BEV-LaneDet
1 BEV-LaneDet简介
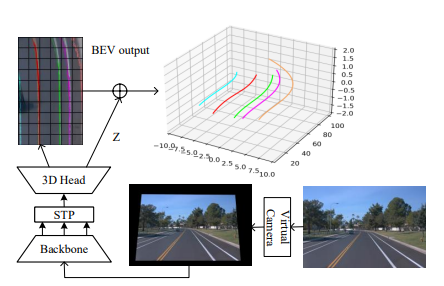
提出了一个高效且简单的单目3D车道线检测方法,称为BEV-LaneDet,有三个主要贡献。
①. 引入了Virutal Camera,统一了安装在不同车辆上的相机的内/外参数,以保证相机之间空间关系的一致性。
②. 提出了一个简单而有效的三维车道表示法,称为关键点表示法(Key-Points Representation), 这个模块更适合于表示复杂多样的三维车道结构。
③. 本文提出了一个轻量级和芯片友好的空间转换模块,名为空间转换金字塔(Spatial Transformation Pyramid),用于将多尺度的前视特征转换成BEV特征。
实验结果表明,BEV-LaneDet在F-Score方面优于最先进的方法,在OpenLane数据集上高出10.6%,在Apollo 3D合成数据集上高出6.2%,V-100上速度为185FPS。
2 BEV-LaneDet架构
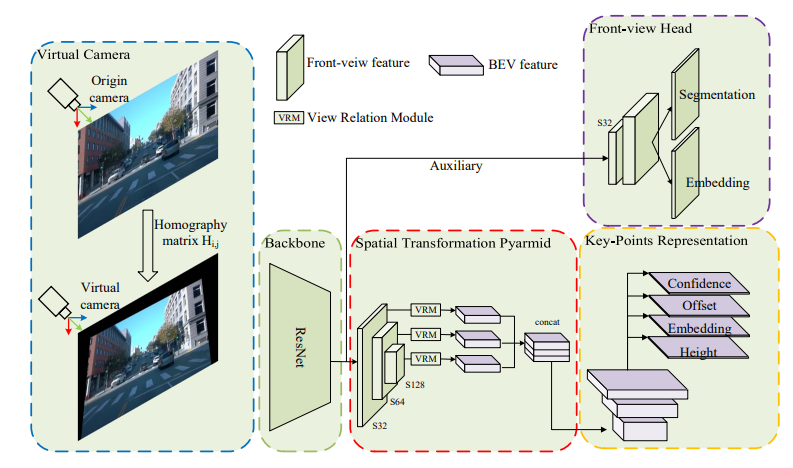
2.1 Virtual Camera
不同车辆的内/外在参数是不同的,这对3D车道线的结果有很大影响。传统的方法采用将摄像机内、外参数整合到网络特征中(PersFormer、LSS等)。
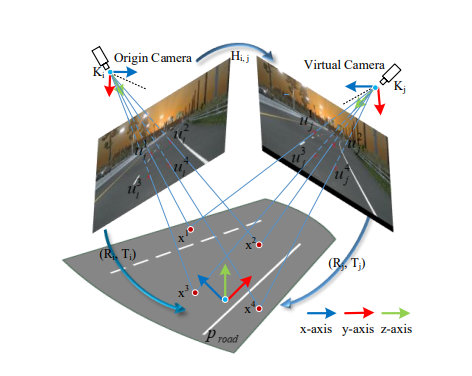
本文实现了一种统一相机内外参的预处理方法,即通过建立具有固定内外参数的虚拟相机(Virtual Camera)完成各个相机的图像内/外参数的快速统一。
核心如何找到当前相机往虚拟相机投影的homography (同源性)转换矩阵Hi,j ?
虚拟相机的说明:
①. 由于 3D 车道检测更关注平面 Proad, 因此假设 Proad 是与局部路面相切的平面。
②. 虚拟相机的内在参数 Kj 和外在参数 (Rj , Tj ) 是固定的,它们是从训练数据集的 in/extrinsic 参数的平均值得出的。
③. 模型在训练的时候每辆车都需要计算一下当前相机转化到virtual camera的转化矩阵Hi,j 。在真正上车运行的时候,Hi,j 仅仅需要计算一次就够了.
操作流程:
①. 在 BEV 平面 Proad 上选择四个点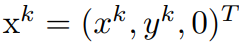
,其中 k = 1, 2, 3, 4。
②. 将它们投影到当前相机的图像上得到 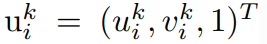
③. 将它们投影到虚拟相机的图像上得到 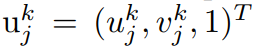
④. 通过最小二乘法: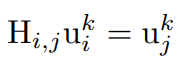
求取Hi,j
⑤. 获得Hi,j后,利用opencv的库函数:cv2.warpPerspective,可以将原始图像投影到虚拟相机图像。
2.2 MLP Based Spatial Transformation Pyramid 基于MLP的空间变化金字塔
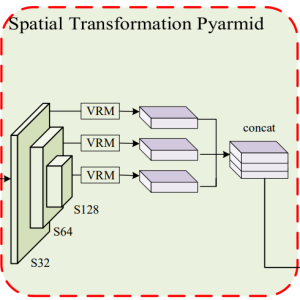
2.2.1 为什么选择MLP作为空间转化(VPN,VRM)?
①. 对于车道线检测这种静态的任务,VRM效果好于基于transformer的方法(BEVFormer,PersFormer等) 和 基于ray的方法(LSS,Fast-BEV等)
②. 计算量小,易于部署。
2.2.2 VRM方式的问题与优化
①. VRM映射方式固定,太过单一 -----借鉴了FPN架构,提出STP(在不同尺度的2d特征图上,采用多个VRM进行映射转换,这样就存在了多个固定映射的可能,然后让卷积去对多层VRM的结果进行可学习的组合,这样一来VRM就有了“个性选择”的能力了)
②. 没法融入相机的内外参 ----- 提出虚拟相机
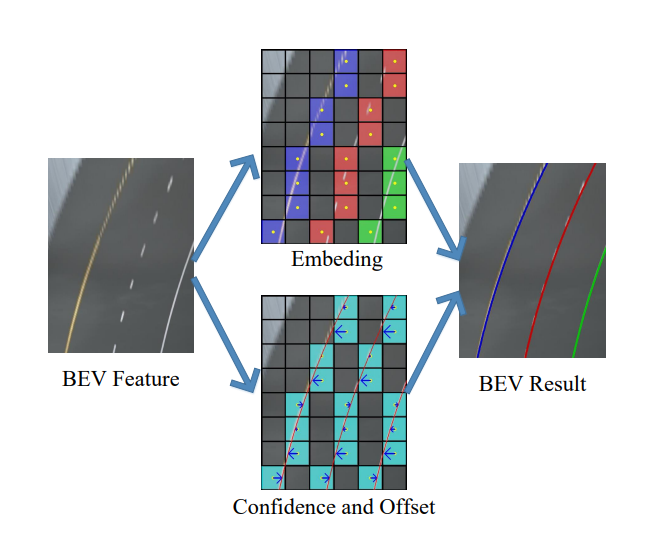
2.3 Key-Points Representation
借鉴了Lane-det和yolo的思路,采用分割的方式去表征车道线建模:
Confidence:是否是车道线的点
Offset:横向偏移量(解决分割下采样时的误差)
Embeding:车道线的点是否属于同个实例
3 损失函数
为了更好的收敛,又增加了2d检测头进行辅助训练监督,总的损失函数如下:
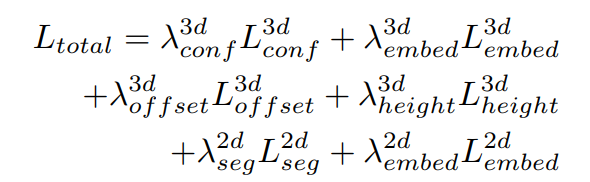
3.1 Confidence loss
BCE loss:
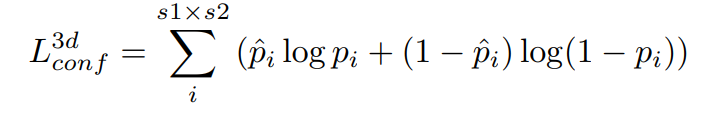
3.2 Offset loss
MSE loss
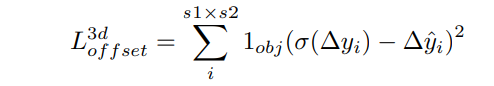
3.3 Embeding loss
push-pull loss
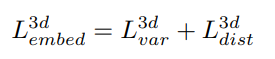
3.4 Height loss
在网络的训练阶段,我们使用网格单元中的平均高度作为地面实况。同时,只有具有正地面实况的格网像元才会计入损失。
MSE loss
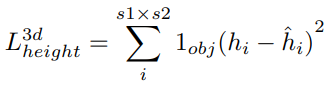
4 实验对比
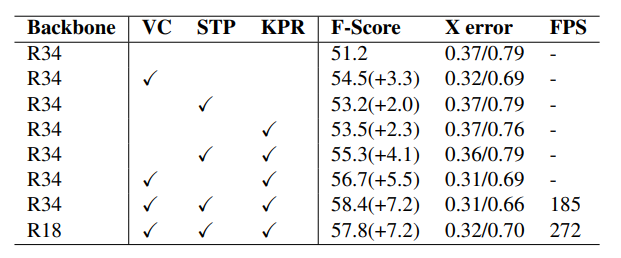
①. 和其余3D车道线算法对比,速度和精度优于其余算法

②. 不同模块的对比实验(ResNet18,virtual camera, STP, 关键点表征)
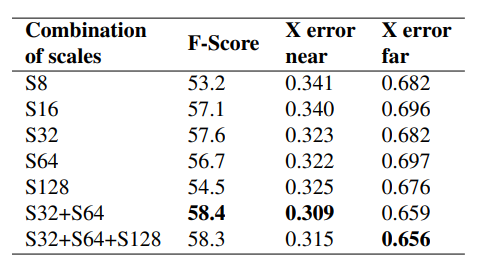
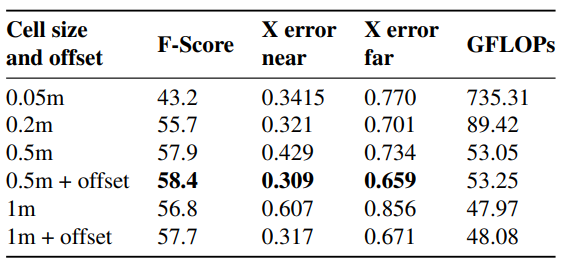
③. 分割单元大小和offset实验
④. 空间变换期间前视要素图层中不同比例的比较。S32 表示输入图像的 32 倍下采样。S32 + S64 表示输入图像的 64 倍下采样和 32 倍下采样的串联。