数据结构自学Day14 -- 利用归并排序思想实现“外排序”
一、归并排序
归并排序是一种分治思想的排序算法,它非常适合处理“外排序”的问题。所谓“外排序”(External Sorting),就是当数据量太大,无法全部加载进内存时,必须依赖磁盘文件进行排序的技术。归并排序的稳定性、高效性和顺序访问特性非常契合这一应用场景。
往期归并排序回顾
数据结构自学Day14 -- 归并排序
二、外排序的基本问题
-
当要排序的数据集非常大(如几十GB或TB),内存(RAM)无法一次性容纳;
-
此时必须通过分块处理、磁盘读写等技术实现排序;
-
外排序的目标:在内存资源受限条件下高效完成排序。
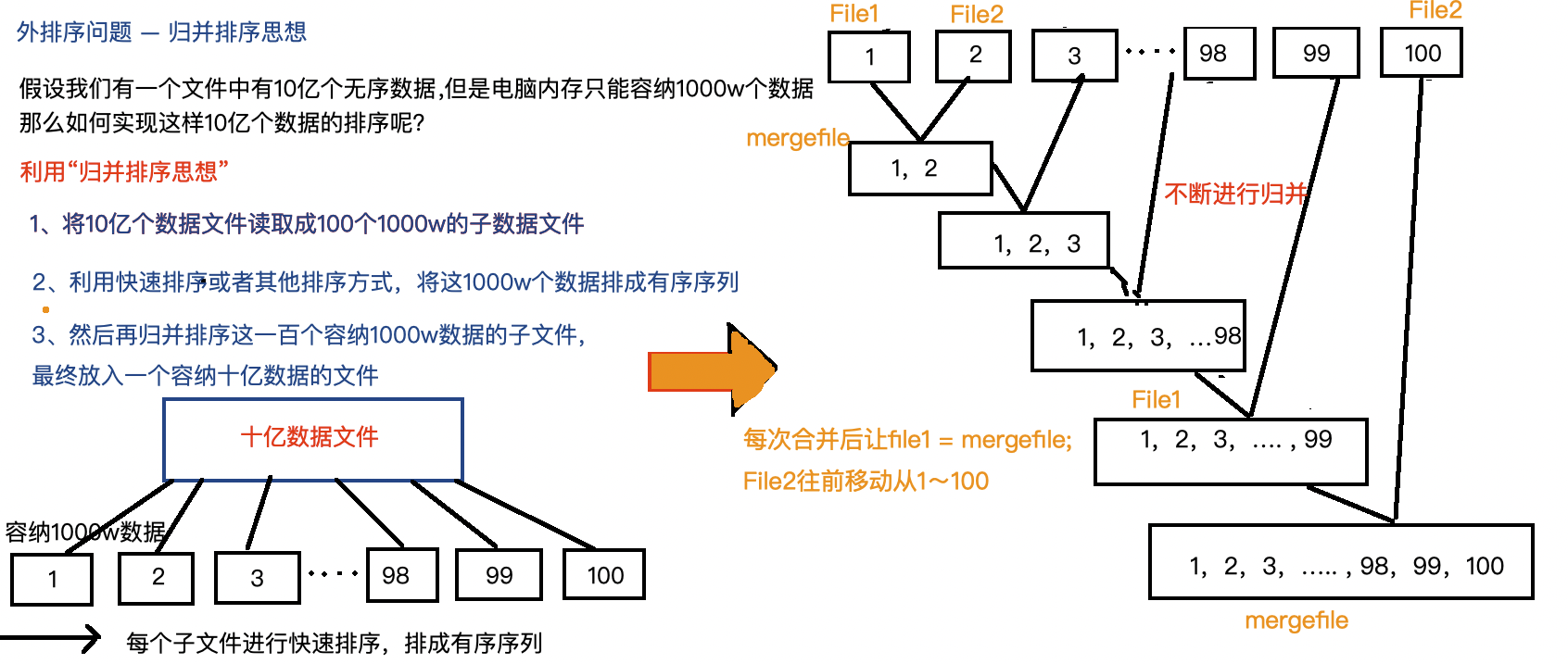
问题描述:不妨假设我们的文件中有10亿个数据,假设我们的内存只能存放1000w个数据。如何实现10亿个数据的排序呢?
三、归并外排序的详细步骤
第一步:分段读取+内排序(Initial Run Generation)
-
将大文件分成多个小块(chunk),每个块的大小不超过内存大小;
-
逐块读取到内存中,对每块使用内部排序算法(比如快速排序、堆排序、归并排序等);
-
将排序后的每个块写回磁盘,称为一个“初始有序子文件(run)”。
比如,一个100GB的文件,内存只有1GB,就将其分成100个1GB的块,分别排好序,保存为 run1, run2, …, run100。
第二步:多路归并(Multi-way Merge)
-
使用k路归并算法将多个有序子文件合并成一个大的有序文件;
-
每次归并时,从每个子文件中依次读取部分数据到内存缓冲区,按序比较最小值写入输出文件;
-
如果内存足够小,可以一次合并2路、4路、8路,甚至更多路;
-
多次归并后,最终形成一个完整的有序文件。
若不能一次性归并所有子文件,则多轮归并直到剩下一个最终文件。
思维导图:
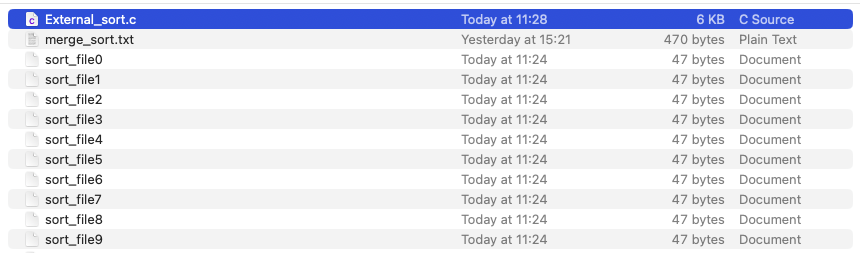
1、首先创建一个由大量数据的文件,里面存有一下无序的数据,文件内容如下:

2、将这些数据分开保存为子文件,假设这里我们有130个数据,按顺序每次读取13个数据保存为子文件,总共10个子文件。
//外排序,划分成排序好的子文件 void External_Sort(const char* file){assert(file);FILE* fout = fopen(file,"r");if(!fout){perror("fopen!");exit(-1);}int num1= 0; //存储读入的数据int size = 13;char Subfile[20];int* arr = (int*) malloc(sizeof(int)*size);int filei = 0;int i=0;while(fscanf(fout,"%d\n",&num1)!=EOF){ //确保读取数据if(i<size-1){arr[i++] = num1; }else{arr[i++] = num1;//读取到足够的数据进行排列后再放入子文件QuickSort_stack(arr,0,size-1);sprintf(Subfile,".//sort_file%d",filei++);FILE* fin = fopen(Subfile,"w");if(!fin){perror("fopen!");exit(-1);}else{for(int k =0;k<size;k++){fprintf(fin,"%d\n",arr[k]);}}i = 0;fclose(fin);memset(arr,0,size);}}//当最后一组数据数量不够,也排序后放入子文件if(i>0){QuickSort_stack(arr,0,i);sprintf(Subfile,".//sort_file%d",filei++);FILE* fin = fopen(Subfile,"w");for(int k =0;k<i;k++){fprintf(fin,"%d\n",arr[k]);}fclose(fin);}//合并子文件 }
//测试函数 int main(){External_Sort("merge_sort.txt"); } // merge_sort.txt是需要排序的那个大数据文件
电脑生成的子目录如下文件目录
3、合并子文件,产生归并排序后的新文件
//归并文件,俩俩进行归并 void _mergefile(const char* file1,const char* file2,const char* merge_file){FILE* fout1 = fopen(file1,"r");FILE* fout2 = fopen(file2,"r");FILE* fin = fopen(merge_file,"w");if(!fout1 || !fout2 || !fin){perror("fopen!");exit(-1);}int num1 = 0;int num2 = 0;int ret1= fscanf(fout1,"%d\n",&num1);int ret2= fscanf(fout2,"%d\n",&num2);while ( ret1 != EOF && ret2 !=EOF){if(num1<num2){fprintf(fin,"%d\n",num1);ret1= fscanf(fout1,"%d\n",&num1);}else{fprintf(fin,"%d\n",num2);ret2= fscanf(fout2,"%d\n",&num2);}}while (ret1 != EOF){fprintf(fin,"%d\n",num1);ret1= fscanf(fout1,"%d\n",&num1);}while (ret2 != EOF){fprintf(fin,"%d\n",num2);ret2= fscanf(fout2,"%d\n",&num2);}}对两个文件进行归并排序函数,其中file1,和file2是需要归并的两个文件,merge_file是归并后的文件;
文件file1和file2的内容如下,将这两个文件内容进行归并排序后放入merge_file中


merge_file文件内容:排好序之后的数据内容
全部代码实现如下
//文件归并函数 void _mergefile(const char* file1,const char* file2,const char* merge_file){FILE* fout1 = fopen(file1,"r");FILE* fout2 = fopen(file2,"r");FILE* fin = fopen(merge_file,"w");if(!fout1 || !fout2 || !fin){perror("fopen!");exit(-1);}int num1 = 0;int num2 = 0;int ret1= fscanf(fout1,"%d\n",&num1);int ret2= fscanf(fout2,"%d\n",&num2);while ( ret1 != EOF && ret2 !=EOF){if(num1<num2){fprintf(fin,"%d\n",num1);ret1= fscanf(fout1,"%d\n",&num1);}else{fprintf(fin,"%d\n",num2);ret2= fscanf(fout2,"%d\n",&num2);}}while (ret1 != EOF){fprintf(fin,"%d\n",num1);ret1= fscanf(fout1,"%d\n",&num1);}while (ret2 != EOF){fprintf(fin,"%d\n",num2);ret2= fscanf(fout2,"%d\n",&num2);}fclose(fout1);fclose(fout2);fclose(fin);} //外排序函数 void External_Sort(const char* file){assert(file);FILE* fout = fopen(file,"r");if(!fout){perror("fopen!");exit(-1);}int num1= 0; //存储读入的数据int size = 13;char Subfile[20];int* arr = (int*) malloc(sizeof(int)*size);int filei = 1;int i=0;while(fscanf(fout,"%d\n",&num1)!=EOF){ //确保读取数据if(i<size-1){arr[i++] = num1; }else{arr[i++] = num1;//读取到足够的数据进行排列后再放入子文件QuickSort_stack(arr,0,size-1);sprintf(Subfile,".//sort_file%d",filei++);FILE* fin = fopen(Subfile,"w");if(!fin){perror("fopen!");exit(-1);}else{for(int k =0;k<size;k++){fprintf(fin,"%d\n",arr[k]);}}i = 0;fclose(fin);memset(arr,0,size);}}//当最后一组数据数量不够,也排序后放入子文件if(i>0){QuickSort_stack(arr,0,i);sprintf(Subfile,".//sort_file%d",filei++);FILE* fin = fopen(Subfile,"w");for(int k =0;k<i;k++){fprintf(fin,"%d\n",arr[k]);}fclose(fin);}fclose(fout);//合并子文件char file1[200] = "sort_file1";char file2[200] = "";char merge_file[200] = "";for(int k = 2;k<filei;k++){// sprintf(file1,"sort_file%d",k-1);sprintf(file2,"sort_file%d",k);sprintf(merge_file,"merge_file%d",k-1);_mergefile(file1,file2,merge_file);strcpy(file1,merge_file);};} //测试函数 int main(){External_Sort("merge_sort.txt"); }注意,要运行上述代码,记住引用相应的头文件,并且有一个大的需要排序的数据文件“merge_sort.txt”。
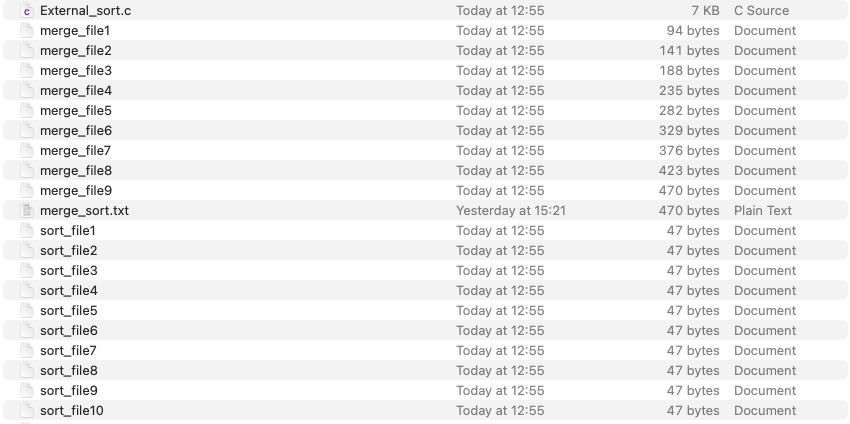
结果展示:
运行代码文件后,当前目录的文件内容,sort_file是划分的子文件,merge_file时合并的文件,其中merge_file9是最终合并的文件,里面包括全部排序之后的数据。
四、为什么归并排序适合外排序?
| 特点 | 原因 |
|---|---|
| 顺序访问磁盘文件 | 归并排序过程中只需要顺序读写,不涉及随机访问,减少磁盘寻址时间 |
| 可扩展性强 | 不受数据规模限制,理论上支持任意大数据集排序 |
| 稳定性好 | 归并排序是稳定排序,适用于对记录结构有额外排序要求的情况(如多关键字) |
| 易于实现多路归并优化 | 可以用堆优化k路归并,进一步提升效率 |
五、总结一句话:
归并排序是外排序的理想选择,因为它天生就适合处理分块+归并的结构,能够在内存受限时高效对大数据集进行排序,且具备稳定性和良好的I/O顺序访问特性。