网络:应用层

网络:应用层
我们要知道,所有的问题解决都是在应用层。:happy:
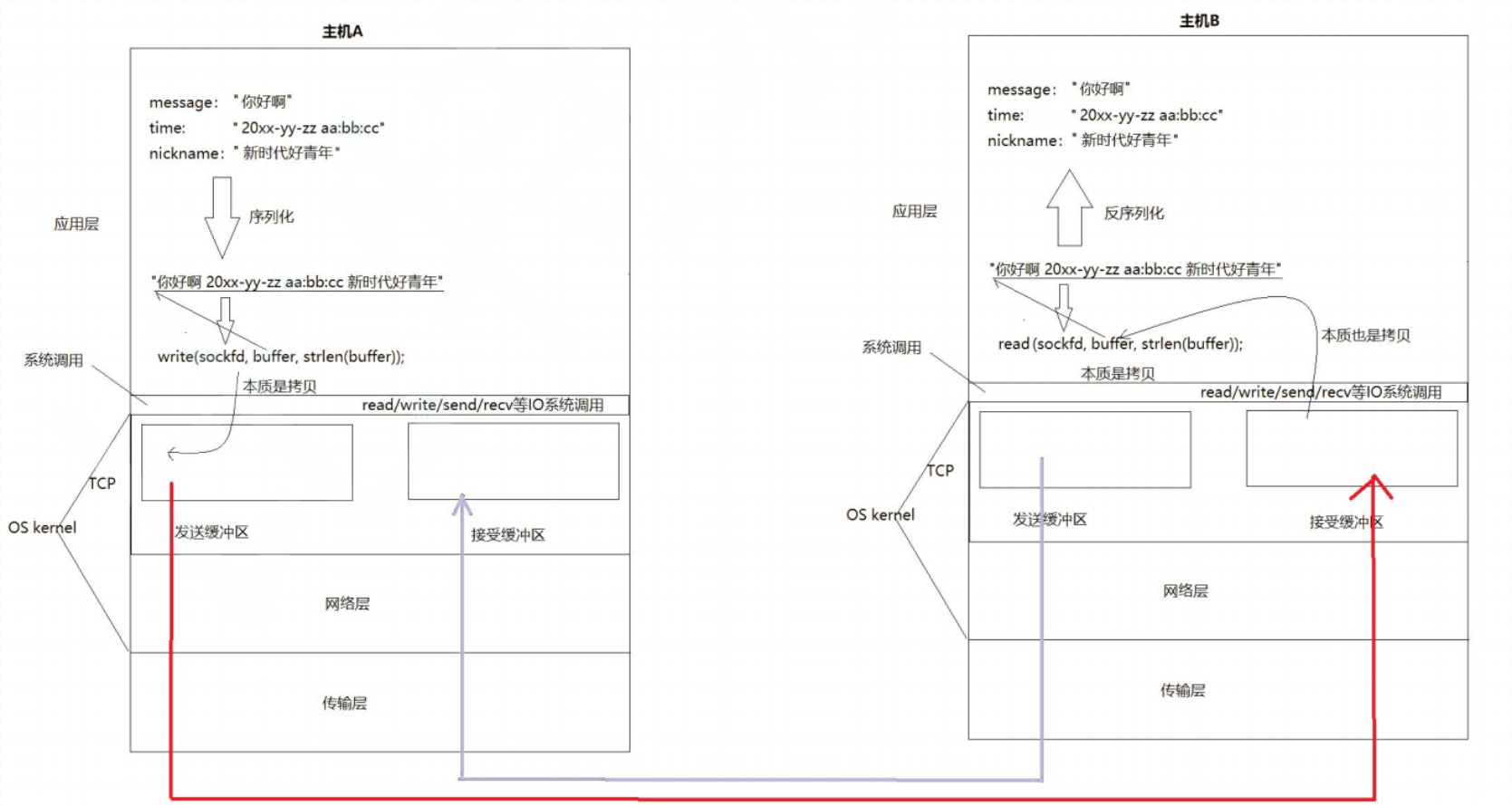
协议是一种约定,也就是双方约定好的结构化的数据。但是在读写数据时我们都是按字符串的方式来发送接受的,那么我们应该如和传输结构化的数据呢?应用层协议,TCP面向字节流导致的粘包问题就是在应用层协议中要解决的问题之一。
自定义协议
理解TCP和UDP为什么支持全双工
在任何一台主机上,TCP连接既有发送缓冲区,又有接受缓冲区,所以在内核中可以在发消息的同时,也可以收消息,也就是全双工。
但是UDP没有发送缓冲区(不使用SentQueue)调用sendto后UDP直接将数据交给内核,内核直接发送。UDP具有接收缓冲区,但是这个接收缓冲区不能保证收到的 UDP 报的顺序和发送 UDP 报的顺序一致,如果缓冲区满了,再到达的 UDP 数据就会被丢弃
为什么会这样设计,TCP、UDP协议详解会给你答案
实现网络计算器方案
我们要实现一个网络版的计算器,由客户端把要计算的两个数和操作发给服务器,服务器经过计算后将结果返回给客户端。
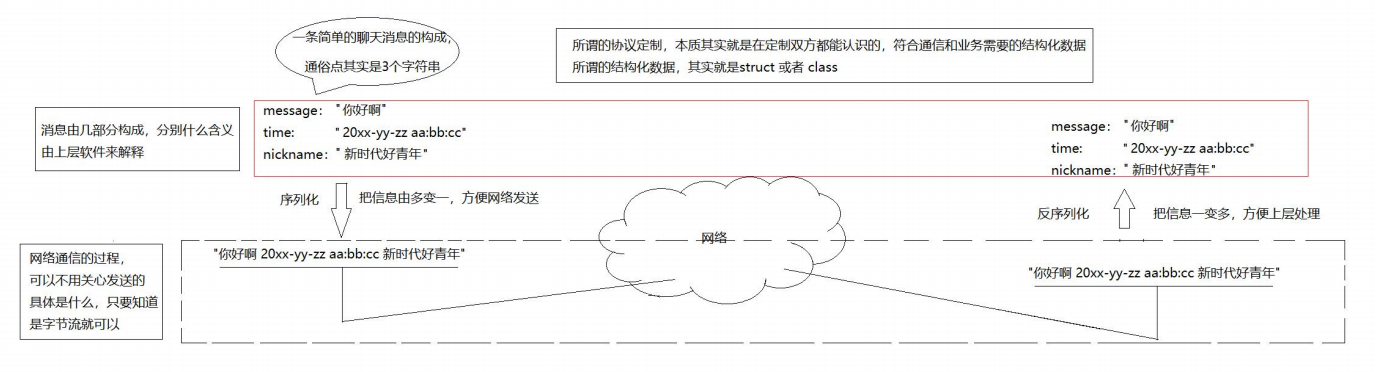
- 定义结构体来表示我们需要交互的信息
- 发送数据时将这个结构体按照一个规则转换成字符串, 接收到数据的时候再按照相同的规则把字符串转化回结构体
- 这个过程叫做 “序列化” 和 “反序列化”
基本方案是,定义一个protocol类,一个req和resp类,req和resp里面就是结构化的数据,req,resp类中实现序列化和反序列化。protocol类中实现Encode和Decode方法,添加报头和去掉报头。序列化和反序列化中我们有现成的方案 --Jsoncpp
网络版本计算器
守护进程化
// daemon.hpp
#pragma once
#include <iostream>
#include <sys/wait.h>
#include <unistd.h>
#include <signal.h>
#include <sys/types.h>
#include <fcntl.h>
#include "log.hpp"const std::string null_dev = "/dev/null";
using namespace LogModule;
// 守护进程
void daemon()
{// 1. 忽略IO,子进程退出信号signal(SIGPIPE, SIG_IGN);signal(SIGCHLD, SIG_IGN);// 2. 新起一个进程,并退出父进程if (fork() > 0)exit(1);// 3. 新建一个会话setsid();// 4. 更改进程的当前执行路径chdir("/");// 5. 关闭标准输入输出错误 可能导致本来输出到显示器的东西出错// 建议重定向到 /dev/null 文件里(无底洞)int fd = ::open(null_dev.c_str(), O_RDWR);if (fd < 0)LOG(LogLevel::FATAL) << "open dev/null error";else{dup2(fd, 0);dup2(fd, 1);dup2(fd, 2);close(fd);}
}
Jsoncpp
Jsoncpp 是一个用于处理 JSON 数据的 C++ 库。它提供了将 JSON 数据序列化为字符串以及从字符串反序列化为 C++ 数据结构的功能。Jsoncpp 是开源的,广泛用于各种需要处理 JSON 数据的 C++ 项目中
- 简单易用:
Jsoncpp提供了直观的API,使得处理JSON数据变得简单 - 高性能:
Jsoncpp的性能经过优化,能够高效地处理大量JSON数据 - 全面支持:支持
JSON标准中的所有数据类型,包括对象、数组、字符串、数字、布尔值和null - 错误处理:在解析
JSON数据时,Jsoncpp提供了详细的错误信息和位置,方便开发者调试。
当使用 Jsoncpp 库进行 JSON 的序列化和反序列化时,确实存在不同的做法和工具类可供选择。以下是对 Jsoncpp 中序列化和反序列化操作的详细介绍:
Jsoncpp库的简单使用方法
Http协议
虽然我们说,应用层协议是我们程序猿自己定的,但实际上,已经有大佬们定义了一些现成的,又非常好用的应用层协议,供我们直接参考使用。HTTP(超文本传输协议)就是其中之一。
在互联网世界中,HTTP(HyperText Transfer Protocol,超文本传输协议)是一个至关重要的协议。它定义了客户端(如浏览器)与服务器之间如何通信,以交换或传输超文本(如 HTML 文档)。
HTTP 协议是客户端与服务器之间通信的基础。客户端通过 HTTP 协议向服务器发送请求,服务器收到请求后处理并返回响应。HTTP 协议是一个无连接、无状态的协议,即每次请求都需要建立新的连接,且服务器不会保存客户端的状态信息。
认识URL
URL就是网址
如:http://wangruqin.site/
urlencode 和 urldecode
像 / ? : 等这样的字符,已经被 url 当做特殊意义理解了,因此这些字符不能随意出现
比如,某个参数中需要带有这些特殊字符,就必须先对特殊字符进行转义
转义的规则如下:
将需要转码的字符转为 16 进制,然后从右到左,取 4 位(不足 4 位直接处理),每 2 位做一位,前面加上%,编码成%XY 格式
例如:
“+” 被转义成了 “%2B”
urldecode就是urlencode的逆过程;urlencode工具

HTTP协议请求与响应格式
HTTP请求
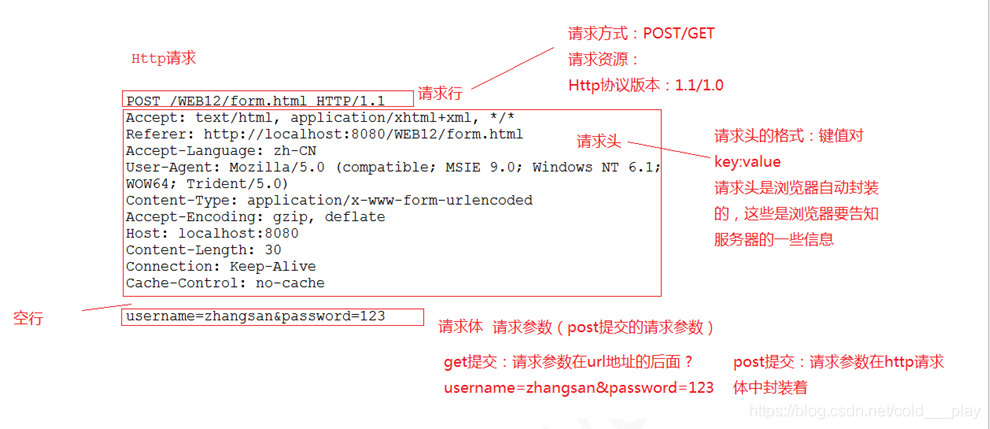
- 首行: [方法] + [url] + [版本]
Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\r\n分隔;遇到空行表示Header部分结束Body: 空行后面的内容都是Body,Body允许为空字符串,如果Body存在,则在Header 中会有一个Content-Length属性来标识Body的长度
HTTP响应
HTTP / 1.1 200 OK
Server=nginx/1.24.0 (Ubuntu)
Date=Tue, 10 Jun 2025 14:13:01 GMT
Content-Type=text/html; charset=utf-8
Transfer-Encoding=chunked
Connection=keep-alive
Content-Encoding=<!DOCTYPE html>
<html>
<head><!-- 页面元信息 --><meta charset="utf-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1"><title>Qin Home</title>...
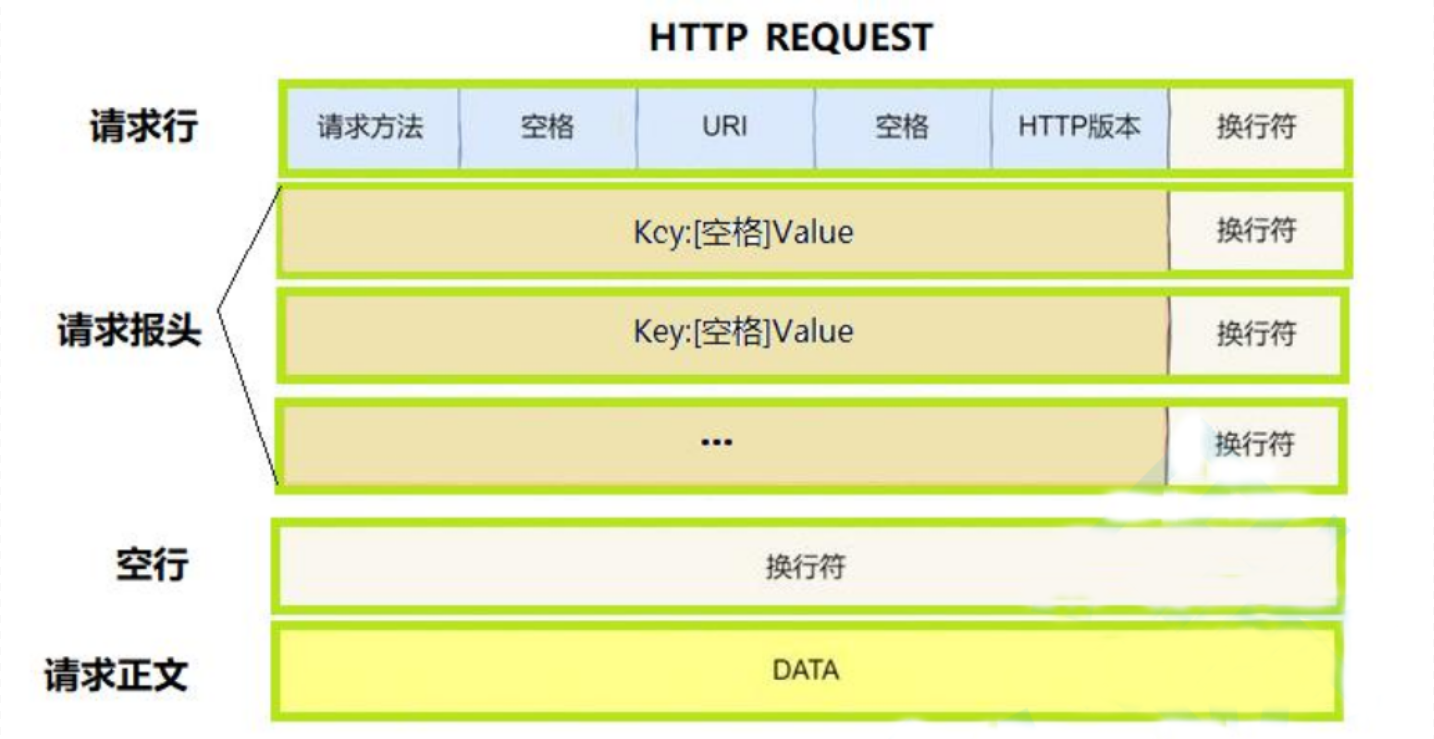
- 首行:[版本号] + [状态码] + [状态码解释]
Header:请求的属性,冒号分割的键值对;每组属性之间使用\r\n分隔;遇到空行表示Header部分结束Body:空行后面的内容都是Body,Body允许为空字符串. 如果Body存在,则在Header中会有一个Content-Length属性来标识Body的长度;如果服务器返回了一个html页面,那么html页面内容就是在body中

HTTP的方法
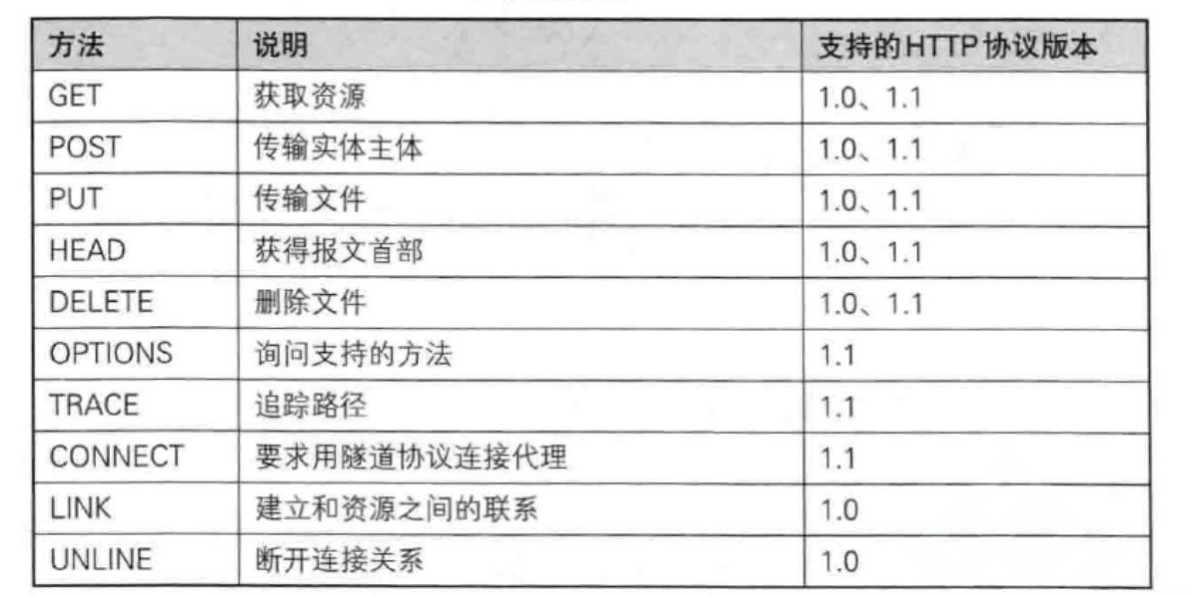
最常见的就是GET和POST方法
GET 方法
用途:用于请求 URL 指定资源
示例:GET /index.html HTTP/1.1
特性:指定资源经服务器端解析后返回响应内容
POST 方法
用途:用于传输实体的主体,通常用于提交表单数据
示例:POST /submit.cgi HTTP/1.1
特性:可以发送大量的数据给服务器,并且数据包含在请求体中
PUT 方法
用途:用于传输文件,将请求报文主体中的文件保存到请求 URL 指定的位置
示例:PUT /example.html HTTP/1.1
特性:不太常用,但在某些情况下,如RESTful API 中,用于更新资源
HEAD 方法
用途:与 GET 方法类似,但不返回报文主体部分,仅返回响应头
示例:HEAD /index.html HTTP/1.1
特性:用于确认 URL 的有效性及资源更新的日期时间等
DELETE 方法(不常用)
用途:用于删除文件,是 PUT 的相反方法
示例:DELETE /example.html HTTP/1.1
特性:按请求 URL 删除指定的资源
PTIONS 方法
用途:用于查询针对请求 URL 指定的资源支持的方法
示例:OPTIONS * HTTP/1.1
特性:返回允许的方法,如 GET、POST 等
HTTP的状态码
| 状态码 | 含义 | 应用样例 |
|---|---|---|
| 100 | Continue | 上传大文件时,服务器告诉客户端可以继续上传 |
| 200 | OK | 问网站首页,服务器返回网页内容 |
| 201 | Create | 发布新文章,服务器返回文章创建成功 |
| 204 | No Content | 删除文章后,服务器返回“无内容”表示操作成功 |
| 301 | Moved Permanently | (永久重定向)网站换域名后,自动跳转到新域名;搜索引擎更新网站链接时使用 |
| 302 | Found 或 See Other | (临时重定向)用户登录成功后,重定向到用户首页 |
| 304 | Not Modified | 浏览器缓存机制,对未修改的资源返回 304 状态码 |
| 307 | Temporary Redirect | (临时重定向)临时重定向资源到新的位置(较少使用) |
| 308 | Permanent Redirect | (永久重定向)永久重定向资源到新的位置(较少使用) |
| 400 | Bad Request | 填写表单时,格式不正确导致提交失败 |
| 401 | Unauthorized | 访问需要登录的页面时,未登录或认证 |
| 403 | Forbidden | 尝试访问你没有权限查看的页面 |
| 404 | Not Found | 访问不存在的网页链接 |
| 500 | Internal Server Error | 服务器崩溃或数据库错误导致页面无法加载 |
| 502 | Bad Gateway | 使用代理服务器时,代理服务器无法从上游服务器获取有效响应 |
| 503 | Service Unavailable | 服务器维护或过载,暂时无法处理请求 |
HTTP中无论是 301 还是 302 重定向 服务器收到请求后除了返回 301 302 状态码,还会再头部中添加Location信息,用于告诉浏览器应该将请求重定向到哪个新的URL地址,浏览器收到回复后重新向 Location 发起请求
HTTP/1.1 301 Moved Permanently\r\n
Location: https://www.new-url.com\r\nHTTP/1.1 302 Found\r\n
Location: https://www.new-url.com\r\n
HTTP 常见 Header
- Content-Type:数据类型(text/html)
- Content-Length:Body的长度
- Host:客户端告诉服务器,请求的资源在哪个主机的哪个端口上
- User-Agent:声明用户的操作系统和浏览器版本信息
- Referer:当前页面是从哪个页面跳转过来的
- Location:搭配3XX状态码使用,告诉客户端接下来要去哪里访问
- Cookie:用于在客户端存储少量信息,通常用户实现会话(session)的功能
关于Header中的connection
这个字段主要是为了控制服务器和客户端之间的连接状态,也就是支持客户端与服务器之间持久连接(响应完成后不立刻关闭TCP连接)这样可以在一个连接上发送多个请求和接受多个响应
在HTTP/1.1中默认就是使用持久连接,HTTP/1.0中默认的连接是非持久的,如果在HTTP/1.0中希望是持久连接,则需要在Header中显示添加该字段:Connection: keep-alive,如果在HTTP/1.1中希望不是持久连接添加该字段:Connection: close
常见Header表
以下是 HTTP 协议中常见的 Header 字段表格,按请求头(Request Headers)和响应头(Response Headers)分类
| 类别 | 字段名称 | 作用描述 | 常见示例 |
|---|---|---|---|
| 请求头 | Host | 指定请求的服务器域名和端口号,HTTP/1.1 必需字段 | Host: www.example.com 或 Host: api.example.com:8080 |
User-Agent | 标识发送请求的客户端(浏览器、爬虫等)信息 | User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/114.0.0.0 | |
Accept | 客户端可接受的响应数据格式(MIME 类型) | Accept: text/html, application/json | |
Accept-Encoding | 客户端支持的内容编码方式(如压缩格式) | Accept-Encoding: gzip, deflate, br | |
Accept-Language | 客户端可接受的自然语言(如中文、英文) | Accept-Language: zh-CN,zh;q=0.9,en;q=0.8 | |
Authorization | 用于身份验证,通常携带令牌(如 Bearer Token)或基本认证信息 | Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9 | |
Content-Type | 请求体的数据格式(仅在 POST/PUT 等有请求体时使用) | Content-Type: application/json 或 Content-Type: multipart/form-data | |
Content-Length | 请求体的字节长度(帮助服务器确定数据是否完整) | Content-Length: 1024 | |
Cookie | 客户端存储的 Cookie 信息,由服务器通过Set-Cookie设置 | Cookie: sessionId=abc123; username=user1 | |
Referer | 标识当前请求的来源页面(防盗链、统计来源常用) | Referer: https://www.example.com/login | |
Origin | 跨域请求时,标识请求的源站(协议 + 域名 + 端口),不含路径 | Origin: https://www.example.com | |
Cache-Control | 客户端对缓存的控制策略(如禁止缓存、强制验证等) | Cache-Control: no-cache 或 Cache-Control: max-age=3600 | |
If-Modified-Since | 条件请求:仅当资源在指定时间后修改过才返回,否则返回 304 | If-Modified-Since: Wed, 21 Oct 2023 07:28:00 GMT | |
Range | 断点续传:请求资源的部分内容(如从第 100 字节开始) | Range: bytes=100- 或 Range: bytes=0-499, 500-999 | |
| 响应头 | Status | 响应状态码及描述(如 200 OK、404 Not Found) | Status: 200 OK |
Content-Type | 响应体的数据格式(MIME 类型),帮助客户端解析数据 | Content-Type: text/html; charset=utf-8 或 Content-Type: image/jpeg | |
Content-Length | 响应体的字节长度 | Content-Length: 2048 | |
Content-Encoding | 响应体的编码方式(如 gzip 压缩),客户端需先解压 | Content-Encoding: gzip | |
Set-Cookie | 服务器向客户端设置 Cookie,可包含过期时间、域名、路径等属性 | Set-Cookie: sessionId=abc123; Expires=Wed, 21 Oct 2024 07:28:00 GMT | |
Cache-Control | 服务器对缓存的控制策略(如客户端可缓存时长、是否可共享等) | Cache-Control: public, max-age=86400 或 Cache-Control: no-store | |
Expires | 资源的过期时间(HTTP/1.0 遗留字段,与Cache-Control配合使用) | Expires: Thu, 22 Oct 2023 07:28:00 GMT | |
Last-Modified | 资源最后修改的时间,用于客户端缓存验证(配合If-Modified-Since) | Last-Modified: Wed, 21 Oct 2023 07:28:00 GMT | |
ETag | 资源的唯一标识(如哈希值),用于更精确的缓存验证(配合If-None-Match) | ETag: "abc123" 或 ETag: W/"abc123"(弱验证器) | |
Location | 重定向时,指定新的资源 URL(配合 3xx 状态码使用) | Location: https://www.example.com/new-page | |
Access-Control-Allow-Origin | 跨域资源共享(CORS):允许访问的源站(* 表示允许所有) | Access-Control-Allow-Origin: https://www.example.com 或 * | |
Access-Control-Allow-Methods | CORS:允许的请求方法(如 GET、POST、PUT) | Access-Control-Allow-Methods: GET, POST, OPTIONS | |
Server | 服务器的软件信息(如 Web 服务器类型、版本) | Server: Nginx/1.21.0 或 Server: Apache/2.4.54 | |
Connection | 控制连接是否保持(HTTP/1.1 默认keep-alive,关闭为close) | Connection: keep-alive 或 Connection: close |
补充说明:
- 部分
Header字段(如Cache-Control、Content-Type)在请求头和响应头中均可使用,但作用对象不同(请求头控制客户端行为,响应头控制服务器行为)。 - 标头名称不区分大小写,但通常约定使用首字母大写(如
User-Agent而非user-agent)。 - 扩展
Header(如X-Forwarded-For、X-Requested-With)常用于特定场景(如代理、AJAX 请求标识),但非HTTP标准定义。
嗯~没错这就是那个被面试官说是LJ的项目👍💩 💩
基于Reactor反应堆+Epoll多路转接的HTTP服务器
附录:
HTTP历史及版本核⼼技术与时代背景
HTTP(Hypertext Transfer Protocol,超⽂本传输协议)作为互联网中浏览器和服务器间通信的基石,经历了从简单到复杂、从单⼀到多样的发展过程。以下将按照时间顺序,介绍HTTP的主要版本、核心技术及其对应的时代背景。
HTTP/0.9
核心技术:
- 仅支持
GET请求⽅法。 - 仅支持纯⽂本传输,主要是
HTML格式。 - 无请求和响应头信息。
时代背景:
- 1991年,HTTP/0.9版本作为HTTP协议的最初版本,用于传输基本的超文本
HTML内容。 - 当时的互联网还处于起步阶段,网页内容相对简单,主要以文本为主。
HTTP/1.0
核心技术:
- 引入
POST和HEAD请求⽅法。 - 请求和响应头信息,⽀持多种数据格式(MIME)。
- 支持缓存(cache)。
- 状态码(status code)、多字符集支持等。
时代背景:
- 1996年,随着互联⽹的快速发展,网页内容逐渐丰富,HTTP/1.0版本应运而生。
- 为了满足日益增长d的网络应用需求,HTTP/1.0增加了更多的功能和灵活性。
- 然而,HTTP/1.0的⼯作方式是每次
TCP连接只能发送⼀个请求,性能上存在⼀定局限。
HTTP/1.1
核心技术:
- 引⼊持久连接(persistent connection),支持管道化(pipelining)。
- 允许在单个
TCP连接上进行多个请求和响应,提高了性能。 - 引⼊分块传输编码(chunked transfer encoding)。
- 支持
Host头,允许在⼀个IP地址上部署多个Web站点。
时代背景:
-
1999年,随着网页加载的外部资源越来越多,HTTP/1.0的性能问题愈发突出。
-
HTTP/1.1通过引⼊持久连接和管道化等技术,有效提高了数据传输效率。
-
同时,互联网应用开始呈现出多元化、复杂化的趋势,HTTP/1.1的出现满满足了这些需求。
HTTP/2.0
核心技术:
- 多路复用(multiplexing),⼀个TCP连接允许多个HTTP请求。
- ⼆进制帧格式(binary framing),优化数据传输。
- 头部压缩(header compression),减少传输开销。
- 服务器推送(server push),提前发送资源到客户端。
时代背景:
-
2015年,随着移动互联⽹的兴起和云计算技术的发展,网络应用对性能的要求越来越高。
-
HTTP/2.0通过多路复用、⼆进制帧格式等技术,显著提高了数据传输效率和网络性能。
-
同时,HTTP/2.0还⽀持加密传输(HTTPS),提高了数据传输的安全性。
HTTP/3.0
核心技术:
-
使用
QUIC协议替代TCP协议,基于UDP构建的多路复用传输协议。 -
减少了
TCP三次握⼿及TLS握手时间,提高了连接建立速度。 -
解决了
TCP中的线头阻塞问题,提高了数据传输效率。
时代背景:
-
2022年,随着5G、物联⽹等技术的快速发展,网络应用对实时性、可靠性的要求越来越高。
-
HTTP/3.0通过使用
QUIC协议,提高了连接建立速度和数据传输效率,满足了这些需求。 -
同时,HTTP/3.0还支持加密传输(HTTPS),保证了数据传输的安全性。
用对性能的要求越来越高。 -
HTTP/2.0通过多路复用、⼆进制帧格式等技术,显著提高了数据传输效率和网络性能。
-
同时,HTTP/2.0还⽀持加密传输(HTTPS),提高了数据传输的安全性。