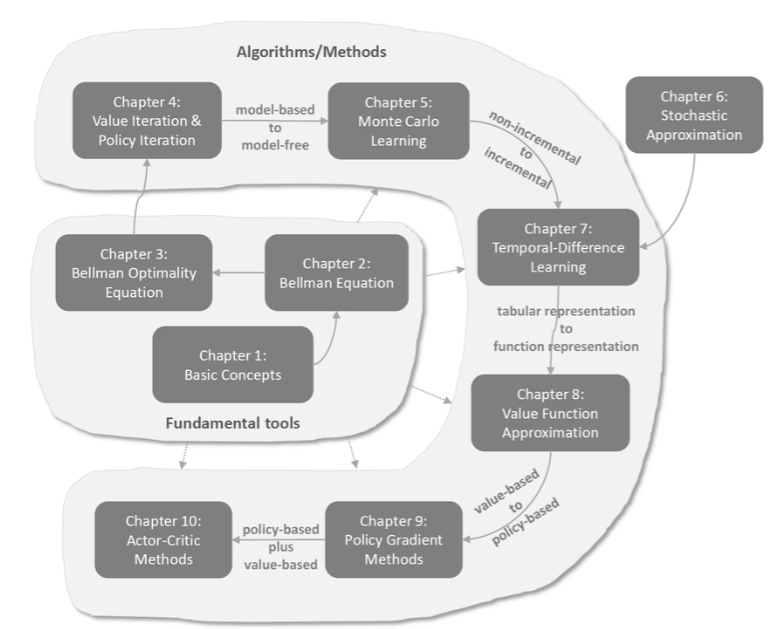
强化学习理论
强化学习算法概述
chapter 1:基本概念
chapter2:贝尔曼公式
状态值:从一个状态出发,沿着一个策略所得到奖励回报的平均值,状态值越高说明策略越好
贝尔曼公式:描述了所有状态和状态值的关系,通过公式可以求解出给定策略的状态值,因此能够评价策略好不好(Policy evaluation策略评价)
vπ=rπ+γPπvπ
v_\pi=r_\pi+\gamma P_\pi v_\pi
vπ=rπ+γPπvπ
chapter3:贝尔曼最优公式
贝尔曼最优公式是贝尔曼公式的特殊情况
强化学习的最终目标是求解最优策略
最优策略:能够得到最大的状态值
分析下面公式使用:不动点原理
- 求解的最优策略是否存在
- 给出求解贝尔曼最优公式的策略
v=maxπ(rπ+γPπv)=f(v) v=\max_\pi(r_\pi+\gamma P_\pi v)=f(v) v=πmax(rπ+γPπv)=f(v)
chapter4:第一批求解的算法
第一批能够求解最优策略的三个算法
Value iteration(值迭代)
Policy iteration(策略迭代)
Truncated policy iteration(上面两个的统一的表示)
每个策略有两个步骤:
- Policy update
- Value update
先进行测量评价,通过评价的值改进策略,反复迭代
chapter5:蒙特卡洛方法(最简单的不需要模型就能找到最优策略的方法)
学习随机变量的期望值(state value和action value全都是随机变量的期望值)
Xi是随机值(没有模型要有数据,没有数据要有模型)
E[X]≈xˉ=1n∑i=1nxi\mathbb{E}[X]\approx\bar{x}=\frac{1}{n}\sum_{i=1}^nx_iE[X]≈xˉ=n1i=1∑nxi
效率特别低,现实中并不使用
具体的三个算法

chapter6:随机近似理论
第六章之前是non-incremental,第七章开始是incremental,第六章是过度
non-incremental:一次使用很多采样,所有数据收集完之后一次求平均,得到一个E(x)的近似
incremental:开始时有一个估计,每得到一个采样就更新一次估计
三个典型算法
- Robbins-Monro(RM) algorithm
- Stochastic gradient descent(SGD随即下降)
chapter7:
三种算法:
- TD 的方法学习state value
- Sarsa:用TD的方法学习action value
- Q-learning:用TD学习optimal action value
两种策略
behavior policy:用来生成经验数据
target policy:目标策略,不断进行改进希望target policy能够收敛到最优的策略
on-policy: behavior policy和target policy相同,为on-policy
off-policy: behavior policy和target policy可以不同,为off-policy
chapter8:
第七章和前面的数据都是表格状态的
第八章开始是函数形式
chapter9:
第八章和之前都是value-based(改变策略中的参数值)
第九章开始是policy-based(改变策略)
chapter10:actor-Critic Methods
把policy-based和value-based方法结合起来
chapter 1:基本概念
state: 位置等各种状态信息
state space: 状态空间,所有状态的集合
Action: 在每个状态可以采取的一系列的行为
Action space: 所有Action的集合,不同状态的Action是不同的
state transition: 当采取一个action的时候,agent可以从一个state转变为另一个state,state transition就是这个过程
Forbidden area:
有些区域可以进入,但是进入后会有惩罚(虽然有惩罚,但是更优)
有些状态就不能进入
Tabular representation: 用表格的形式表示state transition,每一行都表示一个状态,每一列表示一个action(只能表示确定性情况)
state transition:用语言描述状态,或者用数学表示state transition
policy:告诉agent如果在一个状态下应该采取哪一个action
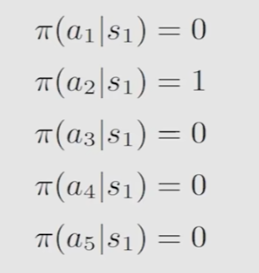
reward:一个数,agent采取action后会得到一个数,这个数为正数表示鼓励这个行为,否则反之
return: 沿着一个路径上的所有rewards加起来
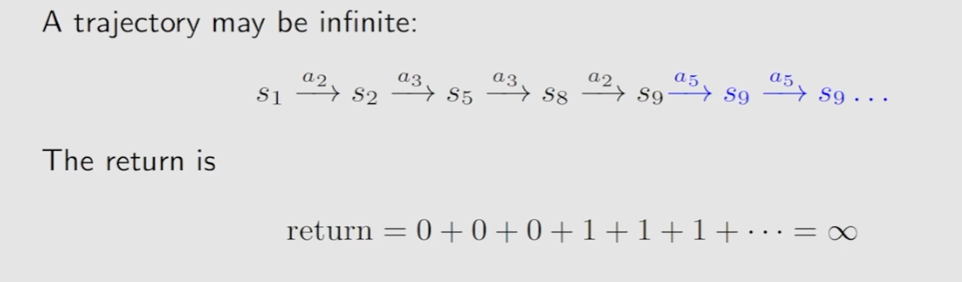
当路径到达终点S9,return仍然会不断增加达到无穷大
引入discount rate解决这个问题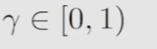
chapter2:贝尔曼公式
Motivating examples(举例计算return)
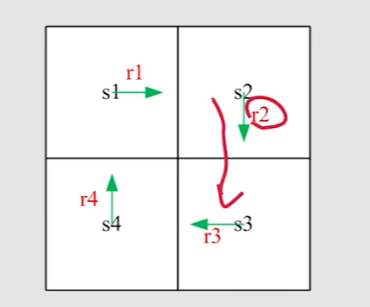
return的计算方法一
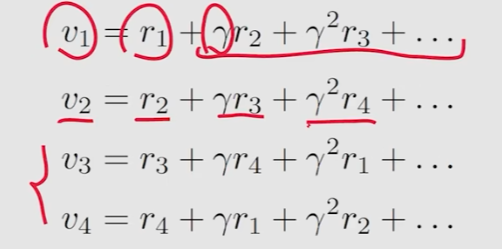
演变为方法二
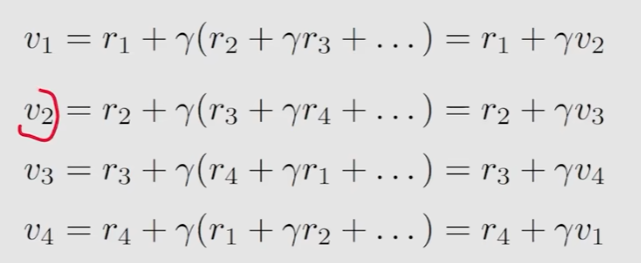
写成矩阵
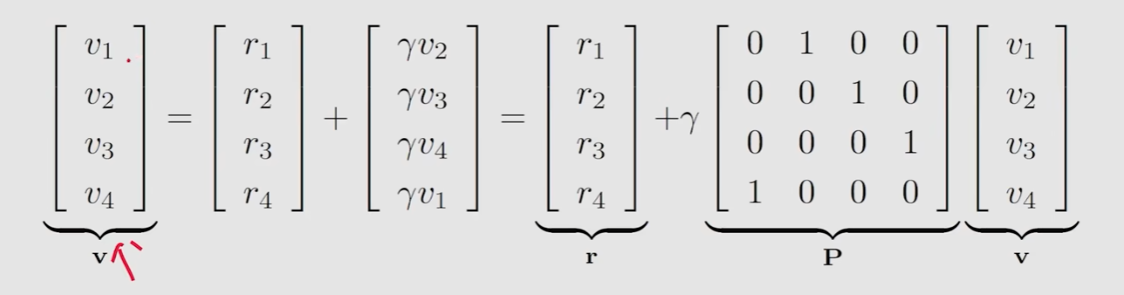
转换成数学公式
v=r+γPv\mathbf{v}=\mathbf{r}+\gamma\mathbf{P}\mathbf{v}v=r+γPv
state value
单步执行的数学表示
St→AtRt+1,St+1S_t\xrightarrow{A_t}R_{t+1},S_{t+1}StAtRt+1,St+1
St是当前的状态
At是采取的动作
Rt+1是reward
St+1是执行过的状态
计算discounted return
Gt=Rt+1+γRt+2+γ2Rt+3+…G_t=R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+\ldotsGt=Rt+1+γRt+2+γ2Rt+3+…
state value是Gt的期望值
vπ(s)=E[Gt∣St=s]v_\pi(s)=\mathbb{E}[G_t|S_t=s]vπ(s)=E[Gt∣St=s]
贝尔曼公式推导
计算Gt
Gt=Rt+1+γRt+2+γ2Rt+3+…,=Rt+1+γ(Rt+2+γRt+3+…),=Rt+1+γGt+1,\begin{aligned}G_{t}&=R_{t+1}+\gamma R_{t+2}+\gamma^{2}R_{t+3}+\ldots,\\&=R_{t+1}+\gamma(R_{t+2}+\gamma R_{t+3}+\ldots),\\&=R_{t+1}+\gamma G_{t+1},\end{aligned}Gt=Rt+1+γRt+2+γ2Rt+3+…,=Rt+1+γ(Rt+2+γRt+3+…),=Rt+1+γGt+1,
计算state value
vπ(s)=E[Gt∣St=s]=E[Rt+1+γGt+1∣St=s]=E[Rt+1∣St=s]+γE[Gt+1∣St=s]\begin{aligned}v_{\pi}(s)&=\mathbb{E}[G_t|S_t=s]\\&=\mathbb{E}[R_{t+1}+\gamma G_{t+1}|S_{t}=s]\\&=\mathbb{E}[R_{t+1}|S_t=s]+\gamma\mathbb{E}[G_{t+1}|S_t=s]\end{aligned}vπ(s)=E[Gt∣St=s]=E[Rt+1+γGt+1∣St=s]=E[Rt+1∣St=s]+γE[Gt+1∣St=s]
在指定状态s下得到Rt+1的期望
E[Rt+1∣St=s]=∑aπ(a∣s)E[Rt+1∣St=s,At=a]=∑aπ(a∣s)∑rp(r∣s,a)r\begin{aligned}\mathbb{E}[R_{t+1}|S_{t}=s]&\begin{aligned}=\sum_a\pi(a|s)\mathbb{E}[R_{t+1}|S_t=s,A_t=a]\end{aligned}\\&=\sum_a\pi(a|s)\sum_rp(r|s,a)r\end{aligned}E[Rt+1∣St=s]=a∑π(a∣s)E[Rt+1∣St=s,At=a]=a∑π(a∣s)r∑p(r∣s,a)r
E[Rt+1∣St=s,At=a]\mathbb{E}[R_{t+1}|S_{t}=s,A_{t}=a]E[Rt+1∣St=s,At=a]是在指定状态下,发生指定动作,得到的所有可能的结果的期望值
π(a∣s)是在状态s下选择动作a 的概率
E[Gt+1∣St=s]=∑s′E[Gt+1∣St=s,St+1=s′]p(s′∣s)=∑s′E[Gt+1∣St+1=s′]p(s′∣s)=∑s′vπ(s′)p(s′∣s)=∑s′vπ(s′)∑ap(s′∣s,a)π(a∣s)\begin{aligned}\mathbb{E}[G_{t+1}|S_{t}=s]&\begin{aligned}=\sum_{s^{\prime}}\mathbb{E}[G_{t+1}|S_t=s,S_{t+1}=s^{\prime}]p(s^{\prime}|s)\end{aligned}\\&=\sum_{s^{\prime}}\mathbb{E}[G_{t+1}|S_{t+1}=s^{\prime}]p(s^{\prime}|s)\\&=\sum_{s^{\prime}}v_\pi(s^{\prime})p(s^{\prime}|s)\\&=\sum_{s^{\prime}}v_\pi(s^{\prime})\sum_ap(s^{\prime}|s,a)\pi(a|s)\end{aligned}E[Gt+1∣St=s]=s′∑E[Gt+1∣St=s,St+1=s′]p(s′∣s)=s′∑E[Gt+1∣St+1=s′]p(s′∣s)=s′∑vπ(s′)p(s′∣s)=s′∑vπ(s′)a∑p(s′∣s,a)π(a∣s)
p(s ′ ∣s) 在状态s下采取某个动作转移到s’的概率
E[Gt+1 ∣St =s,St+1 =s ′ ]:从状态s采取某个动作到达s‘所得到的未来Gt+1的值
贝尔曼公式的最终表达式
vπ(s)=E[Rt+1∣St=s]+γE[Gt+1∣St=s],=∑aπ(a∣s)∑rp(r∣s,a)r⏟mean of immediate rewards+γ∑aπ(a∣s)∑s′p(s′∣s,a)vπ(s′),⏟mean of future rewards=∑aπ(a∣s)[∑rp(r∣s,a)r+γ∑s′p(s′∣s,a)vπ(s′)],∀s∈S.\begin{aligned}v_{\pi}(s)&=\mathbb{E}[R_{t+1}|S_{t}=s]+\gamma\mathbb{E}[G_{t+1}|S_{t}=s],\\&\begin{aligned}&=\underbrace{\sum_a\pi(a|s)\sum_rp(r|s,a)r}_{\text{mean of immediate rewards}}+\underbrace{\gamma\sum_a\pi(a|s)\sum_{s^{\prime}}p(s^{\prime}|s,a)v_\pi(s^{\prime}),}_{\text{mean of future rewards}}\end{aligned}\\&\begin{aligned}=\sum_a\pi(a|s)\left[\sum_rp(r|s,a)r+\gamma\sum_{s^{\prime}}p(s^{\prime}|s,a)v_\pi(s^{\prime})\right],\quad\forall s\in\mathcal{S}.\end{aligned}\end{aligned}vπ(s)=E[Rt+1∣St=s]+γE[Gt+1∣St=s],=mean of immediate rewardsa∑π(a∣s)r∑p(r∣s,a)r+mean of future rewardsγa∑π(a∣s)s′∑p(s′∣s,a)vπ(s′),=a∑π(a∣s)[r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπ(s′)],∀s∈S.
使用矩阵/向量求解贝尔曼公式

写成矩阵乘法
vπ=rπ+γPπvπv_\pi=r_\pi+\gamma P_\pi v_\pivπ=rπ+γPπvπ
案例

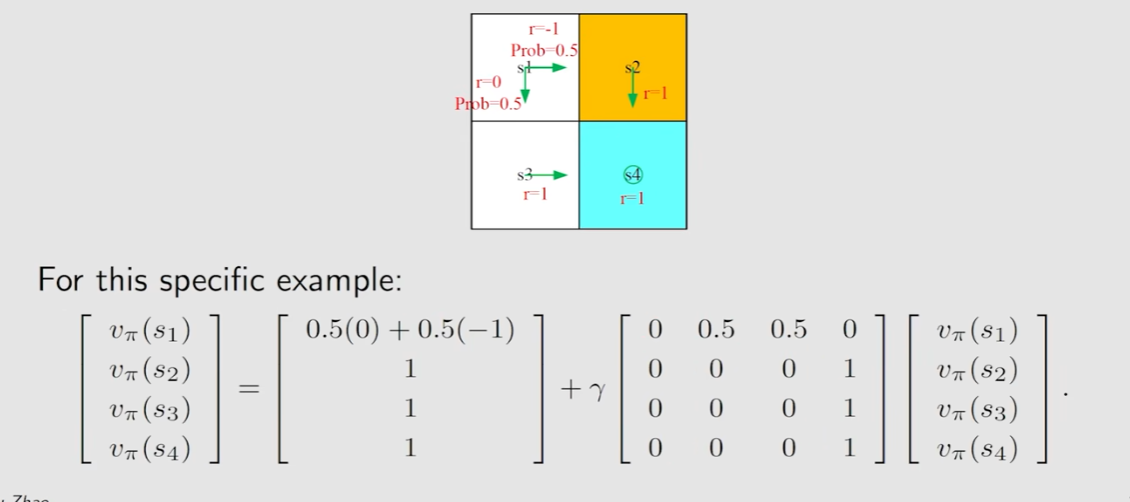
rΠ=r*prob (prob是选择每个r的概率)
pΠ=s到不同位置的prob
贝尔曼公式的迭代过程
vk+1=rπ+γPπvkv_{k+1}=r_\pi+\gamma P_\pi v_kvk+1=rπ+γPπvk
当看趋于无穷大时Vk就hi收敛到VΠ,这个VΠ就是真实的state value
action value
从一个状态出发,采取指定action得到的return的平均值
qπ(s,a)=E[Gt∣St=s,At=a]q_\pi(s,a)=\mathbb{E}[G_t|S_t=s,A_t=a]qπ(s,a)=E[Gt∣St=s,At=a]
就是state value中固定了所进行的action
qπ(s,a)=∑rp(r∣s,a)r+γ∑s′p(s′∣s,a)vπ(s′)q_\pi(s,a)=\sum_rp(r|s,a)r+\gamma\sum_{s^{\prime}}p(s^{\prime}|s,a)v_\pi(s^{\prime})qπ(s,a)=r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπ(s′)
chapter3:贝尔曼最优公式
optimal policy:如果有两个策略,如果在所有状态下,一个策略的state value都大于另一个策略,则说这个策略是更好的
最优策略:如果有一个策略,在所有状态下的state value都优于其他策略,则说这个策略是最好的
贝尔曼公式
v(s)=∑aπ(a∣s)(∑rp(r∣s,a)r+γ∑s′p(s′∣s,a)v(s′)),∀s∈Sv(s)=\sum_a\pi(a|s)\left(\sum_rp(r|s,a)r+\gamma\sum_{s^{\prime}}p(s^{\prime}|s,a)v(s^{\prime})\right),\quad\forall s\in\mathcal{S}v(s)=a∑π(a∣s)(r∑p(r∣s,a)r+γs′∑p(s′∣s,a)v(s′)),∀s∈S
贝尔曼最优公式
v(s)=maxπ∑aπ(a∣s)(∑rp(r∣s,a)r+γ∑s′p(s′∣s,a)v(s′)),∀s∈Sv(s)=\max_{\pi}\sum_{a}\pi(a|s)\left(\sum_{r}p(r|s,a)r+\gamma\sum_{s^{\prime}}p(s^{\prime}|s,a)v(s^{\prime})\right),\quad\forall s\in\mathcal{S}v(s)=πmaxa∑π(a∣s)(r∑p(r∣s,a)r+γs′∑p(s′∣s,a)v(s′)),∀s∈S
矩阵格式
v=maxπ(rπ+γPπv)v=\max_\pi(r_\pi+\gamma P_\pi v)v=πmax(rπ+γPπv)
不动点
当一个点为x,和一个映射关系f,如果f(x)=x, 称这个点为不动点
∥f(x1)−f(x2)∥≤γ∥x1−x2∥\|f(x_1)-f(x_2)\|\leq\gamma\|x_1-x_2\|∥f(x1)−f(x2)∥≤γ∥x1−x2∥
Contraction mapping:一个函数f满足Contraction mapping,则任取两点满足
∥f(x1)−f(x2)∥≤γ∥x1−x2∥\|f(x_1)-f(x_2)\|\leq\gamma\|x_1-x_2\|∥f(x1)−f(x2)∥≤γ∥x1−x2∥
Contraction mapping Theorem:如果一个函数f满足Contraction mapping,对于x=f(x)满足三个结论
- 一定存在一个x,满足f(x)=x,
- 上述x是唯一的
- 可以通过下面这个公式求出xxk+1=f(xk)x_{k+1}=f(x_k)xk+1=f(xk)
已知贝尔曼最优公式是满足Contraction mapping Theorem的
可得vk+1=f(vk)=maxπ(rπ+γPπvk)v_{k+1}=f(v_k)=\max_\pi(r_\pi+\gamma P_\pi v_k)vk+1=f(vk)=πmax(rπ+γPπvk)
进而求解
v∗=maxπ(rπ+γPπv∗)v^*=\max_\pi(r_\pi+\gamma P_\pi v^*)v∗=πmax(rπ+γPπv∗)
最优策略
π∗=argmaxπ(rπ+γPπv∗)\pi^*=\arg\max_\pi(r_\pi+\gamma P_\pi v^*)π∗=argπmax(rπ+γPπv∗)
进而得到
v∗=rπ∗+γPπ∗v∗v^*=r_{\pi^*}+\gamma P_{\pi^*}v^*v∗=rπ∗+γPπ∗v∗
chapter4:迭代算法
第四章开始讲算法
值迭代
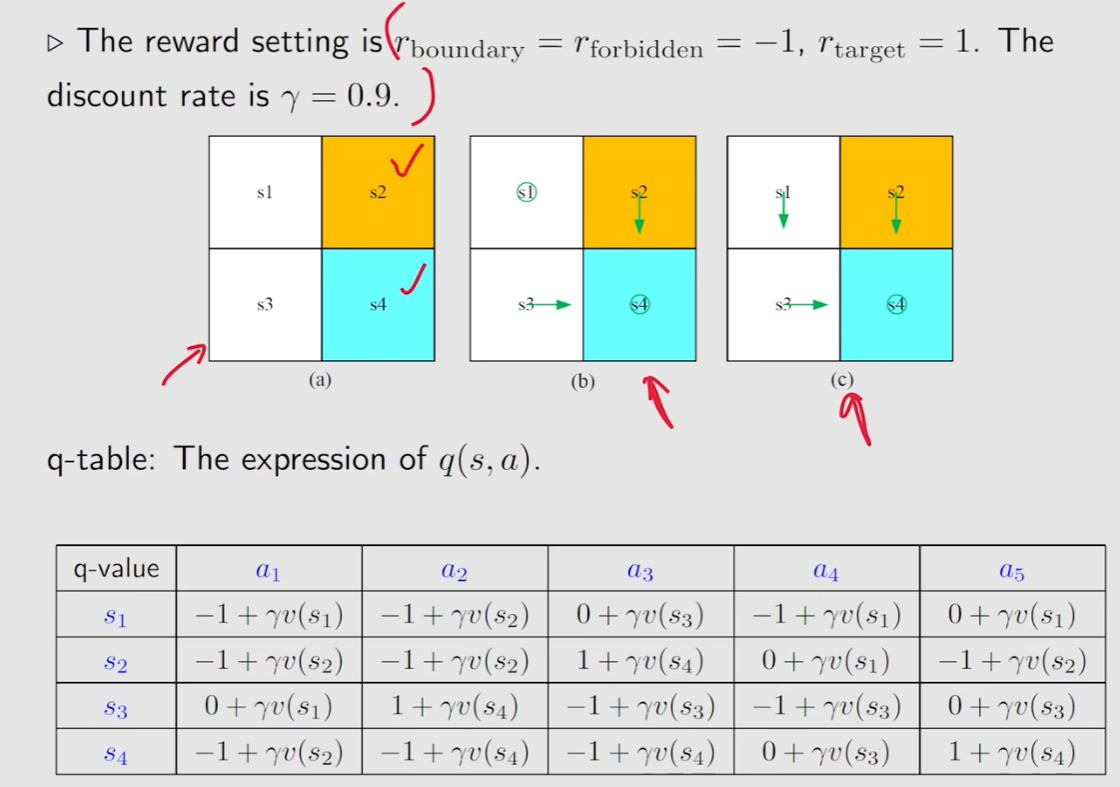
k=0时,选取所有v都是0
Policy update
计算出S1,S2,S3,S4所要做的动作(取计算的最大值)
Value update
V也选最大值
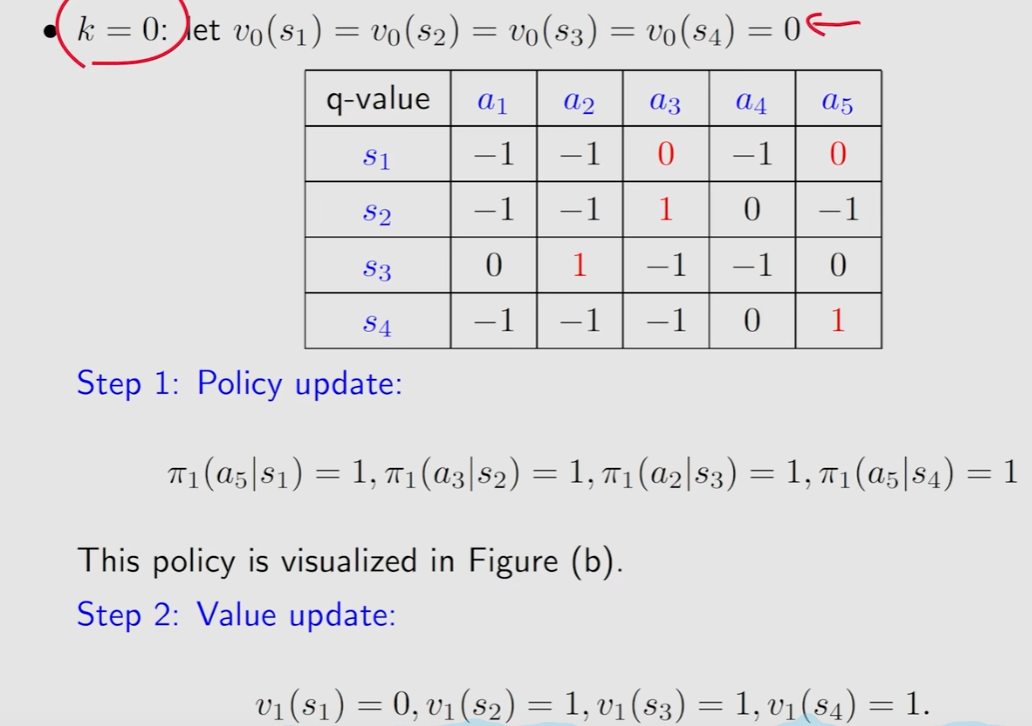
进行迭代计算

当Vk-Vk+1的绝对值很小时就求出来了
策略迭代
给定一个初始策略,在迭代过程中修改策略
- policy evaluation: 给定一个策略,求解策略对应的贝尔曼公式得到state value的过程
vπk=rπk+γPπkvπkv_{\pi_k}=r_{\pi_k}+\gamma P_{\pi_k}v_{\pi_k}vπk=rπk+γPπkvπk - policy improvement: 通过第一步求出的V得到一个新的策略
πk+1∗=argmaxπ(rπ+γPπvπk⏟)\pi_{k+1}^{*}=\arg\max_{\pi}(r_{\pi}+\gamma P_{\pi}\underbrace{v_{\pi_{k}}})πk+1∗=argπmax(rπ+γPπvπk)
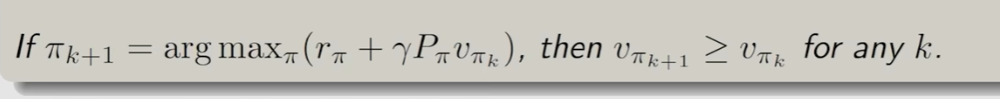
可以说明迭代的是越来越好的
chapter5:蒙特卡洛方法
model-free方法