互联网金融项目实战(大数据Hadoop hive)
一个SQL作业
一、大数据技术相关介绍
什么是互联网金融?
互联网金融 --> 信贷(信用贷款) --> 支付宝率先搞了一个信用体系
互联网金融: 在线支付、P2P
银行: 只会锦上添画、不喜欢雪中送炭
银行害怕出现坏账 ( 储户存钱,银行放贷 赚个利息差 ) 银行是可以倒闭的 保险公司不允许倒闭
银行分为:商业银行(自生自灭的)和非商业银行(国家的) 中国工商银行 全球第一大行 招商银行(清朝的一个李鸿章) 中国银行(历史超过 100 年了)
国家政策:希望银行能够扶持中小型企业
p2p:网络借贷平台 民间吸纳贷款 --> 互联网养猪(琼猪)
支付宝(花呗、借呗)、京东金融、360借贷、百度有钱花… (拉手 Bank–>金手指)
高利贷:利息—> 创新(电子版的)–> 纳斯达克股票交易所的前身 --> 麦道夫三界主席
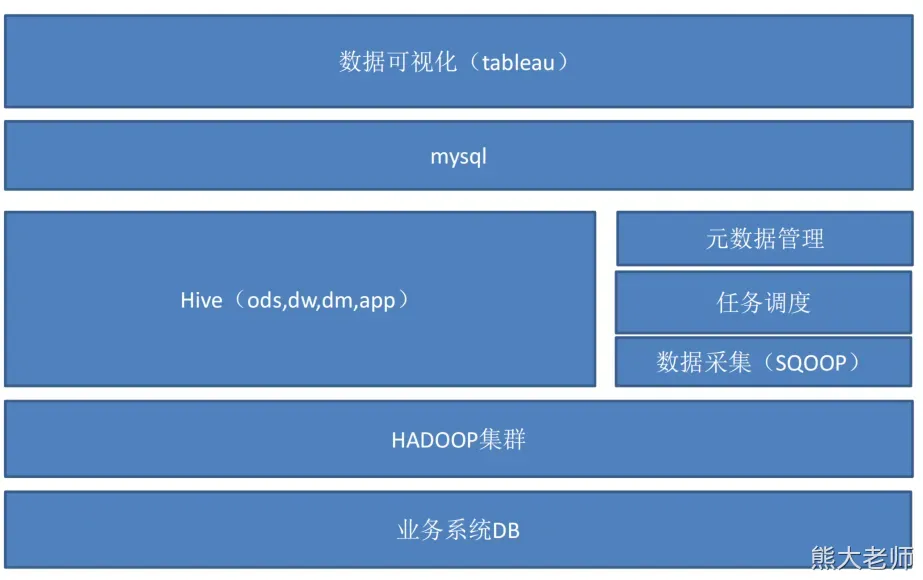
数据仓库介绍
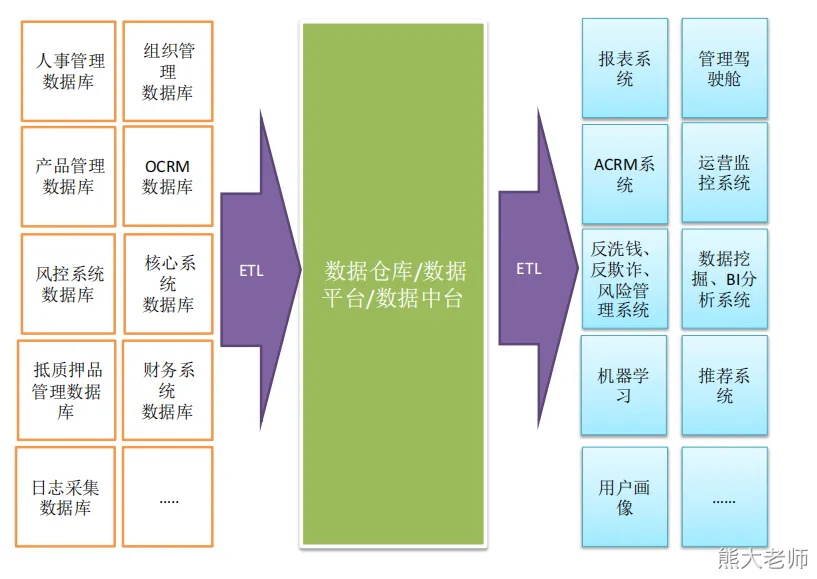
企业数据流转与技术组件关系
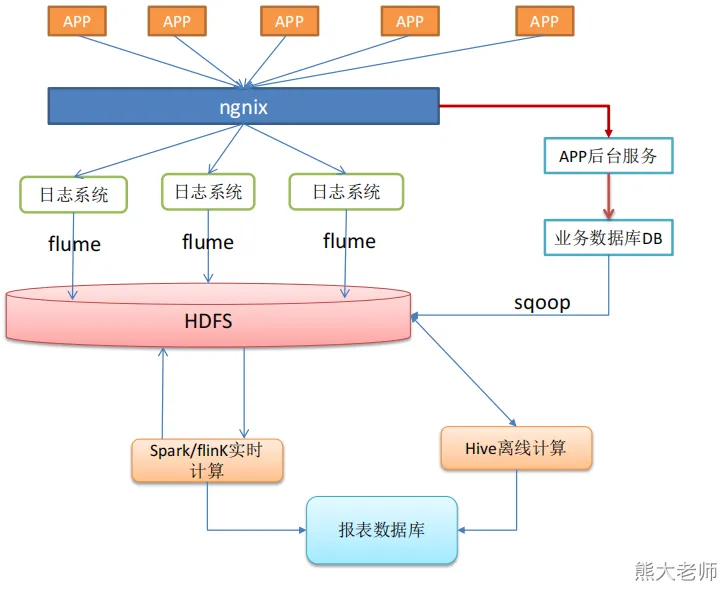
技术选型
技术选型考虑因素:数据量大小,业务需求,行业内经验,技术成熟度,开发
维护成本,总成本预算
数据采集: flume,kafka, sqoop,logstach , datax
数据存储: mysql,hdfs,hbase,redis,elasticSearch,kudu,mongodb ,doris
数据计算: hive ,tez ,spark ,flink,storm
数据查询: presto,kylin,impala,druid,clickhouse
数据可视化: echarts,superset,quickbI,dataV , 达芬奇、帆软 、powbi
任务调度: azkaban,airflow,Oozie 、dolphinScheduler
集群监控: zabbix
元数据管理: atlas 【数据治理工具】
权限管理: ranger
二、企业背景和关键数据需求
神策数据
https://www.sensorsdata.cn/
企业背景
行业:互联网金融行业
产品:信贷,理财
推广渠道:线下、线上、第三方合作。
支付宝 --> 余额宝
上海的一个老板 --> 拉手 Bank --> 只有一个界面 随进随出,年化 12% --> 三四个月的时间上市了 --> 林志颖
互联网金融牌照
关键性数据需求:信贷方向
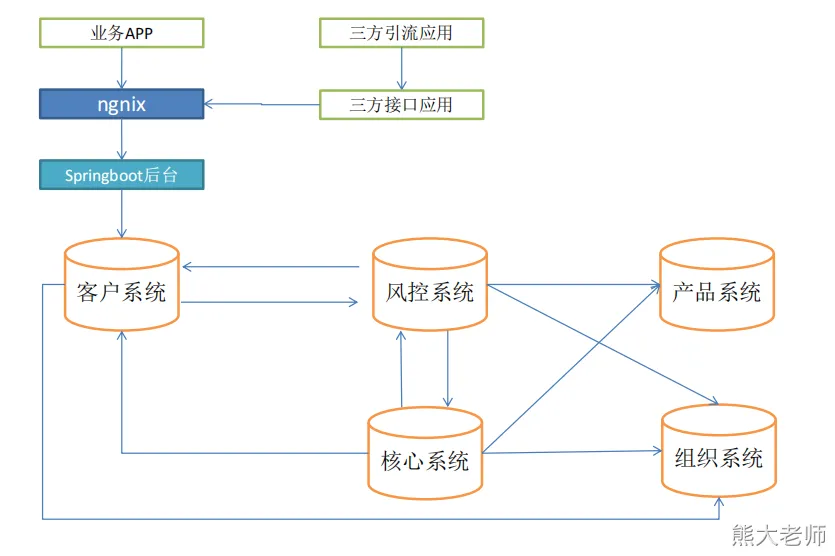
1、客户信息采集系统、风控系统、核心放款系统、产品、组织管理等系统的数据,进行整合;
2、客户主题进行分析:客户结构、客户质量,客户转换率
3、经营效率的分析:
4、风险主题分析:风险,逾期率,产品的违约率,
5、财务主题分析:贡献率
6、数据可视化,通报报表或大屏形式展现给管理者
数据采集到数据仓库(只来自于数据库数据)–> 分析的主题有:用户主题 、经营主题 、风险主题、财务主题 --> 可视化展示
数据来源大概分为三类:
1、业务数据(数据库数据)
2、日志数据 (一般都是用户的行为)
3、第三方数据(买的 、爬的 、给的)
项目需求
1、采集业务数据,包含用户管理、风险管理、核心系统等;
2、数据仓库维度建模;
3、分析用户注册、授信申请、风险审核、放款、还款、逾期等核心业务活动, 完成指标统计计算
4、采用即席查询工具,随时对数据指标进行分析;
5、对集群性能进行监控,发现任务处理异常及时告警;
6、元数据管理;
7、质量监控;
8、数据可视化
三、数据仓库项目流程
项目流程
软件行业也是一个工程 --> 软件工程 --> 工程管理类的(MEM 工程管理) --> 软考(高项)[PMP 证书 ]
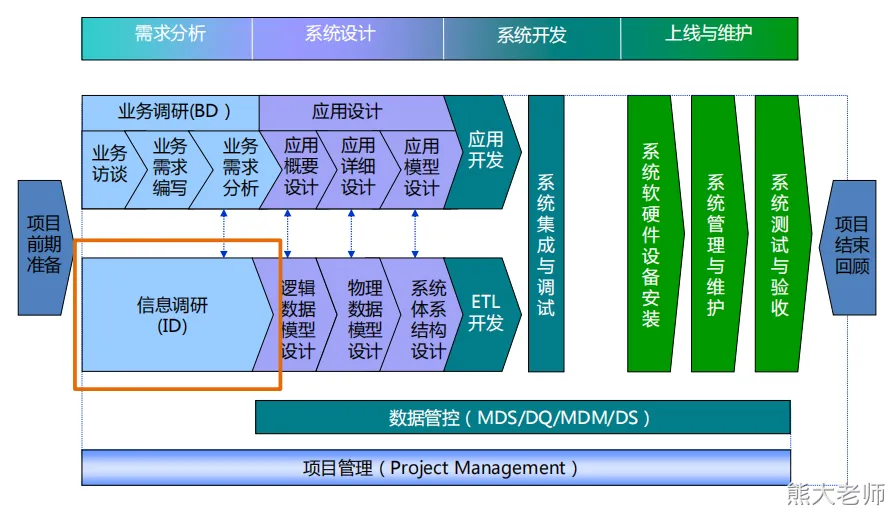
项目角色划分
需求组:调研业务需求
调研组:参与业务调研,进行数据调研,摸清数据的现状
架构组:数据架构,技术架构,集成环境搭建与安装
研发组:ETL的设计、调度任务关系设计,报表设计,报表开展
技术部、研发部
测试组:测试数据,测试报表结构是否与预期一致
项目经理:全权负责整个项目的推进,资源协调,阶段性汇报等;
**在一个项目组中,一个人可能会同时兼任多个角色
业务调研
- 业务访问
1、业务系统之间的交互关系,数据传递关系?
2、业务流程?业务方最关注的流程节点有哪些?
3、业务的组织架构?未来会有什么变化?
4、各业务部门的需求有哪些?
- 业务系统关系
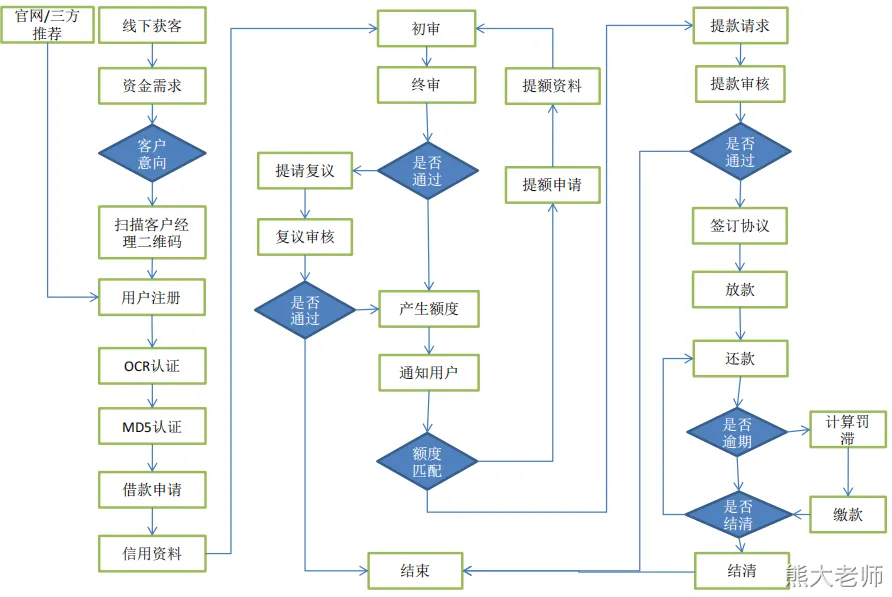
- 业务流程图
征信系统:国家系统,每个人的信息都在里面。 征信拉黑 --> 黑户
- 业务流程关键节点
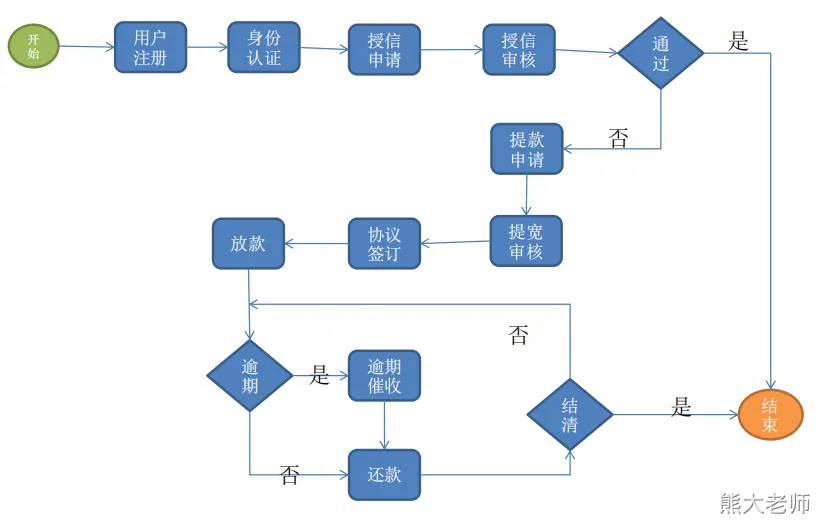
数据调研
系统概要整理
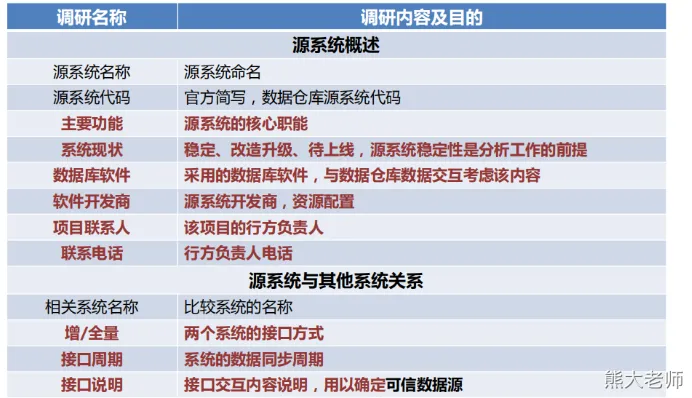
该部分关注的核心:
【0级】系统是干嘛的(在业务流程中位置,是否需要数仓加入)
【0级】什么数据库软件(影响最终技术架构的设计)
【0级】负责人是谁(详细的表元数据信息要找谁了解)
【1级】系统现状(有没有下线等变化,避免白干)
【1级】相关交互系统(可能会有重复的表和字段,但命名不一致)
表级信息整理
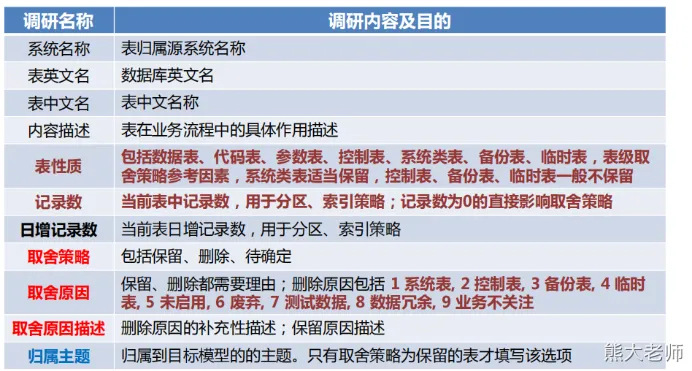
该部分关注的核心:
【0级】表的具体业务功能(表的核心属性信息)
【0级】表的性质(判断事实表、维表的基础依据)
【1级】日增记录数(与计算资源和数据时效相关)
【1级】归属主题(粗略的该表应该属于什么主题)
字段级信息整理1
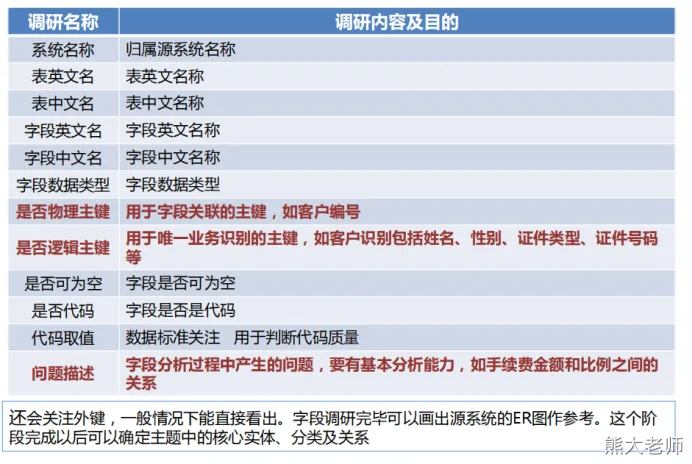
字段级信息整理2
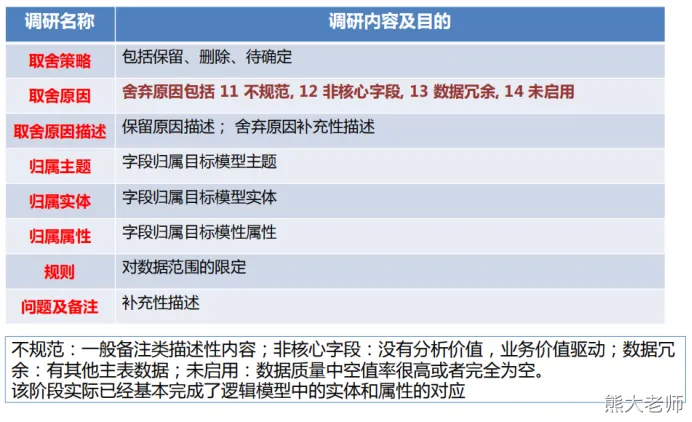
系统代码整理(编码)
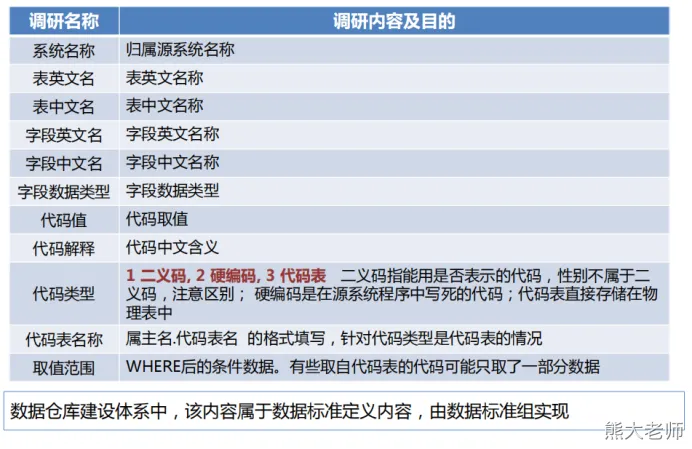
调研模板和实操
《系统概要分析.xls 》 、《系统数据结构整理.xls 》
《系统事件分析.xls 》 、《标准化代码.xlsx》
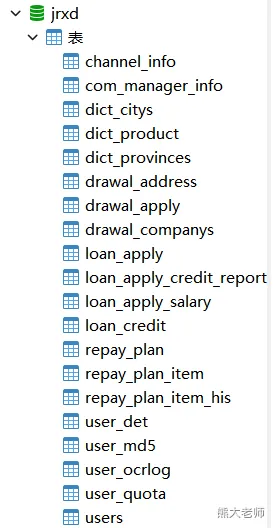
本次数据的表结构及其含义
《数据库表结构.xlsx》
四、数据仓库架构
架构组—数据仓库分层
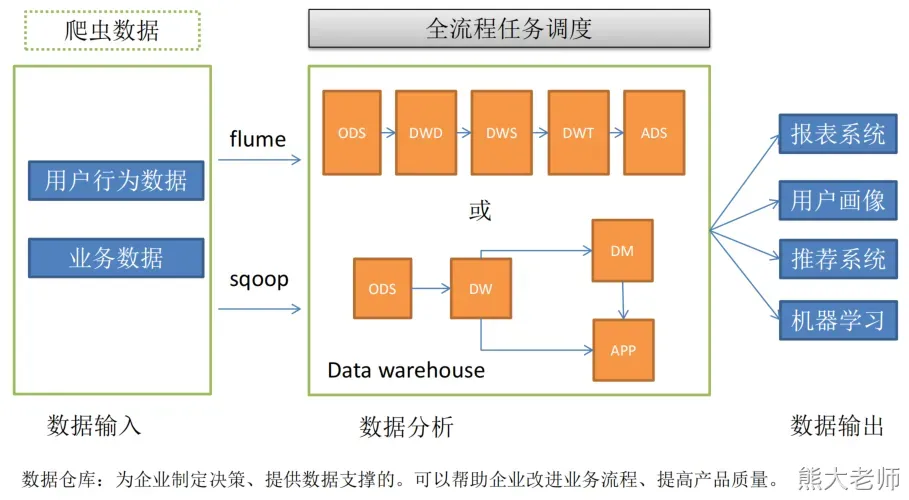
数据仓库分层目的
1、清晰的数据结构:每一层的作用不一样,目的是为了更好的定位和理解数据
2、方便数据血缘追踪,减少重复性的开发:三个不同的需求,都需要从5张表获取数据,都需求进行清洗和转换。
3、把复杂问题简单化
4、维护方便
数据仓库如何分层
ODS层:Operate data store,贴源层(原始数据层、操作数据层)
该层数据最接近原生(原始)数据源
ODS层数据来源:业务库,埋点数据,消息队列、接口数据
与业务库表结构一致,表名可以换,但是一般情况下会在原业务库表名前面添加库前缀,或自定义前缀。
ODS层采用建设方式原则:直接采集业务数据,不做转换处理,数据保留时间根据业务具体确定。
全量采集,第二天再次全量采集,前一天的数据不保留。
优化:大表做增量
DWD层:Data WareHouse Detail 数据明细层
数据来源:只能是ODS层
建设方式:根据ODS层数据按主题性进行归类建模。
DWD,主要是将从业务数据库中同步过来的ODS层数据进行清洗和整合成相应的事实表。事实表作为数据仓库维度建模的核心,需要紧紧围绕着业务过程来设计。在拿到业务系统的表结构后,进行大概的梳理,再与业务方沟通整个业务过程的流转过程,对业务的整个生命周期进行分析,明确关键的业务步骤,在能满足业务需求的前提下,尽可能设计出更通用的模型。
四个基本概念:维度,事实,指标(度量),粒度。
逾期一期的客户表现:逾期金额,(客户、产品、组织,时间)
客户注册事实表:一条客户注册记录就是一个事实,指标,客户注册量。
Dim层: Dimension 维度层
DIM(Dimension)层是数据仓库的关键组成部分之一,它主要负责存储维度数据和规则,使数据仓库中的数据更易于理解和分析。
DWS层:Data WareHouse Servce 数据服务层(数据汇总层)
对明细数据进行预加工,汇总,与关联,建立多维立方体的数据量,提高查询效率。
ADS层:Application Data Store 数据应用层
服务于终端用户,高度汇总。DWD:一张事实表有20个维度,5个指标,DWS层就可能:10个维度,5个指标,APP层:3个维度,5个指标,
五、数据开发规范
数据仓库建表命名规范
ODS层命名规范:源库库名+表名 例如: 库名:jrxd,表名:user_det
表名:ods_jrxd_user_det
DwD层:dwd_fact_主题_table_name; 例如:dwd_fact_cus_regeste_detail
Dim层:dim_table_name 例如:dim_product
DWS层:dws_fact_集市名_table_name 例如: dm_fact_risk_cus_first_overdue
ads 层: ads_fact_table_name字段定义原则
相同的数据属性,如果在不同的表中出现,则应采取相同的字段名、数据类型、数据长度,数据精度;
数字类型的数据必须为整数或浮点数,金额类型数据必须为浮点数
日期类型的数据:同一个字段的值其格式必须统一
YYYY-MM-DD YYYY/MM/DD
字段命名:要么都是英文,要么都是中文拼音缩写。
六、ods层数据开发
业务数据库
可以先在 mysql 创建数据库 jrxd ,也可以直接导入 sql 语句
假如你没有 mysql 客户端软件,或者觉得软件导入比较慢,可以使用 source 命令 [ 先进入 mysql]
source jrxd.sql
sqoop导入业务库数据到ODS层
可以使用 Sqoop、DataX、Kettle
ods层
1)create database ods; 方式1:创建名字叫做ods的数据库,作为ods层,该库下的表都属于ods层
2)ods_xxxx 方式2:创建一个数据库,表名添加前缀ods 【采用第二种方式】
ods_业务数据库名字_mysql表名:例如 mysql中jrxd库下的users,那么导入到hive之后对应的表名 ods_jrxd_users
另一家公司的命名规则
1 数据库命名
命名规则:数仓对应分层_{业务线|业务项目}
命名示例:ods_nshop/dwd_nshop/dws_nshop/dim_nshop/ads_nshop/业务线:新业务,跟之前的业务区别很大。2 数仓各层对应数据库
ods/sda层 -> sda/ods_{业务线|业务项目}(原始数据)
dm层 -> dwd_{业务线|业务项目} (主题) + dws_{业务线|业务项目}(基于主题宽表汇总)
dim层 -> dim_维度 (维表库)
ads层 -> ads_{业务线|业务项目} (应用统计指标等)
middle层 -> mid_{业务线|业务项目}(中间库)
临时数据 -> temp_{业务线|业务项目}(临时库)3 表命名
(3-1) 数据库表命名规则
* 原始数据层(贴源层):
命名规则:ods_{业务线|业务项目}_{数据来源类型}_{业务}
ods_{业务线|业务项目}_{数据来源类型}_{业务}_{时间粒度}_delta (delta代表增量,主要用于数据同步方向产生的原始数据表)
命名示例:
ods_nshop_01_useractlog XX用户日志原始数据表
ods_nshop_02_user XX用户表(全量)
ods_nshop_02_user_delta XX用户表(增量)
ods_nshop_02_user_hh_delta XX用户表(小时级增量 dd天)
* 主题/事实数据层:
命名规则:dwd_{业务线|业务项目}_{主题域}_{子业务}
命名示例:
dwd_nshop_user_logproview XX用户产品浏览日志事实表
dwd_nshop_user_comment XX用户关注事实表
* 主题/事实汇总层:
命名规则:dws_{业务线|业务项目}_{主题域}_{汇总相关粒度}_{汇总时间周期}
命名示例:
dws_nshop_user_order_nd XX用户订单汇总N天统计表
dws_nshop_user_cmtpro_nd XX用户产品关注汇总N天统计表* 维表层:
命名规则:dim_{业务线|业务项目|pub公共}_{维度}
命名示例:
dim_pub_date 时间维表
dim_pub_area 地区维表
dim_pub_category 商品分类* 集市层(指标):
命名规则:ads_{业务线|业务项目}_{统计业务}_{报表form|热门排序topN}
命名示例:
ads_nshop_order_form 订单统计表
ads_nshop_orderpay_form 订单支付统计
ads_nshop_orderpay_top10注释:如果业务名称较长可以简写 如 ods_nshop_01_useractlog数据来源代码(ods层) 码表
01 -> hdfs数据 ods_nshop.ods_01_action_log 行为日志表
02 -> mysql数据 ods_nshop.ods_02_user 用户表
03 -> redis数据
04 -> mongodb数据
05 -> tidb数据在开发过程中有一个名字:约定大于配置
java代码有个规范: 阿里巴巴java规范采集数据:
- 在hive中创建一个数据库: create database finance;
使用 sqoop 将其中一个表导入 hive:
sqoop import --connect jdbc:mysql://shucang:3306/jrxd \
--driver com.mysql.cj.jdbc.Driver \
--username root \
--password 123456 \
--table channel_info \
--hive-import \
--hive-overwrite \
--hive-table ods_channel_info \
--hive-database finance \
-m 1执行报错:
Caused by: java.lang.ClassNotFoundException: org.apache.commons.lang.StringEscapeUtilsat java.net.URLClassLoader.findClass(URLClassLoader.java:381)at java.lang.ClassLoader.loadClass(ClassLoader.java:424)at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)at java.lang.ClassLoader.loadClass(ClassLoader.java:357)... 13 more
解决办法:
cp /opt/installs/hive/lib/commons-lang-2.6.jar /opt/installs/sqoop/lib/
假如出现如下错误:
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConfat java.net.URLClassLoader.findClass(URLClassLoader.java:381)at java.lang.ClassLoader.loadClass(ClassLoader.java:424)at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)at java.lang.ClassLoader.loadClass(ClassLoader.java:357)at java.lang.Class.forName0(Native Method)
解决办法
cp /opt/installs/hive/lib/hive-common-3.1.2.jar /opt/installs/sqoop/lib/
报错:
2024-09-19 15:38:09,650 ERROR tool.ImportTool: Import failed: org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://shucang:9820/user/root/channel_info already exists
解决方案:
hdfs dfs -rm -R /user/root/channel_info
假如我导入表的时候,表中的一个日期字段是 0000-00-00 00:00:00 就会报错
比如 这个表 user_quota、dict_provinces
报如下错误:
Caused by: java.sql.SQLException: Zero date value prohibitedat com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:129)at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:97)at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:89)at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:63)at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:73)at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:99)at com.mysql.cj.jdbc.result.ResultSetImpl.getTimestamp(ResultSetImpl.java:939)at org.apache.sqoop.lib.JdbcWritableBridge.readTimestamp(JdbcWritableBridge.java:111)at com.cloudera.sqoop.lib.JdbcWritableBridge.readTimestamp(JdbcWritableBridge.java:83)at user_quota.readFields(user_quota.java:307)at org.apache.sqoop.mapreduce.db.DBRecordReader.nextKeyValue(DBRecordReader.java:244)... 12 more
导致三个表导入失败:
在提取数据到hive中遇到一个错误,java.sql.SQLException: Zero date value prohibited.
更改了脚本内容,加了一句话:zeroDateTimeBehavior=convertToNull于是命令变为:
sqoop import --connect jdbc:mysql://shucang:3306/jrxd?zeroDateTimeBehavior=convertToNull \
--driver com.mysql.cj.jdbc.Driver \
--username root \
--password 123456 \
--table user_quota \
--hive-import \
--hive-overwrite \
--hive-table ods_user_quota \
--hive-database finance \
-m 1
以上错误解决代表了相当一部分错误已经被解决掉了,我可以可以使用脚本:
#!/bin/bash
while read x1
doecho $x1
done < /root/tables.txt
sqoop_imoprt_finance.sh2) 编写sqoop脚本,完成数据导入hive数仓
在mysql数据库,查询jrxd下的所有表名,复制到/root/tables.txt文件中
select table_name from information_schema.`TABLES` where table_schema = 'jrxd'
在linux上编写sqoop脚本,完成数据导入hive
#按行读取tables.txt文件中表名
#完成这些的表全量导入
#hive-overwrite ods层导入数据的时候会覆盖之前的数据,ods层只保留最新一天的数据tables.txtchannel_info
com_manager_info
dict_citys
dict_product
dict_provinces
drawal_address
drawal_apply
drawal_companys
loan_apply
loan_apply_credit_report
loan_apply_salary
loan_credit
repay_plan
repay_plan_item
repay_plan_item_his
user_det
user_md5
user_ocrlog
user_quota
users编写脚本:
在home目录下,创建目录
mkdir scripts
cd scripts编写脚本: import.sh
指定权限:chmod 777 import.sh#!/bin/bash
while read x1
dosqoop import --connect jdbc:mysql://shucang:3306/jrxd?zeroDateTimeBehavior=convertToNull \--driver com.mysql.cj.jdbc.Driver \--username root \--password 123456 \--table $x1 \--hive-import \--hive-overwrite \--hive-table ods_$x1 \--hive-database finance \--null-non-string '\\N' \--null-string '\\N' \-m 1
done < /root/tables.txt
七、数据仓库建模
范式建模
- 范式建模-概念与特点
在数据仓库中采取范式建模法,主要由Inmon 所提倡,核心是为解决关系型数据库中数据存储,而利用的一种技术层面上的方法。
目前,我们在关系型数据库中的建模方法,大部分采用的是三范式建模法。
在数据仓库的模型设计中,如果采取范式建模法,一般也要遵从第三范式。
一个符合第三范式的关系必须具有以下三个条件 :
每个属性值唯一,不具有多义性 ;
每个非主属性必须完全依赖于整个主键,而非主键的一部分 ;
每个非主属性不能依赖于其他关系中的属性,因为这样的话,这种属性应该归到其他关系中去。
2) 范式建模-案例
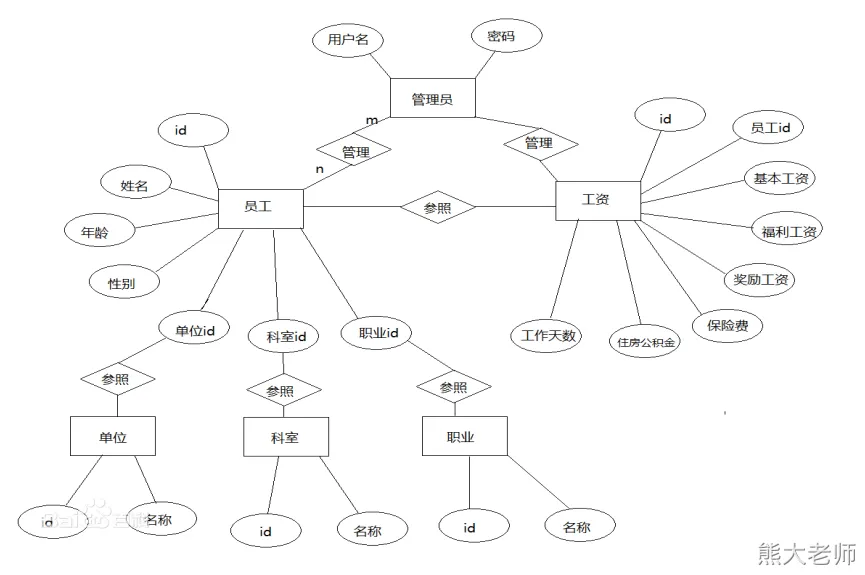
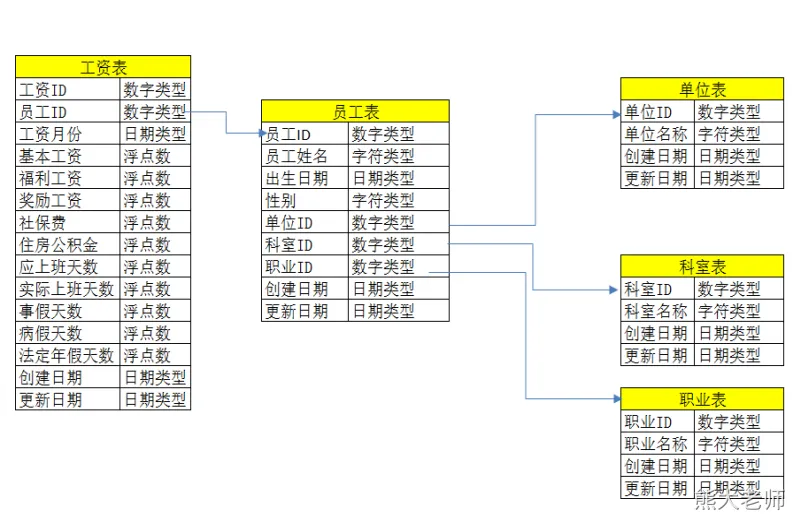
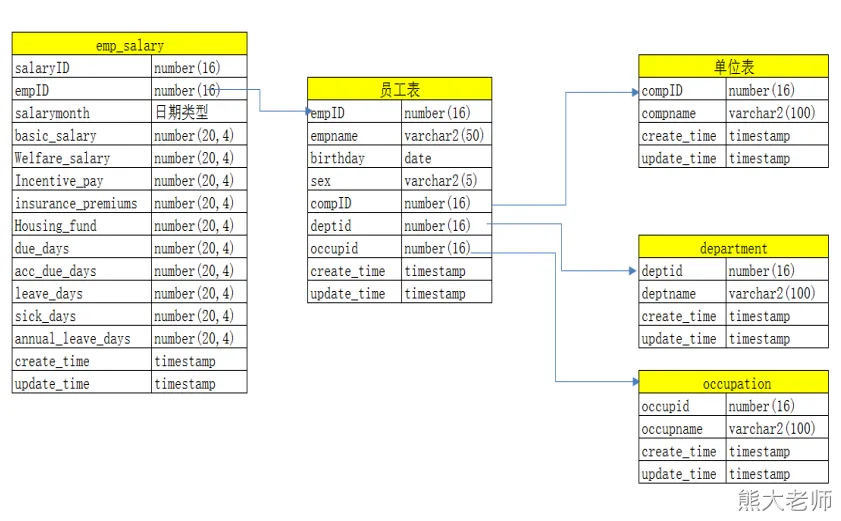
维度建模(dimensional modeling)
专门用于分析型数据库、数据仓库、数据集市建模的方法。
它本身属于一种关系建模方法,但和之前在操作型数据库中介绍的关系建模方法相比增加了两个概念:
1. 维度表(dimension)
表示对分析主题所属类型的描述。
2. 事实表(fact table)
表示对分析主题的度量。
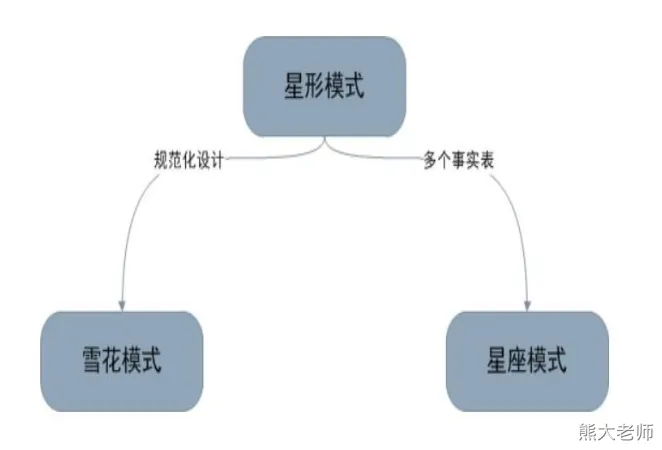
维度建模—星型模型
星型模式是以事实表为中心,所有的维度表直接连接在事实表上,像星星一样。
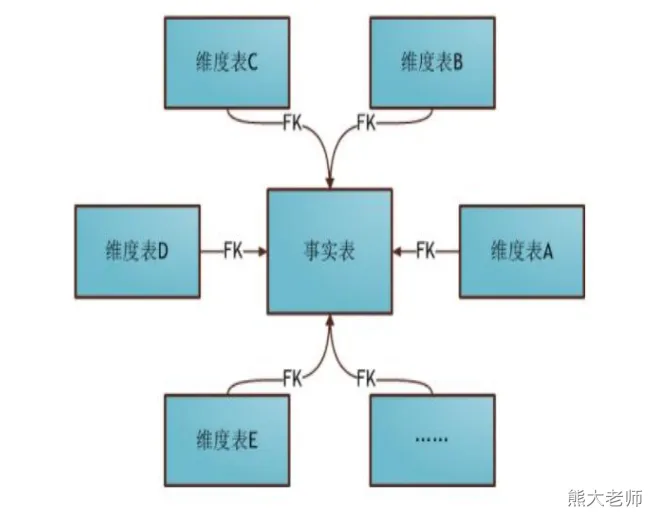
维度建模—雪花模型
雪花模式的维度表可以拥有其他维度表的,虽然这种模型相比星型更规范一些,但是由于这种模型不太容易理解,维护成本比较高,而且性能方面需要关联多层维表,性能也比星型模型要低。所以一般不是很常用。
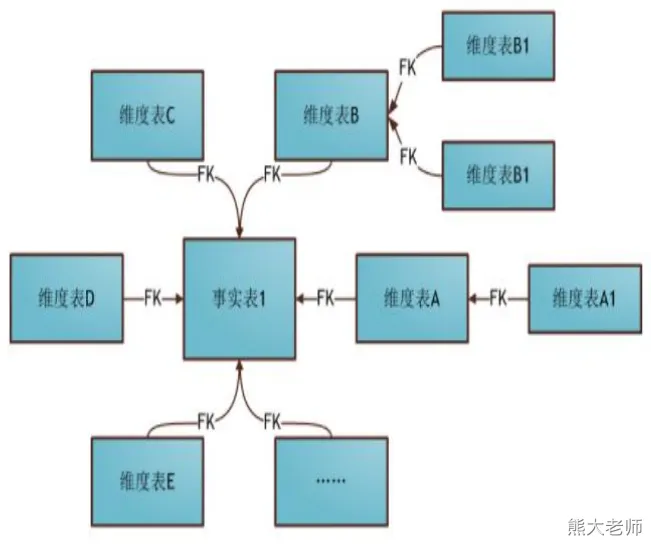
维度建模—星座模型
星座模式是星型模式延伸而来,星型模式是基于一张事实表的,而星座模式是基于多张事实表的,而且共享维度信息。
前面介绍的两种维度建模方法都是多维表对应单事实表,但在很多时候维度空间内的事实表不止一个,而一个维表也可能被多个事实表用到。
在业务发展后期,绝大部分维度建模都采用的是星座模式。
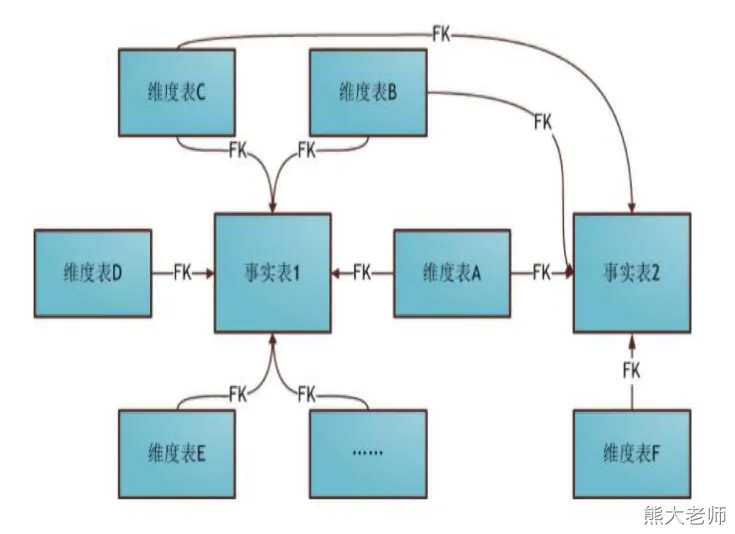
三种模型之间的关系
维度建模过程
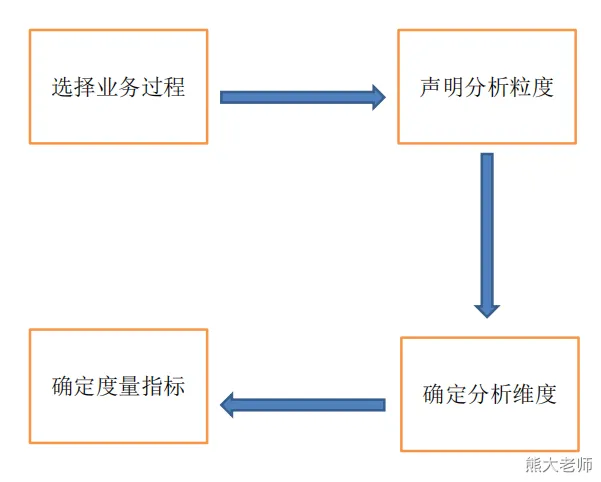
第一步 选取业务处理
业务处理过程是组织机构中进行的一般都由源系统提供支持的[自然业务活动]。
要记住的重要一点是,这里谈到的业务处理过程并不是指业务部门或者职能。第二步 定义粒度
粒度定义意味着对各事实表行实际代表的内容给出明确的说明。
粒度传递了同事实表度量值相联系的细节所达到的程度方面的信息。它给出了后面这个问题的答案:“如何描述事实表的单个行?”。
粒度定义是不容轻视的至关重要的步骤。
在定义粒度时应优先考虑为业务处理获取最有原子性的信息而开发维度模型。
原子型数据是所收集的最详细的信息,是高维度结构化的。
度量值越细微并具有原子性,就越能够确切地知道更多的事情。
原子型数据可为分析方面提供最大限度的灵活性,维度模型的细节性数据是稳如泰山的,并随时准备接受业务用户的特殊攻击。第三步 选定维度
维度所引出的问题是,“业务人员将如何描述从业务处理过程得到的数据?”
应该用一组在每个度量上下文中取单一值而代表了所有可能情况的丰富描述,将事实表装扮起来。
常见维度的例子包括日期、产品、客户、账户和机构等。第四步 确定事实(度量指标)
事实的确定可以通过回答“要对什么内容进行评测”这个问题来进行。
1、针对某个特定的行为动作,建立一个以行为活动最小单元为粒度的事实表。
2、针对某个实体对象在当前时间上的状况。我们通过对这个实体对象在不同阶段存储它的快照。
3、针对业务活动中的重要分析和跟踪对象,统计在整个企业不同业务活动中的发生情况。八、用户注册
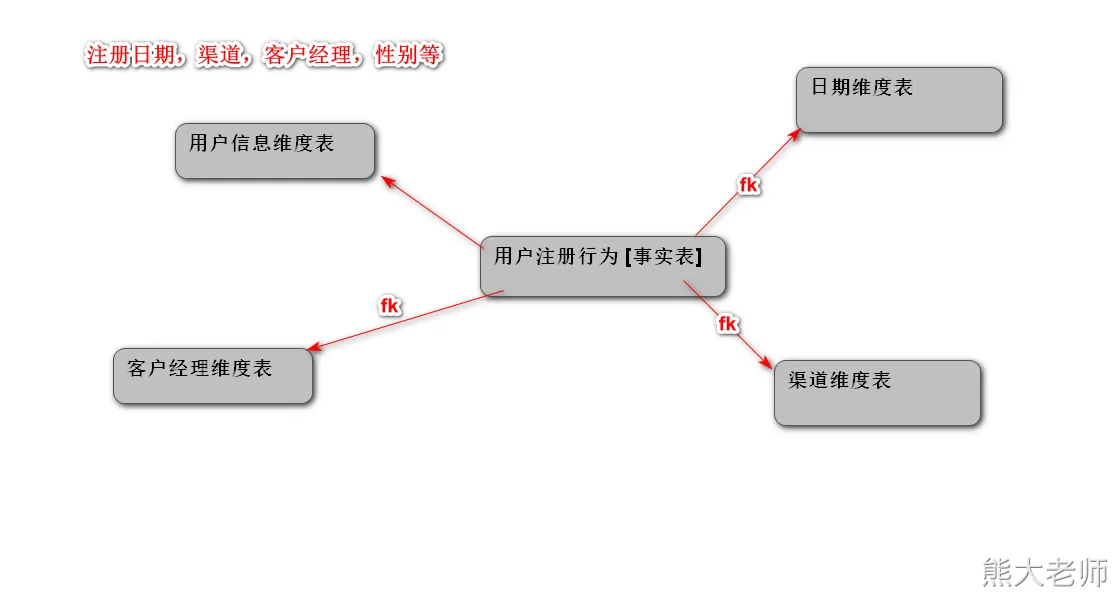
维度建模与开发—用户注册
需求:统计客户的注册行为
统计指标:注册量,OCR认证量,MD5申请量,MD5通过量
分析维度:注册日期,渠道,客户经理,性别等
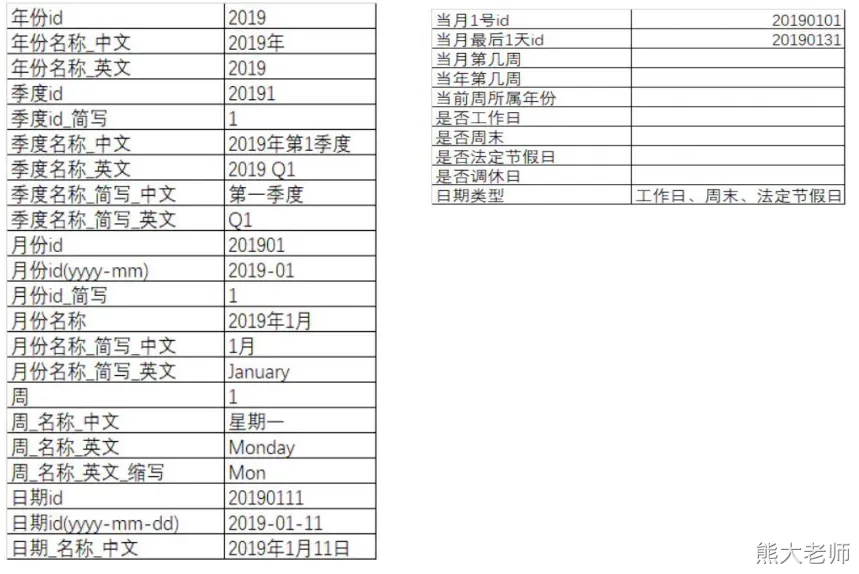
1)日期维度表
某个日期是否是法定节假日你是怎么做的?
自定义一个 hive 的函数,我在代码中将一个日期传递给一个 API 接口(付费),接口返回是否为节假日,我再返回给函数。当然超过今年的查不了。【国务院颁布的】
作用举例:

create table dim_calendar(dateid string,date_desc string,day_of_month string,day_of_month_desc string,day_of_year string,day_of_year_desc string,week_of_year string,week_of_year_desc string,month_of_year string,month_of_year_desc string,monthid string,month_desc string,yearid string,year_desc string,quarterid string,quarter_desc string,quarter_of_year string,quarter_of_year_desc string,create_time string,update_time string,etl_time string
) comment '日期维度表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n';with dates as (select date_add("2019-01-01", a.pos) as dfrom ( select posexplode(split(repeat("o",datediff("2020-12-31", "2019-01-01")),"o"))) a
)
insert overwrite table dim_calendar
select
from_unixtime(unix_timestamp(d,'yyyy-MM-dd'),'yyyyMMdd') as dateid
,d as date_desc
,day(d) as day_of_month
,concat(year(d),'年',month(d),'月第',day(d),'天') as day_of_month_desc
,datediff(d,concat(year(d),'-01-01'))+1 as day_of_year
,concat(year(d),'年第',datediff(d,concat(year(d),'-01-01'))+1,'天') as day_of_year_desc
,weekofyear(d) as week_of_year
,concat(year(d),'年第',weekofyear(d),'周') as week_of_year_desc
,month(d) as month_of_year
,concat(year(d),'年第',month(d),'月') as month_of_year_desc
,from_unixtime(unix_timestamp(d,'yyyy-MM-dd'),'yyyyMM') as monthid
,from_unixtime(unix_timestamp(d,'yyyy-MM-dd'),'yyyy-MM') as month_desc
,year(d) as yearid
,concat(year(d),'年') as year_desc
,(case when month(d) in(1,2,3) then concat(year(d),'01')when month(d) in(4,5,6) then concat(year(d),'02')when month(d) in(7,8,9) then concat(year(d),'03')when month(d) in(10,11,12) then concat(year(d),'04')else nullend) as quarterid
,(case when month(d) in(1,2,3) then concat(year(d),'-','Q1')when month(d) in(4,5,6) then concat(year(d),'-','Q2')when month(d) in(7,8,9) then concat(year(d),'-','Q3')when month(d) in(10,11,12) then concat(year(d),'-','Q4')else nullend) as quarter_desc
,(case when month(d) in(1,2,3) then 1when month(d) in(4,5,6) then 2when month(d) in(7,8,9) then 3when month(d) in(10,11,12) then 4else nullend) as quarter_of_year
,(case when month(d) in(1,2,3) then concat(year(d),'年1季度')when month(d) in(4,5,6) then concat(year(d),'年2季度')when month(d) in(7,8,9) then concat(year(d),'年3季度')when month(d) in(10,11,12) then concat(year(d),'年4季度')else nullend) as quarter_of_year_desc
,from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss') as create_time
,from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss') as update_time
,from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss') as etl_time
from dates
order by dateid;注意:不需要粘贴看看即可
create table dim_calendar(dateid string comment '日期id',date_desc string comment '日期描述',day_of_month string comment '日期是这个月的第几天',day_of_month_desc string comment '日期是这个月的第几天描述',day_of_year string comment '日期是这个年的第几天',day_of_year_desc string comment '日期是这个年的第几天描述',week_of_year string comment '第几周',week_of_year_desc string comment '第几周描述',month_of_year string comment '第几月',month_of_year_desc string comment '第几月描述',monthid string comment '月份id',month_desc string comment '描述',yearid string comment '年id',year_desc string comment '描述',quarterid string comment '季度id',quarter_desc string comment '描述',quarter_of_year string comment '第几个季度',quarter_of_year_desc string comment '描述',create_time string comment '创建时间',update_time string comment '更新时间',etl_time string comment 'etl时间'
) comment '日期维度表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n';复习几个函数的用法:
select datediff("2020-12-31", "2019-01-01"); --730select repeat("o",datediff("2020-12-31", "2019-01-01"));
select repeat("h",5);
-- 730个空白 ""
select split(repeat("o",datediff("2020-12-31", "2019-01-01")),"o");
-- 将一个数组炸裂成两个字段 一个是下标 一个是对应的值,因为值都是 "" 所以不显示
select posexplode(split(repeat("o",datediff("2020-12-31", "2019-01-01")),"o"));
select date_add("2019-01-01", a.pos) as dfrom ( select posexplode(split(repeat("o",datediff("2020-12-31", "2019-01-01")),"o"))) a;可以搜索一下,日期维度表设计。
2)渠道维度表
– 渠道业务含义: 信贷公司,有一个岗位叫做客户经理(业务员),找人办理贷款
– 从公司的角度来说,客户经理能够多渠道(来源)拓张业务,求之不得
– 公司自己的渠道: 公司官网、公司APP
– 第三方获客平台
– 线下渠道获客
可以搜索:信贷员 10 大获客软件 指的都是第三方获客平台
开启本地模式:
set hive.exec.mode.local.auto=true;
//开启本地mr
//设置local mr的最大输入数据量,当输入数据量小于这个值时采用local mr的方式,默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=50000000;
//设置local mr的最大输入文件个数,当输入文件个数小于这个值时采用local mr的方式,默认为4
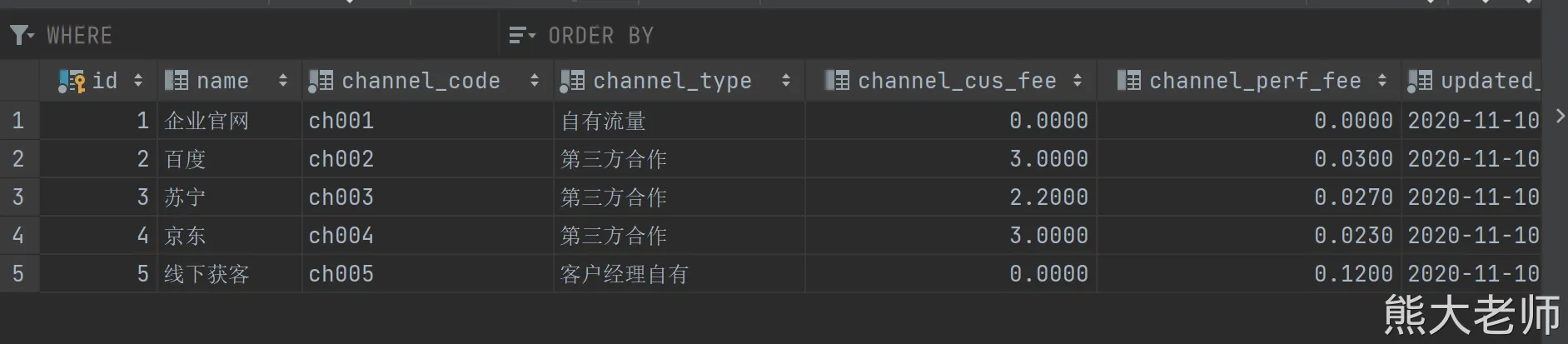
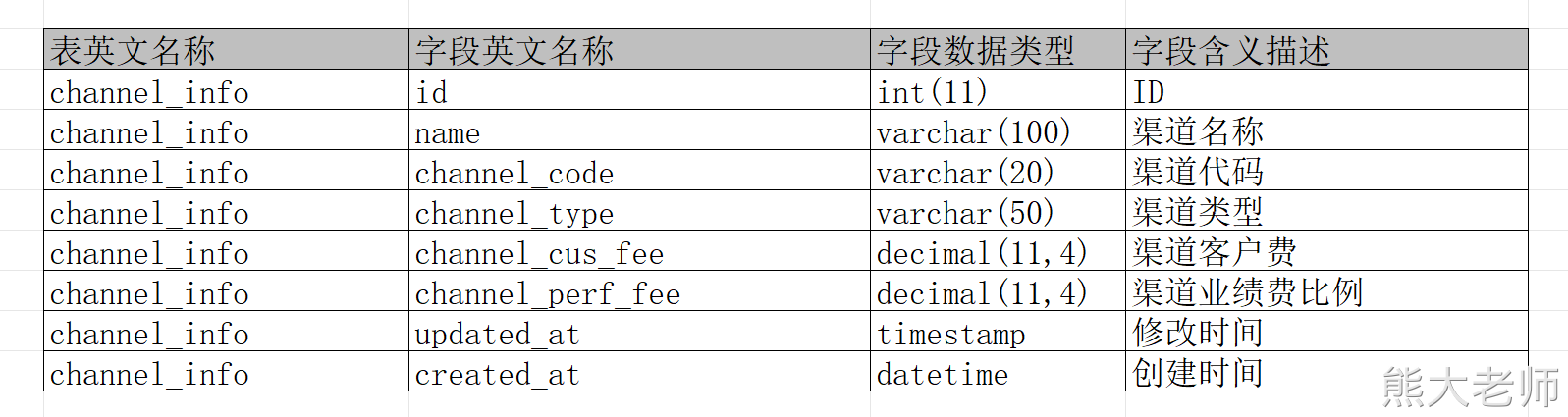
set hive.exec.mode.local.auto.input.files.max=10;create table dim_channel(id bigint,name string,channel_code string,channel_type string,channel_cus_fee string,channel_perf_fee string,created_at string,updated_at string,etl_time string
) comment '渠道维度表'
partitioned by (partition_date string comment '分区日期')
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n';-- 维度表一般不需要创建分区,此处这么搞有点鸡肋
-- 因为上面是一个分区表,下面的sql在导入的时候使用的是动态分区的方案,最后的一个字段必须是分区字段,这个规矩!!!insert overwrite table dim_channel
select
id
,name
,channel_code
,channel_type
,channel_cus_fee
,channel_perf_fee
,created_at
,updated_at
,from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss') as etl_time
,from_unixtime(unix_timestamp(),'yyyy-MM-dd') as partition_date
from ods_channel_info
- 客户经理维度表
客户经理:客户经理就是业务员。
卖房,卖保险,卖车
create table dim_com_manager(id bigint,name string,birthday string,sex string,entry_date string,con_emp_no string,is_positive string,deptname string,bank_card string,departure_date string,updated_at string,created_at string,etl_time string
)
comment '客户经理维度表'
partitioned by (partition_date string comment '分区日期')
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n';set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table dim_com_manager
select
id
,name
,birthday
,sex
,entry_date
,con_emp_no
,is_positive
,deptname
,bank_card
,departure_date
,updated_at
,created_at
,from_unixtime(unix_timestamp()+8*3600,'yyyy-MM-dd HH:mm:ss') as etl_time
,from_unixtime(unix_timestamp()+8*3600,'yyyy-MM-dd') as partition_date
from ods_com_manager_info;
select `current_date`();
select current_timestamp();
select unix_timestamp();
select from_unixtime(unix_timestamp()+8*3600,'yyyy-MM-dd HH:mm:ss');- 用户维度表
create table dim_user(user_id bigint,phone string,hash_pwd string,idty_type string,idty_id string,email string,birthday string,message_auth string,idty_photo_url string,updated_at string,created_at string,etl_time string
) comment '用户维度表'
partitioned by (partition_date string comment '分区日期')
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n';insert overwrite table dim_user
select
id as user_id
,a.phone
,a.hash_pwd
,a.idty_type
,a.idty_id
,a.email
,a.birthday
,a.message_auth
,a.idty_photo_url
,a.updated_at
,a.created_at
,from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss') as etl_time
,from_unixtime(unix_timestamp(),'yyyy-MM-dd') as partition_date
from ods_users a;- 用户注册事实表
OCR:多场景、多语种、高精度的文字检测与识别服务
https://www.ihuyi.com/api/ocr-idcard.html
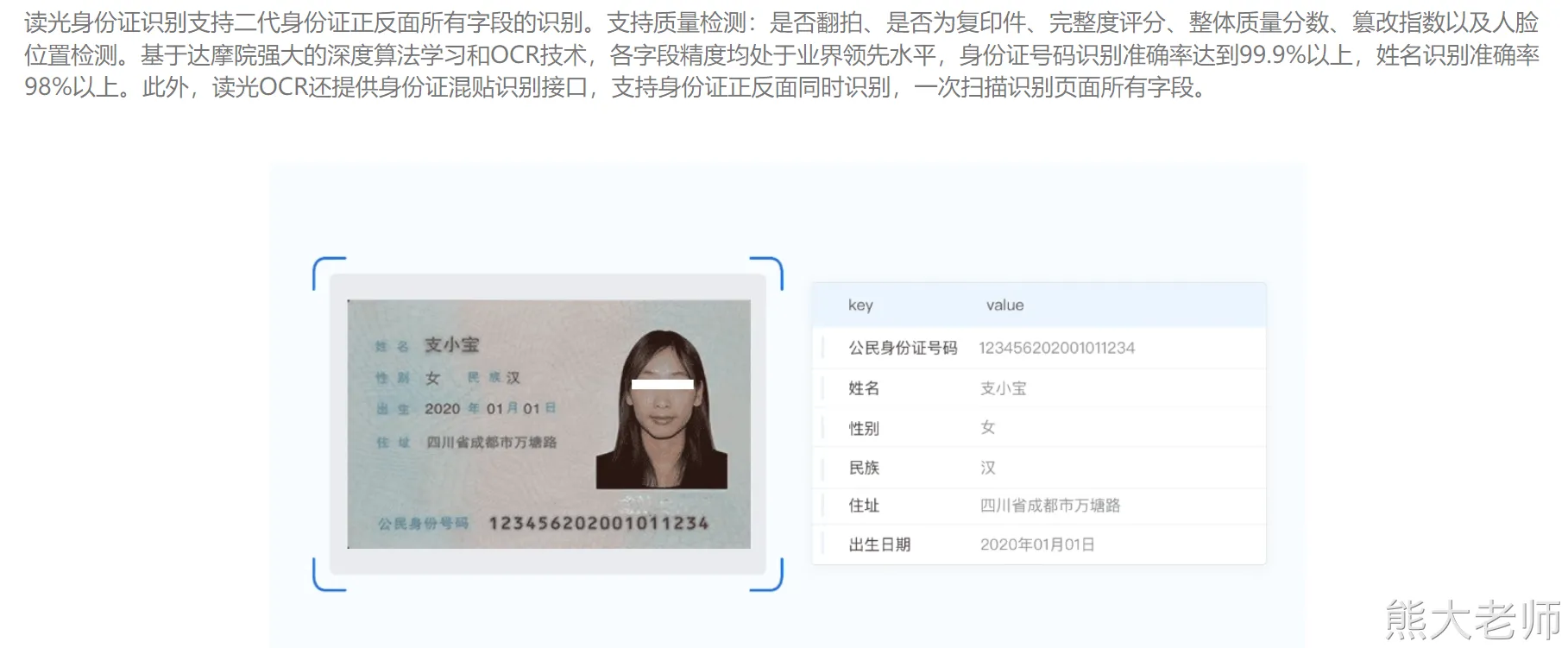
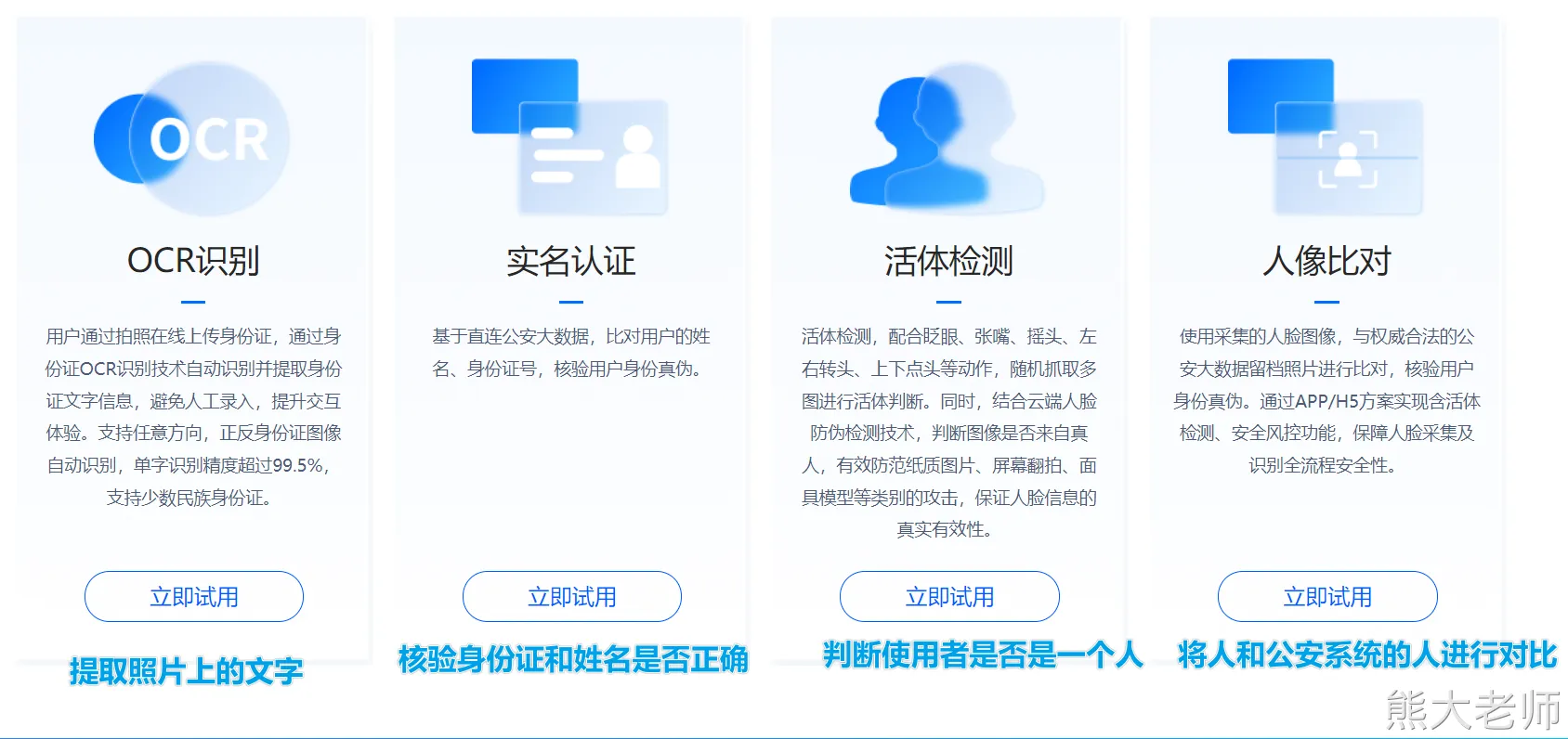
MD5认证:通过调用第三方接口,根据提供姓名、身份证号码来判断是否是合法 [第三方和公安部有合作]
https://www.ihuyi.com/api/idcard2md5.html
身份证验证分为 2 要素和 4 要素,4 要素就是 姓名,身份证号,开始日期,过期日期。
活体认证服务:
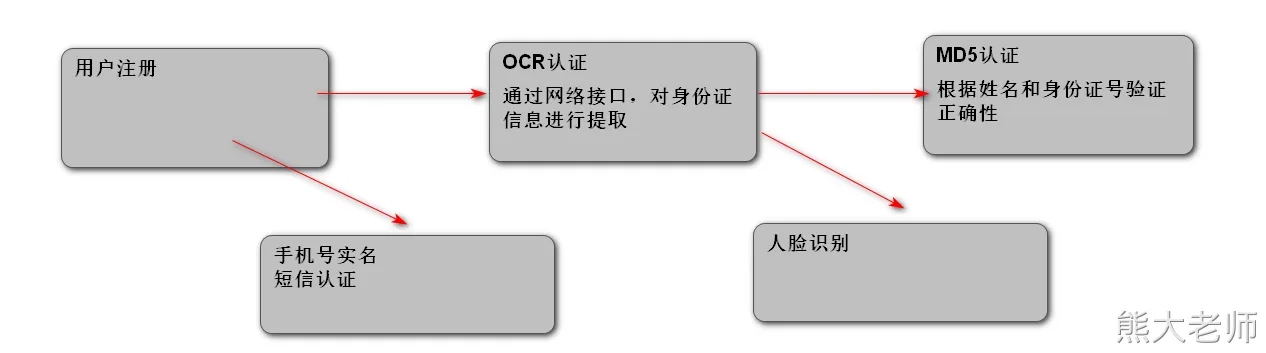
ORC:hive 的数据的一种存储格式
OCR: 提取一张图片的文字的一种技术。
create table dwd_fact_user_regiter_dtl(dateid string,idty_type string,channel_id bigint,user_type string,manager_id bigint,sex string,user_id bigint,birthday string,user_name string,client_id string,message_auth string,idty_error_cnt int,idty_edit_cnt int,regis_cnt int,ocr_cnt int,first_ocr_time string,last_ocr_time string,md5_app_cnt int,md5_val_cnt int,first_md5_time string,last_md5_time string,etl_time string
)
comment '用户注册事实表'
partitioned by (partition_date string comment '分区日期')
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
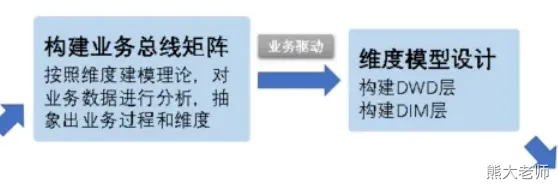
LINES TERMINATED BY '\n';-- 以上这个dwd中的表是从哪里来的,谁创建的,字段如何确定下来?
-- dwd是 数据明细层 是明细数据,要细
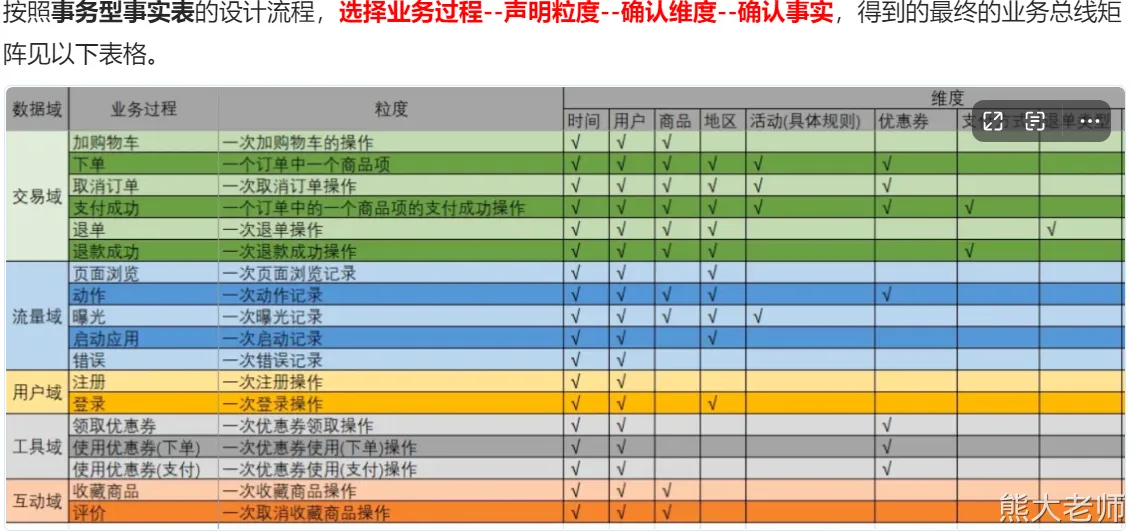
-- dwd中的表是通过什么方法论进行创建的? 根据创建的业务总线矩阵文档进行创建的
-- 业务总线矩阵表从哪里弄的?先写,然后讨论出来的。select from_unixtime(unix_timestamp("2019-11-21 00:01:35"),"yyyyMMdd");
select * from ods_user_md5 where created_at!=updated_at;set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;with t as (select user_id,count(*) md5_app_cnt,count(if(is_valid=1,1,null)) md5_val_cnt,min(created_at) first_md5_time,max(created_at) last_md5_timefrom ods_user_md5 group by user_id
),t2 as (select user_id,count(*) ocr_cnt,min(created_at) first_ocr_time,max(created_at) last_ocr_timefrom ods_user_ocrlog group by user_id
)
insert overwrite table dwd_fact_user_regiter_dtl partition (partition_date)
selectfrom_unixtime(unix_timestamp(u.created_at),"yyyyMMdd") dateid,u.idty_type,u.channel_id,u.user_type,u.manager_id,u.sex,u.id as user_id,u.birthday,u.name as user_name,u.client_id,u.message_auth,u.idty_error_cnt,u.idty_edit_cnt,1,t2.ocr_cnt,t2.first_ocr_time,t2.last_ocr_time,t.md5_app_cnt,t.md5_val_cnt,t.first_md5_time,t.last_md5_time,from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss') as etl_time,from_unixtime(unix_timestamp(),'yyyy-MM-dd') as partition_datefrom ods_users uleft join t on u.id = t.user_idleft join t2 on u.id = t2.user_id;
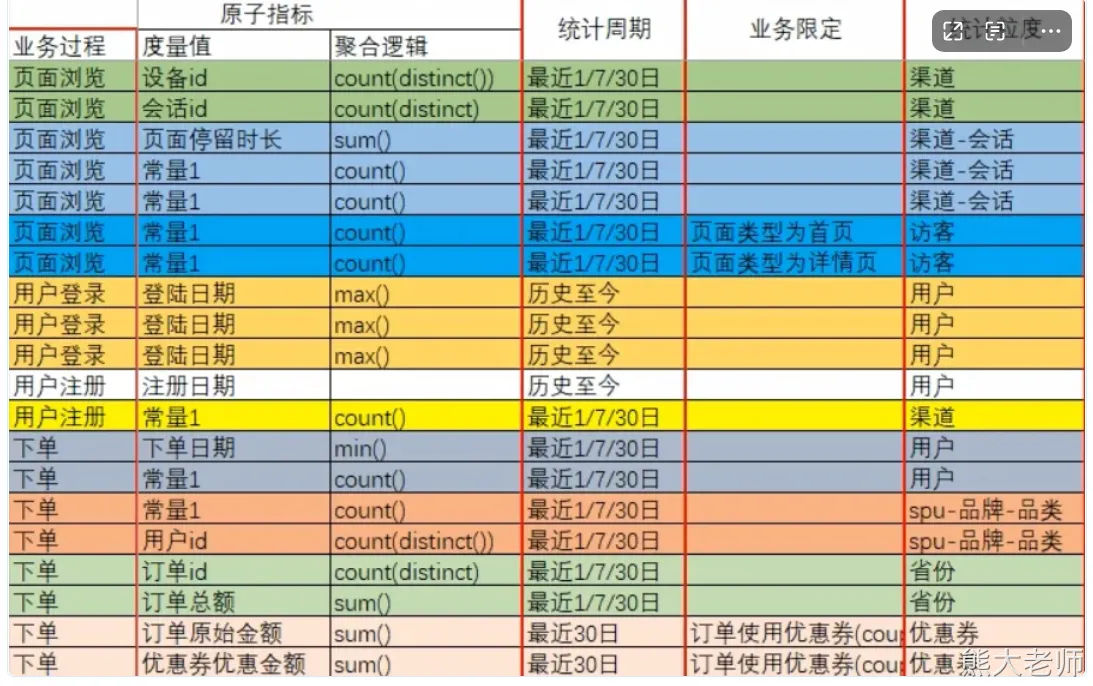
DWS 中创建什么表一般取决于需求,我们将所有的需求进行拆分
衍生指标–>派生指标 --> 原子指标
查看哪些派生指标是重复统计的,将这些指标提前统计出来,供 ads 层的指标使用
dws 层称之为 数据汇总层,数据服务层,轻度汇总层 【汇总】
create table dws_fact_regiter_sum(dateid string,idty_type string,channel_id bigint,user_type string,manager_id bigint,sex string,regis_cnt int,ocr_cnt int,md5_app_cnt int,md5_val_cnt int,etl_time string
)
comment '注册统计聚合表'
partitioned by (partition_date string comment '分区日期')
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n';set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;insert overwrite table dws_fact_regiter_sum partition (partition_date)
select dateid,idty_type,channel_id,user_type,manager_id,sex ,sum(regis_cnt) regis_cnt,sum(ocr_cnt) orc_cnt,sum(md5_app_cnt) md5_app_cnt,sum(md5_val_cnt) md5_val_cnt,from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss') as etl_time,from_unixtime(unix_timestamp(),'yyyy-MM-dd') as partition_datefrom dwd_fact_user_regiter_dtl group bydateid,idty_type,channel_id,user_type,manager_id,sex ;
T+1:今天计算昨天的数据,每天凌晨使用类似于dolphinscheduler这样的定时调度工具对前一天、上一周(周一)、上一月(月初)的数据进行计算。
常见于离线数仓, T+1的优势:稳定 T+1的优势:延迟高。
实时数仓: 数据一边产生,一边统计。数仓名词解释:数据口径、原子指标、派生指标、衍生指标
数据(指标)口径:对于需求的约定。
这个需求就是取数口径:基于年龄区间统计用户注册量、年龄区间[0,22)、[22,30)、[30,40)、[40,50)、[50,100)
年龄是维度、用户量是指标取数:获取数据,交给业务部门。
补数:对于缺失数据的日期的数据进行重跑补充
需求:
于年龄区间统计用户注册量、年龄区间[0,22)、[22,30)、[30,40)、[40,50)、[50,100)
-- drop table dim_user;
create table dim_user(user_id bigint,phone string,hash_pwd string,idty_type string,idty_id string,email string,birthday string,age_range string,message_auth string,idty_photo_url string,updated_at string,created_at string,etl_time string
) comment '用户维度表'
partitioned by (partition_date string comment '分区日期'