十六、全方位监控:Prometheus
十六、全方位监控:Prometheus
文章目录
- 十六、全方位监控:Prometheus
- 1、Prometheus 初识
- 1.1 什么是TSDB?
- 1.2 Prometheus概念
- 1.3 Prometheus核心特性
- 1.4 Prometheus核心组件及架构
- 1.5 Prometheus常见的自定义资源
- 1.6 Relabeling配置详解
- 1.7 Prometheus资源分类总结
- 2、Prometheus 安装
- 2.1 下载安装prometheus
- 2.2 访问 Grafana
- 2.3 配置动态存储
- 3、云原生和非云原生应用监控
- 3.1 使用 ServiceMonitor 监控服务
- 3.1.1 Etcd Service 创建
- 3.1.2 创建 Etcd 证书的 Secret(证书路径根据实际环境进行更改):
- 3.1.3 Etcd ServiceMonitor 创建
- 3.1.4 Grafana 配置
- 3.2 使用 Exporter 监控服务
- 3.2.1 部署测试用例
- 3.2.2 ServiceMonitor 配置
- 3.2.3 Grafana 配置
- 3.3 使用 ScrapeConfig 监控服务
- 3.3.1 部署测试用例
- 3.3.2 ScrapeConfig 配置
- 3.3.3 Grafana 配置
- 3.4 使用 Probe 监控服务
- 3.4.1 Probe 配置
- 3.4.2 Grafana 配置
- 3.5 使用 PodMonitor 监控服务
- 3.5.1 部署测试用例
- 3.5.2 创建 PodMonitor
- 4、K8s 核心组件监控
- 5、Prometheus 监控 Windows/Linux 主机
- 6、Prometheus 语法 PromQL 入门
- 6.1 PromQL 语法初体验
- 6.2 PromQL 操作符
- 6.3 PromQL 常用函数
- 7、Prometheus 告警实战
- 7.1 PrometheusRule
- 7.2 告警实战:域名访问延迟及故障告警
- 7.3 告警实战:应用服务活性探测告警
- 7.4 告警实战:基于 Grafana 图标告警
- 8、Alertmanager 告警入门
- 8.1 Alertmanager 外部网络访问配置
- 8.2 Alertmanager 配置文件解析
- 8.3 Alertmanager 路由规则
- 8.4 Alertmanager 邮件通知配置
- 8.4.1 邮箱配置
- 8.4.2 AlertmanagerConfig 实现邮件告警
- 8.5 Alertmanager 钉钉告警配置
- 8.5.1 钉钉机器人配置
- 8.5.2 钉钉 Webhook 服务部署
- 8.5.3 Alertmanager 实现钉钉告警通知
- 8.6 屏蔽告警
1、Prometheus 初识
1.1 什么是TSDB?
时序数据库(Time-Series Database,简称TSDB)是一种专门用于存储和查询
时间序列数据的数据库。主要用于记录随时间变化而不断产生的数据,例如物联网设备传感器数据、服务器性能指标、金融交易记录、天气数据等。相比于传统的关系型数据库或键值存储数据库,TSDB在处理大规模时间序列数据时,具有更高的效率和更好的性能。
1.2 Prometheus概念
Prometheus是一个开源的系统监控和报警框架,其本身也是一个时序列数据库(TSDB),它的设计灵感来源于Google的Borgmon,就像K8s是基于Borg系统开源的。
Prometheus被设计用来监控服务和应用的健康情况,并且提供强大的查询语言PromQL来进行数据查询和可视化。
1.3 Prometheus核心特性
- 多维数据模型:Prometheus的数据采用时间序列数据进行存储,可以通过指标名称和标签进行检索、分组、过滤和聚合
- 灵活的查询语法:使用PromQL语法可以查询和聚合数据,可用于绘制图表或触发告警
- 存储简化:Prometheus本身就是一个时序数据库,可以提供本地存储和分布式存储,并且每个Prometheus都是自治和独立的
- 拉取模型:Prometheus通过基于HTTP的Pull的模式,定期从配置的目标中拉取应用程序暴露Metrics数据,同时可以使用PushGateway进行Push数据
- 动态发现:Prometheus同时支持动态服务发现和静态配置发现监控目标
- 告警通知:Prometheus支持告警规则的多级配置,并支持通知到多种媒介
- 完善仪表盘:Prometheus具备多种图形和仪表盘支持,同时可以使用Grafana等工具创建丰富等可视化界面
1.4 Prometheus核心组件及架构
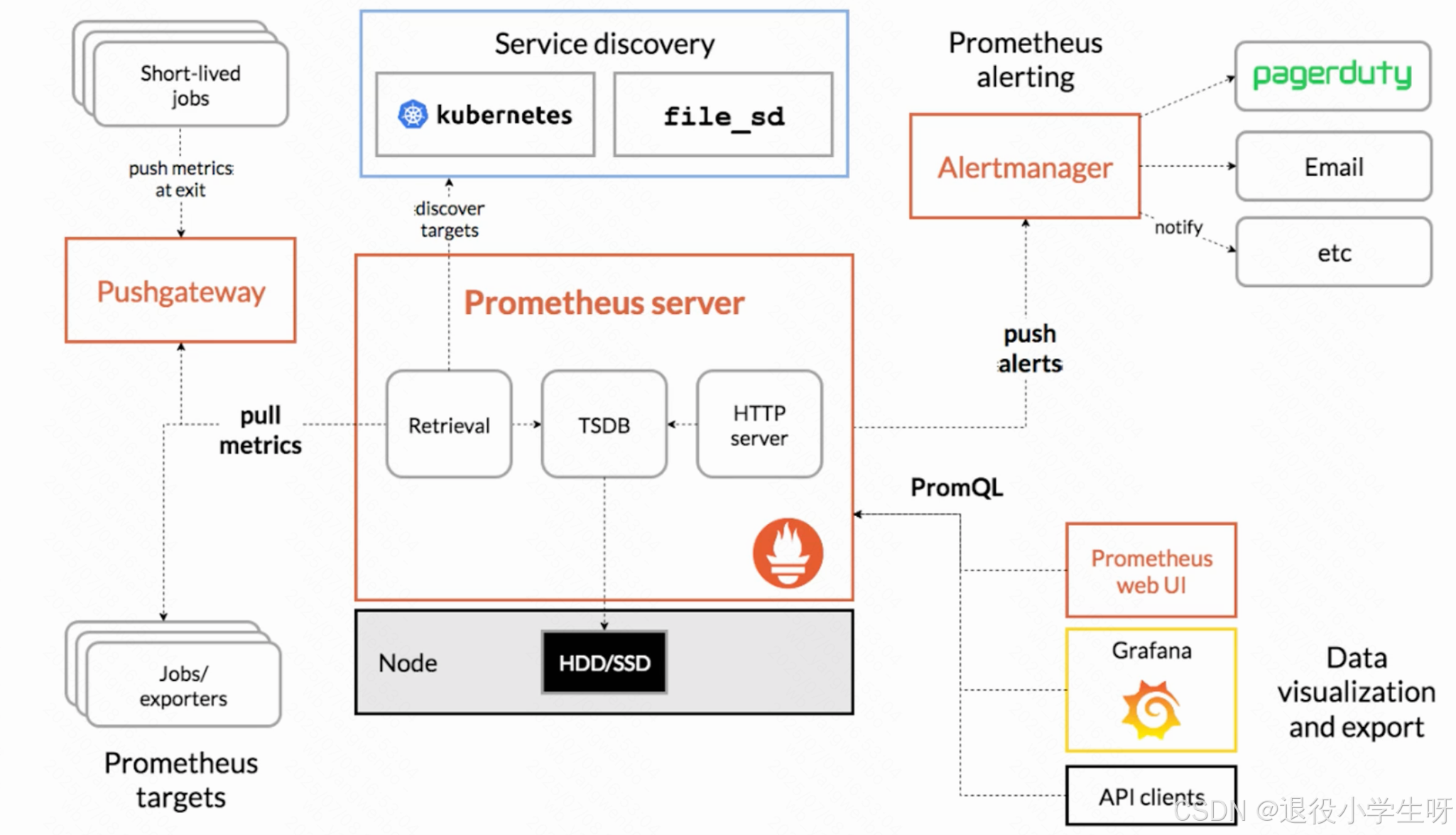
1.5 Prometheus常见的自定义资源
- Prometheus:用于定义 Prometheus Server 实例
- Alertmanager:用于定义 Alertmanager 实例
- ServiceMonitor:用于定义获取监控数据的目标,Operator 根据 ServiceMonitor 自动生成 Prometheus 配置
- PodMonitor:用于监控一组动态的Pod,PodMonitor对象负责发现一些符合规范的Pod,并生成 Prometheus 配置来进行监控
- Probe:用于定义静态目标,通常和 BlackBox Exporter 配合使用
- ScrapeConfig:用于自定义监控目标,通常用于抓取K8s集群外部的目标数据
- AlertmanagerConfig:用于定义 Alertmanager 实例
- PrometheusRule:用于定义告警规则
1.6 Relabeling配置详解
Prometheus的Relabeling功能主要用于对监控目标标签对重写,比如对监控目标进行多重标记、过滤、分类等。
常用Relabeling配置
- source_labels:源标签
- target_label:relabel处理后的标签
- separator:合并多个源标签值的分隔符,默认为“;”
- regex:匹配源标签的值,默认为(.*)
- replacement:指定在进行标签重写时使用的替换值,默认值为$1
- action:正则表达式匹配时执行的动作,默认为replace
- replace:替换标签值
- keep:保留匹配的目标,不匹配的丢弃
- drop:丢弃匹配的目标,保留未匹配的
- labelmap:对于匹配后的标签映射到新的标签中
- labeldrop:删除某个标签
- labelkeep:只保留某个标签
1.7 Prometheus资源分类总结
- 安装
- Operator
- Prometheus
- Alertmanager
- Grafana
- 监控
- ServiceMonitor
- Probe
- PodMonitor
- ScrapeConfig
- 告警
- PrometheusRule
- 通知
- AlertmanagerConfig
2、Prometheus 安装
Kube-Prometheus 项目地址:https://github.com/prometheus-operator/kube-prometheus/
首先需要通过该项目地址,找到和自己 Kubernetes 版本对应的 Kube Prometheus Stack 的版本:
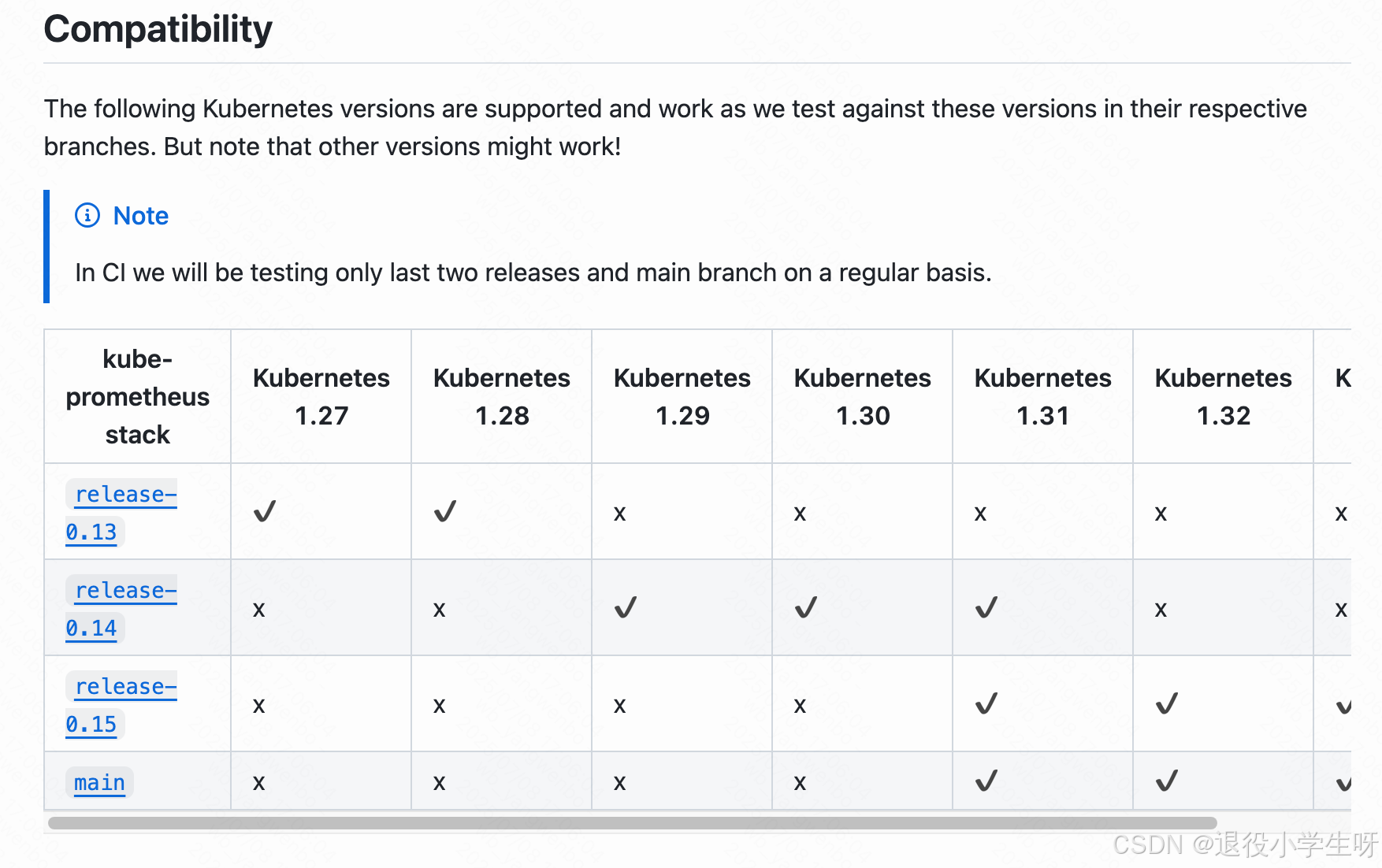
2.1 下载安装prometheus
# 下载包
[root@k8s-master01 ~]# git clone -b release-0.15 https://github.com/prometheus-operator/kube-prometheus.git# 有些是国外地址的镜像,我们需要把他们替换成国内的镜像地址
[root@k8s-master01 ~]# cd kube-prometheus/manifests/
[root@k8s-master01 manifests]# egrep -rn "image: registry.k8s.io|image: grafana" *.yaml
grafana-deployment.yaml:33: image: grafana/grafana:12.0.1
kubeStateMetrics-deployment.yaml:35: image: registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.15.0
prometheusAdapter-deployment.yaml:41: image: registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.12.0# 更改后的
[root@k8s-master01 manifests]# grep -rn "aliyuncs" grafana-deployment.yaml kubeStateMetrics-deployment.yaml prometheusAdapter-deployment.yaml
grafana-deployment.yaml:33: image: crpi-q1nb2n896zwtcdts.cn-beijing.personal.cr.aliyuncs.com/ywb01/grafana:12.0.1
kubeStateMetrics-deployment.yaml:35: image: crpi-q1nb2n896zwtcdts.cn-beijing.personal.cr.aliyuncs.com/ywb01/kube-state-metrics:v2.15.0
prometheusAdapter-deployment.yaml:41: image: crpi-q1nb2n896zwtcdts.cn-beijing.personal.cr.aliyuncs.com/ywb01/prometheus-adapter:v0.12.0# 修改grafana Service网络模式
[root@k8s-master01 manifests]# vim grafana-service.yaml
[root@k8s-master01 manifests]# cat grafana-service.yaml
....selector:app.kubernetes.io/component: grafanaapp.kubernetes.io/name: grafanaapp.kubernetes.io/part-of: kube-prometheustype: NodePort # 修改成NodePort模式# 修改默认时区
[root@k8s-master01 manifests]# sed -i 's/default_timezone = UTC/default_timezone = Asia\/Shanghai/g' grafana-config.yaml
[root@k8s-master01 manifests]# sed -i 's/"timezone": "UTC"/"timezone": "Asia\/Shanghai"/g' grafana-dashboardDefinitions.yaml
[root@k8s-master01 manifests]# sed -i 's/"timezone": "utc"/"timezone": "Asia\/Shanghai"/g' grafana-dashboardDefinitions.yaml
# 删除冲突资源
[root@k8s-master01 manifests]# kubectl delete apiservice v1beta1.metrics.k8s.io
[root@k8s-master01 manifests]# kubectl delete clusterrole system:aggregated-metrics-reader# 安装 Prometheus Operator CRD:
[root@k8s-master01 manifests]# kubectl create -f setup/# 安装 Prometheus Operator 及核心组件:
[root@k8s-master01 manifests]# kubectl create -f .# 查看 Prometheus 容器状态:
[root@k8s-master01 ~]# kubectl get po -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 12m
alertmanager-main-1 2/2 Running 0 12m
alertmanager-main-2 2/2 Running 0 12m
blackbox-exporter-d989f64d9-v5jwt 3/3 Running 0 12m
grafana-544c7b9f4c-b4kpn 1/1 Running 0 12m
kube-state-metrics-86d8d69f6f-kb2wh 3/3 Running 0 12m
node-exporter-8tvxt 2/2 Running 0 12m
node-exporter-bxz96 2/2 Running 0 12m
node-exporter-x7wt9 2/2 Running 0 12m
prometheus-adapter-74b6645f65-9hhkb 1/1 Running 0 12m
prometheus-adapter-74b6645f65-fwc68 1/1 Running 0 12m
prometheus-k8s-0 2/2 Running 0 12m
prometheus-k8s-1 2/2 Running 0 12m
prometheus-operator-6b64df5498-vlrc8 2/2 Running 0 12m
# 注意:新版添加了 NetworkPolicy,可能会导致 Grafana 等服务无法访问,执行一下操作即可:
[root@k8s-master01 ~]# kubectl delete networkpolicy --all -n monitoring
2.2 访问 Grafana
# 查看grafana Service
[root@k8s-master01 manifests]# kubectl get svc grafana -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana NodePort 10.106.79.50 <none> 3000:31024/TCP 92m
之后可以通过任意一个安装了 kube-proxy 服务的节点 IP+31024 端口即可访问到 Grafana(默认登录的账号密码为 admin/admin)
2.3 配置动态存储
# 之前安装的NFS CS
[root@k8s-master01 manifests]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
nfs-csi nfs.csi.k8s.io Delete Immediate false 24h# 创建一个持久化PVC
[root@k8s-master01 manifests]# vim grafana-pvc.yaml
[root@k8s-master01 manifests]# cat grafana-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: grafananamespace: monitoring
spec:accessModes:- ReadWriteManyresources:requests:storage: 5GistorageClassName: nfs-csi[root@k8s-master01 manifests]# kubectl create -f grafana-pvc.yaml [root@k8s-master01 manifests]# kubectl get pv -n monitoring
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
pvc-5152678e-2e93-4710-b383-276aba99f913 5Gi RWX Delete Bound monitoring/grafana nfs-csi <unset> 24s[root@k8s-master01 manifests]# kubectl get pvc -n monitoring
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
grafana Bound pvc-5152678e-2e93-4710-b383-276aba99f913 5Gi RWX nfs-csi <unset> 29s
# 修改grafana存储配置
[root@k8s-master01 manifests]# vim grafana-deployment.yaml
[root@k8s-master01 manifests]# cat grafana-deployment.yaml | grep volumes: -A4volumes:#- emptyDir: {}- name: grafana-storagepersistentVolumeClaim:claimName: grafana# 重新刷新配置
[root@k8s-master01 manifests]# kubectl replace -f grafana-deployment.yaml
3、云原生和非云原生应用监控
3.1 使用 ServiceMonitor 监控服务
Etcd 原生提供了 Metrics 接口,所以无需任何服务就可以直接监控 Etcd。但是访问 Etcd 的Metrics 接口需要使用证书
3.1.1 Etcd Service 创建
# 首先需要创建 Etcd 的 Service 和 Endpoint:
[root@k8s-master01 ~]# vim etcd-svc.yaml
[root@k8s-master01 ~]# cat etcd-svc.yaml
apiVersion: v1
kind: Endpoints
metadata:labels:app: etcd-promname: etcd-promnamespace: kube-system
subsets:
- addresses:- ip: 192.168.200.50 # 改成自己的 Etcd 主机 IPports:- name: https-metricsport: 2379protocol: TCP
---
apiVersion: v1
kind: Service
metadata:labels:app: etcd-promname: etcd-promnamespace: kube-system
spec:ports:- name: https-metricsport: 2379protocol: TCPtargetPort: 2379type: ClusterIP[root@k8s-master01 ~]# kubectl create -f etcd-svc.yaml
[root@k8s-master01 ~]# kubectl get svc etcd-prom -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
etcd-prom ClusterIP 10.96.88.43 <none> 2379/TCP 17s# 通过 ClusterIP 访问测试:
[root@k8s-master01 ~]# curl -s --cert /etc/kubernetes/pki/etcd/server.crt --key /etc/kubernetes/pki/etcd/server.key https://10.96.88.43:2379/metrics -k | tail -3
promhttp_metric_handler_requests_total{code="200"} 6
promhttp_metric_handler_requests_total{code="500"} 0
promhttp_metric_handler_requests_total{code="503"} 0
3.1.2 创建 Etcd 证书的 Secret(证书路径根据实际环境进行更改):
# 创建 Etcd 证书的 Secret
[root@k8s-master01 ~]# kubectl create secret generic etcd-ssl \
--from-file=/etc/kubernetes/pki/etcd/ca.crt \
--from-file=/etc/kubernetes/pki/etcd/server.key \
--from-file=/etc/kubernetes/pki/etcd/server.crt \
-n monitoring
# 接下来将证书挂载至 Prometheus 容器
# 由于 Prometheus 是 Operator 部署的,所以只需要修改 Prometheus 资源即可
[root@k8s-master01 ~]# vim kube-prometheus/manifests/prometheus-prometheus.yaml
[root@k8s-master01 ~]# grep -rn secrets kube-prometheus/manifests/prometheus-prometheus.yaml -C2
49- serviceMonitorSelector: {}
50- version: 3.4.0
51: secrets:
52- - etcd-ssl# 重启配置
[root@k8s-master01 ~]# kubectl replace -f kube-prometheus/manifests/prometheus-prometheus.yaml# 替换后,Prometheus 的 Pod 会自动重启,重启完成后,查看证书是否挂载(任意一个 Prometheus 的 Pod 均可):
[root@k8s-master01 ~]# kubectl get po -n monitoring | grep prometheus-k8s
prometheus-k8s-0 2/2 Running 0 36s
prometheus-k8s-1 2/2 Running 0 69s[root@k8s-master01 ~]# kubectl exec -n monitoring prometheus-k8s-0 -c prometheus -- ls /etc/prometheus/secrets/etcd-ssl/
ca.crt
server.crt
server.key
3.1.3 Etcd ServiceMonitor 创建
[root@k8s-master01 ~]# vim servicemonitor.yaml
[root@k8s-master01 ~]# cat servicemonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:name: etcdnamespace: monitoringlabels:app: etcd
spec:jobLabel: k8s-appendpoints:- interval: 30sport: https-metrics scheme: httpstlsConfig:caFile: /etc/prometheus/secrets/etcd-ssl/ca.crt #证书路径certFile: /etc/prometheus/secrets/etcd-ssl/server.crtkeyFile: /etc/prometheus/secrets/etcd-ssl/server.keyinsecureSkipVerify: true # 关闭证书校验selector:matchLabels:app: etcd-promnamespaceSelector:matchNames:- kube-system[root@k8s-master01 ~]# kubectl create -f servicemonitor.yaml
# 修改网络模式为NodePort
[root@k8s-master01 ~]# cat kube-prometheus/manifests/prometheus-service.yaml
....sessionAffinity: ClientIPtype: NodePort# 重新加载配置
[root@k8s-master01 ~]# kubectl replace -f kube-prometheus/manifests/prometheus-service.yaml[root@k8s-master01 ~]# kubectl get -f kube-prometheus/manifests/prometheus-service.yaml
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus-k8s NodePort 10.99.176.244 <none> 9090:31967/TCP,8080:30771/TCP 23h
任意IP+31967
创建完成后,在 Prometheus 的 Web UI 即可看到相关配置:
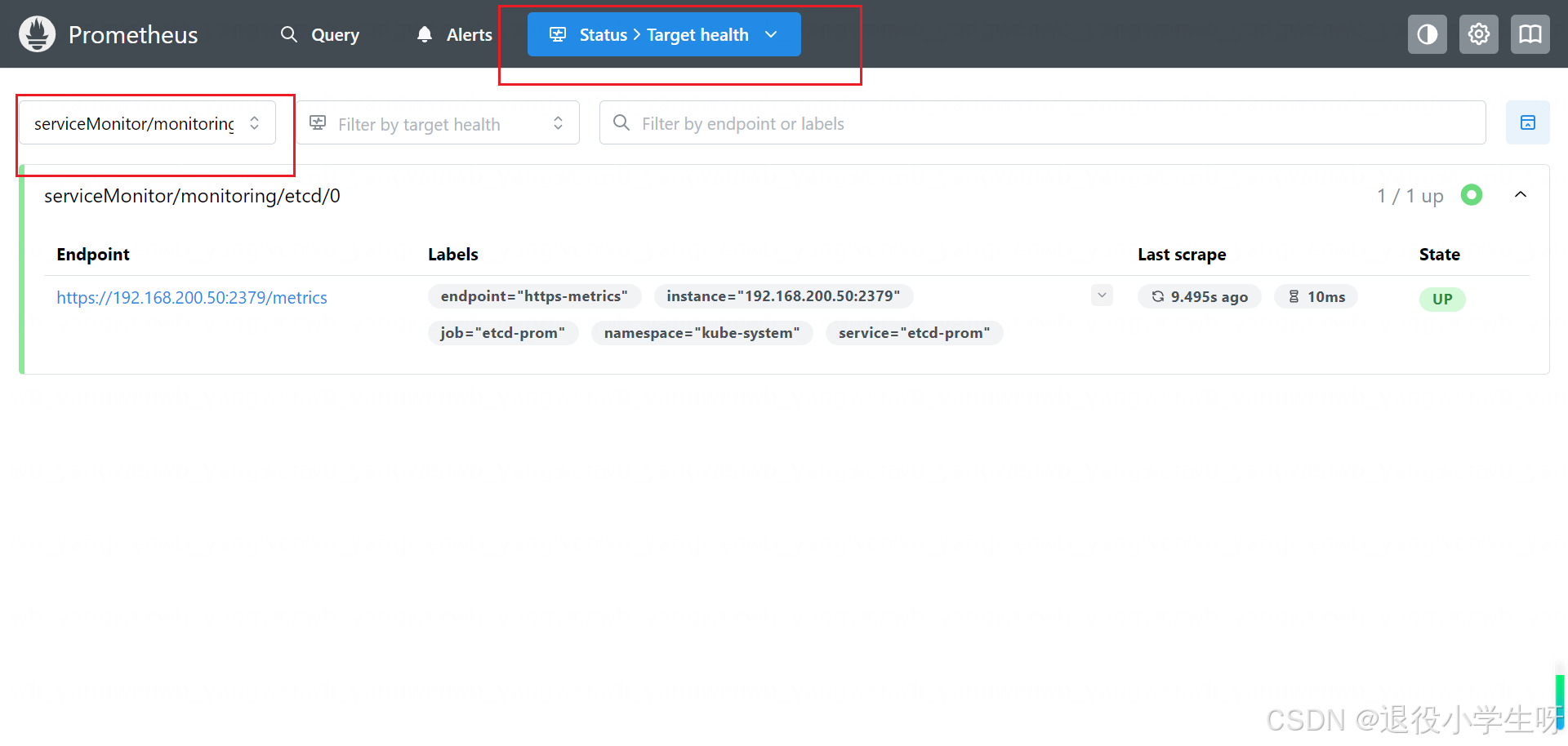
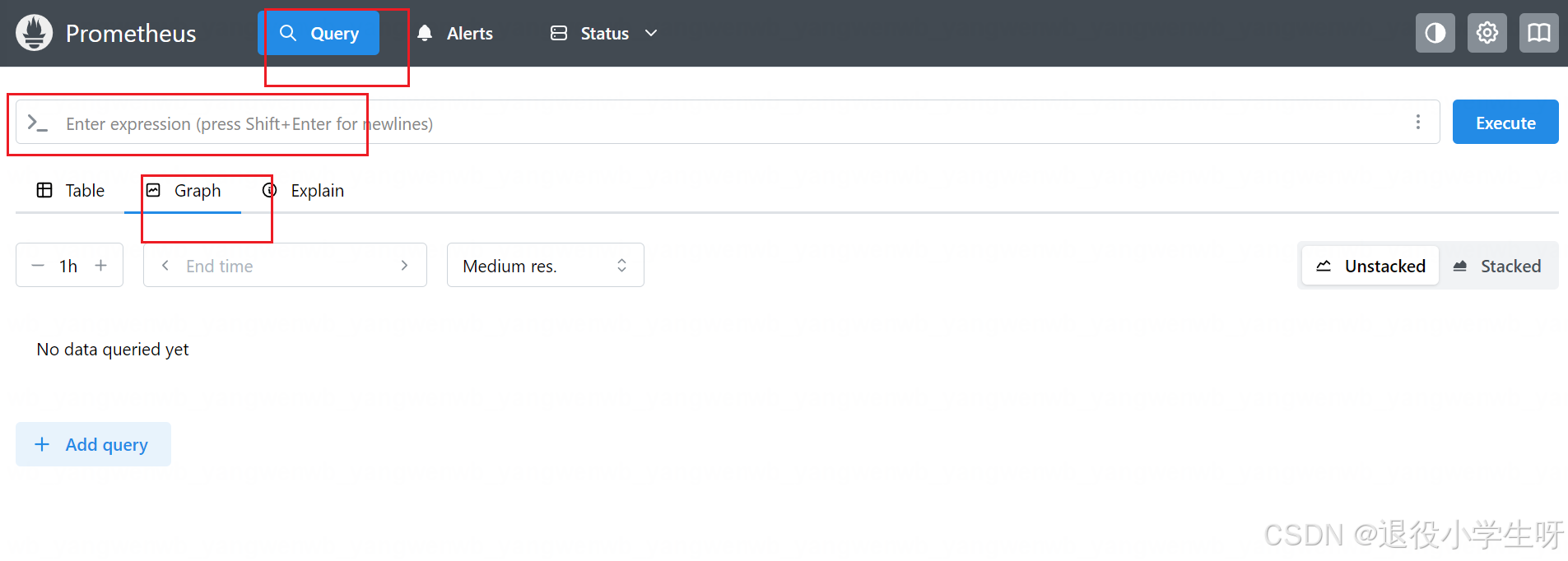
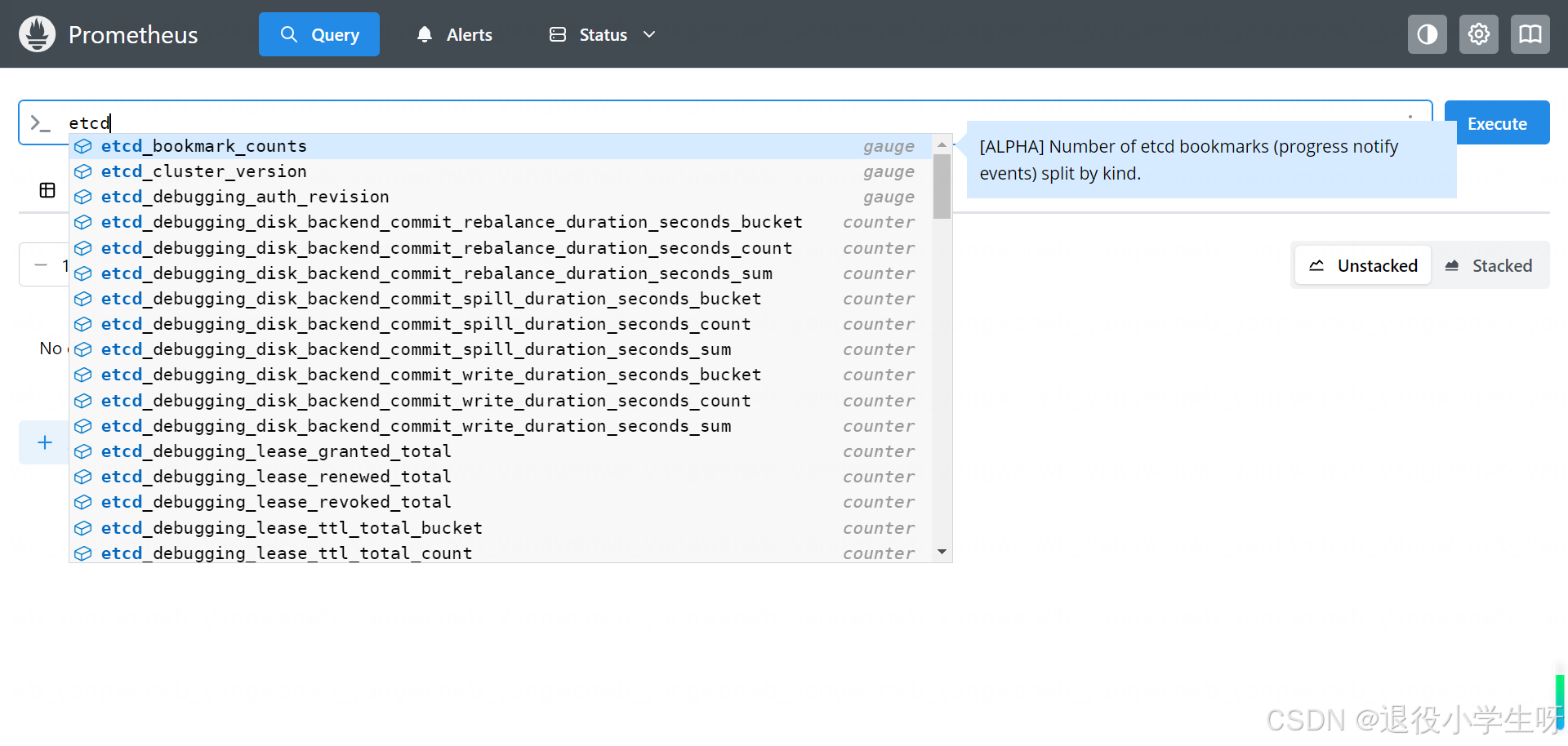
同时也可以查询到 Etcd 相关的指标:
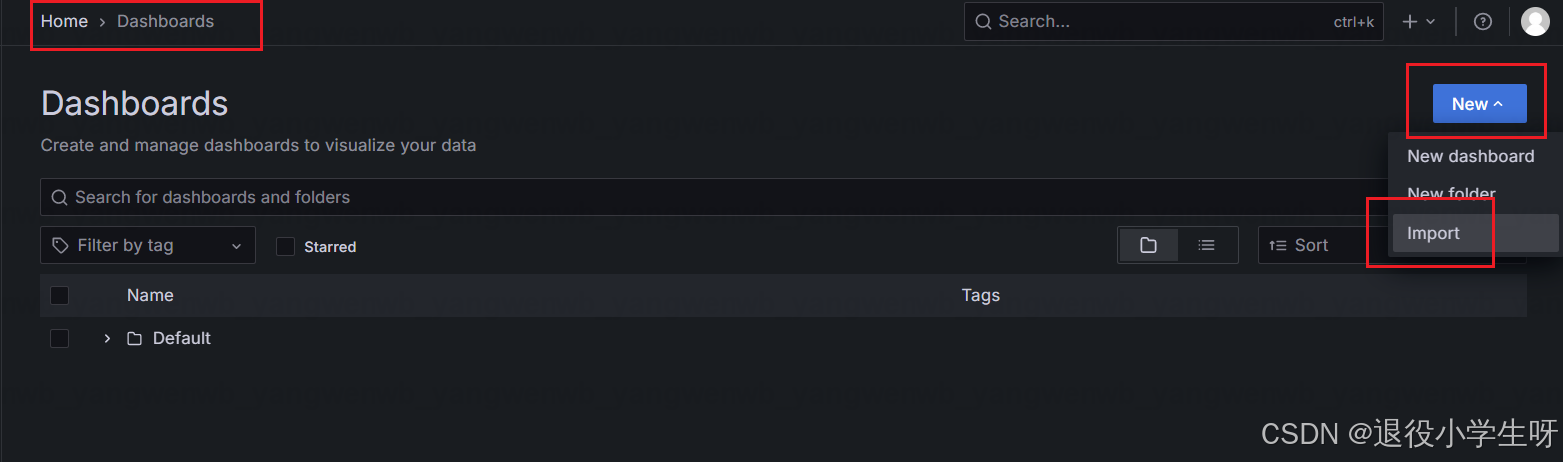
3.1.4 Grafana 配置
接下来打开 Grafana,可以添加 Etcd 的监控面板
之后输入 Etcd 的 Grafana Dashboard ID为3070,点击 Load,如下图所示:
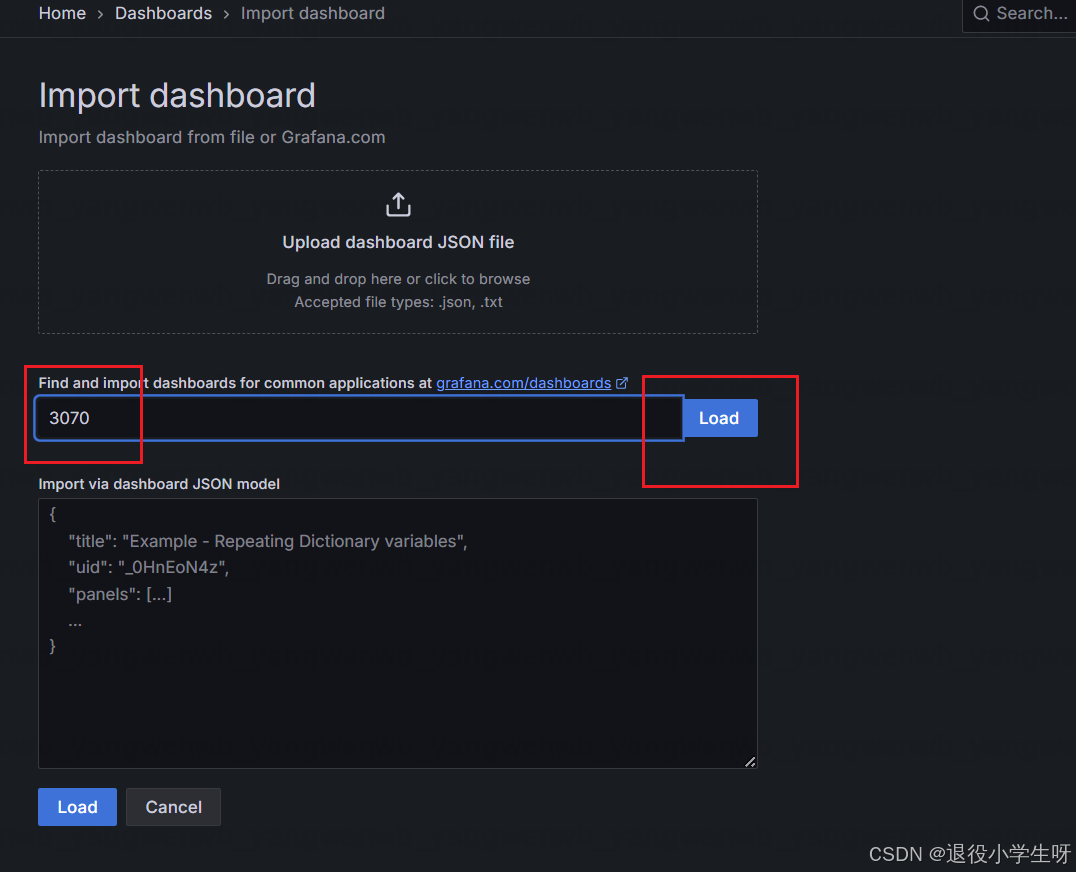
然后选择 Prometheus,点击 Import 即可:
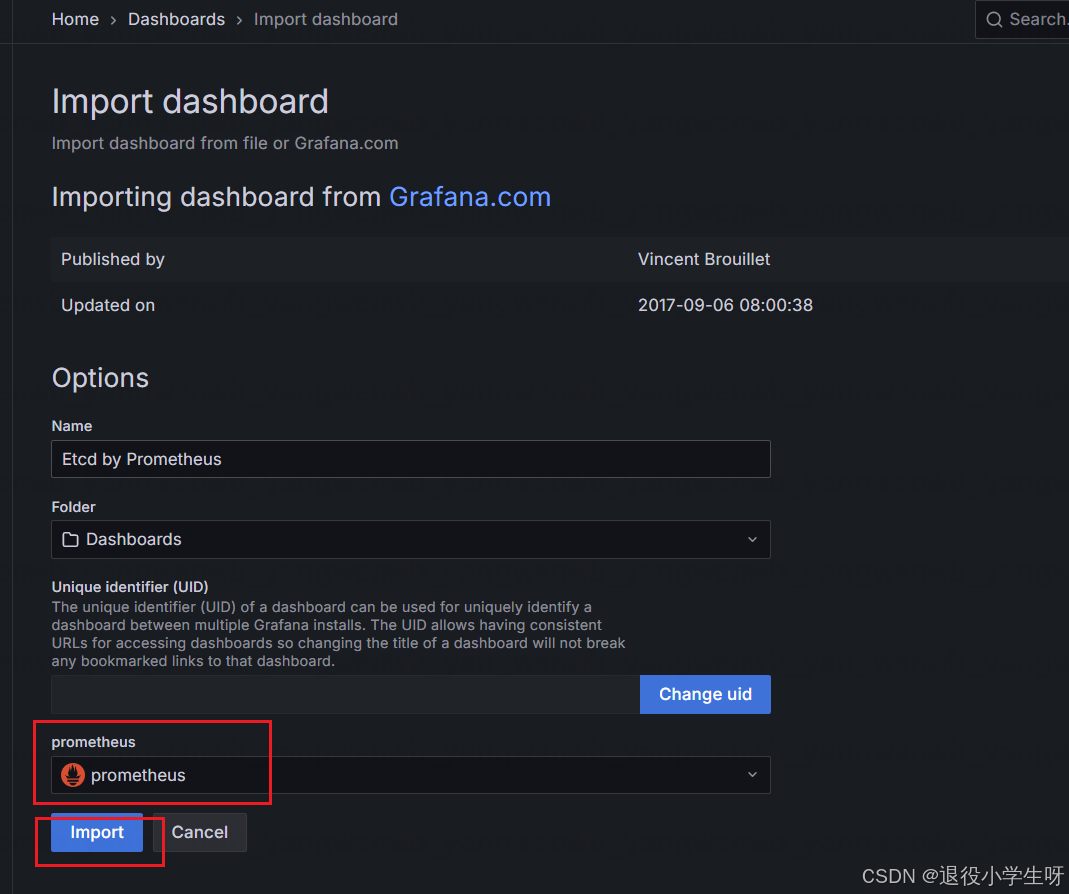
之后就可以看到 Etcd 集群的状态:
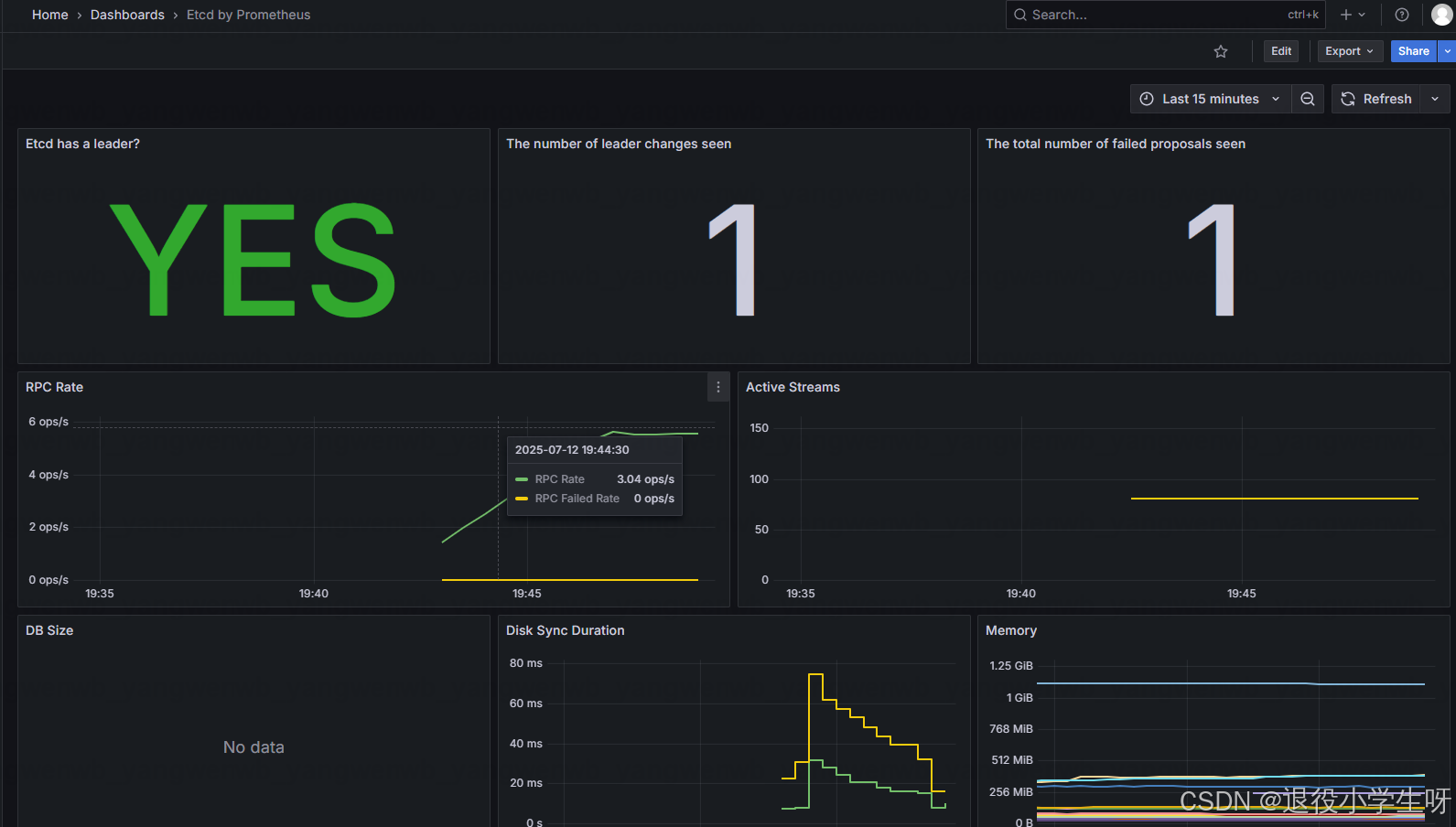
3.2 使用 Exporter 监控服务
如果想要监控一些未提供 Metrics 接口的服务,比如 MySQL、Redis 等,需要安装对应的 Exporter 才能进行监控。
本小节将使用 MySQL 作为一个测试用例,演示如何使用 Exporter 监控非云原生应用。
3.2.1 部署测试用例
首先部署 MySQL 至 Kubernetes 集群中,直接配置 MySQL 的权限即可
[root@k8s-master01 ~]# kubectl create deploy mysql --image=crpi-q1nb2n896zwtcdts.cn-beijing.personal.cr.aliyuncs.com/ywb01/mysql:8.0.20# 设置密码
[root@k8s-master01 ~]# kubectl set env deploy/mysql MYSQL_ROOT_PASSWORD=mysql# 查看 Pod 是否正常
[root@k8s-master01 ~]# kubectl get po -l app=mysql
NAME READY STATUS RESTARTS AGE
mysql-6879774876-s7fpd 1/1 Running 0 2m23s# 创建 Service 暴露 MySQL:
[root@k8s-master01 ~]# kubectl expose deploy mysql --port 3306
[root@k8s-master01 ~]# kubectl get svc -l app=mysql
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mysql ClusterIP 10.101.139.101 <none> 3306/TCP 20s
登录 MySQL,创建 Exporter 所需的用户和权限(如果已经有需要监控的 MySQL,可以直接执行此步骤即可):
[root@k8s-master01 ~]# kubectl exec -ti mysql-6879774876-s7fpd -- bash
root@mysql-6879774876-s7fpd:/# mysql -uroot -pmysql
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 8
Server version: 8.0.20 MySQL Community Server - GPLCopyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.mysql> CREATE USER 'exporter'@'%' IDENTIFIED BY 'exporter' WITH MAX_USER_CONNECTIONS 3;
Query OK, 0 rows affected (0.01 sec)mysql> GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'%';
Query OK, 0 rows affected (0.01 sec)mysql>
# 创建 MySQL Exporter 的配置文件
[root@k8s-master01 ~]# cat <<'EOF' >> .my.cnf
[client]
user=exporter
password=exporter
EOF# 创建 ConfigMap:
[root@k8s-master01 ~]# kubectl create cm mysql-exporter-cm --from-file=.my.cnf -n monitoring
# 配置 MySQL Exporter 采集 MySQL 监控数据:
[root@k8s-master01 ~]# vim mysql-exporter.yaml
[root@k8s-master01 ~]# cat mysql-exporter.yaml
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: mysql-exportername: mysql-exporternamespace: monitoring
spec:replicas: 1selector:matchLabels:app: mysql-exportertemplate:metadata:annotations:app: mysql-exportercreationTimestamp: nulllabels:app: mysql-exporterspec:containers:- args:- --config.my-cnf- /mnt/.my.cnf- --mysqld.address- mysql.default:3306image: crpi-q1nb2n896zwtcdts.cn-beijing.personal.cr.aliyuncs.com/ywb01/mysqld-exporter:latestimagePullPolicy: IfNotPresentname: mysql-exporterports:- containerPort: 9104name: http-webprotocol: TCPresources:limits:cpu: "1"memory: 1Girequests:cpu: 100mmemory: 128MivolumeMounts:- mountPath: /mntname: configvolumes:- configMap:defaultMode: 420name: mysql-exporter-cmoptional: truename: config
---
apiVersion: v1
kind: Service
metadata:name: mysql-exporternamespace: monitoringlabels:k8s-app: mysql-exporter
spec:type: ClusterIPselector:app: mysql-exporterports:- name: http-webport: 9104protocol: TCP# 创建 Exporter:
[root@k8s-master01 ~]# kubectl create -f mysql-exporter.yaml# 查看 Pod 是否正常
[root@k8s-master01 ~]# kubectl get po -n monitoring | grep mysql
mysql-exporter-6666f78794-x59ss 1/1 Running 0 105s# 查看 Service
[root@k8s-master01 ~]# kubectl get svc -n monitoring | grep mysql
mysql-exporter ClusterIP 10.109.48.138 <none> 9104/TCP 2m3s# 通过该 Service 地址,检查是否能正常获取 Metrics 数据:
[root@k8s-master01 ~]# curl -s 10.109.48.138:9104/metrics | tail -3
promhttp_metric_handler_requests_total{code="200"} 2
promhttp_metric_handler_requests_total{code="500"} 0
promhttp_metric_handler_requests_total{code="503"} 0
3.2.2 ServiceMonitor 配置
# 配置 ServiceMonitor:
[root@k8s-master01 ~]# vim mysql-servicemonitor.yaml
[root@k8s-master01 ~]# cat mysql-servicemonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:name: mysql-exporternamespace: monitoringlabels:k8s-app: mysql-exporternamespace: monitoring
spec:jobLabel: k8s-appendpoints:- port: http-webinterval: 30sscheme: httpselector:matchLabels:k8s-app: mysql-exporternamespaceSelector:matchNames:- monitoring# 需要注意 matchLabels 和 endpoints 的配置,要和 MySQL 的 Service 一致。之后创建该 ServiceMonitor:
[root@k8s-master01 ~]# kubectl create -f mysql-servicemonitor.yaml -n monitoring
接下来即可在 Prometheus Web UI 看到该监控:
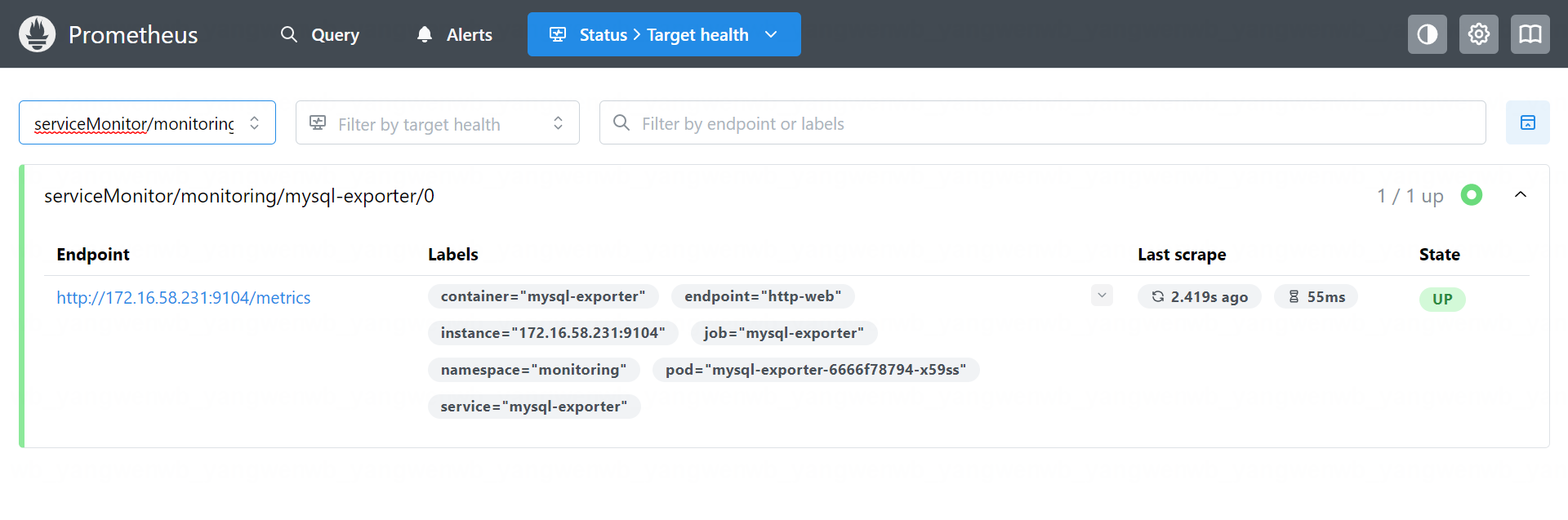
同样的方式也可以在 Graph 查询到监控指标:
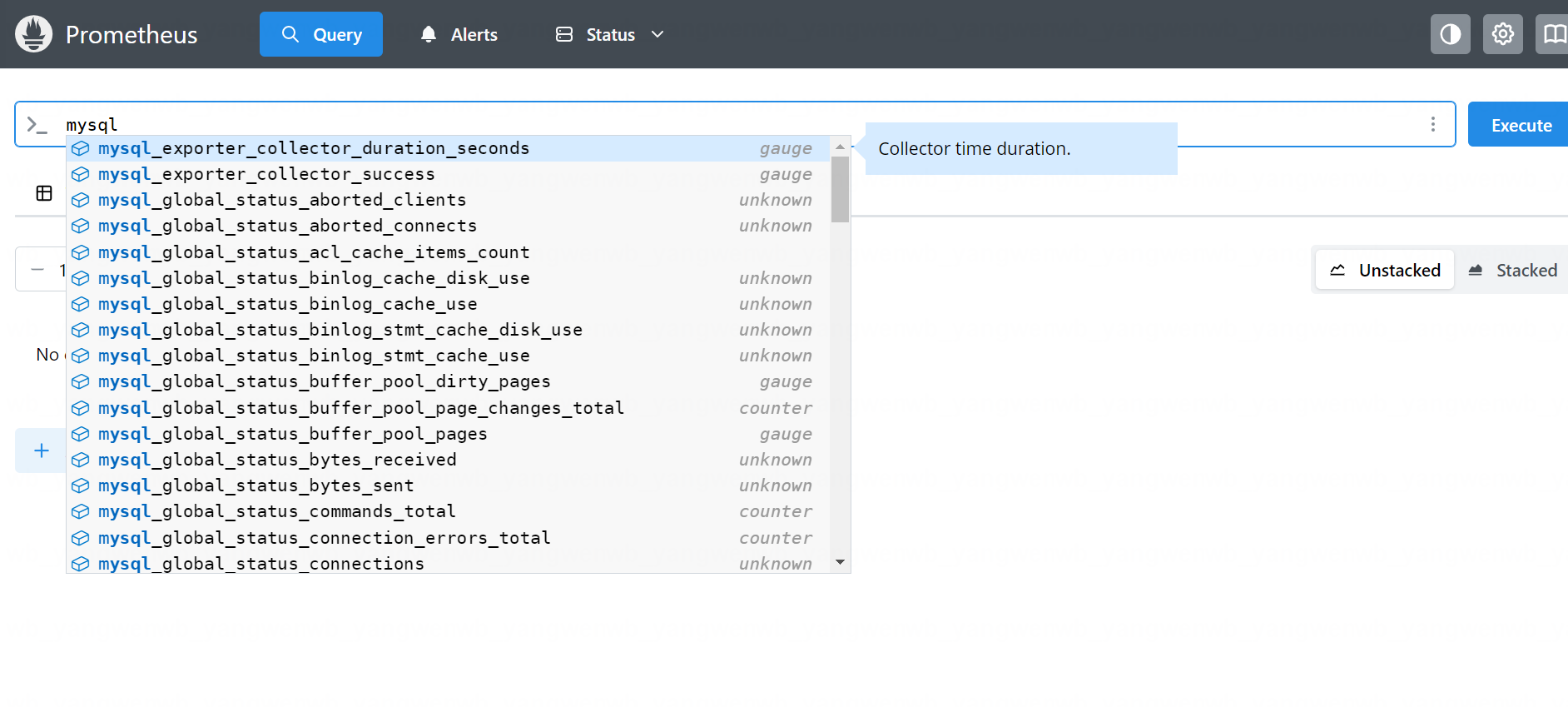
3.2.3 Grafana 配置
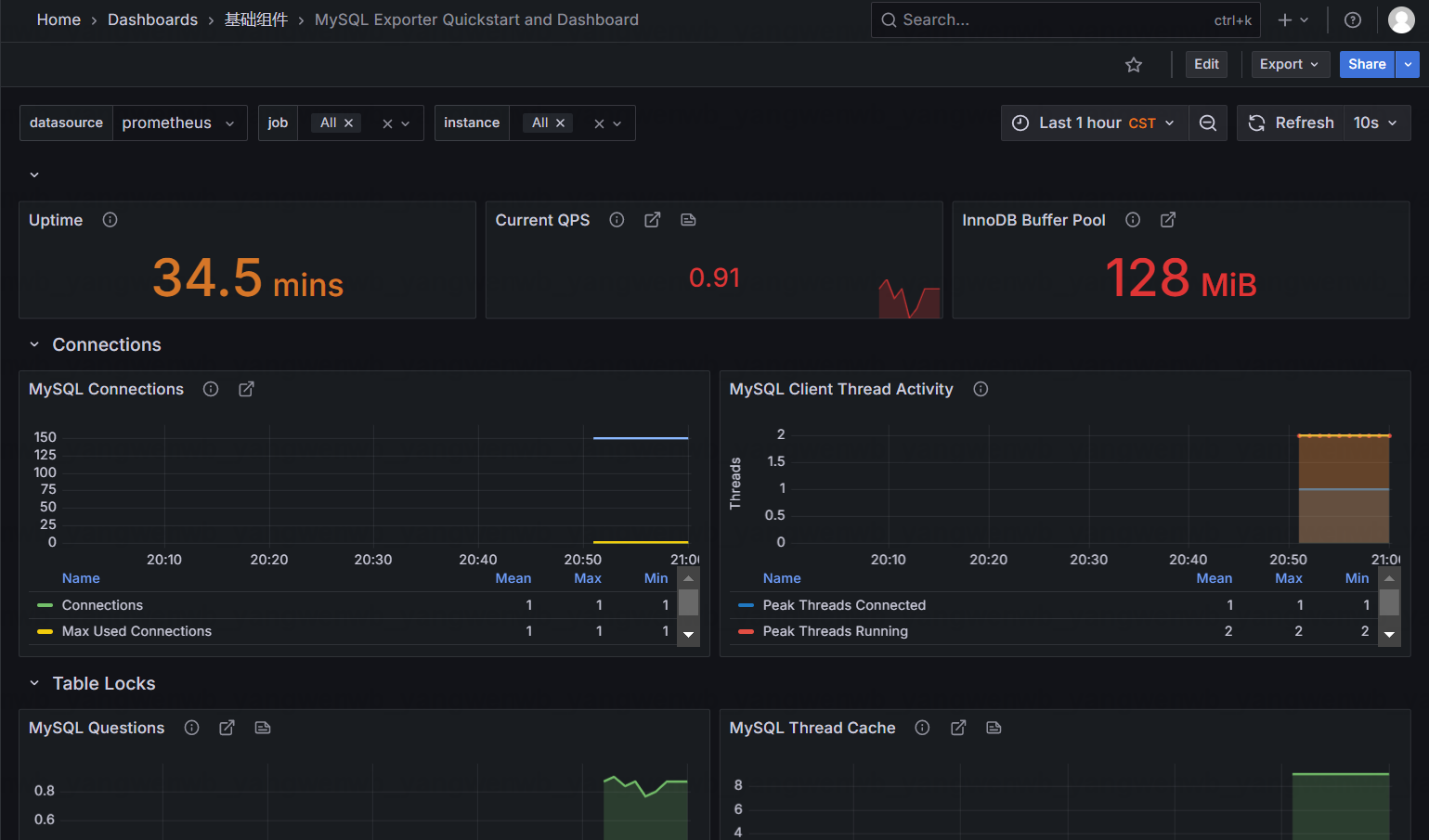
最 后 可 以 导 入 Grafana MySQL 的 Dashboard ,ID:14057。导入完成后,即可在 Grafana 看到监控数据:
3.3 使用 ScrapeConfig 监控服务
参考文档:https://github.com/oliver006/redis_exporter
3.3.1 部署测试用例
# 接下来演示如何使用 ScrapeConfig 进行监控,首先部署一个 Redis 作为测试服务:
[root@k8s-master01 ~]# kubectl create deploy redis --image=crpi-q1nb2n896zwtcdts.cn-beijing.personal.cr.aliyuncs.com/ywb01/redis:7.2.5# 创建 Service
[root@k8s-master01 ~]# kubectl expose deploy redis --port 6379# 查看服务状态:
[root@k8s-master01 ~]# kubectl get po -l app=redis
NAME READY STATUS RESTARTS AGE
redis-564b7bcf74-c79hm 1/1 Running 0 116s
# 接下来部署 Exporter:
[root@k8s-master01 ~]# kubectl create deploy redis-exporter -n monitoring --image=crpi-q1nb2n896zwtcdts.cn-beijing.personal.cr.aliyuncs.com/ywb01/redis_exporter# 创建 Service
[root@k8s-master01 ~]# kubectl expose deployment redis-exporter -n monitoring --port 9121# 查看服务状态:
[root@k8s-master01 ~]# kubectl get po -n monitoring -l app=redis-exporter
NAME READY STATUS RESTARTS AGE
redis-exporter-69f4bd8684-52v4s 1/1 Running 0 59s
3.3.2 ScrapeConfig 配置
# 接下来创建 ScrapeConfig 即可监控不同的实例:
[root@k8s-master01 ~]# vim redis-scrapeConfig.yaml
[root@k8s-master01 ~]# cat redis-scrapeConfig.yaml
apiVersion: monitoring.coreos.com/v1alpha1
kind: ScrapeConfig
metadata:name: redis-exporternamespace: monitoring
spec:scrapeInterval: 30sjobName: redis-exportermetricsPath: /scrapescheme: HTTPstaticConfigs:- targets: # 多个实例写多次即可- redis://redis.default:6379 # redis://<username>:<password>@address:portlabels:env: testrelabelings:- sourceLabels: [__address__]targetLabel: __param_target- sourceLabels: [__param_target]targetLabel: instance- targetLabel: __address__replacement: redis-exporter.monitoring:9121[root@k8s-master01 ~]# kubectl create -f redis-scrapeConfig.yaml -n monitoring
接下来即可在 Prometheus Web UI 看到该监控:
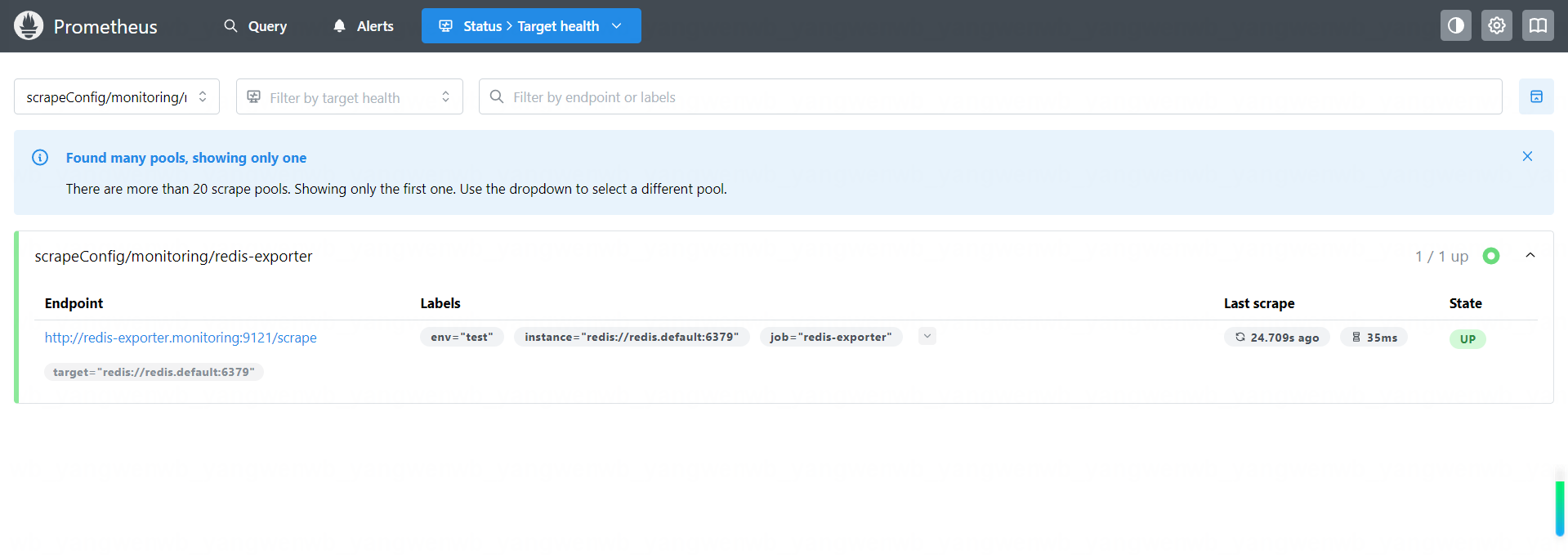
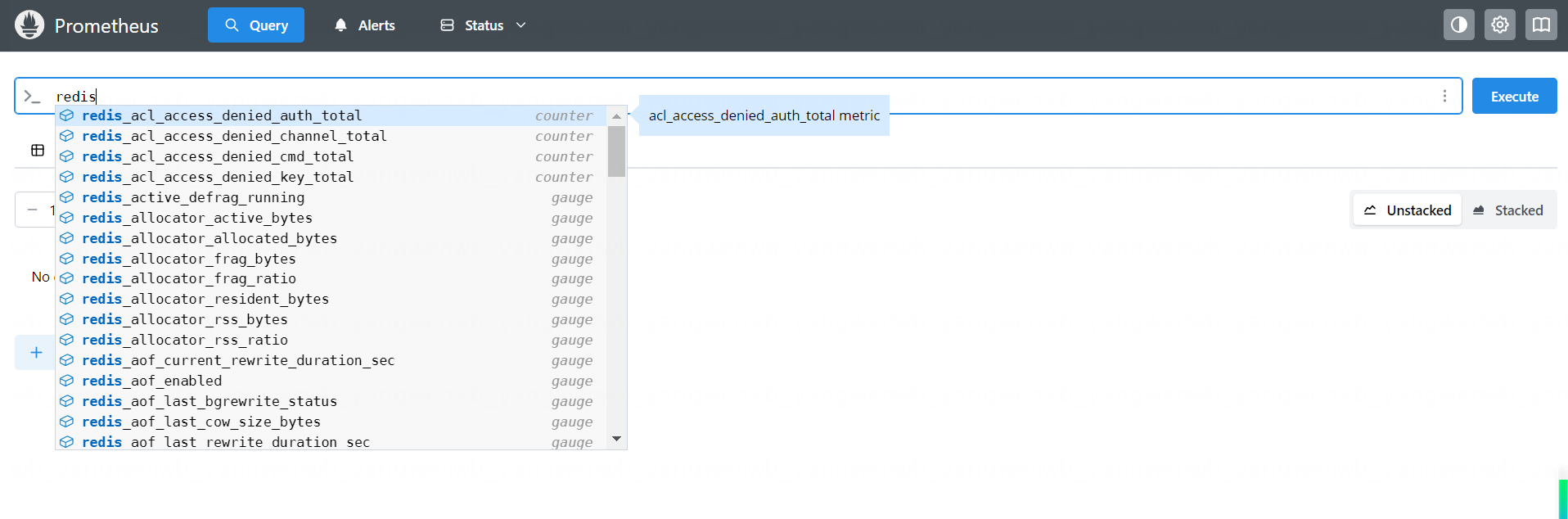
同样的方式也可以在 Graph 查询到监控指标
3.3.3 Grafana 配置
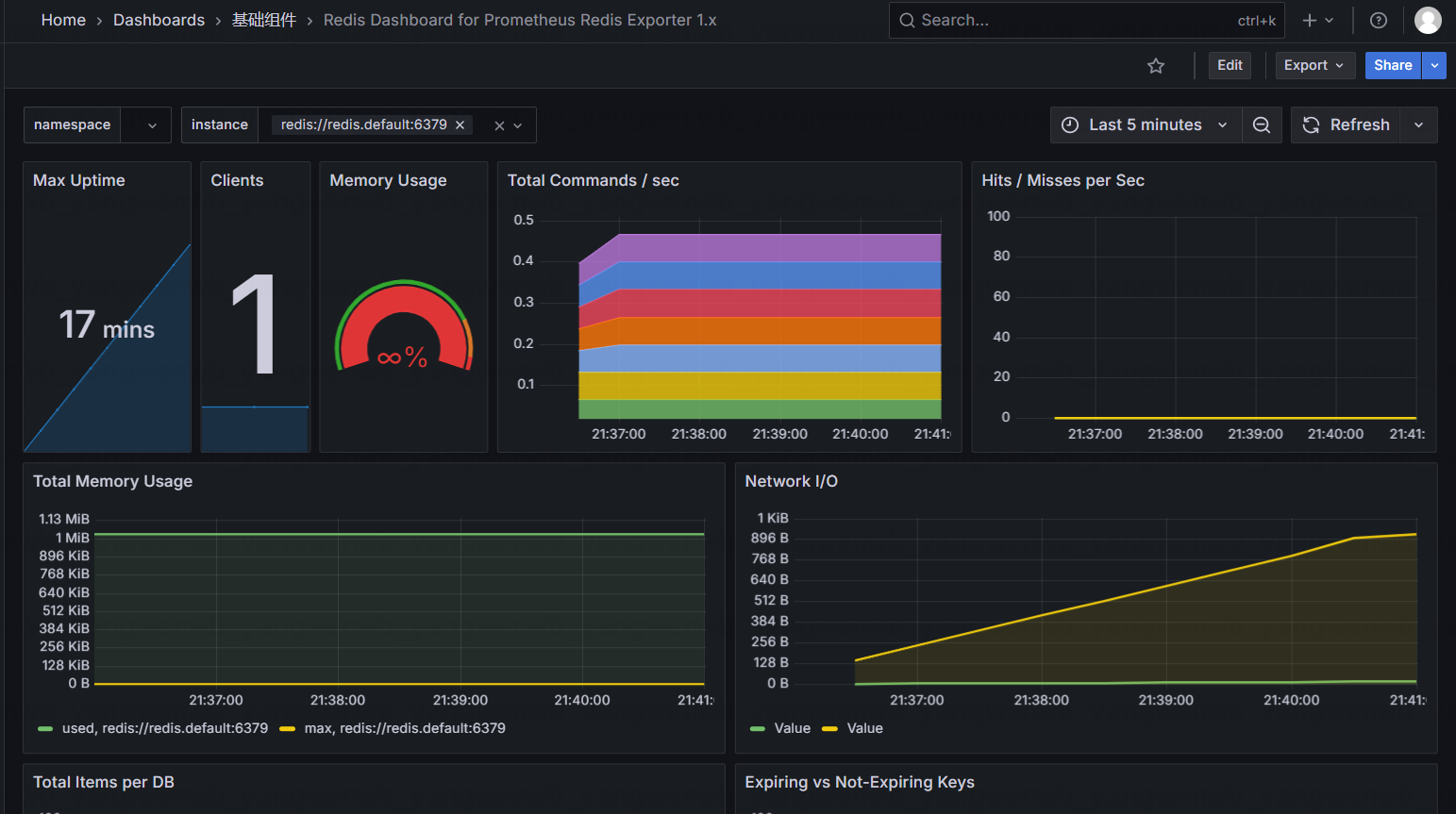
同样的方式,添加 ID 为 763 的面板,即可在 Grafana 上展示数据:
3.4 使用 Probe 监控服务
参考文档:https://github.com/prometheus/blackbox_exporter
CRD 文档:https://github.com/prometheus-operator/kube-prometheus/blob/main/docs/blackboxexporter.md
3.4.1 Probe 配置
Probe 类型的监控通常都会和 Blackbox 配合使用,用于监控域名的可用性。
# 比如需要使用 HTTP 请求监控某个域名,可以使用如下配置:
[root@k8s-master01 ~]# vim probe-scrapeConfig.yaml
[root@k8s-master01 ~]# cat probe-scrapeConfig.yaml
apiVersion: monitoring.coreos.com/v1
kind: Probe
metadata:name: blackboxnamespace: monitoring
spec:interval: 30sjobName: blackboxmodule: http_2xxprober:url: blackbox-exporter.monitoring.svc:19115scheme: httppath: /probetargets:staticConfig:static: # 多个实例写多次即可- https://www.kubeasy.com- https://www.baidu.com[root@k8s-master01 ~]# kubectl create -f probe-scrapeConfig.yaml
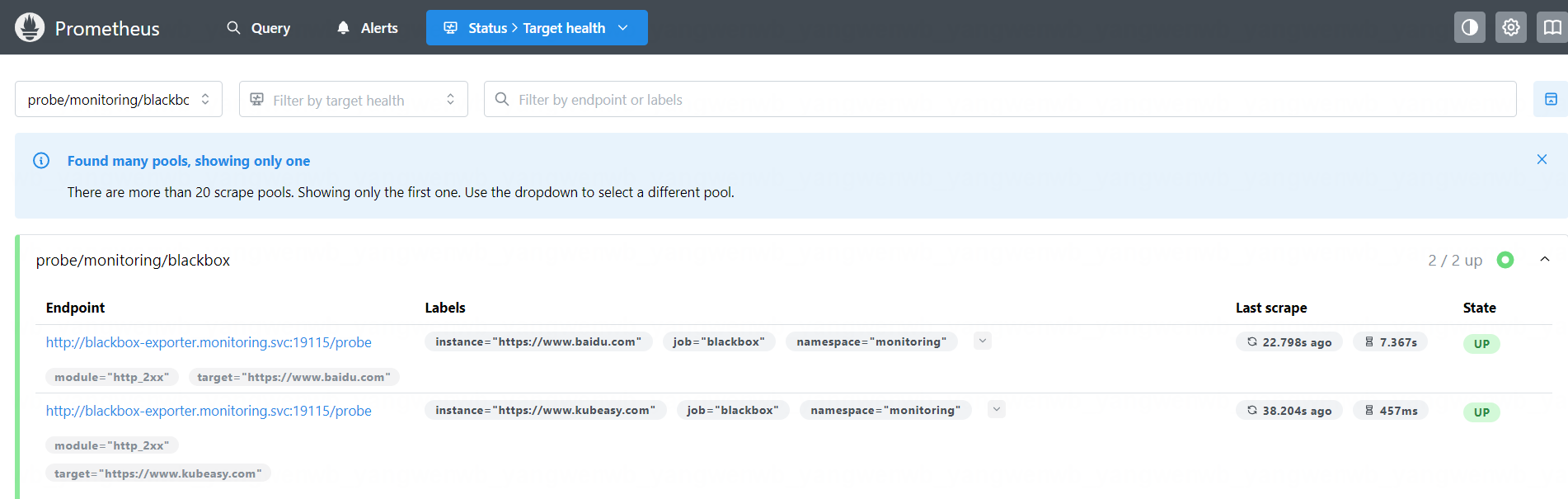
接下来即可在 Prometheus Web UI 看到该监控:
同样的方式也可以在 Graph 查询到监控指标
3.4.2 Grafana 配置
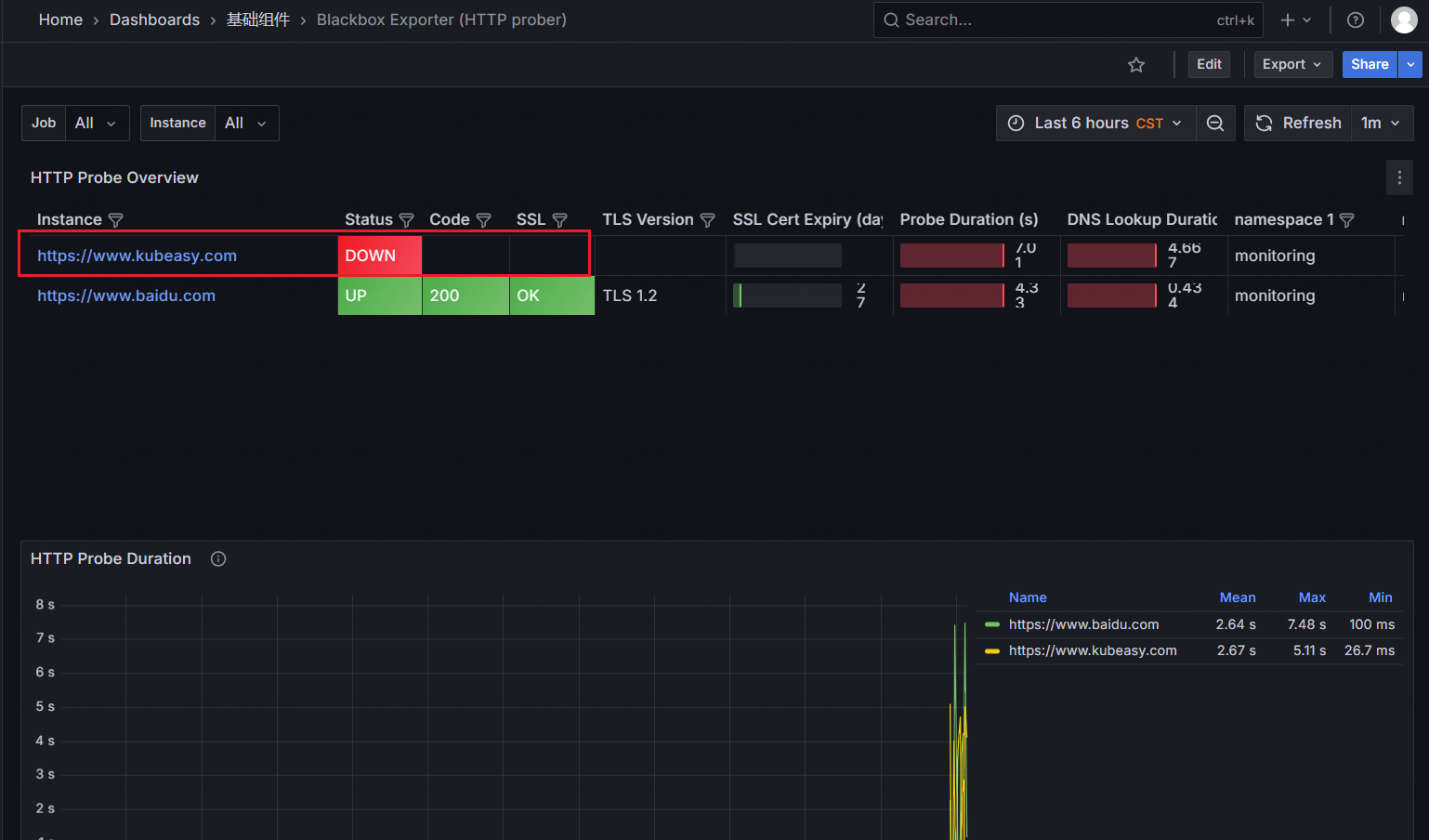
接下来在 Grafana 上添加对应的面板即可查询监控数据,ID 为 13659:
3.5 使用 PodMonitor 监控服务
如果服务原生提供了 Metrics 接口,也可以直接使用 PodMonitor 进行监控。
3.5.1 部署测试用例
# 首先创建一个测试用例:
[root@k8s-master01 ~]# kubectl create deploy example-app --image=crpi-q1nb2n896zwtcdts.cn-beijing.personal.cr.aliyuncs.com/ywb01/example-app:v0.5.0 --port 8080# 查看 Metrics:
[root@k8s-master01 ~]# kubectl get po -owide | grep example-app
example-app-7dc7cbcb4c-5294l 1/1 Running 0 59s 172.16.32.139 k8s-master01 <none> <none># 测试连接
[root@k8s-master01 ~]# curl 172.16.32.139:8080/metrics
# HELP version Version information about this binary
# TYPE version gauge
version{version="v0.5.0"} 1
3.5.2 创建 PodMonitor
# 接下来创建 PodMonitor 监控该服务:
[root@k8s-master01 ~]# vim example-app-pod-monitor.yaml
[root@k8s-master01 ~]# cat example-app-pod-monitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:name: example-applabels:team: frontend
spec:selector:matchLabels:app: example-apppodMetricsEndpoints:- targetPort: 8080[root@k8s-master01 ~]# kubectl create -f example-app-pod-monitor.yaml
接下来即可在 Prometheus Web UI 看到该监控:
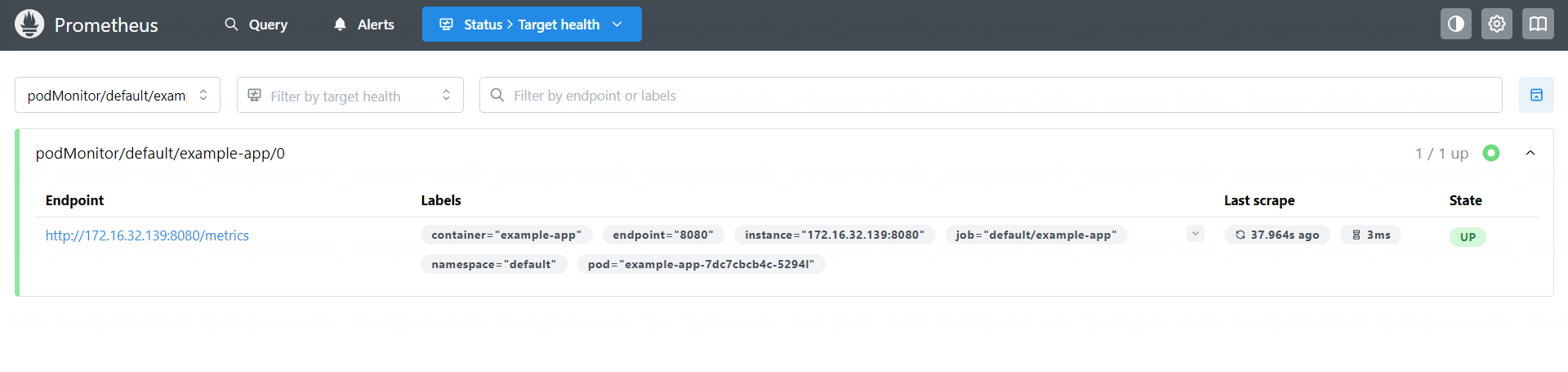

4、K8s 核心组件监控
Prometheus 原生提供了 Kubernetes 核心组件的监控,但是 Scheduler 和 Controller Manager 可能由于配置的问题导致监控失败,如下图所示:
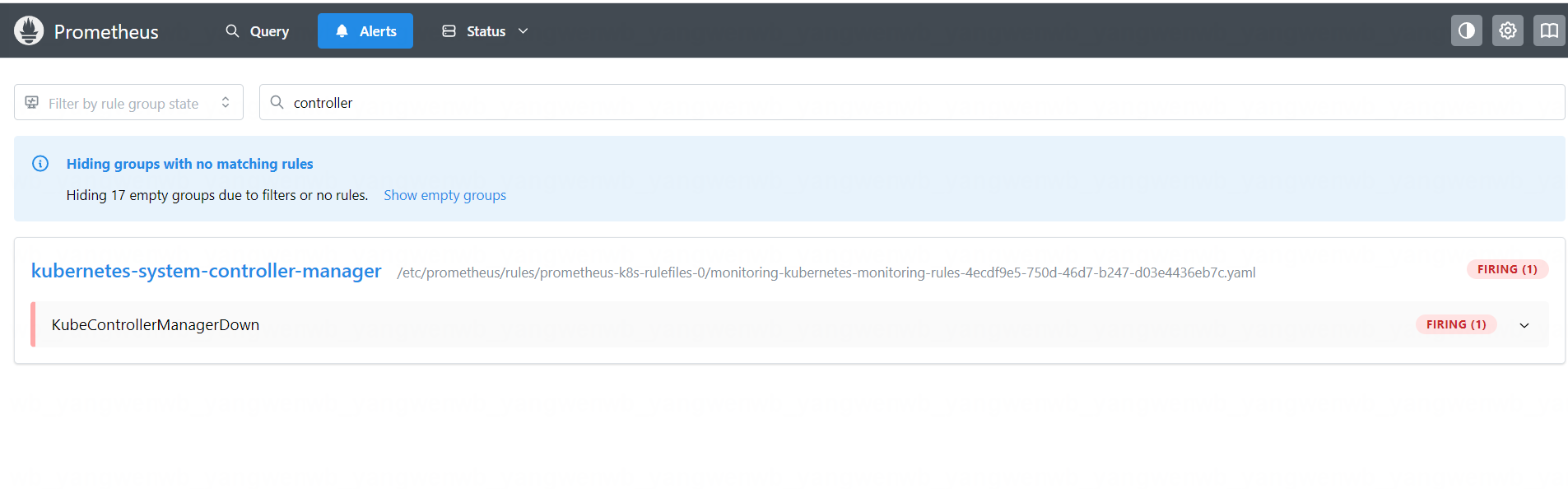
# 接下来看一下无法监控的原因,首先查询一下是否有相关的 ServiceMonitor:
[root@k8s-master01 ~]# kubectl get servicemonitor -n monitoring kube-controller-manager kube-scheduler
NAME AGE
kube-controller-manager 4h40m
kube-scheduler 4h40m# 查看配置文件
[root@k8s-master01 ~]# kubectl get servicemonitor -n monitoring kube-controller-manager -oyaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
....jobLabel: app.kubernetes.io/namenamespaceSelector:matchNames:- kube-systemselector:matchLabels:app.kubernetes.io/name: kube-controller-manager
该 Service Monitor 匹 配 的 是 kube-system 命 名 空 间 下 , 具 有 app.kubernetes.io/name=kube-controller-manager 标签,接下来通过该标签查看是否有该Service:
[root@k8s-master01 ~]# kubectl get svc -n kube-system -l app.kubernetes.io/name=kube-controller-manager
No resources found in kube-system namespace.
可以看到并没有此标签的 Service,所以导致了找不到需要监控的目标,此时可以手动创建该 Service 和 Endpoint 指向自己的 Controller Manager:
[root@k8s-master01 ~]# vim kube-controller-manager-svc.yaml
[root@k8s-master01 ~]# cat kube-controller-manager-svc.yaml
apiVersion: v1
kind: Endpoints
metadata:labels:app.kubernetes.io/name: kube-controller-managername: kube-controller-manager-promnamespace: kube-system
subsets:
- addresses: - ip: 192.168.200.50 # 这里填写 Controller Manager 的 IPports:- name: https-metricsport: 10257protocol: TCP
---
apiVersion: v1
kind: Service
metadata:labels:app.kubernetes.io/name: kube-controller-managername: kube-controller-manager-promnamespace: kube-system
spec:ports:- name: https-metricsport: 10257protocol: TCPtargetPort: 10257sessionAffinity: Nonetype: ClusterIP# 来创建该 Service 和 Endpoint
[root@k8s-master01 ~]# kubectl create -f kube-controller-manager-svc.yaml # 查看创建的 Service 和 Endpoint
[root@k8s-master01 ~]# kubectl get svc -n kube-system kube-controller-manager-prom
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-controller-manager-prom ClusterIP 10.108.0.219 <none> 10257/TCP 8s
创建后,在 Prometheus 上即可查看到监控目标:
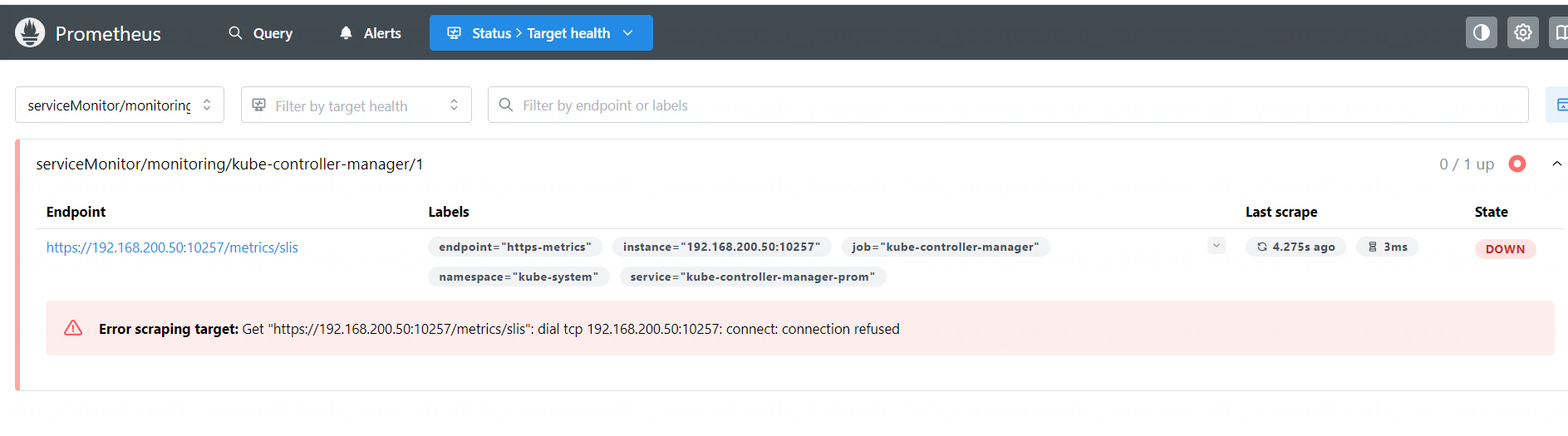
但是由于 Controller Manager 和 Scheduler 是监听的 127.0.0.1 就导致无法被外部访问,此时需要更改它的监听地址为 0.0.0.0
[root@k8s-master01 ~]# sed -i "s#address=127.0.0.1#address=0.0.0.0#g" /etc/kubernetes/manifests/kube-controller-manager.yaml# 更改查看监听端口:
[root@k8s-master01 ~]# netstat -anp | grep 10257
tcp6 0 0 :::10257 :::* LISTEN 214916/kube-control
tcp6 0 0 192.168.200.50:10257 192.168.200.51:38207 ESTABLISHED 214916/kube-control
tcp6 0 0 192.168.200.50:10257 192.168.200.52:59620 ESTABLISHED 214916/kube-control
等待几分钟后,就可以在 Prometheus 的 Web UI 上看到 Controller Manager 的监控目标:
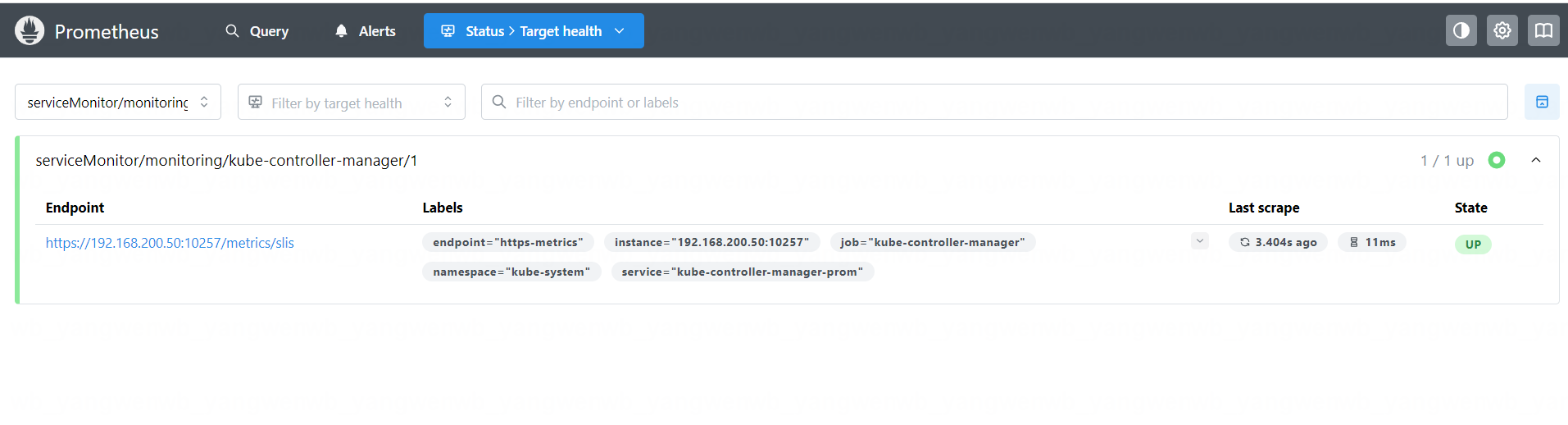
Grafana上面的监控也恢复了正常
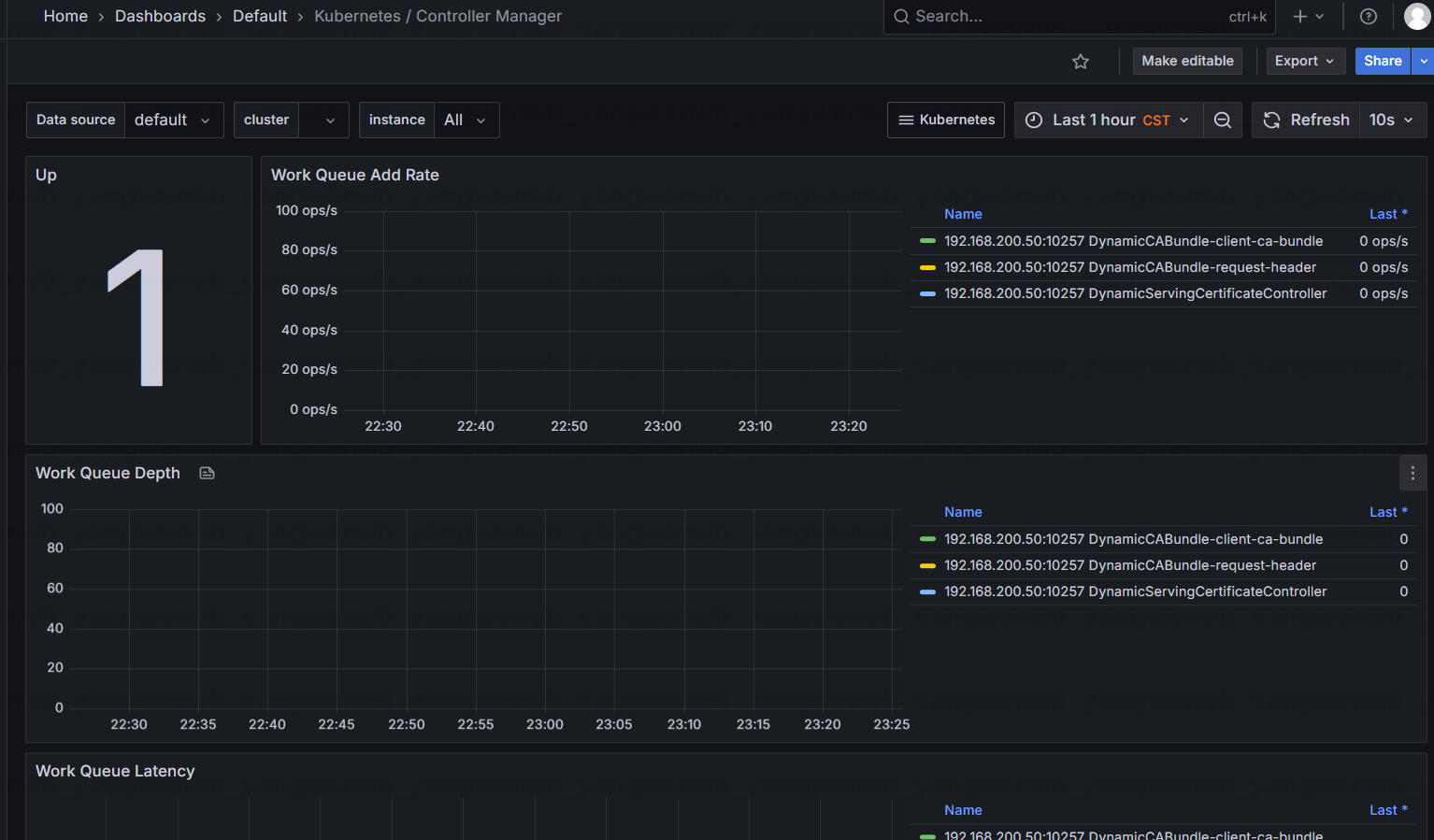
综合可知,使用 ServiceMonitor 监控失败时,可以安装如下步骤排查:
- 确认 Service Monitor 是否成功创建
- 确认 Prometheus 是否生成了相关配置
- 确认存在 Service Monitor 匹配的 Service
- 确认通过 Service 能够访问程序的 Metrics 接口
- 确认 Service 的端口和 Scheme 和 Service Monitor 一致
5、Prometheus 监控 Windows/Linux 主机
监控 Linux 的 Exporter 是:https://github.com/prometheus/node_exporter/releases
监控 Windows主机的 Exporter是:https://github.com/prometheus-community/windows_exporterr/releases
下载安装完成后,Windows Exporter 会暴露一个 9182 端口,可以通过该端口访问到 Windows 的监控数据(该IP是Windows电脑的IP)
[root@k8s-master01 ~]# curl -s 192.168.0.102:9182/metrics | tail -1
windows_system_threads 3156
接下来创建一个 ScrapeConfig 即可监控外部的 Windows 机器:
[root@k8s-master01 ~]# vim windows-scrapeConfig.yaml
[root@k8s-master01 ~]# cat windows-scrapeConfig.yaml
apiVersion: monitoring.coreos.com/v1alpha1
kind: ScrapeConfig
metadata:name: windows-exporternamespace: monitoring
spec:scrapeInterval: 30sjobName: windows-exportermetricsPath: /metricsscheme: HTTPstaticConfigs:- targets: # 多个实例写多次即可- 192.168.0.102:9182labels:env: test[root@k8s-master01 ~]# kubectl create -f windows-scrapeConfig.yaml
之后就可以在 Prometheus Web UI 看到监控数据:
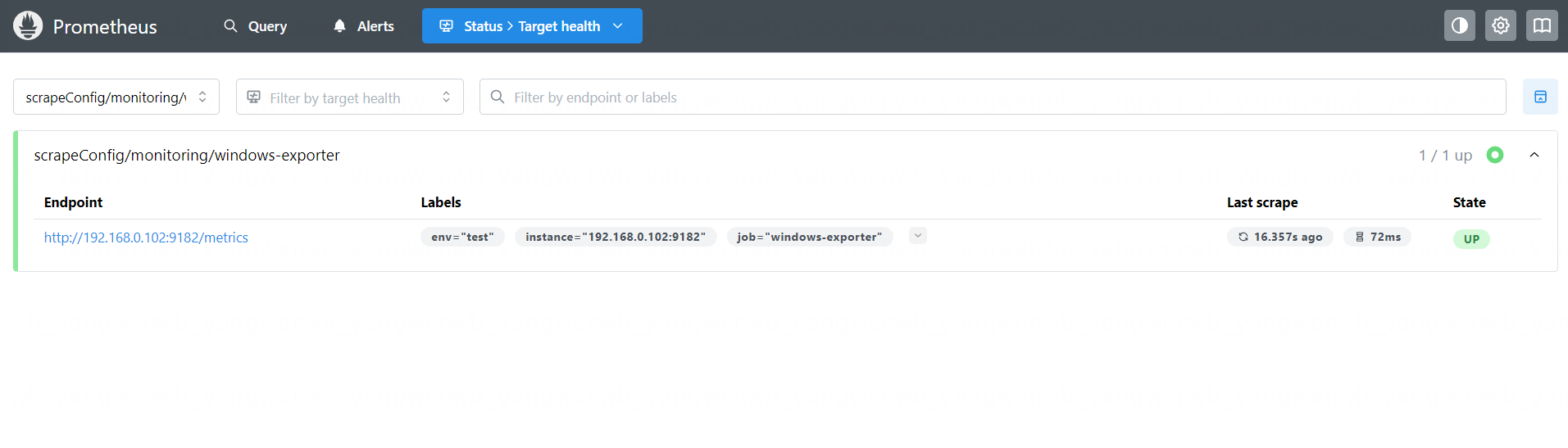
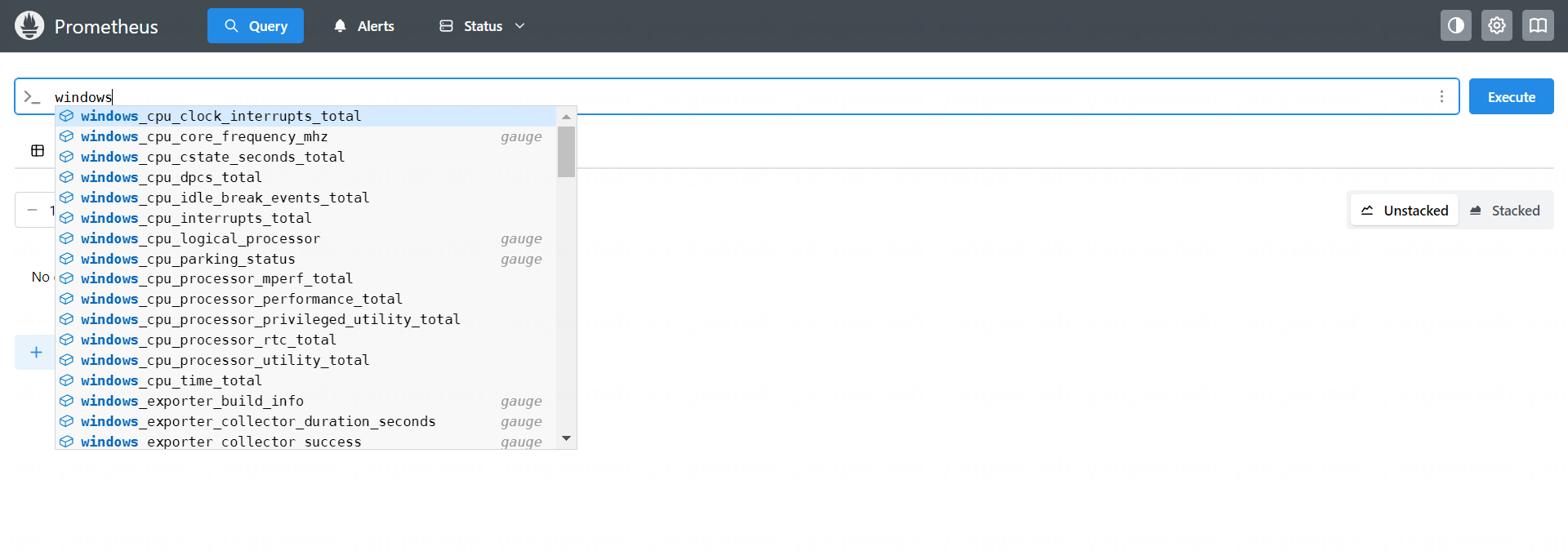
同样的方式也可以在 Graph 查询到监控指标:
最后在 Grafana 中导入模板(ID:20763)即可
6、Prometheus 语法 PromQL 入门
6.1 PromQL 语法初体验
PromQL Web UI 的 Graph 选项卡提供了简单的用于查询数据的入口,对于 PromQL 的编写和校验都可以在此位置。
输入 up,然后点击 Execute,就能查到监控正常的 Target,如图所示:
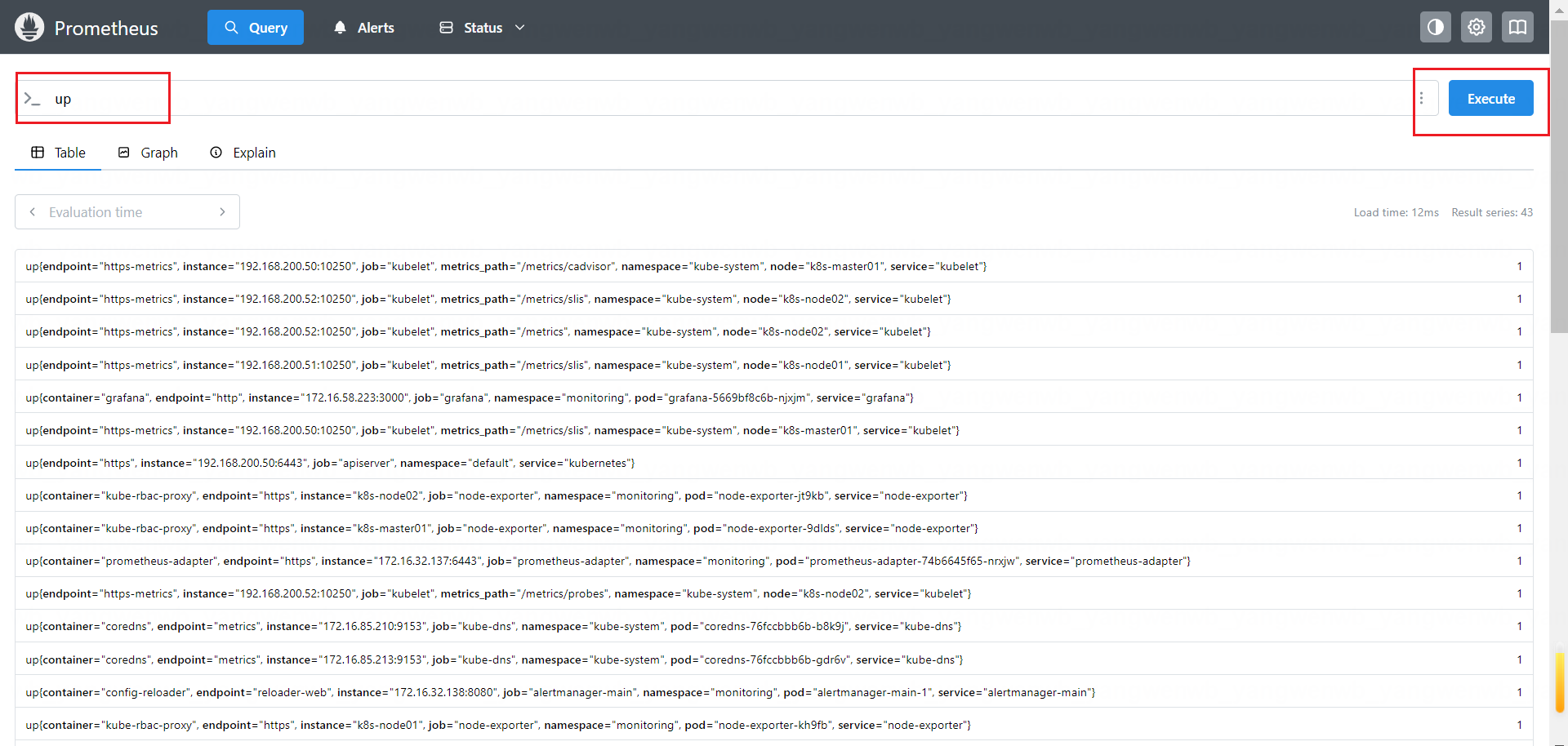
通过标签选择器过滤出 job 为 node-exporter的监控,语法为:up{job="node-exporter"}
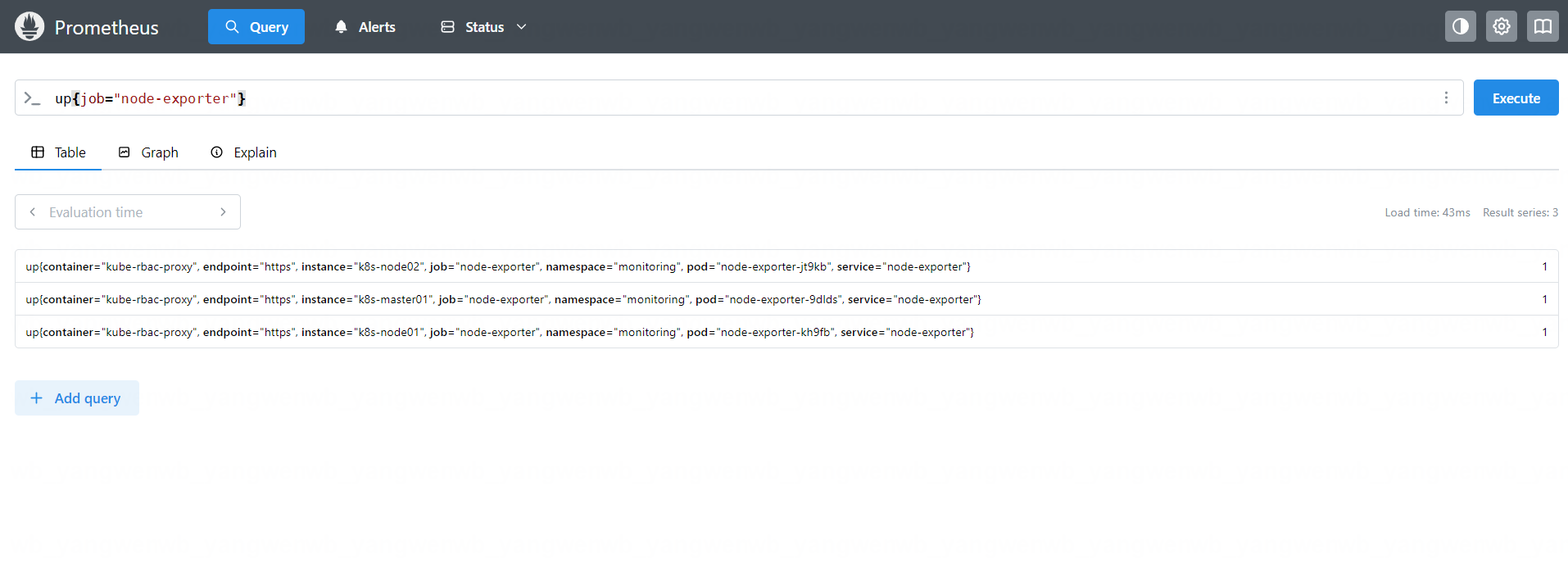
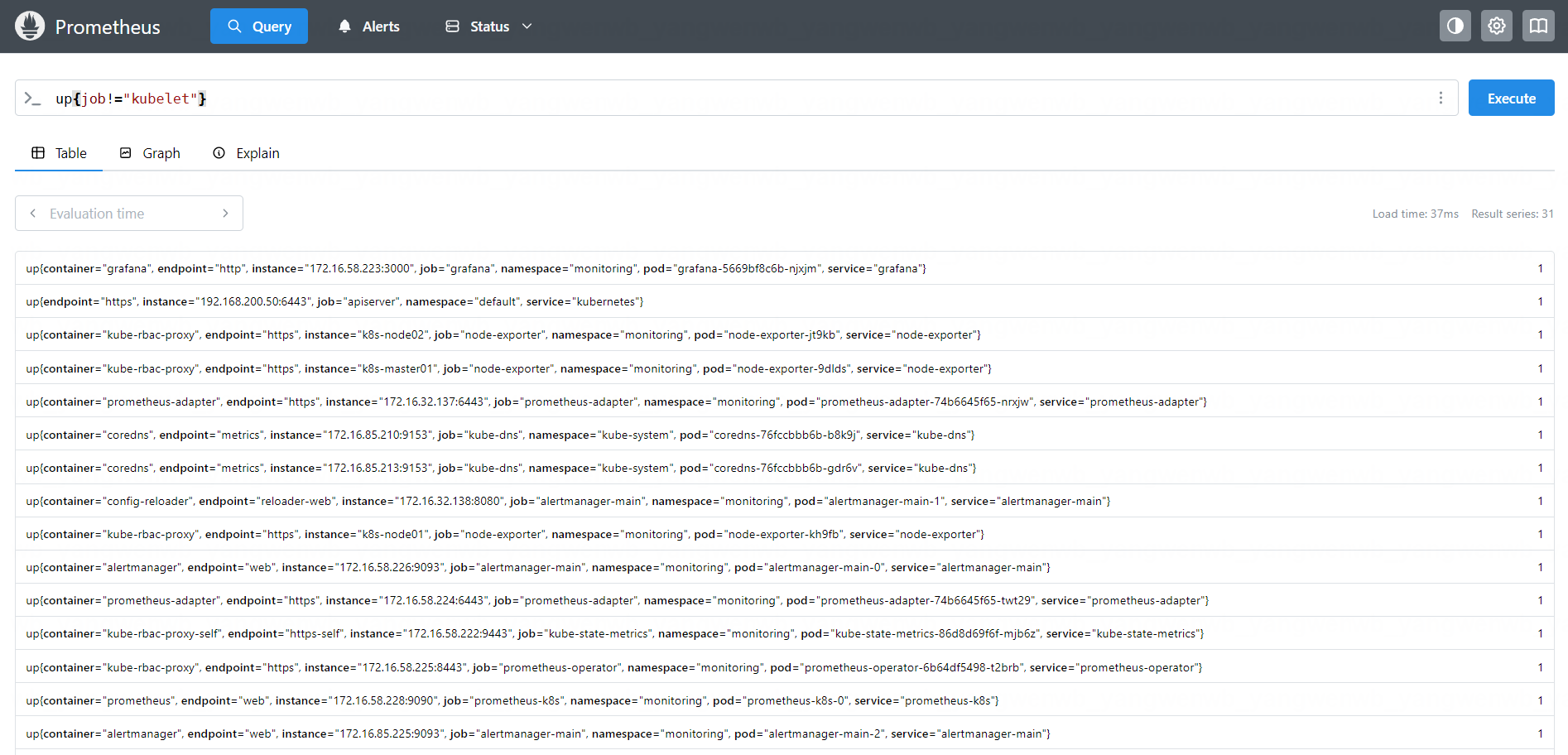
注意此时是 up{job=“node-exporter”}属于绝对匹配,PromQL 也支持如下表达式:
!=:不等于;
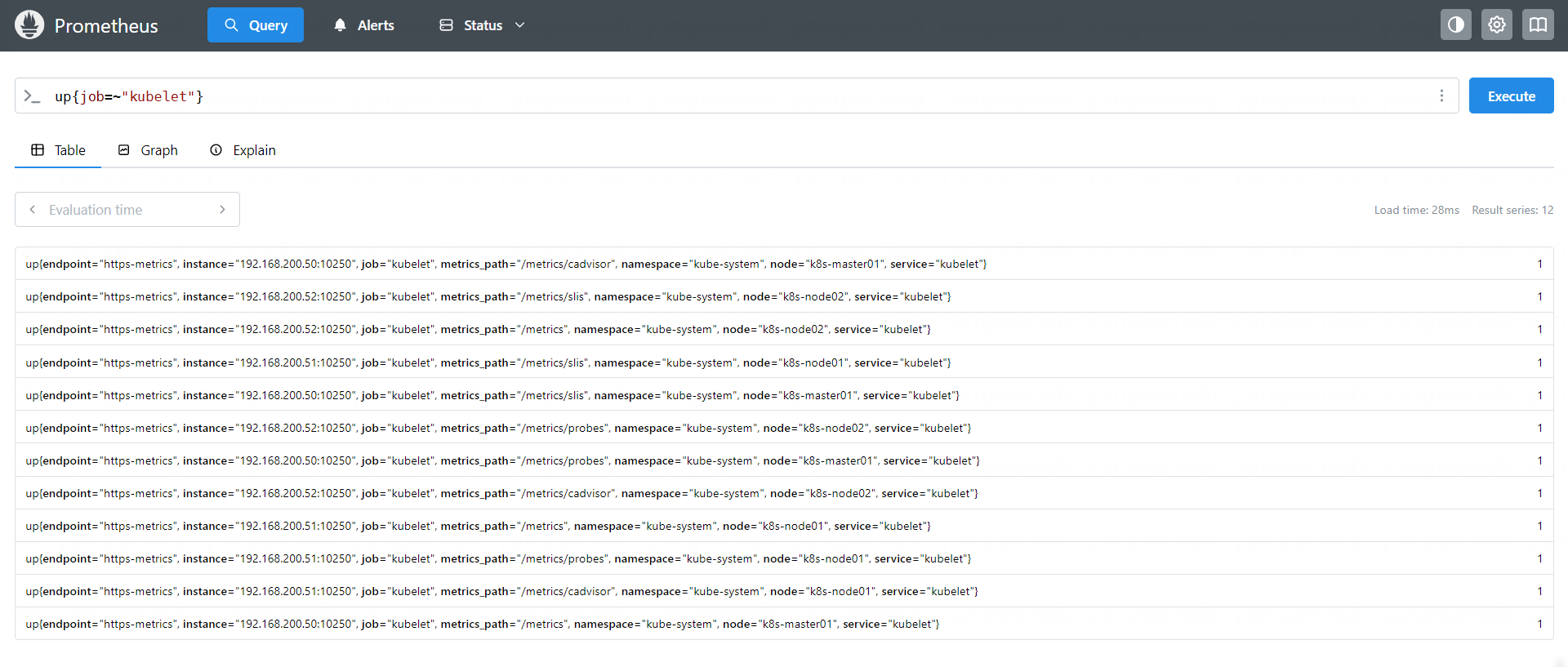
=~:表示等于符合正则表达式的指标;
!:和=类似,=表示正则匹配,!表示正则不匹配。
如果想要查看主机监控的指标有哪些,可以输入 node,会提示所有主机监控的指标:
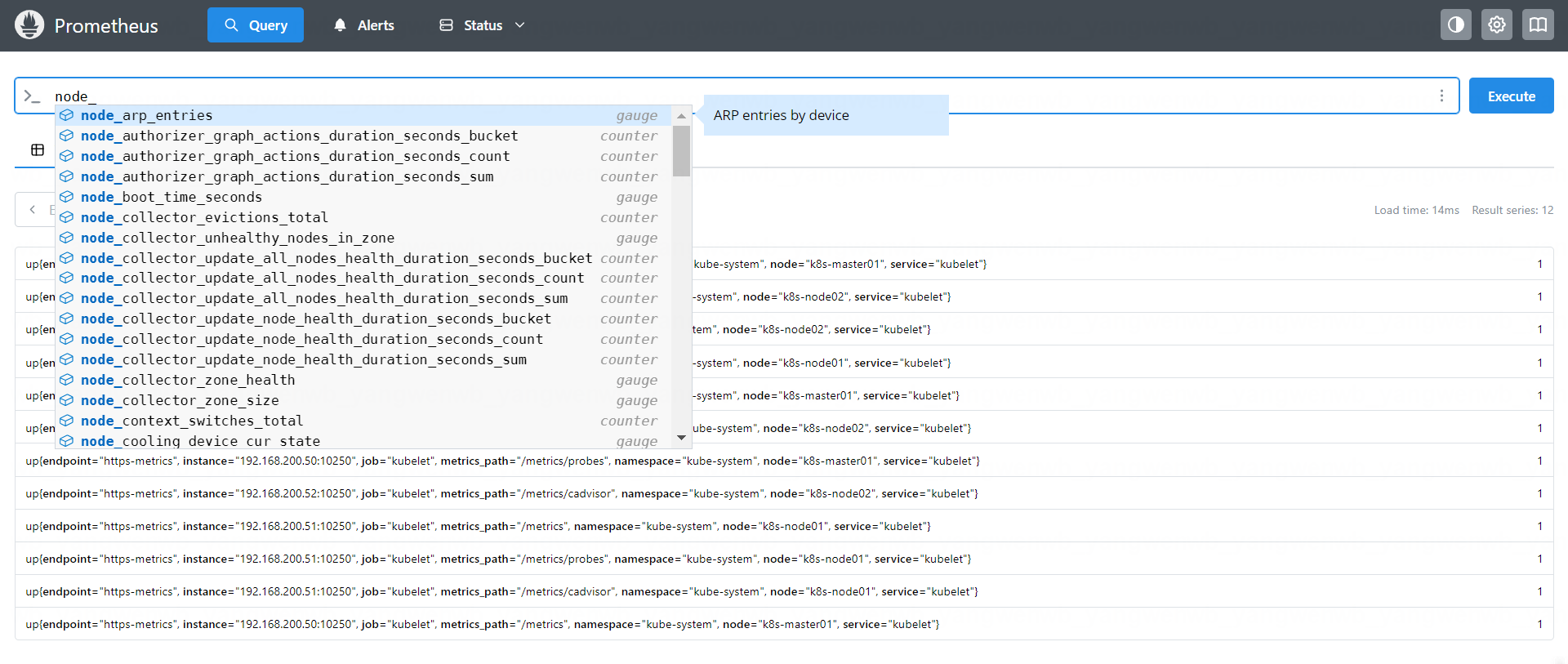
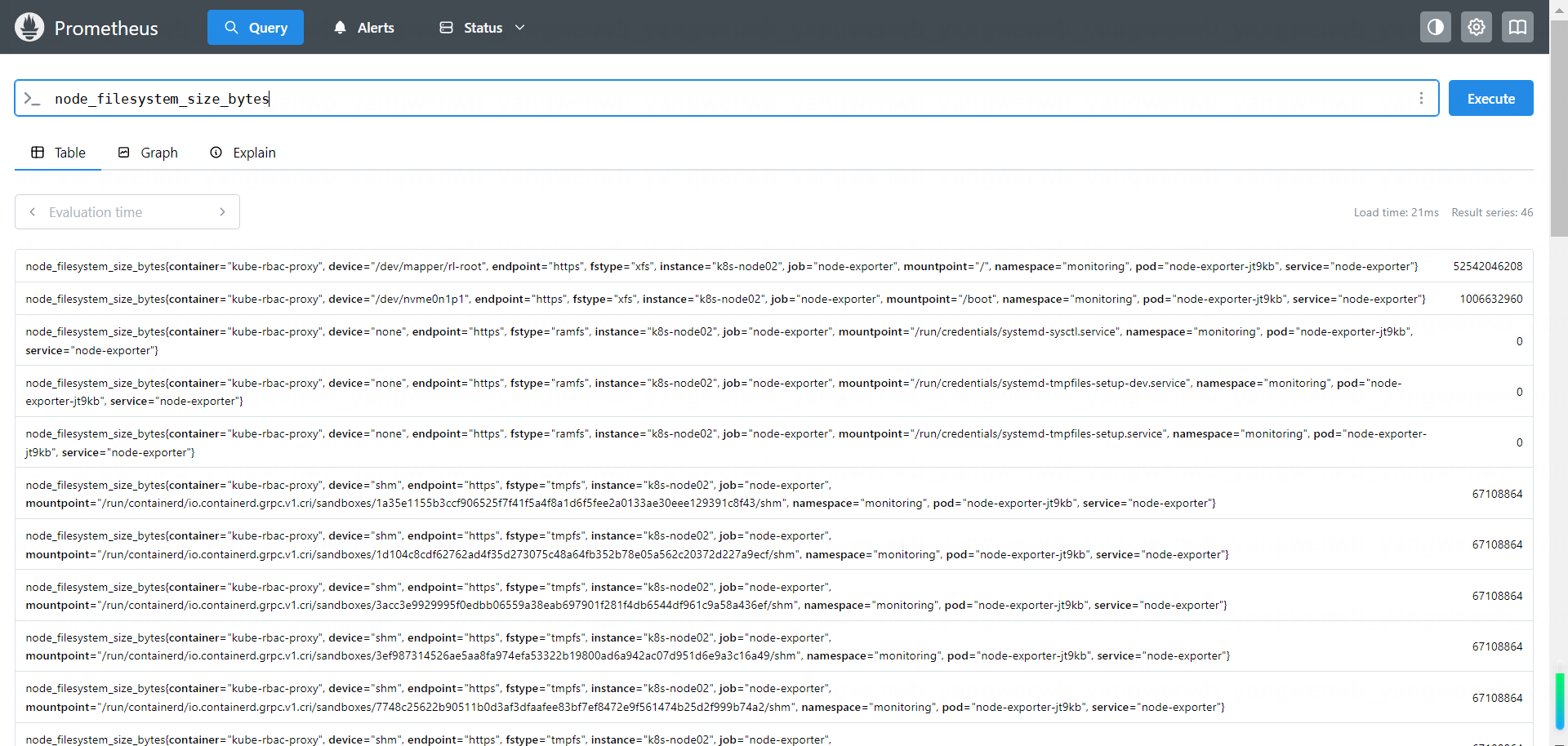
假 如 想 要 查 询 Kubernetes 集 群 中 每 个 宿 主 机 的 磁 盘 总 量 , 可 以 使 用node_filesystem_size_bytes
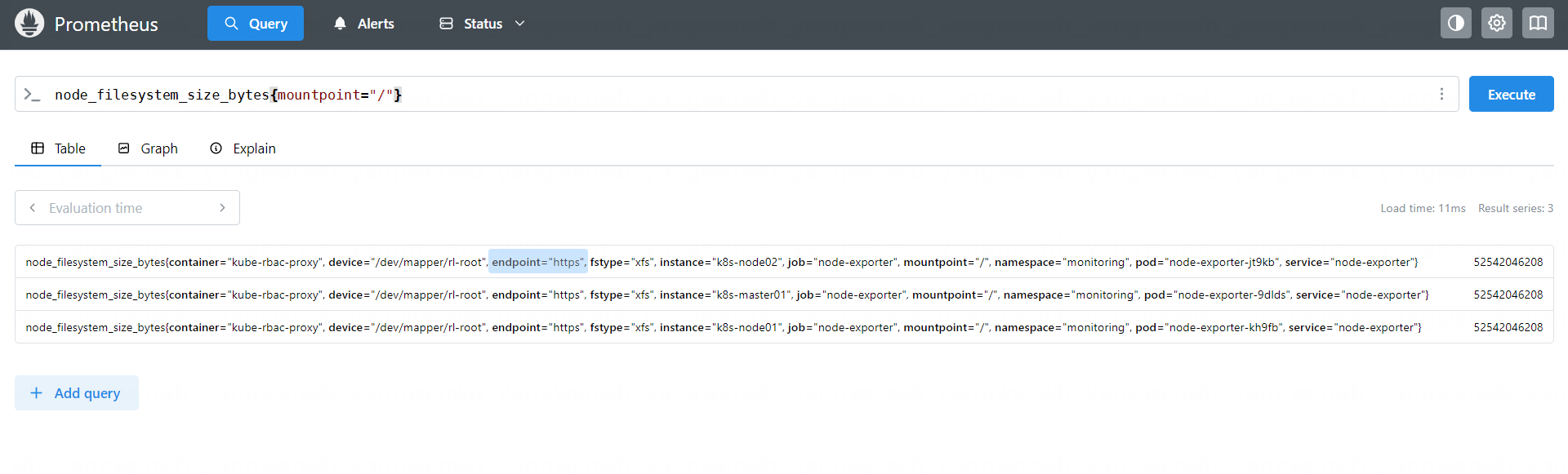
查询指定分区大小 node_filesystem_size_bytes{mountpoint="/"}
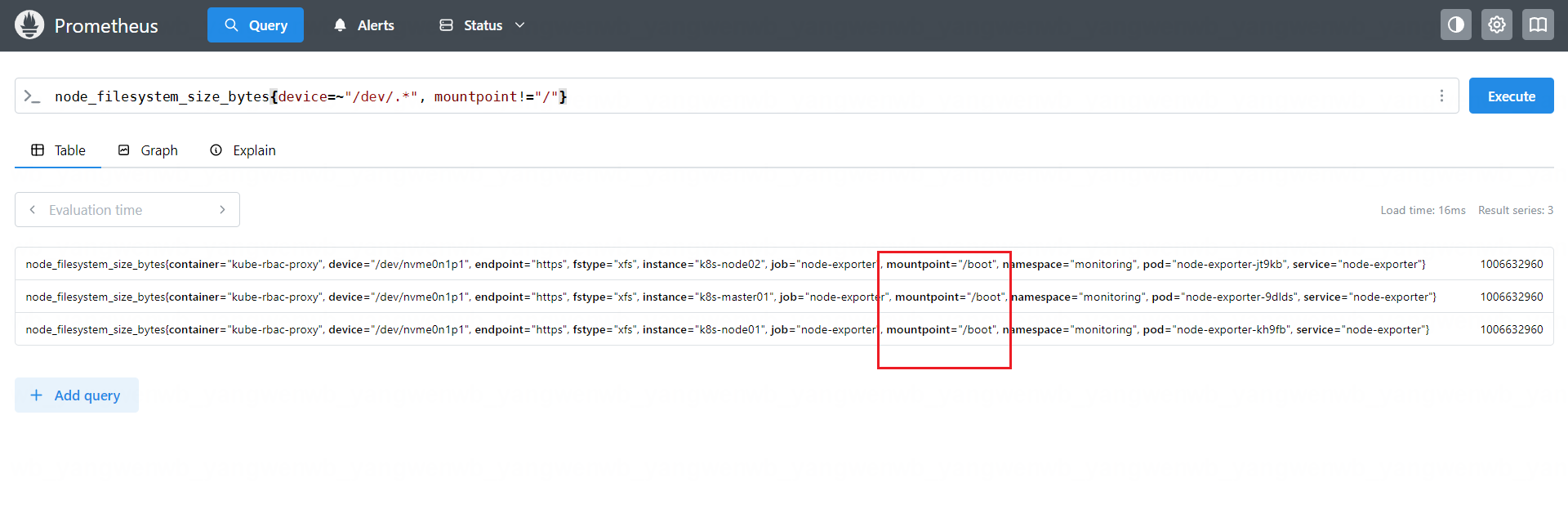
或者是查询分区不是/,且磁盘是/dev/开头的分区大小:
node_filesystem_size_bytes{device=~"/dev/.*", mountpoint!="/"}
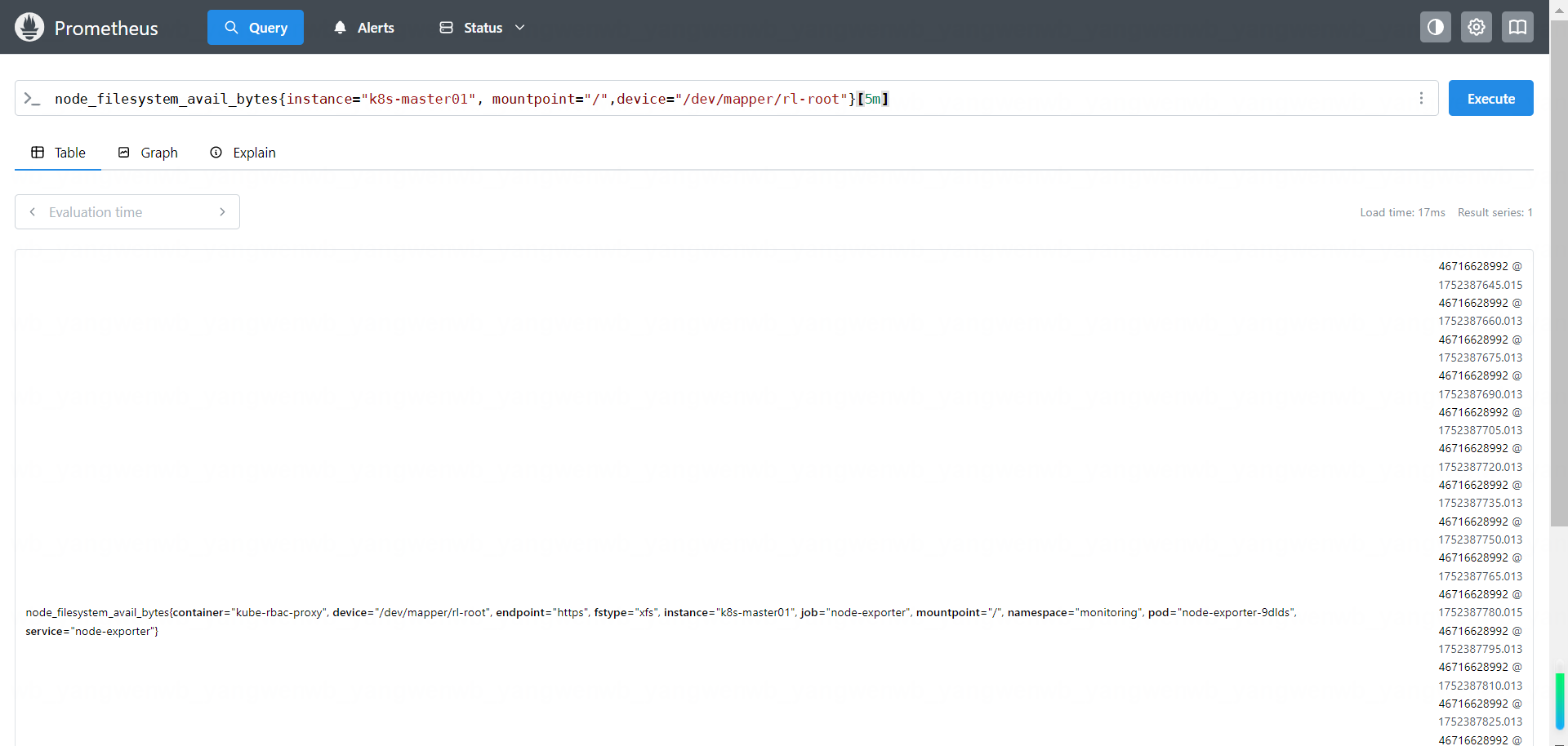
查询主机 k8s-master01 在最近 5 分钟可用的磁盘空间变化:
node_filesystem_avail_bytes{instance="k8s-master01", mountpoint="/",device="/dev/mapper/rl-root"}[5m]
目前支持的范围单位如下:
- s:秒
- m:分钟
- h:小时
- d:天
- w:周
- y:年
查询 10 分钟之前磁盘可用空间,只需要指定 offset 参数即可:
node_filesystem_avail_bytes{instance="k8s-master01", mountpoint="/",device="/dev/mapper/rl-root"} offset 10m
查询 10 分钟之前,5 分钟区间的磁盘可用空间的变化:
node_filesystem_avail_bytes{instance="k8s-master01", mountpoint="/",device="/dev/mapper/rl-root"}[5m] offset 10m
6.2 PromQL 操作符
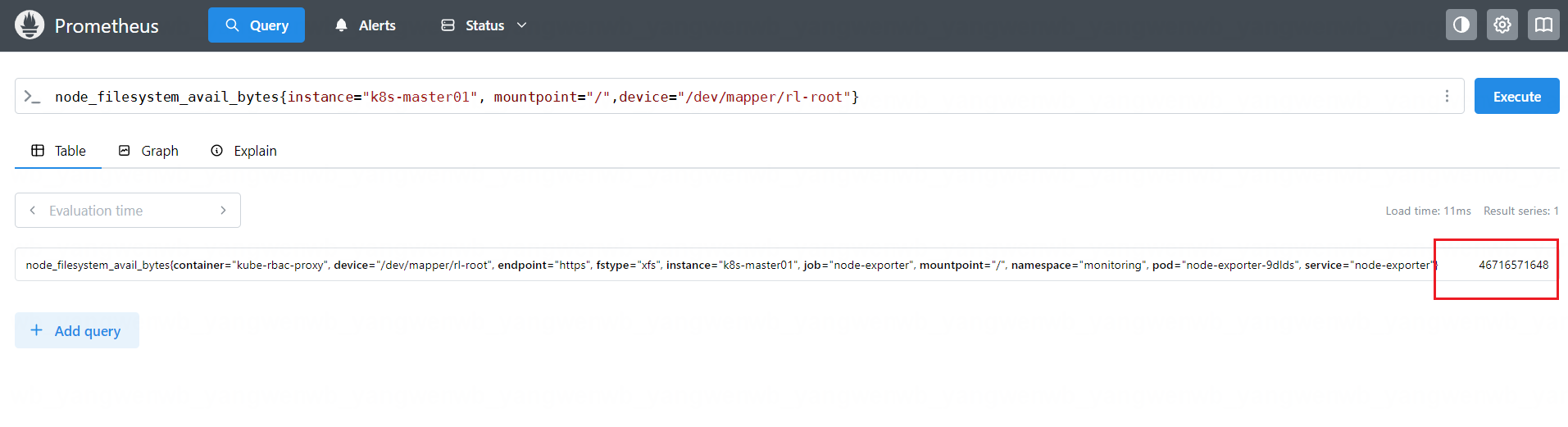
通过 PromQL 的语法查到了主机磁盘的空间数据,查询结果如下:(node_filesystem_avail_bytes{instance="k8s-master01", mountpoint="/",device="/dev/mapper/rl-root"})
可以通过以下命令将字节转换为 GB 或者 MB:
node_filesystem_avail_bytes{instance="k8s-master01", mountpoint="/",device="/dev/mapper/rl-root"} / 1024 / 1024 / 1024
也可以将 1024 / 1024 / 1024 改为(1024 ^ 3):
node_filesystem_avail_bytes{instance="k8s-master01", mountpoint="/",device="/dev/mapper/rl-root"} / (1024 ^ 3)
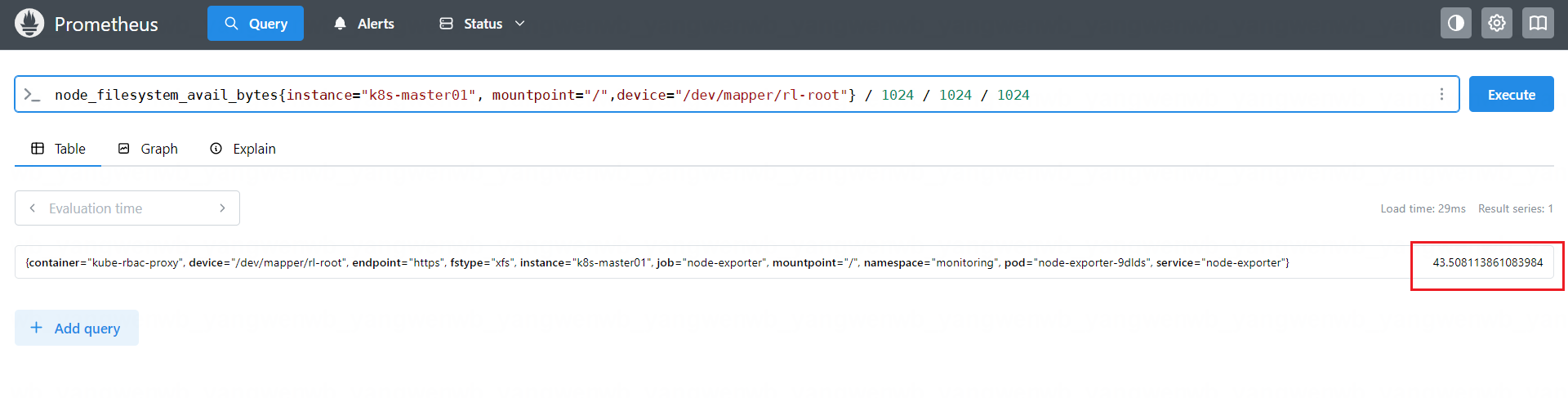
# 此时可以在宿主机上比对数据是否正确:
[root@k8s-master01 ~]# df -hT | grep /dev/mapper/rl-root
/dev/mapper/rl-root xfs 49G 5.5G 44G 12% /
上述使用的“/”为数学运算的“除”,“^”为幂运算,同时也支持如下运算符:
- +: 加
- -: 减
- *: 乘
- /: 除
- ^: 幂运算
- %: 求余
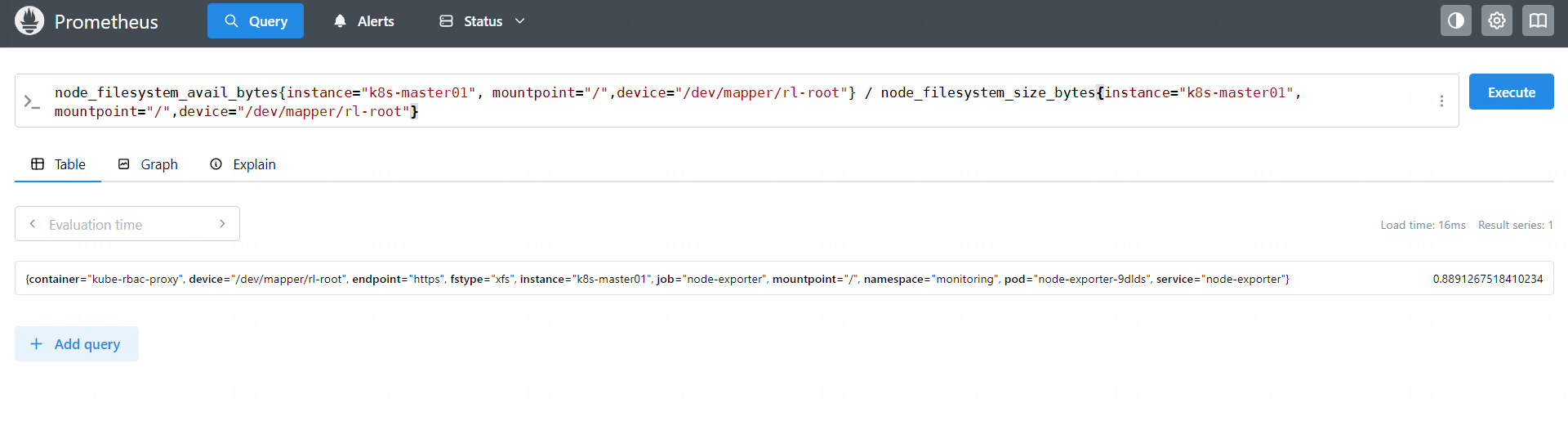
查询 k8s-master01 根区分磁盘可用率,可以通过如下指令进行计算:
node_filesystem_avail_bytes{instance="k8s-master01", mountpoint="/",device="/dev/mapper/rl-root"} / node_filesystem_size_bytes{instance="k8s-master01", mountpoint="/",device="/dev/mapper/rl-root"}
查询所有主机根分区的可用率:
node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"}
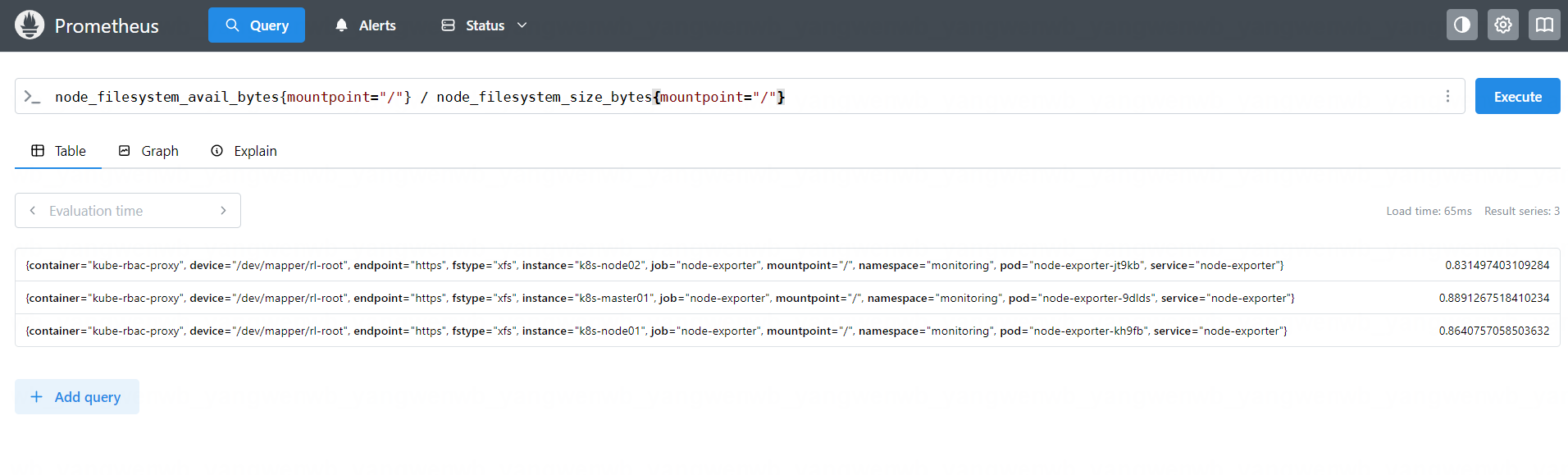
也可以将结果乘以 100 直接得到百分比:
(node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"} ) * 100
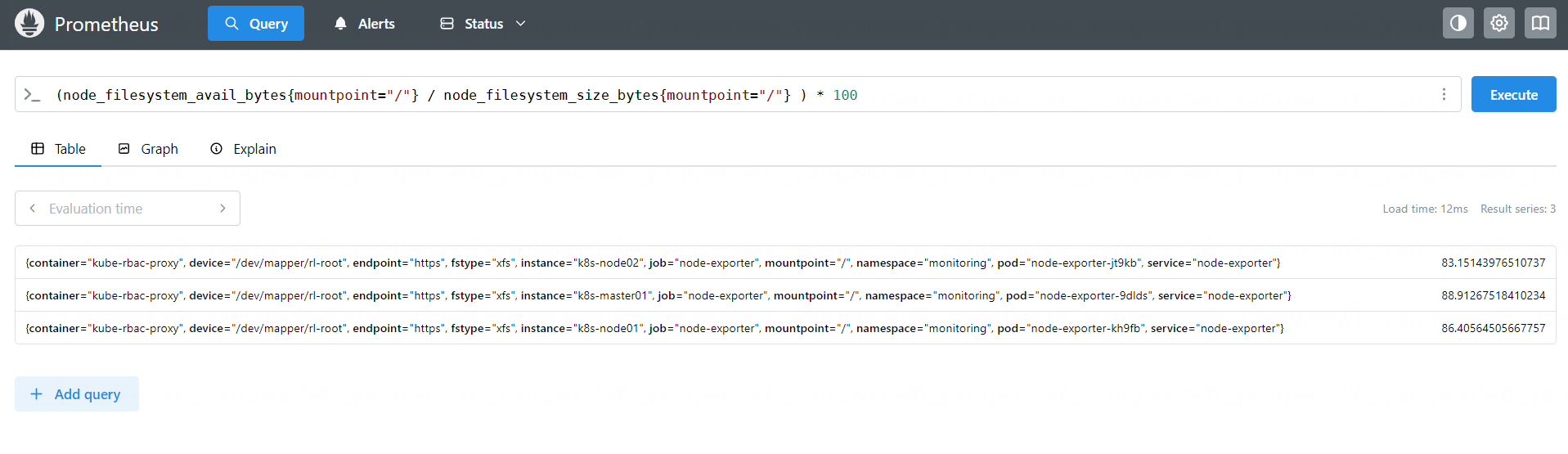
找到集群中根分区空间可用率大于 60%的主机:
(node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"} ) * 100 > 85
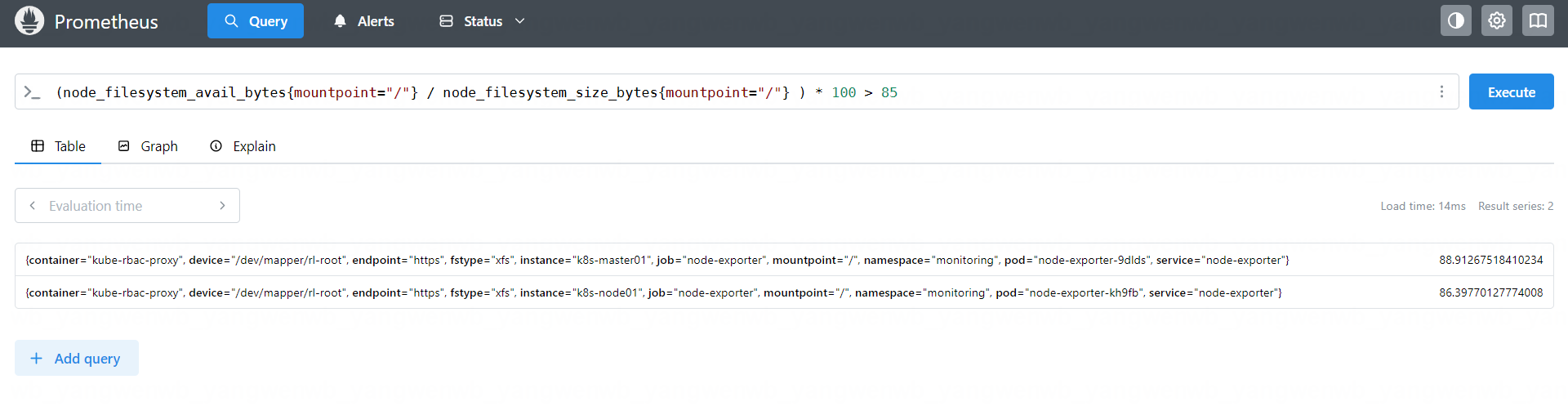
PromQL 也支持如下判断:
- ==: (相等)
- != :(不相等)
:(大于)
- < :(小于)
= :(大于等于)
- <= :(小于等于)
磁盘可用率大于 30%小于等于 60%的主机:
30 < (node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"} ) * 100 <= 60
也可以用 and 进行联合查询:
(node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"} ) * 100 > 30 and (node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"} ) * 100 <=60
除了 and 外,也支持 or 和 unless:
- and: 并且
- or :或者
- unless :排除
查询主机磁盘剩余空间,并且排除掉 shm 和 tmpfs 的磁盘:
node_filesystem_free_bytes unless node_filesystem_free_bytes{device!~"shm|tmpfs"}
当然,这个语法也可以直接写为:
node_filesystem_free_bytes{device!~"shm|tmpfs"}
6.3 PromQL 常用函数
使用 sum 函数统计当前监控目标所有主机根分区剩余的空间:
sum(node_filesystem_free_bytes{mountpoint="/"}) / 1024^3
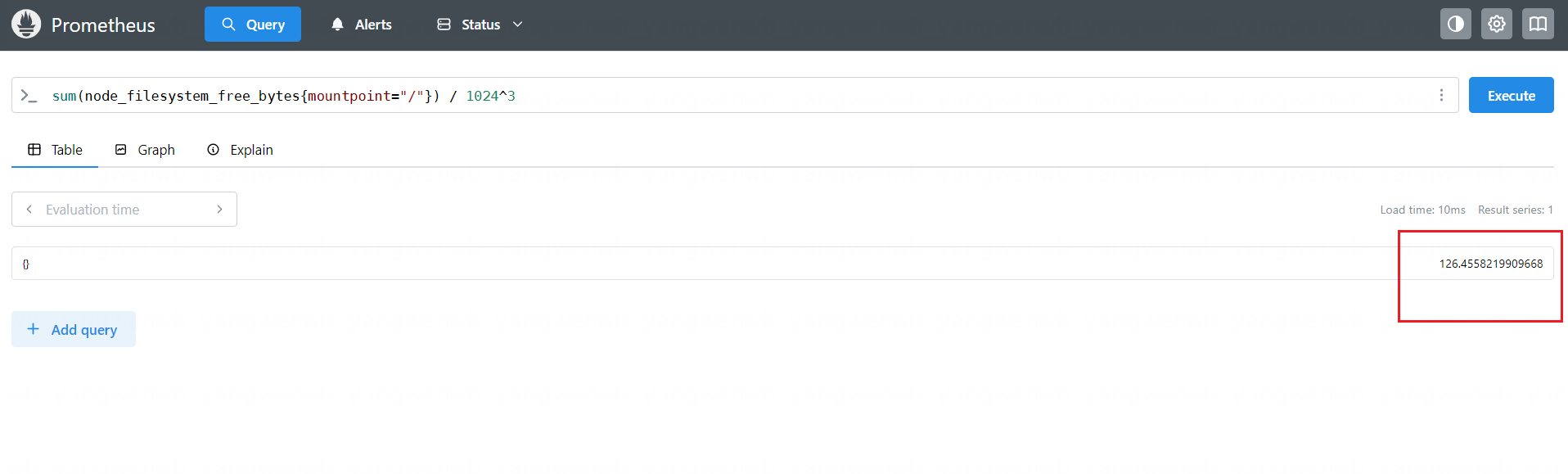
也可以用同样方式,计算所有的请求总量:
sum(prometheus_http_requests_total)
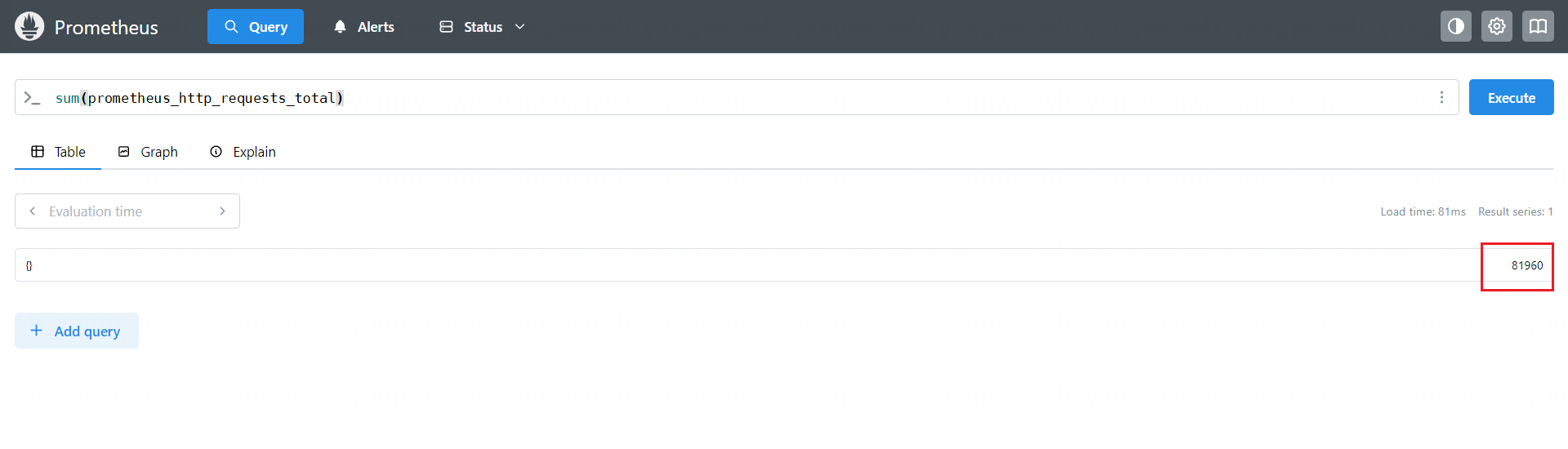
根据 handler 字段进行统计请求数据:
sum(prometheus_http_requests_total) by (handler)
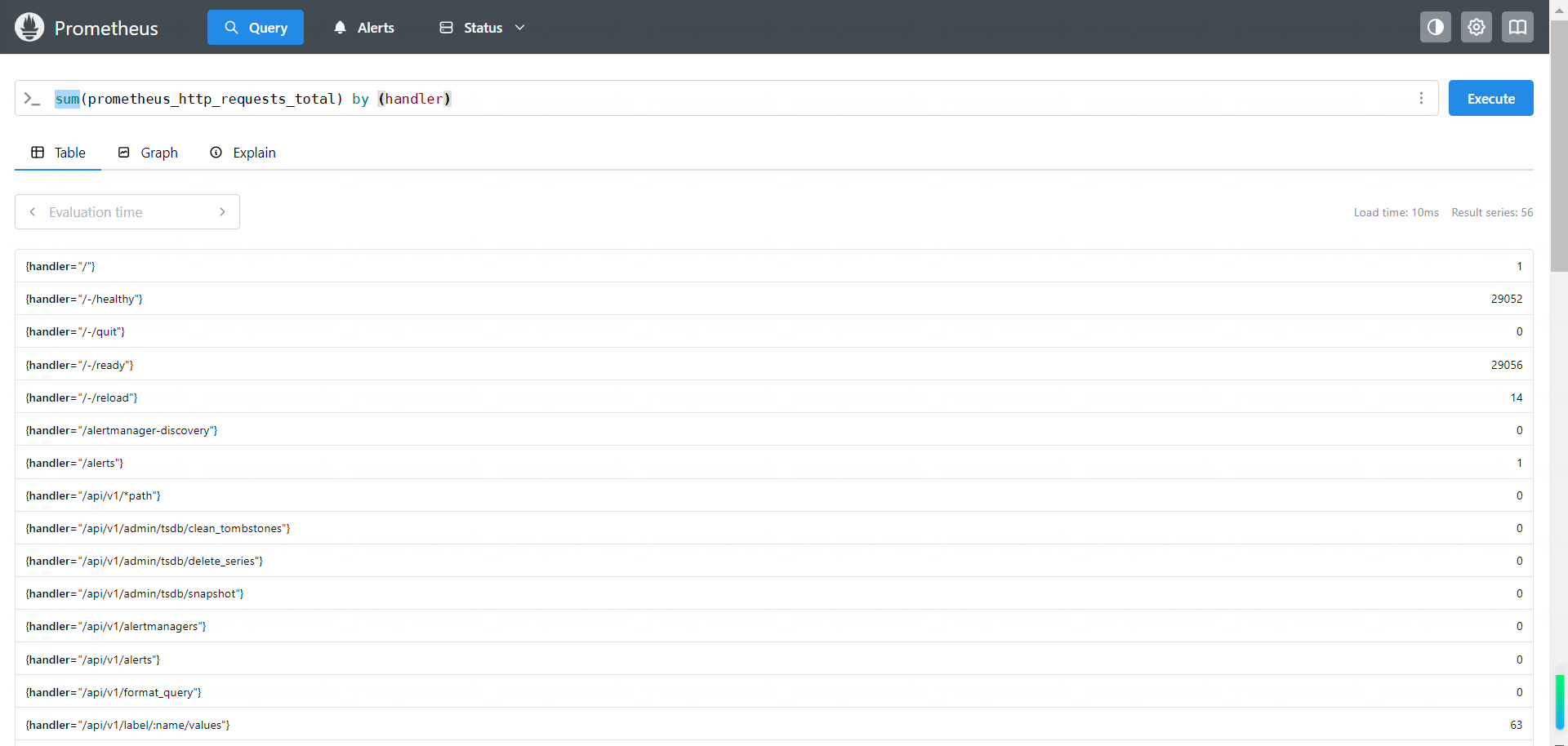
根据 instance 和 handler 两个指标进一步统计:
sum(prometheus_http_requests_total) by (instance, handler)
找到排名前五的数据:
topk(5, sum(prometheus_http_requests_total) by (instance, handler))
取最后三个数据:
bottomk(3, sum(prometheus_http_requests_total) by (instance, handler))
找出统计结果中最小的数据:
min(node_filesystem_avail_bytes{mountpoint="/"})
最大的数据:
max(node_filesystem_avail_bytes{mountpoint="/"})
平均值:
avg(node_filesystem_avail_bytes{mountpoint="/"})
四舍五入,向上取最接近的整数,2.79 → 3:
ceil(node_filesystem_files_free{mountpoint="/"} / 1024 / 1024)
向下取整数, 2.79 → 2:
floor(node_filesystem_files_free{mountpoint="/"} / 1024 / 1024)
对结果进行正向排序:
sort(sum(prometheus_http_requests_total) by (handler, instance))
对结果进行逆向排序:
sort_desc(sum(prometheus_http_requests_total) by (handler, instance))
函数 predict_linear 可以用于预测分析和预测性告警,比如可以根据一天的数据,预测 4 个小时后,磁盘分区的空间会不会小于 0:
predict_linear(node_filesystem_files_free{mountpoint="/"}[1d], 4*3600) < 0
除了上述的函数,还有几个比较重要的函数,比如 increase、rate、irate。其中 increase 是计算在一段时间范围内数据的增长(只能计算 count 类型的数据),rate 和 irate 是计算平均增长率和瞬时增长率。
比如查询某个请求在 1 小时的时间增长了多少:
increase(prometheus_http_requests_total{handler="/-/healthy"}[1h])
将 1h 增长的数量除以该时间即为增长率:
increase(prometheus_http_requests_total{handler="/-/healthy"}[1h]) / 3600
相对于 increase,rate 可以直接计算出某个指标在给定时间范围内的增长率,比如还是计算 1h 的增长率,可以用 rate 函数进行计算:
rate(prometheus_http_requests_total{handler="/-/healthy"}[1h])
如果需要计算瞬时增长率,可以使用 irate(irate 是计算最接近当前时间的两个数据点之间的增长率,即瞬时增长率):
irate(prometheus_http_requests_total{handler="/-/healthy"}[1h])
7、Prometheus 告警实战
使用 Prometheus Operator 安装的 Prometheus 可以直接使用 PrometheusRule 配置监控告警规则,API 参考文档:
https://github.com/prometheus-operator/prometheusoperator/blob/main/Documentation/apireference/api.md#monitoring.coreos.com/v1.PrometheusRule
7.1 PrometheusRule
# 可以通过如下命令查看默认配置的告警策略:
[root@k8s-master01 ~]# kubectl get prometheusrule -n monitoring
NAME AGE
alertmanager-main-rules 22h
grafana-rules 22h
kube-prometheus-rules 22h
kube-state-metrics-rules 22h
kubernetes-monitoring-rules 22h
node-exporter-rules 22h
prometheus-k8s-prometheus-rules 22h
prometheus-operator-rules 22h
# 也可以通过-oyaml 查看某个 rules 的详细配置:
[root@k8s-master01 ~]# kubectl get prometheusrule -n monitoring node-exporter-rules -oyaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
....
spec:groups:- name: node-exporterrules:- alert: NodeFilesystemSpaceFillingUpannotations:description: Filesystem on {{ $labels.device }}, mounted on {{ $labels.mountpoint}}, at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% availablespace left and is filling up.runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodefilesystemspacefillingupsummary: Filesystem is predicted to run out of space within the next 24 hours.expr: |(node_filesystem_avail_bytes{job="node-exporter",fstype!="",mountpoint!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!="",mountpoint!=""} * 100 < 15andpredict_linear(node_filesystem_avail_bytes{job="node-exporter",fstype!="",mountpoint!=""}[6h], 24*60*60) < 0andnode_filesystem_readonly{job="node-exporter",fstype!="",mountpoint!=""} == 0)for: 1hlabels:severity: warning
....
- alert:告警策略的名称
- annotations:告警注释信息,一般写为告警信息
- expr:告警表达式
- for:评估等待时间,告警持续多久才会发送告警数据
- labels:告警的标签,用于告警的路由
7.2 告警实战:域名访问延迟及故障告警
假设需要对域名访问延迟进行监控,访问延迟大于 1 秒进行告警,此时可以创建一个 PrometheusRule 如下:
[root@k8s-master01 ~]# vim blackbox-rule.yaml
[root@k8s-master01 ~]# cat blackbox-rule.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:labels:app.kubernetes.io/component: exporterapp.kubernetes.io/name: blackbox-exporterprometheus: k8srole: alert-rulesname: blackboxnamespace: monitoring
spec:groups:- name: blackbox-exporterrules:- alert: DomainCannotAccessannotations:description: 域名:{{ $labels.instance }} 不可达summary: 域名探测失败expr: probe_success == 0for: 1mlabels:severity: criticaltype: blackbox- alert: DomainAccessDelayExceeds1sannotations:description: 域名:{{ $labels.instance }} 探测延迟大于 1 秒,当前延迟为:{{ $value }}summary: 域名探测,访问延迟超过 1 秒expr: sum(probe_http_duration_seconds{job=~"blackbox"}) by (instance) > 1 for: 1mlabels:severity: warningtype: blackbox[root@k8s-master01 ~]# kubectl create -f blackbox-rule.yaml
[root@k8s-master01 ~]# kubectl get -f blackbox-rule.yaml
NAME AGE
blackbox 49s
之后也可以在 Prometheus 的 Web UI 看到此规则:
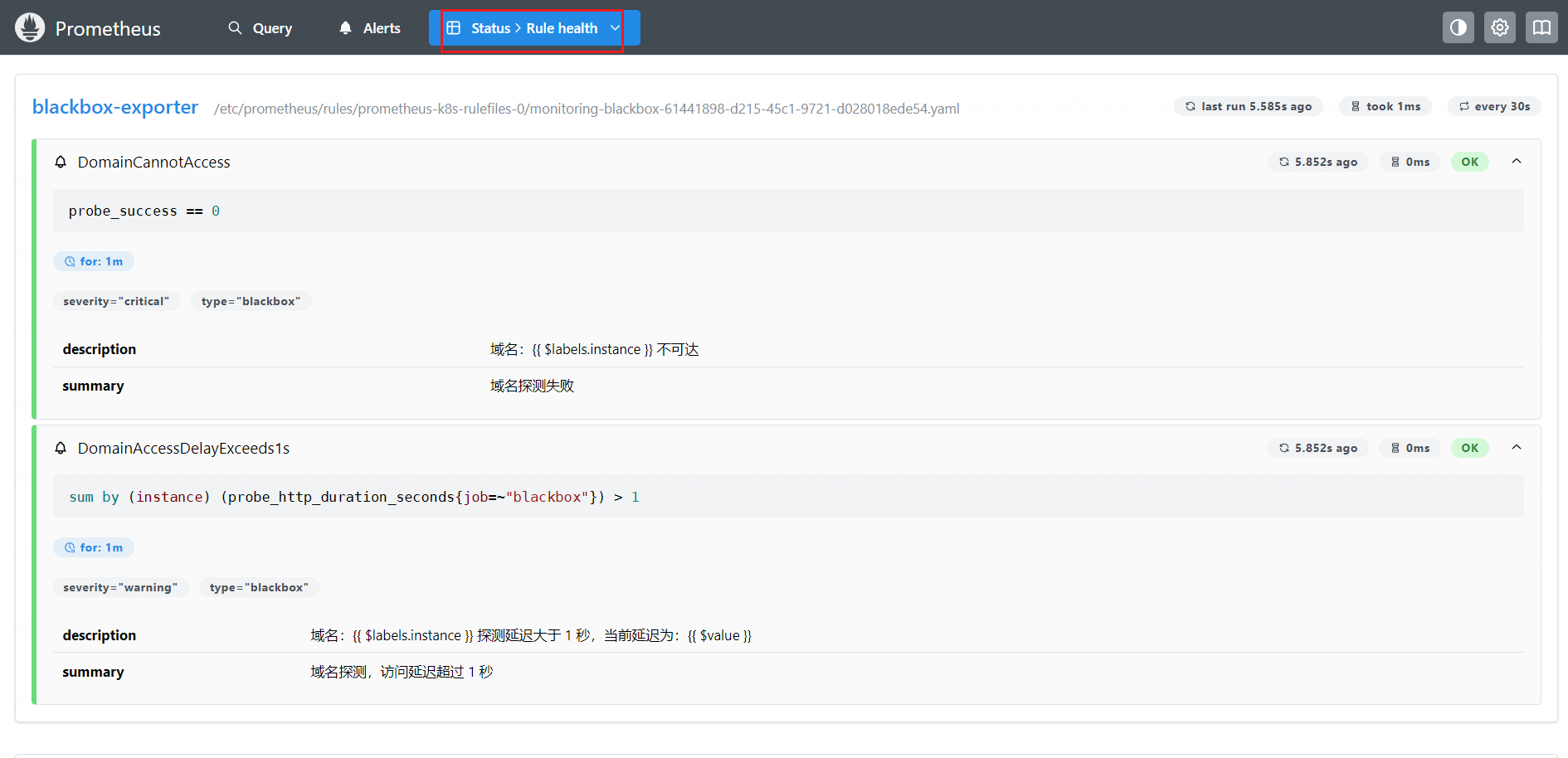
如果探测延迟有超过 1s 的域名或者不可达,就会触发告警,如图所示:
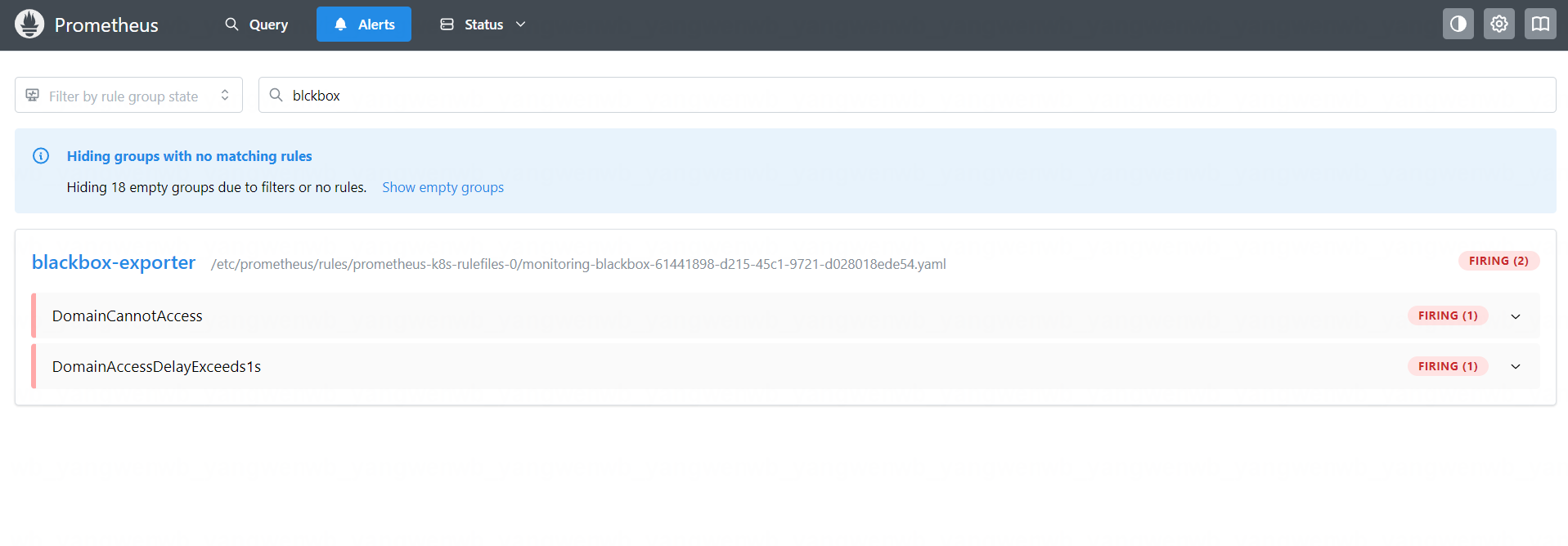
7.3 告警实战:应用服务活性探测告警
针对于基础组件也可以实现活性探测,比如 MySQL 和 Redis 监控,可以通过 up 指标进行监控:
[root@k8s-master01 ~]# vim basic-rule.yaml
[root@k8s-master01 ~]# cat basic-rule.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:labels:prometheus: k8srole: alert-rulesname: basicnamespace: monitoring
spec:groups:- name: mysqlrules:- alert: MySQLStatusannotations:description: 实例:{{ $labels.instance }} 故障summary: MySQL 服务宕机expr: mysql_up == 0for: 1mlabels:severity: criticaltype: basiccomponent: mysql- name: redisrules:- alert: RedisStatusannotations:description: 实例:{{ $labels.instance }} 故障summary: Redis 服务宕机expr: redis_up == 0for: 1mlabels:severity: criticaltype: basiccomponent: redis[root@k8s-master01 ~]# kubectl create -f basic-rule.yaml
[root@k8s-master01 ~]# kubectl get -f basic-rule.yaml
NAME AGE
basic 14s
之后也可以在 Prometheus 的 Web UI 看到此规则:
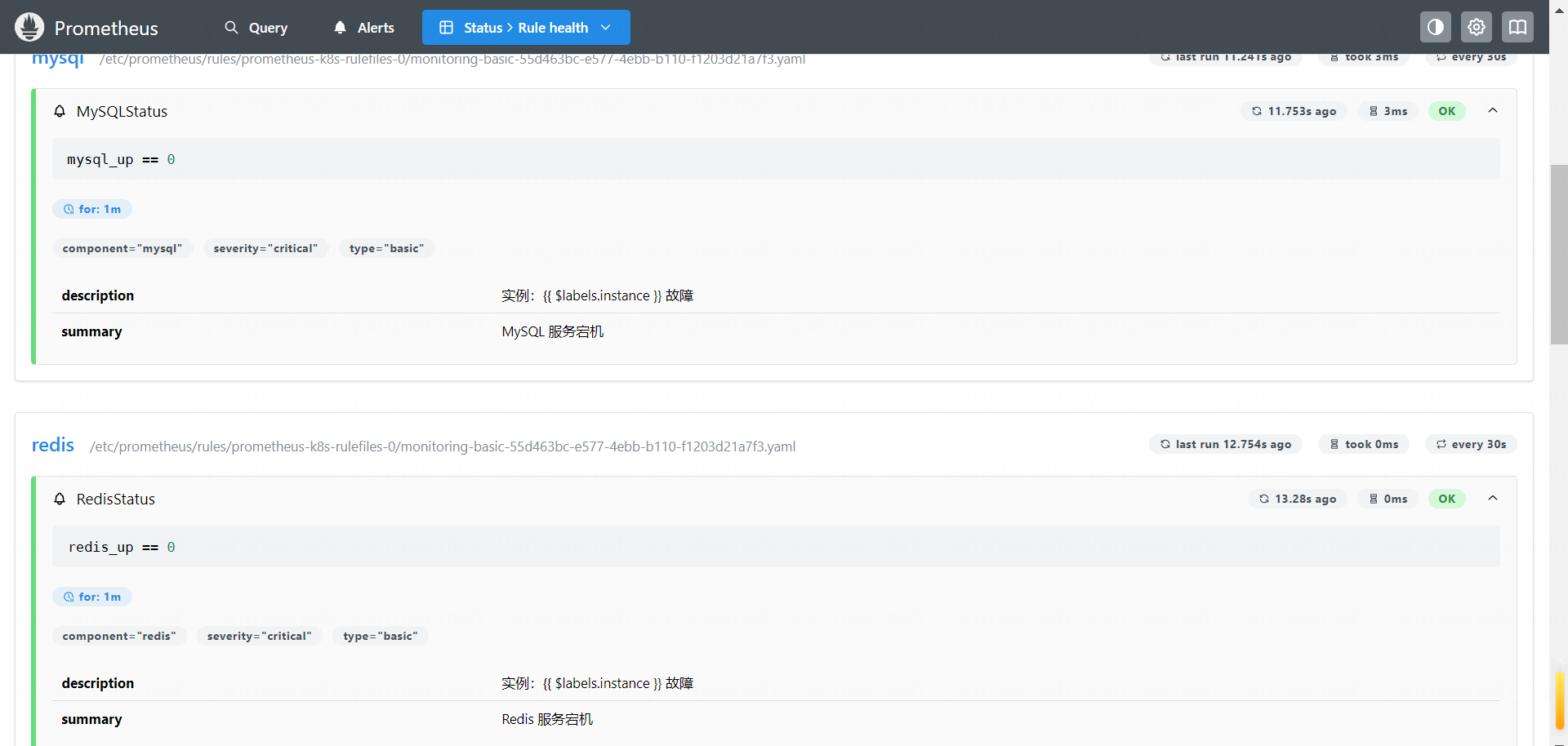
假如某个服务宕机后,就会产生告警:
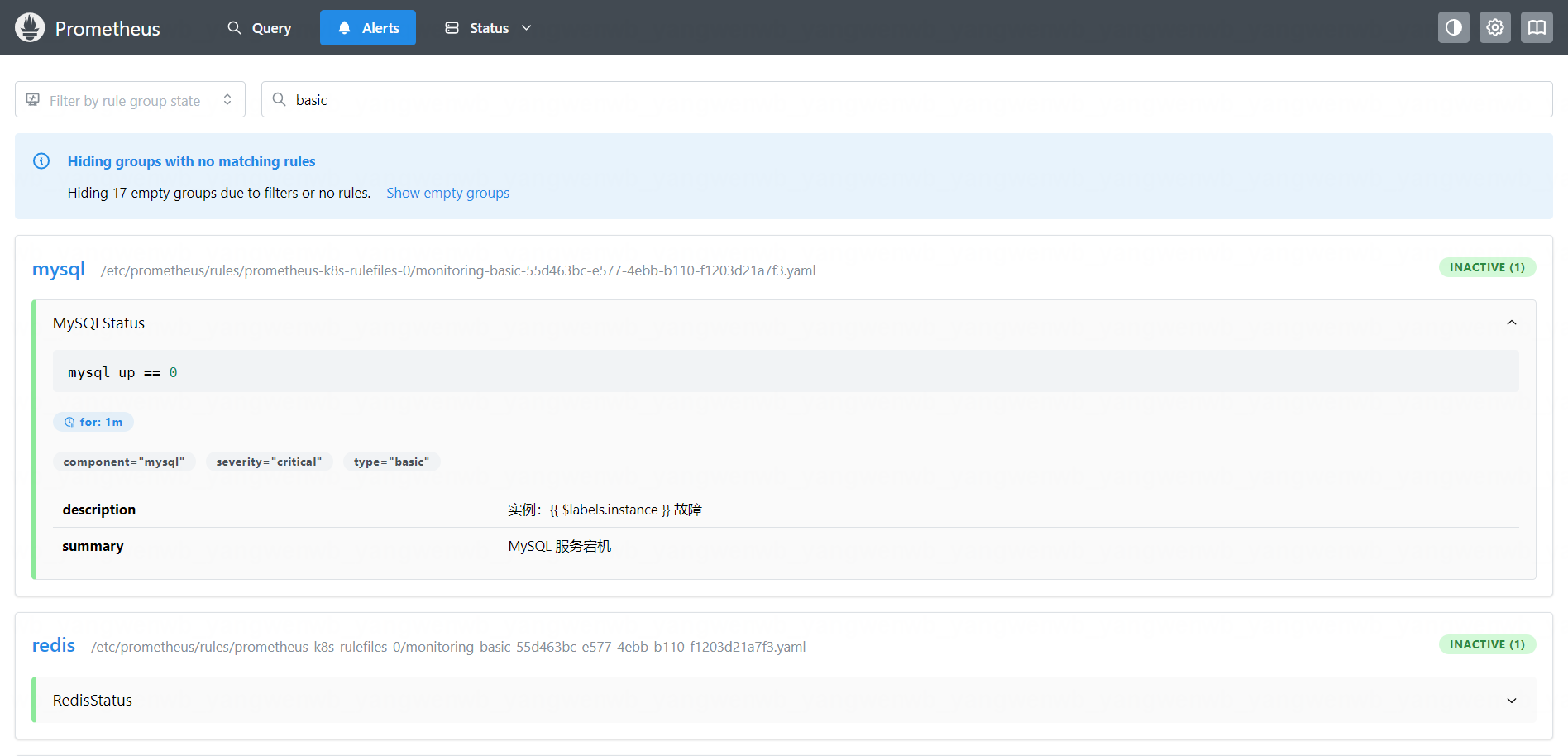
7.4 告警实战:基于 Grafana 图标告警
有很多监控语法可能比较复杂,此时可以借助现有的 Dashboard 编写 PrometheusRule。
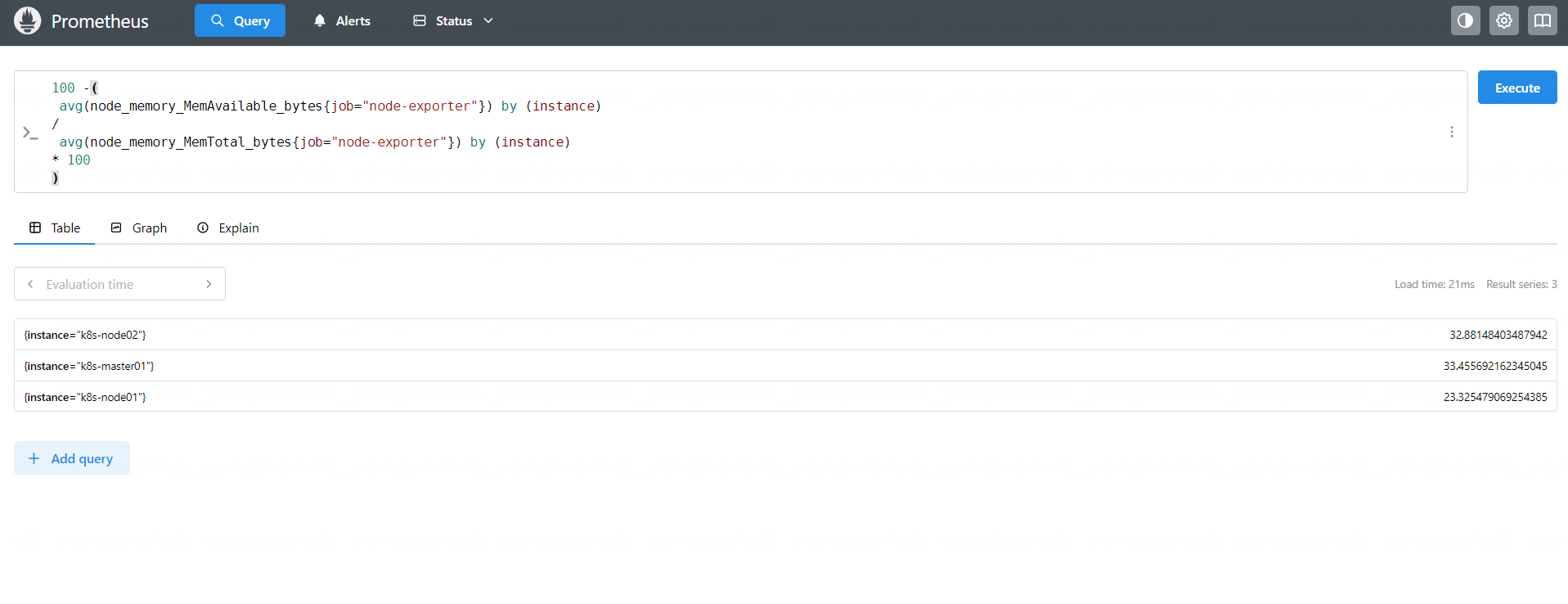
比如想要实现主机内存的监控,可以先从面板获取 PromQL 语法:
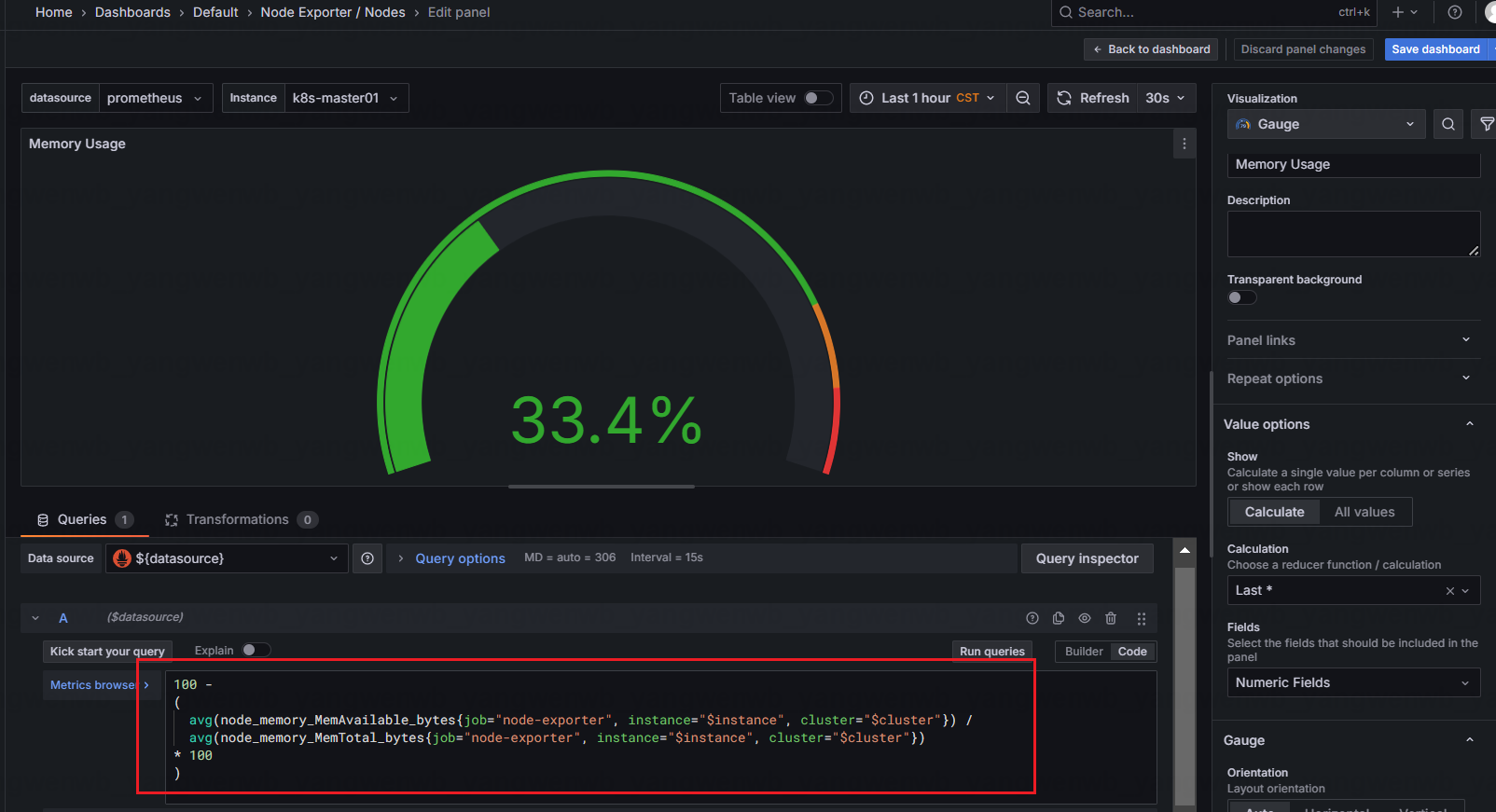
100 -(avg(node_memory_MemAvailable_bytes{job="node-exporter"}) by (instance)
/avg(node_memory_MemTotal_bytes{job="node-exporter"}) by (instance)
* 100
) > 85
可以去 Prometheus 的 Web UI 验证此规则:
# 来创建 PrometheusRule
[root@k8s-master01 ~]# vim node-rule.yaml
[root@k8s-master01 ~]# cat node-rule.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:labels:app.kubernetes.io/component: exporterapp.kubernetes.io/name: nodeprometheus: k8srole: alert-rulesname: nodenamespace: monitoring
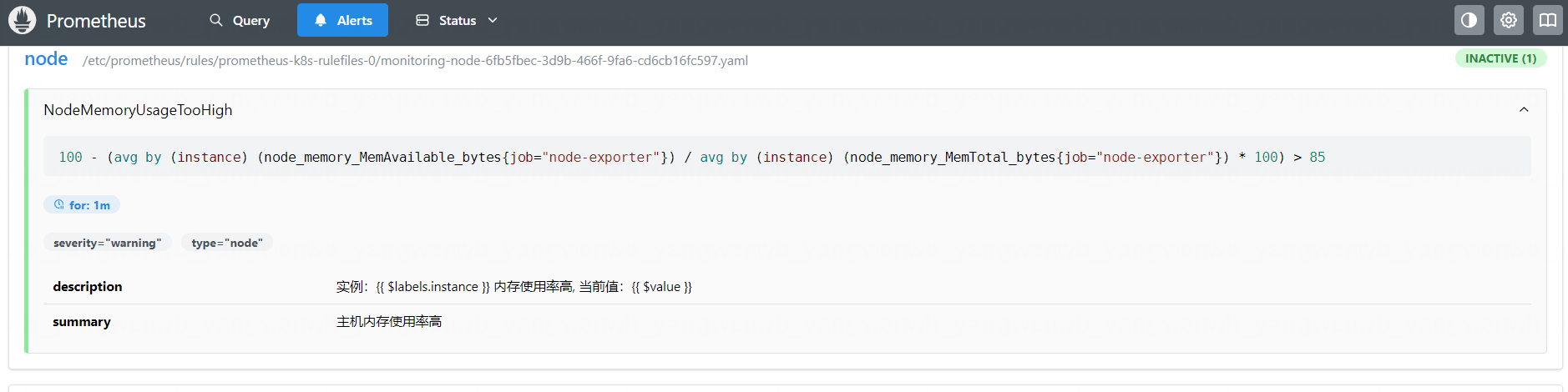
spec:groups:- name: noderules:- alert: NodeMemoryUsageTooHighannotations:description: 实例:{{ $labels.instance }} 内存使用率高, 当前值:{{ $value }}summary: 主机内存使用率高expr: |100 -(avg(node_memory_MemAvailable_bytes{job="node-exporter"}) by (instance) /avg(node_memory_MemTotal_bytes{job="node-exporter"}) by (instance)* 100) > 85for: 1mlabels:severity: warningtype: node[root@k8s-master01 ~]# kubectl create -f node-rule.yaml
[root@k8s-master01 ~]# kubectl get -f node-rule.yaml
NAME AGE
node 6s
创建后即可查到该监控信息:
8、Alertmanager 告警入门
配置示例:
https://github.com/prometheus/alertmanager/blob/main/doc/examples/simple.yml
参考文件:https://prometheus-operator.dev/docs/developer/alerting/
8.1 Alertmanager 外部网络访问配置
# 修改网络模式为NodePort
[root@k8s-master01 ~]# vim kube-prometheus/manifests/alertmanager-service.yaml
[root@k8s-master01 ~]# cat kube-prometheus/manifests/alertmanager-service.yaml
....sessionAffinity: ClientIPtype: NodePort# 重新加载配置
[root@k8s-master01 ~]# kubectl replace -f kube-prometheus/manifests/alertmanager-service.yaml [root@k8s-master01 ~]# kubectl get -f kube-prometheus/manifests/alertmanager-service.yaml
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main NodePort 10.100.50.64 <none> 9093:32573/TCP,8080:32767/TCP 23h
任意节点+32573 可以查看一些配置信息
8.2 Alertmanager 配置文件解析
global:resolve_timeout: 5m
....
route:receiver: Defaultgroup_by:- namespace- job- alertnamegroup_wait: 30sgroup_interval: 5mrepeat_interval: 10mroutes:- matchers:- service=~"foo1|foo2|baz"receiver: team-X-mailsroutes:- matchers:- severity="critical"receiver: team-X-pager
inhibit_rules:
- source_matchers: [severity="critical"]target_matchers: [severity=~"warning|info"]equal: [alertname, cluster, service]
receivers:
- name: Defaultemail_configs:- send_resolved: trueto: kubernetes_guide@163.comfrom: kubernetes_guide@163.comhello: 163.comsmarthost: smtp.163.com:465auth_username: kubernetes_guide@163.comauth_password: <secret>headers:From: kubernetes_guide@163.comSubject: '{{ template "email.default.subject" . }}'To: kubernetes_guide@163.comhtml: '{{ template "email.default.html" . }}'require_tls: false
- name: Watchdog
- name: Critical
templates: []
Alertmanager 的配置主要分为五大块:
- Global:全局配置,主要用来配置一些通用的配置,比如邮件通知的账号、密码、SMTP服务器、微信告警等。Global 块配置下的配置选项在本配置文件内的所有配置项下可见,但是文件内其它位置的子配置可以覆盖 Global 配置;
- Templates:用于放置自定义模板的位置;
- Route:告警路由配置,用于告警信息的分组路由,可以将不同分组的告警发送给不同的收件人。比如将数据库告警发送给 DBA,服务器告警发送给 OPS;
- Inhibit_rules:告警抑制,主要用于减少告警的次数,防止“告警轰炸”。比如某个宿主机宕机,可能会引起容器重建、漂移、服务不可用等一系列问题,如果每个异常均有告警,会一次性发送很多告警,造成告警轰炸,并且也会干扰定位问题的思路,所以可以使用告警抑制,屏蔽由宿主机宕机引来的其他问题,只发送宿主机宕机的消息即可;
- Receivers:告警收件人配置,每个 receiver 都有一个名字,经过 route 分组并且路由后需要指定一个 receiver,就是在此位置配置的。
8.3 Alertmanager 路由规则
# 路由规则配置详解:
route:receiver: Defaultgroup_by:- namespace- job- alertnameroutes:- matchers:- owner="team-X"receiver: team-X-pagercontinue: true- matchers:- owner="team-Y"receiver: team-Y-pager group_wait: 30sgroup_interval: 5mrepeat_interval: 10m
- receiver:告警的通知目标,需要和 receivers 配置中 name 进行匹配。需要注意的是 route.routes 下也可以有 receiver 配置,优先级高于 route.receiver 配置的默认接收人,当告警没有匹配到子路由时,会使用 route.receiver 进行通知,比如上述配置中的Default;
- group_by:分组配置,值类型为列表。比如配置成[‘job’,‘severity’],代表告警信息包含job 和 severity 标签的会进行分组,且标签的 key 和 value 都相同才会被分到一组;
- group_wait:告警通知等待,值类型为字符串。若一组新的告警产生,则会等 group_wait 后再发送通知,该功能主要用于当告警在很短时间内接连产生时,在 group_wait 内合并为单一的告警后再发送,防止告警过多,默认值 30s;
- group_interval:同一组告警通知后,如果有新的告警添加到该组中,再次发送告警通知的时间,默认值为 5m;
- repeat_interval:如果一条告警通知已成功发送,且在间隔 repeat_interval 后,该告警仍然未被设置为 resolved,则会再次发送该告警通知,默认值 4h;
- routes:子路由树,用于详细的告警路由
- matchers:匹配规则
- receiver:局部收件人
- continue:决定匹配到该路由后,是否继续后续匹配。默认为 false,即匹配到后停止继续匹配
8.4 Alertmanager 邮件通知配置
8.4.1 邮箱配置
邮件通知需要先开启邮箱服务的 IMAP/SMTP 服务,以 163 为例:
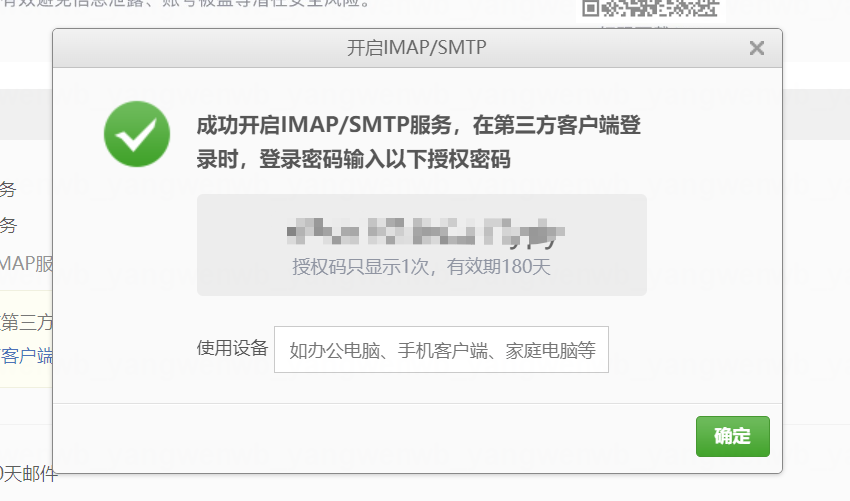
之后找到 Alertmanager 的配置文件,添加邮箱服务配置:
[root@k8s-master01 ~]# vim kube-prometheus/manifests/alertmanager-secret.yaml
[root@k8s-master01 ~]# cat kube-prometheus/manifests/alertmanager-secret.yaml
...."global":"resolve_timeout": "5m"smtp_from: "xxx@163.com" # 改成你实际的163邮箱地址smtp_smarthost: "smtp.163.com:465"smtp_hello: "163.com"smtp_auth_username: "xxx@163.com" # 改成你实际的163邮箱地址smtp_auth_password: "BPkiv32hGkvHZypy" # 邮箱授权码smtp_require_tls: false
...."receivers":- "name": "Default""email_configs": # 代表使用邮件通知- to: "xxx@163.com" # 收件人,可以配置多个,逗号隔开send_resolved: true # 告警如果被解决是否发送解决通知
....# 将更改好的 Alertmanager 配置加载到 Alertmanager:
[root@k8s-master01 ~]# kubectl replace -f kube-prometheus/manifests/alertmanager-secret.yaml
稍等几分钟即可在 Alertmanager 的 Web 界面看到更改的配置(Status):
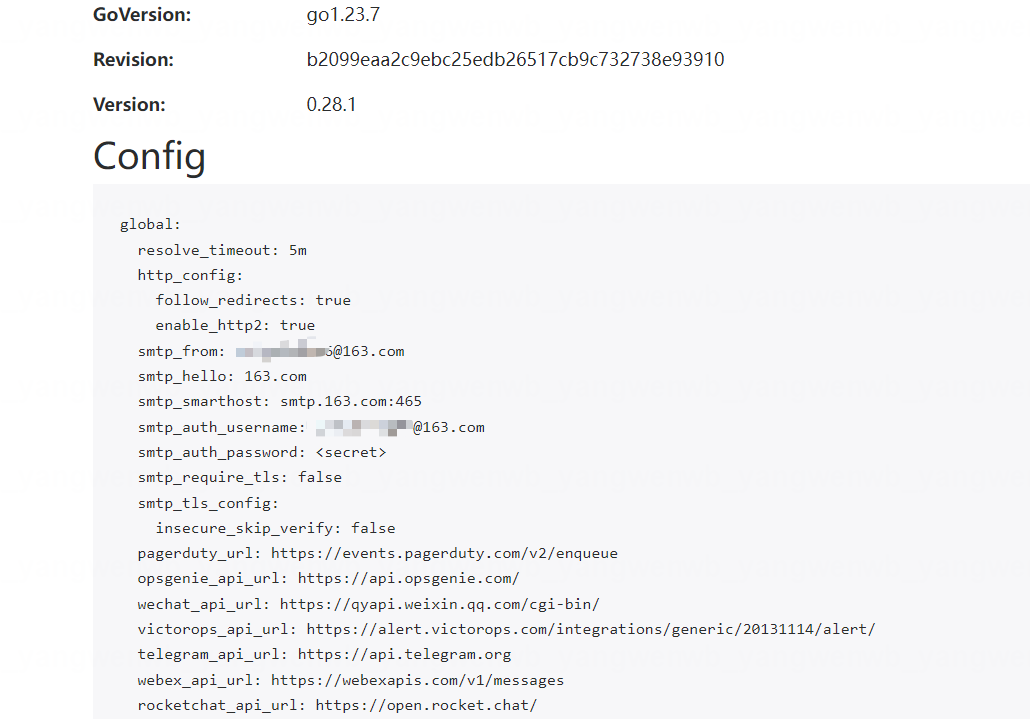
也可以查看分组信息
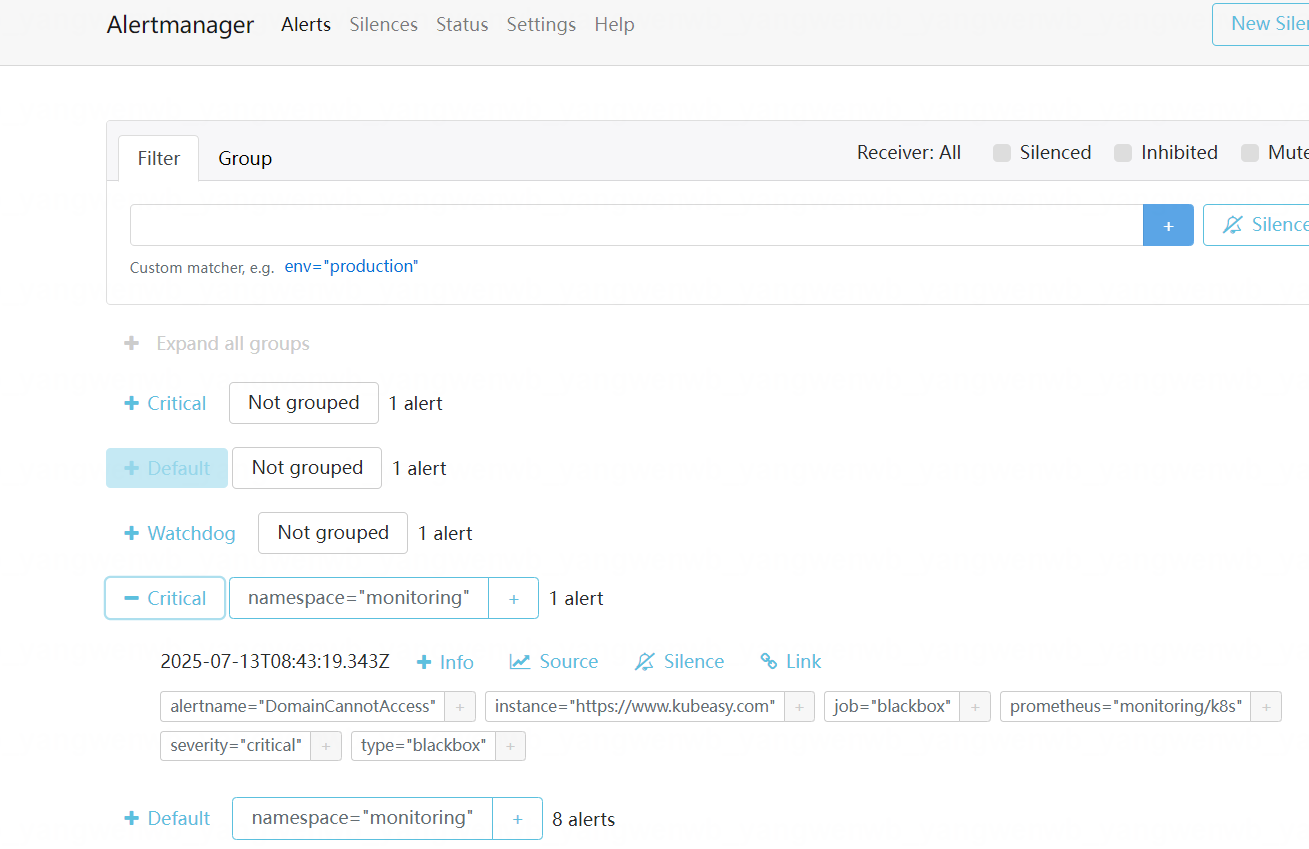
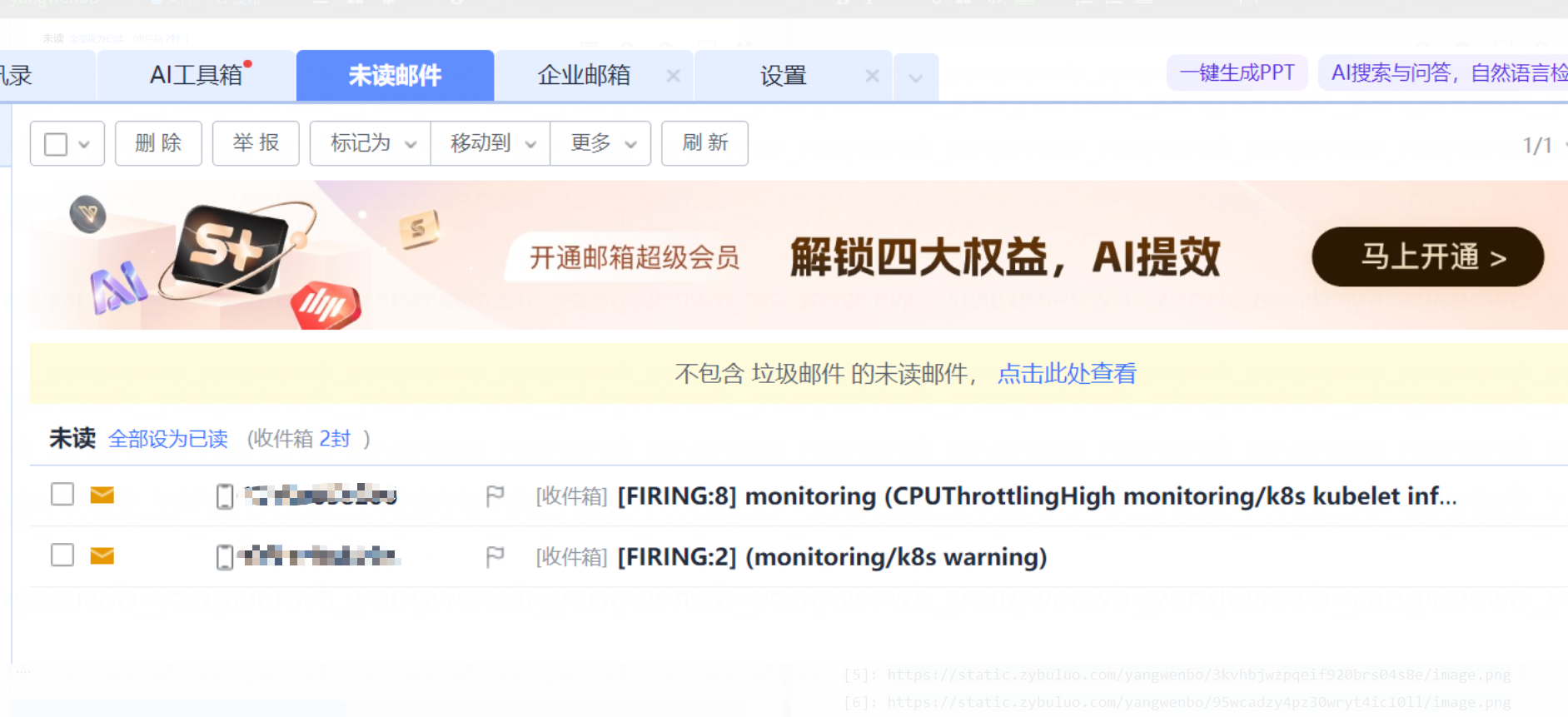
此时 Default receiver 配置的邮箱会收到两者的告警信息,如下所示:
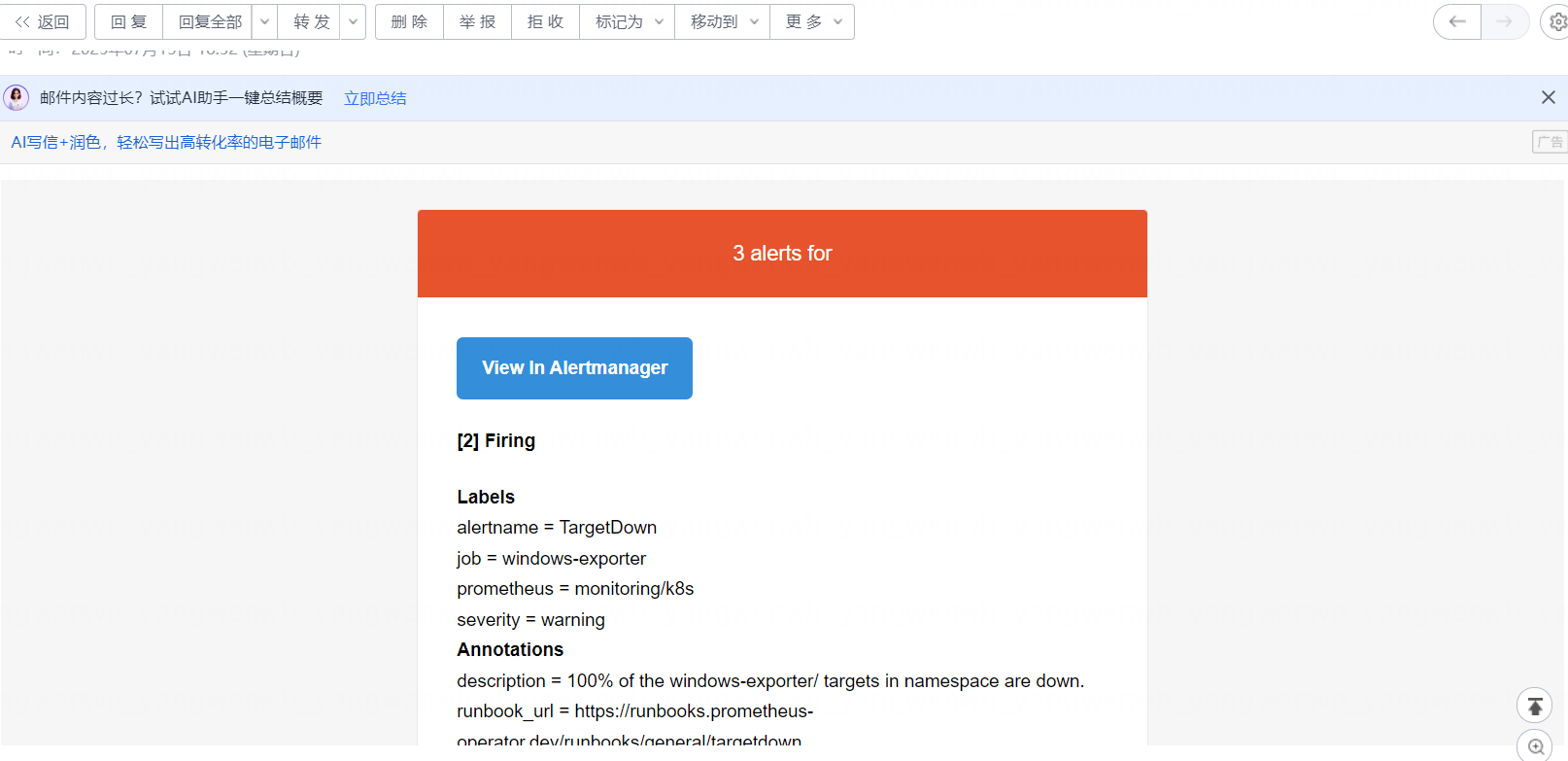
8.4.2 AlertmanagerConfig 实现邮件告警
如果需要将自定义的告警发送至邮件,可以使用 AlertmanagerConfig 进行单独配置,比如把 Blackbox 的告警发送到邮箱。
# 首先更改 Alertmanager 的配置,添加 AlertmanagerConfig 相关配置
[root@k8s-master01 ~]# vim kube-prometheus/manifests/alertmanager-alertmanager.yaml
[root@k8s-master01 ~]# cat kube-prometheus/manifests/alertmanager-alertmanager.yaml
....version: 0.28.1alertmanagerConfigSelector:matchLabels:alertmanagerConfig: example# 重新加载配置
[root@k8s-master01 ~]# kubectl replace -f kube-prometheus/manifests/alertmanager-alertmanager.yaml
# 接下来添加 AlertmanagerConfig:
[root@k8s-master01 ~]# vim blackbox-alertmanagerconfig.yaml
[root@k8s-master01 ~]# cat blackbox-alertmanagerconfig.yaml
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
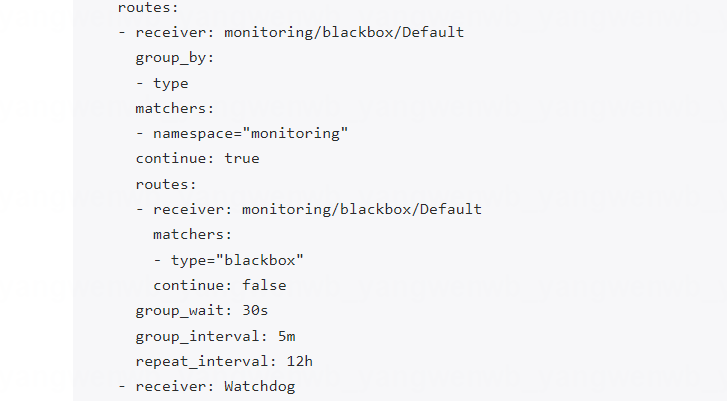
metadata:name: blackboxlabels:alertmanagerConfig: example
spec:route:groupBy: ['type']groupWait: 30sgroupInterval: 5mrepeatInterval: 12hroutes:- matchers:- matchType: =name: typevalue: blackboxreceiver: Defaultreceiver: Defaultreceivers:- name: DefaultemailConfigs:- to: xxx@163.comsendResolved: true[root@k8s-master01 ~]# kubectl create -f blackbox-alertmanagerconfig.yaml -n monitoring
替换后即可在 Alertmanager 上看到路由配置:

稍后就能在邮件中收到 Blackbox 的告警

8.5 Alertmanager 钉钉告警配置
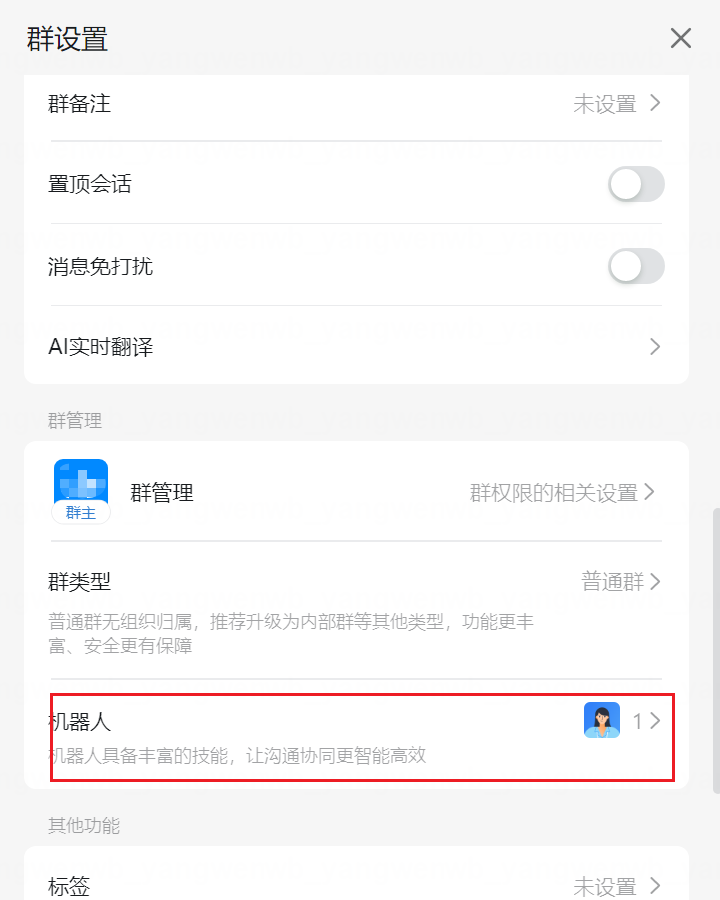
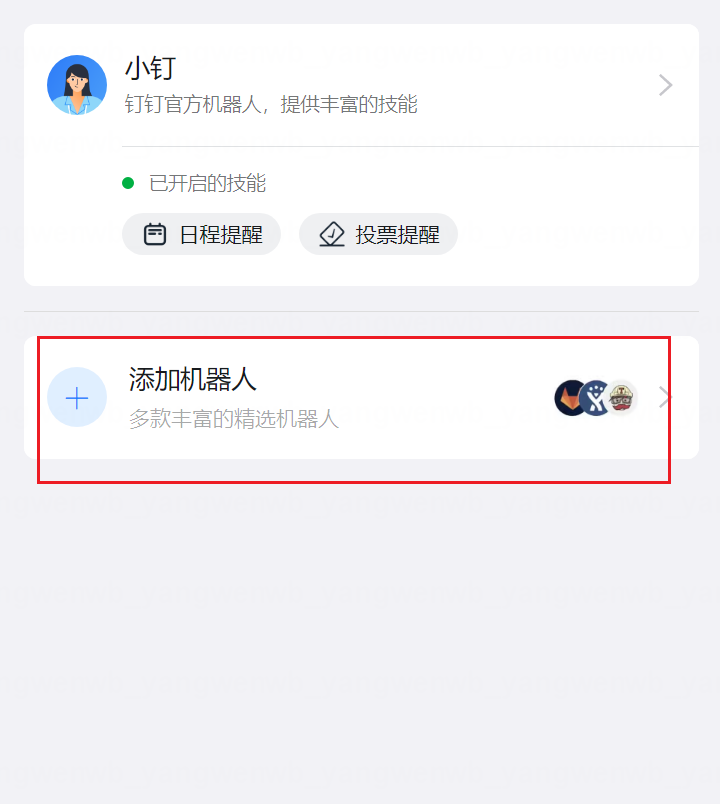
8.5.1 钉钉机器人配置
使用钉钉告警,需要先创建一个群聊,然后添加一个机器人:
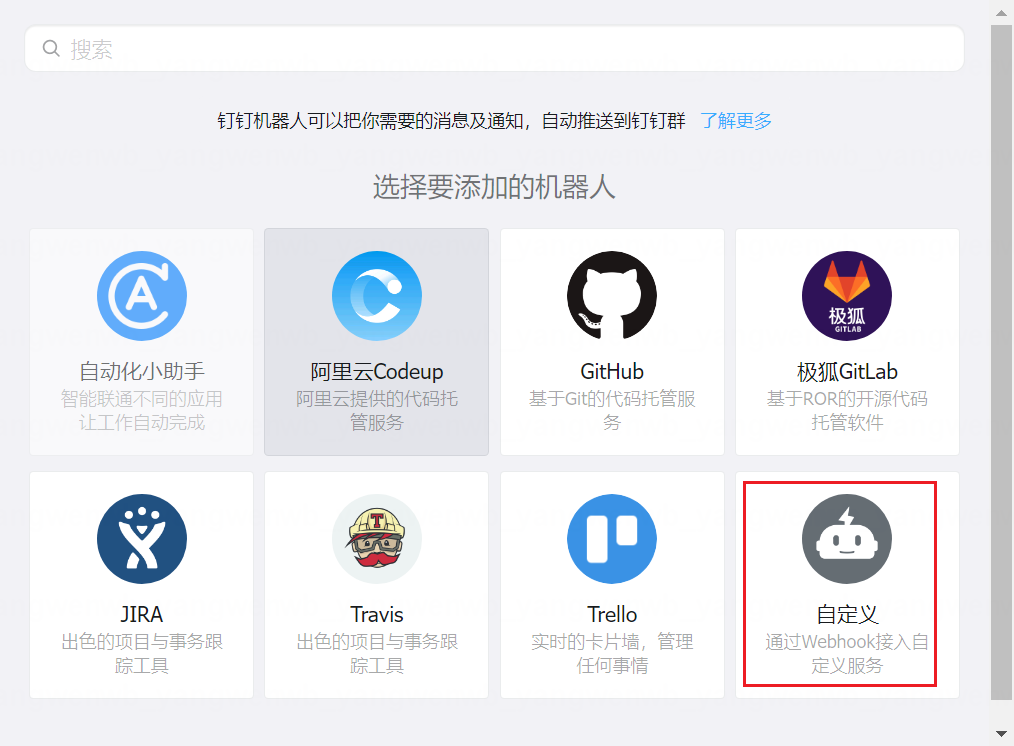
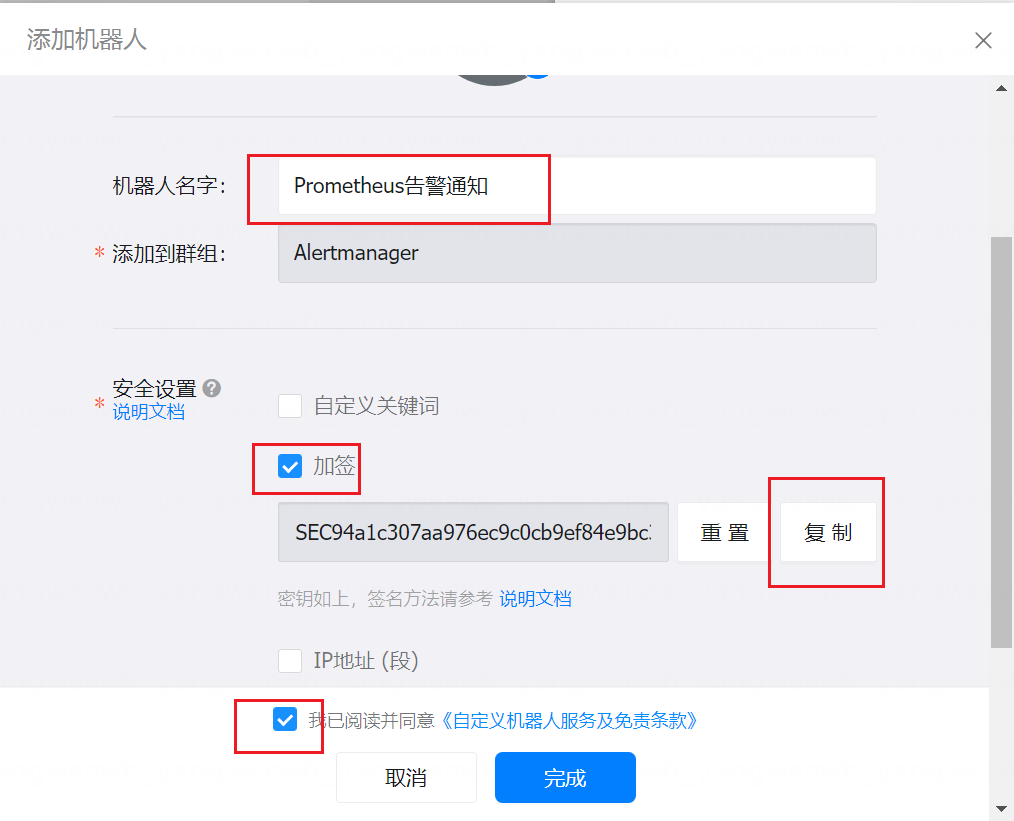
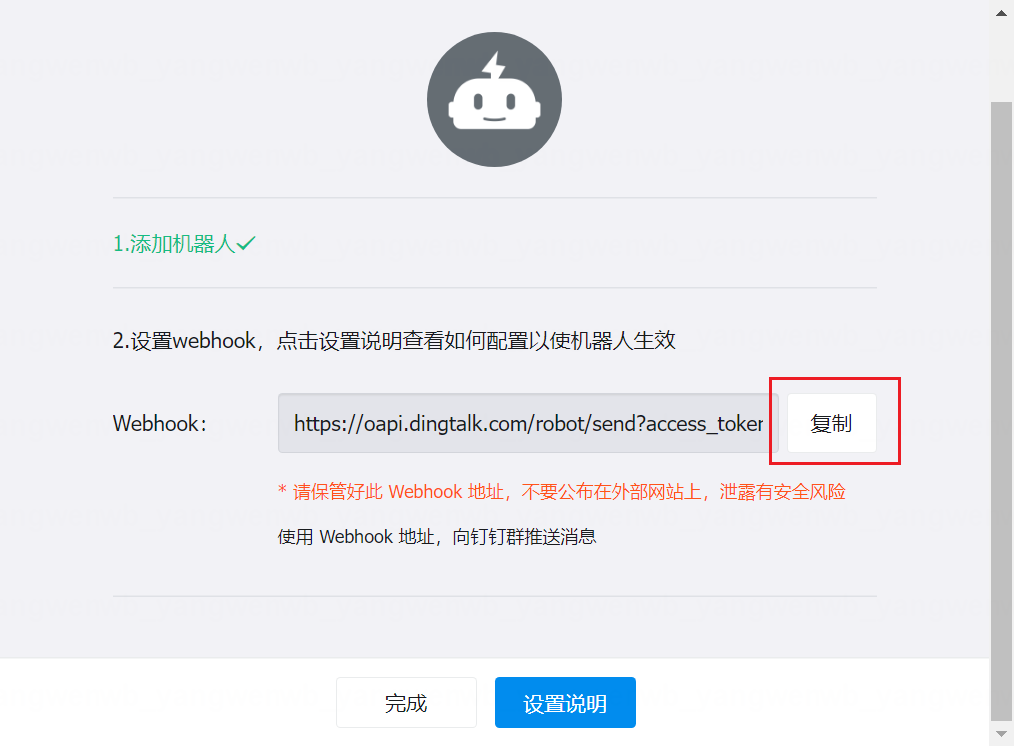
8.5.2 钉钉 Webhook 服务部署
# 下载钉钉 Webhook 服务部署文件:
[root@k8s-master01 ~]# git clone https://gitee.com/dukuan/prometheus-webhook-dingtalk.git# 修改配置为自己的信息:
[root@k8s-master01 ~]# cd prometheus-webhook-dingtalk/contrib/k8s/
[root@k8s-master01 k8s]# vim config/config.yaml
[root@k8s-master01 k8s]# cat config/config.yaml
....
targets:webhook1: # 替换成钉钉机器人生成的地址url: https://oapi.dingtalk.com/robot/send?access_token=d7b9067fd32923ca2261e2afa41f578d786073551d80cb6fd07eab2aa4527faf# secret for signaturesecret: SEC94a1c307aa976ec9c0cb9ef84e9bc36747c4055cfb9a0ab567006180c012feeb
....# 执行安装:
[root@k8s-master01 k8s]# kubectl kustomize | kubectl apply -f - -n monitoring# 查看 Pod 状态:
[root@k8s-master01 k8s]# kubectl get po -n monitoring | grep dingtalk
alertmanager-webhook-dingtalk-65b4b7dd77-lkc5b 1/1 Running 0 4m38s
8.5.3 Alertmanager 实现钉钉告警通知
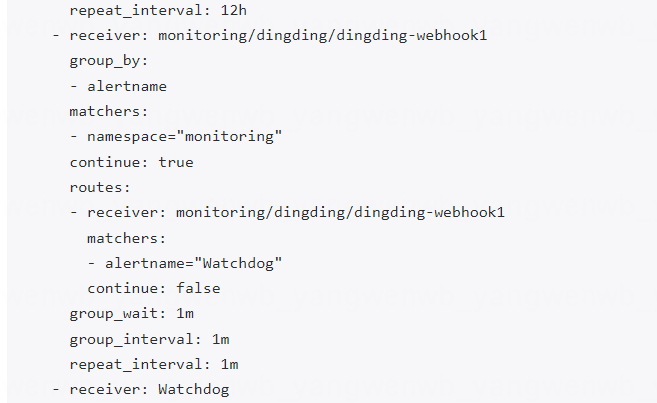
接下来可以自定义路由把一些告警发送至钉钉群,比如把 Watchdog 的告警发送至钉钉:
[root@k8s-master01 ~]# vim dingding-alertmanagerconfig.yaml
[root@k8s-master01 ~]# cat dingding-alertmanagerconfig.yaml
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:name: dingdinglabels:alertmanagerConfig: example
spec:route:groupBy: ['alertname']groupWait: 1mgroupInterval: 1mrepeatInterval: 1mroutes:- matchers:- matchType: "="name: alertnamevalue: "Watchdog"receiver: dingding-webhook1receiver: dingding-webhook1receivers:- name: dingding-webhook1webhookConfigs:- sendResolved: trueurl: http://alertmanager-webhook-dingtalk.monitoring/dingtalk/webhook1/send[root@k8s-master01 ~]# kubectl create -f dingding-alertmanagerconfig.yaml -n monitoring
[root@k8s-master01 ~]# kubectl get -f dingding-alertmanagerconfig.yaml -n monitoring
NAME AGE
dingding 45s
可在 Alertmanager 上看到路由配置:
创建该 AlertmanagerConfig 后,即可在钉钉群中收到告警信息:
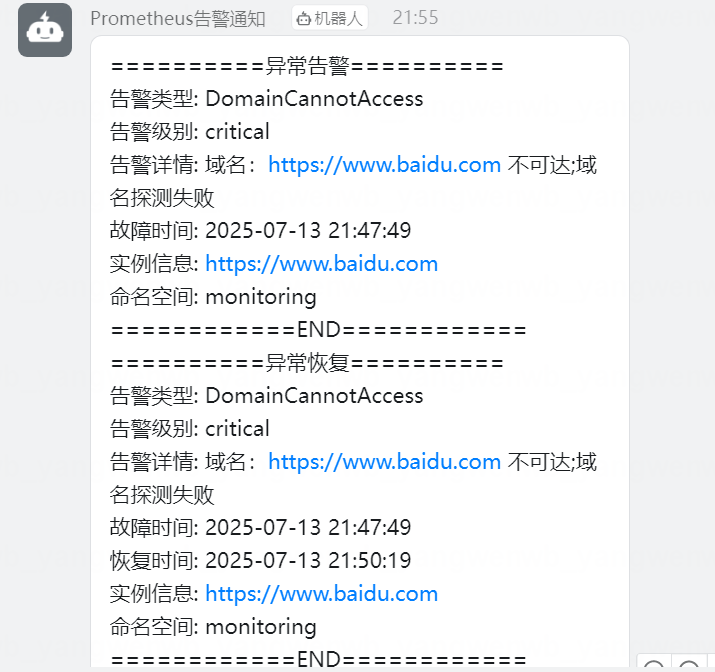
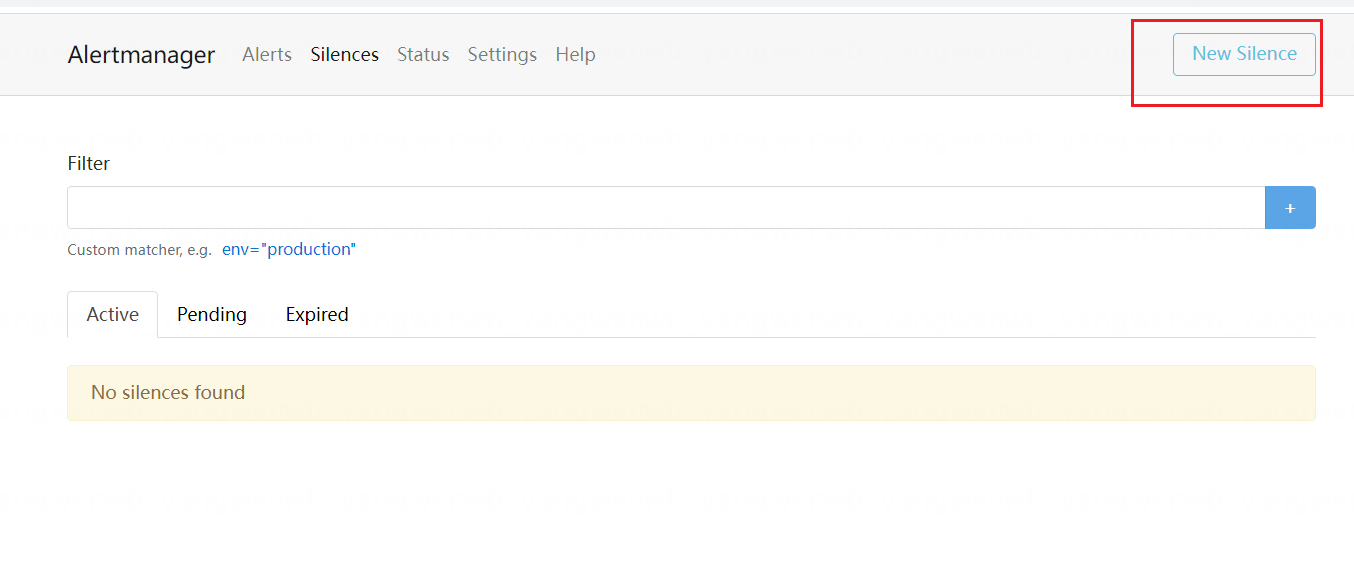
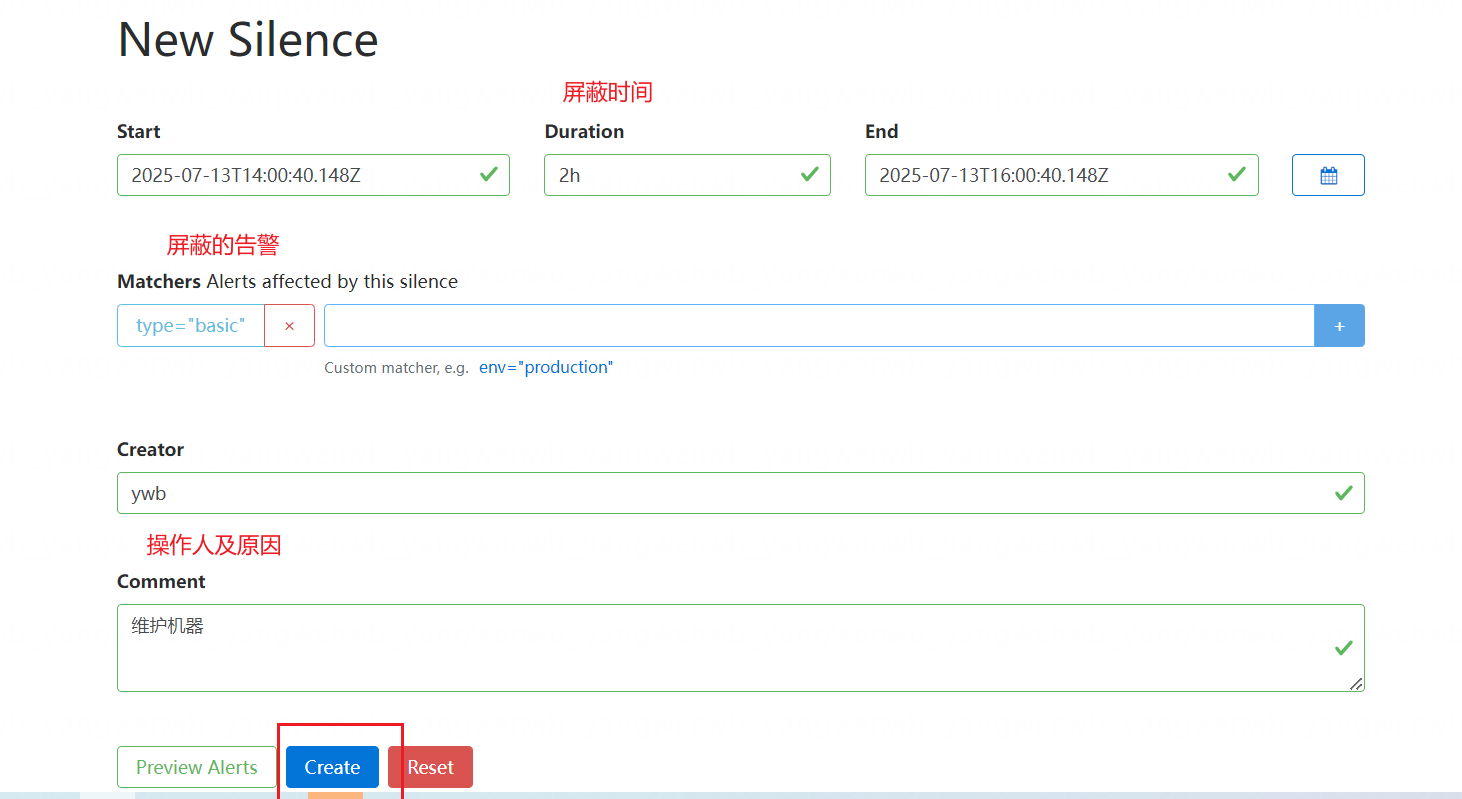
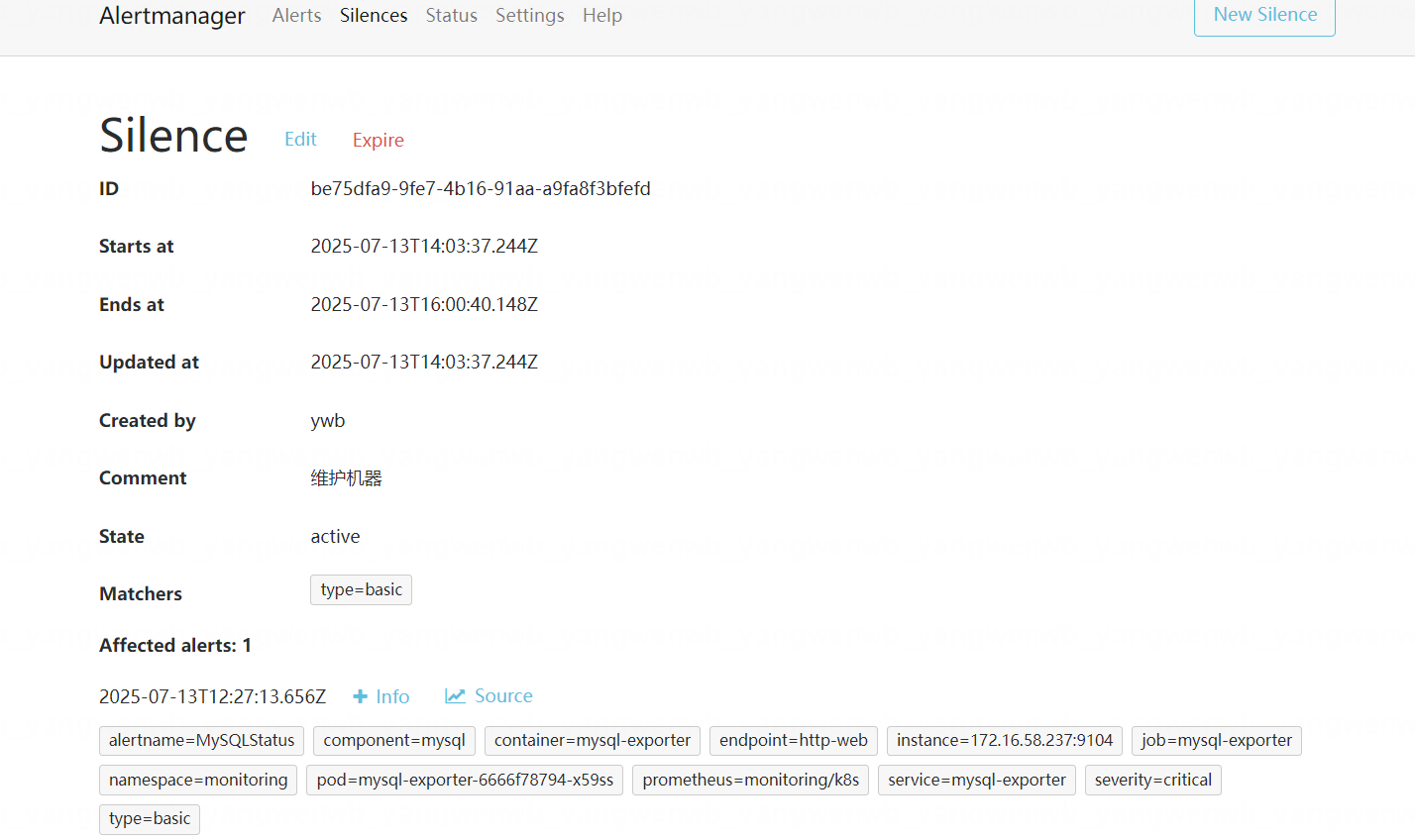
8.6 屏蔽告警
此博客来源于:https://edu.51cto.com/lecturer/11062970.html