AI AgentLLM架构演进的大逻辑和小脉络
这篇文章,我想从AI架构演进的大逻辑和小脉络上,梳理和总结下AI Agent&LLM架构演进逻辑的脉络。
首先如果从大面来看,AI架构的演进主要是两个大的阶段,一个是Agent自主编排,一个是LLM自主编排。
而从小脉络来看,这个演进过程则更为具体和细化。我们可以将它梳理为一条从简单到复杂、从可控到智能的技术迭代路径。
大逻辑:AI架构演进的两个大的阶段
当前阶段:Agent自主编排
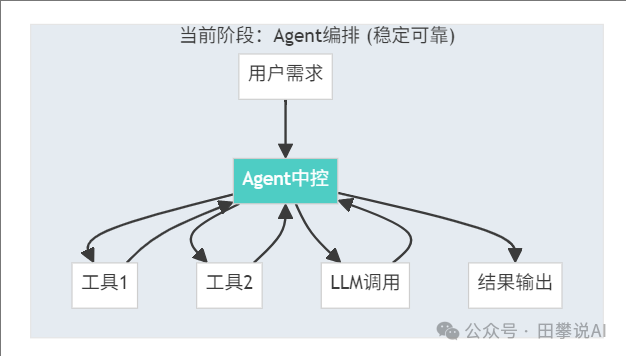
- 核心:Agent作为中控,调用各种工具和模型
- 特点:稳定、可控、可预测
- 现状:这是目前最成熟、最可靠的方案
技术层面: 固定的代码逻辑/Workflow + 工具集(LLM、API等)
简单来说,Agent自主编排就是给AI系统设置一个“项目经理”(即Agent)。 这个Agent负责接收任务,并调用其“专家团队”(如LLM、搜索引擎、计算器等工具)来协同完成。
在此模式下,Agent是遵循固定代码逻辑或Workflow的总控。LLM只是一个被调用的强大“函数”,负责内容处理,但不决定整体流程。这确保了系统的稳定与可控,因为决策逻辑掌握在开发者手中,而非LLM的“黑箱”。

未来阶段:LLM自主编排
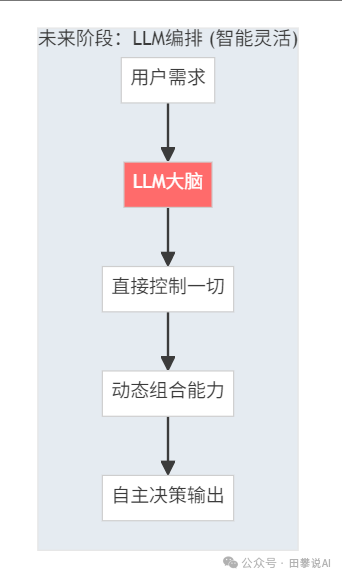
- 核心:LLM直接控制整个系统,自主决定调用什么、怎么调用
- 特点:更智能、更灵活,但也更不可控
- 挑战:可靠性、成本、可解释性
技术层面:(清晰的)Context + (足够完善的)MCP体系
在这种模式下,LLM从一个被调用的“工具人”升级为系统的“大脑”或“总指挥”。它直接接收高级任务,然后自主进行任务分解、规划,并决定调用哪些工具(如API、代码解释器)来执行。
整个工作流是动态生成和调整的,而非预先设定。这赋予了系统前所未有的灵活性和智能,能够处理更复杂、更开放的任务。然而,这也意味着我们将系统的控制权交给了LLM的“黑箱”,其行为可能难以预测和调试,且每次决策都需要调用大模型,成本高昂。
为什么当前停留在Agent编排?
最大的原因,是LLM的可靠性、成本和可解释性问题。
稳定性考虑:
- Agent有明确的决策边界
- 出错时容易定位和修复
- 成本和延迟可控
LLM编排的挑战:
- LLM的"创造性"可能导致不可预测的行为
- 成本高(每次决策都要调用LLM)
- 调试困难
转折点会在哪里?
当LLM的可靠性和成本效率达到临界点时,就会从Agent编排转向LLM编排。
启示:未来会是LLM自主编排,但当下仍然是Agent自主编排
对于企业而言,这意味着一个清晰的路线图。当下,核心任务是构建和完善基于Agent的自主编排系统。这套系统以稳定、可控为首要目标,通过强大的工具集和固定的工作流来解决明确的业务问题,实现AI的可靠落地。未来,随着LLM在可靠性和成本上的突破,这些基于Agent构建的工具和服务,将能够被更智能的LLM大脑无缝接管和编排。因此,现在的投入不仅是解决眼前问题,也是在为未来的LLM自主编排时代构建坚实的基础设施。
小脉络:AI Agent&LLM架构演进详细脉络梳理
和汽车自动驾驶的演进逻辑类似,AI大模型和AI智能体的发展,也是一步步演进的,一步步解决问题的。
第一步:基于LLM的简单问答与内容生成
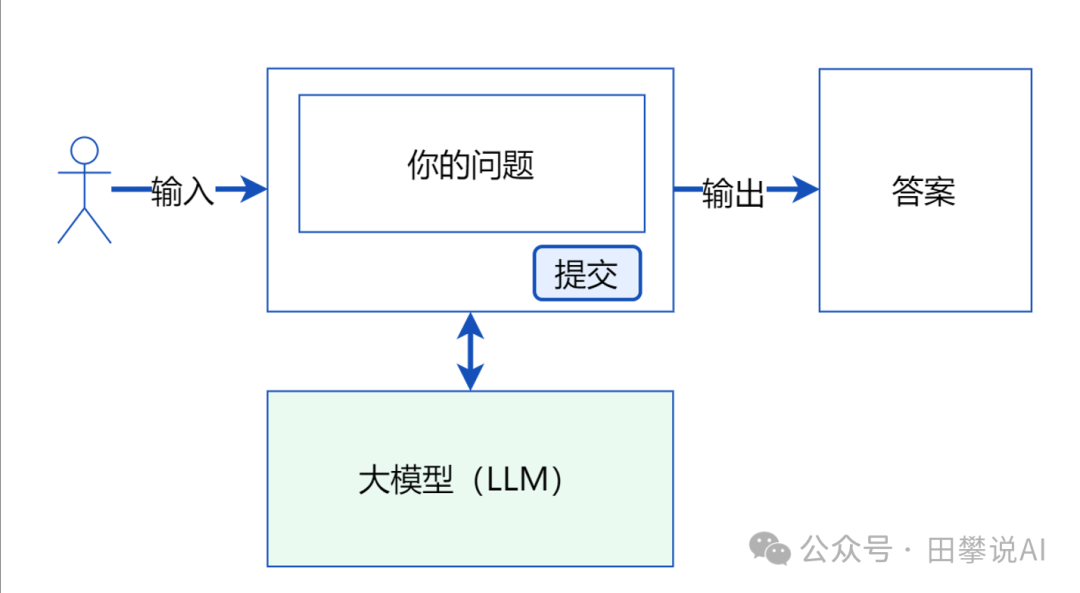
- 核心能力: 概率预测与模式学习
- 解决问题: 基础信息获取、文本创作、简单指令执行。
演进逻辑: 大型语言模型(如GPT、Claude等)通过在海量文本数据上进行训练,学习了语言的统计规律。其本质是一个强大的概率引擎,擅长根据输入的上文(Prompt)预测下一个最可能出现的词元(Token)。这使得它们能够生成连贯、相关甚至富有创造性的文本,回答事实性问题(基于训练数据),进行翻译、摘要等。
如何解决: 用户通过自然语言提示(Prompt)与LLM交互,LLM直接基于其内部知识库(训练数据)生成响应。
局限性:
- 知识滞后: 知识停留在训练数据截止日期。
- 事实幻觉: 可能“一本正经地胡说八道”,编造不实信息。
- 缺乏私有知识: 无法访问用户或企业的特定内部数据。
- 复杂任务无力: 难以执行需要多步骤规划、实时信息或外部工具的任务。
第二步:应对初步复杂性 - 联网、RAG与Agent概念
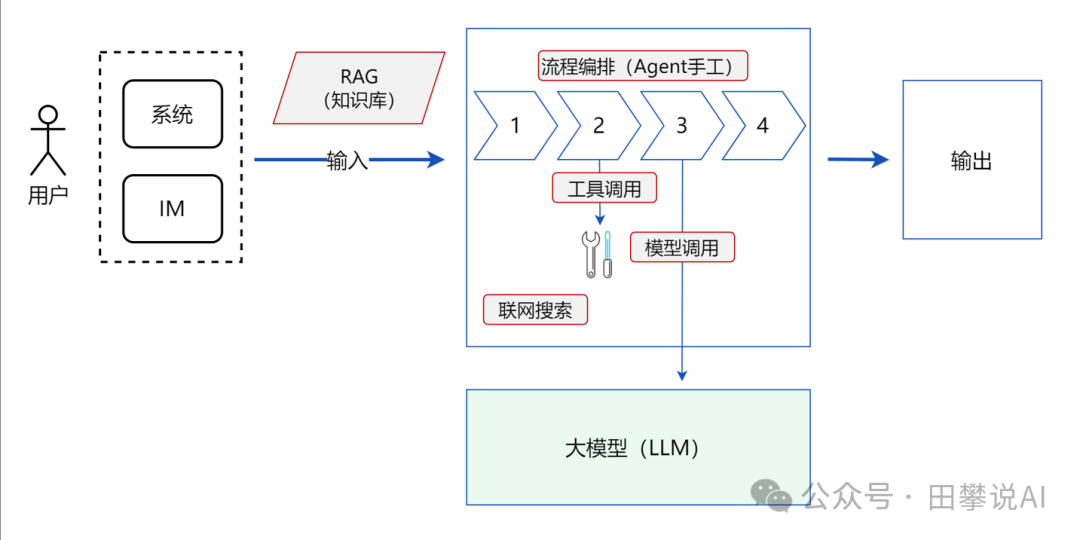
- 核心能力: 信息获取扩展、知识增强
- 解决问题: 知识实时性不足、缺乏私有领域知识。
演进逻辑: 为了克服LLM的局限性,业界发展出两种主要增强手段:
- 联网搜索 (Web Search): 赋予LLM访问互联网、获取最新信息的能力。
- 检索增强生成 (RAG, Retrieval-Augmented Generation): 通过外部知识库(如企业文档、数据库)检索相关信息,将其作为上下文注入LLM的提示词中,让LLM能基于特定、私有的知识进行回答。
同时,为了管理这些外部调用和更复杂的交互逻辑,**Agent(智能体)**的开始出现,作为协调者。
如何解决:
- 联网: LLM在接收到需要实时信息的请求时,触发一个外部搜索工具,将搜索结果整合进回答。
- RAG: 用户问题首先经过一个检索器(Retriever),在向量数据库或知识库中查找相关文档片段,然后将这些片段与原始问题一起提交给LLM。
第三步:显式AI Agent - 应对复杂任务的规划与执行
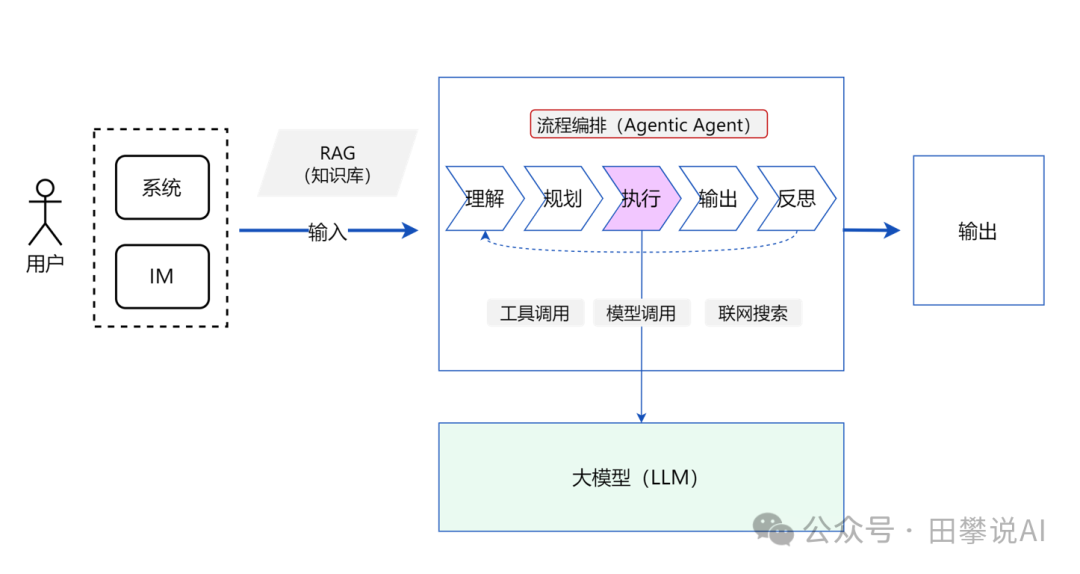
- 核心能力: 任务分解、工具调用、状态管理、自主循环
- 解决问题: 执行需要多步骤、跨工具协作的复杂任务。
演进逻辑: 对于需要“复杂到复杂”处理的任务(如“帮我规划一次旅行并预订机票酒店”、“分析这份财报并生成摘要图表”),仅仅依靠LLM的语言能力和简单的外部调用是不够的。需要一个更高级的控制层——AI Agent。这个Agent以LLM为核心“大脑”,但增加了感知、规划、行动、观察、反思的循环能力。
如何解决: Agent接收复杂目标后:
- 理解/规划: 使用LLM将目标分解为一系列可执行步骤。
- 行动: 选择并调用合适的工具(联网搜索、RAG、代码执行器、API调用等)来执行每个步骤。
- 观察: 获取工具执行的结果。
- 反思/汇总: 评估当前状态是否满足目标,是否需要调整计划或继续执行,最终汇总结果。 这通常需要Agent维护一个内部状态或记忆。
第四步:深度思考模型 + MCP - LLM内化Agent能力
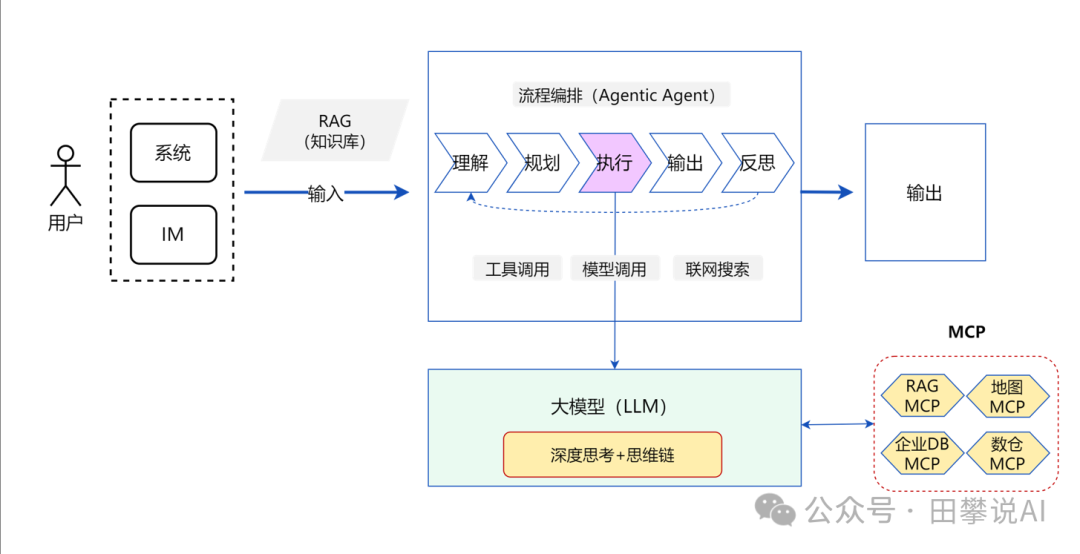
- 核心能力: 内在规划与推理、标准化工具接入
- 解决问题: 简化Agent架构、提升LLM主动性、标准化外部能力访问。
演进逻辑: 开发和维护上层Agent逻辑本身也变得复杂。另一个演进方向是增强LLM自身的能力,使其具备更强的“深度思考”、推理和规划能力(如Google的Gemini 1.5 Pro, DeepSeek V2的MoE模型等)。同时,为了让LLM能更方便、更主动地调用外部工具,标准化的工具调用协议(如Function Calling, Google的MCP - Model Connect Protocol)应运而生。
如何解决: “聪明的”LLM接收到复杂任务后,可以直接在其内部进行更高质量的规划,并根据MCP等协议规范地识别、选择和调用所需的外部工具/API/数据库资源,而不需要一个非常重的外部Agent层来协调。LLM从被动等待Agent调用,变得可以“主动出击”访问所需资源。
第五步:Agent互联互通 (A2A) - 打破信息孤岛
- 核心能力: Agent间协作、能力组合
- 解决问题: 避免大量孤立Agent应用、实现更复杂能力的涌现。
演进逻辑: 无论是显式的特定任务Agent(第三步),还是内化了Agent能力的通用模型(第四步),如果大量开发,每个都可能成为一个“能力孤岛”。例如,一个擅长旅行规划的Agent可能需要调用另一个擅长天气查询的Agent。为了实现更高级的协作和能力组合,需要让Agent之间能够互相发现、通信和协作。这就是**Agent-to-Agent (A2A)**协议或类似机制出现的背景。
如何解决: 通过定义标准的通信协议和发现机制,不同的Agent(或具备Agent能力的LLM)可以像微服务一样互相调用,共享信息、委托任务,共同完成单个Agent无法完成的、更大规模或跨领域的复杂任务。这可能需要一个更高层次的编排器或“元Agent”。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,人才需求急为紧迫!
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
包括:AI大模型学习路线、LLM面试宝典、0基础教学视频、大模型PDF书籍/笔记、大模型实战案例合集、AI产品经理合集等等
大模型学习之路,道阻且长,但只要你坚持下去,一定会有收获。本学习路线图为你提供了学习大模型的全面指南,从入门到进阶,涵盖理论到应用。
L1阶段:启航篇|大语言模型的基础认知与核心原理
L2阶段:攻坚篇|高频场景:RAG认知与项目实践
L3阶段:跃迀篇|Agent智能体架构设计
L4阶段:精进篇|模型微调与私有化部署
L5阶段:专题篇|特训集:A2A与MCP综合应用 追踪行业热点(全新升级板块)





AI大模型全套学习资料【获取方式】