Datawhale AI数据分析 作业2
学生考试表现影响因素数据集
第一步:数据概览与清洗
Prompt 1:
加载
StudentPerformanceFactors.csv文件,并显示前5行数据以及各列的数据类型和非空值数量,检查是否存在缺失值。
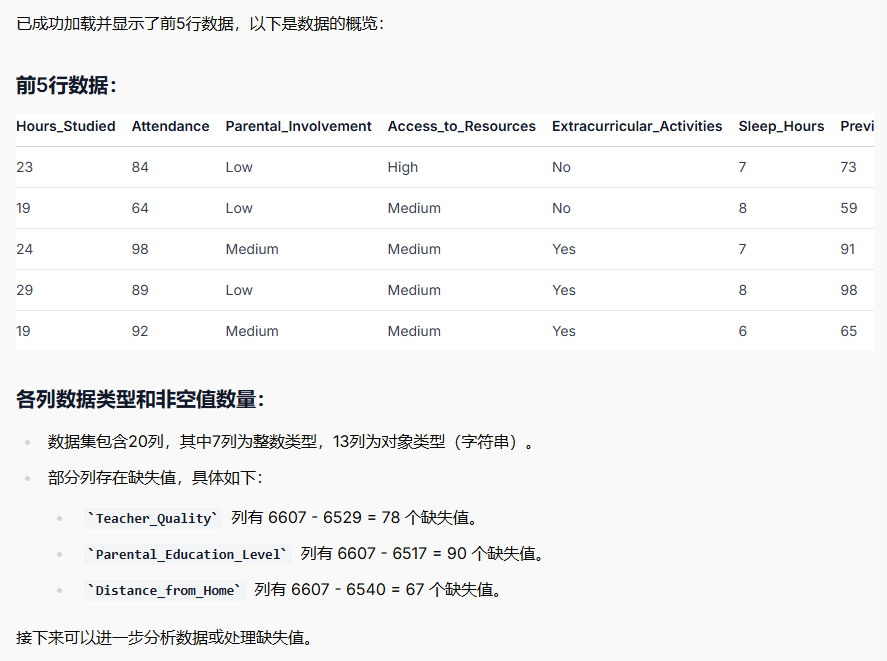
处理缺失值是数据预处理的重要一步。对于您提到的缺失值:Teacher_Quality、Parental_Education_Level 和 Distance_from_Home,它们都是分类型特征。
以下是处理这些分类型特征缺失值的几种常见策略:
1. 众数填充 (Mode Imputation)
策略: 用列中出现频率最高的类别来填充缺失值。
优点: 简单易行,不会改变数据分布,适用于分类数据。
缺点: 如果某个类别出现频率远高于其他类别,可能引入偏差;如果缺失值比例较高,可能会过度强调某个类别。
何时使用: 当缺失值占比较小(例如小于5%到10%)且众数能够较好地代表该特征的典型值时。
2. 创建新类别 "Unknown" 或 "Missing"
策略: 将缺失值作为一个新的类别,例如 "Unknown" 或 "Missing"。
优点: 保留了缺失值本身的信息,不会丢失数据。适用于缺失值可能包含特定含义的情况。
缺点: 增加了特征的类别数量,可能在某些模型中增加复杂度。
何时使用: 当缺失值可能不是随机的,而是代表了某种未知的或无法观测到的信息时。例如,如果
Parental_Education_Level缺失意味着家长不愿提供信息,这本身可能就是一种特征。
3. 基于模型预测的填充 (Model-Based Imputation)
策略: 使用其他特征来预测缺失值。例如,可以使用分类模型(如决策树、K-近邻)来预测缺失的分类特征。
优点: 能够更准确地填充缺失值,考虑了特征之间的关系。
缺点: 更复杂,计算成本高,如果预测模型不准确,可能会引入误差。
何时使用: 当缺失值占比较大,且有其他特征与该缺失特征高度相关时。
4. 删除含有缺失值的行 (Row Deletion)
策略: 直接删除包含缺失值的行。
优点: 简单粗暴,不引入任何新的偏差。
缺点: 如果缺失值较多,可能导致大量数据丢失,减少训练样本,影响模型性能。
何时使用: 当缺失值数量非常少,且对分析结果影响微乎其微时。在您的案例中,
Teacher_Quality缺失78个,Parental_Education_Level缺失90个,Distance_from_Home缺失67个,总数据量为6607条。删除这些行会损失少量数据,但如果这些缺失是分散的,总损失的行数可能更多。
考虑到三个缺失特征 (Teacher_Quality, Parental_Education_Level, Distance_from_Home) 都是分类型特征,且缺失值的数量相对较少(占总数据量的1%左右):
首选:众数填充 (Mode Imputation)
原因: 最简单、最直接的方法,且在缺失值占比较小时通常表现良好。它不会显著改变特征的整体分布。
prompt 1.2:
使用众数填充Teacher_Quality、Parental_Education_Level和Distance_from_Home这三列的缺失值,填充完成后,再次检查确认所有缺失值都已处理。
第二步:描述性统计分析
Prompt 2:
对数值型特征(例如:Hours_Studied, Attendance, Sleep_Hours, Previous_Scores, Exam_Score)进行描述性统计分析,包括均值、中位数、标准差、最小值和最大值。对于分类型特征(例如:Parental_Involvement, Access_to_Resources, Extracurricular_Activities, Motivation_Level, Family_Income, Teacher_Quality, School_Type, Peer_Influence, Learning_Disabilities, Parental_Education_Level, Distance_from_Home, Gender),计算每个类别的频次。

第三步:相关性分析
Prompt 3:
计算
Exam_Score与所有数值型特征之间的相关系数,并生成一个相关性热力图(heatmap)以可视化它们之间的关系。解释哪些数值型因素与考试成绩正相关或负相关。
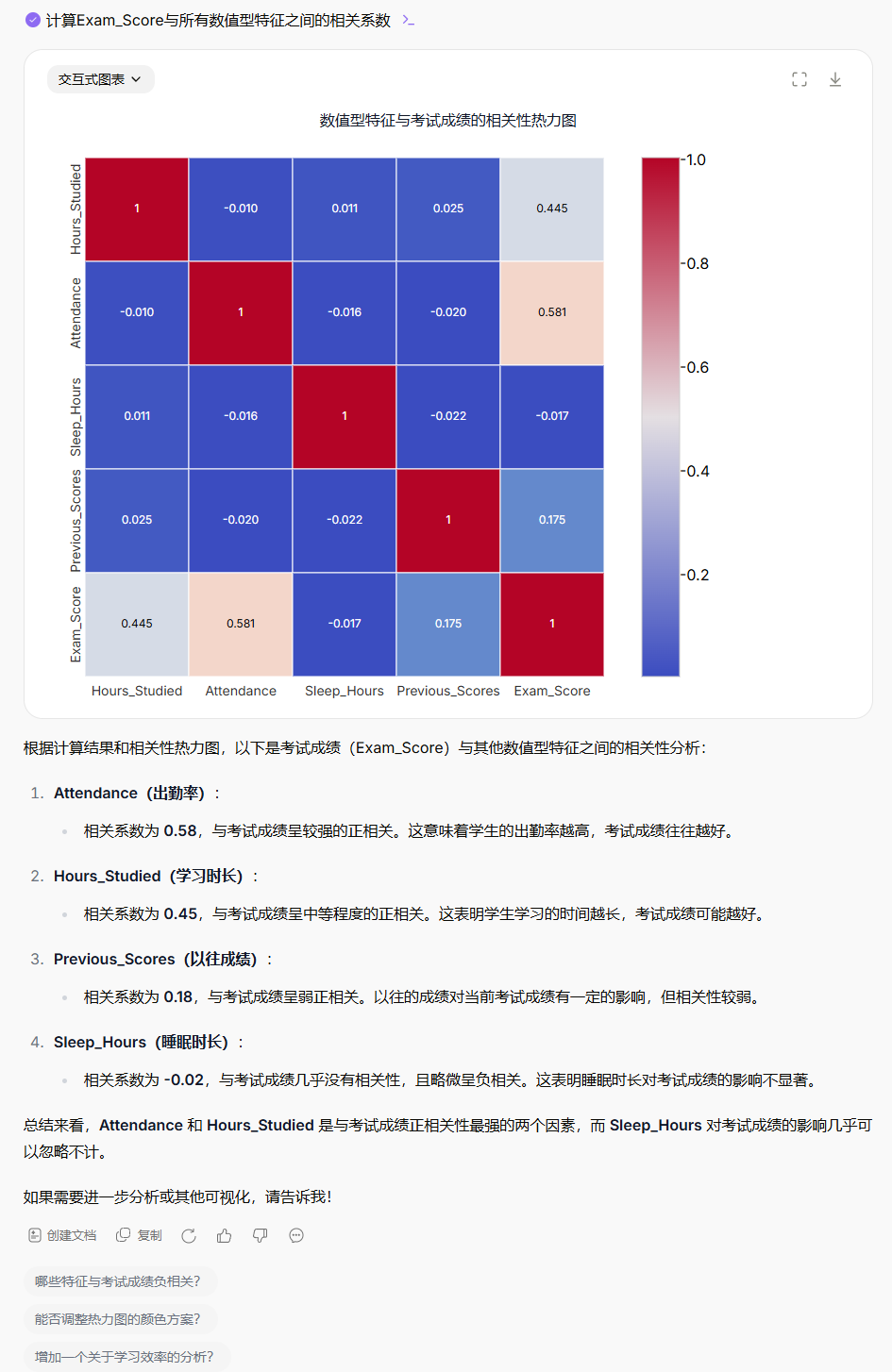 Prompt 4:
Prompt 4:
使用适当的统计方法(例如ANOVA或t检验,具体取决于分类变量的类别数量)分析分类型特征(例如Parental_Involvement, Access_to_Resources, Teacher_Quality, School_Type, Gender等)与Exam_Score之间的关系。对于每个分类特征,计算不同类别下Exam_Score的平均值,并可视化这些关系(例如使用箱线图或条形图)。
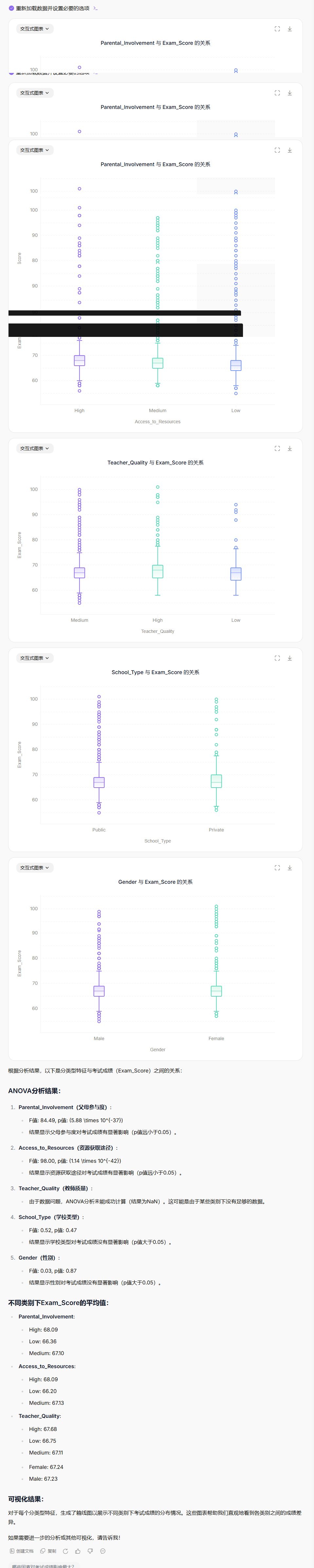
第四步:探索性数据分析 (EDA) - 深入洞察
Prompt 5:
分析
Hours_Studied与Exam_Score之间的散点图,并根据Parental_Involvement(例如High, Medium, Low)进行颜色编码,观察家长参与度是否对学习时长和考试成绩的关系有调节作用。
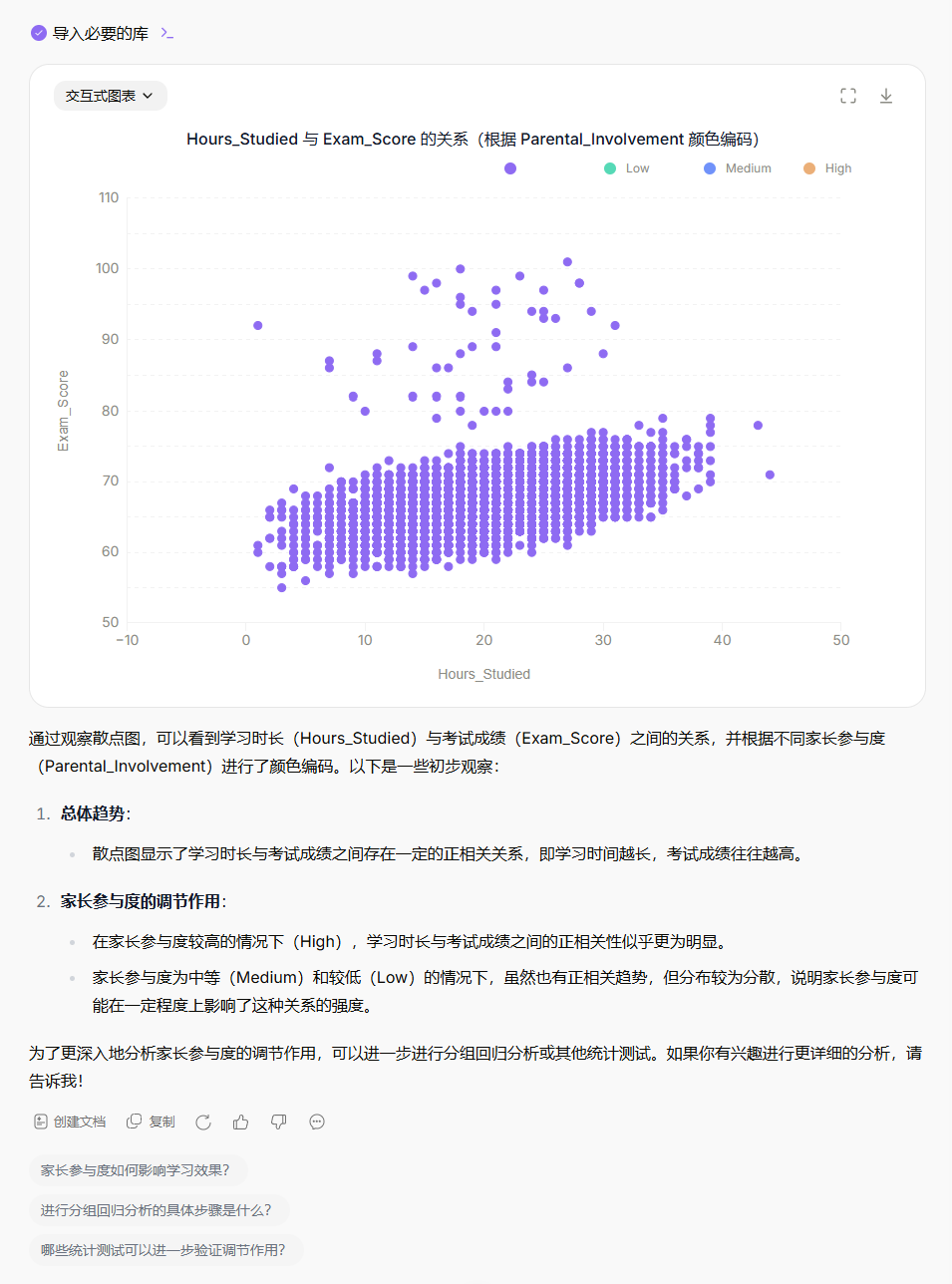
Prompt 6:
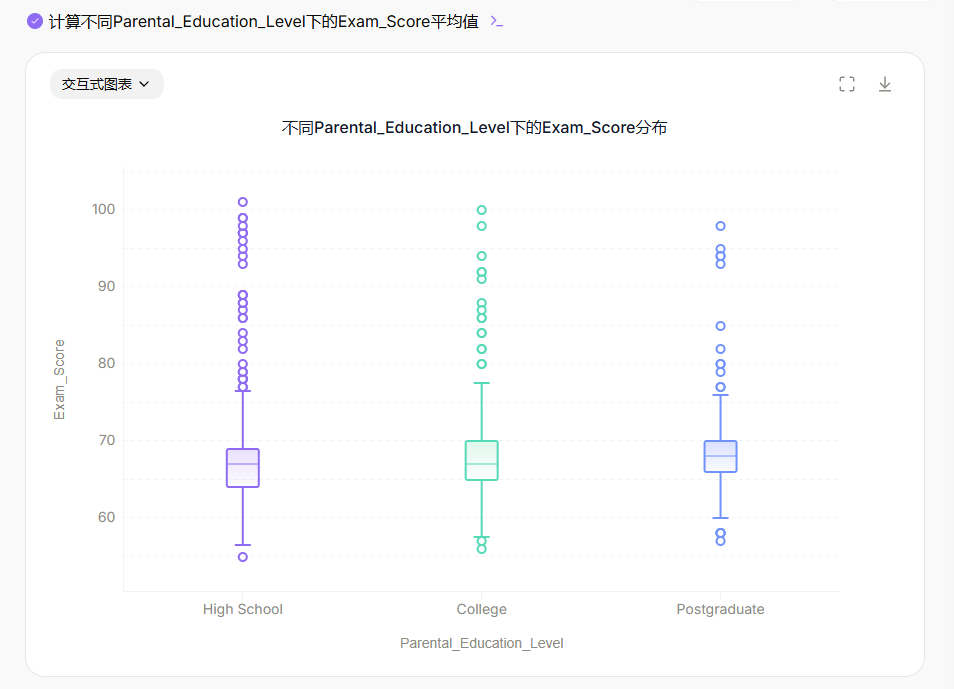
比较不同
Parental_Education_Level(例如High School, College, Postgraduate)的学生在Exam_Score上的差异,并可视化结果。解释家长教育水平对学生表现的潜在影响。
 Prompt 7:
Prompt 7:
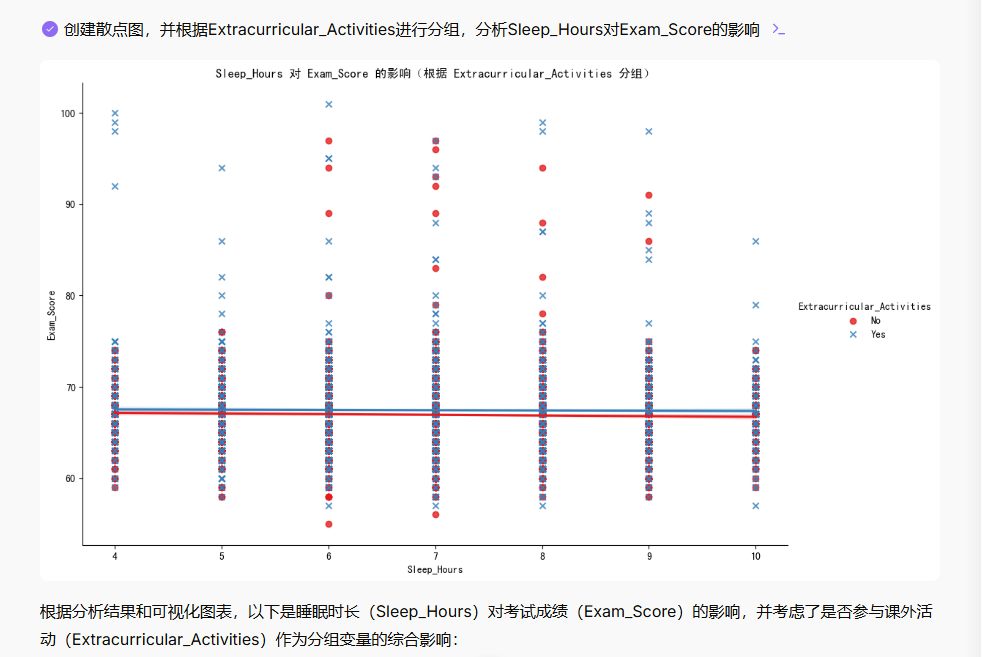
分析
Sleep_Hours对Exam_Score的影响,并考虑Extracurricular_Activities(是否参与)作为分组变量。可视化结果并解释睡眠和课外活动对考试成绩的综合影响。

Prompt 8:
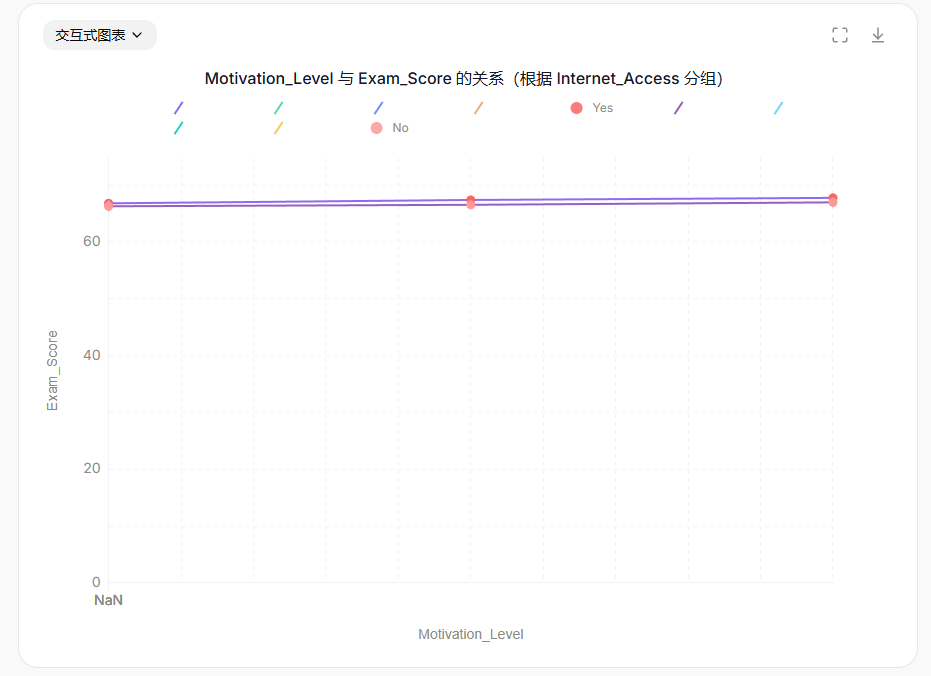
探索
Motivation_Level(High, Medium, Low)与Exam_Score之间的关系,并根据Internet_Access(Yes/No)进行分组。可视化结果并讨论互联网访问在不同动机水平下对考试成绩的影响。
创建散点图,并根据Internet_Access进行分组,分析Motivation_Level与Exam_Score之间的关系

Prompt 9:
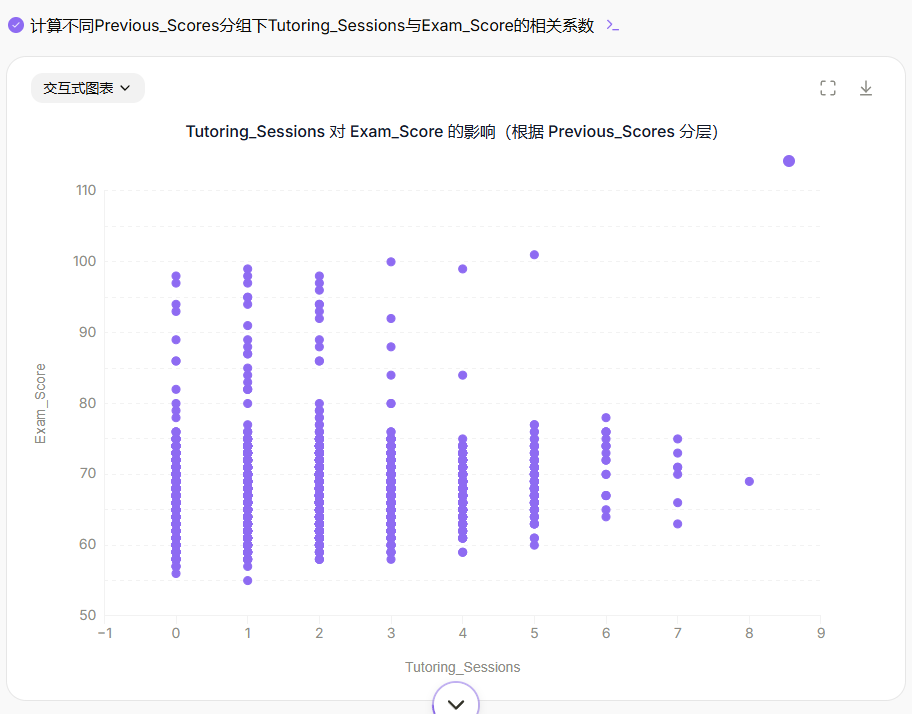
分析
Tutoring_Sessions(补习课程次数)对Exam_Score的影响,同时考虑Previous_Scores。可视化结果并讨论补习课程在不同基础的学生中是否具有不同的效果。

第五步:特征工程与预处理
Prompt 10:
对分类变量进行独热编码(One-Hot Encoding)。如果存在任何缺失值,请使用合适的策略进行填充(例如,对于数值型变量使用均值或中位数填充,对于分类型变量使用众数填充)。准备用于机器学习模型的X(特征)和y(目标变量
Exam_Score)。

第六步:学业表现预测模型构建与评估
Prompt 11:
将数据分为训练集和测试集(例如80%训练,20%测试)。使用线性回归模型预测
Exam_Score。在测试集上评估模型的性能,报告R-squared、均方误差(MSE)和均方根误差(RMSE)。

Prompt 12:
除了线性回归,尝试使用其他回归模型(例如随机森林回归、梯度提升回归)来预测
Exam_Score。比较不同模型的性能指标,并选择表现最好的模型。解释为什么所选模型表现更好。

Prompt 13:
利用最佳模型,识别出对
Exam_Score影响最大的前N个特征(例如前5或前10个)。解释这些特征的重要性。

第七步:干预策略与建议
Prompt 14:
基于以上分析结果(相关性、EDA洞察、模型特征重要性),提供详细的、可操作的干预策略,以提高学生的学业表现。策略应涵盖以下方面:
- 学习习惯: 如何促进高效学习,例如鼓励充足的学习时间、定期复习。
- 家长参与度: 如何鼓励家长更积极地参与学生的学习过程。
- 资源获取: 如何确保所有学生都能获得必要的学习资源(例如互联网访问、补习)。
- 身心健康: 如何强调睡眠、体育活动和积极心态的重要性。
- 学校与教师: 学校和教师可以采取哪些措施来优化学习环境和教学质量。"
