数据湖产品全解析:2025 年主流解决方案选型指南
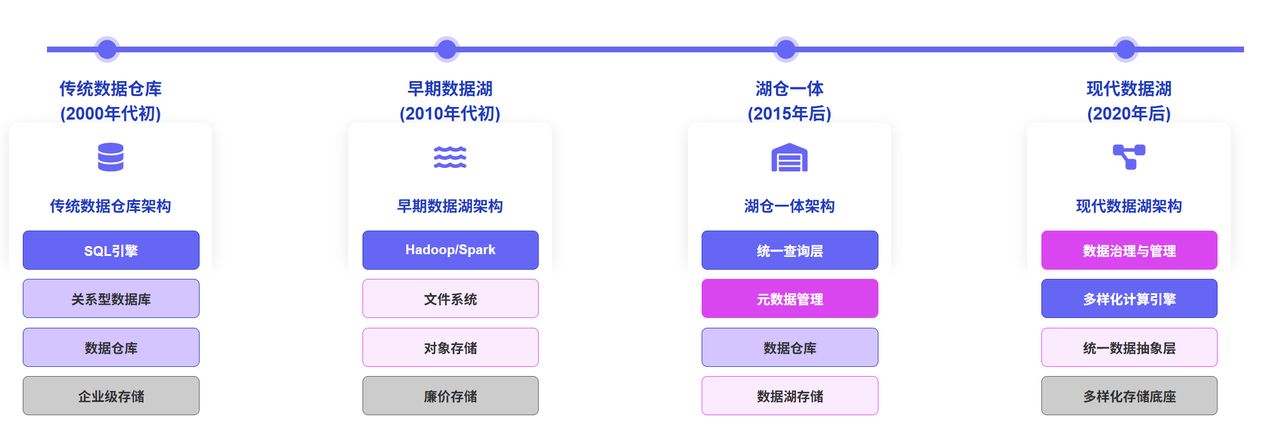
数据湖(Data Lake)概念与发展历程
数据湖(Data Lake)作为一种能够存储海量、多样化数据的存储系统,自 2010 年概念提出以来已经历了多次演变。数据湖的核心价值在于其能够存储任何规模、任何类型、任何形式的数据——无论是结构化、半结构化还是非结构化数据,都可以以原始形态保存,并在需要时快速提取进行处理、分析和精炼。
随着云计算的普及,数据湖的定义逐渐分化为两种主流理解:
公有云数据湖
AWS、Google Cloud 以及国内的阿里云、腾讯云等公有云厂商将数据湖定义为一个集中的、近乎无限空间的数据存储区。在这些云厂商的语境下,数据湖通常指代各家的云存储产品,如 AWS S3、Google Cloud Storage、阿里云 OSS 等。
这类数据湖解决了传统数据库存储空间有限、只能存放结构化数据的问题,使企业能够保存完整的原始数据,为后续多样化的分析应用提供基础。
表格格式数据湖
随着数据应用的深入,仅有存储层已不能满足企业对实时性、一致性的需求。为此,Uber、Netflix、Databricks 等公司在 2017-2019 年间相继推出了 Apache Hudi、Apache Iceberg 和 Delta Lake 等表格格式(Table Format)技术,在存储层之上提供了统一的数据组织和管理能力。
这些技术通常被称为“狭义数据湖”,它们解决了传统数据湖不支持实时增量更新、不支持流式数据处理、查询延迟高等问题,为数据湖的应用场景带来了质的飞跃。
广义数据湖的核心特性
综合来看,一个完整的现代数据湖应当具备以下核心特性:
- 统一存储:支持灵活的存储底座(公有云/私有云、HDD/SSD/缓存),具备集中的、足够大的存储空间
- 通用数据抽象/组织层:支持结构化、半结构化、非结构化等不同数据类型,并提供统一的数据组织形式
- 多样化计算支持:能够支持批处理、流计算、机器学习等不同计算类型
- 统一的数据管理:提供元数据中心、生命周期管理、数据治理等能力,避免形成数据孤岛
主流数据湖产品全景分析
随着数据湖技术的成熟,市场上涌现出众多数据湖产品和解决方案。下面我们将对当前主流的数据湖产品进行全面分析,帮助企业在选型时有更清晰的认识。
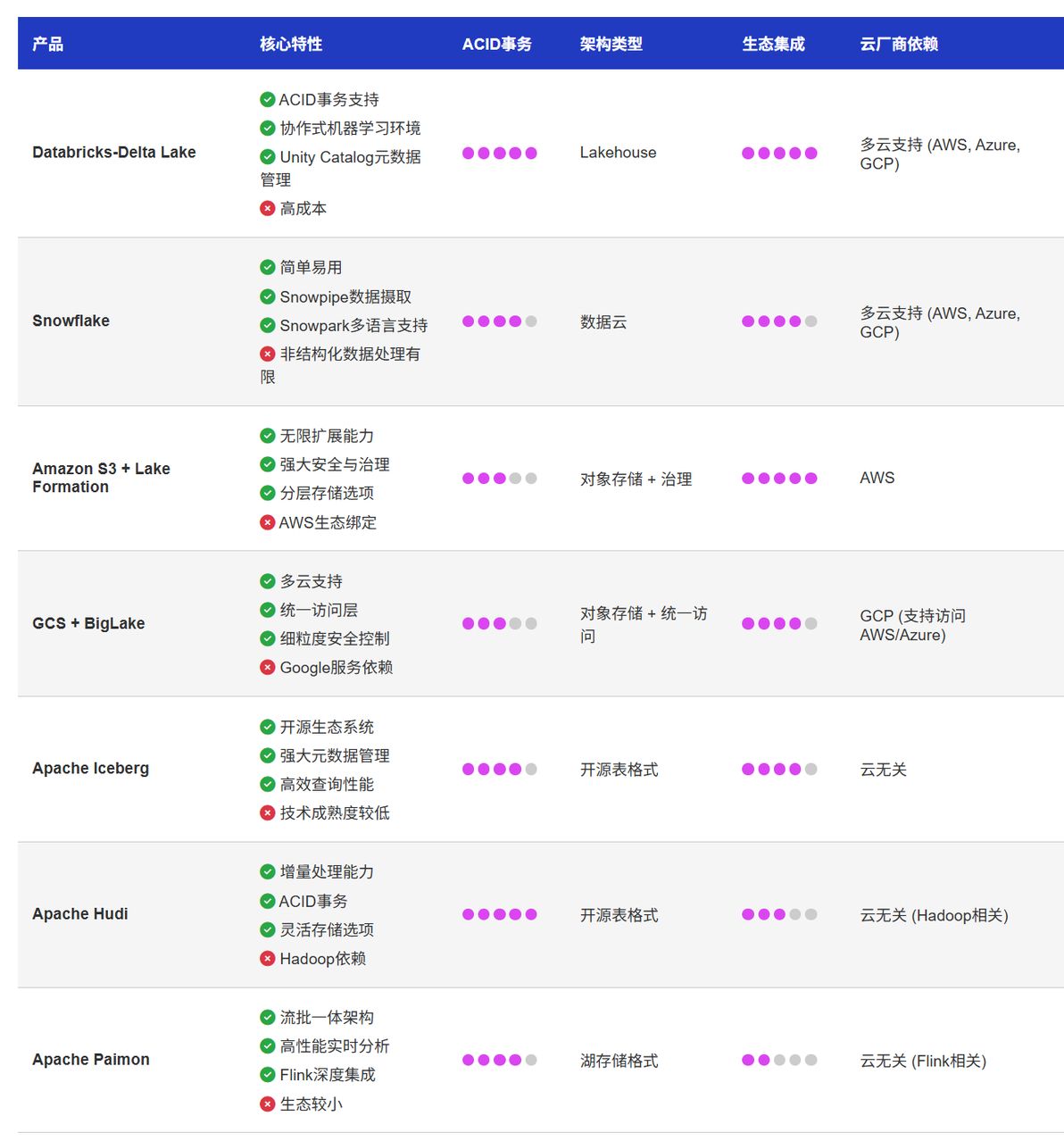
Databricks-Delta Lake
作为数据湖领域的领军者,Databricks 不仅提供了与多个云服务商(包括 AWS、Azure 和 GCP)的原生集成,更重要的是其开创性地提出了现代数据湖仓(Data Lakehouse)架构,将数据湖和数据仓库的优势结合起来。
核心优势:
- Delta Lake 开源表格式:提供 ACID 事务、模式强制执行、版本控制和统一的批处理/流处理能力
- 协作式机器学习环境:基于笔记本的环境允许数据工程师、数据科学家和分析师无缝协作
- Unity Catalog:完全集成元数据存储,增强数据目录和数据安全技术
- 端到端数据管理:从数据摄取、处理到分析的完整工作流支持
适用场景:
- 需要统一数据工程和数据科学工作流的企业
- 有大规模机器学习需求的组织
- 希望构建现代数据湖仓架构的企业
局限性:
- 按需付费的定价模型对于数据量大或变动频繁的工作负载可能导致成本难以预测
- 对于小型项目可能过于复杂和昂贵
Snowflake
虽然 Snowflake 最初以现代数据仓库平台闻名,但其已经成功扩展到数据湖领域,提供了可扩展、高性能且完全托管的原始数据存储解决方案。Snowflake 巧妙地避开了数据湖与数据仓库的二分法,而是将自己定位为“数据云”。
核心优势:
- 简单易用:以“它就是能用”著称,大幅降低了数据工程的复杂性
- Snowpipe:简化数据摄取、查询和转换的流程
- Snowpark:支持多种编程语言如 Python 进行数据处理
- 多云支持:兼容 AWS、Azure 和 GCP,避免厂商锁定
适用场景:
- 寻求简单易用数据平台的企业
- 需要跨云服务提供商灵活性的组织
- 对查询性能有较高要求的分析场景
局限性:
- 对于纯粹的非结构化数据处理能力相对有限
- 成本结构可能对大规模数据处理场景不够友好
Amazon S3 和 Lake Formation
作为最受欢迎的对象存储服务之一,Amazon S3 凭借其高可用性和低延迟访问成为构建数据湖的热门选择。而 Amazon Lake Formation 则进一步简化了数据湖的创建和管理过程。
核心优势:
- 无限扩展能力:几乎无限的存储容量,适合任何规模的数据
- 与 AWS 生态系统深度集成:与 Amazon Athena、Redshift Spectrum、EMR 等服务无缝协作
- 强大的安全和治理功能:集中式权限管理和精细的访问控制
- 成本效益:分层存储选项(如 S3 Glacier)可优化长期存储成本
适用场景:
- 已经深度使用 AWS 服务的企业
- 需要构建大规模数据湖的组织
- 对成本敏感但需要企业级功能的用户
局限性:
- 与 AWS 生态系统紧密绑定,可能导致厂商锁定
- 跨区域数据传输可能产生额外成本
- 需要额外工具来实现高级分析功能
Google Cloud Storage 和 BigLake
Google Cloud Storage(GCS)提供了高度可靠和可扩展的对象存储,而 BigLake 则是一个存储引擎,将存储能力扩展到多云对象存储上的开放格式,使组织能够将数据仓库和数据湖统一为一致的格式,加速数据分析。
核心优势:
- 多云支持:除了 GCS,还支持 Amazon S3 和 Azure Data Lake Storage Gen2
- 统一访问层:无需复制或移动数据,减少成本和低效率
- 强大的分析工具集成:与 BigQuery、Dataproc 等 Google 服务紧密集成
- 细粒度安全控制:行级和列级安全性
适用场景:
- 使用 Google Cloud Platform 的企业
- 需要跨云数据分析能力的组织
- 有 BigQuery 用户基础的企业
局限性:
- 对于非 Google Cloud 用户,学习曲线可能较陡
- 某些高级功能可能需要额外的 Google 服务,增加总体成本
Apache Iceberg
Apache Iceberg 是一种开源表格式,专为大规模数据分析而设计。它提供了丰富的元数据管理、模式演化和高效查询优化能力,已被众多企业采用为构建现代数据湖的基础。
核心优势:
- 开源生态系统:与 Spark、Flink、Trino 等开源分析引擎广泛兼容
- 强大的元数据管理:支持快照、时间旅行和回滚能力
- 高效的查询性能:通过文件级过滤和统计信息加速查询
- 行级更新支持:采用 Merge on Read 策略实现高效的行级操作
适用场景:
- 需要开源解决方案的企业
- 有大规模数据分析需求的组织
- 需要支持实时数据更新的场景
局限性:
- 作为相对较新的技术,生态系统仍在发展中
- 可能需要更多的技术专业知识来部署和维护
Apache Hudi
Apache Hudi(Hadoop Upserts Deletes and Incrementals)是由 Uber 开发的开源数据湖框架,专注于提供流式数据处理、事务支持和增量数据提取能力。
核心优势:
- 增量处理能力:支持高效的增量数据提取和处理
- ACID 事务:确保数据一致性和可靠性
- 灵活的存储选项:支持 Copy on Write 和 Merge on Read 两种存储策略
- 与 Hadoop 生态系统兼容:可与 Spark、Presto、Hive 等工具集成
适用场景:
- 需要实时数据处理和分析的企业
- 有增量 ETL 需求的组织
- Hadoop 生态系统用户
局限性:
- 与 Hadoop 紧密相关,对于云原生环境可能不是最佳选择
- 配置和优化可能较为复杂
Apache Paimon
Apache Paimon(原 Flink Table Store)是一个为流批一体设计的湖存储格式,由阿里巴巴开源,专注于提供高性能的实时数据湖解决方案。
核心优势:
- 流批一体架构:原生支持流式写入和批量读取
- 高性能实时分析:针对实时场景优化的存储格式
- 与 Flink 深度集成:提供最佳的 Flink 兼容性
- 丰富的数据管理功能:支持数据压缩、合并和清理
适用场景:
- 有实时数据处理需求的企业
- Flink 用户
- 需要流批一体解决方案的组织
局限性:
- 作为较新的项目,生态系统和社区支持相对有限
- 主要针对 Flink 优化,与其他计算引擎的集成可能不够成熟
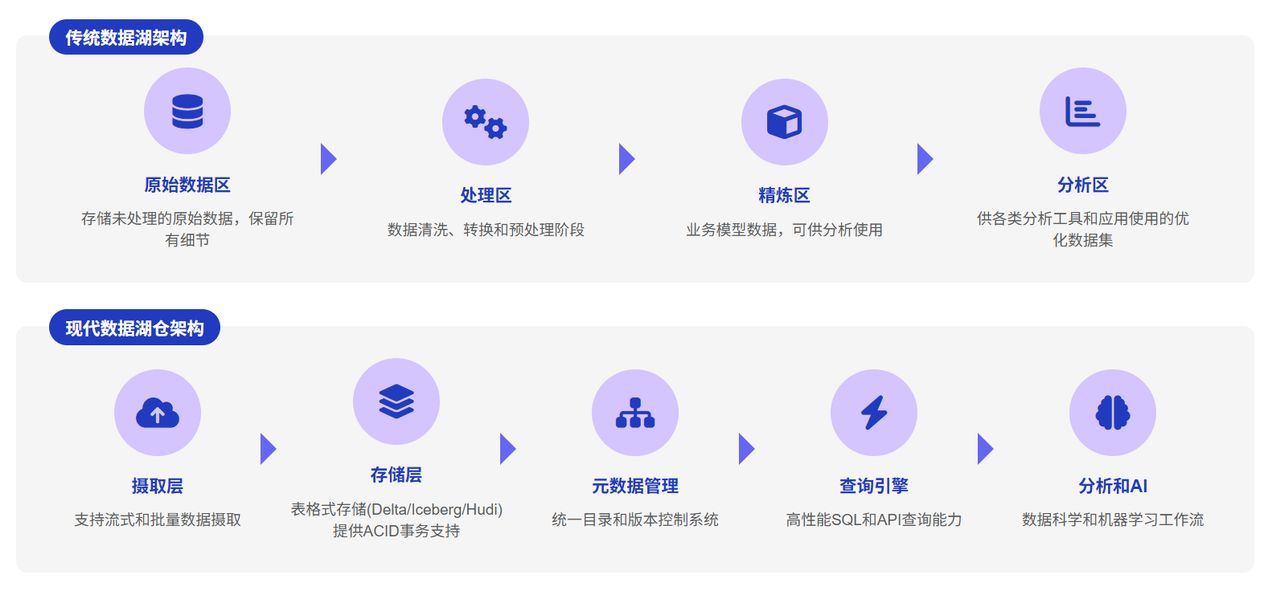
StarRocks 湖仓一体解决方案
随着数据湖技术的发展和企业需求的变化,单纯的数据湖或数据仓库已难以满足现代数据分析的全部需求。StarRocks 作为领先的实时分析数据库,提供了强大的湖仓一体解决方案,帮助企业构建更高效、更灵活的数据架构。
StarRocks 湖仓一体解决方案基于“极速统一”的理念,通过统一的 SQL 接口连接多种数据源,包括各类数据湖产品,实现对内部表和外部数据的高性能分析。

核心组件:
- StarRocks 内部表:提供极致的 OLAP 性能,适合高频访问数据
- Catalog 机制:连接外部数据源的统一接口
- 物化视图:加速外部数据查询的关键技术
- 缓存系统:优化数据访问路径,提升查询性能
支持的数据湖产品:
- Apache Iceberg
- Apache Hudi
- Delta Lake
- Apache Paimon
- 以及各类云存储服务(S3、HDFS 等)
与主流数据湖产品的集成优势

StarRocks 与各类数据湖产品的集成为企业带来了显著价值:
与 Iceberg 的集成:
- 支持 Iceberg 表的高性能查询
- 通过物化视图加速复杂分析
- 支持时间旅行(Time Travel)功能
- 兼容 Iceberg 的元数据和数据格式
与 Paimon 的集成:
- 原生支持流批一体架构
- 高效处理实时数据流
- 优化小文件问题
- 提供端到端的数据一致性
与 Hudi 的集成:
- 支持 Hudi 的增量处理能力
- 兼容 Copy on Write 和 Merge on Read 两种模式
- 优化 Hudi 表的查询性能
- 简化 Hudi 数据的分析流程
企业实践案例
众多企业已经通过 StarRocks 湖仓一体方案获得了显著收益:
小红书湖仓架构升级: 通过 StarRocks 连接 Iceberg 数据湖,实现了离线数仓的显著提效,查询性能提升百倍,同时保持了数据的一致性和完整性。
腾讯天穹一站式湖仓融合平台: 基于 StarRocks 构建统一查询层,连接多种数据源,包括 Hive、Iceberg 等,实现了“一次开发,多源适配”的数据分析能力。
58 同城湖仓一体架构转型: 从 Spark 到 StarRocks 的架构升级,实现了高效的湖仓一体架构,查询性能提升 10 倍,同时降低了 40%的计算资源成本。
饿了么基于 Flink+Paimon+StarRocks 的实时湖仓: 构建了端到端的实时数据处理链路,将数据延迟从小时级降至分钟级,同时保证了数据一致性和查询性能。
结语
数据湖不再仅仅是存储海量数据的场所,而是企业数据战略的核心组成部分。通过选择合适的数据湖产品和数据湖解决方案,企业可以构建灵活、高效、面向未来的数据架构,为业务创新和增长提供强大支持。
随着技术的不断演进,数据湖将继续发展,为企业提供更强大的数据管理和分析能力。那些能够有效利用这些能力的企业,将在数据驱动的未来中获得显著竞争优势。