彻底掌握双列集合——Map接口以及实现类和常用API及其底层原理
目录
前言
双列集合
Map
常见API
遍历方式
HashMap实现类
LinkedHashMap实现类
TreeMap实现类
可变参数
Collections
前言
学习之前如果单列集合不了解的,可以看上期文章。
双列集合
特点:
一次能存一对元素(两个元素),这两个元素一一对应;
左边的叫做键,右边的叫做值;键不可以重复,值可以重复。
键和值 这个整体称为“键值对”或者“键值对象”,在java中叫做“Entry对象”。
Map
Map接口:有两个实现类,HashMap、TreeMap;其中LinkedHashMap类继承于HashMap
Map是双列集合的顶层接口,它的功能是全部双列集合都可以继承使用的。
常见API
V put(K key, V value):添加元素(如果添加的键值对的键重复了,那么就会覆盖,把最近添加的键值对加入集合,把之前的覆盖,并且返回之前键值对的值)
V remove(Object key):根据键删除键值对元素
void clear():移除所有的键值对元素
boolean containsKey(Object key):判断集合是否包含指定的键
boolean containsValue(Object value):判断集合是否包含指定的值
boolean isEmpty():判断集合是否为空
int size():集合的长度,也就是集合中键值对的个数
遍历方式
第一种:(键找值)

第二种:(键值对)

第三种:(Lambda表达式)
default void forEach(BiConsumer<? super K, ? super V> action):结合lambda遍历Map集合

HashMap实现类
无序:存和取的顺序不一样。
不重复:键是不能重复的。
无索引。
和HashSet底层原理一样,都是哈希表结构。(利用键计算哈希值,跟值无关)
于HashSet不同的点是:当计算出来的索引位置已经有键值对时,跟HashSet一样用equals方法比较键,如果键一样就覆盖,如果不一样时,新元素直接挂在老元素的下面形成链表。(当链表长度超过8并且数组长度大于等于64时,自动转为红黑树)
如果键存储的是自定义对象,就要重写hashCode与equals方法;如果值是自定义对象,就不需要重写hashCode与equals方法。
LinkedHashMap实现类
有序:存和取的顺序一致。(由键决定)
不重复、无索引(由键决定)
原理:底层数据结构是哈希表,只是每个键值对元素有额外的多了一个双链表的机制记录存储顺序。
TreeMap实现类
由键决定:不重复、无索引、可排序
底层原理跟TreeSet一样,都是红黑树结构
可排序也是和TreeSet一样。
方式一:实现Comparable接口,指定规则
方式二:创建集合时传递Comparator比较器对象制定规则
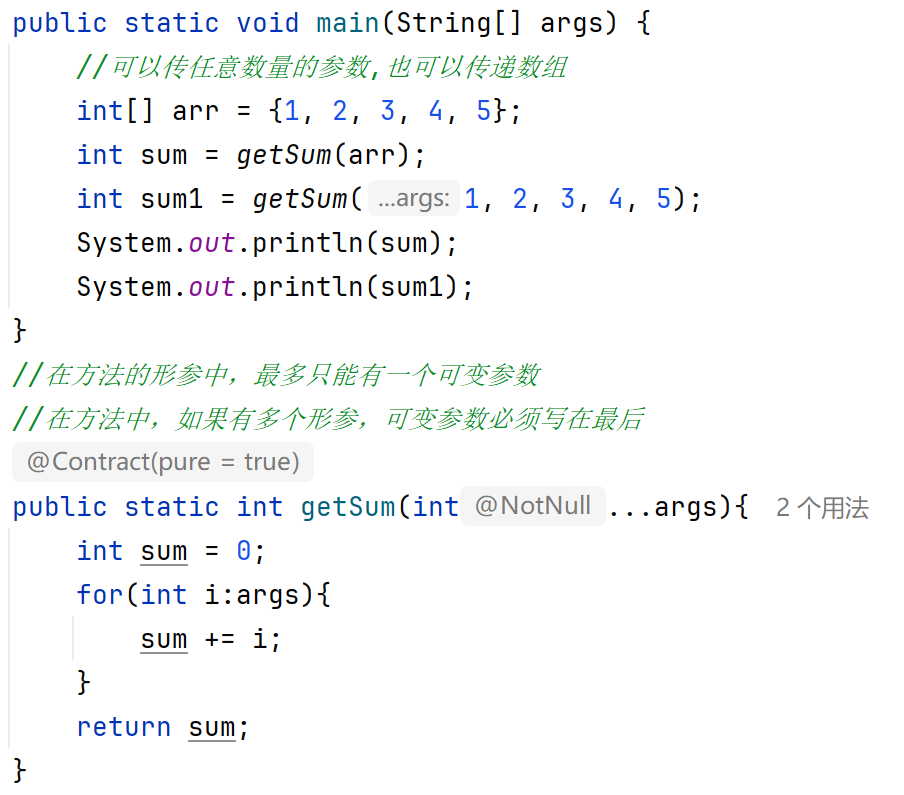
可变参数
格式:属性类型...名字;举例:int...a;
可变参数的底层就是一个数组。
Collections
不是集合,是集合的工具类。
public static ‹T › boolean addAll(Collection<T>c, T... elements):批量添加元素
public static void shuffle(List<?> list):打乱List集合元素的顺序
public static ‹T› void sort (List<T> list):排序
public static ‹T› void sort(List<T > list, Comparator<T> c):根据指定的规则进行排序
public static ‹T› int binarySearch (List‹T> list, T key) ;以二分查找法查找元素
public static ‹T› void copy(List<T > dest, List<T> src) ;拷贝集合中的元素
public static ‹T › int fill (List<T > list, T obj) :使用指定的元素填充集合
public static ‹T› void max/min(Collection<T > coll):根据默认的自然排序获取最大/小值
public static ‹T› void swap (List‹?> list, int i, int j): 交换集合中指定位置的元素