javaSE 6
目录
1.集合
一 单列集合Colletion:
1.List接口:可以存储重复数据
(1)ArrayList类:
1.定义:
2.方法及代码
(2)LinkList类:
1.定义:
2.代码及方法:
(3)Vector类:
1.定义:
2.方法及代码:
(4)List接口集合迭代:
1.使用方法:
2.注意:
3.for循环-增强for-迭代器
2. Set接口:不能存储重复数据
(1)HashSet类:
1.定义:
2.方法及代码
(2)TreeSet类:
1.定义:
2.方法及代码
1.集合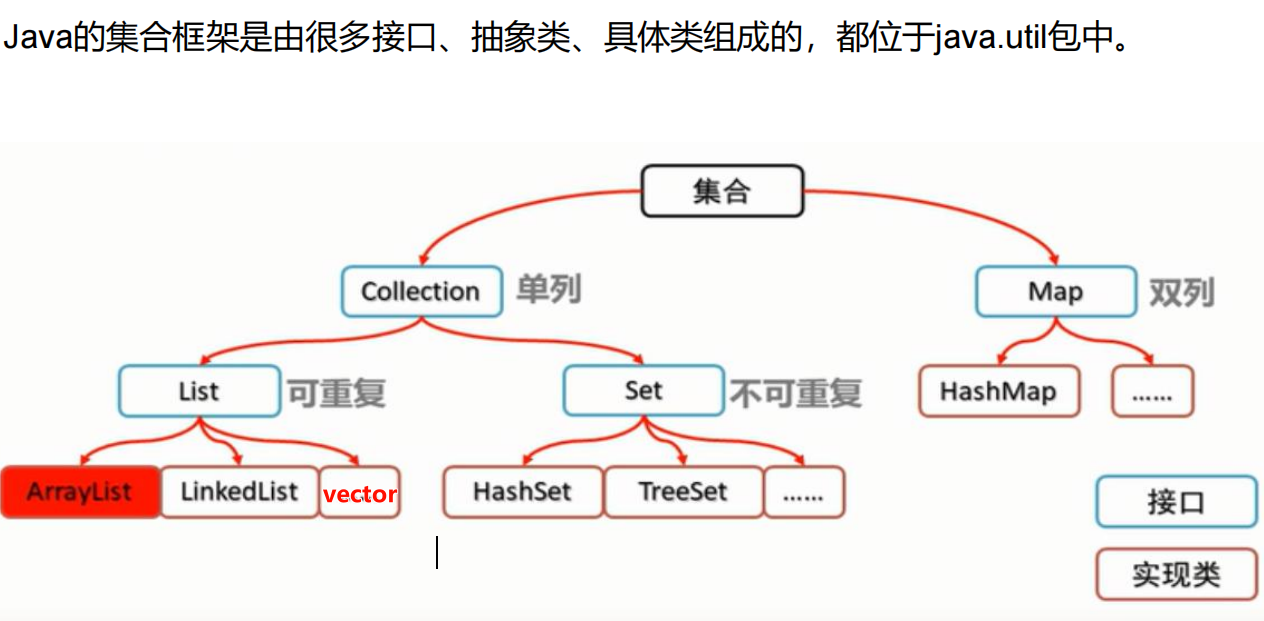
一 单列集合Colletion:
1.List接口:可以存储重复数据
(1)ArrayList类:
1.定义:
底层是数组结构,查询块,中间增删慢 默认可以存储Object类型
2.方法及代码
package Collection.List.ArrayList;import java.util.ArrayList;public class ArrayListDemo1 {/*ArrayList:底层是数组,默认可以存储Object类型*/public static void main(String[] args) {ArrayList arrayList1 = new ArrayList();arrayList1.add("G");//arrayList.add("a");//Object类型//arrayList.add(1);//Object类型//arrayList.add(true);//Object类型//实际开发中,一般建议一个集合对象只存储一个类型,使用泛型,为集合指定类型//泛型: <指定要使用的类型> 指定后,不可使用其他类型,ArrayList<String> arrayList = new ArrayList();arrayList.add("a");//向末尾添加元素arrayList.add("b");arrayList.add("e");arrayList.add("d");arrayList.add(1,"c");//向指定位置添加元素//添加System.out.println(arrayList.addAll(arrayList1));//把另一个集合添加进来//删除System.out.println(arrayList.remove(2));//根据索引删除对应的元素 并返回删除的元素System.out.println(arrayList.remove("b"));//根据内容删除第一次匹配的元素,删除成功返回true,否则falsearrayList.clear();//清空集合元素//判断System.out.println(arrayList.isEmpty());//判断是否为空System.out.println(arrayList.contains("b"));//判断是否包含指定元素//替换System.out.println(arrayList.set(1,"G"));//替换指定位置的元素//其他System.out.println(arrayList.size());//返回集合中实际的元素个数System.out.println(arrayList.get(3));//获取指定位置元素System.out.println(arrayList.indexOf("c"));//返回所给元素第一次出现的位置System.out.println(arrayList);}
}
注意: 可以将集合转为数组,使用数组中的方法
package Collection.List.ArrayList;import java.util.ArrayList;
import java.util.Arrays;public class ArrayListDemo2 {public static void main(String[] args) {//创建集合的三种方法// ArrayList<String> arrayList1= new ArrayList<>(10);//创建一个指定容量数组// ArrayList<String> arrayList2= new ArrayList<>(arrayList1);//创建一个集合时,把另一个集合数据添加到此集合中ArrayList<String> arrayList = new ArrayList<>();//创建默认容量为10的数组空间arrayList.add("a");arrayList.add("a");arrayList.add("a");arrayList.add("a");arrayList.add("a");arrayList.add("a");arrayList.add("a");arrayList.add("a");arrayList.add("a");arrayList.add("a");arrayList.add("a");System.out.println(arrayList.get(10));System.out.println(arrayList);//集合转为数组(之后就可以使用数组Array中的方法进行操作)String[] strings = arrayList.toArray(new String[arrayList.size()]);System.out.println(Arrays.toString(strings));}}
/*add()方法 源码解释:public boolean add(E e) {ensureCapacityInternal(size + 1); // Increments modCount!!elementData[size++] = e;return true;}public void add(int index, E element) {rangeCheckForAdd(index);ensureCapacityInternal(size + 1); // Increments modCount!!System.arraycopy(elementData, index, elementData, index + 1,size - index);elementData[index] = element;size++;}
*//* get()方法 源码解释public E get(int index) {rangeCheck(index);return elementData(index);}
*/(2)LinkList类:
1.定义:
底层是链表结构,查询慢,中间增删块
2.代码及方法:
package Collection.List.LinkList;import java.util.LinkedList;public class LinkedListDemo {public static void main(String[] args) {LinkedList<String> linkedList = new LinkedList<>();linkedList.add("1");linkedList.add("2");linkedList.add("3");linkedList.add("4");linkedList.add(3,"5");//向指定位置添加元素linkedList.addFirst("5");//向头添加元素linkedList.addLast("3");//向尾添加元素//添加System.out.println(linkedList.set(4,"40"));//向指定位置添加元素//删除System.out.println(linkedList.remove(2));//删除指定位置元素System.out.println(linkedList.removeFirst());//删头System.out.println(linkedList.removeLast());//删尾// 获得System.out.println(linkedList.get(3));//获得指定位置元素,只能从头/尾开始查找(使用分半查找)System.out.println(linkedList.getFirst());System.out.println(linkedList.getLast());//判断System.out.println(linkedList.isEmpty());//判断是否为空System.out.println(linkedList.contains("40"));//判断是否包含指定元素System.out.println(linkedList);/*栈和队列队列:例如医院排队 从尾添加 从头取出*/LinkedList<String> linkedList1 = new LinkedList<>();linkedList1.addLast("张三1");linkedList1.addLast("张三2");linkedList1.addLast("张三3");linkedList1.addLast("张三4");linkedList1.addLast("张三5");System.out.println(linkedList1);}
}
方法总结:


(3)Vector类:
1.定义:
底层是数组结构,添加同步锁,线程安全
2.方法及代码:
package Collection.List.vector;import java.util.Vector;public class VectorDemo {public static void main(String[] args) {Vector<Integer> vector = new Vector<>();vector.add(1);vector.get(1);}
}
详细方法省略,可以直接调用下列方法:
(4)List接口集合迭代:
1.使用方法:
for循环迭代 增强for循环迭代 迭代器迭代
2.注意:
a.如果要删除元素,只能通过for循环和迭代器删除, 增强for循环不能删除
b. 获得数组长度:a.length, length 为属性
获得字符串长度:"".length(), length() 为方法
获得集合长度:arrayList.size(),
3.for循环-增强for-迭代器
a. for循环删除元素
package Collection.List.Iterator_for;
import java.util.ArrayList;
public class Demo1 {public static void main(String[] args) {ArrayList<String> arrayList = new ArrayList<>();arrayList.add("a");arrayList.add("a");arrayList.add("a");arrayList.add("d");arrayList.add("e");//方式1: for循环 删除元素for (int i = 0; i < arrayList.size(); i++) {if (arrayList.get(i).equals("a")) {arrayList.remove(i);i--;}} System.out.println(arrayList);/*注意: 如果不写i--. 相当于在第一个元素被删除时,第三个元素转移到第二个位置,而第二个a转移到第一个位置,而此时已经遍历到第二个元素,那第二个元素就没有删掉*/}
}
b.增强for循环
package Collection.List.Iterator_for;
import java.util.ArrayList;
public class Demo2 {public static void main(String[] args) {ArrayList<String> arrayList = new ArrayList<>();arrayList.add("a");arrayList.add("a");arrayList.add("a");arrayList.add("d");arrayList.add("e");//方式2 :增强for循环// 增强for循环只能遍历,不能删除 故会报错for(String s: arrayList){if(s.equals("a"));{arrayList.remove(s);}}}
}
c.迭代器遍历和删除(重点)
package Collection.List.Iterator_for;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.ListIterator;public class Demo3 {public static void main(String[] args) {ArrayList<String> arrayList = new ArrayList<>();arrayList.add("a");arrayList.add("a");arrayList.add("a");arrayList.add("d");arrayList.add("e");//方式3:使用集合中提供的迭代器 专门用来遍历集合数据//Iterator迭代器 遍历Iterator<String> iterator = arrayList.iterator();while (iterator.hasNext()){ //hasNext()表示 是否有下一个元素String item = iterator.next();//将获得的对象赋给itemif(item.equals("a")){iterator.remove();//调用迭代器中的remove()删除}}System.out.println(arrayList);//ListIterator迭代器 遍历//从前往后遍历ListIterator<String> listIterator = arrayList.listIterator();//默认从第0个位置开始迭代while(listIterator.hasNext()){String item = listIterator.next();System.out.println(item);}//从后往前遍历ListIterator<String> listiterator = arrayList.listIterator(arrayList.size());//指定迭代开始的位置//注意当迭代到第0个元素时,继续向前没有元素,会报错,故需要指定迭代的开始位置while (listiterator.hasPrevious()) {String item = listiterator.previous();System.out.println(item);}//迭代器中删除元素(更加方便)Iterator<String> iterator1 = arrayList.iterator();//获得迭代器对象while (iterator1.hasNext()){String item = iterator1.next();if(item.equals("a")){iterator1.remove();//调用迭代器中的remove()}}System.out.println(arrayList);}
}
2. Set接口:不能存储重复数据
(1)HashSet类:
1.定义:
哈希(散列) 本质是一个数组.算出余数并储存在哈希表中对应的位置,储存的元素是无序的
2.方法及代码
package Collection.Set.HashSet;
import java.util.HashSet;public class HashSetDemo1 {public static void main(String[] args) {HashSet<Integer> hashSet = new HashSet<>();hashSet.add(44);hashSet.add(22);hashSet.add(33);hashSet.add(44);//重复元素不会重复输出hashSet.add(1);//1和33算出来的哈希值相同,当哈希值相同时,把1(后出现)放到33(先出现)的下一个位置hashSet.add(65);//其他方法hashSet.contains(5);//判断是否含有指定元素hashSet.iterator();//获得迭代器hashSet.remove(33);//只能根据内容删除指定元素hashSet.size();//集合长度hashSet.clear();//清除System.out.println(hashSet);}
}
问题:HashSet是如何实现值不重复的?(HashSet的key不重复原理)
解释:如果只使用equals()比较,工作量大 效率慢,所以需要使用 hashCode()方法.
先用hashCode(),根据内容算出一个哈希值(int类型),通过哈希值进行比较,如果哈希值相 同,则说明内容相同,
但是用哈希值进行比较有风险,即当内容不同时,可能出现哈希值相同的情况.这时就需要使 用equals()比较内容是否相同
例如:通话和重地 内容不同,但是哈希值相同
package Collection.Set.HashSet;
import java.util.HashSet;public class HashSetDemo2 {public static void main(String[] args) {HashSet<String> hashSet = new HashSet<>();//注意"通话"和"重地"内容不同,但是哈希值相同hashSet.add("通话");hashSet.add("重地");hashSet.add("aaaaaaaaaaaaaaaaaa");hashSet.add("x");hashSet.add("x");hashSet.add("hhh");hashSet.add("vvvv");hashSet.add("aaaaaaaaaaaaaaaaaa");System.out.println(hashSet);}
}
注意:
向HashSet中储存我们自己定义的Studnet类型,如果没有重写hashCode(),默认就会调用Objcet类中的hashCode()
Object类中的hashCode()方法 是一个native关键字修饰本地方法,由操作系统提供,获取是对象的内存地址
所以需要对Object类中的方法进行重写,判断内容是否相等
package Collection.Set.HashSet;import java.util.HashSet;public class HashSetDemo3 {public static void main(String[] args) {HashSet<Student> hashSet = new HashSet<>();hashSet.add(new Student("张三1",101));hashSet.add(new Student("张三2",101));hashSet.add(new Student("张三3",101));hashSet.add(new Student("张三1",101));System.out.println(hashSet);}
}package Collection.Set.HashSet;
import java.util.Objects;public class Student implements Comparable<Student>{String name;int no;//重写equals()方法@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;if (no != student.no) return false;return Objects.equals(name, student.name);}//重写hashCode()方法@Overridepublic int hashCode() {int result = name != null ? name.hashCode() : 0;result = 31 * result + no;return result;}//构造方法public Student(String name, int no) {this.name = name;this.no = no;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", no=" + no +'}';}@Overridepublic int compareTo(Student o) {return this.no-o.no;}
}
(2)TreeSet类:
1.定义:
底层使用的是红黑树,可以进行自平衡,旋转,防止成为链表 . 储存的元素是有序的
2.方法及代码
package Collection.Set.TreeSet;import java.util.TreeSet;public class TreeSetDemo1 {public static void main(String[] args) {TreeSet<Integer> treeSet = new TreeSet<>();treeSet.add(5);treeSet.add(6);treeSet.add(3);treeSet.add(2);treeSet.add(4);System.out.println(treeSet);}
}
package Collection.Set.TreeSet;
import Collection.Set.HashSet.Student;
import java.util.TreeSet;
public class TreeSetDemo2 {public static void main(String[] args) {/*向TreeSet集合中添加的类型必须要实现Comparable接口,提供一个排序的规则eg: public class Student implements Comparable<Student>*/TreeSet<Student> treeSet = new TreeSet<>();treeSet.add(new Student("张三1",101));treeSet.add(new Student("张三3",103));treeSet.add(new Student("张三5",105));treeSet.add(new Student("张三4",104));treeSet.add(new Student("张三2",102));System.out.println(treeSet);}
}
注意: 向TreeSet集合中添加的类型必须要实现Comparable接口,提供一个排序的规则