ClickHouse高性能实时分析数据库-高性能的模式设计
告别等待,秒级响应!这不只是教程,这是你驾驭PB级数据的超能力!我的ClickHouse视频课,凝练十年实战精华,从入门到精通,从单机到集群。点开它,让数据处理速度快到飞起,让你的职业生涯从此开挂!
全套视频教程联系博主
4.1. 核心设计原则
① 宽表优先,适当反范式化
忘掉你在 MySQL 等关系型数据库里学的“第三范式”!在 ClickHouse 的世界里,JOIN 是昂贵的。我们追求的是一次扫描,出所有结果。
传统做法 (慢):
订单表JOIN用户表JOIN商品表...ClickHouse 做法 (快):把
用户名,商品名等信息直接冗余到订单表中,形成一张“宽表”。
② 选择正确的排序键 (ORDER BY):
这是 ClickHouse 最重要的性能优化点
ORDER BY 是 ClickHouse 表设计中最最最重要的一个环节!它决定了数据在磁盘上的物理存储顺序。
想象一下一本巨大的电话簿。如果它是按姓氏首字母排序的,你要找姓“张”的人会非常快。但如果它是乱序的,你只能一页一页翻。
排序键的威力:ClickHouse 会根据
ORDER BY的列创建稀疏索引。当你查询的WHERE条件命中了排序键的前缀时,ClickHouse 就能像翻电话簿一样,迅速跳过大量不相关的数据块。

图解:当查询 WHERE event_date = '2023-10-02' 时,ClickHouse 查看索引发现,只有“数据块2”可能包含这个日期的数据,因此它会跳过“数据块1”和“数据块3”,只读取极少量的数据。
法则:将你最常用作查询条件、范围筛选、分组的列放在 ORDER BY 的最前面!
③ 合理设置分区键 (PARTITION BY)
如果说 ORDER BY 是整理书架上的书,那 PARTITION BY 就是把图书馆分成不同的房间,比如“历史区”、“科技区”。
分区的好处:当你的查询条件能命中分区键时,ClickHouse 连“房间”的门都不会打开,直接跳过整个分区目录。这对于删除、修改旧数据(
ALTER TABLE ... DROP PARTITION)也非常高效。
常用分区策略:按月(toYYYYMM(event_date))或按天(toDate(event_date))。
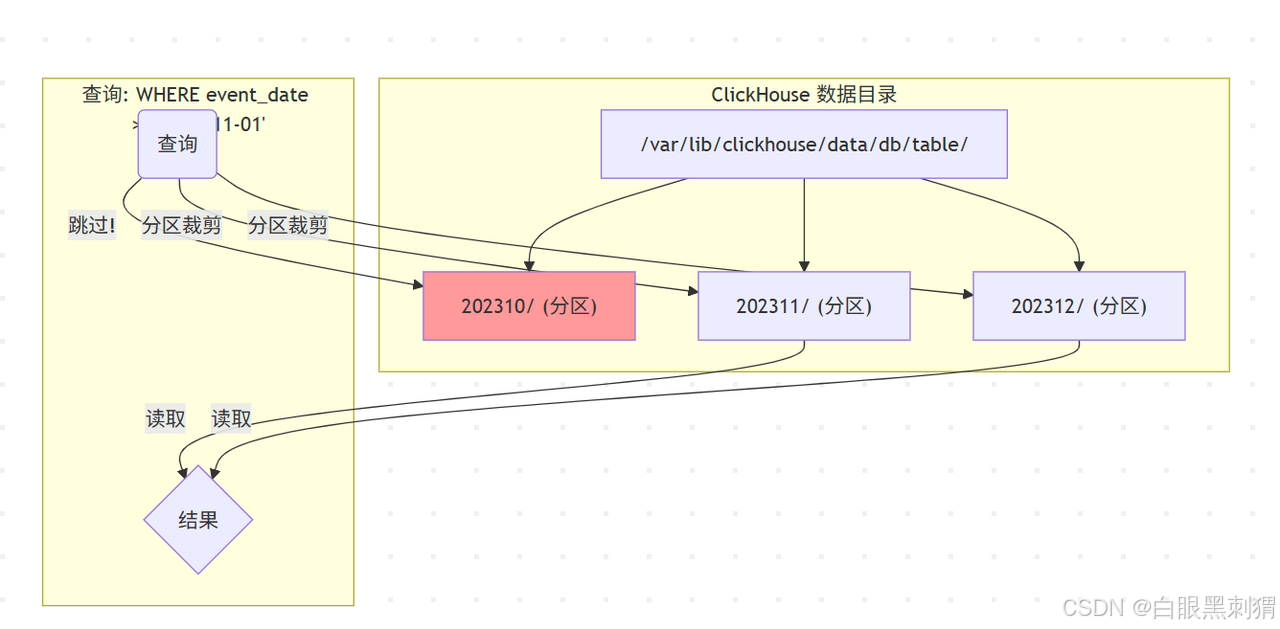
法则:分区粒度不宜过细(比如按秒),否则会产生海量小文件,拖垮性能。通常按月或按天是最佳实践。 数据类型是关键
使用最小且最合适的数据类型
用大炮打蚊子是浪费。为数据选择最小且最合适的类型,可以极大地减少存储空间、降低内存消耗和 I/O,从而提升查询速度。
错误:用
String存IP地址,用Int64存年龄。正确:用
IPv4类型存IP,用UInt8存年龄(0-255岁足够了)。