Go 并发(协程,通道,锁,协程控制)
一.协程(Goroutine)
并发:并发是指程序能够同时执行多个任务的能力
协程:
Go 中的并发执行单位,类似于轻量级的线程。
Goroutine 的调度由 Go 运行时管理,用户无需手动分配线程。
使用 go 关键字启动 Goroutine。
Goroutine 是非阻塞的,可以高效地运行成千上万个 Goroutine。
在main()函数调用时就开启了一个主协程,主协程停止则其他的由主协程创建的分协程也停止
协程的好处:
- 轻量级:协程的创建和切换开销非常小,可以在一个程序中创建大量协程。
- 自动调度:协程由 Go 运行时自动调度,开发者不需要手动管理线程的创建和销毁。
- 共享内存:协程之间可以共享相同的地址空间,简化了内存管理和数据共享。
- 非阻塞:协程之间的通信和同步是非阻塞的,避免了传统线程中的锁竞争问题。
协程与线程的区别:
协程:
- 非操作系统提供而是由用户自行创建和控制的用户态‘线程’,比线程更轻量级。
- 在一个Go程序中同时创建成百上千个goroutine是非常普遍的,一个goroutine会以一个很小的栈开始其生命周期,一般只需要2KB
线程:
- 由操作系统管理,创建和切换开销较大,适用于需要高性能和复杂调度的场景。
问题:
通常主协程运行的速度大于创建的分协程,导致程序运行完了,分协程还没运行就结束了
解决方法:
1.通过time包中sleep函数让主协程睡眠一段时间,但是睡眠时间是固定的从而分协程已经运行完但是主协程还在睡眠。
2.通常在main goroutine 中使用sync.WaitGroup来等待 其他goroutine 完成后再退出。
package mainimport ("fmt""sync"
)// 声明全局等待组变量
var wg sync.WaitGroupfunc hello() {fmt.Println("hello")wg.Done() // 告知当前goroutine完成
}func main() {wg.Add(1) // 登记1个goroutinego hello()fmt.Println("你好")wg.Wait() // 阻塞等待登记的goroutine完成
}协程的调度(GMP):
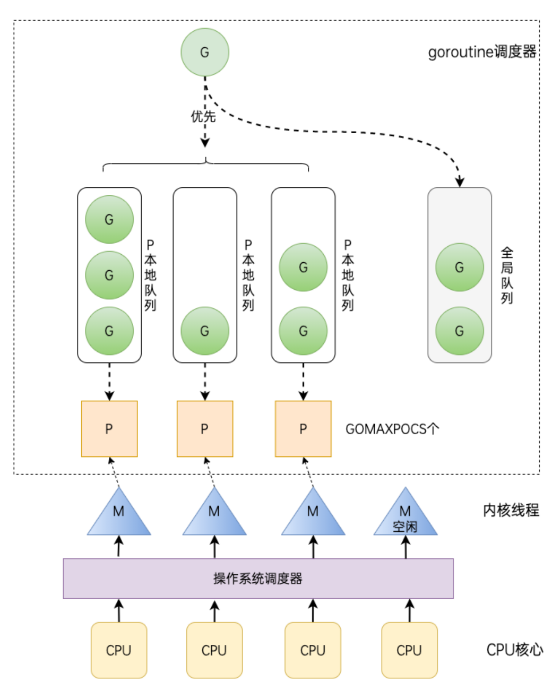
G:表示 goroutine,每执行一次
go f()就创建一个 G,包含要执行的函数和上下文信息。全局队列(Global Queue):存放等待运行的 G。
P:表示 goroutine 执行所需的资源,最多有 GOMAXPROCS 个。
P 的本地队列:同全局队列类似,存放的也是等待运行的G,存的数量有限,不超过256个。新建 G 时,G 优先加入到 P 的本地队列,如果本地队列满了会批量移动部分 G 到全局队列。
M:线程想运行任务就得获取 P,从 P 的本地队列获取 G,当 P 的本地队列为空时,M 也会尝试从全局队列或其他 P 的本地队列获取 G。M 运行 G,G 执行之后,M 会从 P 获取下一个 G,不断重复下去。
Goroutine 调度器和操作系统调度器是通过 M 结合起来的,每个 M 都代表了1个内核线程,操作系统调度器负责把内核线程分配到 CPU 的核上执行。
GOMAXPROCS :Go运行时的调度器使用GOMAXPROCS参数来确定需要使用多少个 OS 线程来同时执行 Go 代码。默认值是机器上的 CPU 核心数。例如在一个 8 核心的机器上,GOMAXPROCS 默认为 8。Go语言中可以通过runtime.GOMAXPROCS函数设置当前程序并发时占用的 CPU逻辑核心数。(Go1.5版本之前,默认使用的是单核心执行。Go1.5 版本之后,默认使用全部的CPU 逻辑核心数。)
调度器步骤
- 创建与入队:G(协程)创建后,优先入 P 本地队列,若本地队列满,会放到全局队列。
- 调度准备:P 绑定 M(内核线程映射),M 从 P 本地队列取 G 执行;本地队列空时,会从全局队列或其他 P 偷取 G 补充。
- 执行与切换:M 执行 G,若 G 阻塞(如 I/O 操作),P 会解绑当前 M、关联新 M 继续调度其他 G;G 恢复后重新入队等待执行 。
- 资源协调:GOMAXPROCS 控制 P 数量,协调 CPU 核心(通过操作系统调度器)与 M 映射,让 G 高效利用计算资源,实现并发调度 。
二.通道(channel)
问题:
单纯地将函数并发执行是没有意义的。函数与函数间需要交换数据才能体现并发执行函数的意义。虽然可以使用共享内存(通过调用函数)进行数据交换,但是共享内存在不同的 goroutine 中容易发生竞态问题。为了保证数据交换的正确性,很多并发模型中必须使用互斥量对内存进行加锁,这种做法势必造成性能问题。
channel:
单纯地将函数并发执行是没有意义的。函数与函数间需要交换数据才能体现并发执行函数的意义。从而引出通道实现协程之前的数据传输与共享
channel特点:
- Go 语言中的通道(channel)是一种特殊的类型。通道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序
- 每一个通道都是一个具体类型的导管,也就是声明channel的时候需要为其指定元素类型。
- 支持同步和数据共享,避免了显式的锁机制。
- 使用
chan关键字创建,通过<-操作符发送和接收数据。 - 声明的通道类型变量需要使用内置的make函数初始化之后才能使用
make(chan 元素类型, [缓冲大小])//默认值为nil
var ch chan int
fmt.Println(ch) // <nil>ch4 := make(chan int)
ch5 := make(chan bool, 1) // 声明一个缓冲区大小为1的通道x := <- ch // 从ch中接收值并赋值给变量x
<-ch // 从ch中接收值,忽略结果<- chan int // 只接收通道,只能接收不能发送
chan <- int // 只发送通道,只能发送不能接收缓存通道和无缓存通道的区别:
缓存通道:无缓冲的通道只有在有接收方能够接收值的时候才能发送成功,否则会一直处于等待发送的阶段。同理,如果对一个无缓冲通道执行接收操作时,没有任何向通道中发送值的操作那么也会导致接收操作阻塞
无缓存通道:只要通道的容量大于零,那么该通道就属于有缓冲的通道,通道的容量表示通道中最大能存放的元素数量。当通道内已有元素数达到最大容量后,再向通道执行发送操作就会阻塞,除非有从通道执行接收操作。
注意事项:
- 对一个关闭的通道再发送值就会导致 panic。
- 对一个关闭的通道进行接收会一直获取值直到通道为空。
- 对一个关闭的并且没有值的通道执行接收操作会得到对应类型的零值。
- 关闭一个已经关闭的通道会导致 panic。
三.锁
当多个 goroutine 同时操作一个资源(临界区)或者一个全局变量资源时的情况,这种情况下就会发生竞态问题(数据竞态)如多个协程同时对map进行存和删除
互斥锁:
互斥锁是一种常用的控制共享资源访问的方法,它能够保证同一时间只有一个 goroutine 可以访问共享资源。Go 语言中使用sync包中提供的Mutex类型来实现互斥锁。
sync.Mutex提供了两个方法供我们使用。
func (m *Mutex) Lock() 获取互斥锁
func (m *Mutex) Unlock() 释放互斥锁
读写互斥锁
互斥锁是完全互斥的,但是实际上有很多场景是读多写少的,当我们并发的去读取一个资源而不涉及资源修改的时候是没有必要加互斥锁的,这种场景下使用读写锁是更好的一种选择。读写锁在 Go 语言中使用sync包中的RWMutex类型。
func (rw *RWMutex) Lock() 获取写锁
func (rw *RWMutex) Unlock() 释放写锁
func (rw *RWMutex) RLock() 获取读锁
func (rw *RWMutex) RUnlock() 释放读锁
func (rw *RWMutex) RLocker() Locker 返回一个实现Locker接口的读写锁
读写锁分为两种:读锁和写锁。当一个 goroutine 获取到读锁之后,其他的 goroutine 如果是获取读锁会继续获得锁,如果是获取写锁就会等待;而当一个 goroutine 获取写锁之后,其他的 goroutine 无论是获取读锁还是写锁都会等待。
四.协程控制
1.通过多返回值,判断通道是否已经关闭
value, ok := <- ch
value:从通道中取出的值,如果通道被关闭则返回对应类型的零值。
ok:通道ch关闭时返回 false,否则返回 true。
2.for-range来循环遍历接收通道的值,当通道的值为空时,结束循环
func f3(ch chan int) {
for v := range ch {
fmt.Println(v)
}
}
通常我们会选择使用for range循环从通道中接收值,当通道被关闭后,会在通道内的所有值被接收完毕后会自动退出循环。
3.select多路复用
在某些场景下我们可能需要同时从多个通道接收数据。通道在接收数据时,如果没有数据可以被接收那么当前 goroutine 将会发生阻塞。你也许会写出如下代码尝试使用遍历的方式来实现从多个通道中接收值。
for{
// 尝试从ch1接收值
data, ok := <-ch1
// 尝试从ch2接收值
data, ok := <-ch2
…
}
这种方式虽然可以实现从多个通道接收值的需求,但是程序的运行性能会差很多。Go 语言内置了select关键字,使用它可以同时响应多个通道的操作。
Select 的使用方式类似于之前学到的 switch 语句,它也有一系列 case 分支和一个默认的分支。每个 case 分支会对应一个通道的通信(接收或发送)过程。select 会一直等待,直到其中的某个 case 的通信操作完成时,就会执行该 case 分支对应的语句。具体格式如下:
select {
case <-ch1:
//...
case data := <-ch2:
//...
case ch3 <- 10:
//...
default:
//默认操作
}
Select 语句具有以下特点:
- 可处理一个或多个 channel 的发送/接收操作。
- 如果多个 case 同时满足,select 会随机选择一个执行。
- 对于没有 case 的 select 会一直阻塞,可用于阻塞 main 函数,防止退出。
- 如果一个case中有多个通道发送数据,则接收时会串行排列等待被接受