Spring循环依赖以及三个级别缓存
Spring循环依赖以及三个级别缓存
什么是循环依赖?
循环依赖,顾名思义,就是指两个或多个 Spring Bean 之间相互依赖,形成一个闭环。
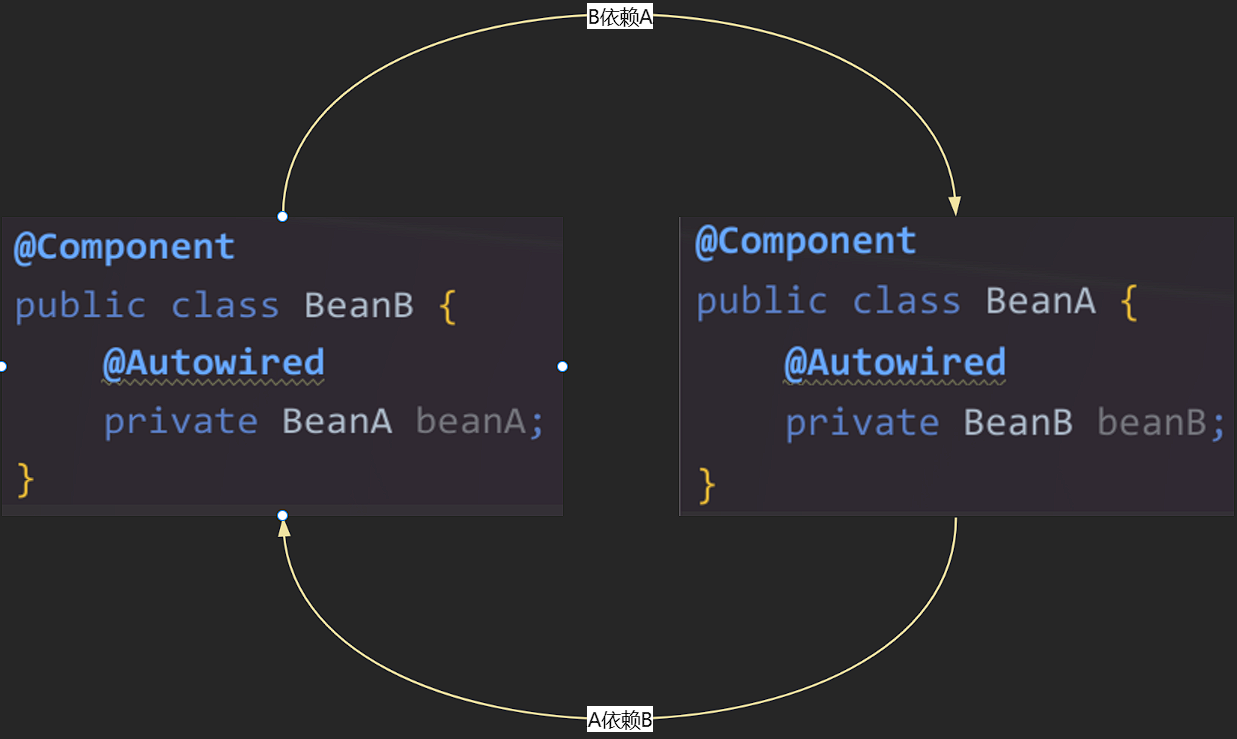
最常见也是 Spring 能够“解决”的循环依赖是构造器注入 和 setter 注入 混合或单独使用时,发生在 单例(Singleton) Bean 上的情况。
什么是三级缓存?
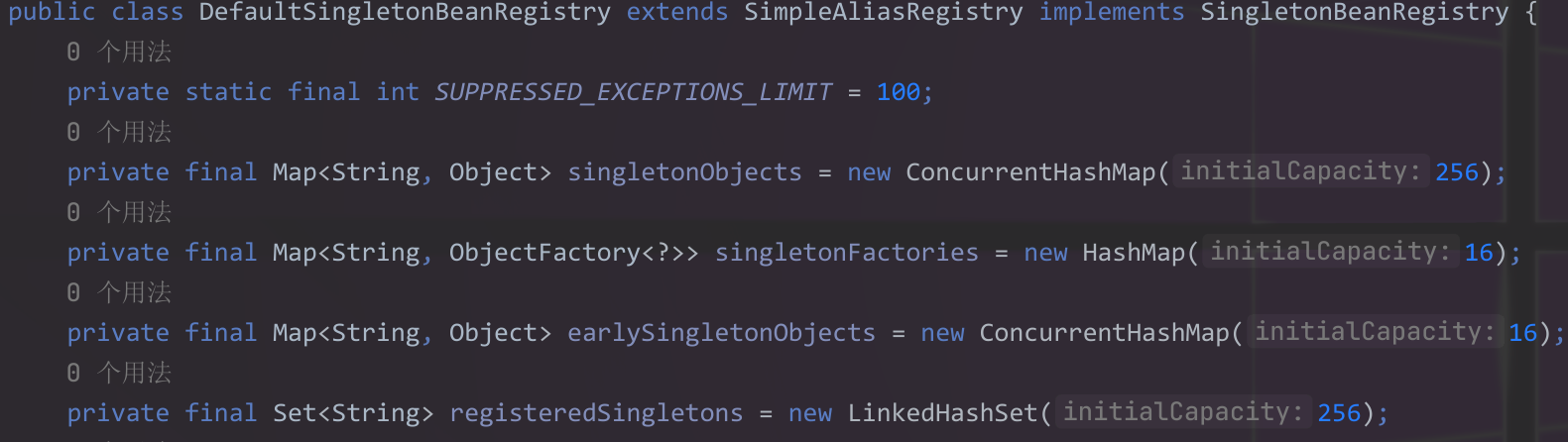
第一级缓存:singletonObjects (一级缓存 / 成品 Bean 缓存)
-
类型:
ConcurrentHashMap<String, Object> -
作用: 存放已经完全初始化好,并且可供使用的单例 Bean。当一个 Bean 在这里被找到时,它就是“成品”了,可以直接返回给请求者。
第二级缓存:earlySingletonObjects (二级缓存 / 早期暴露对象缓存)
-
类型:
ConcurrentHashMap<String, Object> -
作用: 存放已经实例化但尚未完成属性填充和初始化的 Bean。这些 Bean 是“半成品”,但它们被提前暴露出来,以便解决循环依赖。
第三级缓存:singletonFactories (三级缓存 / 早期单例工厂缓存)
- 类型:
HashMap<String, ObjectFactory<?>> - 作用: 存放创建 Bean 的 ObjectFactory。这个工厂负责生产“半成品”的 Bean 实例(可能经过 AOP 代理)。它是解决循环依赖的关键所在,尤其是在涉及到 AOP 代理的场景。
- 特点: 这里的不是 Bean 实例本身,而是一个能够获取早期 Bean 引用(可能是原始对象,也可能是代理对象)的工厂。
我们可以看到三级缓存singletonFactories的类型是HashMap,并且map的value值为ObjectFactory,不同于其他两级缓存。
💠为什么 value 是 ObjectFactory 而不是 Object?
-
这就是第三级缓存的精妙之处,也是它能够解决循环依赖与 AOP 代理同时存在问题的关键:
- 延迟生成早期引用:
- 在 Bean A 实例化后,它会立即将一个
ObjectFactory放入第三级缓存。 - 这个工厂只有在另一个 Bean B 发生循环依赖,并且需要提前获取 Bean A 的引用时,才会被调用(
singletonFactory.getObject())。 - 这种延迟机制使得 Spring 可以在真正需要 Bean A 的早期引用时,才决定并生成它。
- 在 Bean A 实例化后,它会立即将一个
- 处理 AOP 代理:
- 如果 Bean A 需要进行 AOP 代理(例如,因为它上面有
@Transactional注解,或者被某个切面匹配到),那么在ObjectFactory的getObject()方法被调用时,Spring 的 AOP 逻辑会被触发。 - 此时,
getObject()方法将不会简单地返回 Bean A 的原始实例,而是会返回 Bean A 的代理实例。 - 这个代理实例随后会被放入第二级缓存
earlySingletonObjects,供依赖方使用。
- 如果 Bean A 需要进行 AOP 代理(例如,因为它上面有
总结来说:
- 一级和二级缓存直接存放Bean 实例(成品或半成品)。
- 第三级缓存存放的是一个**“生产 Bean 实例的工厂”**。这个工厂在被调用时,能根据 Bean 的特性(特别是是否需要 AOP 代理),决定是返回原始实例还是其代理实例。
正是因为
singletonFactories存储的是一个能够“生产”早期 Bean 实例的工厂,而不是直接的 Bean 实例,Spring 才能够在循环依赖的场景下,灵活地提供经过 AOP 代理的早期 Bean 引用,从而保证了 Bean 引用的一致性,解决了复杂场景下的循环依赖问题。 - 延迟生成早期引用:
💠为什么 singletonFactories 使用 HashMap?
-
singletonObjects和earlySingletonObjects需要ConcurrentHashMap是因为它们是并发访问的热点,需要内部的并发控制来保证性能和线程安全。 -
singletonFactories使用HashMap是因为它的所有相关操作都已经被外部的synchronized (this.singletonObjects)锁保护起来,本身不需要内部的并发机制。 在这个全局锁的保护下,使用HashMap既满足了线程安全,又因为其操作频率相对较低而没有性能瓶颈。
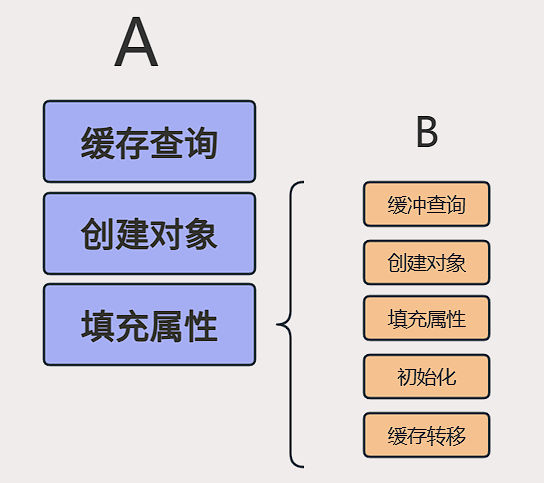
循环依赖流程?
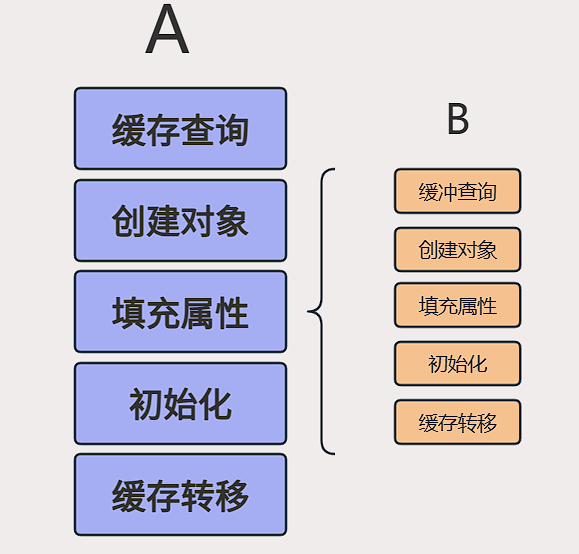
这五个是单例 Bean 的创建和缓存紧密相关的核心环节,清晰描述了 Spring 单例 Bean 的生命周期
- 缓存查询
这是获取 Bean 的第一步,也是最快、最高效的方式。
-
目标:检查 Spring IoC 容器中是否已经存在一个完全初始化好的 Bean 实例。
-
实现:Spring 会首先去它的**一级缓存(
singletonObjects)**中查找。 -
结果:
-
如果找到了,直接返回这个 Bean 实例。这是最理想的情况,省去了后续所有创建和初始化步骤。
-
如果没找到,并且这个 Bean 当前正在创建中(表示可能存在循环依赖),它会进一步尝试从**二级缓存(
earlySingletonObjects)或三级缓存(singletonFactories)**获取一个早期引用。
-
- 创建对象 (实例化)
如果缓存中没有找到可用的 Bean,那么 Spring 就会开始创建新的 Bean 实例。
- 目标:根据 Bean 定义(
BeanDefinition),通过反射等方式,生成 Bean 的原始实例。 - 实现:
- 对于普通 Bean,通常是调用其构造函数来创建对象。
- 在实例化完成后,Bean 的原始实例就存在了,但此时它只是一个“空壳”,没有任何属性被填充,也没有进行任何初始化操作。
- 关键时机:这个阶段是 Bean 生命周期中首次出现具体对象的地方。也是在这个阶段之后,如果存在循环依赖且允许早期引用,Spring 会将 Bean 的一个早期引用工厂(
ObjectFactory)放入三级缓存。
- 填充属性
对象创建后,它需要被注入所依赖的其他 Bean 和配置。
- 目标:将 Bean 定义中声明的属性(通过
@Autowired、@Resource等注解或 XML 配置)注入到刚创建的 Bean 实例中。 - 实现:
- Spring IoC 容器会解析 Bean 的依赖关系。
- 如果是通过 Setter 方法注入或字段注入,Spring 会查找对应的依赖 Bean。
- 如果在这个过程中遇到循环依赖(例如,
BeanA依赖BeanB,而BeanB此时需要BeanA),Spring 会利用之前放入三级缓存中的ObjectFactory来获取BeanA的早期引用(可能是代理对象),从而打破循环。
- 关键时机:循环依赖问题主要发生在这个阶段。
- 初始化
属性填充完成后,Bean 实例就具备了它所有的依赖,但可能还需要进行一些自定义的初始化工作。
-
目标:执行 Bean 的自定义初始化逻辑和生命周期回调。
-
实现:
- Aware 接口回调:如果 Bean 实现了
BeanNameAware、BeanFactoryAware、ApplicationContextAware等接口,Spring 会调用相应的方法注入名称、工厂或上下文。 - BeanPostProcessor 前置处理:调用所有注册的
BeanPostProcessor的postProcessBeforeInitialization方法。 @PostConstruct方法:执行 Bean 中被@PostConstruct注解标记的方法。InitializingBean接口afterPropertiesSet()方法:如果 Bean 实现了InitializingBean接口,调用其afterPropertiesSet()方法。- 自定义
init-method:执行 Bean 定义中指定的自定义初始化方法(如 XML 配置中的init-method)。 - BeanPostProcessor 后置处理:调用所有注册的
BeanPostProcessor的postProcessAfterInitialization方法。AOP 代理通常在这个阶段发生,postProcessAfterInitialization方法会返回 Bean 的代理对象。
- Aware 接口回调:如果 Bean 实现了
-
关键时机:Bean 的最终形态(包含所有代理)通常在这个阶段确定。
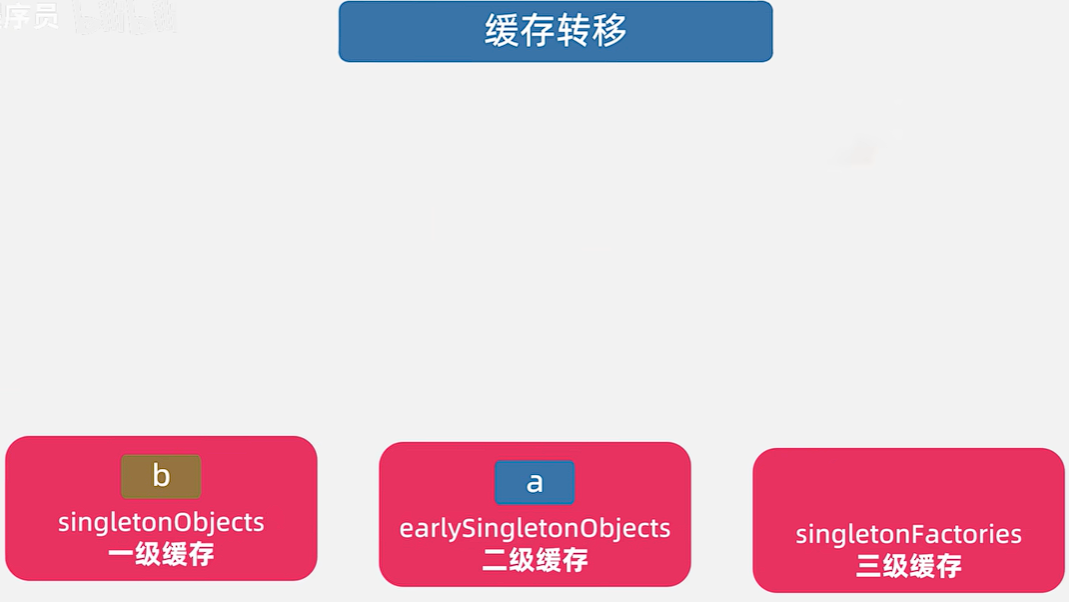
- 缓存转移 (放入一级缓存)
所有步骤都完成后,这个 Bean 就“大功告成”了。
- 目标:将完全初始化并可用的 Bean 实例,从所有临时缓存中移除,并放入最终的成品缓存。
- 实现:
- Spring 会将这个 Bean 实例放入一级缓存(
singletonObjects)。 - 同时,从**二级缓存(
earlySingletonObjects)和三级缓存(singletonFactories)**中移除该 Bean 的相关条目,因为它现在已经是“成品”了,不再是早期引用或工厂。
- Spring 会将这个 Bean 实例放入一级缓存(
- 结果:此后,任何对该 Bean 的请求都将直接从一级缓存中获取,高效且快速。
来看BeanA和BeanB这个循环依赖流程,在三级缓存中是怎么作用的?
流程参考视频[彻底拿捏Spring循环依赖以及三个级别缓存哔哩哔哩bilibili]
首先来看BeanA的创建过程
✨1.缓存查询
查询三级缓存,都没有,回到主流程,进行创建对象。
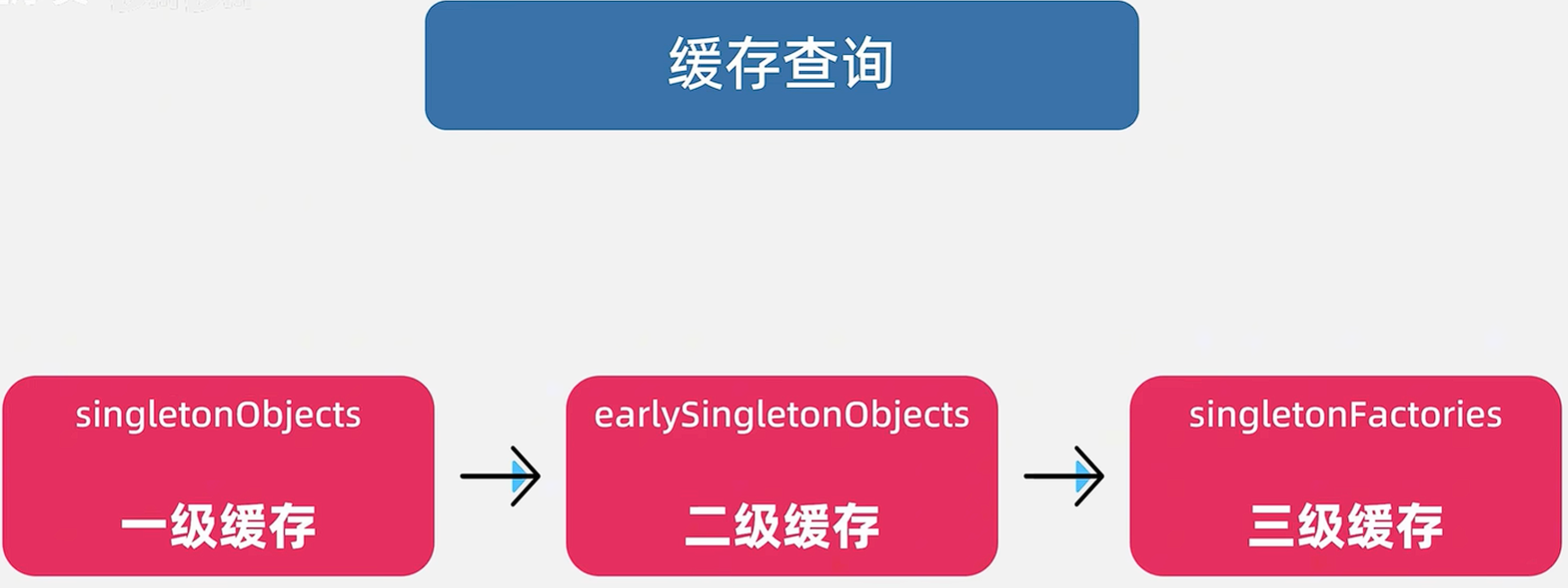
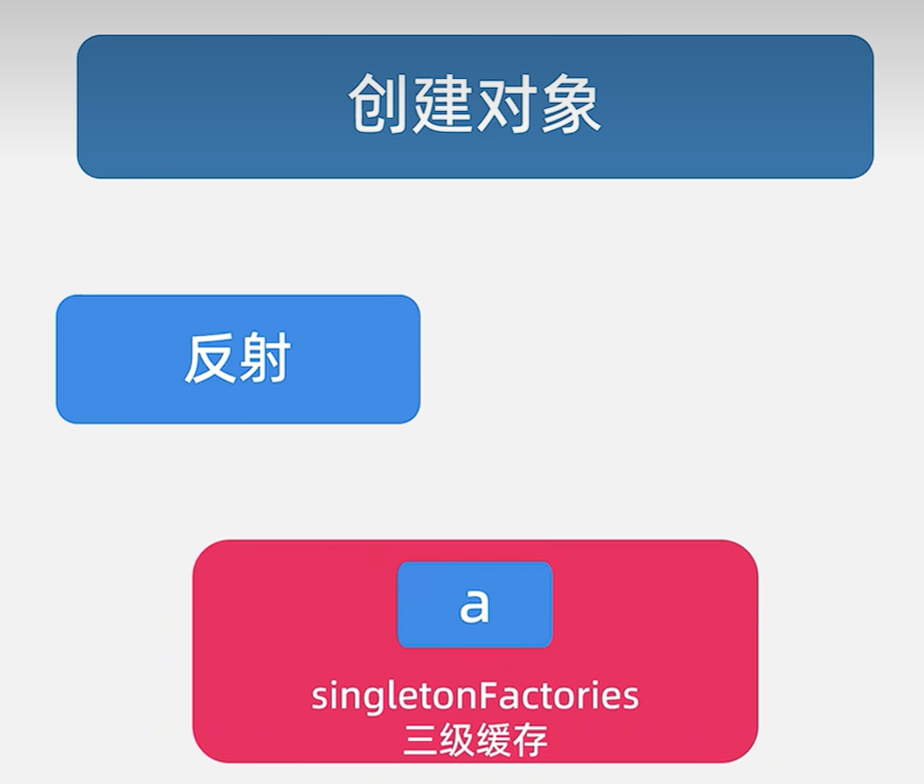
✨2.创建对象
我们通过反射创建对象,包装成ObjectFactory类型,放到三级缓存singletonFactories中,再回到主流程,进行填充属性。
✨3.填充属性
因为填充的是BeanB,所以要开始创建BeanB,同样走的是BeanA走的那一套流程 。
🎯3.1 进行缓存查询,查询不到,进行下一步创建对象。
🎯3.2 进行通过反射创建对象,此时三级缓存singletonFactories中已经有BeanA了,将BeanB放进去
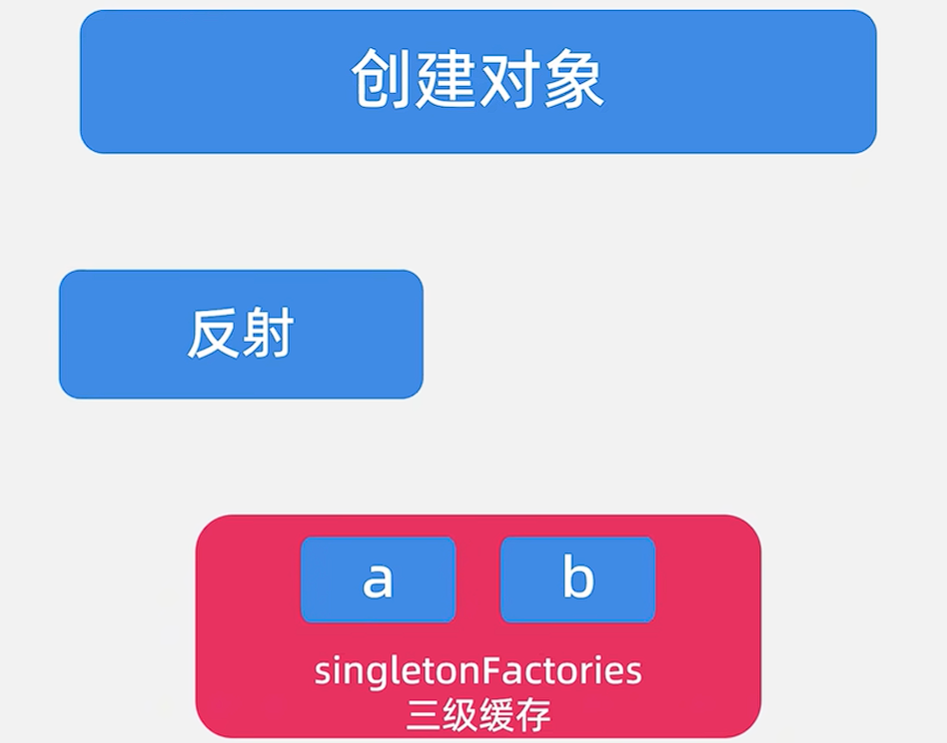
🎯3.3填充属性,要填充BeanA,又要开始创建BeanA的那一套流程。
3.3.1 进行缓存查询,此时三级缓存中是有的,执行一些额外操作
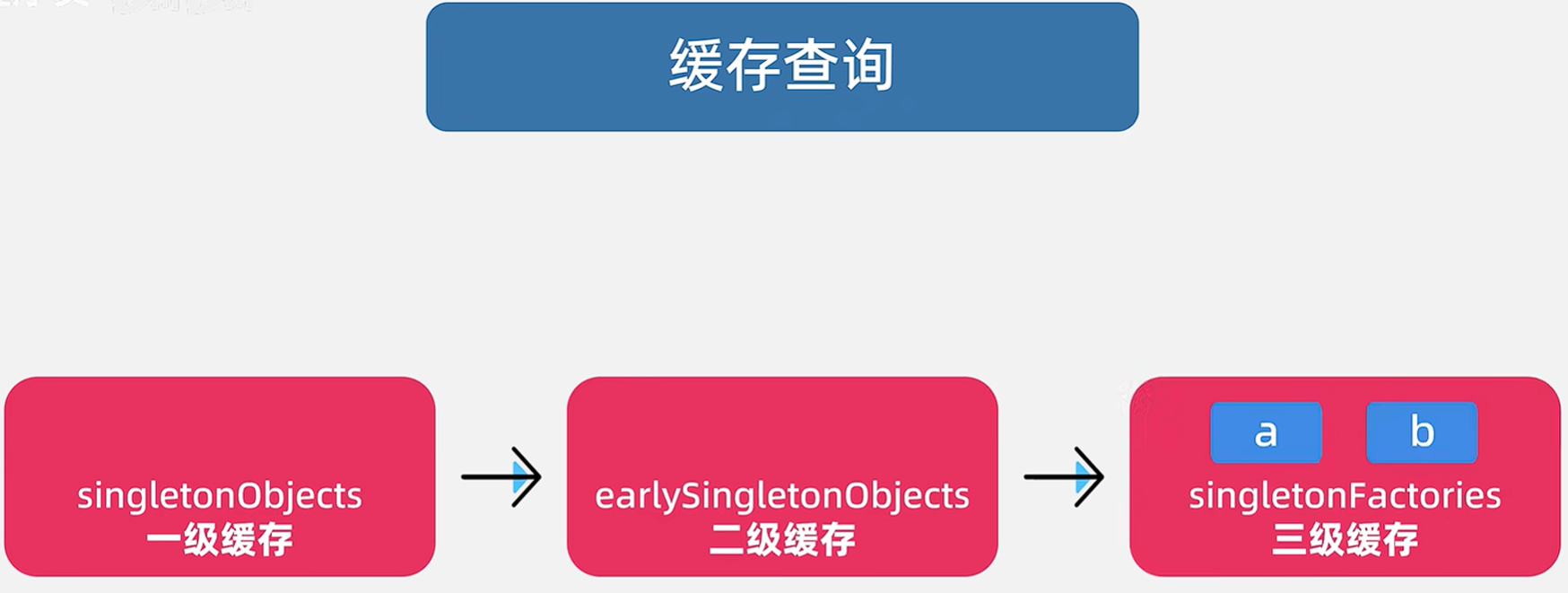
来看源码,重点看2.3-2.6 ,通过getObject获得对象,放到二级缓存中,并在三级缓存中移除它。
这样BeanB的填充属性就完成了。回到BeanB的主流程中,进行初始化
protected Object getSingleton(String beanName, boolean allowEarlyReference) {// 1. 首先尝试从一级缓存中获取成品 BeanObject singletonObject = this.singletonObjects.get(beanName);// 2. 如果一级缓存中没有,并且该 Bean 正在创建中 (解决循环依赖的关键入口)if (singletonObject == null && this.isSingletonCurrentlyInCreation(beanName)) {// 2.1. 尝试从二级缓存中获取早期暴露的 BeansingletonObject = this.earlySingletonObjects.get(beanName);// 2.2. 如果二级缓存中也没有,并且允许早期引用 (allowEarlyReference通常为true,表示允许循环依赖)if (singletonObject == null && allowEarlyReference) {// 对 singletonObjects 进行同步锁,保证线程安全,防止多个线程同时处理同一个Bean的早期引用synchronized(this.singletonObjects) {// 再次检查一级缓存,因为在同步块外可能被其他线程放入singletonObject = this.singletonObjects.get(beanName);if (singletonObject == null) { // 再次确认一级缓存没有// 再次检查二级缓存,确保同步块内没有被其他线程放入singletonObject = this.earlySingletonObjects.get(beanName);if (singletonObject == null) { // 再次确认二级缓存没有// 2.3. 从三级缓存中获取 ObjectFactoryObjectFactory<?> singletonFactory = (ObjectFactory)this.singletonFactories.get(beanName);if (singletonFactory != null) {// 2.4. 调用 ObjectFactory 的 getObject() 方法获取早期 Bean 实例// 这可能是原始对象,也可能是代理对象(如果AOP触发)singletonObject = singletonFactory.getObject();// 2.5. 将获取到的早期 Bean 实例放入二级缓存this.earlySingletonObjects.put(beanName, singletonObject);// 2.6. 从三级缓存中移除对应的 ObjectFactory,因为已经使用了this.singletonFactories.remove(beanName);}}}}}}return singletonObject;
}
🎯3.4 初始化,执行 Bean 的自定义初始化逻辑和生命周期回调。
🎯3.5 缓存转移,因为BeanB已经完全创建完毕了,所有要将缓存里面的对象进行转移
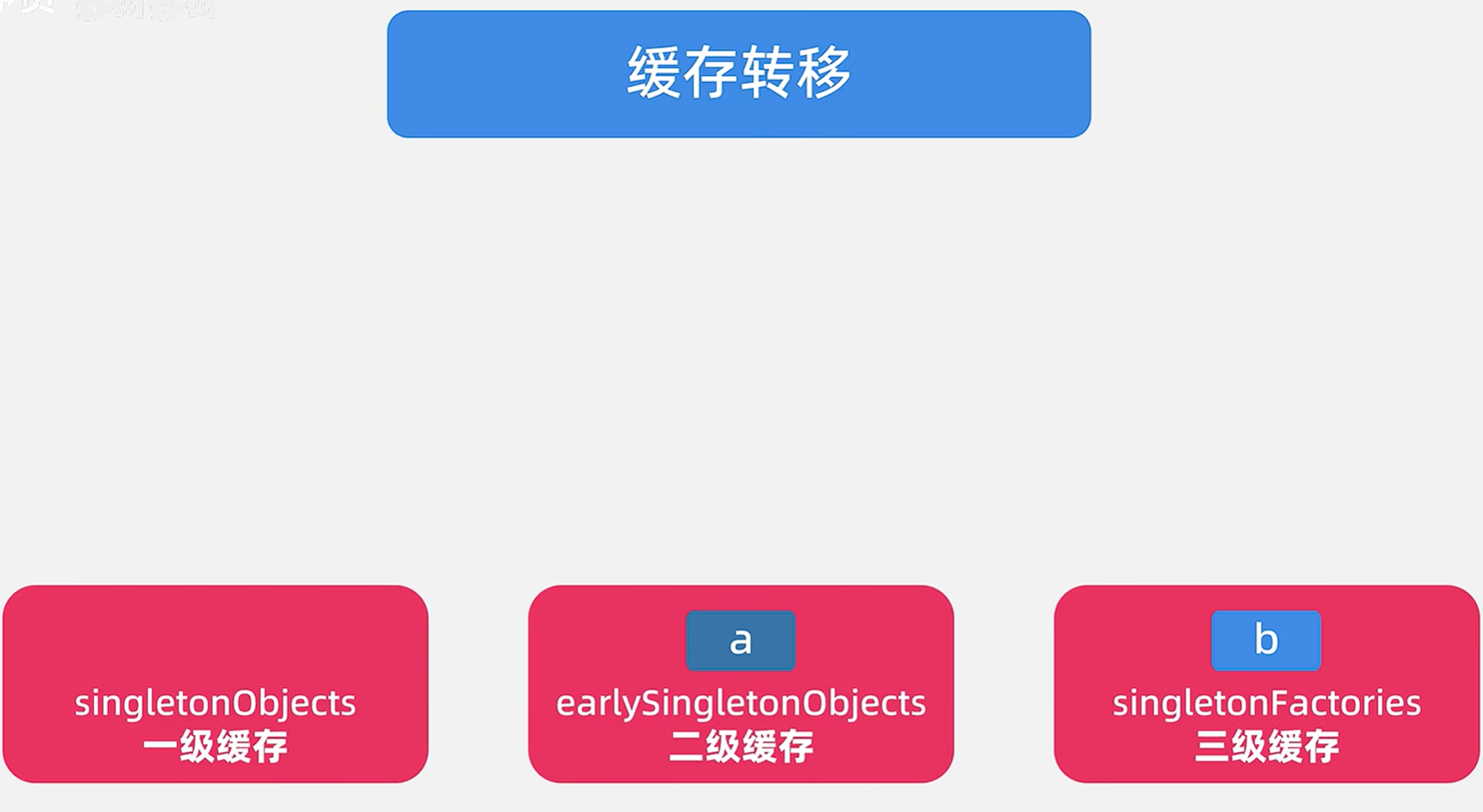
看源码,将BeanB放入一级缓存中,从三级缓存中移除,从二级缓存中移除。
protected void addSingleton(String beanName, Object singletonObject) {synchronized(this.singletonObjects) {this.singletonObjects.put(beanName, singletonObject); // 放入一级缓存this.singletonFactories.remove(beanName); // 从三级缓存移除,因为已经不是早期引用了this.earlySingletonObjects.remove(beanName); // 从二级缓存移除,因为已经不是早期引用了this.registeredSingletons.add(beanName); // 记录为已注册的单例}
}

到这里整个BeanB的创建过程就完成了,但这只是BeanA填充属性,我们还要跳回BeanA的创建过程。
✨4.初始化
✨5.缓存转移
同上类似,移除二级和三级缓存中的BeanA,添加一级缓存中

为什么需要第三级缓存,有两个不就行了
简单来说,第三级缓存是为了解决当 Bean 存在循环依赖,并且还需要进行 AOP 代理(或者其他后置处理器处理)时的问题。
如果没有第三级缓存,仅靠两级缓存,Spring 无法在需要 AOP 代理时正确处理循环依赖。
为什么两级缓存不够?
我们来想象一下只有两级缓存(singletonObjects 和 earlySingletonObjects)的场景:
假设有两个 Bean:BeanA 和 BeanB。
BeanA依赖BeanB。BeanB依赖BeanA。- 最重要的是:
BeanA需要被 AOP 代理(例如,它上面有@Transactional注解,或者自定义的切面)。
流程推演(只有两级缓存):
- 创建
BeanA:- Spring 开始创建
BeanA。 - 实例化
BeanA的原始对象a。 - 将
a放入二级缓存earlySingletonObjects。
- Spring 开始创建
BeanA填充属性,需要BeanB:BeanA的属性填充过程中,发现需要BeanB。- Spring 暂停
BeanA的创建,转而创建BeanB。
- 创建
BeanB:- Spring 开始创建
BeanB。 - 实例化
BeanB的原始对象b。 - 将
b放入二级缓存earlySingletonObjects。
- Spring 开始创建
BeanB填充属性,需要BeanA:BeanB的属性填充过程中,发现需要BeanA。- Spring 到缓存中查找
BeanA:- 在一级缓存
singletonObjects中找不到BeanA(因为它还没初始化完)。 - 在二级缓存
earlySingletonObjects中找到了BeanA的原始对象a。 - 将
a注射到BeanB中。
- 在一级缓存
BeanB完成初始化:BeanB完成属性填充和所有初始化步骤。BeanB被放入一级缓存singletonObjects,完成创建。
BeanA继续完成初始化:BeanA现在得到了完整的BeanB。BeanA继续进行初始化步骤,包括执行 AOP 代理逻辑。- 此时,问题来了:当
BeanA执行 AOP 代理时,它会生成一个代理对象a_proxy。这个a_proxy才是最终应该被其他 Bean 引用和使用的对象。 - 但问题是,
BeanB在第4步中已经获取并使用了BeanA的原始对象a,而不是a_proxy。
结论: 在这种情况下,BeanB 引用的是未被 AOP 代理的 BeanA 原始对象,而其他后来的 Bean 引用的是 BeanA 的代理对象。这就导致了 Bean 实例的不一致性,后续对 BeanA 的方法调用可能无法触发 AOP 逻辑,从而导致功能异常。
第三级缓存 singletonFactories 的作用
第三级缓存 singletonFactories 存放的不是 Bean 实例,而是一个 ObjectFactory(一个工厂)。这个工厂的 getObject() 方法,会在需要时,动态地生成并返回 Bean 的早期引用。
关键在于:这个工厂在生成早期引用时,会判断当前 Bean 是否需要进行 AOP 代理。如果需要,它会直接返回代理对象;如果不需要,它就返回原始对象。
引入第三级缓存后的流程推演:
- 创建
BeanA:- Spring 开始创建
BeanA。 - 实例化
BeanA的原始对象a。 - Spring 将一个
ObjectFactory放入第三级缓存singletonFactories。 这个工厂在被调用时,会负责生成BeanA的早期引用(可能是原始对象或代理对象)。 - 同时,将
BeanA从singletonFactories中移除,将原始对象a放入earlySingletonObjects(二级缓存)。
- Spring 开始创建
BeanA填充属性,需要BeanB:BeanA的属性填充过程中,发现需要BeanB。- Spring 暂停
BeanA的创建,转而创建BeanB。
- 创建
BeanB(步骤同前,不再赘述)。 BeanB填充属性,需要BeanA:BeanB的属性填充过程中,发现需要BeanA。- Spring 到缓存中查找
BeanA:- 在一级缓存
singletonObjects中找不到。 - 在二级缓存
earlySingletonObjects中找到了BeanA的原始对象a。 - 如果此时
BeanA需要被 AOP 代理,并且 AOP 后置处理器已经准备好,那么earlySingletonObjects中的a将不会直接返回给BeanB。 - 而是会通过
singletonFactories中对应的ObjectFactory来获取BeanA的早期引用。 这个工厂被调用时,会触发BeanA的 AOP 代理逻辑,生成a_proxy。 a_proxy会被放入二级缓存earlySingletonObjects,替换掉原始对象a。(重要:这里原始对象被替换为代理对象)- 然后,
a_proxy被注射到BeanB中。
- 在一级缓存
BeanB完成初始化:BeanB完成属性填充和所有初始化步骤,并被放入一级缓存singletonObjects。
BeanA继续完成初始化:BeanA现在得到了完整的BeanB。BeanA继续进行剩余的初始化步骤。BeanA的最终代理对象(如果之前生成过,就是那个a_proxy;如果没有,则在此处生成并最终确定)被放入一级缓存singletonObjects。
核心优势:
通过三级缓存,当一个 Bean(比如 BeanA)在创建过程中被另一个 Bean(比如 BeanB)提前引用时,并且这个 BeanA 需要被 AOP 代理,三级缓存中的 ObjectFactory 能够保证所有获取到的早期引用都是经过 AOP 代理后的对象。这样就确保了 Bean 实例的一致性,无论是在循环依赖中被提前引用,还是在后续正常流程中被引用,都将得到的是同一个 AOP 代理后的实例。
总结: 两级缓存无法处理 AOP 代理的场景,因为在 Bean 完全初始化前无法确定最终是返回原始对象还是代理对象。第三级缓存通过存储一个工厂(ObjectFactory),使得 Spring 能够在需要时才决定并生成最终的早期引用(可以是原始对象,也可以是代理对象),从而保证了在循环依赖和 AOP 代理同时存在时的正确性和一致性。