论文笔记:Seed: Bridging Sequence and Diffusion Models for RoadTrajectory Generation
WWW 2025
1 INTRO
- 随着 GPS 设备的普及,车辆和个体的移动轨迹可以轻松被记录为轨迹数据
- 大量的轨迹数据促进了许多重要应用的发展,例如城市交通规划、车辆导航和路径推荐
- 然而,获取真实世界的轨迹数据面临多种挑战,包括高昂的数据采集成本、隐私问题 ,以及商业限制
- 轨迹生成技术通过基于参考轨迹数据集生成合成但真实感强的轨迹,从而成为应对上述挑战的有效方案
- 为了服务下游任务,合成轨迹需具备以下特性:
- 应与参考轨迹相似(即一致性)、遵循轨迹运动规律],并且在生成的多个轨迹之间具有差异性(即多样性)
- 现有轨迹生成方法根据方法论可分为两类:
- 递归式方法(Recurrent)
- 使用序列模型( LSTM 和 Transformer)以自回归的方式逐段生成轨迹(即一次一个道路段)
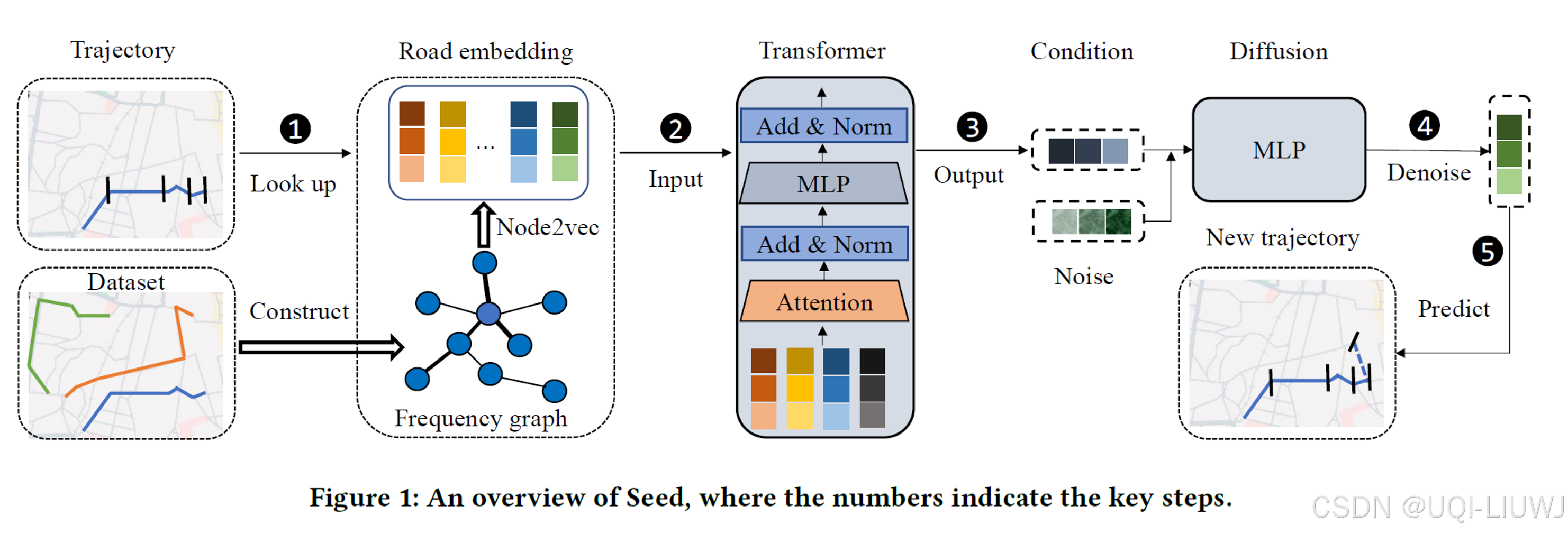
- SeqGAN 结合了 LSTM 和生成对抗网络(GAN),并使用策略梯度算法进行训练。
- TrajVAE 利用 LSTM 和变分自编码器(VAE)学习轨迹表示并重构轨迹。
- TS-TrajGen 则结合 Transformer 和两个 GAN,以由粗到细的粒度生成每条轨迹。
- 使用序列模型( LSTM 和 Transformer)以自回归的方式逐段生成轨迹(即一次一个道路段)
- 整体式方法(Holistic)
- 一次性生成完整的轨迹
- TrajGAN使用基于卷积神经网络(CNN)的 GAN 生成虚拟的轨迹图像,再将其转化为轨迹
- 为了利用扩散模型,DiffTraj和Diff-RNTraj将扩散模型分别集成到 U-Net [31] 和 WaveNet [18] 中进行轨迹生成。
- 一次性生成完整的轨迹
- 递归式方法(Recurrent)
- 递归方法在一致性和规律性方面表现出色,这是因为序列模型擅长捕捉参考轨迹沿道路段的运动模式
- 然而,它们的多样性较差,因为生成的轨迹常常严格遵循同一运动模式,导致生成轨迹相似
- 相反地,那些基于扩散模型的整体式方法具有较高的多样性,但一致性和规律性较弱
- 这是因为扩散模型是从随机噪声中恢复轨迹,不同运行中生成的轨迹往往不同,但它们无法很好地捕捉沿道路段的顺序移动模式
- ——>论文提出了一种名为 Seed 的轨迹生成方法,目标是同时实现一致性、规律性和多样性
- 核心思想是联合使用序列模型和扩散模型,兼顾两者优点,同时避免其缺陷
2 问题定义
2.1 道路网络

2.2 道路轨迹

2.3 轨迹生成

3方法
Seed 包含三个主要组件:
一个道路段嵌入字典模块,用于将离散的道路轨迹转换为连续表示;
一个条件扩散模块,用于学习轨迹数据的分布,并以自回归方式生成道路轨迹;
一个课程学习模块,用于加速模型收敛并提升模型性能。
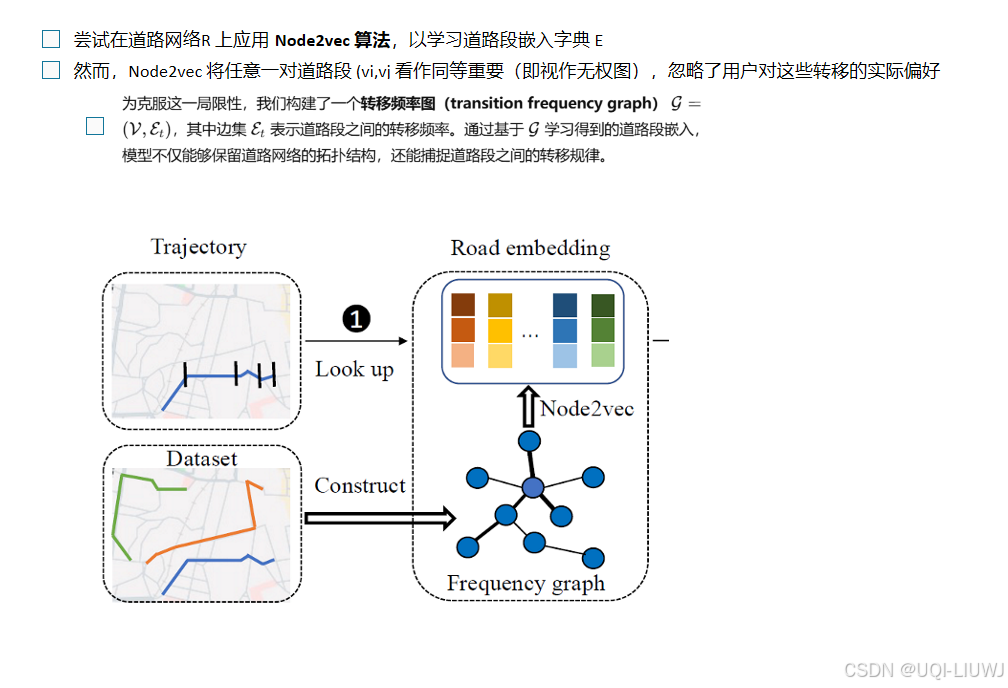
3.1 道路段嵌入
- 一种简单的方法是使用一个随机道路段嵌入字典
- 每个轨迹中的道路段均从该字典中提取
- 然而,这种方法忽略了道路网络的拓扑结构以及用户的出行模式
- ——>论文提出一种预训练策略,旨在学习一个更有效的道路段嵌入字典
3.2 条件扩散结构
3.2.1 扩散模型预备知识
- 与标准扩散模型不同,标准模型处理的是整个轨迹表示,而本工作将扩散应用于每个道路段嵌入,并以自回归方式逐段生成轨迹,从而在保持序列性基础上提升生成多样性。扩散模型主要包括正向扩散过程与反向去噪过程


3.2.2 引导条件

3.2.3 离散化与空间偏置

4.3 模型训练

4.4 课程学习

4.5 采样(Sampling)

需要在采样开始时指定要生成多少个道路段(比如 20 个),每步生成一个,生成满就停止。
5 实验
5.1 实验设置
5.1.1 数据集
- 在三个广泛使用的真实世界数据集上评估 Seed 的性能,分别为:Porto¹、Shenzhen² 和 Chengdu³
- 在每个数据集中,随机选取 80% 的轨迹作为训练集,剩余 20% 作为测试集
5.1.2 衡量指标



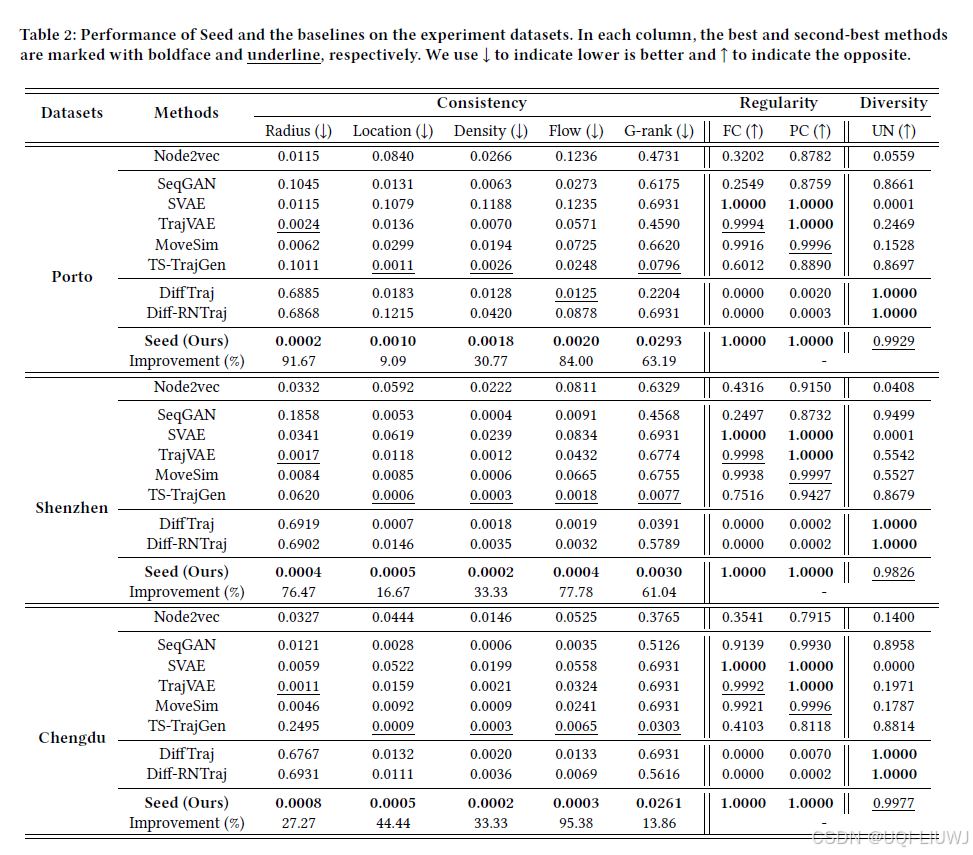
5.2主要结果
5.2.1 有效性分析
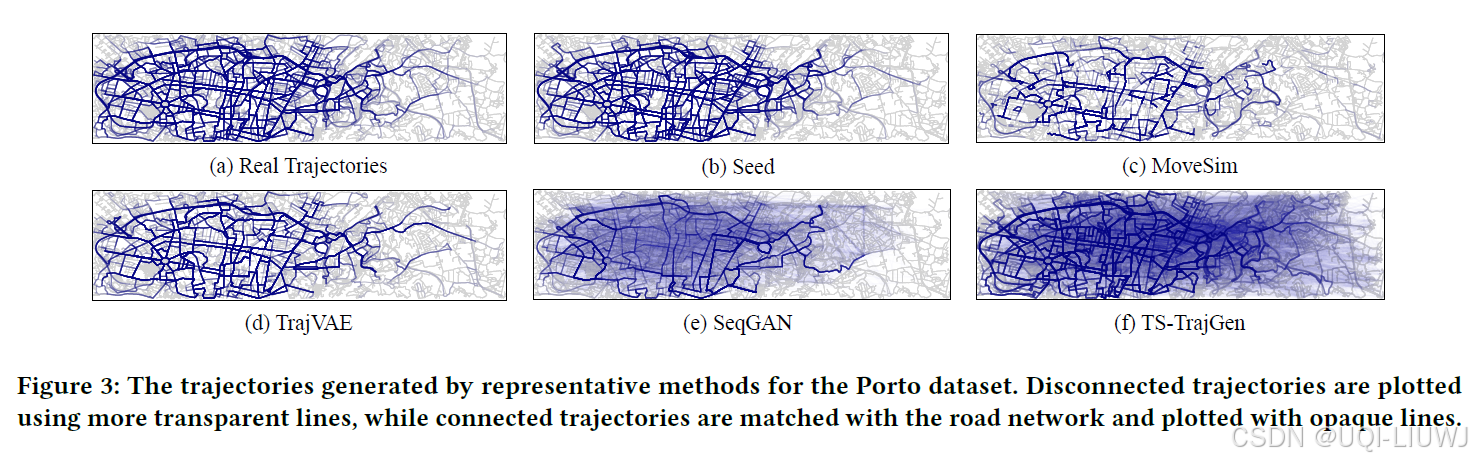
5.2.2 地理可视化分析
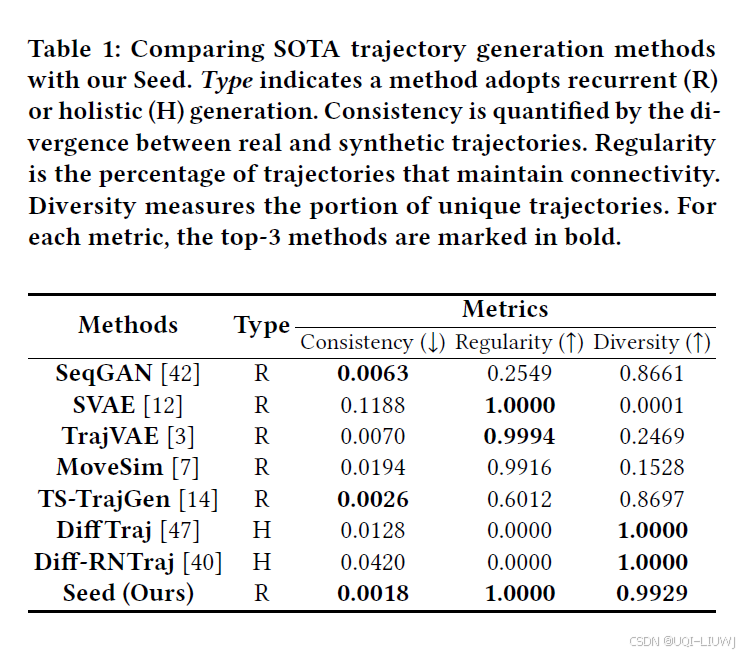
5.2.3 ablation study