public/ # 静态资源
└── src/
├── api/ # Axios封装
└── views/ # 数据可视化页面
AI写代码
开发注意事项
抖音API合规性
使用抖音开放平台官方接口,禁止逆向工程
遵守《抖音开放平台运营规范》,设置合理的API调用频率(建议≤30次/分钟)
代码安全
Token等敏感信息通过Vault或K8s Secret管理,禁止硬编码
视频存储路径加密(AES-256),防止未授权访问
灰度发布策略
新账号先进入沙盒环境测试,验证通过后再加入生产队列
使用Feature Toggle控制算法版本切换
技术选型与架构设计
1. 基础技术栈
后端框架:Python + Django(快速开发) / Go + Gin(高性能)
前端框架:Vue.js + Element UI(管理后台) / React Native(移动端)
数据库:MySQL(结构化数据) + MongoDB(日志 / 行为数据)
消息队列:RabbitMQ/Kafka(任务调度与异步处理)
存储服务:MinIO(私有视频存储) / 阿里云 OSS(云端存储)
2. 短视频平台 API 集成
官方 API:抖音开放平台、快手 API、YouTube Data API 等。
第三方 SDK:使用开源库(如 douyin-python-sdk)简化对接流程。
自动化协议:Selenium/Puppeteer(模拟操作,应对无开放 API 场景)。
首先需要明确短视频矩阵系统的核心需求:高并发视频处理、分布式存储、实时推荐算法、负载均衡等。底层框架的选择至关重要,它决定了系统的可扩展性和稳定性。
在技术选型方面,后端可以考虑使用Golang或Java,因为它们在高并发场景下表现优异。对于视频处理,FFmpeg是行业标准工具。存储系统可能需要结合对象存储(如MinIO)和分布式文件系统。消息队列如Kafka能有效解耦处理流程。
分布式架构设计是关键。我们可以采用微服务架构,将上传、转码、分发等模块拆分为独立服务。服务发现和配置中心可以使用Consul,API网关选用Kong或Spring Cloud Gateway。
数据库方面需要混合使用:关系型数据库(如PostgreSQL)存储元数据,Redis作为缓存,时序数据库(如InfluxDB)记录监控数据。对于推荐算法部分,需要集成机器学习框架如TensorFlow Serving。
代码结构应该遵循清晰的分层原则:controller层处理请求,service层实现业务逻辑,dao层操作数据库。每个微服务都应有独立的代码仓库和CI/CD流程。
性能优化点包括:使用连接池减少数据库开销,视频转码采用GPU加速,实施分布式限流策略。监控系统需要覆盖从基础设施到应用层的各项指标。
安全措施不容忽视:视频上传需要严格的内容安全检查,接口必须实施OAuth2.0认证,敏感数据要进行加密存储。对抗DDoS攻击应部署在网关层。
最后是部署方案:使用Kubernetes进行容器编排,配合Prometheus和Grafana实现监控,日志系统采用ELK栈。多可用区部署能确保高可用性。
以下是基于5年开发经验的短视频矩阵系统底层框架搭建要点,采用模块化设计思路:
一、核心架构设计
复制插入
graph TDA[客户端SDK] --> B(API网关层)B --> C[业务微服务集群]C --> D[分布式存储引擎]D --> E[CDN加速网络]C --> F[实时推荐引擎]F --> G[用户行为分析]
复制插入
二、关键技术栈
- 服务框架:
python复制插入
# 基于gRPC的微服务通信示例
import grpc
from video_pb2 import VideoRequest
from video_pb2_grpc import VideoServiceStubchannel = grpc.insecure_channel('video-service:50051')
stub = VideoServiceStub(channel)
response = stub.GetFeed(VideoRequest(user_id=123))
复制插入
- 存储方案:
- 元数据存储:PostgreSQL(分库分表)
- 视频文件:MinIO分布式存储
- 缓存层:Redis Cluster
- $$ \text{存储成本} = \sum_{i=1}^{n} (S_i \times P_i) + B_w \times C_t $$ 其中$S_i$为存储类型容量,$P_i$为单位价格
三、核心模块实现
视频处理流水线:
python复制插入
def video_pipeline(file):# 1. 预处理meta = extract_metadata(file) # 2. 转码profiles = [{'resolution': '1080p', 'bitrate': 5000},{'resolution': '720p', 'bitrate': 2500}]outputs = parallel_transcode(file, profiles)# 3. 内容审核if not nsfw_detect(outputs):upload_to_cdn(outputs)return generate_video_id()
复制插入
四、性能优化策略
并发处理:
- 使用Go协程池处理IO密集型任务
- GPU加速转码:FFmpeg + NVIDIA NVENC $$ \text{转码速度} = \frac{\text{GPU核心数} \times \text{时钟频率}}{\text{目标码率}} \times \eta $$
推荐算法框架:
python复制插入
class VideoRecommender:def __init__(self):self.model = load_dnn_model()def recommend(self, user_vector):# 实时特征拼接context = get_real_time_features()input_vec = concat([user_vector, context])return self.model.predict(input_vec)
复制插入
五、高可用保障
- 熔断机制:
java复制插入
// Java熔断示例 (Resilience4j)
CircuitBreakerConfig config = CircuitBreakerConfig.custom().failureRateThreshold(50).waitDurationInOpenState(Duration.ofMillis(1000)).build();CircuitBreaker breaker = CircuitBreaker.of("videoService", config);
复制插入
- 监控体系:
- 日志采集:ELK Stack
- 指标监控:Prometheus + Grafana
- 链路追踪:Jaeger
六、部署架构
复制插入
┌─────────────────┐ ┌─────────────────┐
│ CDN边缘节点 │◄─────►│ 对象存储集群 │
└─────────────────┘ └─────────────────┘▲│
┌───────────────────────────────┐
│ Kubernetes集群 │
│ ┌─────────┐ ┌─────────┐ │
│ │ API网关 │ │ 推荐服务│ ... │
│ └─────────┘ └─────────┘ │
└───────────────────────────────┘
复制插入
经验总结:系统峰值需支持10万QPS时,重点优化:
- 视频上传采用分片传输+断点续传
- 推荐服务使用局部敏感哈希(LSH)加速相似度计算
- 数据库查询实施二级缓存策略
- 使用QUIC协议优化弱网环境体验
建议采用渐进式开发策略,优先构建视频基础服务(上传/转码/分发),再迭代推荐算法和社交功能,注意预留30%的性能冗余量应对流量增长。