第21章 常用的用户调查分析方法
一、核心逻辑
用户调查分析方法分为两类:
- 定性深挖(小样本,信息深度高)→ 焦点小组、用户体验研究
- 定量验证(大样本,统计显著性高)→ 日志分析、问卷调查
目的:弥补AB实验的高成本局限性,通过多方法交叉验证提升结论可靠性。
二、五大方法详解与案例
用户调查分析方法的用户规模和信息深度
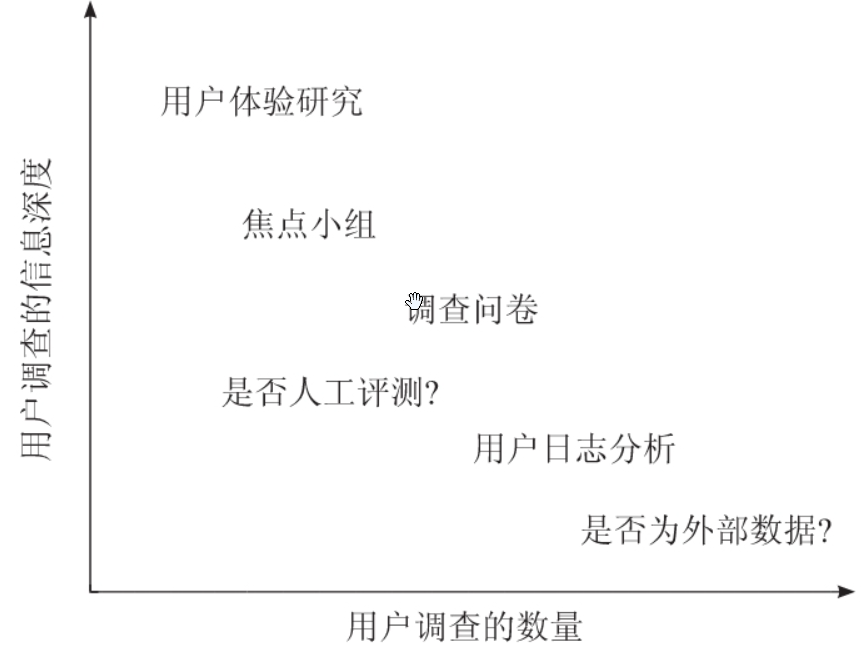
| 方法 | 用户规模 | 信息深度 | 典型场景 |
|---|---|---|---|
| 用户体验研究 | 极少 | ★★★★★ | 实验室观察用户操作眼动轨迹 |
| 焦点小组 | 少 | ★★★★☆ | 组织10人讨论产品概念 |
| 调查问卷 | 中 | ★★★☆☆ | 万人规模满意度调研 |
| 人工评测 | 中 | ★★☆☆☆ | 第三方标注搜索结果相关性 |
| 用户日志分析 | 多 | ★★☆☆☆ | 分析百万用户点击行为路径 |
| 外部数据 | 极多 | ★☆☆☆☆ | 行业报告分析竞品趋势 |
产品阶段适配:
- 早期探索:优先选左上角(高深度),如用户体验研究挖需求;
- 后期验证:转向右下角(大规模),如AB测试+日志分析。
资源分配决策:
- 若需快速验证一个功能对大众用户的影响,优先选调查问卷+日志分析;
- 若需理解小众高端用户痛点,则选焦点小组+用户体验研究。
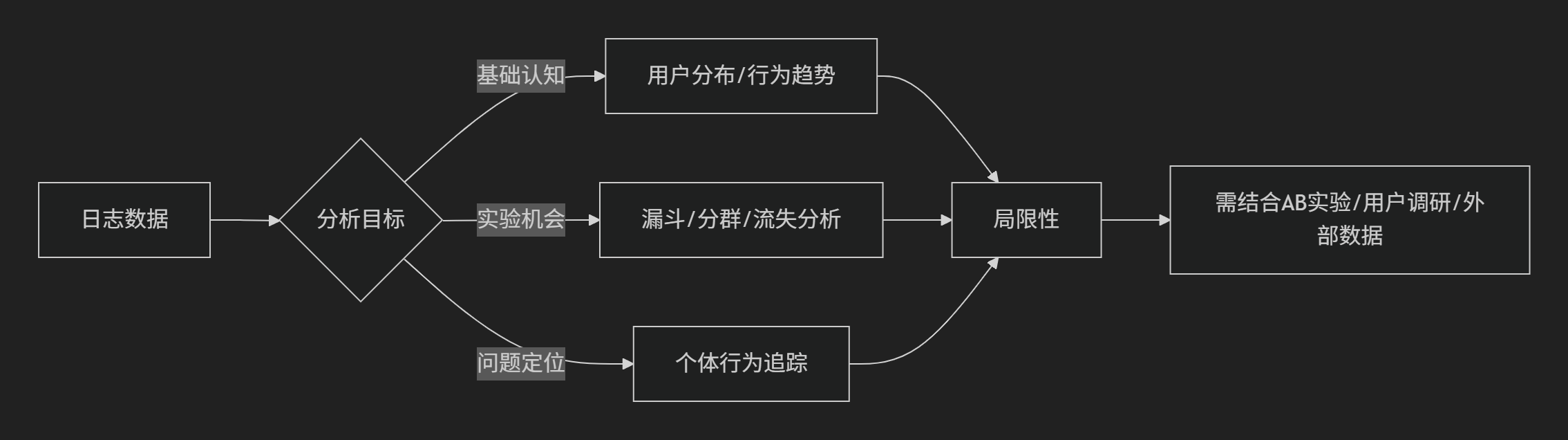
1. 用户日志分析
(1)用户日志分析的核心价值与案例
1. 构建产品数据直觉
作用:通过日志数据建立对用户行为的基础认知,识别自然波动与异常。
案例:
某视频APP发现iOS用户日均观看时长比Android用户高20%。进一步细分发现:
- 一线城市iOS用户:偏好短剧,单次观看时长低但频次高;
- 下沉市场Android用户:偏好长视频,单次观看时长稳定。
- 结论:内容推荐策略需按设备和地域差异化,不能统一优化。
2. 发现AB实验机会
(1) 漏斗分析定位转化瓶颈
案例:
电商平台日志显示“加入购物车→支付”转化率仅15%。拆解发现:
- 支付页跳出用户中,80%停留在“选择支付方式”步骤超过30秒;
- 结合设备日志发现:Android用户因默认支付方式(信用卡)与主流偏好(支付宝)不匹配导致流失。
优化:根据用户历史支付数据预选支付方式,转化率提升至22%。
(2) 用户分群识别低效群体
案例:
教育APP通过日志分群发现:
- “低频高时长”用户:周末集中学习,课程完成率90%;
- “高频低时长”用户:工作日碎片化学习,完成率仅35%。
优化:对后者推送“每日学习目标提醒”,完成率提升至60%。
(3) 时间序列分析流失环节
案例:
社交APP发现新用户7日留存率低。日志追踪显示:
- 流失高峰:注册后第3天(60%用户未完成好友添加);
- 幸存用户:均在48小时内收到至少1条消息互动。
优化:新增“智能破冰消息”功能,7日留存率提高18%。
3. 个体行为追踪(Bad Case分析)
案例:
问题:某资讯APP用户流失率突增。
日志深挖:
- 案例A:用户点击“体育”内容占比90%,但画像标签为“娱乐”→ 推荐内容不匹配,7天后流失;
- 案例B:用户仅通过预装渠道启动,点击内容多为低质软广→ 渠道用户质量差,自然流失。
解决方案:
- 优化兴趣标签算法(案例A);
- 关闭低质渠道推广(案例B)。
(2)用户日志分析的三大局限性与应对
1. 仅反映历史行为,无法预测未来
案例:
某工具类APP发现“邮件附件”功能使用率仅1%,决定砍掉该功能。后续用户访谈却揭示:
- 真实原因:附件上传流程复杂(需5步操作),非需求不足。
- 教训:日志需结合用户反馈(如NPS调查)判断功能价值。
2. 仅显示相关性,无法验证因果
案例:
日志显示“活跃用户”与“互动频次”高度相关,但无法确定:
- 是活跃导致用户更愿意互动?
- 还是互动促进了活跃度?
解决方法:
- 设计AB实验,对随机用户组强制推送互动任务,对比活跃度变化。
3. 数据盲区(无法记录离线/主观因素)
案例:
外卖APP发现午间订单下降,日志未显示异常。线下调研发现:
- 真实原因:写字楼新增食堂,用户转向线下就餐。
- 应对:需结合外部数据(如竞品趋势、线下调研)。
(3)用户日志分析的最佳实践
数据整合:前端埋点(按钮点击、页面停留)+ 后端日志(订单、登录)拼接完整链路。
例:电商用户从“搜索关键词→商品详情页→加购→支付”全流程追踪。交叉验证:日志发现“支付失败率上升” → 结合客服工单数据发现“某银行接口故障”。
动态监控:设置关键指标(如DAU、转化率)的自动预警阈值,实时响应异常。
(4)总结:用户日志分析的核心逻辑
2. 调查问卷
1、问卷调查的核心价值
1. 解决日志数据无法回答的问题
场景案例:
某电商App发现用户将商品加入购物车后放弃支付的比例高达70%。日志仅显示行为路径,但通过问卷发现:
- 运费敏感(35%):用户在支付页才看到运费,产生“价格锚定偏差”(商品价+运费>心理预期)。
- 比价行为(28%):用户跳转至其他平台比价,发现更低价后流失。
关键洞察:
- 运费展示时机和比价便利性是转化率的关键瓶颈。
- 这些原因属于用户决策心理和跨平台行为,日志数据无法直接捕捉。
优化:隐藏运费至支付前最后一步,并增加“全网比价”功能,支付转化率提升22%。
2. 衡量主观体验(信任/满意度)
- 案例:
银行APP通过季度NPS(问用户“多愿意推荐此功能”)调查发现:
- 用户对“刷脸登录”的信任度仅为6.2分(10分制),说明用户担心安全性。
- 深挖原因:开放式问题反馈“担心人脸数据被滥用”。
- 解决方案——上线弹窗解释:“您的脸数据已加密,仅用于登录,绝不外泄”。用户信任分涨到8.1分,因为知道了数据如何被保护,打消了顾虑。
2、问卷设计的四大雷区与规避策略
1. 引导性问题(诱导答案)
- 错误示例:❌ “您是否喜欢我们全新的、更流畅的界面?”(暗示“新界面更好”)
- 正确做法:
✅ “您对新版界面的使用体验如何?”(中性表述)
✅ 提供5级量表(从“非常不满意”到“非常满意”)。
2. 问题顺序偏差
案例:
错误顺序:
先问「是否关注环保?」 → 激活用户的「环保认同感」
- 紧接着问「是否愿为环保多付钱?」 → 用户被“环保”标签绑架,高估支付意愿。
类似场景
先问“您爱国吗?”再问“是否愿买国货贵10%?”,也会虚高结果。
人们会无意识地保持回答的前后一致:若先声明“关注环保”,后续不愿为环保付费会显得虚伪 → 被迫选择“愿意”。
解决方案
- AB测试问卷顺序:随机让50%用户先问环保态度,50%先问支付意愿,对比结果差异。
- 心理学本质:排除「问题引发临时性道德光环」对答案的干扰,捕捉真实决策动机。
问卷像谈话——先聊理想(环保)再谈钱,人会装大方;先谈钱再聊理想,才暴露真实底线。
3. 幸存者偏差(样本失真)
- 典型案例:
某游戏问卷显示90%玩家“每日在线>2小时”,但日志数据实际仅30%。
原因:仅活跃玩家愿意填问卷。
解决:- 通过推送奖励(如游戏金币)激励非活跃用户参与;
- 对比问卷样本与大盘用户画像的匹配度。
4. 绝对数据误读
- 案例:
问卷显示“50%用户对客服不满意”,但未说明基线(过去为70%不满意)。
正确解读:相对改善比绝对值更重要。
3、高阶应用:问卷+日志的交叉验证
1. 行为与态度的矛盾分析
- 案例:
视频App用户问卷中“广告体验”评分平均8分,但日志显示:
- 90%用户5秒内跳过广告;
- 广告点击率仅0.3%。
结论:用户“口头宽容”但行为诚实,需优化广告相关性而非单纯减量。
2. 与AB实验联动
- 操作流程:
 案例:
案例:某工具类APP实验“智能排版”功能,日志显示使用率仅5%,但问卷中实验组满意度显著更高。
决策:保留功能但改进引导教育(因核心用户需求存在)。
4、特殊场景下的问卷创新
1. 实时情境化调查
- 案例:
用户在支付失败后,立即弹出简短问卷:
❓ “您放弃支付的原因是?”(选项:价格高/流程复杂/其他)。
结果:63%选择“流程复杂”,针对性简化后支付成功率提升18%。
2. 长周期追踪调查
- 案例:
智能硬件公司购买后3个月问:“您过去一个月使用本产品的频率?”
发现早期宣传的“每日健康监测”实际周均使用1.2次,调整营销重点至“按需使用”。
5、避坑清单
- 样本量:单细分群体(如VIP用户)至少200份有效问卷。
- 开放题:不超过3题,避免用户疲劳(如“请用一句话描述您的痛点”)。
- 时间控制:完成时间<2分钟,完成率可提升50%+。
- 版本管理:记录每次问卷修改,避免历史数据对比失效。
6、总结
问卷调查是“用户说”与“用户做”之间的桥梁,但需警惕:
- 不能替代行为数据(如用户声称愿意付费≠实际支付);
- 必须与其他方法交叉验证(如AB实验、日志分析)。
- 核心原则:明确目标(测态度?挖原因?),设计匹配问题,永远质疑样本代表性。
3. 焦点小组
焦点小组(Focus Group)是一种小规模、互动式的用户研究方法,通过组织6-10名目标用户进行开放式讨论,挖掘潜在需求、态度和情绪反馈。
1. 焦点小组的核心特点
- 适用场景:
- 早期产品概念测试(如包装设计、广告创意);
- 探索用户隐性需求(如“为什么不喜欢某功能”)。
- 优势:
- 深度互动:用户之间的讨论能激发新观点(如A用户吐槽后,B补充类似经历);
- 非结构化:可灵活追问(如“你刚才说的‘难用’具体指什么?”)。
- 局限性:
- 群体压力:用户可能附和多数人意见(如飞利浦音箱案例);
- 言行不一:口头表达与实际行为脱节(如声称爱环保却选黑色音箱)。
2. 经典案例:飞利浦音箱的“颜色陷阱”
- 背景:飞利浦想设计一款针对青少年的音箱,焦点小组中展示黑、黄两色原型。
- 讨论结果:
- 参与者集体称赞黄色“时尚、叛逆”,贬低黑色“保守、过时”;
- 主持人记录结论:黄色更受欢迎。
- 实际行为:结束时让用户任选一款带走,80%选了黑色。
- 原因分析:
- 社交表演:青少年在群体中倾向标榜个性(选黄色);
- 真实偏好:私下考虑实用性和耐脏(黑色更稳妥)。
- 教训:焦点小组的“表面共识”可能掩盖真实需求,需结合行为数据验证。
3. 焦点小组的正确打开方式
(1) 设计阶段:如何提问?
- 避免引导性问题:
❌ “你们觉得这个新功能是不是很创新?”
✅ “这个功能给你们什么感觉?能联想到什么?” - 用具体场景触发反馈:
“想象你在加班时突然想点外卖,看到这个界面会怎么做?”
(2) 执行阶段:减少群体偏差
- 分小组对比:同一主题组织2-3组,对比结论是否一致;
- 匿名投票:敏感问题(如价格接受度)先匿名填表,再讨论原因。
(3) 分析阶段:识别“假共识”
- 关注矛盾点:若所有人一致赞同,需警惕群体思维;
- 结合行为数据:
某APP焦点小组称“爱看长视频”,但日志显示平均观看时长仅90秒 → 用户可能混淆“理想自我”和真实行为。
4. 焦点小组 vs 其他方法
| 维度 | 焦点小组 | 问卷调查 | 用户体验测试 |
|---|---|---|---|
| 样本量 | 6-10人 | 100+人 | 5-8人 |
| 信息类型 | 态度、情绪、群体互动 | 量化数据、广泛趋势 | 具体行为痛点 |
| 适用阶段 | 早期概念验证 | 中后期大规模验证 | 功能原型测试 |
| 典型问题 | “你们如何看待这种设计?” | “给此功能打分(1-5分)” | “请完成下单流程并吐槽” |
5. 实战案例:电商APP的“购物车焦虑”
- 目标:了解用户放弃购物车的原因。
- 焦点小组发现:
- 用户A:“总担心还有更低价,不敢下单”;
- 用户B:“希望有人帮我做决定,比如显示‘库存仅剩3件’”。
- 后续行动:
- 新增“全网比价”和库存紧张提示,购物车转化率提升15%;
- 关键点:焦点小组揭示了“决策恐惧”这一日志无法捕捉的心理因素。
6. 总结:焦点小组的生存法则
- 用对场景:适合探索“为什么”,而非测量“有多少”;
- 警惕表演:用户可能在扮演“理想消费者”,需用实际选择验证(如飞利浦案例);
- 交叉验证:结论必须结合其他数据(如AB测试、日志分析)。
记住:焦点小组是“显微镜”,能看清细节,但别用它来丈量整个森林。
4. 用户体验研究(实地/实验室)
用户体验研究(UX Research)是通过直接观察用户行为和深度互动来发现产品问题的核心方法。与焦点小组或问卷不同,它更关注用户实际怎么做(而非怎么说)。
1. 核心方法论与适用场景
| 类型 | 实验室研究 | 实地研究 |
|---|---|---|
| 环境 | 受控实验室(如单向镜、眼动仪) | 用户真实场景(家庭/办公室/商店) |
| 优势 | 高精度数据(如点击热图、注视轨迹) | 发现环境干扰因素(如网络差、多任务) |
| 典型案例 | 电商结账流程优化 | 智能家居设备实际使用痛点 |
何时使用?
- 产品存在高流失环节(如支付失败);
- 需要理解复杂行为动机(如为什么忽略关键功能)。
2. 经典案例解析
案例1:电商优惠券找不到(实验室研究)
- 问题:某平台发现“购物车→支付”转化率低,但日志未显示明确障碍。
- 实验室测试:
- 让10名用户在实验室完成购买任务;
- 通过眼动仪发现:80%用户视线完全跳过“领券入口”(位于页面右上角角落);
- 用户访谈:“以为优惠券会自动生效,没注意到要手动领”。
- 解决方案:
- 将领券入口移至“总价下方”+ 红点提示;
- 转化率提升18%。
关键点:实验室设备(眼动仪)揭示了视觉盲区,这是问卷或日志无法捕捉的。
案例2:外卖APP现场观察(实地研究)
- 问题:骑手端APP投诉率高,但线上反馈模糊。
- 实地调研:
- 跟随5名骑手送餐,观察其操作;
- 发现:订单导航默认“最短距离”而非“最省时”,导致骑手频繁逆行/闯红灯;
- 骑手原话:“系统逼我违规,否则超时罚款”。
- 解决方案:
- 算法增加“交通规则合规路径”;
- 骑手投诉率下降40%。
关键点:实地研究暴露了环境与系统的冲突,这是实验室无法模拟的。
3. 特殊技术工具的应用
- 眼动追踪(实验室):
- 适用问题:广告位是否被看见?
- 案例:某新闻APP发现“重要新闻”被放置在用户视线停留仅0.3秒的区域,调整后点击率提升2倍。
- 行为录像分析(实地):
- 适用问题:用户如何自然使用产品?
- 案例:智能音箱用户实际会对着设备大喊指令(非预设唤醒词),优化语音触发灵敏度。
4. 如何避免常见陷阱?
- 陷阱1:霍桑效应
- 问题:用户在实验室可能改变自然行为(因被观察)。
- 解法:前15分钟不记录,让用户适应环境。
- 陷阱2:样本偏差
- 问题:招募的“热心用户”不代表沉默大多数。
- 解法:强制覆盖不同层级用户(如新/老/流失用户)。
5. 用户体验研究的不可替代性
- 对比其他方法:
方法 能回答的问题 不能回答的问题 日志分析 用户点击了什么? 为什么忽略按钮A? 问卷调查 用户说自己喜欢什么? 实际如何使用功能? 用户体验研究 用户如何决策?视觉焦点在哪? 大规模统计趋势(需AB测试)
核心价值:
- 发现“用户自己都没意识到的”问题(如视觉习惯);
- 为AB实验提供假设来源(如“改导航路径可能减少骑手违规”)。
6. 总结
用户体验研究是产品优化的显微镜:
- 实验室研究:精准定位界面问题(如眼动追踪);
- 实地研究:还原真实场景痛点(如外卖骑手困境);
- 必须结合量化数据(如后续AB测试验证)。
记住:当用户说“没问题”但数据表现差时,永远相信他们的行为而非语言。
5. 人工评测
人工评测是搜索、推荐、内容审核等系统的核心评估手段,通过训练有素的评测员对内容质量、相关性等进行标注,弥补算法和自动化工具的不足。
1. 人工评测的核心应用场景
(1) 搜索/推荐系统的相关性评估
- 案例:电商搜索排序优化
某平台发现“iPhone 手机壳”搜索结果的点击率低,但日志无法解释原因。人工评测发现:
- 前10结果中,3个是安卓手机壳(算法误匹配“手机壳”关键词);
- 2个是iPhone贴膜(类目分类错误)。
优化:调整语义匹配模型,准确率提升35%。
(2) 内容安全与质量审核
- 案例:短视频低质内容过滤
算法自动审核误杀率高达20%(如误判“医疗科普”为违规)。人工评测规则:
- 扣分项:标题党(扣2分)、画面模糊(扣1分)、诱导点击(扣3分);
- 通过标准:总分≥6分方可推荐。
- 结果:误杀率降至5%,且低质内容曝光量减少60%。
(3) A/B实验的辅助决策
- 案例:新闻APP标题优化实验
算法生成A(标题A)和B(标题B),日志显示A点击率高10%,但人工评测发现:
- A标题含误导性夸张(如“震惊!”);
- B标题信息更准确。
- 决策:优先B标题,避免长期损害用户信任。
2. 评测流程与质量控制
(1) 评测任务设计
- 简单任务:二选一(如“哪个结果更相关?”)
- 复杂任务:多维度打分(如下表)
| 维度 | 评分标准(0-5分) | 案例说明 |
|---|---|---|
| 相关性 | 结果是否完全匹配查询意图? | 搜索“减肥餐”出现甜品食谱→1分 |
| 时效性 | 内容是否过时? | 3年前的新闻→0分 |
| 内容质量 | 是否低质/标题党? | “不看后悔!”→扣分 |
(2) 避免评测偏差的策略
- 多人交叉校验:同一任务由3名评测员独立完成,取多数意见;
- 黄金标准测试:混入已知正确答案的任务,淘汰准确率<90%的评测员;
- 动态校准:每周更新评测指南,同步算法迭代(如新增“AI生成内容”识别标准)。
3. 经典行业案例
案例1:Google搜索的“并排评测”
- 背景:评估搜索算法A和B的优劣。
- 方法:
- 同一查询下,A/B算法的结果左右并列显示;
- 评测员选择“哪侧更优”或“无差异”;
- 统计胜率(如A胜60%,B胜30%,平局10%)。
- 价值:避免绝对评分的主观性,聚焦相对体验。
案例2:字节跳动的推荐系统冷启动评测
- 问题:新用户兴趣不明时,推荐内容质量不稳定。
- 解法:
- 人工标注种子内容:对百万级文章打标签(如“体育-篮球”“科技-AI”);
- 冷启动兜底策略:新用户优先推荐高标注分内容(如评分≥8分)。
- 结果:新用户首日留存率提升12%。
4. 人工评测的局限性
人工评测虽能解决算法盲区(如内容质量判断),但存在用户场景偏差、成本高、主观性三大局限,需通过数据补充、AI协同和标准化流程来优化。
(1) 与真实用户的差距
- 案例:方言搜索偏差
评测员将“嘻嘻”统一标注为“表情包需求”,但实际用户可能是搜索“嘻嘻村”(地名)。
解法:补充地域特征数据,区分语义场景。
(2) 成本与效率瓶颈
- 案例:Facebook内容审核
每日需审核百万级帖子,纯人工成本过高。
优化:AI自动过滤95%内容,人工仅复核疑似违规case。
(3) 主观标准不一致
- 案例:奢侈品电商的“质量”评分
评测员对“皮革瑕疵”的容忍度差异大(有人扣1分,有人扣3分)。
解法:提供标准实物样本图库(如“何种划痕算3分瑕疵”)。
5. 人工评测的未来趋势
- AI辅助标注:算法预标注结果,人工仅修正错误(如OpenAI的RLHF技术);
- 众包评测平台:亚马逊Mechanical Turk模式,快速获取多样化标注数据;
- 实时动态评测:抖音部分直播间安排人工实时监测违规内容,5秒内干预。
6. 总结:人工评测的生存法则
- 明确目标:回答算法不能解决的问题(如内容主观质量);
- 交叉验证:结合用户行为数据(如点击率)修正偏差;
- 持续迭代:评测标准需随产品/算法进化同步更新。
记住:人工不是“落后手段”,而是人机协同中不可替代的认知层防线。
6. 外部数据
| 用途 | 案例 |
|---|---|
| 指标归因 | 游戏DAU暑期上涨30%,竞品同期均涨→ 归因假期而非产品优化 |
| 相关性验证 | 研究发现用户停留时长与满意度正相关 → 将时长作为OEC实验指标 |
| 证据强化 | 引用Google研究证实“页面加载速度影响留存” → 内部优先投入性能优化 |
| 竞品对标 | 电商GMV增速仅为行业均值50% → 预警需重构货品策略 |
外部数据是企业跳出内部视角、理解市场全局的关键工具,尤其在验证趋势、竞品对标和用户洞察中不可或缺。
1. 核心应用场景与案例
(1) 归因分析:区分内部问题与外部影响
- 案例:在线教育暑期波动
某K12网课平台发现2023年7月用户活跃度环比下降15%,但外部数据(如QuestMobile)显示:
- 行业TOP3竞品同期均下滑10%-20%;
- 国家同期发布“暑期线下研学”政策扶持。
- 结论:下跌主因是政策导向+行业周期性,非产品问题,避免错误投入改版。
(2) 指标替代:用可测数据替代主观指标
- 案例:搜索满意度优化
Google学术论文指出:搜索任务完成时间与用户满意度相关系数达0.81。某电商平台据此:
- 将“搜索响应时间<1秒”设为核心指标;
- 优化后NPS(净推荐值)提升12%,省去高频满意度调研成本。
(3) 竞品对标:定位差距
- 案例:外卖APP配送时效
内部数据显示平均送达时长35分钟,但第三方报告(如美团财报)披露行业头部为28分钟。
行动:- 引入动态路径规划算法;
- 6个月后缩短至29分钟,市场份额提升5%。
(4) 用户冷启动:丰富画像维度
- 案例:金融APP的信用评估
新用户注册时,通过运营商数据(如手机号使用时长)和电商消费数据(如天猫品类偏好),补充信用模型。
结果:首贷通过率提高18%,坏账率下降3%。
2. 外部数据的主要来源
| 类型 | 典型数据源 | 应用场景 |
|---|---|---|
| 行业报告 | QuestMobile、艾瑞咨询 | 趋势分析、竞品对标 |
| 公开数据 | 国家统计局、上市公司财报 | 宏观经济关联分析 |
| 第三方SDK | 友盟、TalkingData | 用户跨APP行为画像补充 |
| 学术研究 | Google/Microsoft等发表的论文 | 技术方案可行性验证 |
3. 使用陷阱与解决方案
(1) 数据口径不一致
- 问题:外部报告的“DAU”可能包含Web端,而内部仅统计APP端。
- 解法:要求数据源提供计算逻辑文档,对齐统计维度。
(2) 样本偏差
- 案例:某第三方报告称“Z世代偏好短视频”,但样本仅覆盖一线城市。
- 解法:交叉验证多数据源(如结合国家统计局城乡分布数据)。
(3) 数据时效滞后
- 问题:行业报告数据更新周期为季度,无法应对实时决策。
- 解法:采购实时数据接口(如极光推送的实时活跃设备数)。
4. 经典行业案例
案例1:Netflix的内容采购决策
- 方法:
- 分析HBO、Disney+等竞品的内容播放量排行榜;
- 结合IMDb评分数据筛选高潜力题材;
- 优先采购同类剧集(如《纸牌屋》对标《权力的游戏》政治剧标签)。
- 结果:新剧续订率提升25%。
案例2:SHEIN的爆款预测模型
- 步骤:
- 爬取Instagram、TikTok热门标签(如#Y2K风);
- 关联Google Trends区域搜索热度;
- 快速打样投放测试,7天内决定是否量产。
- 优势:从设计到上架仅需2周,碾压ZARA的3个月周期。
5. 如何有效落地?
- 明确问题:先定义“需要外部数据回答什么”(如“是行业问题还是我司问题?”);
- 数据清洗:过滤噪声(如某平台刷量数据);
- 内外数据融合:用户购买行为(内部) + 天气数据(外部) → 预测雨天促销备货量。
6. 总结
外部数据是企业的“雷达系统”:
- 短期:避免闭门造车(如误判行业波动为自身故障);
- 长期:发现新机会(如SHEIN抓取社交趋势)。
- 关键原则:绝对数值谨慎对待,相对趋势和交叉验证优先。
四、选择方法的决策逻辑
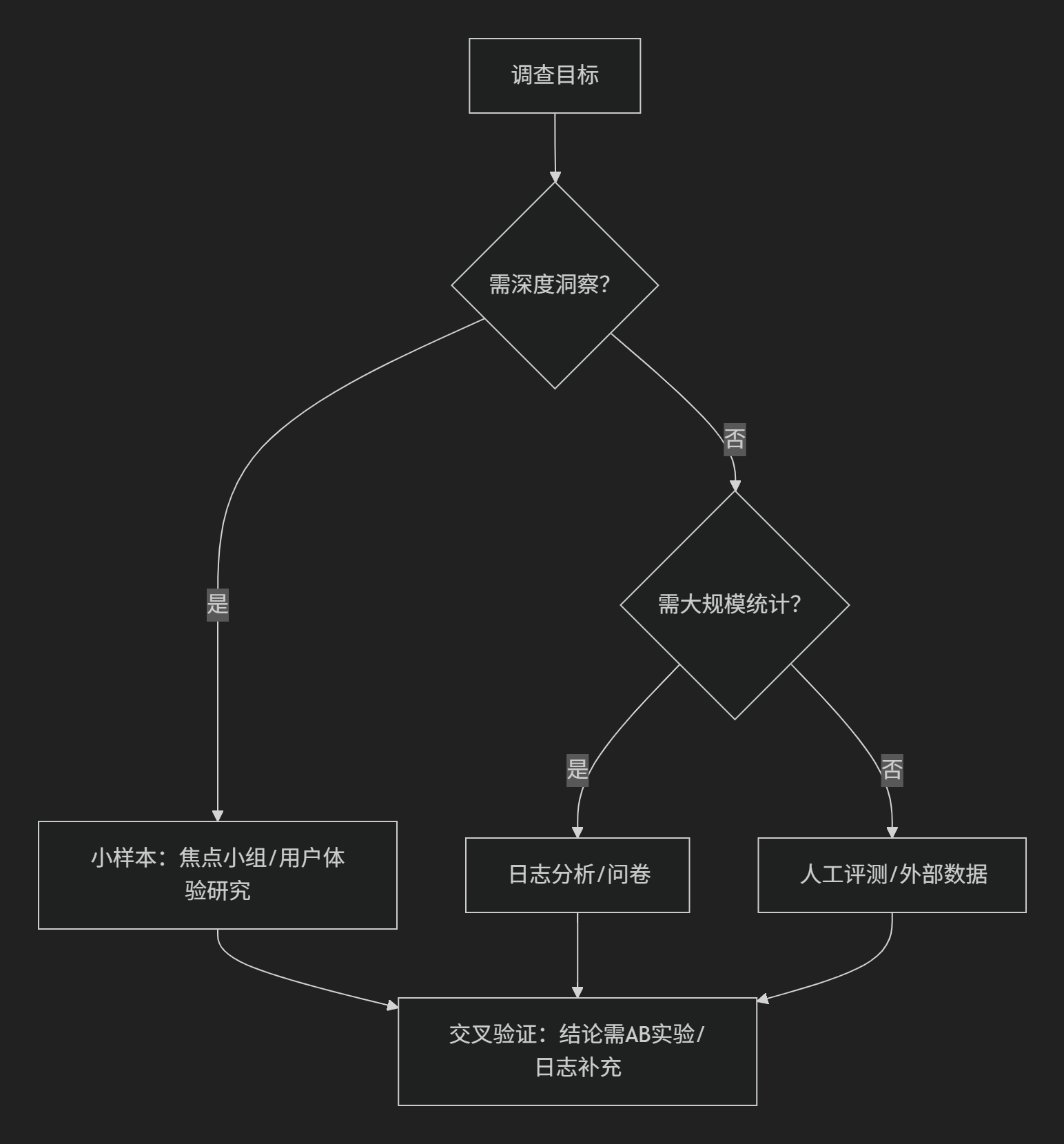
关键原则:
- 低成本验证:用问卷/日志预筛高成本想法(如仅影响1%用户的功能不做AB实验)
- 多源互补:日志发现行为异常 → 用户访谈挖掘动机 → 问卷量化问题普适性
来源书籍:——刘玉凤《AB实验:科学归因于增长的利器》
