TVLT:无文本视觉-语言Transformer
温馨提示:
本篇文章已同步至"AI专题精讲" TVLT:无文本视觉-语言Transformer
摘要
在本研究中,我们提出了 Textless Vision-Language Transformer(TVLT),其中同构的 transformer 模块直接接受原始视觉和音频输入,用于视觉-语言表示学习,几乎不需要模态特定设计,并且不使用诸如 tokenization 或自动语音识别(ASR)等文本专用模块。TVLT 通过重建被遮蔽的视频帧和音频频谱图的连续 patch(masked autoencoding)以及用于对齐视频与音频的对比建模进行训练。TVLT 在视觉问答、图像检索、视频检索和多模态情感分析等多种多模态任务上达到了与其基于文本的对标模型相当的性能,推理速度提升了 28 倍,参数量仅为其三分之一。我们的研究结果表明:可以在不依赖文本先验的前提下,从低级视觉和音频信号中学习紧凑高效的视觉-语言表示。
1 引言
人类通过来自多个模态的信号感知并学习外部世界。为了在机器中实现类似的人类学习方式,大量研究致力于开发视觉-语言(VL)模型,以理解视觉模态与语言模态之间的联合语义,并解决如视觉问答 [4] 等任务。虽然大多数此类 VL 模型采用书面语言而非口语作为主要的语言交流方式,但人类自约公元前 10 万年起,默认的交流模态一直是口语 [78]。而书面语言是相对较新的事物;最早的文字系统楔形文字大约在公元前 3200 年被发明 [65]。此外,我们已看到 AI 模型越来越多地应用于虚拟助手、智能音箱等现实产品中 [40],在这些场景中,视频和音频等感知层信号才是输入的自然形式。从直觉上讲,直接建模这些信号可能会带来更紧凑且更高效的表示。
transformer [81] 最近在视觉-语言表示学习中取得了巨大成功 [76; 10; 48; 74; 87; 86],这些方法通常使用基于文本的模块 [15] 来处理带有文本标注的图像或视频。然而,若要使用仅包含低层视觉和听觉输入、且不依赖于书面语言先验的 transformer 来学习 VL 表示,这并非易事。挑战在于文本和音频信号之间的差异:文本是离散的、信息密集的,而音频信号是连续的、信息稀疏的 [26; 7]。因此,不同模态的数据通常需要采用模态特定的架构来建模。直到最近,研究者才开始使用模态无关的 transformer 架构来学习不同单模态 [17; 19; 8]、视觉-文本 [32; 54] 或视觉-音频-文本 [2] 数据的表示。然而,据我们所知,此前尚未有工作探索一种单一的、同构的(模态无关的)极简 transformer,该模型可在感知层直接从视觉和音频输入中学习视觉-语言表示(不依赖文本),同时还能在结构上比现有基于文本的 VL 模型更紧凑和高效(详见第 2 节)。
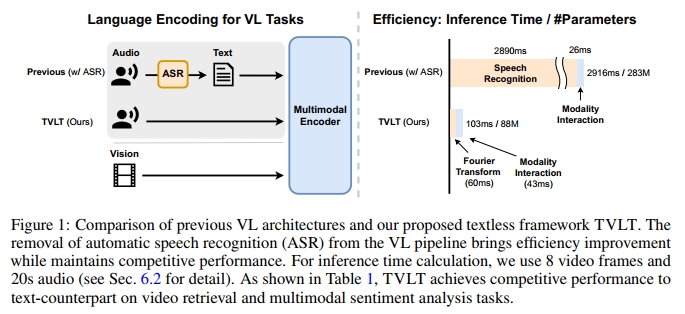
在本研究中,我们提出了一种用于视觉-语言表示学习的 Textless Vision-Language Transformer(TVLT),其基于视频数据这一原始视觉和音频输入的自然来源。如图 2 所示,TVLT 接受低级的视频帧和音频频谱图作为输入。我们为 TVLT 采用了极简设计,即在编码器和解码器中均使用同构的 transformer 块。TVLT 通过重建被遮蔽的视频帧和音频频谱图的连续 patch(masked autoencoding)以及用于对齐视频与音频的对比建模进行训练。更重要的是,TVLT 不对书面语言的存在做任何假设,也不涉及对文本输入的显式建模,例如自动语音识别(ASR)或 tokenization——这些是现有 VL 模型中将书面概念与视觉线索对齐的关键子模块。
尽管移除了基于文本的模块和模态特定设计,TVLT 在多模态任务中(无论是直接使用音频输入,还是通过 TTS 将文本转换为音频输入)如视觉问答、图像检索、视频检索以及多模态情感分析方面,依然取得了与其基于文本的对标模型相当的效果,同时在计算效率方面更具优势,其参数量仅为三分之一,推理速度快 28 倍,如图 1 所示。这表明,在视觉-语言建模中移除 ASR 等文本特定模块,有助于减少现有流水线式学习范式中的计算冗余,在这些范式中,文本首先通过 ASR 提取,再由基于文本的 VL 模型进一步处理。此外,我们还展示了 TVLT 能够捕捉超越语音的音频信息,并且在多模态情感分类中比其基于文本的对标模型表现更为优异。我们希望这些发现能够激发关于 textless VL 模型的进一步研究,该类模型直接以原始信号为输入,旨在学习更紧凑且更高效的视觉-语言表示。
2 相关工作
**基于文本的表示学习。**近年来,基于书面文本的大规模无监督上下文语言模型预训练取得了巨大成功。ELMo [58] 提出了预训练和微调一个大型循环语言模型的方法,从而提升了在多种下游自然语言处理任务上的表现。BERT [15] 使用具有 masked language modeling 目标的 transformer [81] 模型,提升了预训练-微调范式的可扩展性。自那以后,transformer 的预训练被广泛用于语言中的迁移学习 [46; 83; 38; 16; 73; 60; 13]。在这些方法中,学习的重点是从未标注的书面文本或自然单词序列中提取高层次的语言语义和结构。
**基于音频的表示学习。**在音频输入上的预训练方法通常涉及将连续的一维音频信号转化为稠密向量,以输入至语音或声学模型中。早期的工作主要使用循环神经网络 [12; 11; 70] 和卷积网络 [66] 进行音频编码。为了利用 transformer 在表达力和通用性上的优势,近期的研究提出将音频频谱图 [19; 20; 7] 作为图像输入,然后采用类似计算机视觉中的方法 [17],用 transformer 对这些图像的 patch 进行编码。
transformer 的预训练目标涵盖从分类 [19] 到 masked audio modeling [20; 7] 的多种形式。有一类工作使用带有离散音频单元的 audio transformer 进行预训练 [27],以及用于生成式口语建模 [37; 31] 和语音情感转换 [35] 的语音任务。这些研究关注于从原始音频或频谱图中学习语言的声学和语言特征。
**视觉-语言表示学习。**继 transformer 语言模型预训练成功之后,图像+文本 [76; 48; 10; 43; 90; 41]、视频+文本 [74; 52; 92; 51; 42; 77; 87]、以及视频+文本+音频 [79; 85; 61; 86; 2] 的多模态 transformer 预训练方法,近年来在视觉-语言下游任务(如视觉问答 [4; 28] 和文本到视频检索 [82; 91])上取得了显著进展。这些方法使用文本(如书面标题或 ASR 转录结果)作为语言通道的输入。另有一类研究关注于处理视频+音频输入的模型,这类方法可利用视频中天然同步的视觉+音频对。音视频同步常被用于自监督学习 [56; 5; 55; 34; 6; 53; 49],或用于下游任务,如自动语音识别 [1; 72; 71] 和视频检索 [75; 63; 64; 45]。
我们的方法不同于上述工作,我们的重点在于设计一种同质化且模态无关的 transformer(见第 3 节),以实现一种新颖、统一、极简的无文本视觉-语言表示学习方法,该方法直接从视觉和音频信号中学习(不依赖文本),并通过masked autoencoding 和 contrastive modeling 目标进行训练(见第 4 节),从而使该无文本 VL 模型比现有基于文本的 VL 模型更加紧凑且高效。
3 TVLT: 无文本视觉-语言 Transformer
我们提出 TVLT:Textless Vision-Language Transformer,一种极简的端到端视觉-语言 transformer 模型,如图 1 和图 2 所示,它接受直接从感知层的视频和音频输入中获得的 embedding 列表作为输入,而不依赖任何与文本相关的模块。
3.1 输入 embedding
TVLT 的输入 embedding 是以下四项的总和:(1) 模态 embedding,(2) 视频的时间/空间 embedding,(3) 音频的时间/频率 embedding,以及 (4) 视觉/音频 patch embedding。如图 2 中红色和蓝色框所示,模态 embedding 是两个可训练向量,分别加到输入 embedding 上,用于指示输入是来自视觉还是音频模态。下面我们将详细说明视觉和音频 embedding 的细节。
**视觉 embedding。**我们采用 ViT [17] 风格的视觉 embedding,将每帧 224×224224 × 224224×224 像素的视频帧划分为若干 16×1616 × 1616×16 大小的 patch。然后对每个 patch 的归一化像素值应用一个线性投影层,得到一个 768 维的 patch embedding。对于一个包含 N 帧的视频片段,其输入张量形状为 N×224×224×3N × 224 × 224 × 3N×224×224×3(时间 × 高度 × 宽度 × 通道),最终得到 N×14×14N × 14 × 14N×14×14 个 embedding。我们在 N×14×14N × 14 × 14N×14×14 的 embedding 上分别添加时间、空间两个方向的可训练向量,来融合每个 patch 的时间和空间信息。我们将图像输入视为单帧视频,这样模型在结构上就可以统一处理图像和视频任务 [9]。时间 embedding 仅用于视频输入,对于图像输入不使用时间 embedding。
**音频 embedding。**为了获得音频 embedding,我们首先将原始音频信号的一维波形转换为 128 维 log Mel-spectrogram,其维度为 T×128T × 128T×128(时间轴 × 频率轴)[^2]。然后我们将音频频谱图视为图像,将其划分为若干 patch,并对每个 patch 应用一个线性投影层,得到一个 768 维的 patch embedding。这一方法借鉴了近期研究中的音频 embedding 方法 [19; 20; 7],这些方法同样使用模态无关的 transformer 来建模频谱图 patch。我们实验了两种不同的 patch 大小:16×1616 × 1616×16(与视觉模态中相同的方形 patch)和 2×1282 × 1282×128(面积相同,但覆盖整个频率域、时间跨度较短),并使用可训练的时间和频率 embedding 表示 patch 的时间和频率信息。
3.2 多模态编码器-解码器
TVLT 的主要架构是一个 transformer [81],包含一个 12 层的编码器(隐藏维度为 768),记作 EEE,以及一个 8 层的解码器(隐藏维度为 512),记作 DDD。我们遵循 He 等人 [26] 的方法,使用一个浅层解码器,该解码器仅用于掩码自编码目标(第 4.2 节),其计算开销远小于编码器。预训练完成后,我们仅使用编码器的表示进行下游任务的微调。
4 预训练目标
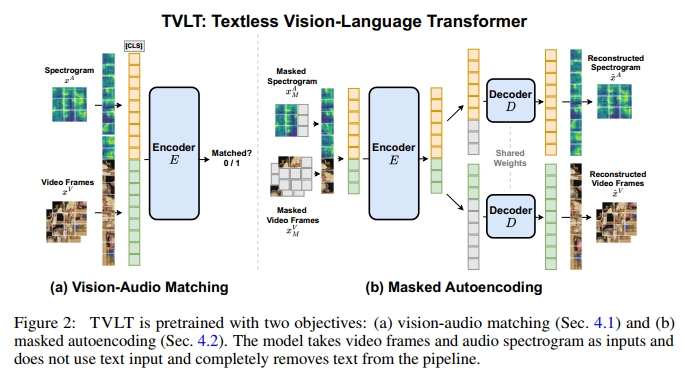
由于我们采用了极简且模态无关的设计,TVLT 使用两个目标进行预训练:(1)视觉-音频匹配(第 4.1 节)和(2)掩码自编码(第 4.2 节)。对于每一个训练 batch,我们分别对每个目标执行一次前向传播,并使用它们的加权和作为最终损失函数,其中 λVAM=1.0\lambda^{\text{VAM}} = 1.0λVAM=1.0,λMAE=0.3\lambda^{\text{MAE}} = 0.3λMAE=0.3:
loss=λVAMlossVAM+λMAElossMAE(1)\mathit { l o s s } = \lambda ^ { \mathrm { V A M } } l o s s ^ { \mathrm { V A M } } + \lambda ^ { \mathrm { M A E } } l o s s ^ { \mathrm { M A E } }\quad(1) loss=λVAMlossVAM+λMAElossMAE(1)
4.1 视觉-音频匹配
我们使用视觉-音频匹配(Vision-Audio Matching, VAM)目标来学习全局跨模态表示,如图 2(a) 所示。对于每个视频输入,我们创建一个(正样本)视觉-音频对 (xV+,xA)(x_V^+, x_A)(xV+,xA)。然后,我们将 batch 中一半的视觉-音频对构造为不匹配的(负样本)对 (xV−,xA)(x_V^-, x_A)(xV−,xA),方法是用来自训练数据集中的随机视频帧 xV−x_V^-xV− 替换掉 xV+x_V^+xV+。
参照已有的视觉-语言 transformer 方法 [76; 10; 48; 32],我们使用带有 sigmoid 激活函数的线性层作为分类头,作用于第一个 [CLS] token 的编码器输出,以获得匹配概率 ppp。然后我们计算二分类交叉熵损失如下:
lossVAM=−ylogp(2)l o s s ^ { \mathrm { V A M } } = - y \log p\quad(2) lossVAM=−ylogp(2)
其中,yyy 为标签,当视觉-音频对 (xV,xA)( x ^ { V } , x ^ { A } )(xV,xA) 是匹配对时取值为 1,否则为 0。
4.2 掩码自编码
除了用于学习跨模态表示的 VAM 目标之外,我们还使用掩码自编码(Masked Autoencoding, MAE)目标来提升在视觉-语言环境下的单模态表示。具体方法是对视觉帧和音频声谱图的随机 patch 进行掩码,并重建缺失的输入,如图 2(b) 所示。具体来说,我们随机丢弃一部分视觉 embedding xVx_VxV 和音频 embedding xAx_AxA,然后将剩余的 patch embedding 输入编码器 EEE。我们通过将丢弃的 embedding 替换为可训练向量 [MASK] 并放置在原始输入的相同位置(图 2(b) 中的灰色框)来创建解码器 DDD 的输入。同时,我们还向解码器输入添加相应的时间、位置和频率 embedding。注意,编码器和解码器的时间、位置和频率 embedding 是分别参数化的。我们计算重建后的视频帧和声谱图与原始输入之间的均方误差如下:
lossMAE=1NMV∑i∈masked∣∣xiV−x^iV∣∣22+1NMA∑j∈masked∣∣xjA−x^jA∣∣22(3)l o s s ^ { \mathrm { M A E } } = \frac { 1 } { N _ { M } ^ { V } } \sum _ { i \in m a s k e d } | | x _ { i } ^ { V } - \hat { x } _ { i } ^ { V } | | _ { 2 } ^ { 2 } + \frac { 1 } { N _ { M } ^ { A } } \sum _ { j \in m a s k e d } | | x _ { j } ^ { A } - \hat { x } _ { j } ^ { A } | | _ { 2 } ^ { 2 }\quad(3) lossMAE=NMV1i∈masked∑∣∣xiV−x^iV∣∣22+NMA1j∈masked∑∣∣xjA−x^jA∣∣22(3)
其中,NVMN_V^MNVM 和 NAMN_A^MNAM 分别是视觉和音频中被掩码的 patch 数量。我们仅在被掩码的 patch 上计算损失,类似于 BERT [15] 的做法。
为节省计算量,我们将编码器输出中的音频部分和视频部分分别切片,然后分别输入解码器,而不是对视频帧和音频声谱图进行联合解码。在第 6.6 节中,我们展示了这种分离解码方式在微调性能和效率上均优于联合解码。
4.3 掩码策略
视觉掩码:遵循 MAE [26],我们随机掩码 75% 的视觉 patch,且每个视频帧独立应用掩码。
音频掩码:遵循 MAE-AST [7],我们随机掩码 75% 的声谱图 patch。为了更好地捕捉与语音相关的音频表示,我们将音频掩码重点应用于语音音频。我们使用 Audiotok [3],一种基于音频信号能量事件检测的语音活动检测工具,来确定语音跨度。然后,仅在这些音频跨度上应用掩码。我们使用 15% 的掩码概率。语音跨度检测的详细信息见附录。
5 实验设置
为了比较基于音频和基于文本的语言表示在视觉-语言任务中的表现,我们在视频数据集上对 TVLT 及其基于文本的对应模型进行了预训练。然后,我们在一组下游的视觉-语言数据集上对模型进行了微调,以进行评估。
5.1 基于文本的 TVLT 对应模型
我们的基于文本的 TVLT 对应模型与原始 TVLT 具有相同的架构,仅在输入处理上进行了少量修改。首先,我们使用 sentence-piece [36] 分词器,将每个词元映射到可训练的向量,从而将原始文本编码为 embedding,而不是像原始 TVLT 那样将连续的帧或声谱图输入转换为 patch embedding。其次,我们遵循掩码语言建模 [15] 中的规范,使用仿射层作为解码器来恢复掩码的词语,并将文本的掩码比例设置为 15%,而不是在原始 TVLT 中使用 transformer 解码器重建 75% 的掩码视频和音频 embedding。
5.2 预训练数据集
HowTo100M:我们使用了 HowTo100M [52] 数据集,该数据集包含来自 1.22M 个 YouTube 视频的 136M 个视频片段,总时长为 134,472 小时。我们将原始 TVLT 直接用视频片段的帧和音频流进行预训练。基于文本的 TVLT 使用视频的帧和字幕流进行训练。字幕是数据集中自动生成的 ASR 提供的。我们使用了 92 万个视频进行预训练,因为一些视频链接无法下载。
YTTemporal180M:YTTemporal180M [87] 包含来自 6M 个 YouTube 视频的 1.8 亿个视频片段,涵盖多个领域和主题,包括 HowTo100M 数据集中的教学视频、VLOG 数据集中的日常事件视频以及 YouTube 上针对流行话题(如‘科学’或‘家居装修’)的自动推荐视频。每个视频片段包括 1) 从片段中提取的中间时间步的图像帧,以及 2) 基于 ASR 的字幕,包含 L=32 的 BPE [18; 68] 词元。对于每个样本,我们从整个视频中随机抽取一个 15 秒的视频片段,形成类似于 HowTo100M 数据集的设置。具体来说,原始数据集提供了 100 个标签文件,这些文件是数据集的随机拆分。我们从 YTTemporal180M 中抽取 20%(92 万个视频),使得结果子集的数量与 HowTo100M 相似(92 万个视频),并称之为 YTT-S。在附录中,我们展示了在 YTT-S 上预训练 TVLT 能提高下游任务性能,优于在 HowTo100M 上的预训练。
温馨提示:
阅读全文请访问"AI深语解构" TVLT:无文本视觉-语言Transformer