CAN基础知识 - 进阶版
文章目录
- 一、什么是CAN通信?
- 1.1、为什么 CAN 使用差分电平
- 1.2、CAN 波特率
- 1.3、采样点的概念
- 1.3.1、实战中遇到的问题
- 1.4、波特率是怎么算出来的
- 1.5、表征通信质量的一些参数
- 二、CAN 通信的数据链路层
- 2.1、CAN报文的组成
- 2.2、帧起始
- 2.3、仲裁场
- 2.4、控制场
- 2.5、数据场
- 2.6、CRC 场
- 2.7、ACK 场
- 2.8、结束位
- 三、CAN驱动
- 3.1、CAN 驱动的位置
- 3.2、CAN 驱动的内容
- 3.2.1、CAN 初始化
- 3.2.2、basic CAN VS full CAN:
- 3.3、CAN 的接收和发送
- 3.4、CAN 的发送和接收故障
- 3.5、CAN 的 bus off
- 总结
一、什么是CAN通信?
CAN 通信的物理介质其实就是两根线,芯片根据两根线上的不同电压值来确定当前传递的信号,一个个的信号组成一连串的报文包,通过解析而成为通信中的数据值。
一个最简单的例子,当收到高电平时,表示收到了 1,当收到了低电平时,表示收到了 0。
这样,通过一串串的 0 和 1 就可以表示出成千上万的不同意思。
那么这里的个问题是,怎样来确定当前的信号呢?用什么方法来确定呢?这个问题其实很好解决,只要通信双方确定好传输的时间起始点和每个信号之间的时间间隔,就可以区分出各时间段的电平,通过电平确定当前传递的信号是 0还是 1。本篇的意义主要就是描述如何从物理电平获得 1 个 bit 的数据,及其在获取的过程中需要注意的事项。
话不多说,走你~
1.1、为什么 CAN 使用差分电平
早期的通信一般都是基于普通电平的通信,如 K 线、LIN 线之类。这种通信方式都是使用两根线来完成通信的物理连接,一根用于传输信号称为信号线,另外一根用于共地称为地线。通过这样两根线的连接,将双方的地线间接相连,通过信号线上的电压值来表示当前的数据,以 K 线为例子,如果信号线上的电压值在 12V 左右,认为是 1,如果信号线上的电压值在 0V 左右,认为是 0。这种模式理解起来简单,也是早期最常用的通信模式。
然而,这种模式主要有两大局限性:
- 随着通信距离的增加,信号线上电压值衰减的很快,传输数据的错误率会大幅增加(如信号线上的数据是 6V 怎么办?),校验判断的工作量增大,传输速率大幅度下降。
- 供地模式导致通信时必然是点对点的通信,当两个节点通信时,其他节点必须是监控态,不能参与网络上的通信行为,这种模式导致了网络利用率不高,错误概率较大。
那么为什么市面还能看到 K 线、LIN 线之类的通信模式呢?原因很简单,价格便宜且用户使用习惯了。但是笔者可以肯定,随着 CAN 模块的广泛应用,CAN模块价格不断下降,上述通信模式自然会被淘汰。
为了解决上诉所言的局限性问题,CAN 通信在这个问题上采用了差分电平的模式。所谓差分电平,简单的说就是不在使用电压的绝对值来表示信号,而是使用两根线之间的电压差来表示。当 CAN_H 上的电压高于 CAN_L 上的电压 2V 左右时,表示 0(即显性电平),当两者之间的电压差在 0V 左右,表示 1(即隐性电平),如图所示。
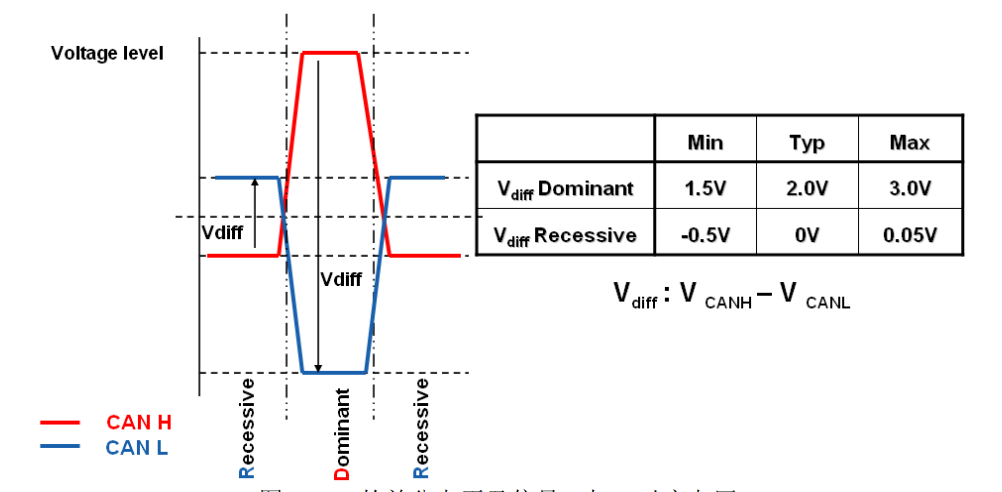
这种模式的好处在于:
-
设备间不需要将电源相连(或间接相连),两者之间只需要两根信号线便可以完成通信;
-
当通信距离增加时,两根通信线的电压会同时衰减或者放大,但是两者之间的电压差的改变相对较少,这样的结果是可以减少距离增加对信号的影响;
-
CAN 通信协议在设计时考虑到了广播通信的性能,增加了仲裁机制(这个在后续会讲到),使通信模式不再是简单的点对点,而是可以大范围的相互信息交换,极大的增加了网络利用率。
1.2、CAN 波特率
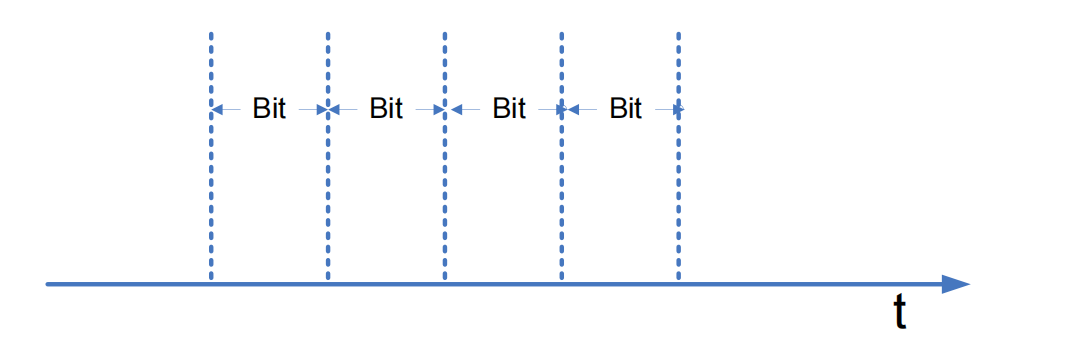
上面说到只要通信双方确定好传输的时间起始点和每个信号之间的时间间隔就可以确定当前的信号(见 章节 什么是 CAN 通信)。关于信号的起始,在后续(见 CAN 的起始位)中会详细解释如何同步到起始状态。时间间隔其实就是一段段时间间隔相等的时间段(如下图所示,一段时间就是时间轴上传输一个 bit 所需的时间),每一段时间的差分电压值就是该 bit 的值。为了方便起见,后面我们会用 bit 时间来代替“一段时间”的说法。波特率指的就是在 1s 内可以传送多少个 bit,单位 bps(bit per second)。
1.3、采样点的概念
在 1 个 bit 的时间内,差分电压的值会抖动,尤其是在起始阶段和结尾阶段,往往会有一段上升或者下降区间,如图 所示,报文抖动,在上升区间和下降区都有一定的延时。因此需要定义一个确定的采样点来确定该 bit 的值,这个确定的采样点在整个 bit 时间中的位置,就是采样点。
一个 bit 的时间又分为 4 部分(如下图所示),sync(同步段)+prop seg(传播段)+ seg1+seg2,其中 prop seg + seg1 加起来统称为 TSEG1,seg2 又为TSEG2。如图 ,为传播完同步+传播部分+ seg1 的时刻。
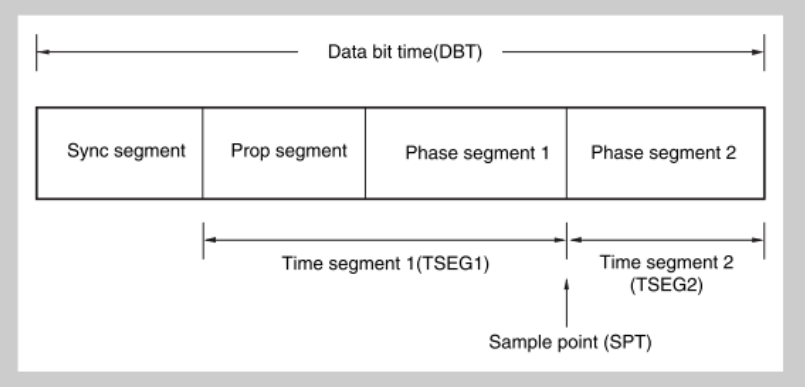
因此,计算采样点的公式为:
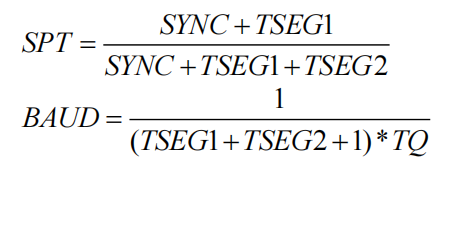
而 SYNC 始终为 1,所以采样点的公式为:
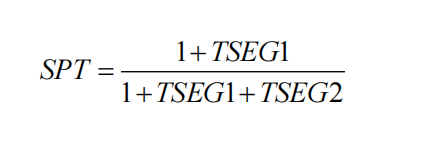
说到这里,读者肯定很迷茫,没有弄明白怎么回事。那么我们直接介绍一下工程中如何设置采样点。真正在使用中,TSEG1 和 TSEG2 都是 CAN 的寄存器,可以通过设置寄存器的值按照上述公式确定采样点。 如果您是工程人员,知道这些就够了,因为你已经知道怎么配置采样点了。但是如果您有耐心了解其中的来龙去脉,看完1.4章节的内容就明白了。
1.3.1、实战中遇到的问题
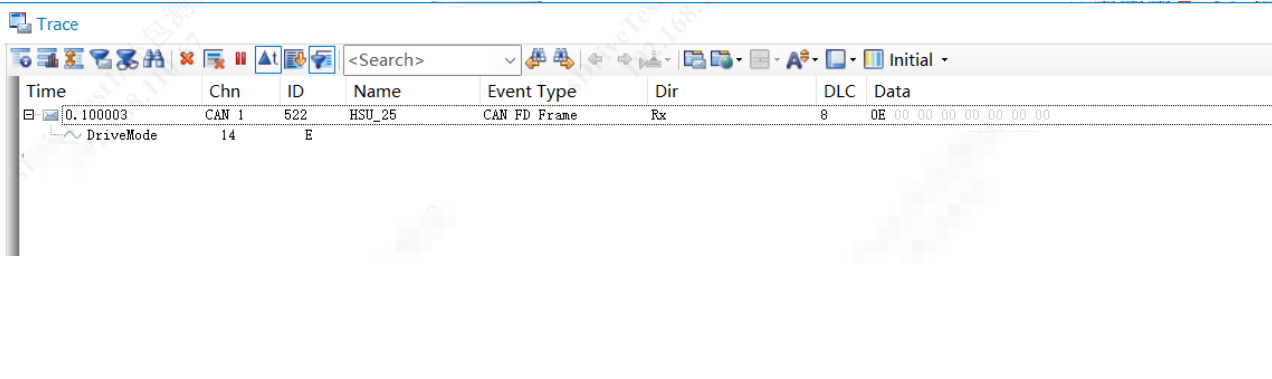
我在基于DaVinCi Config这套工具环境下开发通信配置时,发现ECU发出去的报文在CANoe上以错误帧的形式出现,如下图:
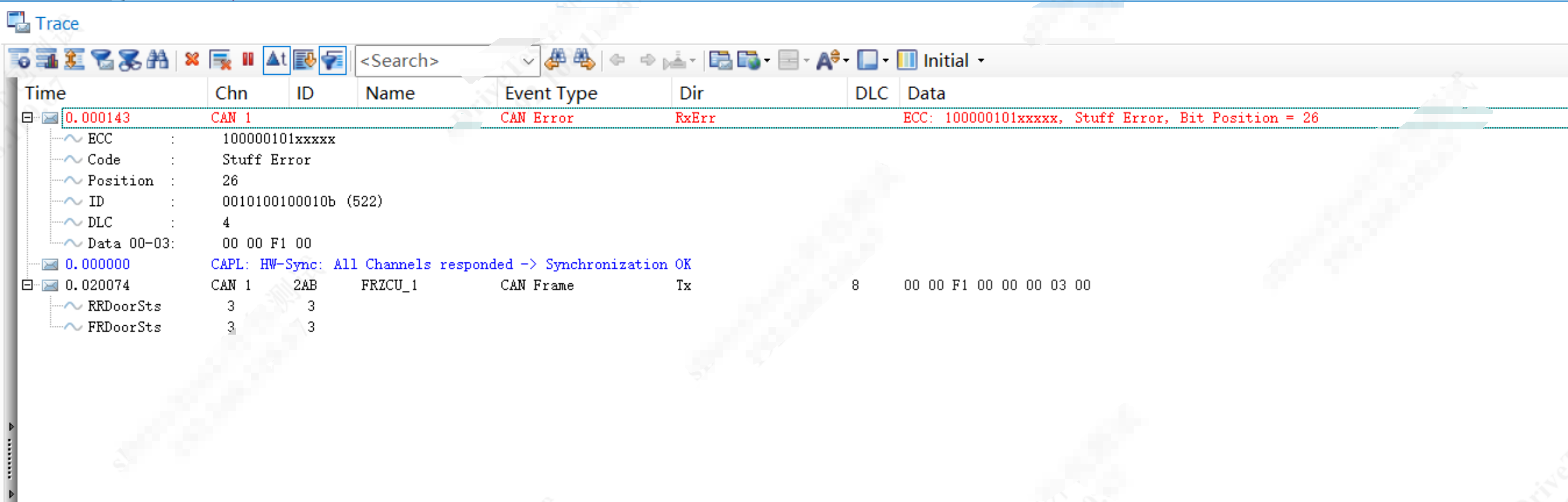
1)打开CANoe配置如下,CANoe上位机的采样点如下所示:
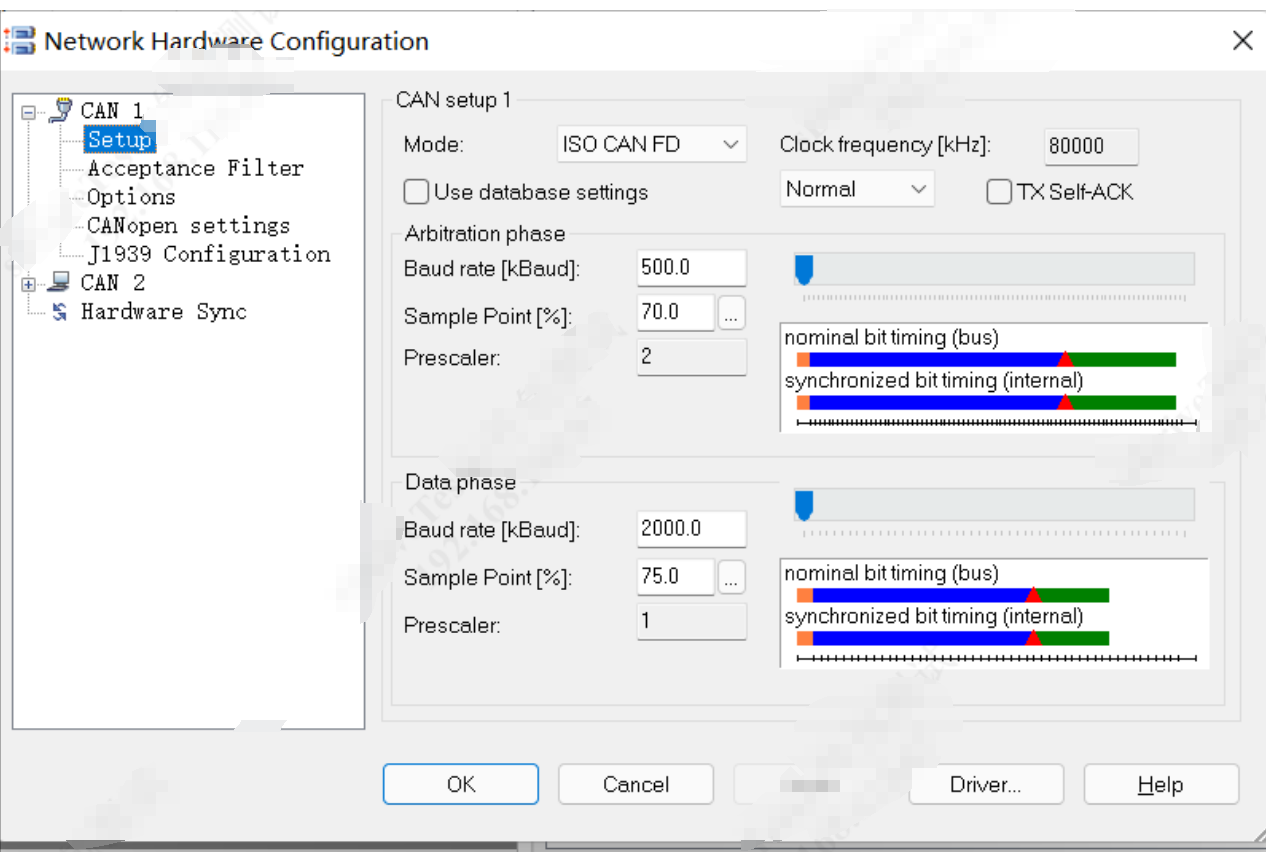
2)打开DaVinCi Config检查采样点配置:


3)计算上述配置的采样点:

4)修改CANoe上的采样点为80%
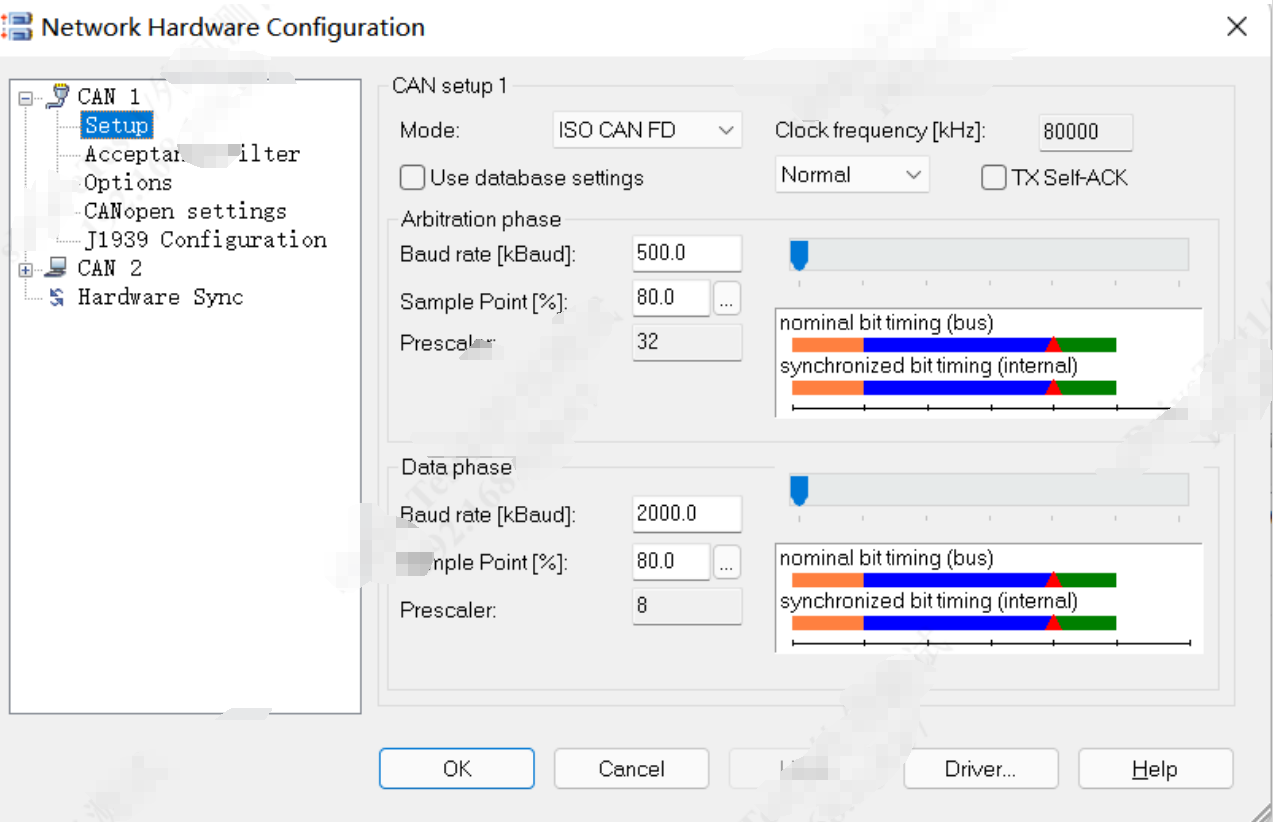
5)通信成功啦
1.4、波特率是怎么算出来的
我们来从最原始的状态开始分析。首先,CAN 的通信是靠一个晶振来提供频率(物理频率),我们将这个频率称为 CAN_CLK,用 fCANCLK表示。但是晶振一般都很快,如 4M、8M 之类,而 CAN 的速度并不需要这么快,因此这个频率需要被分频。
在 CAN 模块的寄存器中有一个寄存器叫 BPR(有的芯片会用两个寄存器来表示,两个值的乘积为 BPR 的值),就是用来分频的,分频后的频率用 fCAN表示,因此:
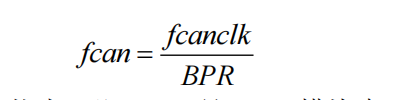
现在我们进入到第二个状态,即 fCAN 是 CAN 模块真正的频率输入而 fCAN 的倒数就是 CAN 模块里面最小的一个时间间隔,名字叫 TQ。
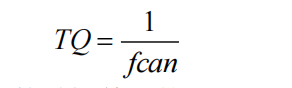
换句话说,CAN 通信里最小的时间单位就是 TQ。
这里千万注意,TQ 不是一个 bit 的时间,而是 CAN 模块的最小时间单位,这个 TQ 的值是由进入到 CAN 模块的频率决定的(进入到 CAN 模块的频率是由外部晶振和 BRP 决定的。如果将 BPR 配置为 1,那么 TQ 就是由 CAN 模块外部晶振决定的,其值为晶振频率的倒数。)
了解了 TQ 后就好办了,一个 bit 时间就是由 sync(同步段)+ TSEG1+TSEG2组成,那么这三部分分别是多少 TQ 呢?同步段规定为 1 个 TQ,而 TSEG1 和TSEG2 由寄存器设定而来。那么一个 bit 的时间就是:
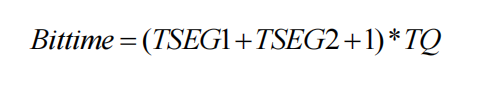
波特率的定义是 1s 可以传送多少个 bit,那么波特率就是 bit time 的倒数了:
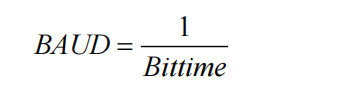
将 bit time 的公式代入:
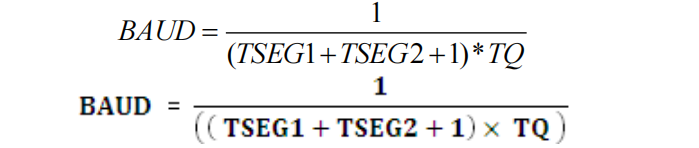
将 TQ 的公式代入:
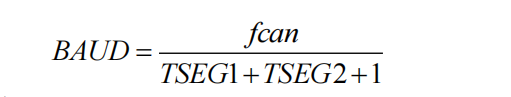
将 fCAN 的公式代入:
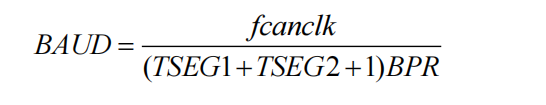
有了以上公式,在工程设计中,就可以按照需求设计出 CAN 总线上的波特率和采样点了,而这两样是在 CAN 的初始化中客户最关心的两样。
1.5、表征通信质量的一些参数
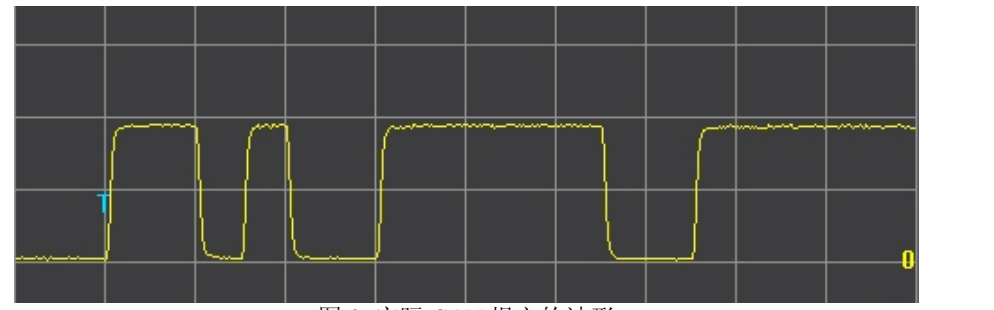
在 CAN 通信中,报文波形越整齐,说明通信质量越好。而实际的波形却不可能是完美的方波,如图 :
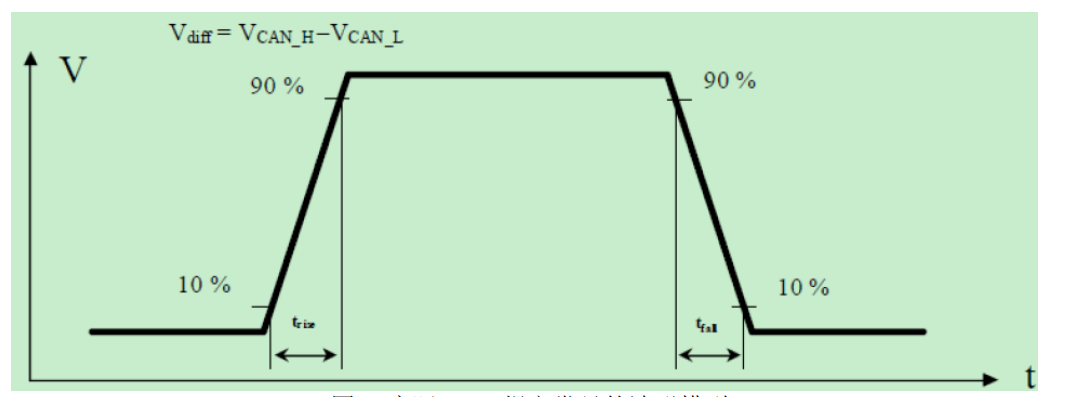
因此在底层测试的时候需要测试一些内容来表征波形的通信质量。一般在工程中会在各种输入电压下测试以下 CAN 信号的内容:
内部延迟时间——信号从控制器发送出来到真正达到 CAN 总线上的时间
电压值——包括 VCAN_H 、VCAN_L 、Vdiff 的电压变化范围
电压上升时间—— 电压从 10% V 到 90% V 的时间(如上图所示)
电压下降时间—— 电压从 90% V 到 10% V 的时间(如上图所示)
位时间测试—— 1 个 bit 传送的时间
采样点测试
以上内容的标准,一般在车辆设计时,统一由整车网络供应商提出标准。对于零配件供应商而言,其产品必须符合测试规范上的参数标准才能批产。
二、CAN 通信的数据链路层
在前面我们介绍了一个 bit 的认知方法和性能参数,然而 1 个 bit 是构不成通信报文的,在 本章节中我们主要讲解网络上 CAN 报文的发送和接收情况。
2.1、CAN报文的组成
CAN 的报文分四种,数据帧、远程帧、超载帧、错误帧。在实际的工程应用中,一般用到的是数据帧,另外芯片因为一些故障也会自动发送错误帧出来。对于远程帧和超载帧由于工程上基本没用,此处不做讨论,重点讲述数据帧,并简单介绍一下错误帧。
所谓数据帧,就是用来传送数据的报文,如图所示,一帧 CAN 报文首先是帧起始,然后进入仲裁场、控制场、数据场、CRC 场、ACK 场,帧结束。后面我们详细解释每个场的用途和注意事项。顺便说一下,这些场的处理都是由芯片自身控制的,和软件设计、驱动编写基本没有关系(这里加上了“基本”,是因为有的芯片在设计的时候会预留一些寄存器来获取这些场的状态信息,但是这些信息对于正常的通信一般不会用到) 。因此,对于不做物理层测试的工程师们,可以不用阅读后续场描述的章节。
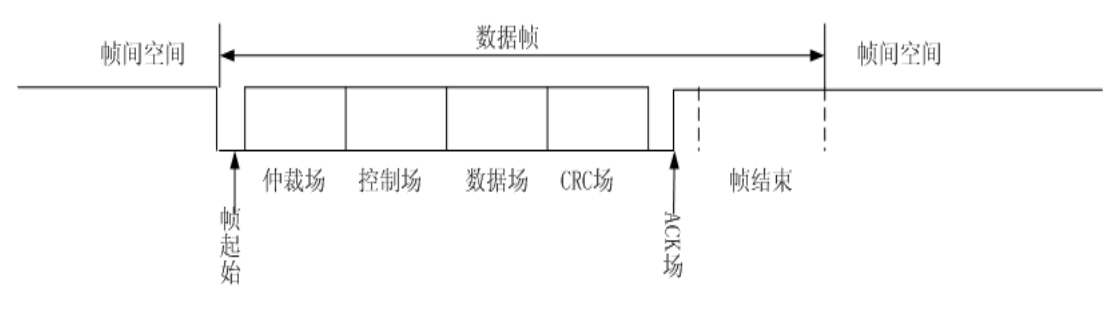
那么对于使用 CAN 通信的工程师需要注意什么呢?从 CAN 报文的功能来
说,只需知道 4 个概念:
- 报文的 ID
- 报文的内容
- 报文的新旧
- 网络是否故障
对于这四个概念的解释是
报文的 ID 用来表征这帧报文是谁发来的或者是要发给谁;
报文的内容表示我收到了些什么数据或者我要发送什么数据;
报文的新旧表明这帧报文是这次传来的还是上次传来的,或者上次的报文是否已经发送出去,当前是否可以继续发送;
网络是否故障表明当前网络是否可以通信。
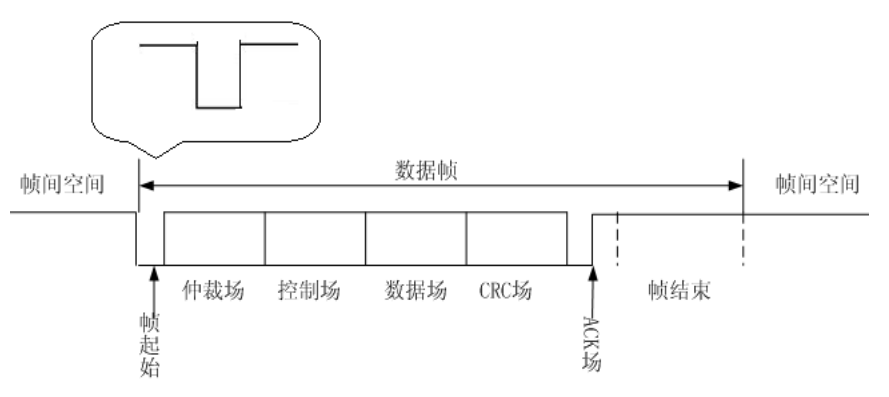
2.2、帧起始
帧起始 SOF(start of frame),就是一个显性位(如下图)。大多数的书都是这种解释,这样解释在理论上是没有问题的,但是大家看完后,会很迷惑,为什么显性位就是 SOF,如果数据过程中来了显性位是不是都是 SOF 呢?现在我来解释一下。
不知大家还记得,在前面所述,我们说“通信双方确定好传输的时间起始点和每个信号之间的时间间隔,就可以区分出各时间段的电平,通过电平确定当前传递的信号是 0 还是 1”。关于时间间隔的解释,在波特率的相关章节已经说明,现在就来说说这个这个“起始点”的问题。CAN 的规范规定了 CAN 总线在空闲时候是隐性电平(即 CAN_H = CAN_L 的时候),换句话说,无论是刚上电,还是一帧发送完成后,总线上都是隐性电平状态。因此当总线处于空闲态时,来了一个显性电平,就说明 CAN 报文要开始传送
(请注意,这里说的是总线空闲态,不是隐性电平)
2.3、仲裁场
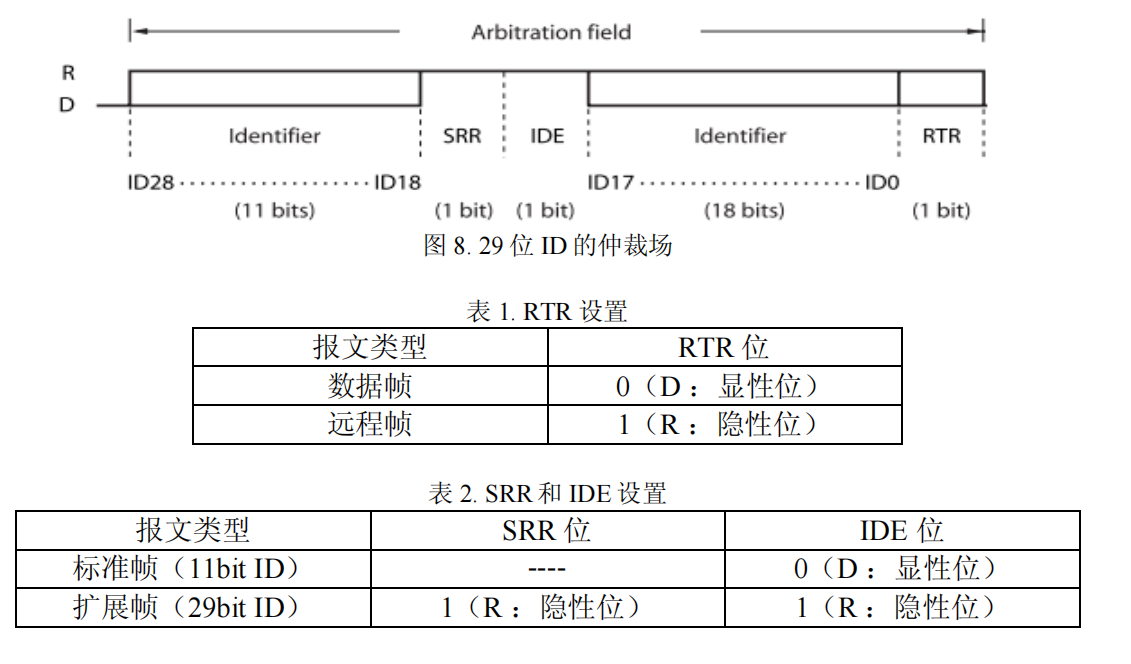
仲裁场其实就是为了表示 CAN 的 ID 号,所谓仲裁的概念就是要通过一个 ID号让 CAN 总线上的节点知道这一帧究竟是发给谁的。CAN2.0 协议中规定了两种数据帧,一种是 11 位的,一种是 29 位的。定义这两种报文形式的目的是为了针对通信 ID 号的数目。当 ID 数目过多的时候,就采用 29 位的 ID。 如图所示,在 11 位 ID 的报文中有 11 个 bit 表示 ID 号,还有一个 bit RTR 表示该报文是远程帧还是数据帧。
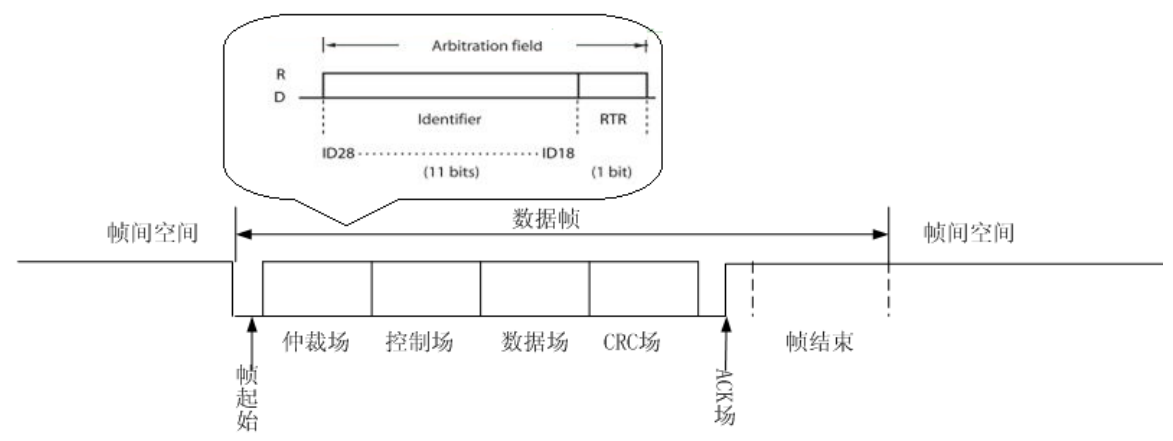
这里顺便讲解一下扩展帧,所谓扩展帧,即使用 29 个 bit 来表示 ID 号,与11bit 的标准帧相比,具有更多的寻址空间(11 位的 ID 有 2^11 次的寻址空间,而29 位的 ID 有 2^29 个寻址空间)。ID 的仲裁场如下图所示,除了有 29 个 bit 表示ID 号,还有一个 bit SRR 和一个 bit 的 IDE 共同表示该报文是标准报文还是扩展报文,当两个都为隐性电平时,就表示为的扩展帧。另外和标准帧一样还有 RTR 位表示报文是远程帧还是数据帧。(如下图 、表 1、表 2 所示)
在实际的工程环境下,网上的众多节点都是定时向外发送自己的报文,这种发送方式对于整个网络来说是没有先后顺序的。换句话说,在某一个时间点上有可能几个节点同时发送报文,也可能一段时间内没有一个节点发送报文。那么对于多个节点同时发送报文时,到底谁会先发出去?答案是当多个节点同时发送报文时候ID 号小的会先发出去,简单的解释是两个节点同时发送了自己的报文,经过相同的起始位(都是一个显性电平),在发送 ID 时分道扬镳,ID 号小的发送出去了,ID 号大只能等小的发完后在发送。举个例子吧,网上有节点 A ,ID 为 0x000,另一个节点 B ,ID 为 0x400,还有一个节点 C, ID 为 0x7ff,三个节点同时发送报文,那么 A 最先发送,B 其次,C 最后。具体的原因我们暂时放一放,在 ACK 那一章里一起回答。
2.4、控制场
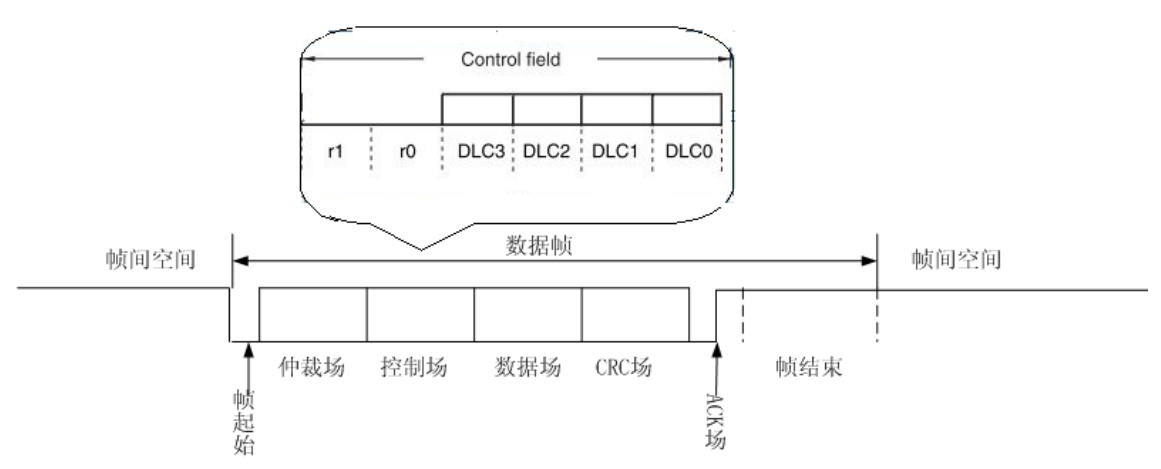
控制场的目的主要是确定这帧报文的数据长度,其中在 r0 和 r1 是保留位,DLC3-DLC0 表示数据场的数据长度。
2.5、数据场
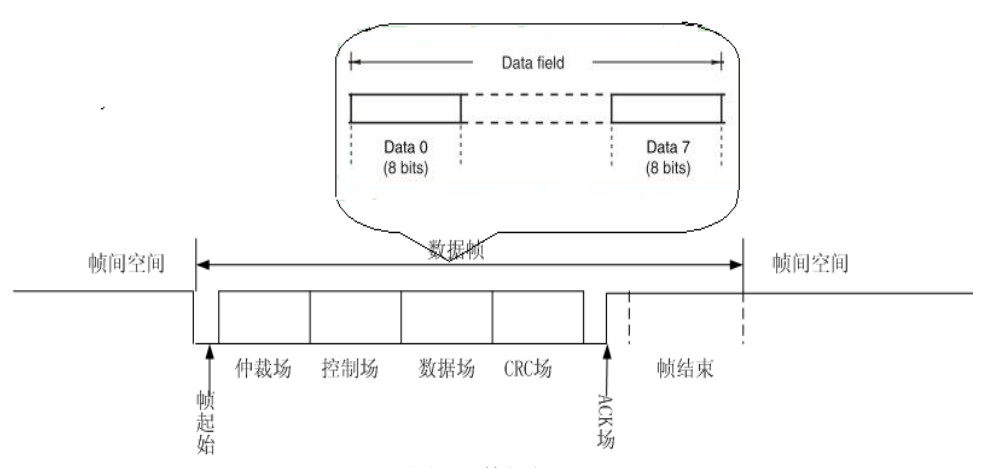
数据场才是 CAN 报文中真正表示内容的部分。数据场最多 8 个字节,具体长度由控制场中的 DLC 值决定
2.6、CRC 场
CRC 场用于校验前面的数据(仲裁场、控制场、数据场)
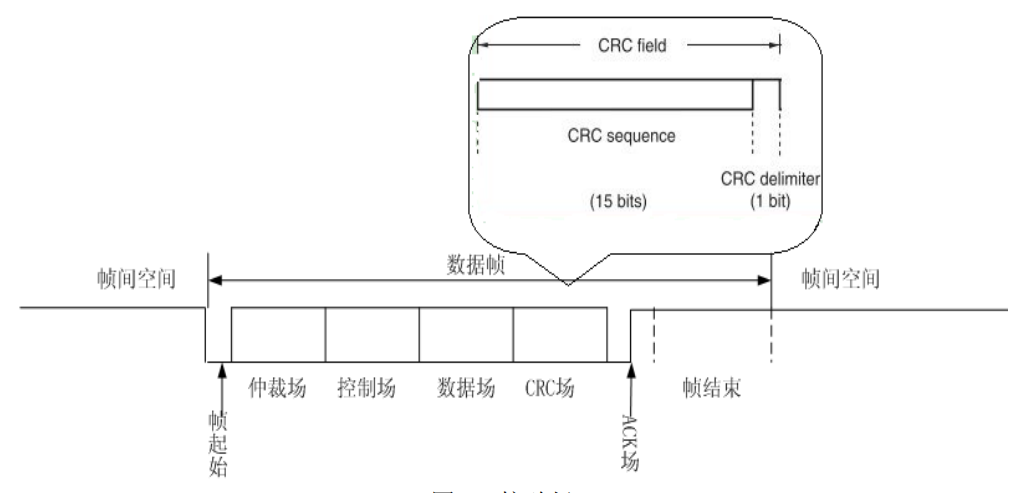
2.7、ACK 场
ACK 场是用于表达 CAN 报文的应答标志,里面有两个 bit 时间。当发送节点发送完 CRC 场后,会发出一个隐性电平(在 ACK slot 时间内),当接收节点在ACK slot 中收到该隐性电平时,会马上发出显性电平(也在 ACK slot 时间内),这时发送节点监控到该显性电平就认为一切正常,然后会发送另外一个隐性电平(即 ACK delimiter)
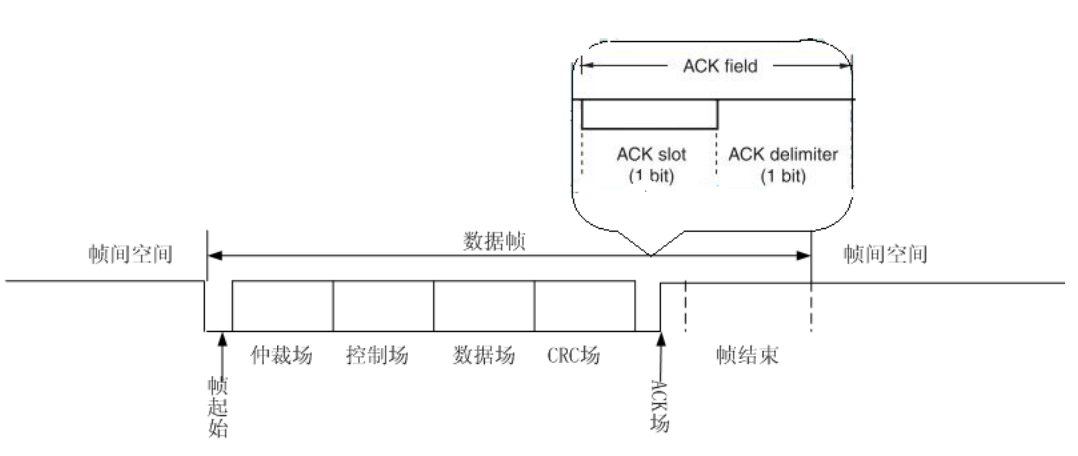
这里读者会有点迷糊,一会儿隐性,一会儿显性的。笔者需要详细解释一下,顺便也可以解释前章节中在仲裁场中确定当前是哪个发送节点在工作的问题。 我们先补充一点基础知识,CAN 模块(硬件层面上)有确保信号发送成功的机制,即在发送电平出去的时候,会同时接收到自己发送的电平,然后作出判断,当自己接收的电平和发送的一致时,就认为这个 bit 发送成功,如果不一致就知道发送失败。但是,有两种情况除外,一种是在仲裁场,一种是在 ACK 场。这两个场中是允许发送电平和接收电平不一致的。
好了,有了以上知识,我们来解释下 ACK 场的问题。ACK 场存在的目的是判断总线上除自己以外的其他节点,通俗的说,就是我发送了数据,有没有人接收。那么怎么判断呢?解决方法就是,发送节点在 ACK slot 期间发送一个隐性电平,如果网上有节点接收,会在接收到该电平的时候马上发送一个显性电平。这样做的结果就是,CAN 的硬件模块在发送的时候是隐性电平,而在接收的时候收到了显性电平,在 ACK 场中,出现这种情况,就证明网上有其他节点,通信可以正常进行。请读者注意一下,是一定要在 ACK 场中。
接着,我们解释下仲裁场中的问题。在发送完起始位后,节点们按照自己预定的 ID 号向外发送 CAN 报文,与此同时,CAN 模块也在监测网络上的电平。当一个节点发送的是隐性而接收的是显性时(即在仲裁场内,自己发送是“1”信号,而监测到的网络上的信号却是“0”信号),这个节点就知道了,有一个级别比它高的节点正在发送报文,于是它会自动放弃发送,而等一段时间后重新发送。
这里需要注意的是,在 CAN 网络中,显性电平是起主导的电平,简单的说就是当两个节点都在发送信号时,一个发送显性电平,一个发送隐性电平,那么网络上就是显性电平。这样就解释为什么 ID 号小的报文先发送,因为显性电平是逻辑“0”,同时有 0 和 1 信号时,总线上就是信号 0,所以大 ID 号的节点就退出了发送。因此,当小 ID 号报文和大 ID 号报文同时出现在 CAN 网络上时,小的 ID 号总是可以“战胜”大的 ID 号,而占有网络。
2.8、结束位
结束位表示的是该帧报文已经结束,由 7 个 bit 的隐性电平决定。
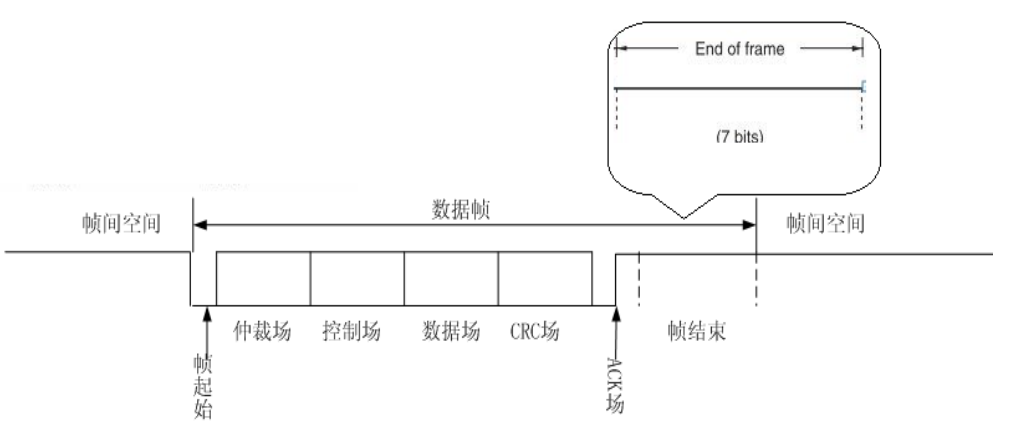
在结束位后,会有不少于 3 个 bit 的隐性位来间隙两帧(芯片自动的)。这样就保证了 CAN 报文由显性电平启动,由隐性电平结束。
三、CAN驱动
3.1、CAN 驱动的位置
在实际的工作中,CAN 驱动的主要作用一方面是驱动 CAN 控制器,即提供接收和发送的接口,另外一方面是提供一些标志,表征当前 CAN 的状态,如是否正在发送、是否正在接收、是否有故障、是否….等等。无论是哪种架构,CAN 驱动都是最下面一层,它是专门和硬件打交道的,用于驱动硬件的控制芯片。对于软件开发者而言,所谓 CAN 驱动就是对寄存器的处理,不同的芯片有不同的驱动函数,但是最终的目的都是让 CAN 控制器可以正常的通信起来。
3.2、CAN 驱动的内容
关于 CAN 驱动,一般会将其分为三部分:初始化部分、数据处理部分、特殊处理部分。这里说明一下,对于驱动,本来没有所谓“部分”的概念,其实就是寄存器对应通信功能上的开关,但是在真正到了工程应用的时候,往往将其分为一些不同的模块来处理,所以笔者就有了以上三部分的概念。
3.2.1、CAN 初始化
CAN 的控制器,对外表现就是芯片的两个管脚,而且这两个管脚是可以复用的两个脚。经过初始化后,通过软件设置使其成为 CAN 的接口。初始化的过程分为三步:
1) 管脚初始化—将芯片的管脚初始化为 CAN 功能
2) 控制器初始化—启动控制器,配置控制器参数
3) Buffer 初始化—初始化芯片的硬件缓存
以上三步是所有初始化过程中都要经历的。管脚初始化,又可以称之为硬件初始化,主要是将芯片的这两个管脚初始化为 CAN 功能。控制器初始化,将 CAN控制器打开,赋予该 CAN 口的各种特性,如波特率、采样点、控制器状态。Buffer 初始化,将控制器的硬件缓冲配置为 CAN 协议的接口参数,如过滤器mask、发送接收、是否中断等。
对于所有的 CAN 驱动,前两步基本都是相同的,即将这个芯片的管脚初始化为 CAN,且启动通信功能,并配置时钟等基础功能,但是,Buffer 的配置方法却有很大的不同。每个芯片都有自己的配置方法,因此也推出了各自名目的 CAN,听说过的就有 AFCAN、CCAN 等等,各有不同,但是总体上分为两大类:basic CAN 和 full CAN。
3.2.2、basic CAN VS full CAN:
这里首先解释下 basic CAN 和 full CAN 的区别,然后才好说明初始化不同之处。对于 basic CAN ,顾名思义,就是基础 CAN,涵盖 CAN 基本功能。这种模式下芯片很简单,对于所有网络上正在流通的 CAN 报文都会接收到到芯片的预接收buffer 中,穿过 filter 后就统一放到芯片的硬 buffer 里面(通常这个硬 buffer 是CAN 控制器自带的,数量很少,过滤器也是统一的),然后挂起一个寄存器通知软件层来处理。接收过程可以参考图:
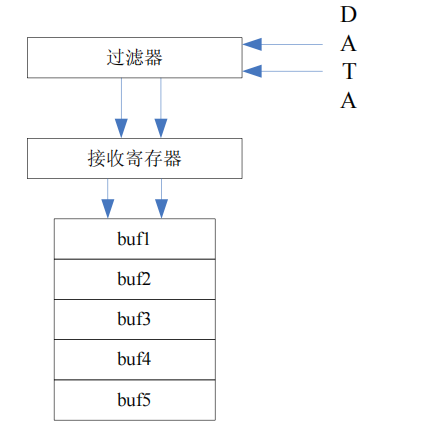
而 full CAN 就不同了,它可以通过硬件的设置,根据 ID 号的不同来区分 CAN报文,比如有 32 个硬接收 buffer,我们预先配置 32 个 ID 号使每个 ID 对应一个硬buffer,那么当报文来的时候,芯片会根据 ID 号的不同自动分析,并将 ID 号一致的报文放到对应的 硬 buffer 中,如果没有对应的 ID 号,那么这帧报文会自动丢弃。每个硬 buffer 可以选择不同的配置,如有没有 mask 过滤器,几号 mask 过滤器(甚至有的芯片可以一个硬 buffer 配一个可设置的过滤器),DLC 过滤器等等。
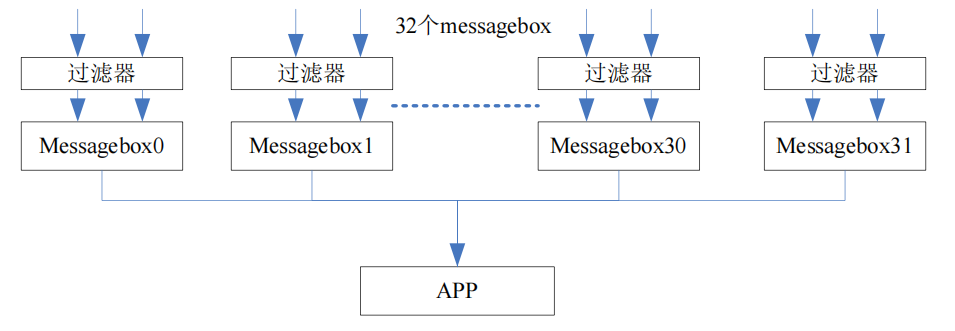
举个很简单的例子来比喻 Basic CAN 和 full CAN 的处理方式。我家有间仓库,平时用来堆放我的东西。那么存储的方式有两种,一种是只要来了东西就往里面放,直到放满为止,另外一种是将仓库分为诺干个小格子,每个格子只能放一种类型的东西。
那么对应于 CAN 的两种模式,就很明白了,前一种是 basic CAN,后一种是full CAN。这两种处理方式各有其优劣之处。对于 basic CAN 而言,我可以最大程度上的利用我的资源,只有在仓库放满的时候才会丢弃一些东西,但是劣势就是我每次找东西的时候很麻烦,因为我要把整个仓库都翻出来,将东西理一遍才知道我要的东西在哪里。与之相对的 full CAN 却不同,东西摆放很整齐,要找东西很方便,但是问题是我浪费了一些空间,因为有的类别的报文很少才来一帧,而有的类别却一直来。
虽然 Basic CAN 的硬 buffer 很小,但是软 buffer(所谓软 buffer 就是单片机里面的 RAM 空间)却可以做的很大,只要是收到的报文都可以存储到软 buffer 中,这样对于网络节点多,CAN ID 多,但是数据量很小的网络而言,使用 Basic CAN是一个很好的选择。(例如网络上有 100 个 CAN ID 需要发送,发送完所有的 ID号需要 10s 的时间,即平均 100ms 才一帧报文)full CAN 虽然可以根据 CAN ID 的不同来分类,但是硬 buffer 毕竟有限(笔者见过的硬件 buffer 最大的是 64 个),那么对于多 ID 的环境而言就不适合了(如上述 100 个 CAN ID 的时候)。
而在数据量大,CAN ID 少的情况(如 20 帧 CAN 报文每 10ms 轮询一次)就恰恰相反,这种情况下 full CAN 可以很好的接收到这些 CAN 报文,将其归类,减少了软件层面上的大量工作,有效的提高了软件的效率。
Full CAN 除了以上主流的实现方式,还有一些非主流的实现方式,如硬 buffer只有一个,却有多个 mask(即掩码,用于确定不同子网的 ID 优先顺序),初始化时将 ID 和 mask 绑定,根据接收时与 mask 的匹配来分类报文。非主流模式,这里不在详细阐述。
一般对 buffer 的初始化,basicCAN 的没有什么好初始化的,数据来了就在硬件接收 buffer 里,想啥时候读取就啥时候读取,对于发送,只要填充进硬件的发送buffer,然后置位发送就可以了。这里需要讲讲的是 full CAN 的初始化,对于 full CAN 而言,需要配置硬buffer 的以下基本属性:
帧类型
报文类型
接收还是发送
报文长度
名字(即该 buffer 的位置处于硬 buffer 中的第几个)
CAN ID 号
mask 是多少
是否需要中断
是否支持覆盖
初始化后的 CAN 控制器,就可以用了,挂在 CAN 网络上就会自动和网上的各个节点之间相互响应,如自动回复 ACK 场,自动发送故障帧,接收符合设置的报文等等。
3.3、CAN 的接收和发送
仅仅完成初始化显然对于 CAN 节点的通信是不够的。CAN 通信最终的目的是将自己节点想要传递的信号发送出去,将和自己有关的内容接收进来。
CAN 的接收在驱动层面仅仅就是一个读取寄存器的过程,对于各个名字不同、地址不同的寄存器,可以获取 CAN 的各种信息。这里我们不对具体的驱动做解释,只谈谈数据接收的过程:当网络上有报文经过时,CAN 的控制器会将该报文截获,然后放到一个寄存器中(该寄存器对软件层面不可见,即这个寄存器的状态变化不在软件中看到,也不能通过软件改写寄存器值),然后将这个报文与各个filter 一层层比较,当符合所有的 filter 后,就将报文接收到硬件 buffer 中。Basic CAN 的 filter 一般就是 mask,只要 mask 过滤通过就会到硬件 buffer 中,而 full CAN 除了 mask,还会多一些其它的 filter,比如 DLC、ID 等等。当穿过来这些filter 后,能够在寄存器中读取的报文就是指定的需求报文。
对于 basic CAN 的接收,由于其硬件 buffer 会比较小(主要是为了省成本,也许这就是它被称为 Basic CAN 的原因吧)。所以一般处理上会建立一块软件 buffer来存储这些报文,如图:
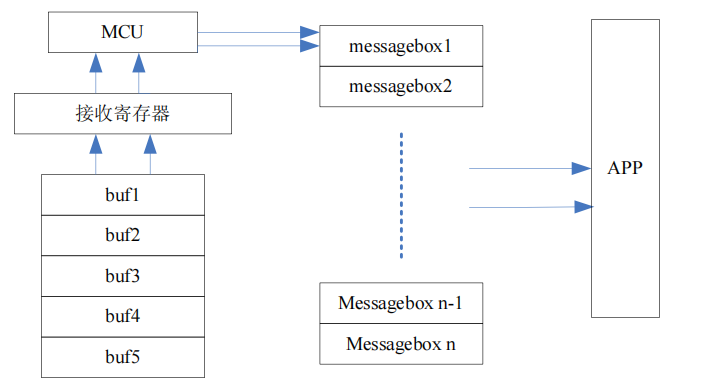
对于接收上来的报文,一般上层只需要三个信息:CAN ID 、CAN 报文、报文长度。根据这三个信息就可以处理 APP 的各种需求了。
在 CAN 接收的过程中,有一种极端的情况需要驱动编写者尤其注意。我们知道,读取报文的过程就是读取寄存器的过程,但是读取的寄存器不是一个,至少是10 个。那么会有一种情况:正在读取的时候,来了一帧新报文,新报文覆盖了旧报文,导致这帧报文前面几个字节是上一帧的,后面几个字节是后一帧的。因此,在工程使用的时候,往往会将报文读取方式设置为保存旧报文,即如果新报文来了,而旧报文没有来,就丢弃新报文。
CAN 报文的发送相对比较简单,也没有什么值得深究的。整个过程无非是:将数据写入寄存器,置位发送标志,该报文自动发送出去。这里需要提一下的是,工程上为了保证数据发送不会过载,往往会有一个表示该帧报文是否发送成功的函数接口,通过这个接口的返回值可以获取当前发送的状态,从而处理发送过程中的各项问题。还有的时候需要发送多个报文,但是硬件 buffer 比较少,一次发不完,这个时候可以考虑在软件 buffer 中做个发送报文队列,等硬件发送完毕,中断后将队列的报文写入发送。
3.4、CAN 的发送和接收故障
CAN 的故障有很多类,如 bit error ,crc error,ACK error 等等,但是总结到驱动层就两种:一种是发送错误,一种是接收错误。这两种错误在驱动级对应有两个寄存器来表示。寄存器值由小到大,有几种状态:
- 没有故障(其实也不能说一定没有故障,应该说是故障数量<96);
- 有故障,但是故障不严重(故障数量在 96~127 之间);
- 严重故障(故障量在 128~255 之间);
- bus off,(最严重的状态,故障量大于 255,有的芯片不在发送接收故障寄存器中表示该状态)。
其中,1 和 2 的状态称之为 error active,3 和 4 的状态称为 error passive,这两种状态下的故障帧格式不同。
软件层面上,大多数的项目不会分别 error active 和 error passive 状态(大多数,具体到多少,给个估计吧,95% )。在故障情况下,不需要特意的去处理这些故障计数器,这些故障计数器的值也是可以自我修复的,当网络恢复正常后,寄存器的值会自动降低。软件层面一般关注的是下面这个概念:bus off。
3.5、CAN 的 bus off
Bus off 在通信层面上是严重故障的代名词,但是在驱动层面上而言,就是一个寄存器的值。
为什么软件层面要处理 bus off 呢?原因很简单,因为 bus off 后,即使总线恢复正常状态,如果软件层面不对 bus off 的寄存器处理,CAN 网络也不会恢复,而且往往在处理了 bus off 寄存器后还需要对 CAN 模块重新初始化,才能保证 CAN通信的正常运行。
有一种情况是软件工程师需要注意的:如果总线处于 bus off 状态(比如CAN_H 和 CAN_L 短路),寄存器不一定就显示当前 bus off 了,这是为什么呢?
我们知道, bus off 是严重故障,其故障次数需要大于 255 次。当总线处于静态时候,无任何节点发送报文,仅仅完成了初始化,这个时候网上并没有故障帧,也没有故障位出现,因此芯片控制器无法得知此时网上是否故障,因此无法置位 bus off 寄存器。那么软件层面上如果需要知道当前网络是否是 bus off,需要按照以下步骤工作:
- 发现 bus off 寄存器置位
- 清除 bus off
- 重新初始化
- 重新连接 CAN 网络
- 尝试发送报文
只有在尝试发送报文后,CAN 寄存器才知道是否当前网络又 bus off 了。这里需要说明下,所谓尝试发送报文,就是调用了 CAN 发送的函数。更直白的说就是将发送报文写到了发送寄存器,置位发送。这个发送报文就是来自应用层的正常报文。不管网络状况如何,这些报文都是会定时传送的。显然,如果网络仍然是 bus off 状态,这个报文肯定发不出去,但是硬件会尝试发送,导致 error 产生,进而使自己的芯片监测到 error,并置位 bus off 寄存器。有以下结论:网络上如果无报文收发时,bus off 寄存器不会检测到该故障。对应到软件编程上,当网络恢复 bus off 后,需要尝试发送报文,然后才能去检测 bus off 寄存器。
总结
本文节选看的一本书里的内容,看完之后让我加深了印象。如果哪里表达的有问题,还请大佬们指点指点哈。只算是个人笔记,内容和图片非原创。