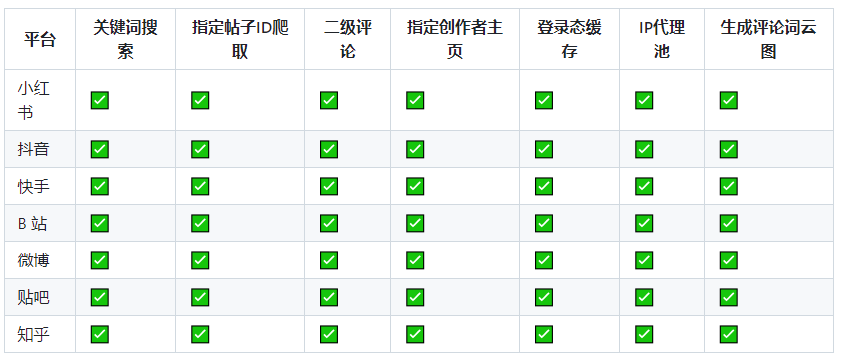
全平台爬虫配置流程
01|30 秒极速体验
环境准备
git clone https://github.com/NanmiCoder/MediaCrawler.git
cd MediaCrawler
pip install -r requirements.txt最小可运行配置
# config.py 片段
PLATFORMS = ['xiaohongshu', 'douyin']
KEYWORDS = ['露营装备']
MAX_PAGE = 10 # 按需调整运行
python main.py首次运行会提示填写代理池与 Cookie,按指引操作即可。
02|实测截图 & 数据样例
| 平台 | 抓取字段 | 单页耗时 |
| 小红书 | 笔记标题、点赞、收藏、图片 URL | 1.8 s |
| 抖音 | 视频描述、播放数、评论数、封面 | 2.1 s |
| B 站 | 视频 BV 号、弹幕数、投币数 | 1.9 s |
导出 CSV 后直接拖进 Excel,透视表 5 分钟出报告。
03|进阶玩法
- 1. 自定义扩展
继承BaseCrawler类,重写parse()与save(),即可接入新平台。 - 2. 定时任务
搭配crontab或 GitHub Actions,每天 9:00 自动跑,钉钉推送日报。 - 3. 合规提醒
作者已内置rate_limit与robots.txt校验,建议再加一层企业代理,避免法律风险。
项目地址(Star 已破 31.2k):
https://github.com/NanmiCoder/MediaCrawler