7.3.2 内核内存管理运行机制
一、虚拟内存地址布局
1、内存管理架构
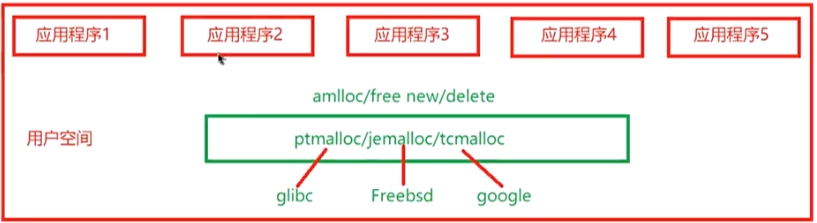
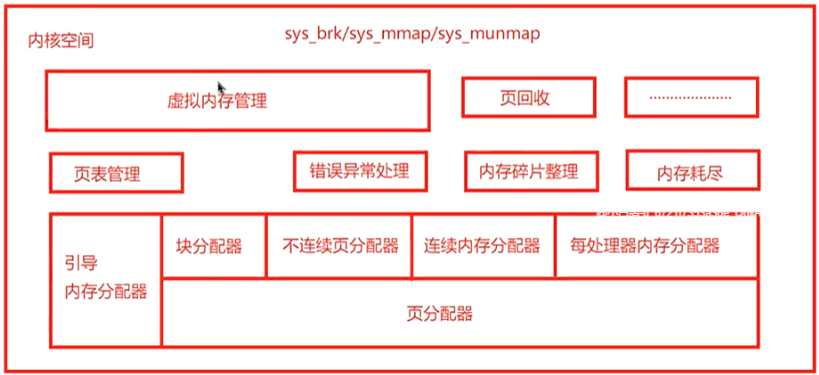
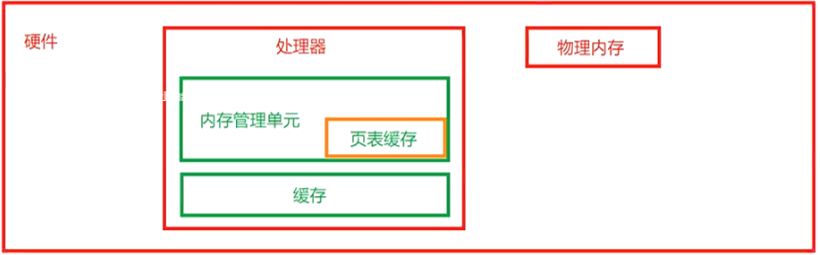
内存管理子系统架构可以分为:用户空间、内核空间及硬件部分3个层面,具体结构如下所示:
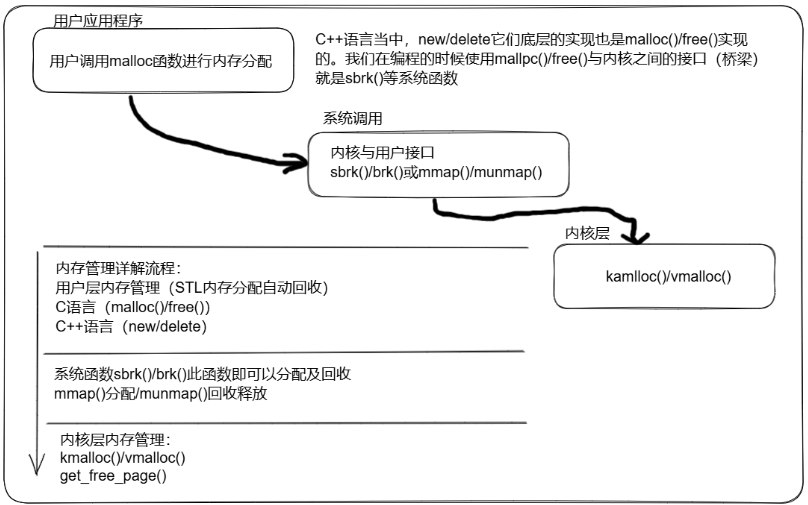
a、用户空间:应用程序使用malloc()申请内存资源/free()释放内存资源。
b、内核空间:内核总是驻留在内存中,是操作系统的一部分。内核空间为内核保留,不允许应用程序读写该区域的内容或直接调用内核代码定义的函数。
c、硬件:处理器包含一个内存管理单元(Memory Management Uint,MMU)的部件,负责把虚拟地址转换为物理地址。
1、Linux内核只是操作系统当中的一部分,对下管理系统所有硬件设备;对上通过系统调用向Libaray Routine(或者其它应用程序提供API接口)

2、虚拟地址空间分布机构
因为目前应用程序没有那么大的内存需求,所以ARM64处理器不支持完全的64位虚拟地址。
在ARM64架构的Linux内核中,内核虚拟地址和用户虚拟地址的宽度相同。
所有进程共享内核虚拟地址空间,每个进程有独立的用户虚拟地址空间,同一个线程组的用户线程共享用户虚拟地址空间,内核线程没有用户虚拟地址空间。

3、用户虚拟地址空间划分
进程的用户虚拟空间的起始地址是0,长度是TASK_SIZE,由每种处理器架构定义自己的宏TASK_SIZE。ARM64架构定义的宏TASK_SIZE如下:
32位用户空间程序:TASK_SIZE的值是TASK_SIZE_32,即0x100000000,等4GB。
64位用户空间程序:TASK_SIZE的值是TASK_SIZE_64,即2VA_BITS字节。
用户虚拟地址空间Linux内核源码分析下图所示:

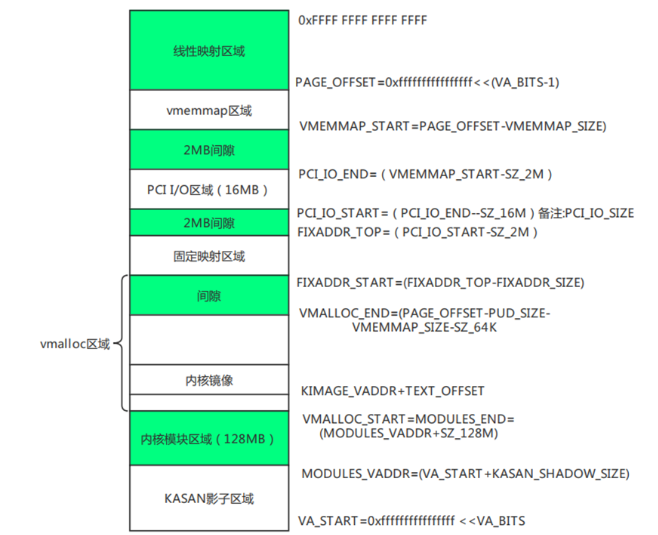
4、内核地址空间布局
ARM64处理器架构内核地址空间布局如下图所示:
Linux内核使用内存描述符mm_struct描述进程的用户虚拟地址,具体内核源码如下:
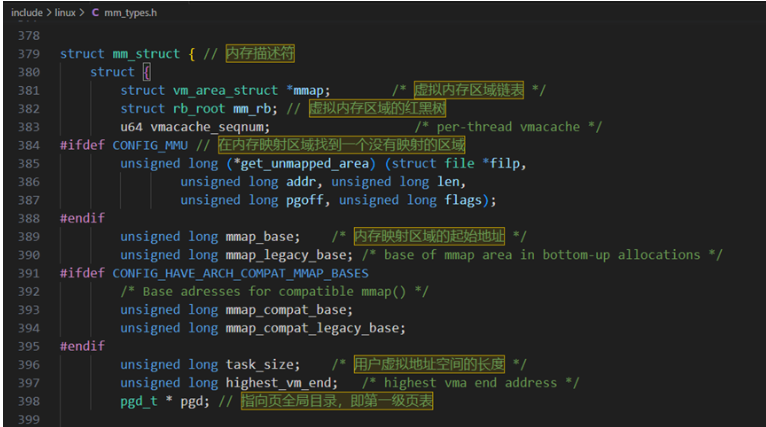
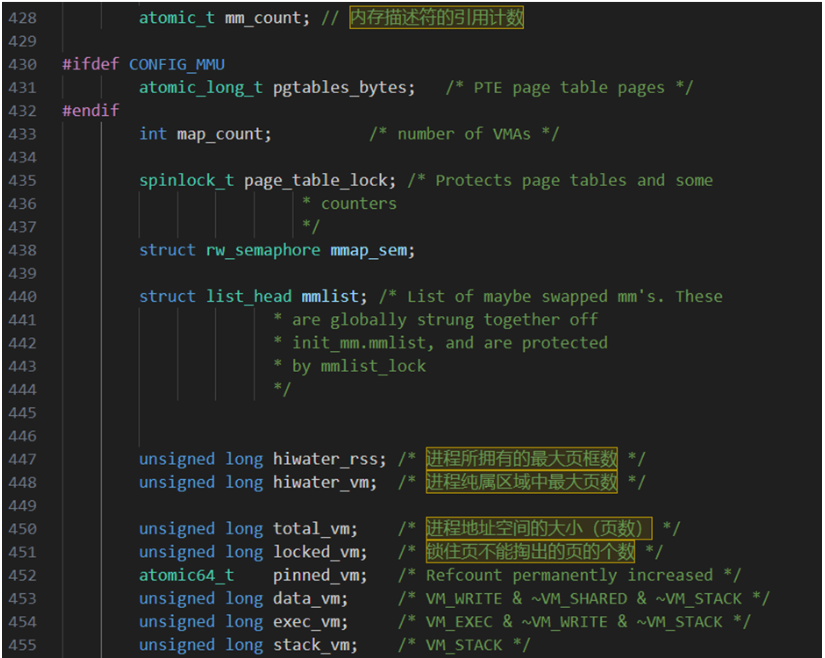
逻辑关系:一个进程的虚拟地址空间主要由两个数据结构进行描述,一个是最高层次的mm_struct,较高层次的vm_area_struct。最高层次mm_struct结构体描述一个进程整个虚拟地址空间。较高层次结构体描述虚拟地址空间的一个区间(称为虚拟区)。每个进程只有一个mm_struct,每个进程的task_struct结构体中,有一个专门用来指向进程的结构体。mm_struct结构体是对整个用户空间的描述。

二、SMP/NUMA模型
1、SMP(对称多处理器结构,又称UMA)
对称多处理器结构(symmetrical mulit-processing,SMP),在对称多处理器系统中,所有处理器的地位都是平等的,所有的CPU共享全部资源,比如内存、总线、中断及I/O系统等等,都具有相同的可访问性,消除结构上的障碍,最大特点就是共享所有资源。
在多处理器系统当中,内核必须考虑几个额外的问题,主要以确保良好的调度。
CPU负荷必须尽可能公平地在所有的处理器上共享。
进程与系统中某些处理器的亲合性(affinity)必须是可设置的。内核必须能够将进程从一个CPU迁移到另一个。
Linux SMP调度就是将进程安排/迁移到合适的CPU中去,保持各CPU负载均衡的过程。
2、NUMA(非一致内存访问结构)
NUMA为是多处理器计算机,系统各个CPU都有本地内存,可以支持超快的访问能力,各个处理器之间通过总线连接起来,支持对其他CPU的本地内存访问(但比访问自己的内存要慢点)。
3、CPU域初始化
根据实际物理属性CPU分类(SMT、MC、SoC),Linux内核分类(CONFIG_SCHED_SMT、CONFIG_SCHED_MC、DIE)。Linux内核对CPU的管理是通过bitmap来管理的,并且定义4种状态:possible/present/online/active。具体内核源码处理如下:
// include/linux/cpumask.h
extern struct cpumask __cpu_possible_mask;
extern struct cpumask __cpu_online_mask;
extern struct cpumask __cpu_present_mask;
extern struct cpumask __cpu_active_mask;
#define cpu_possible_mask ((const struct cpumask *)&__cpu_possible_mask)
#define cpu_online_mask ((const struct cpumask *)&__cpu_online_mask)
#define cpu_present_mask ((const struct cpumask *)&__cpu_present_mask)
#define cpu_active_mask ((const struct cpumask *)&__cpu_active_mask)三、页表缓存原理
处理器厂商在内存管理单元(MMU)里增加一个TLB(Translation Lookaside Buffer)的高速缓存,TLB直译为转译后备缓冲器,也被翻译为页表缓存。
TLB为CPU的一种缓存,由存储器管理单元用于改进虚拟地址到物理地址的转译速度。
TLB 用于缓存一部分标签页表条目。TLB可介于 CPU 和CPU缓存之间,或在 CPU 缓存和主存之间,这取决于缓存使用的是物理寻址或是虚拟寻址。
1、TLB表项格式
不同处理器架构的TLB表项的格式不同。ARM64处理器的每条TLB表项不仅包含虚拟地址和物理地址,也包含属性:内存类型、缓存策略、访问权限、地址空间标识符((ASID)及虚拟机标识符(VMID)。地址空间标识符区分不同进程的页表项,虚拟机标识符区分不同虚拟机的页表项。
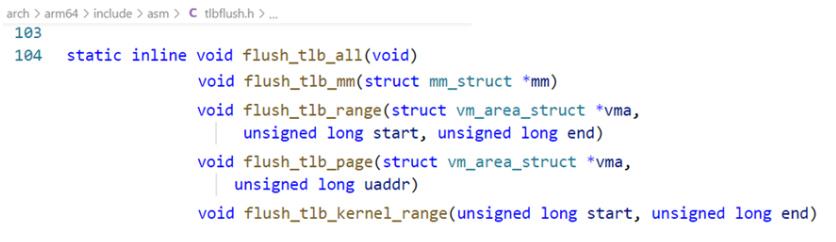
2、TLB管理
若内核修改了可能缓存在TLB里面的页表项,那么内核必须负责使用旧的TLB表项失效,内核定义每种处理器架构必须实现的函数,具体可查阅源码分析如下:
3、ARM64架构提供一条TLB失效指令
TLBI <type><level>{IS} {,<Xt>}
字段<type>常见选项
字段<level>指定异常级别(E1/E2/E3)
字段{IS}表示内部共享,即多个核共享
字段Xt是X0-X31中的任何一个寄存器:
-
X0零寄存器(始终为零)
-
X1返回地址寄存器
-
X2-X11临时寄存器(临时保存计算过程中的数据)
-
X12-X17保留寄存器
-
X18平台相关寄存器
-
X19-X28保存寄存器
-
X29帧指针寄存器
-
X30链接地址寄存器
-
X31栈指针寄存器(用于指向当前线程栈的顶部)
案例分析:ARM64内核实现函数flush_tlb_all,用来使用所有核的所有TLB表项失效,其源码如下:
static inline void flush_tlb_all(void)
{dsb(ishst);__tlbi(vmalle1is);dsb(ish);isb();
}dsb(ishst):确保屏障之前的存储指令执行完毕,dsb是数据同步屏障。
__tlbi(vmalle1is):使所有栈上匹配VMID,阶段1和异常级别1的所有TLB表项失效。
dsb(ish):确保之前的 TLB失效指令执行完毕,ish表示数据同步屏障指令对所有核起作用。
isb():指令同步屏障,冲刷处理器流水线,重新读取屏障指令后面的所有指令。
4、地址空间标识符
为了减少在进程切换时清空页表缓存的需要,ARM64处理器的页表缓存使用非全局(not global, nG)位区分内核和进程的页表项,使用地址空间标识符(Address Space Identifer,ASID)区分不同进程的页表项。
ARM64处理器ASID长度是由具体实现定义的,可以选择8位或者16位,寄存器ID_AA64MMFRO_EL1(AArch64内存模型特性寄存器0,AArch64 Memory Model Feature Register 0)的字段ASIDBits存放处理器支持的ASID长度。
5、虚拟机标识符
虚拟机里面运行的客户操作系统的虚拟地址换成物理地址分两个阶段:第1阶段把虚拟地址转换成中间物理地址,第2阶段把中间物理地址转换成物理地址。第1阶段转换由客户操作系统的内存控制,和非虚拟化的转换过程相同。第2阶段转换由虚拟机监控器控制,虚拟机监控器为每个虚拟机维护一个转换表,分配一个虚拟机标识符(Virtual Machine Identifier,VMID),寄存器VTTBR_EL2(虚拟化转换表基准寄存器,Virtualization Translation Table Base Register)存放当前虚拟机的阶段2转换表的物理地址。
四、伙伴系统算法原理
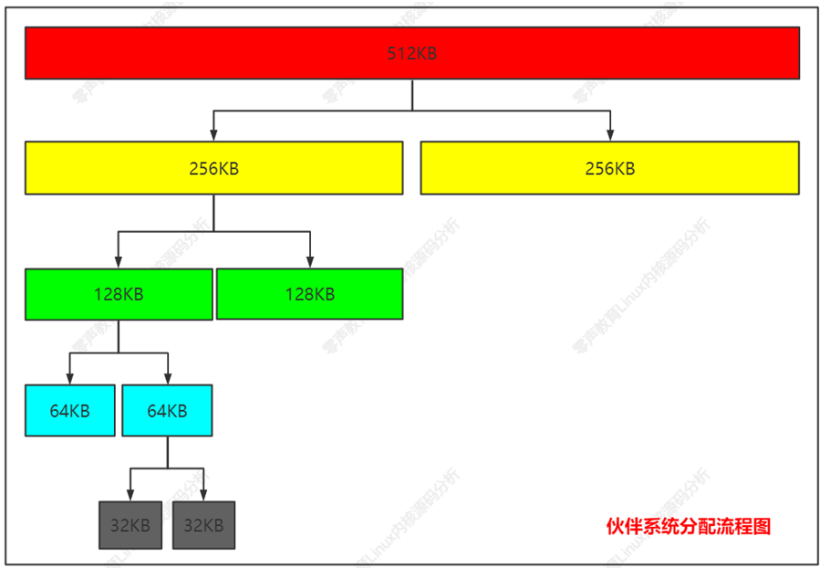
Linux 的伙伴算法把所有的空闲页面分为11个块组,每组中块的大小是2的幂次方个页面。例如,第0组中块的大小都为2(0)(1 个页面),第1组中块的大小都为 2(1)(2个页面),第8组中块的大小都为 2(8)(256个页面),依次类推。也就是说,每一组中块的大小是相同的,且这同样大小的块形成一个链表。
系统内存中的每个物理内存页(页帧),都对应于一个struct page实例, 每个内存域都关联了一个struct zone的实例,其中保存了用于管理伙伴数据的主要数组,具体如下:
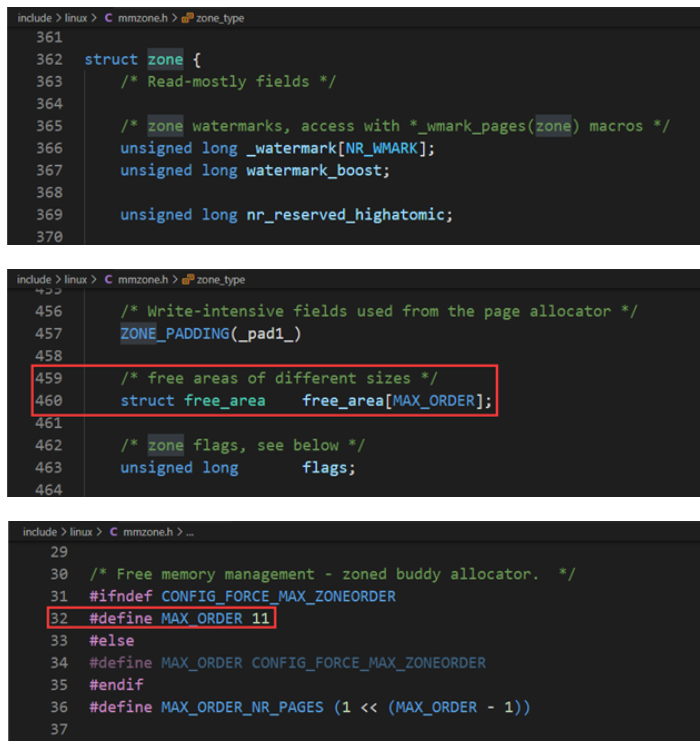
一般来说MAX_ORDER默认定义为11,但如果特定于体系结构的代码设置FORCE_MAX_ZONEORDER配置选项,该值也可以手工改变。
struct free_area是一个伙伴系统的辅助数据结构:
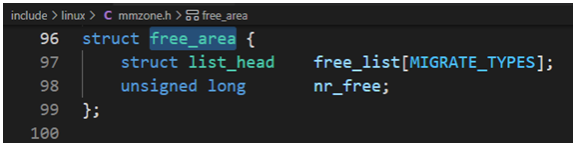
其中:free_list是用于连接空闲页的链表。页链表包含大小相同的连续内存区;nr_free指定了当前内存区中空闲页块的数目(对0阶内存区逐页计算,对1阶内存区计算页对的数目,对2阶内存区计算4页集合的数目,依次类推。伙伴系统的分配器维护空闲页面所组成的块, 这里每一块都是2的方幂个页面, 方幂的指数称为阶。
伙伴系统从物理连续的大小固定的段进行分配,方法如上所述,内核请求28KB的内存,具体案例分析如下:
五、块分配(slab/slub/slob)原理实现
1、SLAB是Linux内核中一种高效的内存分配器,通过预先划分大小相等的SLAB来管理小型对象的分配和回收。这种机制可以提高系统性能和内存利用率。
2、SLUB(Slab Allocator)是Linux内核中的一种内存分配器,用于管理小块内存的分配和释放。它是一种基于slab的内存管理机制。
3、SLOB(Simple List of Blocks)是一种用于Linux内核的内存分配器,主要用于小型嵌入式系统。
六、brk/kmalloc/vmalloc系统调用流程
1、brk
当进程需要动态分配内存时,可以使用brk系统调用来扩展或缩小进程的堆空间。下面是brk系统调用的简要流程:
-
a.进程通过调用brk()函数来请求更改堆的结束地址。
-
b.内核检查传入的参数是否有效,包括新的结束地址是否在合法范围内。
-
c.内核验证后,会将当前进程的堆结束地址(brk指针)设置为新的值,并返回修改后的值给进程。
-
d.进程可以根据返回值判断是否成功扩展或缩小堆空间。
2、vmalloc/vfree函数原型
a、vmalloc()函数功能,内核专用申请动态内存空间,该函数分配的内存来自内核地址空间的非连续物理内存(系统内部进行对齐和管理)。
b、vmalloc()函数原型
形式参数size:是指要分配的地址空间的字节数。
返回参数:返回创建的地址区间的虚拟地址,如果分配失败则返回NULL。
c、vfree()函数原型
3、kmalloc/kfree函数原型
a、kmalloc()函数功能:该函数是内核中动态内存分配函数之一,主要用于从内核空间中分配连续的物理内存块。
b、kmalloc()函数原型
-
size:是指要分配的内存的字节数。
-
flags:是分配标志,提供多种kmalloc( )的行为。
该函数返回值:返回一个指向分配的内存块起始地址的地址指针。
c、kfree()函数原型
主要作用:释放地址objp开始的一段内存。
参考连接:https://github.com/0voice