自然语言推理技术全景图:从基准数据集到BERT革命
深入解析NLP领域如何让机器像人类一样“读懂言外之意”
引言:为什么NLI是AI皇冠上的明珠?
想象这样一个场景:
"Jack急需用钱,于是摇了摇他的存钱罐。当听不到任何声响时,他感到失望。"
人类能瞬间理解:Jack没找到钱(未明确陈述)且情绪消极。这种能力源于常识推理:
-
存钱罐装硬币(非猪)
-
硬币是金属制品
-
金属摇动会发声 → 无声意味无硬币
这种超越字面含义的自然语言推理(NLI)能力,正是当前NLP研究的核心挑战。本文将带您纵览NLI领域三大支柱:评测基准、知识资源和推理技术的最新进展。
一、NLI评测基准演进史
1.1 基准分类与代表数据集
| 任务类型 | 代表数据集 | 样本量 | 特点 | 示例问题(答案加粗) |
|---|---|---|---|---|
| 指代消解 | Winograd Schema | 60 | 依赖物理/心理常识 | "奖杯放不进棕色行李箱,因为它太大" → 奖杯 |
| WinoGrande | 44,000 | 对抗性生成的大规模数据集 | ||
| 问答推理 | SQuAD 2.0 | 150,000 | 引入不可回答问题 | 根据文章判断问题是否有解 |
| CommonsenseQA | 9,500 | 直接测试ConceptNet常识关系 | ||
| 文本蕴含 | SNLI | 570,000 | 首个人工标注大规模蕴含数据集 | "黑衣人在人群中驾车" vs "男子在孤独路上驾驶" → 矛盾 |
| MultiNLI | 433,000 | 多领域文本蕴含 | ||
| 心理推理 | SocialIQA | 45,000 | 社交情境中的意图理解 | "Tracy在电梯里不小心压到Austin" → 原因?电梯拥挤 |
1.2 基准构建的黄金法则
-
对抗过滤(Adversarial Filtering)
-
方法:用当前最强模型筛选模型无法正确回答的样本
-
案例:SWAG → HellaSWAG的演进使SOTA模型准确率从86.3%降至47.3%
-
-
偏差防御策略
-
语法偏差:在Winogender中发现性别关联(如"护士她")
-
统计偏差:SNLI中"nobody"高频指向矛盾标签
-
解决方案:
-
# 伪代码:对抗过滤实现
while baseline_accuracy > threshold:generate_candidate_samples()current_model.predict(candidates)retain_hard_samples()retrain_model_on_new_set()二、知识资源:机器的“常识库”
2.1 知识图谱三巨头对比
| 资源名称 | 知识类型 | 规模 | 独特价值 |
|---|---|---|---|
| WordNet | 语言知识 | 117,000概念 | 词义关系网络(同义/反义等) |
| ConceptNet | 常识知识 | 2100万关系边 | 多语言常识("冰-寒冷") |
| ATOMIC | 事件推理 | 87万if-then规则 | 心理推理("X道歉→Y感到欣慰") |
2.2 知识获取技术突破
-
文本挖掘:从Web自动构建(WebChild提取78000个名词-形容词常识关系)
-
众包游戏化:Open Mind Common Sense通过游戏收集50万条常识
-
神经网络补全:
# ConceptNet关系补全模型
model = TransE(knowledge_graph)
for (head, relation) in query:tail = model.predict(head, relation) # 预测缺失实体在Event2Mind任务中补全准确率达92.1%
三、神经推理模型:从LSTM到Transformer
3.1 模型进化关键节点
-
注意力机制(2015):
-
ESIM模型在SNLI达到88.0%,通过句对交叉注意力实现
-
-
Transformer革命(2017):
-
自注意力公式:
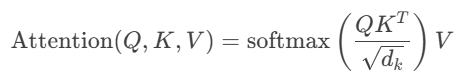
-
并行计算效率比RNN提升8倍
-
-
预训练范式(2018-2019):
模型 预训练任务 GLUE得分 突破点 ELMo 双向语言模型 70.0 首款上下文相关嵌入 BERT Masked LM + 下一句预测 80.5 双向Transformer编码器 XLNet 排列语言模型 88.4 解决BERT的[MASK]偏差 RoBERTa 动态掩码 + 更大数据 88.5 取消NSP任务
3.2 知识融合前沿方案
-
ERNIE(清华):
-
将Wikidata实体链接注入Transformer
-
在关系抽取任务F1提升4.7%
-
-
K-BERT(北大):
# 知识注入伪代码
sentence = "巴黎是法国首都"
kg_triples = [("巴黎", "位于", "法国")]
model = InjectKG(sentence, kg_triples) # 构建知识增强树四、挑战与未来方向
4.1 现存核心问题
-
虚假关联:BERT在ARCT基准中通过词频模式作弊(Niven & Kao 2019)
-
知识割裂:当前SOTA模型极少使用外部知识库
-
解释缺失:99%准确率的模型无法解释推理过程
4.2 突破性方向
-
具身推理(Embodied Reasoning)
-
案例:ALFRED指令数据集(在虚拟环境中执行"把微波炉里的苹果放到碗柜")
-
-
可解释结构
-
神经符号系统:如IBM的Neuro-Symbolic Concept Learner
-
推理路径可视化:
text
输入: "疫苗为什么需要冷藏?" 路径: 疫苗→含蛋白质→蛋白质高温变性→失效
-
-
统一评估框架
-
提议:SuperGLUE 2.0引入:
-
反事实样本测试("如果存钱罐是塑料的...")
-
推理链标注(要求模型输出推理步骤)
-
-
五、实战资源包
-
数据集:
-
GLUE基准
-
CommonsenseQA
-
-
预训练模型:
python
# HuggingFace调用RoBERTa from transformers import RobertaTokenizer, RobertaModel tokenizer = RobertaTokenizer.from_pretrained('roberta-large') model = RobertaModel.from_pretrained('roberta-large') -
可视化工具:
-
BERTviz:注意力头可视化
-
最新动态:Google在2023年推出PaLM-E模型,首次实现视觉-语言-行动的联合推理,在"把桌上的可乐递给穿蓝色衬衫的人"等复杂指令中展现人类级理解能力。这预示着NLI正在向多模态具身推理的新纪元迈进。