数据库技术总结
前言
什么是数据库?
存储数据的仓库。
常见的数据库有哪些?
- ————SQL Server(数据库较大 5G)
- ————Access
- ————Oracle(大型数据库700多兆-200多兆)(付费)
- ————Mysql(50多兆)
- ————DB2(付费)
- ————人大金仓
1、数据库发展史
1、程序管理阶段(20世纪50年代中期)
特点:数据不能长期保存
2、文件系统阶段(20世纪50年代后期至60年代后期)
特点:数据缺乏独立性
3、数据库系统阶段(20世纪60年代后期)
特点:实现数据共享,减少数据冗余
2、数据库术语
1、关系 :一个关系就是一个二维表
2、属性 :表中的一列称为一个属性,一般习惯称为列或者字段,表中的列不能重名。
3、元祖 :表中的一行称为一个元祖,一般习惯称为行或者记录。
4、主键 :表示表中某个列或者几个列的集合,用于唯一标识表中每一行记录。一张表中只能有一个主键,被定义为主键的列,其列值是唯一且非空的。
3、数据库技术
3.1 Oracle 数据库及数据库连接工具
Oracle 数据库是美国ORACLE公司提供的一款关系型数据库,可跨平台,安全性高,市场主要数据库版本有:Oracle9i, Oracle10g, Oracle11g, oracle12c
数据库连接工具:
- SQL Developer :Oracle公司自己研发

- PL/SQL Developer :第三方

- Navicat 第三方

3.2 Oracle 数据库登录
开始--搜索程序和文件--cmd--Enter--Dos 窗口
1)输入: sqlplus
2)输入用户名:system
3)输入密码:123456
连接到:
Oracle Database 10g Express Edition Release 10.2.0.1.0 - Production
SQL>
3.3 表空间
表空间就是用来存储数据库对象(表,视图,索引、序列)的容器。表和表空间的关系就是文件和文件夹的关系一样,所有的数据库对象都存在指定的表空间中,但是主要存储表,所以称为表空间。
数据库创建的时候,系统会默认创建一个SYSTEM表空间。
通过system表空间可以创建其他表空间。
一个数据库中,可以只有一个表空间(system),也可以有若干个表空间。
3.4 数据类型
数据类型:字符型、数值型、日期型。
3.4.1 字符型
char 、varchar、varchar2
char(n):用来表示固定长度的字符串,n代表字符串的长度(个数),当实际保存的数据长度小于n时,在该字符串的右边使用空格补齐。char(10)保存‘zhang’会占用系统10个存储空间。
varchar(n):用来表示可变字符串类型,n代表能保存字符串的最大长度,当要保存的字符串长度小于n时,会按照实际长度进行保存。
varchar(10)保存‘zhang’会占用5个系统存储工空间。
varchar2 使用oracle 公司自定义的类型,而且兼容性特别好,在实际企业中,建议使用vachar2 代替varchar。
3.4.2 数值型
number 可以用来表示整数和小数。
number(n)用来保存整数,n代表能保存整数的最大位数。
例如:number(3) 999
number(n,m)可以用来保存整数或者小数,n代表有效数字(整数位数+小数位数)最大位数,m代表小数的最大位数。n-m代表整数的最大位数。
例如:number(7,2) 12345.67
5.4.3 日期型
date : 用来保存日期时间类型,包含:年 月 日 时 分 秒
默认日期格式:DD-MON月-YY
DD:表示几号
MON:表示几月
YY:表示年份
3.5 SQL语句(结构化查询语句)
结构化查询语句,通过SQL语句对数据库进行各种操作,掌握SQL就可以操作任意一款数据库。
SQL语句分类如下:
3.5.1 DDL 数据定义语句
主要用来创建,删除,修改表的结构。
创建-----create
删除-----drop
修改----alter
3.5.2 DML 数据操纵语句
主要用来操纵表中的数据。
插入----insert
更新(修改)----update
删除----delete
3.5.3 TCL 事务控制语句
主要用来管理数据库的事务。
提交事务----commit
回滚事务----rollback
3.5.4 DQL 数据查询语句
查询--------select
3.6 创建表
格式:
create table 表名(
列名1 数据类型 primary key,
列名2 数据类型,
列名3 数据类型,
........
列名n 数据类型
);
create table person1(
id number(4) primary key,
name varchar2(20),
age number(3),
adr varchar(50)
);
create table person2(
id number(4) primary key,
name varchar2(30),
age number(3)
);
3.7 查看表结构
格式:desc 表名;
案列:查看 person1 表结构
desc person1;
3.8 插入(insert )语句
3.8.1 向全部列插入数据
insert into 表名 values(列值1,列值2,列值3.......);
说明:values中列值的顺序必须跟表结构是对应的。
验证:select * from 表名;
案列:向person2表中,插入2条记录
desc person2;
insert into person2 values(1,'李明',50);
insert into person2 values(2,'tom',20);
3.8.2 向指定列插入数据
insert into 表名(列名1,列名2,列名3....) values(列值1,列值2,列值3......);
说明:表中列名必须和values中的列值是一一对应的关系。
案例:向person1表中插入数据
insert into person1(id,name) values(10,'张飞');
insert into person1(id,age) values(11,120);
insert into person1(id,name) values(12,'关羽');
insert into person1(id,adr) values(13,'北京');
update peeson1 set name='yyp' where id=11;
update person1 set age=100 where id=12;
案例:
insert into person3(id,name) values(101,'古洞青');
insert into person3(id,address) values(102,'北京');
insert into person3(id,name) values(103,'郑元畅');
select * from person3;
3.9 修改(更新)语句
格式:
update 表名 set 列名1=该列新值,列名2=该列新值....... where 条件;
案例:修改person3 表中编号是1将姓名修改为 张丹丹
update person3 set name='张丹丹' where id=1;
update person3 set address='成都' where name='古洞青';
说明:如果没有where条件将修改表中全部数据。
案例:修改person3表,将地址修改为上海
update person3 set address='上海';
案例:修改person1 表中将年龄改为20
update person1 set age=20;
3.10 删除表中的数据
3.10.1 delete 删除
格式: delete from 表名 where 条件;
说明:如果没有where条件将修改表中全部数据。
案例:删除person3表中编号是101的记录
delete from person3 where ID=101;
案列:删除person3表中姓名是张无忌的记录
delete from person3 where name='张无忌';
案例:删除person3中全部数据
delete from person3;
3.10.2 truncate 删除
格式: truncate table 表名;
说明:直接删除表中全部数据,而且被删除的数据无法恢复,工作过程中尽量不用。
案例:删除person2表中全部数据。
truncate table person2;
案例:删除person1表中全部数据
truncate table person1;
3.11 删除表
格式:drop table 表名;
案例:删除person1 、person2、person3表
drop table person1;
drop table person2;
drop table student;
3.12 查询语句
3.12.1 没带条件的查询语句
1)查询表中全部列的数据
格式:select * from 表名;
select * from emp;
emp --------员工表
select * from dept;
dept ------部门表
select * from salgrade;
salgrade------工资等级表
2)查询表中指定列的数据
格式: select 列名1,列名2,列名3....... from 表名;
案例:查询emp表中,所有员工的编号empno,姓名,ename,职位,job
select empno,ename,job from emp;
3.12.2 给列起别名
1)使用as给列起别名
格式: select 列名1 as 别名1,列名2 as 别名2,列名3 as 别名3...... from 表名;
案例:查询emp表中,员工编号,姓名,职位,上级领导编号,入职时间,给每个列起别名
select empno as 员工编号,ename as 员工姓名,job as 职位,mgr as 上级领导编号,hiredate as 入职时间 from emp;
练习:查询dept表中,部门编号deptno,部门名称,部门地址,给每列起别名
select deptno as 部门编号,dname as 部门名称,loc as 部门地址 from dept;
2)使用空格给列起别名
格式: select 列名1 别名1,列名2 别名2,列名3 别名3 ......from 表名;
案例:查询emp表中,员工姓名ename,职位job,上级领导编号mgr,入职时间hiredate,工资sal,奖金comm,部门编号deptno,给每一列取别名。
select ename 员工姓名,job 职位,mgr 上级领导编号,hiredate 入职时间,sal 工资,comm 奖金,deptno 部门编号 from emp;
3.12.3 排序(order by)
格式:
select */列名 from 表名 order by 列名1 asc/desc,列名2 asc/desc;
说明:asc 默认 升序排列
desc 降序排列
根据一列或者几列的列值,把查询回来的数据进行升序或者降序排列
查询emp表中,员工的姓名,职位,工资,根据员工的工资进行升序排列;
select ename,job,sal from emp
order by sal asc;
练习:查询emp 表中,员工的编号,姓名,职位,根据员工的编号进行降序排列
select empno,ename,job from emp
order by empno desc;
3.12.4 去掉重复的列值(distinct)
格式:select distinct 列名 from 表名;
案列:查询emp表中,员工职位的名称
select distinct job from emp;
3.12.5 带条件的查询语句
格式:select */列名 from 表名 where 条件;
说明:条件包含关系运算符,逻辑运算符
案例:查询emp表中,30号部门下,所有员工的编号,姓名,部门编号
select empno,ename,deptno from emp where deptno=30;
说明:关系运算符 > < = ,>= ,<= ,<> /!=(不等于)
案例:查询emp表中,工资高于2000的所有员工的编号,姓名,职位,工资
select empno,ename,job,sal from emp
where sal>2000;
案例:查询emp表中,职位是'CLERK '员工的姓名,职位,工资
select ename,job,sal from emp where job='CLERK';
案例:查询emp表中,工资不等于1250的所有员工的编号,姓名,工资,根据工资降序排列
select empno,ename,sal from emp where sal<>1250
order by sal desc;
select empno,ename,sal from emp where sal!=1250
order by sal desc;
3.12.5.1 该列的列值为空(is nul)
案例:查询emp表中,没有上级领导的员工信息
select * from emp where mgr is null;
案例:查询emp表中,奖金为空的员工编号,姓名,工资,奖金
select empno,ename,sal,comm from emp
where comm is null;
3.12.5.2 该列列值不为空(is not null)
案例:查询emp表中,有上级领导的员工信息
select * from emp where mgr is not null;
案例:查询emp表中,奖金不为空的员工编号,姓名,工资,奖金
select empno,ename,sal,comm from emp where comm is not null;
3.12.5.3 模糊查询(like)
格式:
select 列名 from 表名 where 列名 like 条件;
说明:A.% 表示0个或者多个任意字符
B. _ 表示任意1个字符
案例:查询emp表中,员工的姓名的第一个字母是M的所有员工的姓名
select ename from emp where ename like 'M%';
案例:查询emp表中,姓名中包含字母N,的员工姓名
分析:Nddd fjN fdgNdgh N
select ename from emp where ename like '%N%';
案例:查询emp表中,姓名倒数第2个字母是N 的员工姓名
分析:Nf GUNJ eNf
select ename from emp where ename like '%N_';
select ename from emp where ename like '%N__';
3.12.5.4 逻辑运算符
or and not
1)and 并且 用来连接多个并且关系的表达式(条件)
案例:查询emp表中,工资在1000-3000之间的,所有员工的编号,姓名,职位,工资
select empno,ename,job,sal from emp where sal>1000 and sal<3000;
案例:查询emp表中,30号部门并且职位是SALESMAN的员工的编号,姓名,职位,部门编号
select empno,ename,job,deptno from emp
where deptno=30 and job='SALESMAN';
案例:查询emp表中,工资高于2500并且职位是MANAGER的所有员工的编号,姓名,职位,工资
select empno,ename,job,sal from emp
where sal>2500 and job='MANAGER';
扩展:查询emp 表中,姓名中包含N并且有上级领导编号的员工的编号,姓名,上级领导编号mgr
select empno,ename,mgr from emp
where ename like '%N%' and mgr is not null;
2) or 或者
案例:查询emp表中,工资高于2000或者部门编号为30号的所有员工的编号,姓名,职位,工资,部门编号
select empno,ename,job,sal,deptno from emp
where sal>2000 or deptno=30;
案例:查询emp表中,工资小于2000或者没有上级领导编号的员工的编号,姓名,职位,工资,部门编号
select empno,ename,mgr,sal from emp
where sal<2000 or mgr is null;
3)not 非
案例:查询emp表中,工资不等于1250的,员工的编号,姓名,工资
select empno,ename,sal from emp
where sal <>1250;
select empno,ename,sal from emp where not sal=1250;
案例:查询emp中,姓名中不包含字母N 的员工的编号,姓名
select empno,ename from emp where ename not like '%N%';
select empno,ename from emp where not ename like '%N%';
3.12.5.5 between and
格式:
select 列名 from 表名 where 列名 between 初值 and 终值;
说明:查询该列的列值,从初值到终值之间 的值;
【初值,终值】
案例:查询emp表中,工资在1250到3000之间的所有员工的编号,姓名,工资(题目要求取边界值时写=)
select empno,ename,sal from emp where sal>1250 and sal<3000;
select empno,ename,sal from emp where sal between 1250 and 3000;
案例:查询emp表中,员工的编号是7369、7499、7521、7902的员工的全部信息
select * from emp where empno=7369 or empno=7499 or empno=7521 or empno=7902;
select * from emp where empno in(7369,7499,7521,7902);
3.12.5.6 in
用来比较一个列中的几个列值。
格式:select 列名 from 表名 where 列名 in(列值1,列值2,列值3.....);
案例:查询emp表中,员工的编号是7369、7499、7521、7902的员工的全部信息-
select * from emp where empno in(7369,7499,7521,7902);
案例:查询emp表中,职位是CLERK、SALESMAN、ANALYST的所有员工的信息。
select * from emp where job in('CLERK','SALESMAN','ANALYST');
3.12.6 处理空值 的方法
案例:查询emp表中,员工的编号,职位,工资,年薪(工资*12)
select empno,job,sal,sal*12 from emp;
案例:查询emp表中,员工的编号,职位,工资,奖金,年薪(工资*12+奖金)
select empno,job,sal,comm,sal*12+comm from emp;
select empno,job,sal,comm,sal*12+nvl(comm,0) from emp;
说明:任何数值类型使用“+”跟null连接结果为null。
示例:13555+null=null
nvl函数:专门处理null值问题
nvl(列名,数值) 如果列值为null,将null变成数值;如果列值不为null,列值不变,正常计算。
select empno,job,sal,comm,sal*12+nvl(comm,1000) from emp;
3.12.7 聚合函数
count sum avg min max
1)count(列名/*)
* :统计表中数据的总条数(包括null都统计)
列名:统计该列中列值不为null的数据的总条数
案例:查询emp表中,员工的总数量
select count(*) from emp;
案例:查询emp表中,奖金不为null员工总数的条数
select count(comm) from emp ;
案例:查询emp中职位种类的个数
select count(distinct job) from emp;
select distinct job from emp;
2)sum(列名)统计该列中所有列值的累加之和
聚合函数在计算的过程中,遇到数值为null的情况,自动过滤为null,不参与计算
案例:查询emp表中所有员工工资之和
select sum(sal) from emp;
案例:查询emp表中所有奖金之和
select sum(comm) from emp;
3)avg(列名) 统计该列中所有列值的平均值
案例:查询emp表中,工资的平均值
select avg(sal) from emp;
案例:查询emp表中,奖金的平均值
select avg(comm) from emp;
4)min(列名) 统计该列中的最小值
案例:查询emp表中,员工编号的最小值
select min(empno) from emp;
案例;查询emp表中,员工的最低工资
select min(sal) from epm;
5)max(列名)统计该列中的最大值
案例:查询emp表中,员工的最高工资
select max(sal) from emp;
3.12.8 分组(group by)
解释:根据某一个列,把数据分成几组(相同的分成一组),可以对每一组数据使用聚合函数,聚合函数经常和分组查询一起使用。
格式:select 列名/聚合函数 from 表名
where 条件
group by 列名
order by 列名/聚合函数 asc/desc;
案例:查询emp表中,每一个部门的编号,部门人数,部门工资总和,根据部门人数进行降序排列
select deptno ,count(*),sum(sal) from emp
group by deptno
order by count(*) desc;
案例:查询emp表中,每个职位的名称,职位的人数总和,最高工资,最低工资,根据人数总格进行升序排列
select job,count(*),max(sal),min(sal) from emp
group by job
order by count(*) asc;
案例:查询emp表中,工资在1000-5000之间的员工信息,每个部门的编号,部门的最低工资,部门的最高工资,根据部门编号降序排列
select deptno,min(sal),max(sal) from emp
where sal>1000 and sal<5000
group by deptno
order by deptno desc;
案例:查询emp表中,姓名中不包含字母C,每个职位的名称,人数,最高工资,平均工资,首先根据人数进行升序排列,如果人数一致,根据平均工资降序排列。
select job,count(*),max(sal),avg(sal) from emp
where ename not like '%C%'
group by job
order by count(*) asc,avg(sal) desc;
3.12.9 having 语句
说明:对分组以后的数据,再次进行过滤,经常和聚合函数一起使用。
比较having和where
where 条件针对的是整张表,
having 针对的是分组后的数据,而且必须和group by 语句一起使用
Select列名/聚合函数from 表名
where 条件
group by 列名
having 条件
order by 列名/聚合函数 asc/desc;
执行顺序:首先执行where 条件,对表中的全部数据进行过滤,然后group by 根据列名进行分组,之后对分组后的每一组数据使用聚合函数,再使用having 语句,对分组后的数据再次进行过滤,最后使用order by 进行排序。
案例:查询emp表中,部门的平均工资高于2000的部门编号,部门人员,部门平均工资、部门的最高工资,根据部门人数进行升序排序,如果部门人数一致,根据部门平均工资降序排列。
select deptno,count(*),avg(sal),max(sal) from emp
group by deptno
having avg(sal)>2000
order by count(*) asc,avg(sal) desc;
案例:查询工资在1000-5000之间,每个职位的名称,人数,最高工资,要求职位的最高工资低于2500,根据人数进行降序排列。
select job,count(*),max(sal) from emp
where sal between 1000 and 5000
group by job
having max(sal)<2500
order by count(*) desc;
案例:查询emp表中姓名不是以字母M 开头并且工资高于1000的员工信息,查询每个部门的编号。部门的人数。部门的工资综合,最高工资,要求部门的最高工资低于3000,根据部门编号进行升序排列。
select deptno,count(*),sum(sal),max(sal) from emp
where ename not like 'M%' and sal>1000
group by deptno
having max(sal)<3000
order by deptno asc;
3.12.10 常用字符处理函数
1)length(列名/字符串)
统计出列值/字符串字符的个数
案例:查询emp表中,员工的姓名以及该姓名字符的个数。
select ename,length(ename) from emp;
2)dual 虚拟表,经常用于各种函数的测试
案例:查询'helloworld'字符串中字符的个数
select length('helloworld') from dual;
select length(trim(' helloworld ')) from dual;
------------helloworld
3)trim(列名/字符串)
去掉列值/字符串两端的空格
select trim(' 明天 放假 ') from dual;
4)substr(参数1,参数2,参数3)
用于截取字符串
参数1:要截取的字符串/列名
参数2:从哪里开始截取
如果为正数,表示从正数第几个开始截取
如果为负数,表示从倒数第几个开始截取
参数3:表示截取字符串的个数
案例:截取字符串helloworld
select substr('helloworld',4,4) from dual;
案例:查询emp表中,员工de姓名以及姓名最后2个字母
select ename,substr(ename,-2,2) from emp;
select ename,substr(ename,length(ename)-1,2) from emp;
5)拼接字符串
A。使用|| 连接
select '今天星期五' || '明天不上课' || 'fghhtd' from dual;
select ename || job from emp;
B. concat(字符串1/列名1,字符串2/列名2)------不能连接3个字符串
select concat(ename,job) from emp;
3.12.11 常用数值处理函数
1)round(数值,位数)-四舍五入函数
如果位数大于0,表示小数点后保留几位小数,如果位数等于0,不保留小数,如果位数小于0,表示小数点之前第几位进行四舍五入。
select round(37.738,2) from dual;-----37.74
select round(37.738,1) from dual;----37.7
select round(37.738,0) from dual;-----38
select round(37.738,-1) from dual;-----40
select round(37.738,-2) from dual;----- 0
2)trunc(数值,位数) 截取函数
如果位数大于0,保留小数点后几位;
如果位数等于0,表示舍弃小数点后所有数字;
如果位数小于0,表示舍弃小数点前第几位。
select trunc(37.738,2) from dual;-----37.73
select trunc(37.738,0) from dual;------37
select trunc(37.738,-1) from dual;---30
select trunc(37.738,-2) from dual;--------0
3)sqrt(数值) 求平方根
10*10=100,10就是100的平方根
select sqrt(100) from dual;-----10
4)power(底数,指数)---求乘方
select power(2,3) from dual;
3.12.12常用日期处理函数
1)常见的日期格式
yyyy-mm-dd 年月日
yyyy-mm-dd hh24:mi:ss 年月日时分秒
默认日期格式:dd-mon月-yy
2)sysdate 当前系统时间
案例:查询昨天,今天,明天的日期
select sysdae-1,sysdate,sysdate+1 from dual;
3) to_char 函数
把date类型数据按照指定的日期格式,转化为char类型数据
格式:
to_char(列名,'日期某一部分格式')--------- 列名必须是(日期型)
案例:查询当前系统时间的分钟数
select to_char(sysdate,'ss') from dual;
select to_char(sysdate,'mi') from dual;
案例:查询当前系统时间的月份
select to_char(sysdate,'mm') from dual;
案例:查询emp表中,12月份入职的员工的姓名,入职时间
hiredate
select ename,hiredate from emp
where to_char(hiredate,'mm')='12';
4)to_date 函数
把满足特定日期格式的字符串转化为date类型数据,经常用于插入操作
格式:
to_date('日期格式字符串','日期格式')
案例:向emp表中插入2条记录
empno ename hiredate
insert into emp(empno,ename,hiredate) values(1234,'rose',to_date('2018-10-20 17:50:15','yyyy-mm-dd hh24:mi:ss'));
结果:系统默认日期:20-10月-18
insert into emp(empno,ename,hiredate) values (4563,'jack',to_date('2018-08-03','yyyy-mm-dd hh24:mi:ss'));
结果:03-8月-18
3.13 连接查询
说明:由于要查询的数据分布在不同的表中,为了一次获得不同表中的数据,就需要使用连接查询。
格式:
select 别名1.*/列名1,别名2. */列名2.....
from 表1 别名1,表2 别名2........
where 关联条件;
3.13.1 等值连接
说明:2张表的关联条件是通过 = 连接起来的,称为等值连接。
案例:查询emp表中,员工的编号,姓名以及dept表中部门编号,部门名称
select e.empno,e.ename,d.deptno,d.dname
from emp e,dept d
where e.deptno=d.deptno;
关联条件:emp表中的deptno和dept 部门表中的deptno相等
案例:查询emp表中,员工编号,员工姓名,职位,工资以及dept表中 部门名称,部门地址,根据员工的员工编号降序排列
select e.empno,e.ename,e.job,e.sal,d.dname,d.loc
from emp e,dept d
where e.deptno=d.deptno
order by e.empno desc;
案例:查询emp表中,工资高于1000的员工的编号,姓名吗,工资以及dept表中部门编号,名称,以及部门地址,根据部门编号升序排列
select e.ename,e.empno,e.sal,d.deptno,d.dname,d.loc
(select e.ename,e.empno,e.sal,d.*)
from emp e,dept d
where e.sal>1000 and e.deptno=d.deptno
order by e.deptno asc;
案例:查询emp表中,工资在1000-3000之间的员工的编号,姓名,工资以及dept表中全部数据,根据部门编号升序排列,如果部门编号一致,根据员工编号降序排列
select e.empno,e.ename,e.sal,d.*
from emp e,dept d
where sal between 1000 and 3000 and e.deptno=d.deptno
order by e.deptno asc,e.empno desc;
3.13.1 非等值连接
说明:2张表的关联条件不是通过= 连接在一起,称为非等值连接
emp表中的sal(工资),一定在salgrade(工资等级表) 表中losal(最低工资) 和hisal (最高工资)之间
案例:查询emp表中,员工的编号,姓名,工资,以及salgrade表中,该工资的等级,该等级下的最低工资
select e.empno,e.ename,e.sal,s.grade,s.lower
from emp e,salgrade s
where e.sal between s.losal and s.hisal ;
案例:查询emp表中,姓名中不包含字母K的员工编号,工资以及salgrade 表中,该工资的等级,该等级的最高工资,根据员工编号降序排列
select e.empno,e.ename,e.sal,s.grade,s.hisal
from emp e,salgrade s
where e.ename not like '%K%' and e.sal between s.losal and s.hisal
order by e.empno desc;
案例:查询emp表中,工资高于1250并且在10和20号部门,查询员工的编号,姓名,工资,部门编号,以及salgrade表中,工资等级最低工资,根据工资等级进行升序排列,如果工资等级已一致,根据工资降序排列
select e.empno,e.ename,e.sal,e.deptno,s.grade,s.losal
from emp e,salgrade s
where e.sal between s.losal and s.hisal and e.sal>1250 and e.deptno in(10,20)
order by s.grade asc,e.sal desc;
select e.empno,e.ename,e.sal,e.deptno,s.grade,s.losal
from emp e,salgrade s
where e.sal between s.losal and s.hisal and e.sal>1250 and (e.deptno='10' or e.deptno='20')
order by s.grade asc,e.sal desc;
3.13.3 自连接
说明:如果一张表中,列与列之间存在关联关系,可以使用自连接进行查询
自连接可以将1张表看作成2张表,然后使用等值连接查询
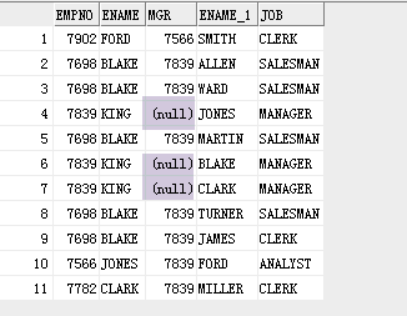
案例:查询emp表中,员工的编号,姓名,职位,工资,上级领导编号,上级领导姓名
分析:emp 员工表 e
emp 领导表 m
员工表中,员工的上级领导编号 等于 领导表中 员工的编号
员工表.mgr=领导表.empno
select e.empno,e.ename,e.job,e.sal,e.mgr,e.deptno,m.ename
from emp e,emp m
where e.mgr=m.empno;
结果:
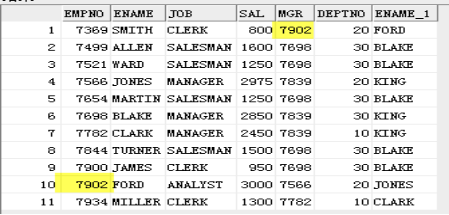
emp表中的内容
emp e emp m
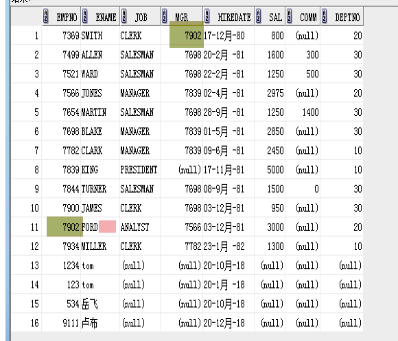
员工表.mgr=领导表.empno
select e.empno,e.ename,e.job,e.sal,e.mgr,e.deptno,m.ename
from emp e,emp m
where e.mgr=m.empno;
where e.empno=m.mgr;
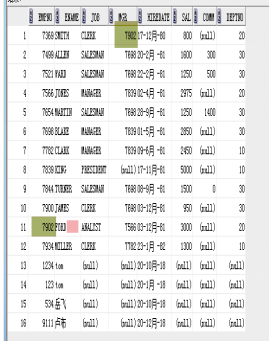
案例:查询emp表中,工资在1000-3000之间的所有员工的编号,姓名,上级领导编号以及上级领导的姓名,上级领导的职位
select e.empno,e.ename,e.mgr,m.ename,m.job
from emp e,emp m
where e.mgr=m.empno and sal >1000 and sal<3000;
正确
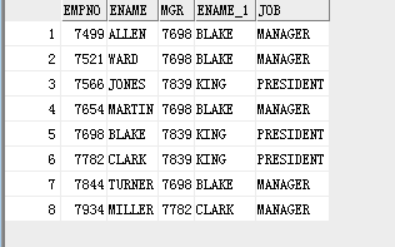
select e.empno,e.ename,e.mgr,m.ename,m.job
from emp e,emp m
where e.empno=m.mgr;
错误结果
3.14 子查询(嵌套查询)
说明:在查询内部又包含一个查询语句
案例1:查询emp表中,工资高于平均工资的员工的编号,姓名,职位,工资
where sal>平均工资
1)求出emp表中员工的平均工资
select avg(sal) from emp;
select empno,ename,job,sal
from emp
where sal>(select avg(sal) from emp);
案例2:查询emp表中,工资高于20号部门最高工资所有员工的编号,姓名,职位,工资
select max(sal) from emp where deptno=20
select empno,ename,job,sal
from emp
where sal>( select max(sal) from emp where deptno=20);
案例3:查询dept表中,部门的名称SALES下的所有员工的编号,姓名,职位,部门编号
select e.empno,e.ename,e.job,d.deptno
from emp e,dept d
where d.dname='SALES' and e.deptno=d.deptno;
1)根据部门名称查询部门编号
select deptno from dept where dname='SALES';
2)根据部门编号查询员工信息
select empno,ename,job,deptno from emp
where deptno=(select deptno from dept where dname='SALES');
案例4:查询dept表中,部门地址是DALLAS下的所有员工的姓名,职位,部门编号
select ename,job,deptno from emp
where deptno=(select deptno from dept where loc='DALLAS');
案例5:查询emp表中,跟员工编号是7521是同一个部门的员工的编号,姓名,职位,部门编号
select deptno from emp where empno=7521;
select empno,ename,job,deptno from emp
where deptno=( select deptno from emp where empno=7521) and empno<>7521;
案例6:创建三张表分别是 Student、Course、Score并插入数据,进行如下查询
--Student表
学员编号 PK
学员姓名
学员性别
学员年龄
入学时间
--Course表
课程编号 PK
课程名称
--Score表
学员编号
课程编号
学员成绩
1、查询学员姓名是'Tom'全部信息
select s.*,c.*,e.score
from student s,course c,score e
where s.sname='Tom' and s.sid=e.sid and e.cid=c.cid;
2、查询学员姓名是'Rose'的平均成绩
select avg(score)
from student s, score e
where s.sname='Rose' and s.sid=e.sid;
3、查询平均成绩高于>60的学员的编号、姓名、平均成绩
1)求出每个学员的平均成绩
select sid,avg(score) from score
group by sid ;
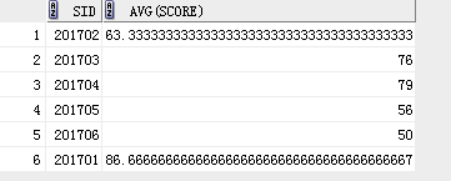
2)平均分数大于60
select sid,avg(score) from score
group by sid
having avg(score)>60;
1).给平均分数表取别名 a(给表取别名 不能用as )
2)给 a表中的avg(score)列取别名 avg
3). 在student表和avg表中关联
select s.sid,s.sname,a.avg
from student s,
(select sid,avg(score) as avg from score
group by sid
having avg(score)>60) a
where s.sid=a.sid;
select s.sid,max(sname)
4、查询学员姓名中含有'o'且平均成绩高于70学员的编号、姓名、平均成绩
select s.sid,s.sname,a.avg
from student s,
(select sid,avg(score) as avg from score
group by sid
having avg(score)>70) a
where s.sid=a.sid and s.sname like '%o%';
5、查询课程编号是004学员的编号、姓名、性别、年龄
select s.sid,s.sname,s.ssex,s.sage
from student s,course c,score e
where c.cid='004' and c.cid=e.cid and e.sid=s.sid;
6、查询和学员编号是 201706 学习同一门课程的学员的编号(201706除外)
select sid
from score
where cid=(select cid from score where sid='201706')
and sid<>201706;
3.15 约束
说明:对创建的表设置一些规则,只有满足这些规则的数据,才可以插入进去,我们把这些规则叫做约束。
常见约束有:
1)主键约束
2)唯一约束
3)检查约束
4)默认值约束
5)非空约束
3.15.1 主键约束
说明:主键约束用来标识表中的数据,避免表中出现重复的数据,被主键约束所修饰的列,该列的列值是唯一且非空的。
一张表中只能有一个主键约束。
1)创建表时添加主键约束
create table work1(
id number(4) primary key,
name varchar2(50),
age number(3)
);
insert into work1 values(1,'mm','23');
2) 复合主键(联合主键)
说明:使用主键约束修饰2个或者2个以上的列的组合值,叫做复合主键
create table work2(
id number(4) ,
name varchar2(40),
age number(3);
sex char(3)
constraint pk_id_name_w2 primary key(id,name)
);
insert into work4 values(1,'李白', 28,'男');
insert into work2 values(1,'杜甫', 30,'男');
insert into work4 values(1,'李白', 28,'男'); X(违反唯一约束)
3)修改表时,添加主键约束
alter table表名 add constraint 约束名 primary key(列名1,列名2.......);
案例:创建一张表work3,id number(4),name varchar2(30),age number(3) ,修改表时,对id天剑主键约束,约束名为pk_id_w3.
create table work3(
id number(4),
name varchar2(30),
age number(3)
);
alter table work3 add constraint pk_id_w3 primary key(id);
案例:创建一张表work4,id number(4),name varchar2(30),age number(3) ,sex char(3),修改表时,对id和name添加主键约束,约束名为pk_id__name_w4.
create table work4(
id number(4),
name varchar2(30),
age number(3),
sex char(3)
);
alter table work4 add constraint pk_id_name_w4 primary key(id,name);
insert into work4 values(1,'李白', 28,'男');
insert into work4 values(1,'dufu', 28,'男');
insert into work4 values(2,'李白', 28,'男');
4)删除主键约束
格式1:
alter table 表名 drop primary key;
案列:删除work1 中主键约束
alter table work1 drop primary key;
格式2:
alter table 表名 drop constraint 约束名;
可以用来删除主键约束,唯一约束,检查约束
案列:删除work3、work4 表中数据
alter table work4 drop constraint pk_id_name _w4 ;
alter table work3 drop constraint pk_id_w3;
3.15.2 唯一约束
说明:用来指定一个或者多个列的组合值,具有唯一性,防止用户在该列上插入重复用的数据。
使用唯一约束修饰的列,该列可以插入null值。
一张表中可以有多个唯一约束.
1) 创建表时,添加唯一约束
create table work5(
id number(4) primary key,
name varchar2(20) unique,
age number(3)
);
insert into work5 values(1,'mmmm',34);
insert into work5(id,age) values(2 ,34);
insert into work5 values(3,'mmmm',30); X 姓名违反唯一约束
2)修改表时,添加唯一约束
alter table 表名 add constraint 约束名 unique(列名1,列名2......);
案列:创建一张表work6
id number(4) Pk
name varchar2(30)
addresss varchar2(50) ,修改表时,对name添加唯一约束,约束条件为uq_name_w6
create table work6(
id number(4) primary key,
name varchar2(30) ,
addresss varchar2(50)
);
alter table work6 add constraint uq_name_w6 unique(name);
案列:创建一张表work7
id number(4) Pk
name varchar2(30)
password varchar2(10)
sal number(7,2)
,修改表时,对name和password添加唯一约束,约束条件为uq_name_pwd_w7
create table work7(
id number(4) primary key,
name varchar2(30) ,
password varchar2(10)
sal number(7,2)
);
alter table work7 add constraint uq_name_pwd_w7 unique(name,password);
insert into work7 values(1,'mm','123',4500.5);
insert into work7 values(2,'yy','123',4500.5);
insert into work7 values(3,'yy','123',4500.5); X 违反唯一约束条件
insert into work7 values(4,'yy','123456',8500.5);
3)删除唯一约束
格式:alter table 表名 drop constraint 约束名;
删除work7 表中唯一约束,约束名为uq_name_pwd_w7
alter table work7 drop constraint uq_name_pwd_w7;
案例:删除work6 表中唯一约束名
alter table work6 drop constraint uq_name_w6;
3.15.3. 检查约束
说明:检查约束就是用于限定某列的列值,必须满足某些特定的条件,避免用户输入非法的数据
1)创建表时,添加检查约束
create table work8(
id number (4) primary key,
name varchar2(80) unique,
sex char(3) check(sex in('男','女')),
age number(3),
email varchar2(30)
);
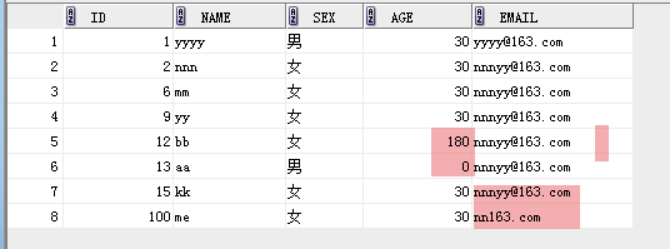
insert into work8 values(1,'yyyy','男',30,'yyyy@163.com');
insert into work8 values(2,'nnn','x',30,'nnnyy@163.com'); 违反检查约束,只能输男或者女,其他不识别
insert into work8 values(2,'nnn','女',30,'nnnyy@163.com');
2)修改表时,添加检查约束
格式:
alter table 表名 add constraint 约束名 check(约束条件);
案例:修改work8表,在age列上条件检查约束,约束名为chk_age_w8
要求年龄必须在1-150之间
alter table work8 add constraint chk_age_w8 check(age between 1 and 150);
insert into work8 values(6,'mm','女',30,'nnnyy@163.com');
insert into work8 values(7,'解决','女',180,'nnnyy@163.com');
insert into work8 values(8,'n哦n','男',0,'nnnyy@163.com');
案例:修改work8表在,email列添加检查约束,chk_emai_w8,要求邮箱中必须包含@
alter table work8 add constraint chk_email_w8 check(email like '%@%');
insert into work8 values(9,'yy','女',30,'nnnyy@163.com');
insert into work8 values(10,'一','女',30,'nn163.com');
3) 删除检查约束
alter tbale 表名 drop constraint 约束名;
案例:删除work8表中,chk_age_w8和chk_email_w8 检查约束
alter table work8 drop constraint chk_age_w8 ;
insert into work8 values(12,'bb','女',180,'nnnyy@163.com');
insert into work8 values(13,'aa','男',0,'nnnyy@163.com');
alter table work8 drop constraint chk_email_w8 ;
insert into work8 values(15,'kk','女',30,'nnnyy@163.com');
insert into work8 values(100,'me','女',30,'nn163.com');
3.15.4 默认值约束
说明:默认值约束就是,给某列指定默认列值,当执行插入操作的时候,如果该列没有列值,系统会自动把默认值作为该列的列值,每列只能指定一个默认值。
1) 创建表时,添加默认值约束
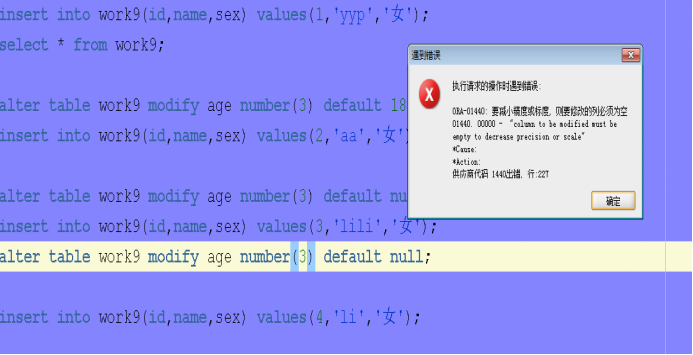
create table work9(
id number(4) primary key,
name varchar2(70) unique,
sex char(3) check(sex in('男','女')),
hiredate date default sysdate,
age number(3)
);
2) 修改表时,添加默认值约束
格式:alter table 表名 modify 列名 数据类型 default 默认值;
案例:修改work9 表,在age列上添加默认值约束,默认值18
alter table work9 modify age number(3) default 18;
3) 删除默认值约束
格式;
alter table 表名 modify 列名 数据类型 default null;
案例;
删除work9表中,age列上的默认值约束
alter table work9 modify age number(3) default null;
案例:删除work9 表中,hiredate列上的默认值约束
alter table work9 modify hiredate date default null;
3.15.5 非空约束
说明:执行插入操作的时候,非空约束修饰的列,该列必须要有列值(该列列值不能为null)
1)创建表时,添加非空约束
create table work10(
id number(4) primary key,
name varchar2(30) unique,
age number(3) check(age between 1 and 130),
hiredate date default sysdate,
address varchar2(50) not null
);
2) 修改表时,添加非空约束
格式:
alter table 表名 modify(列名1 not null)
modify(列名2 not null)
......
modify(列名n not null);
案例:创建表work11,id number(4) pk
name varchar2(50)
age number(3),修改表时对name和age添加非空格式。
create table work11(
id number(4) primary key,
name varchar2(50) ,
age number(3)
);
alter table work11 modify(name not null)
modify(age not null);
insert into work11 values(1,'mm',15);
insert into work11(id,name) values(2,'yy'); age 为空不能插入
3)删除非空约束
格式:
alter table 表名 modify(列名1 null)
modify(列名2 null)
....
modify(列名n null) ;‘’案例:删除work10 表中,address列上的非空约束
alter table work10 modify(address null);
案例:删除work11表中,name和age列上的非空约束
alter table work11 modify(name null) modify(age null);
insert into work11(id) values(10);----------ok
总结:
主键约束(primary key)
唯一约束(unique )
检查约束(check)
默认值约束(default)
非空约束(not null)
3.16 事务控制语句
说明:数据库中,把一系列的操作都封装在一起,要么一起成功,要么一起失败。
3.16.1 提交事务
(commit)-----保存
说明:把对数据库的修改操作,真实的在底层执行,对所有的对表的操作,只有提交事务后,表才能真正发生改变。
create table work12(
id number(4) primary key,
name varchar2(30));
insert into work12 values(1,'mm');
3.16.2 回滚事务
(rollback)----撤销
说明:可以撤销未提交的操作(没有commit的插入数据可以撤销)
insert into work12 values(4,'hh');
insert into work12 values(6,'dd');
3.17 索引
说明:是建立在表中列上的数据库对象,用于提高查询数据的速度。
3.17.1 创建索引
create index 索引名称 on 表名(列名);
案例:创建一张表work13
id number(4) primary key,
name varchar2(30),
age number(3) ,给name 列添加索引。
create table work13(
id number(4) primary key,
name varchar2(30),
age number(3)
);
create index index_name_w13 on work13(name);
说明:
- 被主键约束所修饰的列,系统默认添加一个索引。
- 被唯一约束所修饰的列,系统默认添加一个索引。
3.17.2 删除索引
格式:drop index 索引名称;
案例:删除work13表中,name列上的索引
drop index index_name_w13;