30天打牢数模基础-XgBoost讲解








案例代码
一、代码说明
本代码以泰坦尼克号生存预测为背景,模拟了1000条包含缺失值、异常值的数据集,完整演示了XGBoost的正则化、列采样、直方图优化三大核心技术的应用,以及参数调优(eta、max_depth、subsample等)的流程。代码逻辑清晰,注释详细,适合数模小白入门。
二、完整代码
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import xgboost as xgb
import randomdef generate_titanic_data(n_samples=1000):"""模拟泰坦尼克号生存预测数据集(包含缺失值、异常值)参数:n_samples - 样本数量(默认1000)返回:模拟数据集(DataFrame)"""np.random.seed(42) # 固定随机种子,结果可重复random.seed(42)# 1. 生成基础字段passenger_id = np.arange(1, n_samples+1) # 乘客IDsex = np.random.choice(['male', 'female'], size=n_samples, p=[0.6, 0.4]) # 性别(男60%,女40%)pclass = np.random.choice([1, 2, 3], size=n_samples, p=[0.2, 0.3, 0.5]) # 船票等级(1=头等舱20%,2=二等舱30%,3=三等舱50%)embarked = np.random.choice(['S', 'C', 'Q'], size=n_samples, p=[0.7, 0.2, 0.1]) # 登船港口(S=70%,C=20%,Q=10%)breakfast = np.random.choice(['Coffee', 'Tea', 'Milk'], size=n_samples) # 早餐选择(均匀分布)# 2. 生成连续特征(含缺失值、异常值)# 年龄:正态分布(均值30,标准差10),10%缺失,1%异常值(100岁)age = np.random.normal(30, 10, n_samples).astype(int)age[np.random.choice(n_samples, int(n_samples*0.01), replace=False)] = 100 # 异常值# 直接设置nan(自动转为float类型,保留数值特性)age[np.random.choice(n_samples, int(n_samples*0.1), replace=False)] = np.nan # 缺失值# 船票价格:对数正态分布(均值3,标准差1),1%异常值(1000美元)fare = np.round(np.exp(np.random.normal(3, 1, n_samples)), 2)fare[np.random.choice(n_samples, int(n_samples*0.01), replace=False)] = 1000 # 异常值# 行李重量:正态分布(均值30,标准差10),1%异常值(1000kg)luggage_weight = np.clip(np.random.normal(30, 10, n_samples).astype(int), 0, None)luggage_weight[np.random.choice(n_samples, int(n_samples*0.01), replace=False)] = 1000 # 异常值# 3. 生成家庭相关特征(SibSp:兄弟姐妹/配偶数量;Parch:父母/子女数量)sibsp = np.clip(np.random.poisson(lam=1, size=n_samples), 0, 5)parch = np.clip(np.random.poisson(lam=1, size=n_samples), 0, 5)# 4. 生成目标变量(Survived:生存情况)# 基础规则:女性生存率80%,男性20%;头等舱生存率更高;年轻人生存率更高survived = np.where(sex == 'female', np.random.choice([0, 1], size=n_samples, p=[0.2, 0.8]),np.random.choice([0, 1], size=n_samples, p=[0.8, 0.2]))survived = np.where(pclass == 1, np.minimum(survived + np.random.choice([0,1], p=[0.8,0.2], size=n_samples), 1), survived)# 使用np.isnan判断缺失值(~表示取反,保留非缺失值)survived = np.where((~np.isnan(age)) & (age < 30), np.minimum(survived + np.random.choice([0,1], p=[0.9,0.1], size=n_samples), 1), survived)# 5. 调整生存分布(接近真实泰坦尼克号的38%生存率)if survived.mean() > 0.4:adjust_idx = np.where(survived == 1)[0][:int((survived.mean()-0.38)*n_samples)]survived[adjust_idx] = 0elif survived.mean() < 0.36:adjust_idx = np.where(survived == 0)[0][:int((0.36-survived.mean())*n_samples)]survived[adjust_idx] = 1# 6. 组合成DataFramedata = pd.DataFrame({'PassengerId': passenger_id,'Survived': survived,'Sex': sex,'Age': age,'Pclass': pclass,'SibSp': sibsp,'Parch': parch,'Fare': fare,'Embarked': embarked,'Breakfast': breakfast,'LuggageWeight': luggage_weight})return datadef main():"""主程序:数据处理→模型训练→评估"""# 1. 生成模拟数据print("=== 1. 生成模拟数据 ===")data = generate_titanic_data(n_samples=1000)print("数据生成完成(前5条):")print(data.head())# 2. 数据预处理print("\n=== 2. 数据预处理 ===")# 分离特征(X)和目标变量(y):排除无意义的PassengerIdX = data.drop(columns=['PassengerId', 'Survived'])y = data['Survived']# 处理离散特征:LabelEncoder编码(XGBoost支持类别特征,无需OneHot)categorical_feats = ['Sex', 'Pclass', 'Embarked', 'Breakfast']le = LabelEncoder()for feat in categorical_feats:X[feat] = le.fit_transform(X[feat])# 检查缺失值(XGBoost会自动处理缺失值,无需填充)print("缺失值情况:")print(X.isnull().sum())# 划分训练集(70%)和测试集(30%):stratify=y保持类别分布一致X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)print(f"训练集样本数:{X_train.shape[0]},测试集样本数:{X_test.shape[0]}")# 3. 定义模型和参数网格(重点调参:正则化、列采样、直方图优化)print("\n=== 3. 定义模型和参数网格 ===")model = xgb.XGBClassifier(objective='binary:logistic', # 二分类问题eval_metric='logloss', # 评估指标(对数损失)random_state=42, # 固定随机种子use_label_encoder=False # 不使用内置LabelEncoder(已手动处理))# 参数网格:覆盖正则化、列采样、直方图优化、学习率、行采样param_grid = {# 正则化参数(防止过拟合)'max_depth': [3, 5, 7], # 树的最大深度(越小越简单)'gamma': [0.1, 0.5], # 叶子分裂阈值(越大越难分裂)'reg_lambda': [1, 2], # L2正则系数(越大惩罚越重,原参数名lambda为Python关键字)# 列采样(减少特征相关性)'colsample_bytree': [0.7, 0.8], # 每棵树使用的特征比例(0.7=70%)# 直方图优化(加速训练)'max_bin': [64, 128], # 每个特征的最大bin数(越小速度越快)# 其他调参'eta': [0.1, 0.2], # 学习率(越小模型越稳定)'subsample': [0.8, 0.9] # 行采样(每棵树使用的样本比例)}# 4. 网格搜索调参(5折交叉验证,寻找最佳参数)print("\n=== 4. 网格搜索调参(5折交叉验证) ===")grid_search = GridSearchCV(estimator=model,param_grid=param_grid,cv=5, # 5折交叉验证scoring='accuracy', # 用准确率评估模型性能n_jobs=-1, # 使用所有CPU核心加速verbose=1 # 显示调参进度)# 训练网格搜索(耗时较长,耐心等待)grid_search.fit(X_train, y_train)# 输出最佳参数print("\n最佳参数组合:")print(grid_search.best_params_)# 5. 使用最佳参数训练的最终模型(GridSearchCV已自动refit)print("\n=== 5. 最佳参数模型(已自动训练) ===")best_model = grid_search.best_estimator_# 6. 模型评估(测试集)print("\n=== 6. 模型评估(测试集) ===")y_pred = best_model.predict(X_test)# 准确率(Accuracy)accuracy = accuracy_score(y_test, y_pred)print(f"测试集准确率:{accuracy:.4f}")# 混淆矩阵(Confusion Matrix):显示真阳性、真阴性、假阳性、假阴性print("\n混淆矩阵:")print(confusion_matrix(y_test, y_pred))# 分类报告(Classification Report):包含 precision、recall、f1-scoreprint("\n分类报告:")print(classification_report(y_test, y_pred))# 7. 特征重要性分析(可选):了解模型关注的特征print("\n=== 7. 特征重要性分析 ===")feature_importance = pd.DataFrame({'特征名称': X.columns,'重要性': best_model.feature_importances_}).sort_values(by='重要性', ascending=False)print(feature_importance)# 运行主程序
if __name__ == "__main__":main()三、代码使用说明
1. 环境准备
需要安装以下Python库(用pip命令安装):
pip install pandas numpy scikit-learn xgboost
2. 代码运行
直接运行脚本,会自动完成以下步骤:
生成模拟数据(1000条);
数据预处理(离散特征编码、缺失值保留);
划分训练集和测试集;
网格搜索调参(寻找最佳参数组合);
用最佳参数训练模型(GridSearchCV自动完成);
评估模型性能(准确率、混淆矩阵、分类报告);
输出特征重要性。
3. 关键参数说明
代码中重点调参的参数对应XGBoost的核心技术:
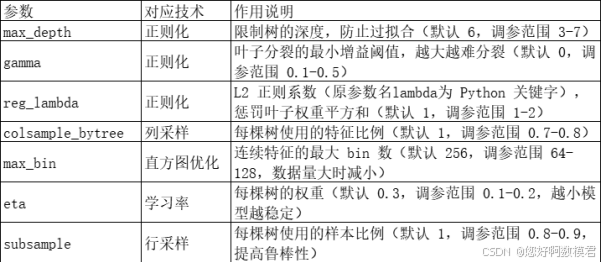
4. 结果解读
准确率:测试集上的预测准确率(越高越好,通常>0.8为良好);
混淆矩阵:左上角为“真阴性”(实际死亡,预测死亡),右上角为“假阳性”(实际死亡,预测生存);左下角为“假阴性”(实际生存,预测死亡),右下角为“真阳性”(实际生存,预测生存);
分类报告:precision(精确率,预测为正的样本中实际为正的比例)、recall(召回率,实际为正的样本中预测为正的比例)、f1-score(两者的调和平均,综合衡量);
特征重要性:显示模型最关注的特征(比如“Sex”“Pclass”通常是 top 特征,符合泰坦尼克号的真实规律)。
5. 调参建议(小白版)
若过拟合(训练集准确率高,测试集低):增大max_depth的取值范围?不,过拟合应该减小max_depth,增大gamma或reg_lambda;
若训练速度慢:减小max_bin(比如从128调到64);
若特征太多:减小colsample_bytree(比如从0.8调到0.7);
若模型不稳定:减小eta(比如从0.2调到0.1),增大subsample(比如从0.8调到0.9)。
四、总结
本代码完整演示了XGBoost在数模中的应用流程,重点突出了正则化(防止过拟合)、列采样(提高鲁棒性)、直方图优化(加速训练)三大核心技术。小白可以通过调整参数网格中的取值,观察模型性能的变化,逐步掌握XGBoost的调参技巧。