C++STL系列之unordered_set和unordered_map
前言
unordered_set和unordered_map仍然是关联式容器,底层是哈希表。跟上次讲的multimap和multiset类似,也有unordered_multiset和unordered_multimap。
一、unordered_set和unordered_map
unordered意思为无序的,所以他的迭代器遍历不是有序的,和set、map用法类似,不详细介绍了,介绍一下用法上不一样的。这两个迭代器都是单向迭代器,只支持++,不支持- - ,因为内部挂的是单链表,既然内部无序,就不支持lower_bound这种需要容器有序的操作

前两个参数老朋友了,第三个就是哈希函数,库里是有hash函数的,想使用直接使用也可以,第四个是判断相不相等,如果不传,就是默认哈希函数算出来的值相等就是相等,自己传就是自定义相等。
另外:其实还多了一点接口,但是作用不大,熟悉拉链法应该能看懂大概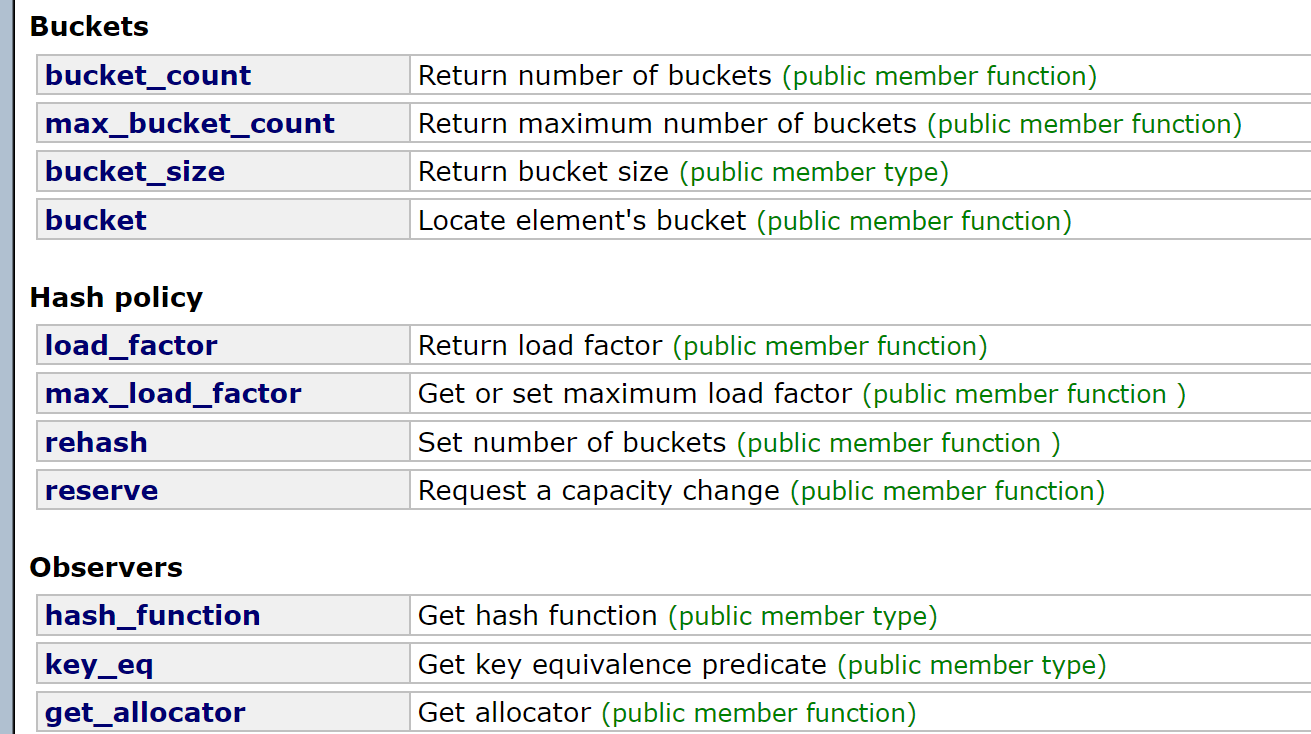
第一块就是关于桶的各种接口
第二块类似开空间,负载因子这种
第三块得到各种内部函数,比如hash函数等等,其实作用都不大,重要的还是上次讲到那些比如insert,erase等等
二、unordered_set和unordered_map的模拟实现
基本框架
有了上次的经验,这次会快一点,但是到迭代器部分还需要仔细讲,
对于哈希表,一共四个参数,K,T,KofT,HashFunc
template<class K, class T, class KofT,class HashFunc = DefaultHashFunc<K>>
class HashTable
{typedef HashData<T> Node;
private:vector<Node*> _table;int _n;//存储有效数据
};
当然insert还需要改
框架先搭上
template <class K>
class unordered_set {struct SetKeyOfT{const K& operator()(const K& key){return key;}};
private:HashTable<K, K,SetKeyOfT> _table;
};```cpp
template <class K, class V>
class unordered_map
{
private:struct MapKeyOfT{const K& operator()(const pair<K,V>& key){return key.first;}};
public:
private:HashTable<K, pair<const K, V>,MapKeyOfT> _table;
};
Hash_Iterator
迭代器怎么设计,既然是单向,主要考虑++就可以
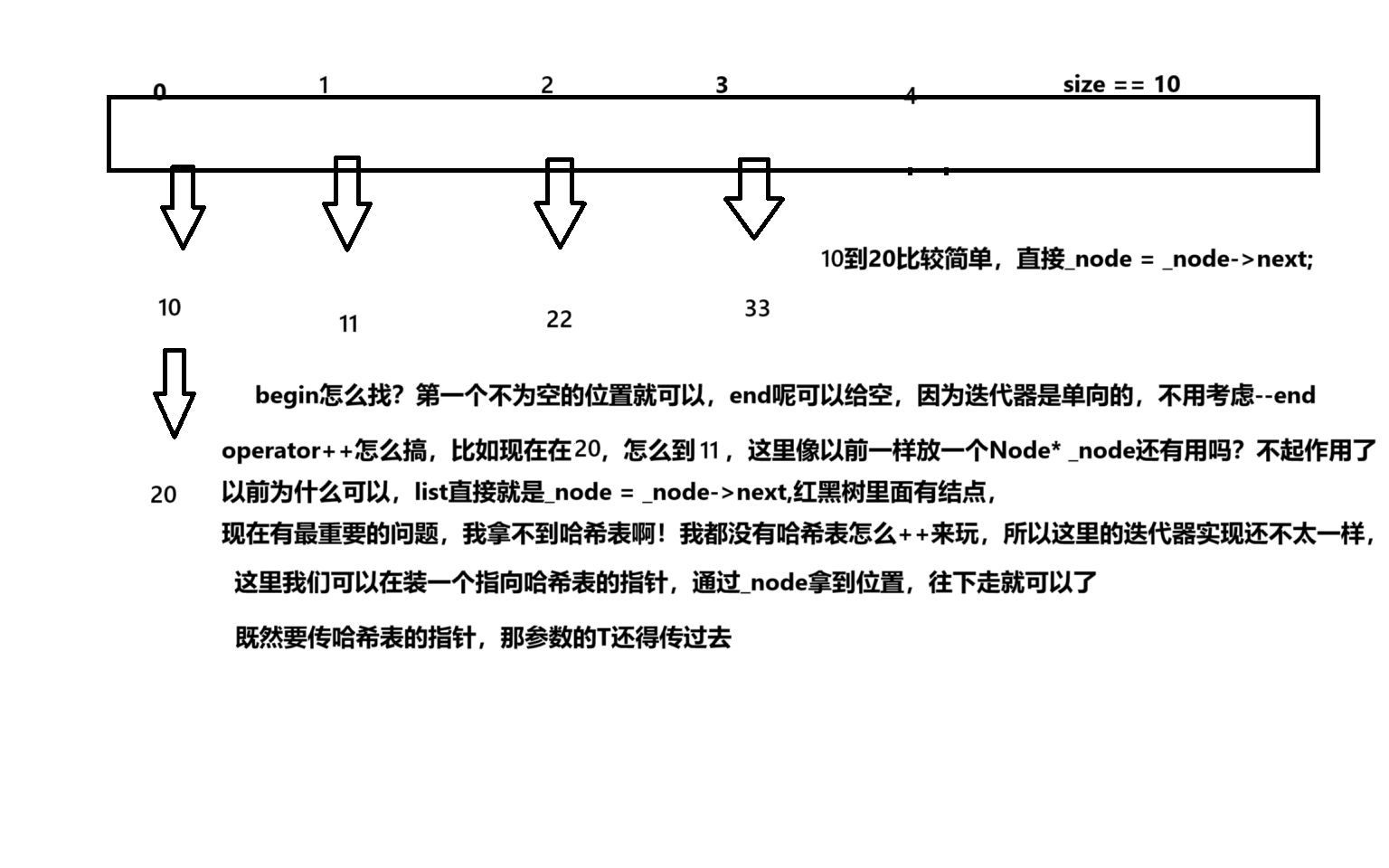
迭代器:
template<class K,class T,class Ref,class Ptr,class KofT,class HashFunc>
class Hash_Iterator
{
public:typedef HashData<T> Node;typedef Hash_Iterator<K, T,Ref, Ptr,KofT,HashFunc> Self;HashTable<K, T, KofT, HashFunc>* _ht;Node* _node;typedef Hash_Iterator<K, T, T&, T*, KofT, HashFunc> iterator;Hash_Iterator(Node* node, HashTable<K, T, KofT, HashFunc>* ht):_node(node),_ht(ht){}Hash_Iterator(const iterator& it):_node(it._node),_ht(it._ht){ }Ref operator*(){return _node->_kv;}Ptr operator->(){return &(operator*());}Self& operator++(){if (_node->_next != nullptr){_node = _node->_next;return *this;}else{KofT koft;HashFunc hs;size_t hashi = hs(koft(_node->_kv)) % _ht->_table.size();++hashi;while(hashi < _ht->_table.size()){if (_ht->_table[hashi] != nullptr){_node = _ht->_table[hashi];return *this;}else{++hashi;}}_node = nullptr;return *this;}}Self operator++(int){Self tmp(*this);++(*this);return tmp;}bool operator==(const Self& ot)const{return _node == ot._node;}bool operator!=(const Self& ot)const{return _node != ot._node;}
};
注意:这里六个参数要知道都是干什么的,以及计算hashi要套两层函数,第一层是取到key,第二层是哈希函数。
然后套begin和end
template<class K, class T, class KofT,class HashFunc = DefaultHashFunc<K>>class HashTable{typedef HashData<T> Node;public:template<class K, class T, class Ref, class Ptr,class KofT, class HashFunc>typedef Hash_Iterator<K,T,T&,T*,KofT,HashFunc> iterator;typedef Hash_Iterator<K,T,const T&,const T*,KofT,HashFunc> const_iterator;iterator begin(){for (size_t i = 0; i < _table.size(); ++i){if (_table[i] != nullptr){return iterator(_table[i], this);}}return iterator(nullptr, this);}iterator end(){return iterator(nullptr,this);}.....}
这里就提现出为什么传哈希表的地址了,this指针就是哈希表的地址啊,直接传this就可以。
unordered_map、unordered_set里面的迭代器
复习一下上次:set的普通迭代器和const迭代器都是const迭代器,map正常,但是为了防止key修改加上const,记得加typename告诉编译器这是类型
unordered_map:
typedef typename HashTable<K, pair<const K, V>, MapKeyOfT>::iterator iterator;
typedef typename HashTable< K, pair<const K, V>, MapKeyOfT>::const_iterator const_iterator;
unordered_set:
typedef typename HashTable<K, K, SetKeyOfT>::const_iterator iterator;
typedef typename HashTable<K, K, SetKeyOfT>::const_iterator const_iterator;
错误分析
到这以为迭代器整完了结果一跑,一万个错误,一个个分析一下。
先指出一个问题,就是迭代器的构造函数里不要给const Node*_node,因为const Node* 类型无法给Node*类型,所以不要任意的构造函数里的形参都加const,我们看看报了那些错误。
。。。这个编译器报的错误真是一言难尽,我们就直接分析了。
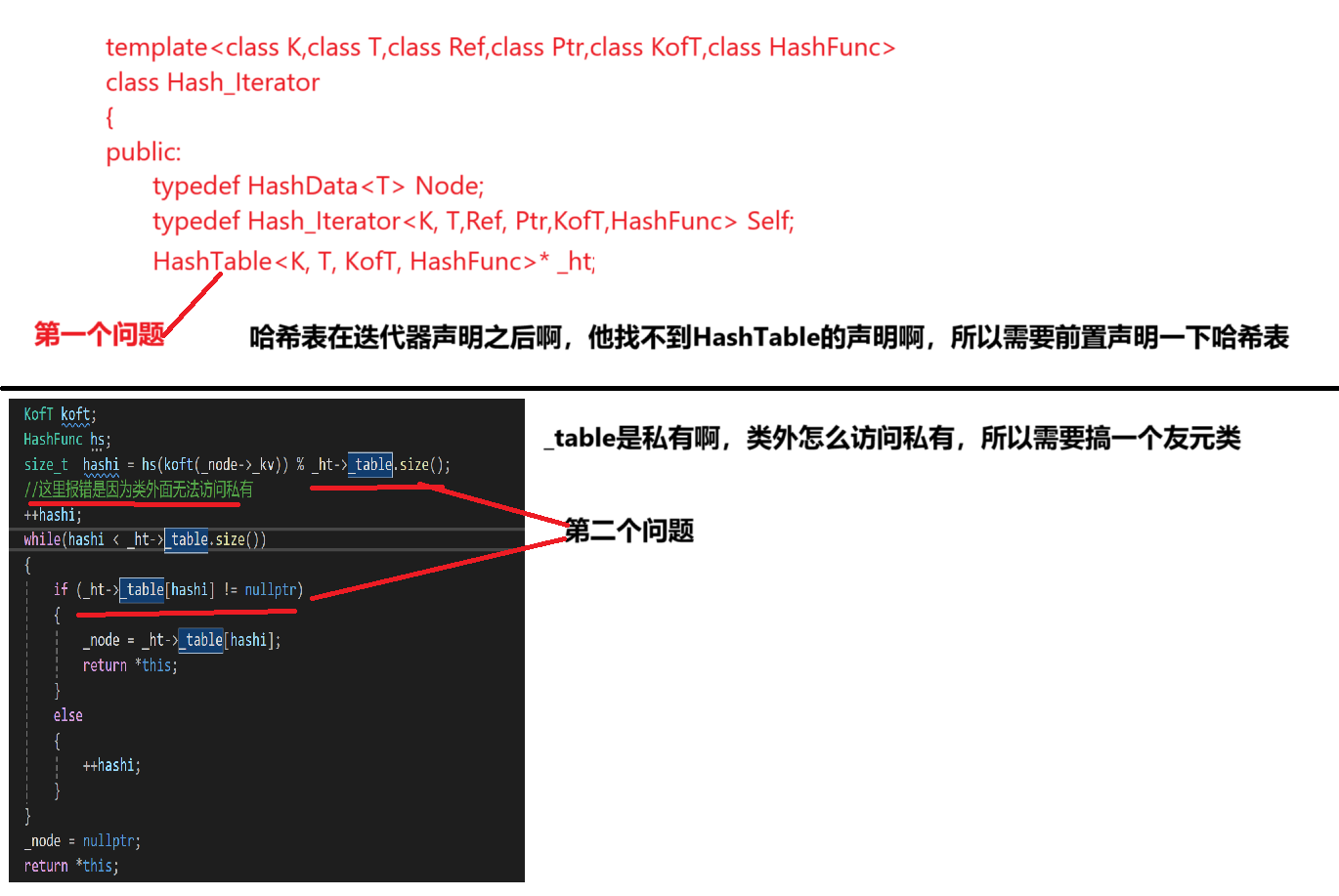

第一个问题的解决方案:
template<class K, class T, class KofT, class HashFunc>
class HashTable;
//前置声明一下
第二个:
template<class K, class T, class Ref, class Ptr,class KofT, class HashFunc>
friend class Hash_Iterator;
第三个:
const HashTable<K, T, KofT, HashFunc>* _ht;
Hash_Iterator( Node* node, const HashTable<K, T, KofT, HashFunc>* ht):_node(node),_ht(ht)
{}
operator[]
和map,set一样的套路,这里就简单提一遍过程。
V& operator[](const K& key)
{auto it = insert(make_pair(key,V())).first;return *it.second;
}
改的过程是:1.先改insert的返回值,改成pair<iterator,bool>,
2.改unordered_map和unordered_set的返回值
3.因为unordered_set的迭代器默认是const迭代器,返回类型不匹配,在哈希表迭代器中搞一个一直是普通迭代器的iterator,写一个构造,如果实例化是const迭代器就是普通迭代器构造const迭代器,如果是普通迭代器那就是他的拷贝构造。
pair<iterator,bool> insert(const pair<K,V>& p)
{return _table.insert(p);
}
V& operator[](const K& key)
{iterator it = insert(make_pair(key, V())).first;return (*it).second;//
}
pair<iterator,bool> insert(const T& p)
{KofT koft;auto it = Find(koft(p));if (it != end()){return make_pair(it,false);}HashFunc h;if (_n == _table.size()){//扩容size_t newsize = GetNextPrime(_table.size());vector<Node*> newtable;newtable.resize(newsize, nullptr);for (size_t i = 0; i < _table.size(); ++i){Node* cur = _table[i];while (cur){Node* next = cur->_next;size_t newhashi = h(koft(p)) % newsize;cur->_next = newtable[newhashi];newtable[newhashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newtable);//这里newtable会调用析构导致}size_t hashi = h(koft(p)) % _table.size();Node* newnode = new Node(p);//悬挂结点newnode->_next = _table[hashi];_table[hashi] = newnode;_n++;return make_pair(iterator(_table[hashi],this),true);
}
typedef Hash_Iterator<K, T, T&, T*, KofT, HashFunc> iterator;
Hash_Iterator(const iterator& it):_node(it._node),_ht(it._ht)
{ }
有一些说法说哈希桶的桶的数量取一些特定的质数可以减少冲突。取质数的方式:
size_t GetNextPrime(size_t prime)
{const int PRIMECOUNT = 28;static const size_t primeList[PRIMECOUNT] ={53ul, 97ul, 193ul, 389ul, 769ul,1543ul, 3079ul, 6151ul, 12289ul, 24593ul,49157ul, 98317ul, 196613ul, 393241ul, 786433ul,1572869ul, 3145739ul, 6291469ul, 12582917ul,25165843ul,50331653ul, 100663319ul, 201326611ul, 402653189ul,805306457ul,1610612741ul, 3221225473ul, 4294967291ul};size_t i = 0;for (; i < PRIMECOUNT; ++i){if (primeList[i] > prime)return primeList[i];}return primeList[i];
}
insert扩容时的逻辑就变成了size_t newsize = GetNextPrime(_table.size());
这样下来我们的哈希表就可以跑起来了。
完整代码
个人gitee
总结
unordered系列模拟实现的东西比较多,需要掌握,另外,其实哈希还有一个位图 、布隆过滤器就在下次讲了。