安德鲁·卡帕西:深入探索像ChatGPT这样的大语言模型
笔记源自2025年2月安德鲁大神3.5小时的视频。
原视频链接:【【1080P】安德烈·卡帕西:深入探索像ChatGPT这样的大语言模型|Andrej Karpathy】
简洁比喻:大模型就是一个transformer结构的脑子,人们训练大模型,就像教学生学习:
-
预训练(pre-trainning) 就是看教材,学习完所有的语料(把互联网上的所有资料有损压缩在模型参数中)
-
监督微调(surpervised Fine tuning, SFT)看例题,教会大模型用对话的形式输出上下文
-
强化学习(reforce learning) 做真题,让大模型亲自上手做题
1、预训练 pre-training
步骤1:下载和处理互联网数据
大一点的大模型公司,都有自己预处理的数据集
-
例子:FineWeb数据集,一个15T tokens(15万亿), 占用44TB 磁盘空间的数据集。https://huggingface.co/spaces/HuggingFaceFW/blogpost-fineweb-v1
-
数据下载和处理的步骤
-
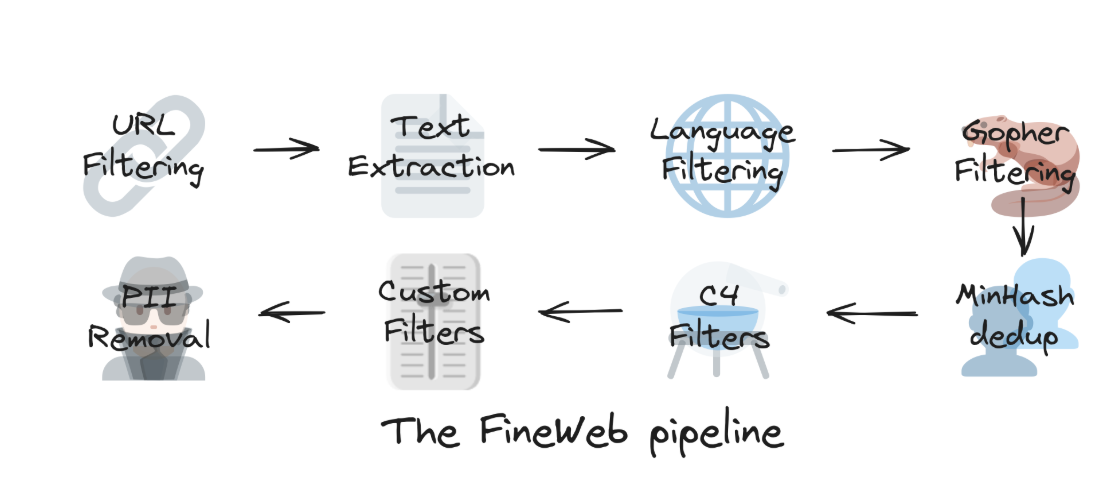
URL过滤:不希望获取数据的“域名”黑名单(垃圾网站等)
-
文本提取:从前端页面的代码中提取出有用文字
-
语言过滤:只保留英语内容比例高于一定阈值的网页
-
Gopher过滤
-
MinHash去重
-
C4过滤器
-
自定义过滤
-
PII移除:personal indentify information,移除个人信息
-
步骤2:tokenization
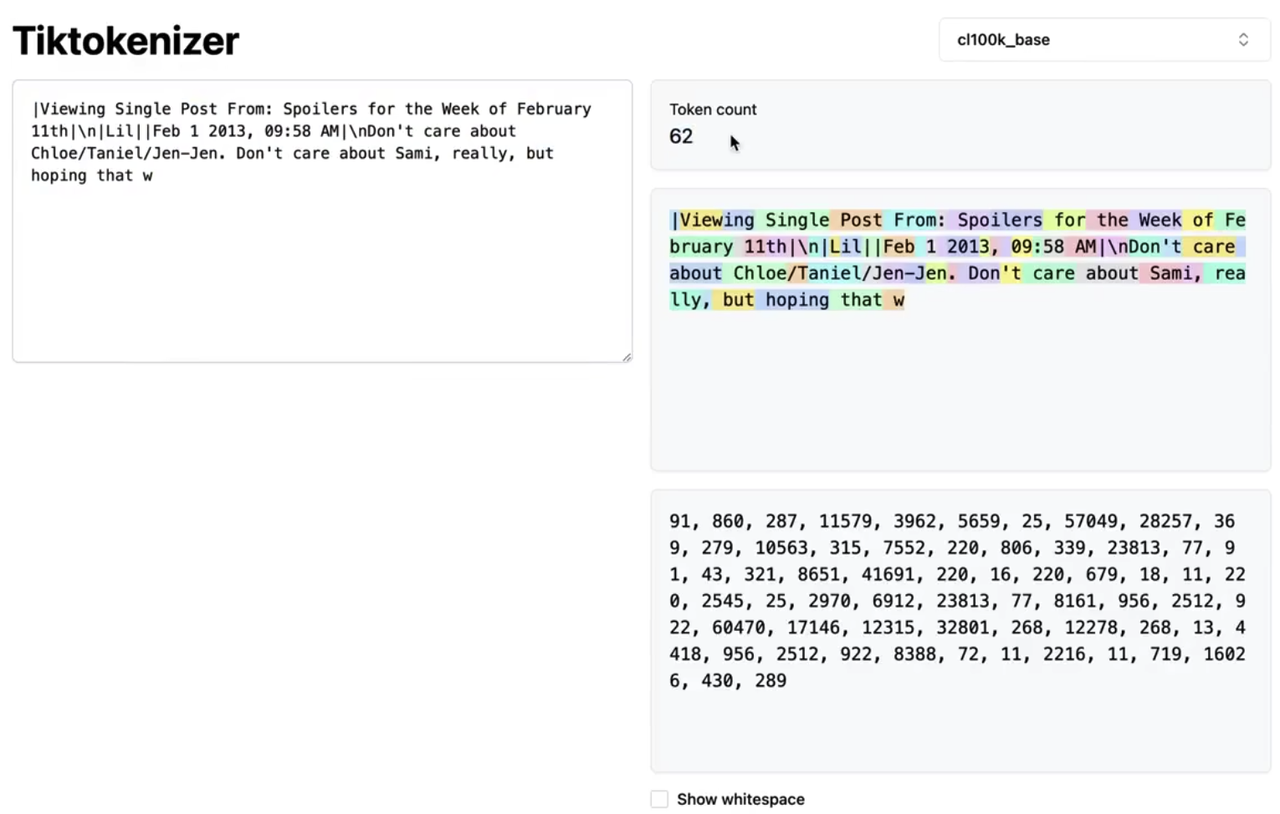
把原始文本转换为数字符号序列的形式,输入到模型中(例子: https://tiktokenizer.vercal.app/
-
chapGPT-4 的token 词表量为100277
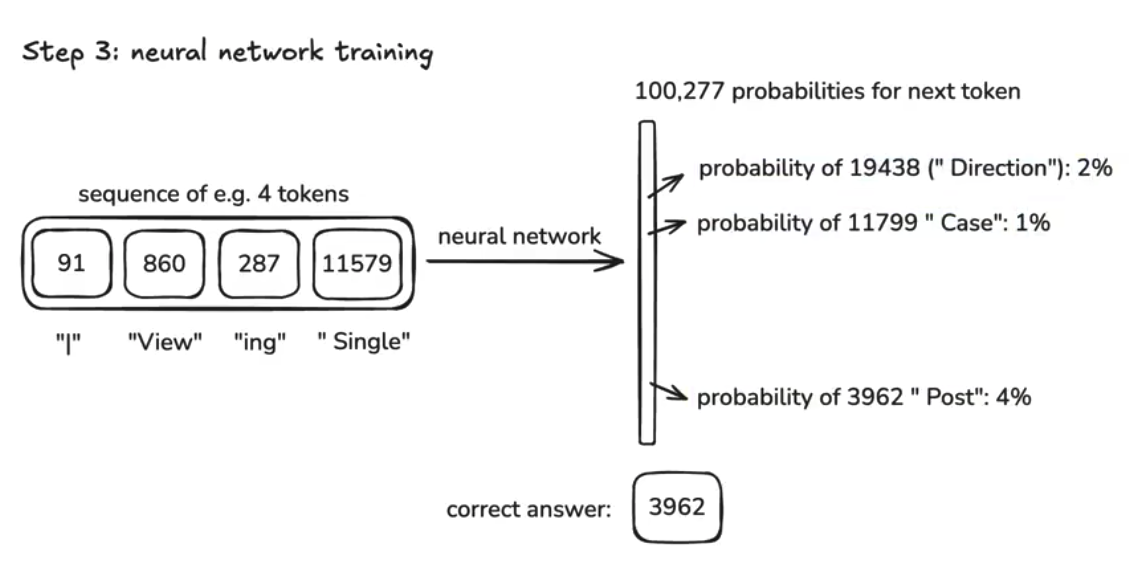
步骤3:神经网络训练(neural network training)
模型的工作可以简单理解为,构建一个复杂的函数,对token之间的序列关系建模(固定函数中的参数),简单来说,就是根据输入的token序列,预测下一个token是什么
-
在上一步的token序列中,按照不同的窗口长度,截取token(理论上可以截取任意长度的token,但是窗口越长约消耗计算计算资源),比如8000个token 或4000个token作为一次输入
-
根据输入,用神经网络,预测并输出下一个词
神经网络-内部样子
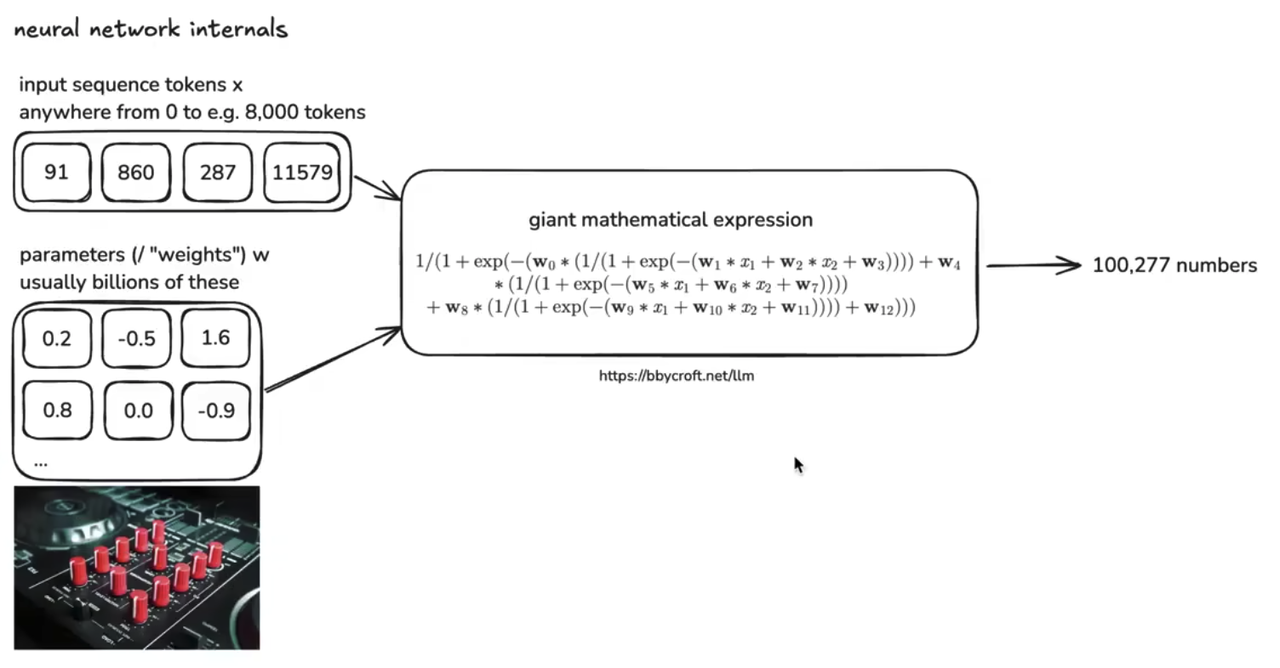
神经网络内部有非常多的参数,比如200B的模型就是意味着有2000亿个参数(200 billion)
比喻:可以理解为仪表盘,盘上有有很多的旋钮,训练神经网络就是把旋钮转到合适位置,不同位置的旋钮会给出不同的预测结果。内部结构例子,以一个8.56万参数的nano-GPT为例子:LLM Visualization
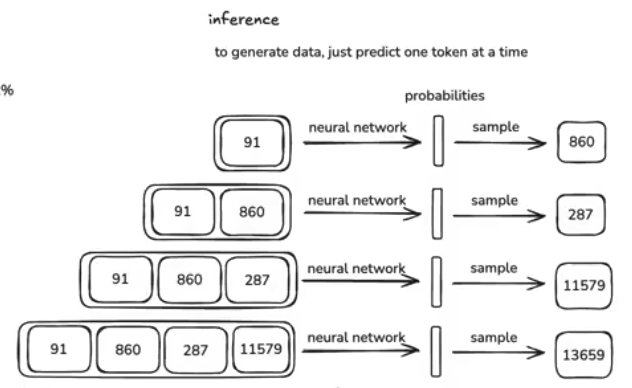
推理 inference
推理:从模型中生成新数据,一般我们从一些token开始,每次只输出1个token。
-
跟chatGPT对话,就是模型在推理。
-
也可以在训练过程中,简单看一下参数内化了什么样的模式,比如每训练一小批数据就推理一下看看效果。
DEMO:复现 OPENAI 的GPT-2
大约有1.6B的参数,最大上下文1024 token
https://github.com/karpathy/llm.c/discussions/677
结果:基座模型(base model)
-
我们想要的是能回答问题的助手,目前的base model还只能输出互联网文本的排列组合
-
发布模型包含两个东西
-
跑Transformer的Python代码
-
Transformer的参数
-
-
现实世界中的基座模型:比如 meta 发布的 llama 3 多个基础模型的试用:https://app.hyperbolic.xyz/models/llama31-405b-base-bf-16
基础模型的 “心理机制”
-
它是一个基于token层面的互联网文档模拟器。
-
它具有随机性 / 概率性 —— 每次运行你都会得到不同的结果。
-
它还能逐字背诵一些训练文档(“复述”)。
-
模型的参数有点像互联网的有损压缩文件 => 大量有用的世界知识存储在网络的参数中。
-
通过巧妙设置提示词,你已经可以将其用于各种应用(如翻译)。
-
但我们还可以做得更好……
2、后训练 post-training
通过给模型示例,让模型学会对话,让模型给出问题的答案。
-
对话是什么?
-
我们如何表示对话(represent conversation)
-
如何让模型看到对话而不是原始文本?
-
训练的结果是什么
-
模型的心理机制是什么?我们跟模型对话的时候,我们得到的是什么?
1)创建“对话数据集”
-
通过创建对话数据集,来隐式的对“助手”编程。
-
数据集来自人工标注
-
各家模型公司对数据集有自己的要求,比如有帮助的对话,无害的对话
-
也有用LLM生成的数据集 UltraChat
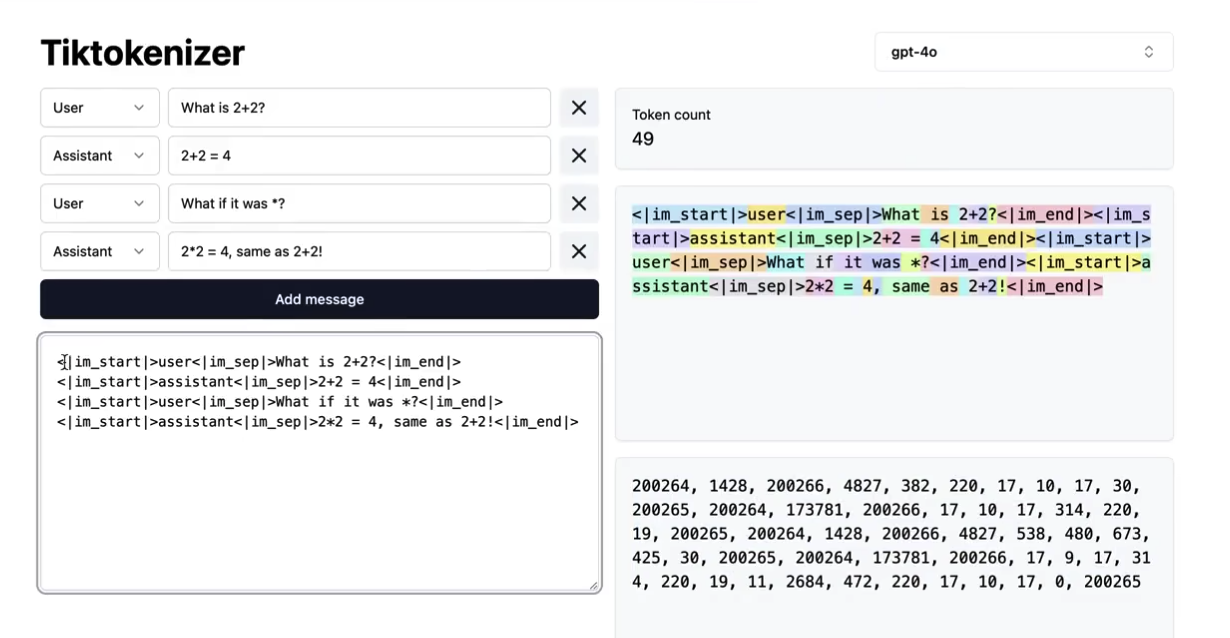
2)把对话符号化
-
按照某种协议 / 格式 处理“对话”,不同公司,不同LLM 有不同的方式
-
chatGPT-4o的方式如下:200264 是一个新的token,在预训练中没有被加进去,后训练中就把该token表示为用户的对话起始token
3)再次训练模型
-
用“对话数据集”再次训练基座模型,可能几个小时,快速的调整模型的参数
4)从chatGPT获得的回答是什么?
-
从统计学上,模仿人类的高概率的词汇组合
-
数据标注者有一定的专业性,比如问代码的问题,实际上就是在问一个模拟代码专家。模型实际上混合了预训练中的所有互联网数据,和后训练中的专家标注数据。
5) 模型的心理学特征
-
幻觉 hallucination:大模型会捏造信息,因为它只输出概率最高的词汇组合,改善方式
-
搜索互联网
-
让模型学会说不知道(The Llama 3 herd of models:)
-
在后训练数据中定义了事实性的问题,从网页、文章中随机选取片段,让模型自己生成事实性的问题和回答,然后让另一个模型多次回答生成的问题,对照多次的答案,如果一致,那么模型知道。
-
如果多次答案不一致,说明模型不知道,正确答案是“不知道”
-
-
-
模型的记忆:
-
参数中的知识,是模型的“模糊记忆”
-
窗口中的上下文,是模型的“工作记忆”
-
-
模型的自我认知:模型不知道自己是谁,除非后训练中加入特点的数据做微调
-
模型需要token来思考:
-
把所有答案压缩到一个token很昂贵
-
次优解:多个token正向传递,一步步正向传递
-
最优解:允许模型调用工具
-
-
模型不擅长计数
-
模型不擅长拼写(上下文 打成token,导致模型看不到字符)
3、强化学习 (Reinforce Learning, RL)
-
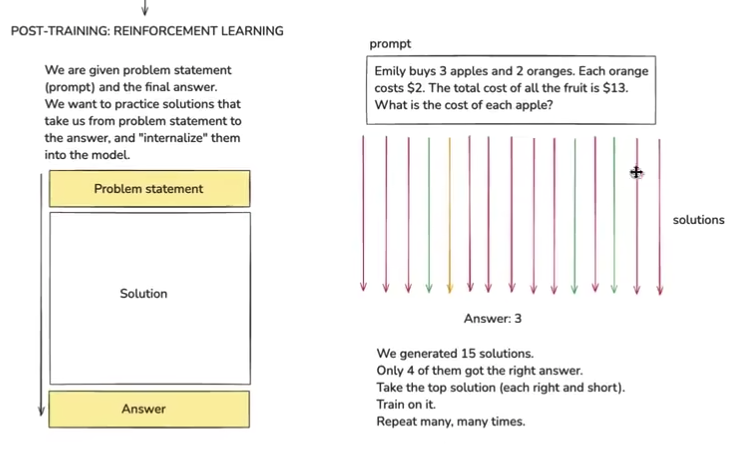
模型可能生成多种答案,但是人们希望让模型自己找到,哪些答案(token的排序)是可靠的,所以引入了强化学习。
-
补充-强化学习概念:我们无法直接告诉智能体(或算法)如何产生正确的动作,智能体通过与“环境”交互,获得奖励或者惩罚信号。通过不断的“试错”,智能体自主的发现和选择回报最大的动作。
-
截图,提出问题,然后假设运行模型15次,4次给了正确答案,然后我们选择(正确且长度短)的答案,再训练一次模型。重复
-
RL还处在相对较早的状态,上面的截图跳过了非常多细节,比如
-
如何挑选最佳方案
-
挑选多少正确方案来进行训练
-
什么是提示分布(prompt distribution)
-
如何保证模型训练过程有效
-
-
Deepseek R1惊艳的原因:
-
大多数公司,比如openAI,会在公司内部自己做RL
-
Deepseek 公开了RL的细节
-
当你正确使用RL的时候,LLM会发生什么?
-
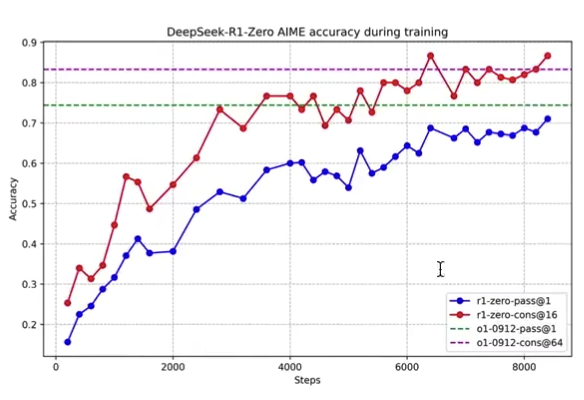
迭代次数上升,对数学(AIME)的准确率越高
-
Deepseek R1涌现了长思维:模型在发现答案之后,会自己再从不同角度,去验证一遍!
-
-
-
Openai o3,o3-mini 都用了强化学习;openAI-GPT4等模型,就只用到SFT和简单的强化学习
-
当你询问知识性的问题或者简单的问题,推理模型就会显得过于复杂。
-
强化学习第一次获得大众注意,是谷歌的AlphaGo,围棋里:在人类数据的基础上,模型始终无法超越人类;但是引入了强化学习后,强化学习的能力突破了人类专家
-
在不可验证的领域(比如写一首诗,总结一段文字,讲笑话),如何解决“评估模型好坏”的问题。

-
Reinforcement Learning from Human Feedback,RLHF(论文原文:Fine-Tuning Language Models from Prefernces)
-
训练一个模型(Reword Model),可能是另一个transformer,代替人类,对LLM的结果,排序,选出最优解。
-
4、其他:模型未来的能力、AI信息源
1)未来的能力
-
多模态(不仅是文本,还有音频、图像、视频、自然对话等)
-
任务 => agents(连贯的,自己纠正错误的完成任务)
-
计算机执行键盘和鼠标的操作
-
参数量随时间变化的模型
-
目前的模型参数量是固定的,模型所接触到的学习途径为上下文窗口,只能优化参数,不能改变参数量级
-
人类能根据所做的事情更新参数量级和参数值
-
2)信息源
-
https://lmarena.ai
-
https://buttondown.com/ainews
-
X/ twitter