训练日志7.23
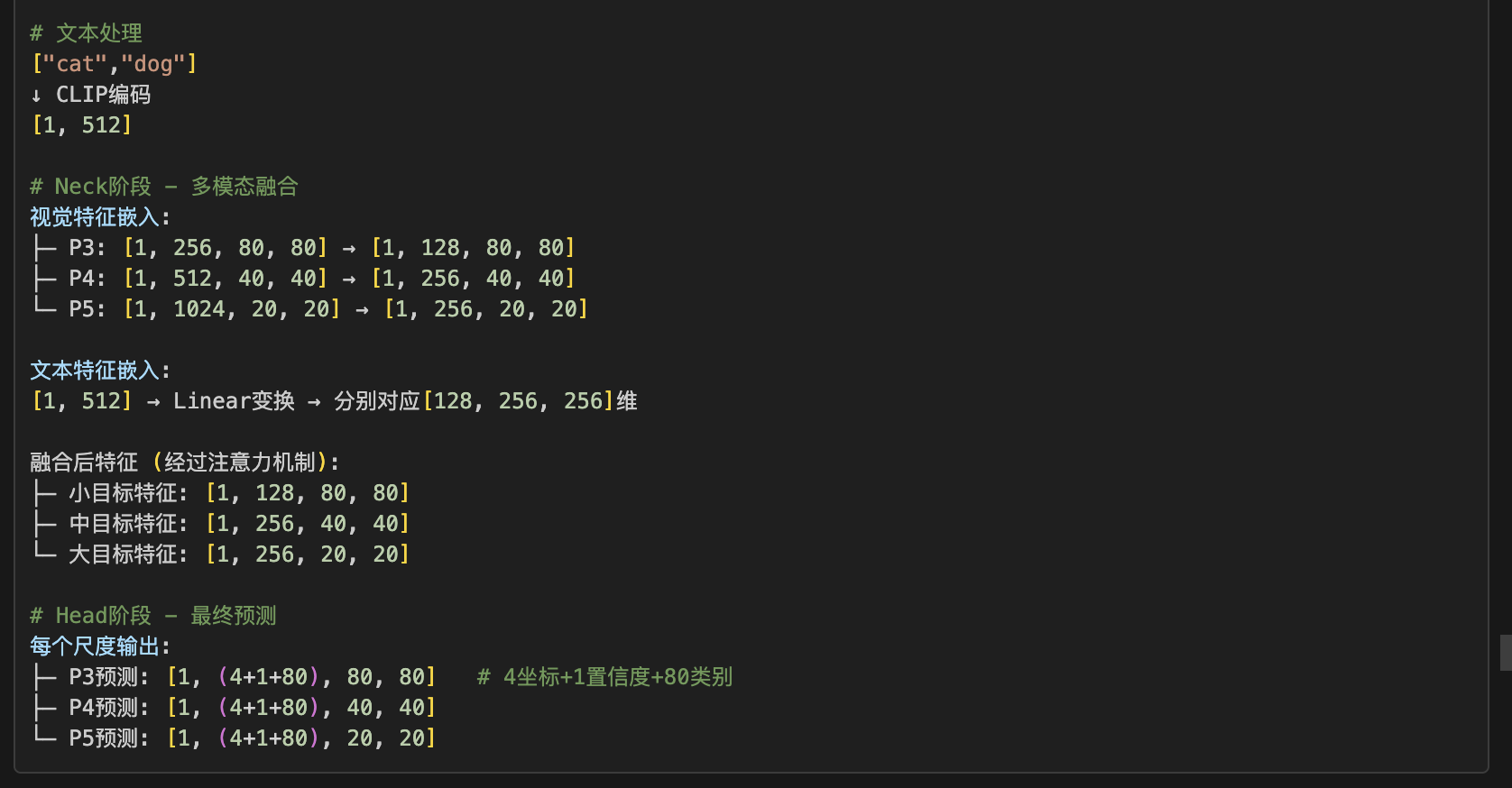
# 🔄 YOLO-World完整数据流程# === 输入层 ===
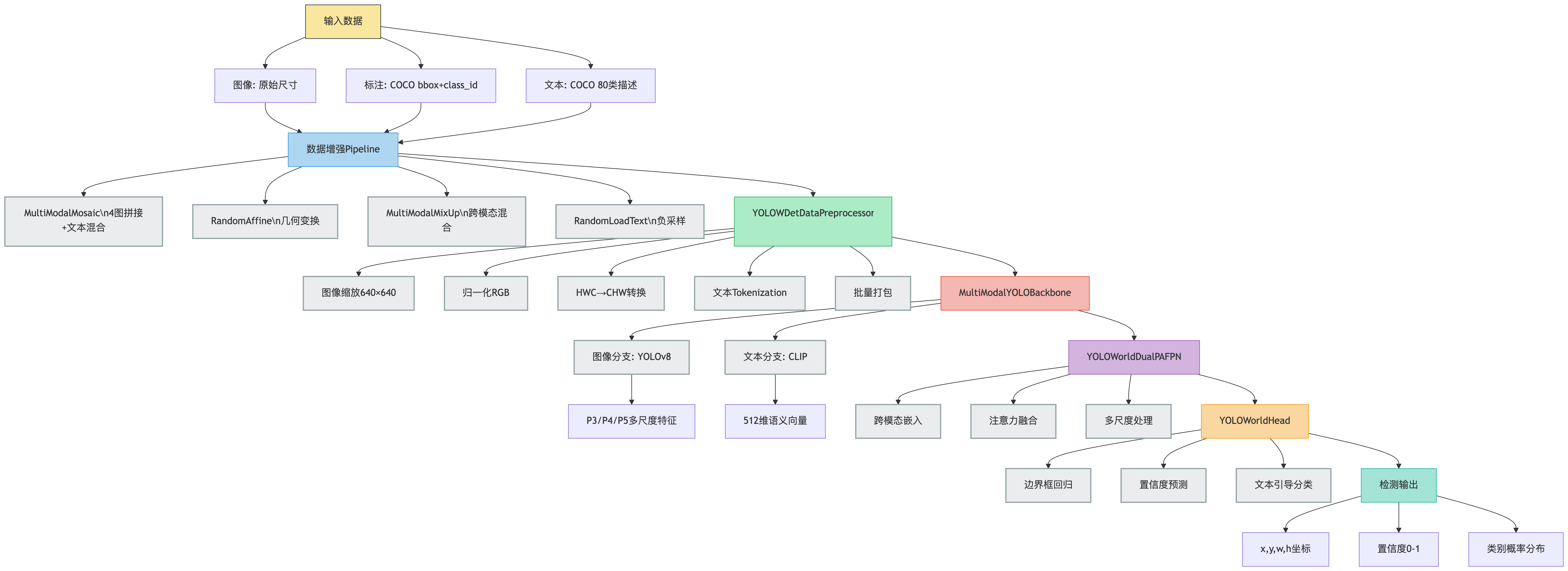
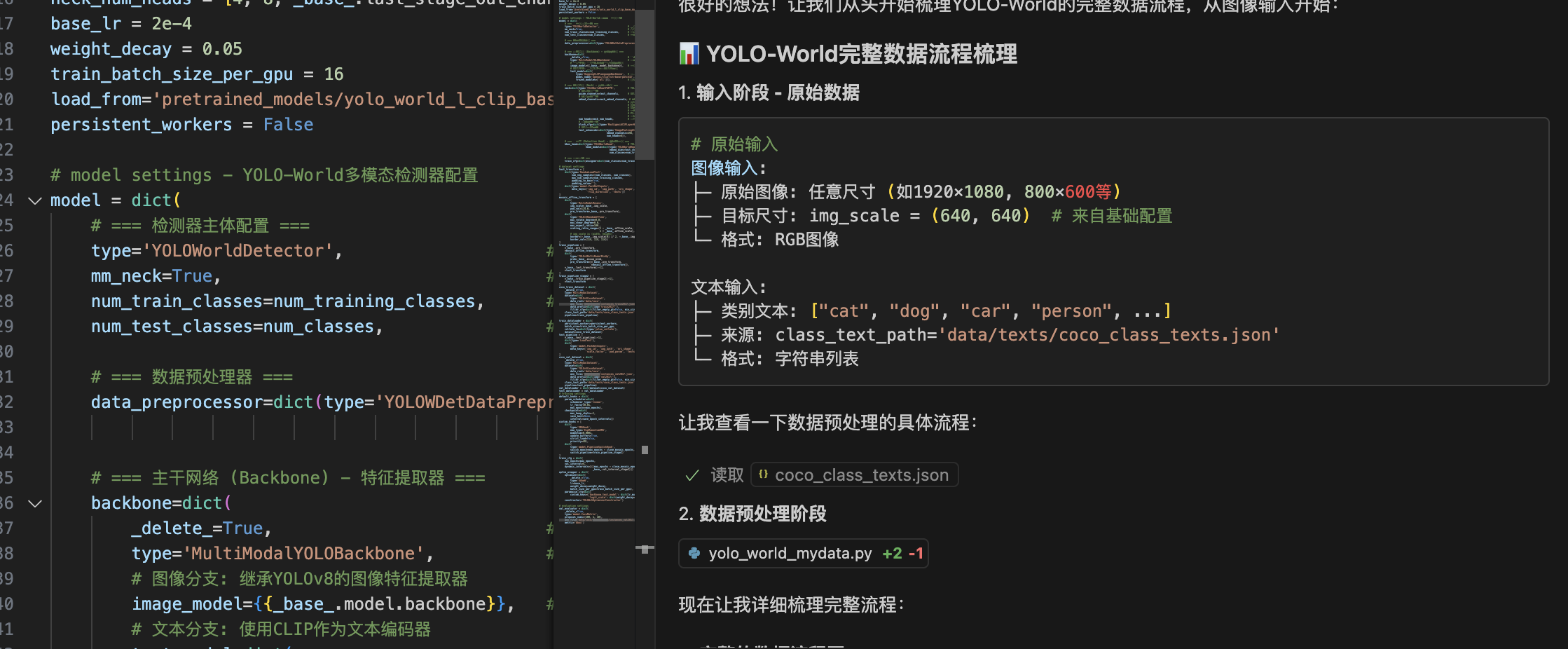
输入数据:
├─ 图像: 原始尺寸图像文件
├─ 标注: COCO格式的bbox + class_id
└─ 文本: COCO 80类的文本描述# === 数据增强层 (训练时) ===
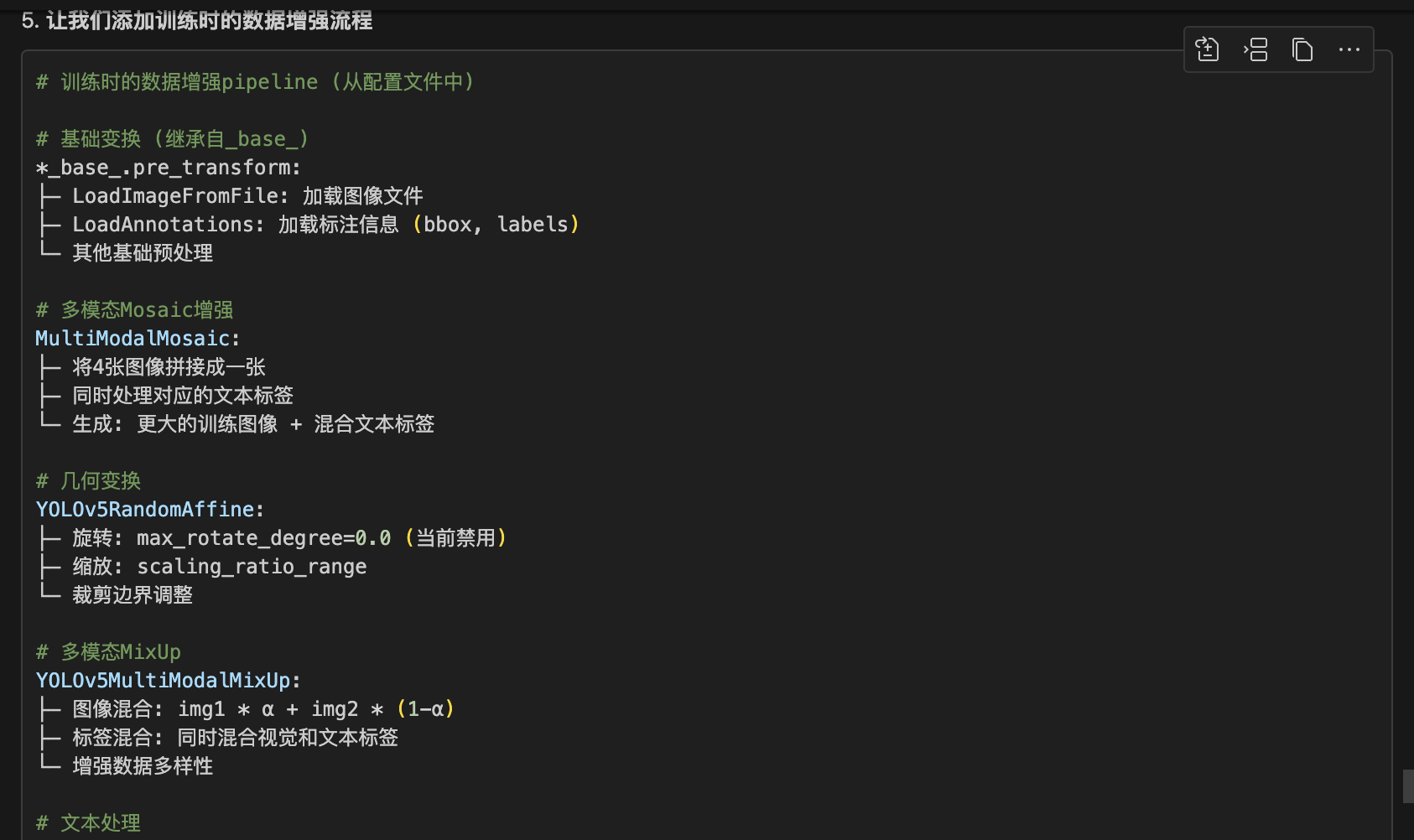
Pipeline增强:
├─ MultiModalMosaic: 4图拼接 + 文本混合
├─ RandomAffine: 几何变换 (旋转、缩放、剪切)
├─ MultiModalMixUp: 图像和文本的混合增强
└─ RandomLoadText: 文本负采样# === 数据预处理层 ===
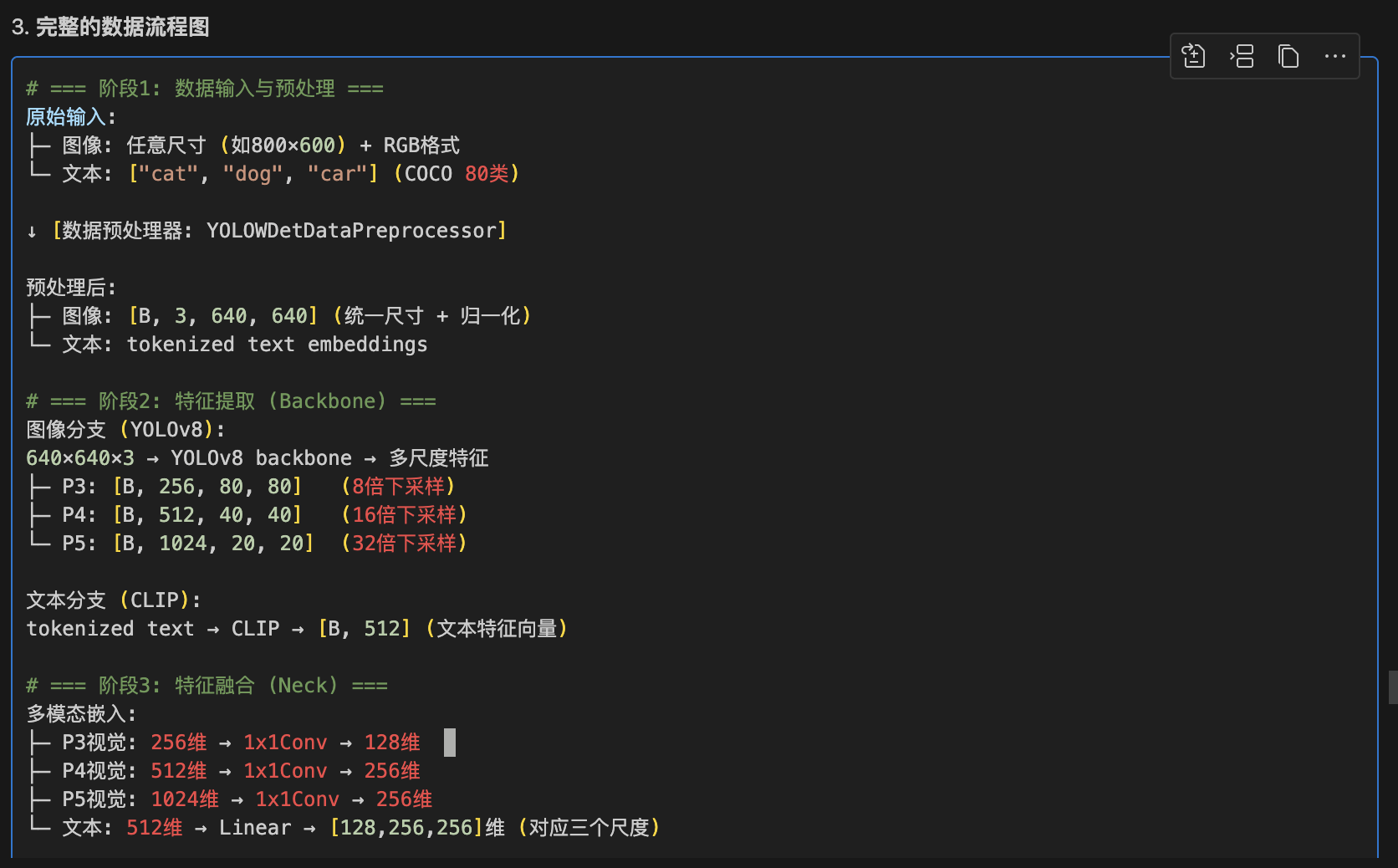
YOLOWDetDataPreprocessor:
├─ 图像缩放: 统一到640×640
├─ 数据归一化: RGB值归一化
├─ 格式转换: HWC→CHW, BGR→RGB
├─ 文本tokenization: 文本转为数值
└─ 批量打包: 组织成batch格式# === 特征提取层 (Backbone) ===
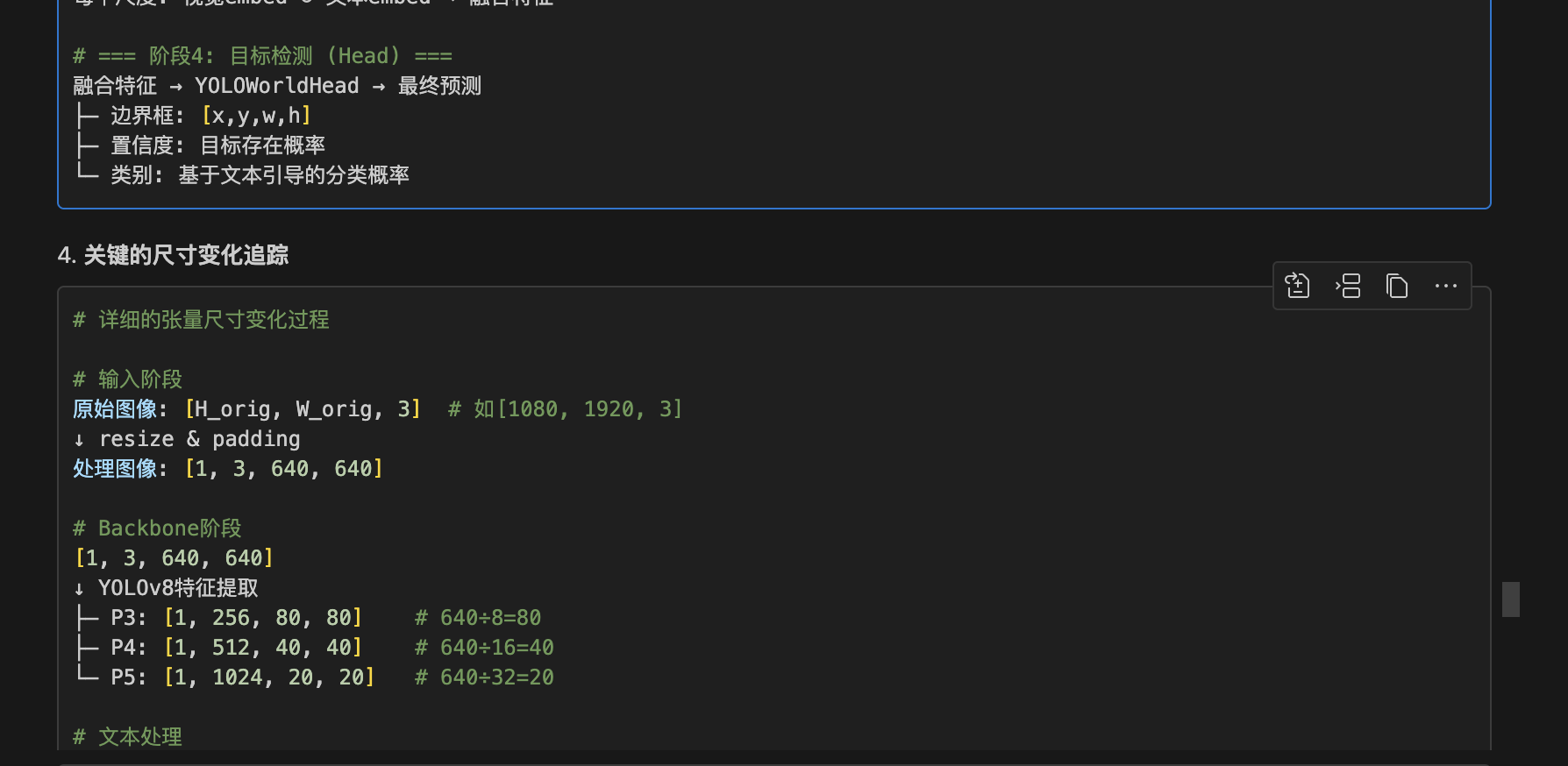
MultiModalYOLOBackbone:
├─ 图像分支: YOLOv8 → P3,P4,P5多尺度特征
└─ 文本分支: CLIP → 512维语义特征# === 特征融合层 (Neck) ===
YOLOWorldDualPAFPN:
├─ 特征嵌入: 视觉和文本统一到embed空间
├─ 注意力融合: 跨模态信息交互
└─ 多尺度处理: 三个检测尺度并行处理# === 预测层 (Head) ===
YOLOWorldHead:
├─ 边界框回归: 预测目标位置
├─ 置信度预测: 预测目标存在概率
└─ 文本引导分类: 基于文本语义的类别预测# === 输出层 ===
最终输出:
├─ 检测框: [x,y,w,h] 坐标
├─ 置信度: 0-1之间的概率值
└─ 类别: 对应文本描述的类别概率
以下是基于YOLO-World数据流程的专业流程图设计(采用Mermaid语法,可直接渲染):
flowchart TD%% === 输入层 ===A[输入数据] --> B[图像: 原始尺寸]A --> C[标注: COCO bbox+class_id]A --> D[文本: COCO 80类描述]%% === 数据增强层 ===B --> E[数据增强Pipeline]C --> ED --> EE --> E1[MultiModalMosaic\n4图拼接+文本混合]E --> E2[RandomAffine\n几何变换]E --> E3[MultiModalMixUp\n跨模态混合]E --> E4[RandomLoadText\n负采样]%% === 预处理层 ===E --> F[YOLOWDetDataPreprocessor]F --> F1[图像缩放640×640]F --> F2[归一化RGB]F --> F3[HWC→CHW转换]F --> F4[文本Tokenization]F --> F5[批量打包]%% === 特征提取 ===F --> G[MultiModalYOLOBackbone]G --> G1[图像分支: YOLOv8]G1 --> G11[P3/P4/P5多尺度特征]G --> G2[文本分支: CLIP]G2 --> G21[512维语义向量]%% === 特征融合 ===G --> H[YOLOWorldDualPAFPN]H --> H1[跨模态嵌入]H --> H2[注意力融合]H --> H3[多尺度处理]%% === 预测层 ===H --> I[YOLOWorldHead]I --> I1[边界框回归]I --> I2[置信度预测]I --> I3[文本引导分类]%% === 输出层 ===I --> J[检测输出]J --> J1[x,y,w,h坐标]J --> J2[置信度0-1]J --> J3[类别概率分布]%% 样式优化style A fill:#F9E79F,stroke:#333style E fill:#AED6F1,stroke:#3498DBstyle F fill:#ABEBC6,stroke:#27AE60style G fill:#F5B7B1,stroke:#E74C3Cstyle H fill:#D2B4DE,stroke:#9B59B6style I fill:#FAD7A0,stroke:#F39C12style J fill:#A3E4D7,stroke:#1ABC9CclassDef tech fill:#EAECEE,stroke:#95A5A6,stroke-width:2pxclass E1,E2,E3,E4,F1,F2,F3,F4,F5,G1,G2,H1,H2,H3,I1,I2,I3 tech
流程图关键说明
-
跨模态交互
- 红色标注的
MultiModalMosaic/MixUp体现视觉-文本联合增强 - 紫色
DualPAFPN中的注意力融合层实现特征对齐
- 红色标注的
-
多尺度处理
- 通过
P3/P4/P5三路特征金字塔保留不同粒度信息 - 最终输出层支持开放词汇检测(文本引导分类)
- 通过
-
工程优化点
- 蓝色背景为数据预处理关键步骤
- 橙色标注的Head层包含YOLO特有的解耦头设计
可视化建议
- 使用暗色背景+高对比色突出流程主线
- 对CLIP文本分支和YOLOv8图像分支采用左右对称布局
- 在注意力融合层添加闪光效果强调跨模态交互
如果需要更详细的架构图(如模块内部实现),可补充绘制子流程图说明各组件连接关系。