课题学习笔记2——中华心法问答系统
1 任务
进行环境配置,对基本代码进行阅读,理解代码的结构、主要功能模块的代码实现。
该系统是基于语义相似度的问答系统。利用BERT 将文本(问题)转化为具有强语义表示能力的向量。
该系统核心目标是:当用户输入一个查询问题时,系统能从已有的问答库中找到与查询语义最相似的问题,并返回对应的答案。
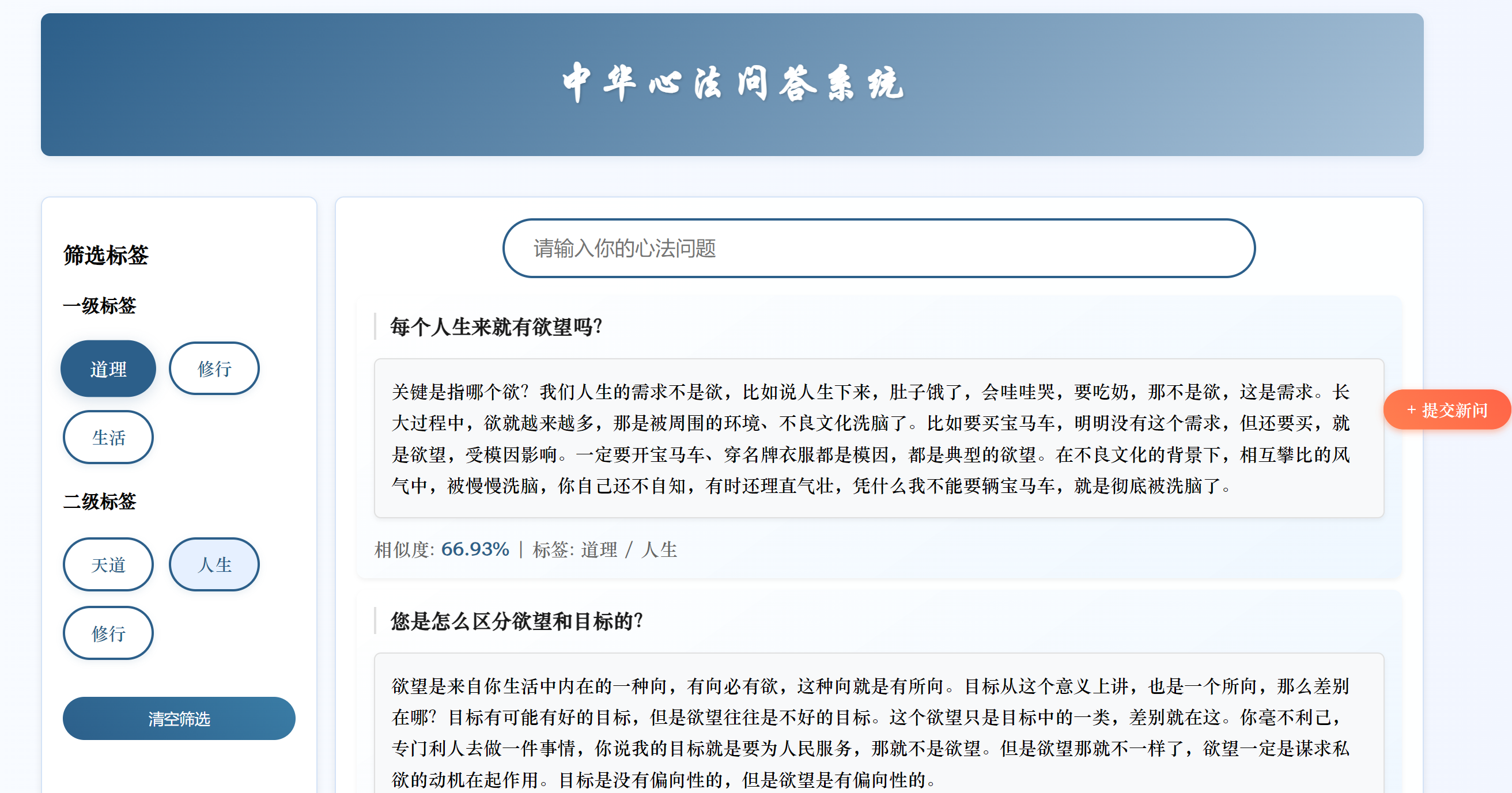
2 系统主要流程
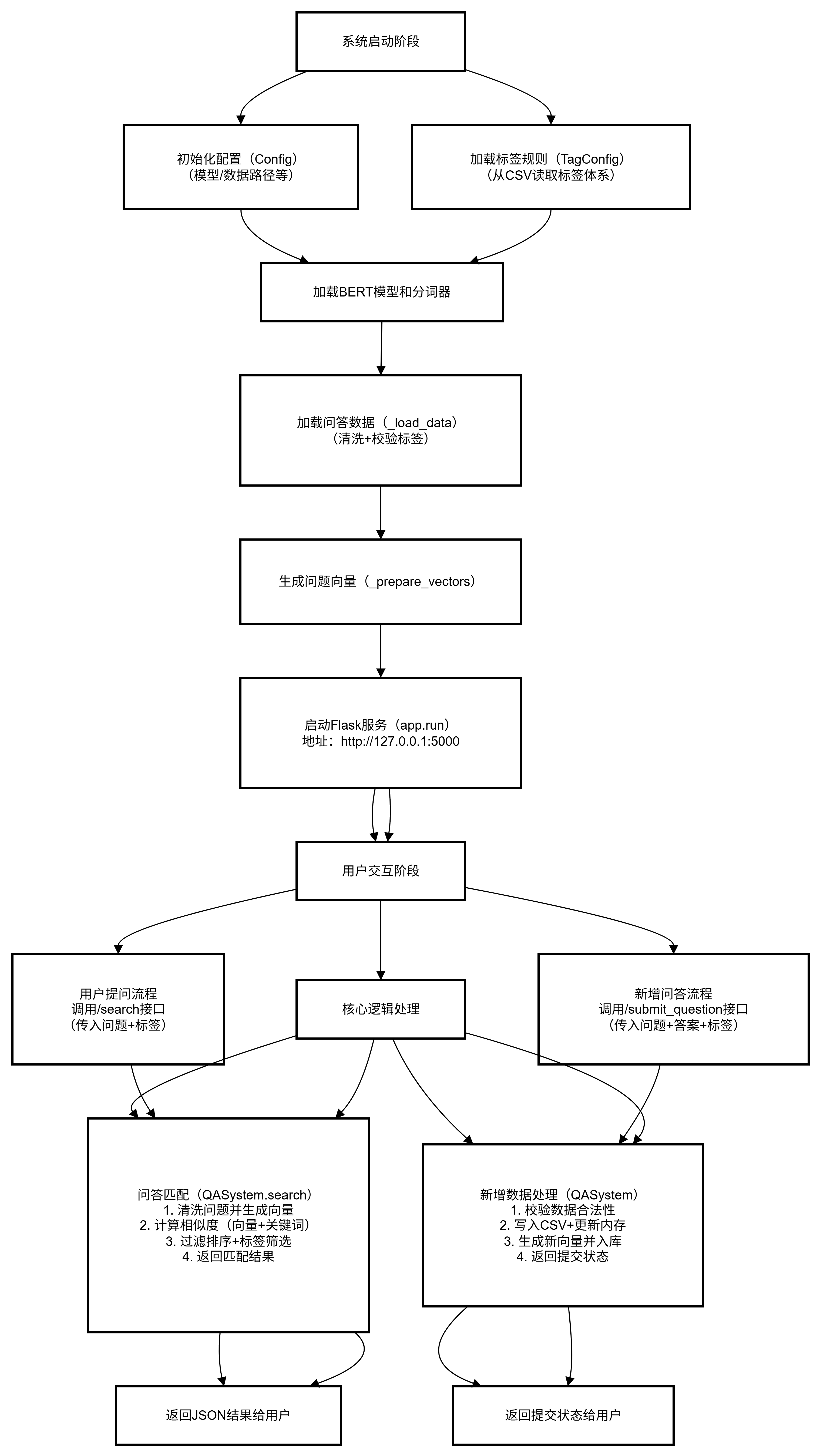
2 代码分析
2.1 导入和库
-
核心库: Python 的标准库,
os、csv和json,处理文件 I/O 操作和数据存储。 -
自然语言处理(NLP):使用
jieba库进行中文分词,torch用于深度学习处理。 -
Transformers:使用 Hugging Face 的
transformers库加载 BERT(双向编码器表示模型),用于文本嵌入和分类。 -
Flask:使用 Flask 框架来提供一个 Web 服务接口,供用户通过 HTTP 请求访问问答系统。
2.2 类与关键功能
TagConfig
-
功能:该类负责加载包含标签信息(一级标签和二级标签)的 CSV 文件,将标签信息存储在集合和字典中。
-
方法:
加载并处理 CSV 文件,提取一级标签和二级标签,并将其存储为LEVEL1和LEVEL2。
Config
-
功能:配置类,用于存储应用程序中使用的常量和路径,包括 BERT 模型路径、QA 文件路径、停用词文件路径以及其他系统参数。
QASystem
-
功能:核心类,负责管理问答对、查询模型并返回结果。
-
方法:
-
_load_model():加载 BERT 的 tokenizer 和模型。 -
_load_data():从 CSV 文件加载问答对和相关标签。 -
_prepare_vectors():将所有问题转换为 BERT 嵌入(向量表示)。 -
_get_embedding():计算给定查询的 BERT 嵌入。 -
search_with_tags():按选择的标签过滤搜索结果,并根据相似度对其进行排序。 -
search():基于查询进行相似度搜索,使用 BERT 嵌入和关键词匹配对结果进行排序。
-
(BERT在后文解释)
API 路由(Flask 路由)
-
/:渲染首页。 -
/submit:显示提交新问题和答案的页面。 -
/search:接受一个 JSON 请求,包含问题和选择的标签,搜索并返回最相似的问题。 -
/submit_question:允许用户提交新的问题、答案和标签。输入验证通过后,会将新数据存储到 CSV 文件中,并更新内存中的数据。
2.3 文本处理与嵌入
2.3.1 文本清洗
clean_text 函数对输入文本进行预处理,移除非字母数字字符,进行分词,并根据提供的停用词文件过滤掉停用词。
假设输入文本是:
“追名逐利是欲,那对孩子和亲人的有所期待是不是欲?如果是,怎样放下?”1. 移除非字母数字字符(保留核心文字)
操作:用正则表达式去掉文本中除了 “中文、英文、数字、常见标点(?!)” 之外的符号(如逗号、引号、空格等)。
效果:
原文本 →“追名逐利是欲那对孩子和亲人的有所期待是不是欲如果是怎样放下”
(去掉了逗号、问号,只保留核心文字)为什么要做:特殊符号(如 “,”“?”)本身没有实际语义,留着会增加后续处理的 “噪音”。
2. 分词(把句子拆成单个词)
操作:用
jieba.posseg.cut对文本进行分词(同时标注每个词的词性,如名词、动词)。效果:
处理后的文本 →[追名逐利, 是, 欲, 那, 对, 孩子, 和, 亲人, 的, 有所期待, 是, 不, 是, 欲, 如果, 是, 怎样, 放下]
(同时标注词性:“孩子” 是名词(n),“放下” 是动词(v)等)为什么要做:计算机无法直接理解完整句子,需要拆成最小单位(词)才能进一步分析。
3. 过滤停用词(去掉无意义的 “填充词”)
操作:参考
stopwords.txt中的停用词表,过滤掉 “无实际语义、对句子意思影响极小” 的词;同时保留核心词性(名词、动词、形容词等)。停用词举例:
“的”“是”“那”“和”“如果”(这些词在中文里很常见,但单独存在时没有具体含义)。效果:
最终保留的词 →[追名逐利, 欲, 孩子, 亲人, 有所期待, 欲, 放下]
(去掉了 “是”“那”“和” 等停用词,只留核心词)为什么要做:停用词会 “稀释” 核心语义。比如原句中 “的”“是” 出现多次,但去掉后不影响句子核心意思(“追名逐利、欲、孩子、亲人、期待” 才是关键)。
经过这三步处理,文本从 “冗余的句子” 变成 “简洁的核心词集合”,后续用 BERT 模型生成向量时,就能更聚焦于 “真正有意义的语义”,避免被噪音干扰。
2.3.2 BERT 嵌入
人类能通过文字直接理解语义(比如知道 “追名逐利” 和 “追求名利” 是一个意思),但计算机只能处理数字。BERT 嵌入的作用就是把文本的语义 “翻译” 成一串数字(向量),让计算机能通过比较向量的相似度,判断文本语义是否相近。
“传统问答系统常依赖关键词匹配(比如用户问‘亲人期待算欲吗?’,必须包含‘期待’‘欲’等词才能匹配),但实际中用户表述多样(比如‘对家人的期望是不是欲望?’),容易漏检。
因此,引入 BERT 模型 —— 它能理解文本语义,把‘意思相近但表述不同’的问题映射到相似的向量,从根本上解决关键词匹配的局限性。”
BERT 嵌入的过程:
“文本→标记化(拆成模型能懂的单位)→多层语义计算(获取不同层面的理解)→加权融合(综合多层语义)→最终向量(语义的数字表达)”
第一步:文本预处理
“用户输入或知识库中的问题,会先经过 clean_text 函数清洗:去除逗号、引号等无关符号,用结巴分词拆分成词语,再过滤‘的’‘是’等停用词,只保留核心词汇(如名词、动词)。这一步是为了减少噪音,让 BERT 更专注于有意义的内容。”第二步:BERT 生成语义向量
“清洗后的文本会通过 BERT 转化为向量:
① 标记化:把文本拆成 BERT 能识别的小单位(比如‘对亲人的期待’拆成‘[CLS]、对、亲人、的、期待、[SEP]’),并转化为数字编码;
② 提取多层语义:BERT 的 12 层神经网络会输出不同深度的特征(底层抓字面意思,高层抓抽象语义);
③ 融合优化:最后 4 层特征按权重融合(权重 [0.15, 0.25, 0.35, 0.25]),既保留字面信息,又突出深层语义,最终生成 768 维的语义向量。”第三步:基于向量的问答匹配
“系统启动时,会提前把知识库中所有问题的向量计算好;用户提问时,实时生成问题向量,通过计算‘余弦相似度’找到最相似的已有问题,返回对应的答案。比如‘对孩子的期待是不是欲?’和‘亲人的期待属于欲望吗?’的向量相似度很高,会匹配到同一个答案。”
2.4 相似度计算与排序
-
余弦相似度:系统使用余弦相似度来比较问题的嵌入,并按相似度对结果进行排序。
-
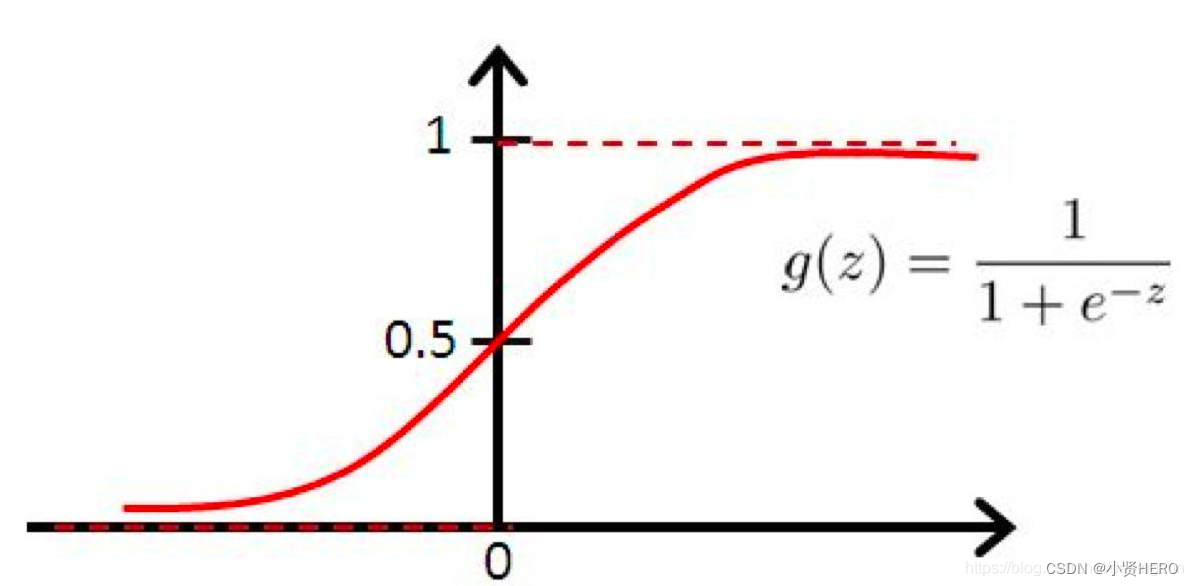
校准相似度:使用sigmoid函数对原始相似度进行校准,以提高排序准确性。
原始余弦相似度可能存在 “区分度不足” 的问题:比如两个答案的相似度分别是 0.8 和 0.82,原始差异很小,难以判断哪个更优。
逻辑函数(Sigmoid 函数)的作用是放大相似与不相似的差距,让排序更明确。
-
关键词匹配:此外,系统还通过关键词匹配来进一步优化搜索结果。
BERT 向量擅长捕捉深层语义,但有时会忽略 “字面强相关” 的情况(比如用户问题和答案包含完全相同的核心词,理应优先匹配)。
关键词匹配的作用是补充字面信息,强化 “核心词重叠” 的答案权重。
2.5 提交新的问答对
-
用户可以通过
/submit_question提交新的问题和答案。系统会验证输入内容,处理并将其存储到 CSV 文件中,此外,还会更新内存中的数据结构,供后续查询使用。
3 BERT模型详解
(参考B站视频小白也能听懂的 bert模型原理解读 预训练语言模型_哔哩哔哩_bilibili)
BERT(Bidirectional Encoder Representations from Transformers)是由 Google 在 2018 年提出的预训练语言模型,它的核心突破在于 **“双向预训练”**,彻底改变了自然语言处理(NLP)的范式。
3.1 BERT 的核心思想
是自编码模型,BERT 的核心结构是多层 Transformer 编码器(仅用 Transformer 的编码器部分,不用解码器)
- BERT-Base:12 层 Transformer 编码器,12 个注意力头,隐藏层维度 768,总参数约 110M。
- BERT-Large:24 层 Transformer 编码器,16 个注意力头,隐藏层维度 1024,总参数约 340M。
Transformer 编码器层
BERT 的核心计算单元是 Transformer 编码器,每层包含两个核心模块(与原 Transformer 一致):
- 多头自注意力(Multi-Head Self-Attention):让每个词 “关注” 文本中其他相关词(如 “他” 关注前文的 “小明”),捕捉上下文依赖。
原理:将输入向量拆分为多个子空间(“多头”),每个子空间独立计算注意力,再拼接结果,提升模型对不同语义关系的捕捉能力。- 前馈神经网络(Feed-Forward Network, FFN):对每个词的注意力输出进行非线性转换(先升维再降维),增强模型拟合能力。
此外,每层还包含残差连接(Residual Connection) 和层归一化(Layer Normalization),用于缓解梯度消失,加速训练。
双向预训练 + 微调
传统语言模型(如 ELMo、GPT)多为 “单向”(如 GPT 仅从左到右预测),而 BERT 通过双向 Transformer 编码器学习文本的上下文信息,实现 “真正的双向理解”。其核心流程分为两步:
- 预训练(Pre-training):在大规模无标注文本(如维基百科)上训练模型,学习通用语言知识(语法、语义、逻辑等)。
- 微调(Fine-tuning):针对具体任务(如文本分类、问答),用少量标注数据调整预训练模型参数,适配任务需求。
这种 “预训练 + 微调” 模式的优势:避免重复训练,用通用知识提升任务性能,尤其在小数据场景下效果显著。
3.1.1 预训练(Pre-training)
任务一:MLM(Mask Language Model)
在训练的时候随机选择一些要预测的词用mask遮掩,让模型根据标签去学习这个地方应该填的词
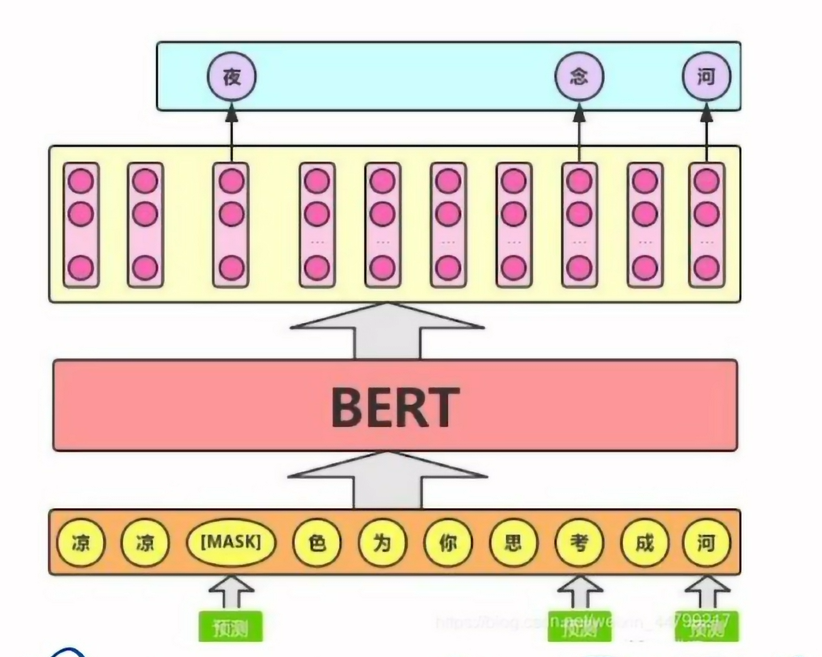
 随机屏蔽15%的单词,但是这样会在预训练和微调之间产生差异,因为微调中的句子没有mask标记,为解决该问题利用了“80、10、10”规则。对于随机屏蔽的15%的单词,百分之80是mask,百分之10用随机单词,剩下的百分之10保持原来的单词。将这样处理过后的数据喂给标记嵌入、片段嵌入和位置嵌入层得到输入嵌入,然后将三者相加喂给BERT模型
随机屏蔽15%的单词,但是这样会在预训练和微调之间产生差异,因为微调中的句子没有mask标记,为解决该问题利用了“80、10、10”规则。对于随机屏蔽的15%的单词,百分之80是mask,百分之10用随机单词,剩下的百分之10保持原来的单词。将这样处理过后的数据喂给标记嵌入、片段嵌入和位置嵌入层得到输入嵌入,然后将三者相加喂给BERT模型
任务二:NSP(Next Sentence Prediction)
下一个句子的预测,在双向语言模型的基础之上增加了一个句子级别的连续性预测任务。
判断两段文本是否为连续的文本,二分类任务
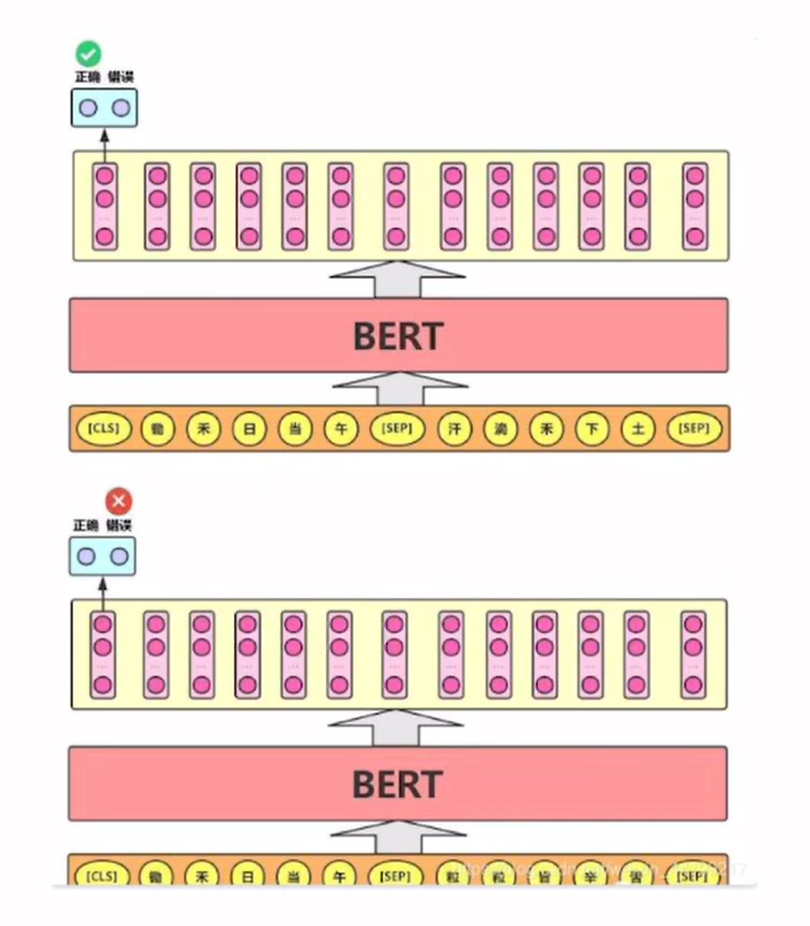
 BERT如何进行预训练
BERT如何进行预训练
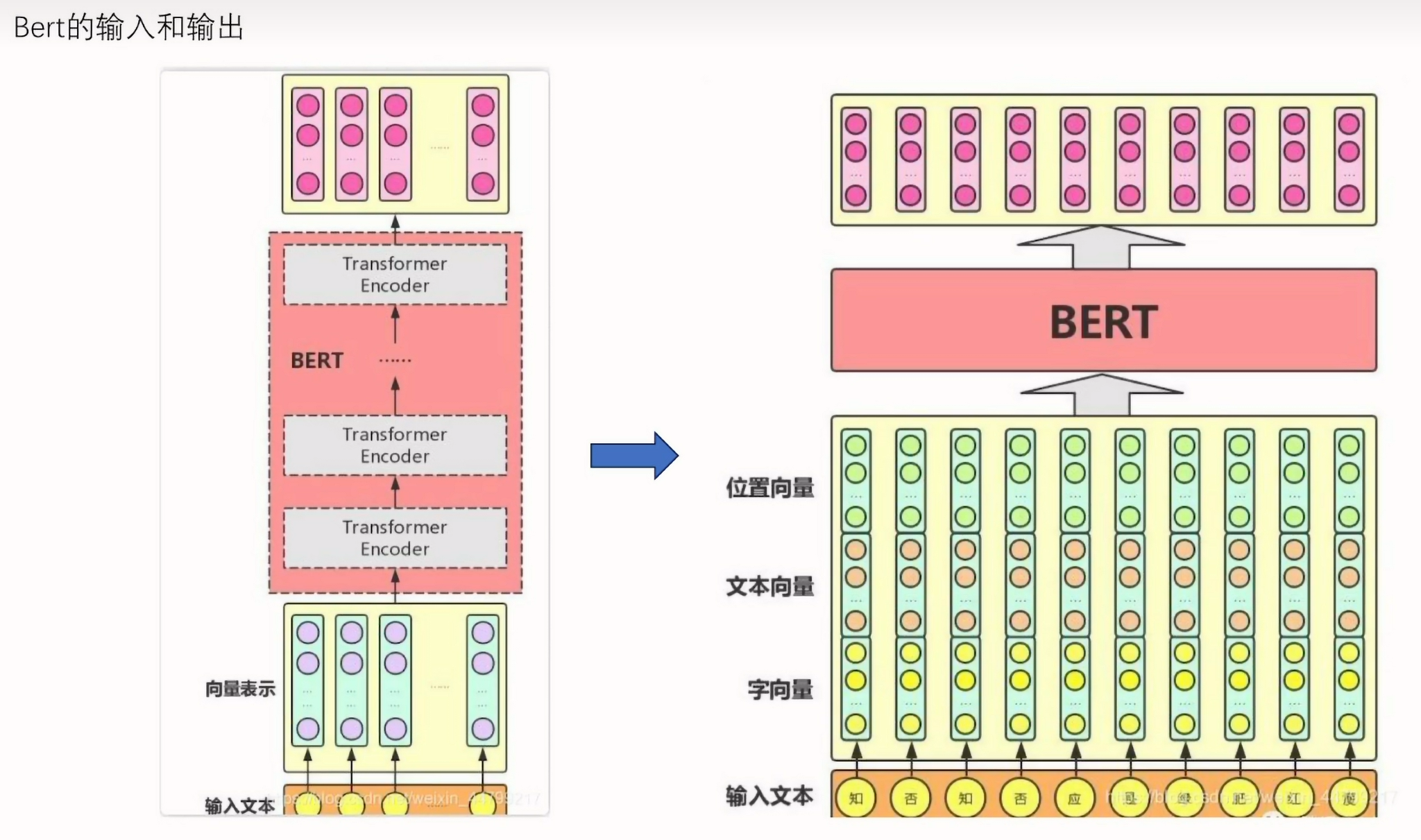
输入:字向量、文本向量、位置向量求和作为BERT的输入
输出:每个标记的嵌入
在transformer的encoder部分的输入Xt也是由两个向量进行相加(文本embedding+位置embedding),BERT特殊的点是有一个字向量(可以随机初始化也可以用word2vct进行预训练作为初始值),由于BERT拥有字向量可以考虑到颗粒度比较细的token信息,最后BERT将字向量、文本向量、位置向量求和作为BERT的输入,BERT返回每个标记的嵌入作为输出。
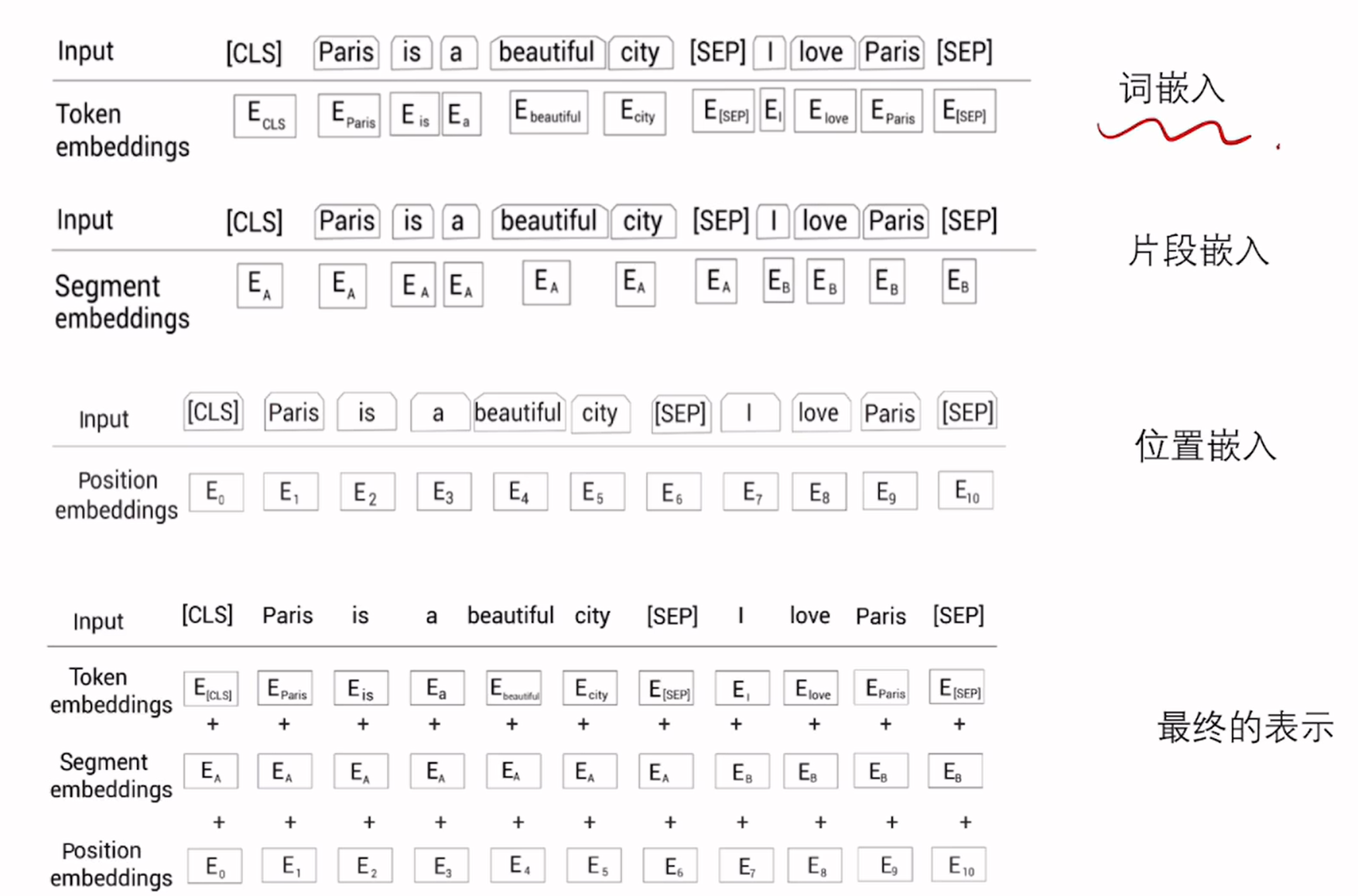
补充语言建模知识
- 自回归语言建模:是单向的,一类为从左到右,一类为从右到左
- 自编码语言建模:双向的,在预测时读入两端的数据

BERT预训练目标就是预测被掩盖的词,接着将BERT预测的词输入到一个带有softmax(softmax:![]() 适用于多分类,输出多个概率值,且和为 1,强制类别间为 “互斥关系”)的前馈神经网络,最后输出是各个词的概论。
适用于多分类,输出多个概率值,且和为 1,强制类别间为 “互斥关系”)的前馈神经网络,最后输出是各个词的概论。
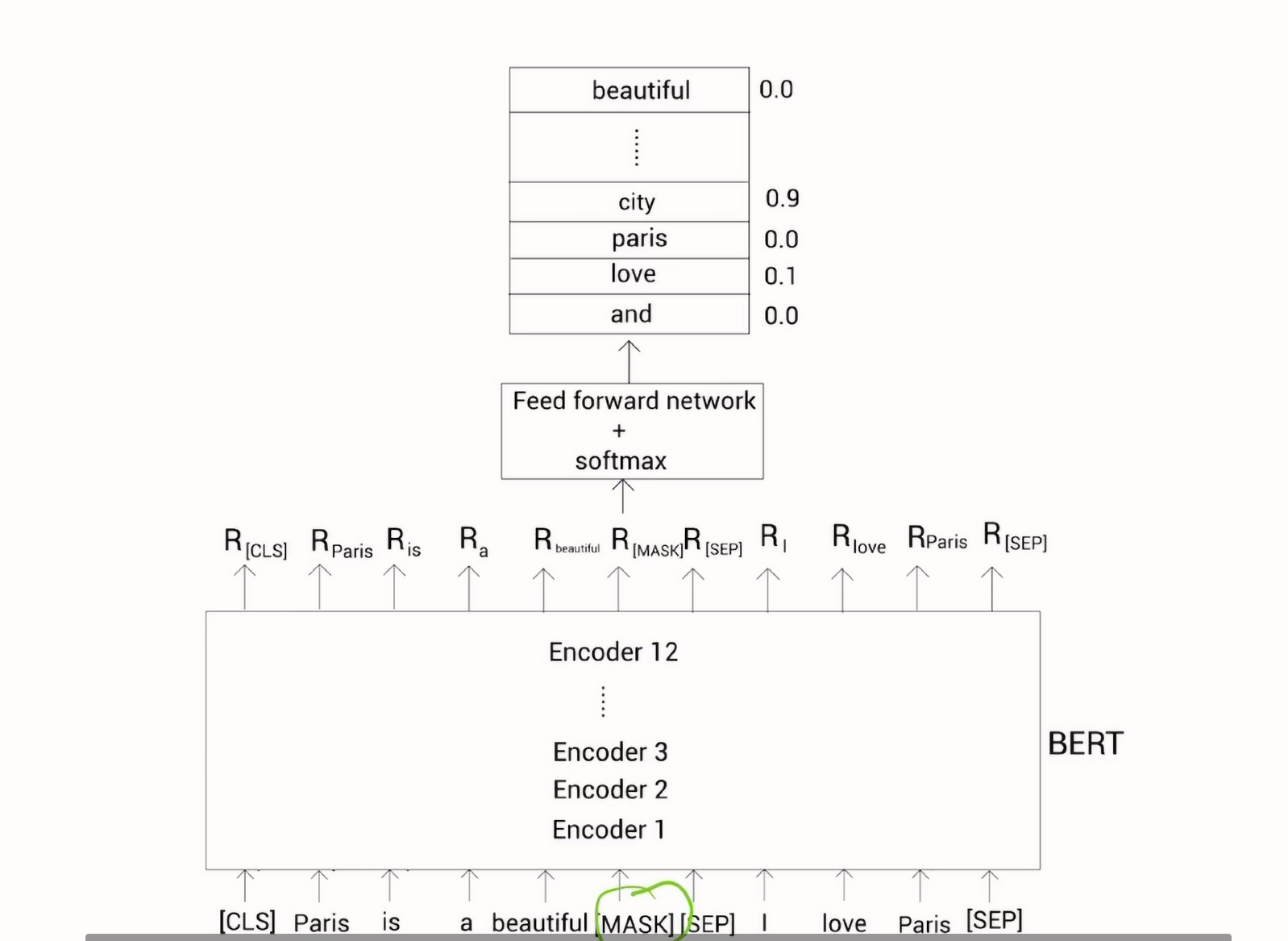 预训练的本质是让 BERT 学习 “语言规律”—— 通过预测掩码词,BERT 被迫理解上下文之间的语义关联(比如 “他在吃 [MASK]” 中,结合上下文能推断出 [MASK] 可能是 “苹果”“米饭” 等)。这种学习过程让 BERT 掌握了强大的语义理解能力,而这种能力可以被迁移到各种 NLP 任务中,包括系统中的 “文本转向量”。
预训练的本质是让 BERT 学习 “语言规律”—— 通过预测掩码词,BERT 被迫理解上下文之间的语义关联(比如 “他在吃 [MASK]” 中,结合上下文能推断出 [MASK] 可能是 “苹果”“米饭” 等)。这种学习过程让 BERT 掌握了强大的语义理解能力,而这种能力可以被迁移到各种 NLP 任务中,包括系统中的 “文本转向量”。