【AI论文】递归混合体:学习动态递归深度以实现自适应的令牌级计算
摘要:扩展语言模型规模可解锁令人瞩目的能力,但随之而来的计算与内存需求却使得模型训练和部署成本高昂。现有的提升效率方法通常侧重于参数共享或自适应计算,但如何同时实现这两点仍是一个待解难题。为此,我们提出了递归混合体(Mixture-of-Recursions,MoR)这一统一框架,它将两种效率提升途径整合于单一的递归Transformer之中。MoR通过在递归步骤中复用共享层堆栈来实现参数高效利用,同时,轻量级路由器能够动态地为单个令牌分配不同的递归深度,从而实现自适应的令牌级思考。这使得MoR仅在给定递归深度下仍处于活跃状态的令牌之间进行二次注意力计算,并通过仅选择性缓存这些令牌的键值对,进一步提高了内存访问效率。除了这些核心机制外,我们还提出了一种键值(KV)共享变体,它复用首次递归中的键值对,旨在降低预填充延迟和内存占用。在模型规模从1.35亿到17亿参数的范围内,MoR形成了新的帕累托前沿:在训练浮点运算次数(FLOPs)相同且模型规模更小的情况下,与普通模型和现有的递归基线相比,它显著降低了验证困惑度,提高了少样本准确率,同时实现了更高的吞吐量。这些优势表明,MoR是一条在不增加大模型成本的情况下实现大模型质量的有效途径。Huggingface链接:Paper page,论文链接:2507.10524
研究背景和目的
研究背景:
随着语言模型规模的扩大,模型展现出了惊人的少样本泛化和推理能力,例如GPT-4、Llama等模型的出色表现。然而,这种性能提升伴随着巨大的计算和内存需求,使得模型的训练和部署成本高昂,尤其是在非超大规模数据中心环境中部署这些模型变得具有挑战性。为了应对这一问题,研究人员提出了多种提升模型效率的方法,主要包括参数共享和自适应计算两大方向。
参数共享方面,通过层绑定(layer tying)等技术,在多个层中重复使用同一组权重,从而减少模型参数数量,如Universal Transformer和Relaxed Recursive Transformers等模型所示。然而,单纯的参数共享方法虽然减少了参数量,但并未解决计算冗余问题。
自适应计算方面,研究者们探索了动态计算分配的方法,如早期退出(early-exiting)机制,通过根据输入样本的复杂度动态调整计算量,以减少不必要的计算。然而,这些方法往往需要专门的训练过程或在部署时面临效率挑战,且通常应用于固定的模型深度,无法真正实现自适应的令牌级计算分配。
研究目的:
本研究旨在提出一种统一的框架,能够同时实现参数高效利用和自适应计算,从而在不增加大模型成本的情况下实现大模型的质量。具体而言,研究旨在:
- 实现参数高效利用:通过层复用减少模型参数数量,降低内存占用。
- 实现自适应计算:通过动态调整每个令牌的递归深度,使计算资源能够集中在需要更多处理的复杂令牌上,提高计算效率。
- 优化内存访问效率:通过选择性缓存活跃令牌的键值对,减少不必要的内存访问,提高模型推理速度。
研究方法
为了实现上述研究目的,本研究提出了Mixture-of-Recursions(MoR)框架,具体方法包括以下几个方面:
1. 参数共享策略:
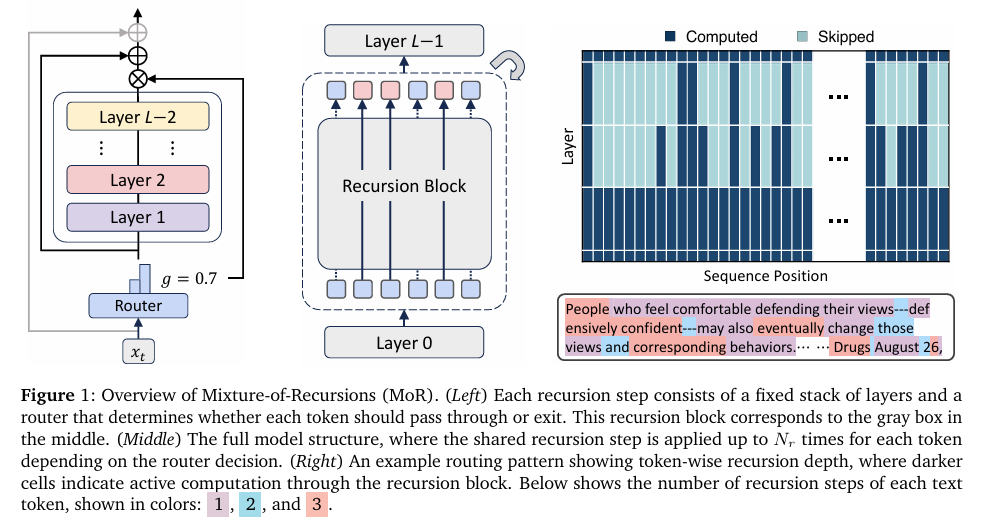
MoR框架在递归Transformer中复用共享层堆栈,通过参数共享减少模型参数量。研究比较了四种参数共享策略:Cycle、Sequence、Middle-Cycle和Middle-Sequence。Middle-Cycle策略在保持首尾层独特参数的同时共享中间层参数,被证明是最有效的参数共享方式。
2. 自适应递归深度分配:
MoR框架引入了轻量级路由器,用于动态决定每个令牌的递归深度。研究设计了两种路由策略:
- Expert-choice路由:在每个递归深度上选择top-k个令牌继续递归,其余令牌退出。这种方法保证了固定的计算预算,但可能违反因果性。
- Token-choice路由:在初始阶段为每个令牌分配一个完整的递归路径,令牌根据分配的路径进行递归。这种方法避免了因果性问题,但可能导致负载不均衡。
为了缓解负载不均衡问题,研究还引入了平衡损失(balancing loss)和损失无算法(loss-free algorithm)。
3. 键值缓存策略:
MoR框架提出了两种键值缓存策略:
- 递归级缓存(Recursion-wise Caching):在每个递归深度上缓存当前活跃令牌的键值对,确保注意力计算仅在活跃令牌之间进行。
- 递归共享缓存(Recursive KV Sharing):在所有递归深度上共享首次递归中计算的键值对,减少内存占用,但可能引入分布不匹配问题。
4. 模型训练和评估:
研究在FineWeb-Edu数据集上预训练了不同规模的MoR模型,并在多个少样本基准测试集上评估了模型性能。评估指标包括验证困惑度和少样本准确率。同时,研究还测量了模型的推理吞吐量,以评估其在实际部署中的效率。
研究结果
1. 性能提升:
MoR框架在多个模型规模下均实现了显著的性能提升。与普通模型和递归基线相比,MoR模型在相同的训练FLOPs下显著降低了验证困惑度,并提高了少样本准确率。特别是在模型规模较大时(如730M和1.7B参数),MoR模型的优势更加明显。
2. 推理效率提升:
MoR框架通过动态递归深度分配和选择性缓存策略,显著提高了模型的推理吞吐量。与普通模型相比,MoR模型在连续深度批处理(continuous depth-wise batching)模式下实现了更高的吞吐量,尤其是在递归深度较大时。
3. 参数高效利用:
通过参数共享策略,MoR模型在保持高性能的同时显著减少了模型参数量。Middle-Cycle策略被证明是最有效的参数共享方式,能够在减少参数量的同时保持模型的表达能力。
研究局限
尽管MoR框架在性能和效率方面均取得了显著提升,但研究仍存在一些局限性:
1. 路由器的稳定性:
Expert-choice路由在训练过程中可能出现因果性问题,尽管辅助损失和辅助路由器能够在一定程度上缓解这一问题,但路由器的稳定性仍有待进一步提高。
2. 负载不均衡:
Token-choice路由虽然避免了因果性问题,但可能导致负载不均衡,尤其是在处理复杂输入时。尽管引入了平衡损失和损失无算法来缓解这一问题,但在某些情况下仍难以实现完全的负载均衡。
3. KV共享的性能影响:
递归共享缓存策略虽然减少了内存占用,但可能引入分布不匹配问题,对模型性能产生一定影响。尽管这种影响在大多数情况下并不显著,但在某些特定任务上仍可能导致性能下降。
未来研究方向
针对上述研究局限,未来研究可以从以下几个方面展开:
1. 改进路由器设计:
探索更稳定的路由器设计方法,如引入更复杂的网络结构或优化算法,以提高路由器的选择准确性和稳定性。同时,可以考虑结合多种路由策略,以充分利用它们的优势并弥补各自的不足。
2. 优化负载均衡机制:
进一步研究负载均衡机制,如设计更有效的平衡损失函数或引入动态调整机制,以更好地处理复杂输入时的负载不均衡问题。同时,可以考虑结合模型并行和任务并行技术,以进一步提高大规模模型的训练和推理效率。
3. 探索更高效的KV缓存策略:
研究更高效的KV缓存策略,如引入分层缓存机制或压缩技术,以减少内存占用并提高缓存命中率。同时,可以考虑结合模型剪枝和量化技术,以进一步降低模型的存储和计算需求。
4. 扩展至多模态和非文本领域:
将MoR框架扩展至多模态和非文本领域,如视频、音频等,以探索其在更广泛任务上的应用潜力。通过结合不同模态的信息,MoR框架有望进一步提升模型的性能和泛化能力。
5. 结合稀疏算法:
探索将稀疏算法与MoR框架相结合,以进一步提高模型的计算效率。通过引入结构化稀疏性或动态稀疏性技术,可以在保持模型性能的同时显著减少计算量。这将为MoR框架在大规模模型和实时应用中的部署提供更多可能性。