Java集合体系详解
目录
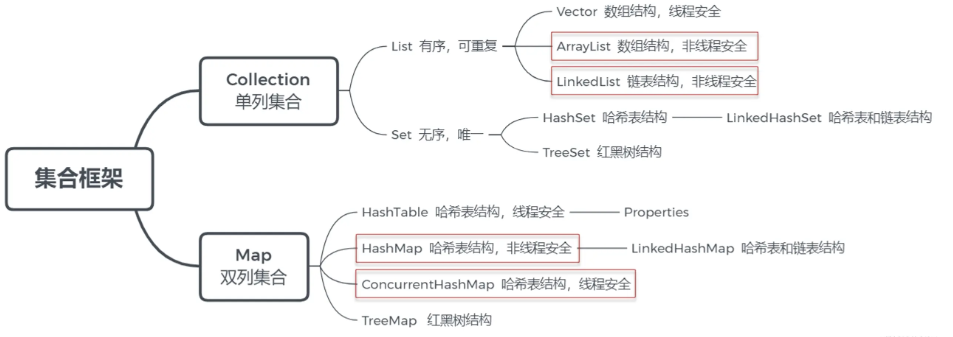
一、Java 集合框架
二、List
1、ArrayList
2、LinkedList
3、Vector
三、Set
1、HashSet
2、LinkedHashSet
3、TreeSet
四、Queue
1、PriorityQueue
2、Deque
五、Map
1、HashMap
2、Hashtable
3、LinkedHashMap
4、TreeMap
5、ConcurrentHashMap
ConcurrentMap
一、Java 集合框架
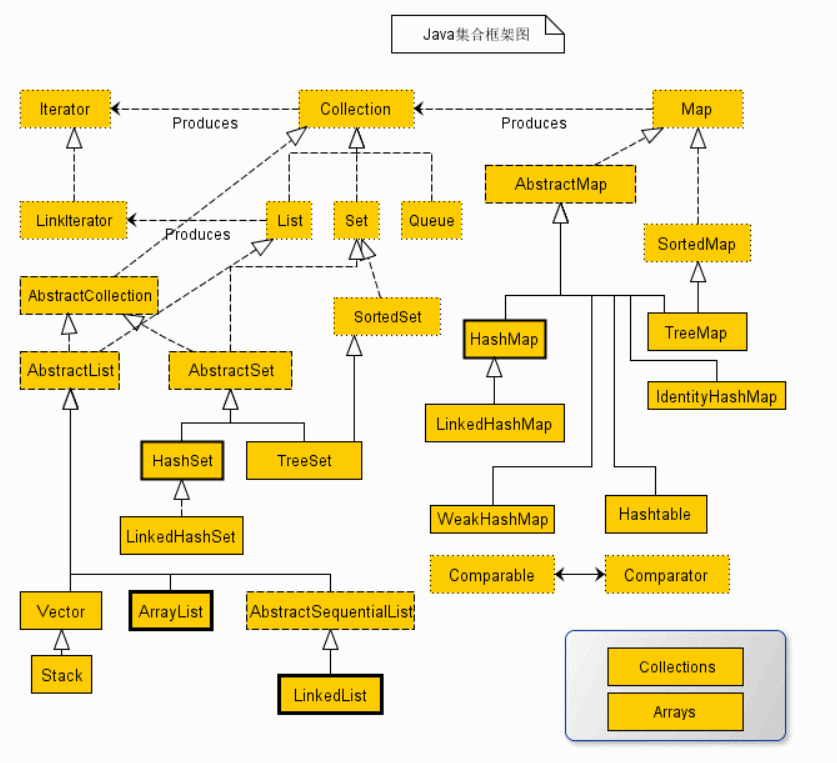
从上面的集合框架图可以看到,Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。
其中Collection派生出了三个子接口:List代表了有序可重复集合,可直接根据元素的索引来访问、Set代表无序不可重复集合,只能根据元素本身来访问、Queue是队列集合。
集合框架是一个用来代表和操纵集合的统一架构。
二、List
List代表了有序可重复集合,可直接根据元素的索引来访问。常用的实现类有:ArrayList、LinkedList、Vector。
List集合的特点:存取有序、可以重复、有索引
Collection与List区别:Collection是无序的,不支持索引操作;而List是有序的,支持索引操作
1、ArrayList
底层是数组结构实现,查询快、增删慢。线程不安全
该类是非同步的,在多线程的情况下不要使用。扩容时,ArrayList 增长当前长度的50%,插入删除效率低。
扩容机制:如果当前数组长度为10,扩容后会创建一个长度为15的数组(新数组的长度,是原来的1.5倍),并把所有元素拷贝到新数组中。如果一次性添加过多15个还是不够,那就会按照添加的长度来,比如我要添加100个,那新数组的长度就是110。
2、LinkedList
底层是链表结构实现,查询慢、增删快。
3、Vector
底层数据结构是数组,查询快,增删慢。线程安全
和ArrayList非常相似,但是该类是同步的,可以用在多线程的情况,该类允许设置默认的增长长度,默认扩容方式为原来的2倍。
三、Set
Set 具有与 Collection 完全一样的接口,只是行为上不同,Set 不保存重复的元素。
Set 接口存储一组唯一,无序的对象。
Set 接口继承自 Collection 接口,其核心特点是存储唯一、无序的对象(“无序” 指不保证元素的存储顺序与插入顺序一致,除非特定实现类),不允许重复元素(通过元素的 equals() 方法判断重复性)。常用实现类包括 HashSet、LinkedHashSet、TreeSet。
1、HashSet
底层结构:基于 HashMap 实现(将元素作为 HashMap 的 key 存储,value 为一个固定的空对象)。
特点:
无序性:不保证元素的存储顺序与插入顺序一致,依赖元素的哈希值确定存储位置。
高效性:查询、添加、删除操作的时间复杂度接近 O (1),取决于哈希函数的均匀性。
去重机制:依赖元素的 hashCode() 和 equals() 方法 —— 若两个元素的 hashCode() 返回值不同,则一定不相等;若 hashCode() 相同,需通过 equals() 进一步判断是否重复。因此,存储在 HashSet 中的元素必须重写这两个方法。允许 null 元素(但只能有一个 null,因不可重复)。
线程不安全,多线程环境下需额外同步处理。
2、LinkedHashSet
底层结构:继承自 HashSet,底层在 HashMap 基础上额外维护了一条双向链表,用于记录元素的插入顺序。
特点:
有序性:保证元素的存储顺序与插入顺序一致(通过链表维护)。
性能:略低于 HashSet(因需维护链表结构),但迭代遍历效率更高(直接按链表顺序访问)。
其他特性与 HashSet 一致(如去重机制、允许 null、线程不安全等)。
3、TreeSet
底层结构:基于 TreeMap 实现(将元素作为 TreeMap 的 key 存储),底层依赖红黑树(一种自平衡二叉搜索树)。
特点:
有序性:会对元素进行排序(“有序” 指按特定规则排序,而非插入顺序),支持两种排序方式:定制排序:创建 TreeSet 时传入 Comparator 接口实现类,指定排序规则。自然排序:元素需实现 Comparable 接口,通过 compareTo() 方法定义排序规则。
去重机制:通过排序规则判断元素是否重复(若 compareTo() 或 compare() 返回 0,则视为重复元素,不允许添加)。
不允许 null 元素(若元素未实现 Comparable,或排序规则不支持 null,添加 null 会抛出异常)。
线程不安全,查询、添加、删除操作的时间复杂度为 O (log n)(红黑树的特性)。
四、Queue
Queue 接口继承自 Collection 接口,代表队列数据结构,核心特性是先进先出(FIFO):通常从队列尾部添加元素,从头部删除元素。部分实现类支持优先级或双端操作。常用实现类包括 PriorityQueue、Deque 及其实现类。
1、PriorityQueue
- 特点:并非传统 FIFO 队列,而是基于优先级的队列,元素按优先级排序(优先级高的元素先出队)。
- 底层结构:基于二叉堆(一种完全二叉树结构)实现,通过数组存储堆元素。
- 排序规则:
- 元素需实现
Comparable接口(自然排序),或创建时传入Comparator(定制排序),否则添加元素时会抛出ClassCastException。 - 优先级最高的元素位于队列头部(如自然排序中,数值小的元素优先级高)。
- 元素需实现
- 其他特性:
- 允许 null 元素,但添加 null 会抛出
NullPointerException(因无法比较)。 - 非线程安全,多线程环境下需使用
PriorityBlockingQueue(并发队列)。 - 初始容量为 11,扩容时若当前容量小于 64,则翻倍;否则扩容 50%。
- 允许 null 元素,但添加 null 会抛出
2、Deque
- 定义:Deque(双端队列)是 Queue 的子接口,允许在两端(头部和尾部)都进行添加、删除和查询操作,既可以作为 FIFO 队列使用,也可以作为 LIFO(后进先出)栈使用。
- 常用实现类:
- ArrayDeque:
- 底层基于动态数组实现,无容量限制(自动扩容)。
- 效率高于 LinkedList(因数组访问更快),适合作为栈或队列使用。
- 不允许 null 元素(添加 null 会抛出
NullPointerException),非线程安全。
- LinkedList:
- 底层基于双向链表实现,允许 null 元素。
- 作为 Deque 时,可通过
addFirst()/addLast()添元素,pollFirst()/pollLast()删元素,peekFirst()/peekLast()查元素。
- ArrayDeque:
- 特点:
- 功能灵活:提供了专门的栈操作方法(
push()头部添加、pop()头部删除)和队列操作方法(offer()尾部添加、poll()头部删除)。 - 非线程安全,并发场景下需使用
LinkedBlockingDeque。
- 功能灵活:提供了专门的栈操作方法(
五、Map
Map 接口是独立于 Collection 的另一种集合类型,用于存储键值对(key-value) 数据,其中键(key)唯一(不允许重复),值(value)可重复。键与值一一对应,通过键可快速查找值。常用实现类包括 HashMap、Hashtable、LinkedHashMap、TreeMap。
1、HashMap
- 底层结构:JDK 1.8 及以后基于数组 + 链表 + 红黑树实现(数组为主体,链表用于解决哈希冲突,当链表长度超过 8 且数组容量 ≥ 64 时,链表转为红黑树;当红黑树节点数少于 6 时,转回链表)。
- 特点:
- 无序性:不保证键值对的存储顺序与插入顺序一致。
- 线程不安全:多线程环境下并发修改可能导致数据不一致(如扩容时的死循环)。
- 允许 null 键和 null 值(仅允许一个 null 键,多个 null 值)。
- 扩容机制:默认初始容量为 16,负载因子为 0.75(当元素数量超过容量 × 负载因子时,触发扩容),扩容后容量为原来的 2 倍。
- 查找效率高:哈希函数均匀时,查询、添加、删除操作的时间复杂度接近 O (1)。
相关源码分析:HashMap中get()、put()详解_idear中outmap.get()-CSDN博客
2、Hashtable
- 底层结构:基于数组 + 链表实现(JDK 1.8 后未引入红黑树优化),是早期的哈希表实现。
- 特点:
- 线程安全:所有方法通过
synchronized修饰,支持多线程并发访问,但效率较低(锁粒度大)。 - 不允许 null 键和 null 值(添加 null 会抛出
NullPointerException)。 - 扩容机制:默认初始容量为 11,负载因子为 0.75,扩容后容量为原来的 2 倍 + 1。
- 已被淘汰:因性能问题,多线程场景下建议使用
ConcurrentHashMap(分段锁机制,效率更高)。
- 线程安全:所有方法通过
3、LinkedHashMap
- 底层结构:继承自 HashMap,在其基础上通过双向链表维护键值对的插入顺序或访问顺序(即有序性)。
- 特点:
- 有序性:
- 默认按插入顺序存储(键值对的迭代顺序与插入顺序一致)。
- 若构造时指定
accessOrder = true,则按访问顺序排序(最近访问的键值对移至链表尾部),可用于实现 LRU(最近最少使用)缓存。
- 其他特性与 HashMap 一致:允许 null 键值、线程不安全、底层哈希表结构等。
- 性能略低于 HashMap(因需维护链表),但迭代效率更高(无需遍历整个哈希数组)。
- 有序性:
4、TreeMap
- 底层结构:基于红黑树(自平衡二叉搜索树)实现,键值对按 key 的排序规则存储。
- 特点:
- 有序性:按 key 的排序规则(自然排序或定制排序)维护键值对的顺序,迭代时按排序后的 key 顺序输出。
- 自然排序:key 需实现
Comparable接口,通过compareTo()定义排序规则。 - 定制排序:创建时传入
Comparator接口实现类,指定排序规则。
- 自然排序:key 需实现
- 不允许 null 键(若为自然排序,添加 null 会抛出
NullPointerException;定制排序若支持 null 则可添加),允许 null 值。 - 线程不安全:多线程环境下需手动同步(如使用
Collections.synchronizedSortedMap())。 - 查找、添加、删除操作的时间复杂度为 O (log n)(红黑树特性),适合需要按 key 排序的场景。
- 有序性:按 key 的排序规则(自然排序或定制排序)维护键值对的顺序,迭代时按排序后的 key 顺序输出。
5、ConcurrentHashMap
JDK 1.8 及以后的底层结构
- 数组 + 链表 + 红黑树:
- 数组(Node [])是主体结构,每个位置存储链表头节点或红黑树根节点。
- 链表:当发生哈希冲突时,元素通过链表连接;若链表长度超过 8 且数组容量 ≥ 64,链表转换为红黑树。
- 红黑树:当树节点数少于 6 时,自动转回链表,平衡查询与插入效率。
特点
-
线程安全:
- 使用 CAS(Compare-And-Swap)+ synchronized 实现并发控制,锁粒度为链表头节点或红黑树根节点(而非整个 Map),允许多线程同时操作不同位置的元素。
- 读操作无锁:通过 volatile 修饰 Node 节点的 value 和 next 指针,保证可见性。
-
高效并发:
- 写操作仅对冲突位置加锁(synchronized),其他位置的读写不受影响,并发度显著高于分段锁(JDK 1.7 的 ConcurrentHashMap)。
- CAS 操作在无竞争时性能接近无锁状态,减少线程阻塞。
-
不允许 null 键值:
- 键和值均不允许为 null,否则抛出
NullPointerException(与 HashMap 不同),设计目的是避免多线程环境下对 null 值的歧义(无法区分 “值不存在” 与 “值为 null”)。
- 键和值均不允许为 null,否则抛出
-
弱一致性迭代器:
- 迭代器创建后,允许其他线程修改 Map,迭代器不会抛出
ConcurrentModificationException,但可能反映部分修改结果(弱一致性)。
- 迭代器创建后,允许其他线程修改 Map,迭代器不会抛出
扩容机制
-
触发条件:
- 元素数量超过 容量 × 负载因子(默认 0.75)。
- 链表长度超过 8 且数组容量不足 64 时,优先扩容而非转红黑树。
-
并行扩容:
- 扩容时创建新数组(原容量的 2 倍),多线程可协助迁移元素(每个线程负责一段连续的桶位置)。
- 迁移过程中,原数组和新数组并存,读操作优先访问新数组,写操作会同时更新新旧数组。
原子操作
- 复合操作原子性:
putIfAbsent(K key, V value):若 key 不存在则插入,返回 null;存在则返回原值(原子性插入)。remove(Object key, Object value):仅当 key 的值等于 value 时删除(避免误删)。replace(K key, V oldValue, V newValue):仅当 key 的值等于 oldValue 时替换为 newValue。
ConcurrentMap
ConcurrentHashMap 是 ConcurrentMap 最核心的实现类,也是 JDK 中并发场景下的首选 Map
ConcurrentMap 是 Java 集合框架中 java.util.concurrent 包下的一个接口,它继承自 Map 接口,专门设计用于多线程并发场景,提供了线程安全的操作方法,同时避免了传统线程安全 Map(如 Hashtable)的全表锁低效问题,是高并发环境下 Map 操作的首选。
核心特点
- 线程安全:所有方法都通过特定机制保证多线程并发操作的安全性,避免了 HashMap 并发修改时可能出现的
ConcurrentModificationException。 - 高效并发:摒弃了 Hashtable 的 “全表锁”(对整个 Map 加锁),采用更细粒度的锁或无锁机制(如 CAS),允许多个线程同时读写,并发性能大幅提升。
- 原子操作:定义了一系列原子性的复合操作(如
putIfAbsent、remove带条件删除等),避免多线程下的竞态条件。