DataFrame数据的常用方法
DataFrame 是 pandas 库中最为常用的数据结构之一,它是一个二维的、表格型的数据结构,类似于电子表格或者 SQL 中的表。下面我将从多个方面详细介绍 DataFrame 数据形式。
1. 基本概念
DataFrame 由行和列组成,每一列可以是不同的数据类型(如整数、浮点数、字符串等)。它既有行索引(index),又有列索引(columns),可以看作是多个 Series 对象的集合,每个 Series 对应 DataFrame 中的一列。
2. 创建 DataFrame
2.1 从字典创建
可以使用包含列表的字典来创建 DataFrame,字典的键将成为列名,列表中的元素将成为对应列的数据。(注意是按列插入的)
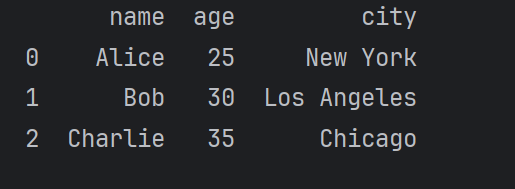
import pandas as pddata = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'City': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
print(df)
- 以下3个创建方法中,df的值都是一样的
2.2 从列表的列表创建
可以使用嵌套列表创建 DataFrame,同时可以指定列名。
data = [['Alice', 25, 'New York'], ['Bob', 30, 'Los Angeles'], ['Charlie', 35, 'Chicago']]
columns = ['Name', 'Age', 'City']
df = pd.DataFrame(data, columns=columns)
print(df)
- 其中data是3行3列的矩阵,columns是1行3列的矩阵。
- df是DataFrame格式,其中数据有3行3列,每一列都有列标。
2.3 从 Series 创建
可以将多个 Series 组合成一个 DataFrame。
name = pd.Series(['Alice', 'Bob', 'Charlie'])
age = pd.Series([25, 30, 35])
city = pd.Series(['New York', 'Los Angeles', 'Chicago'])
df = pd.DataFrame({'Name': name, 'Age': age, 'City': city})
print(df)
3. DataFrame 的属性
3.1 index
行索引,可以是整数、字符串等,用于标识每一行。
print(df.index)

- 意思为df的行下标是从0开始到3结束,每个下标间隔为1
3.2 columns
列索引,用于标识每一列。
print(df.columns)

- 意思为df的列下标有3个,分别是"name,age,city",下标数据类型为object
3.3 shape
返回一个元组,包含 DataFrame 的行数和列数。
rows, columns = df.shape
print(f'行数: {rows}, 列数: {columns}')

- df为3行3列
4. 数据访问
4.1 按列访问
可以使用列名访问单列或多列数据。
# 访问单列
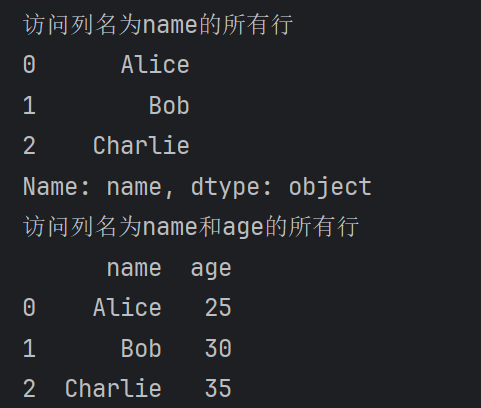
print("访问列名为name的所有数据")
print(df['name'])
# 访问多列
print("访问列名为name和age的所有数据")
print(df[['name', 'age']])
4.2 按行索引访问
可以使用 loc或iloc 方法按索引访问数据。
#使用loc方法按行名列名访问数据
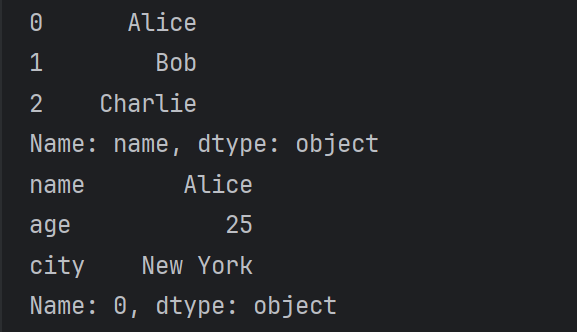
print(df.loc[:,"name"])#打印为列名为name的列
# 使用 iloc 按行整数索引访问
print(df.iloc[0])#打印0第行
4.3 按行和列同时访问
可以使用 iloc 方法同时指定行和列进行访问。
# 使用 iloc 按行整数索引和列整数索引访问
print(df.iloc[0, 0])#打印第0行第0列的数据

5. 数据操作
5.1 数据筛选
可以根据条件筛选数据。
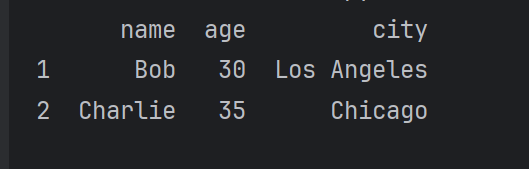
# 筛选 Age 大于 28 的行
filtered_df = df[df['age'] > 28]
print(filtered_df)
5.2 数据修改
可以修改 DataFrame 中的数据。
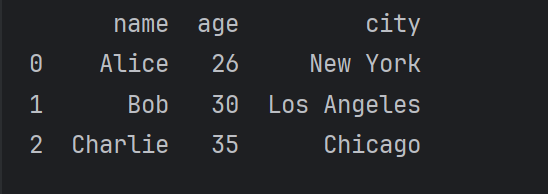
# 修改第 0 行 'age' 列的值
df.loc[0, 'age'] = 26
print(df)
5.3 数据删除
可以删除行或列。
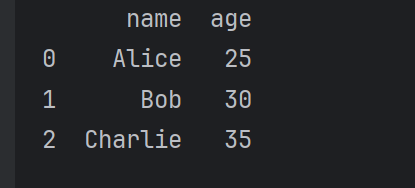
# 删除 'city' 列
df = df.drop('city', axis=1)
print(df)
- axis=0,表示按行方向进行,也就是删除行(默认为axis=0)
- axis=1,表示按列方向进行,也就是删除列
6. 数据处理
6.1 缺失值处理
可以处理 DataFrame 中的缺失值。
import numpy as np
# 创建包含缺失值的 DataFrame
data = {'Name': ['Alice', 'Bob', np.nan],'Age': [25, np.nan, 35]
}
df = pd.DataFrame(data)
# 删除包含缺失值的行
df = df.dropna()
print(df)
6.2 数据排序
可以按列的值对 DataFrame 进行排序。
# 按 'Age' 列升序排序
sorted_df = df.sort_values(by='Age')
print(sorted_df)
7. 数据保存
可以将 DataFrame 保存为文件,如 CSV、Excel 等。
# 保存为 CSV 文件
df.to_csv('data.csv', index=False)
# 保存为 Excel 文件
df.to_excel('data.xlsx', index=False)
8.总代码
以下是本文设计到的所有代码,大家可以复制下来自己运行
import pandas as pd
# 创建示例 DataFrame
data = {'name': ['Alice', 'Bob', 'Charlie'],'age': [25, 30, 35],'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
print(df)
# 使用 loc 方法获取列标签为 'name' 的所有行数据
name_column = df.loc[:, 'name']
print(name_column)
print(df.index)
print(df.columns)
rows, columns = df.shape
print(f'行数: {rows}, 列数: {columns}')
# 访问单列
print("访问列名为name的所有行")
print(df['name'])
# 访问多列
print("访问列名为name和age的所有行")
print(df[['name', 'age']])
#使用loc方法按行名列名访问数据
print(df.loc[:,"name"])#打印为列名为name的列
# 使用 iloc 按行整数索引访问
print(df.iloc[0])#打印0第行
# 使用 iloc 按行整数索引和列整数索引访问
print(df.iloc[0, 0])
# 筛选 Age 大于 28 的行
filtered_df = df[df['age'] > 28]
print(filtered_df)
# 修改第 0 行 'age' 列的值
df.loc[0, 'age'] = 26
print(df)
# 删除 'city' 列
df = df.drop('city', axis=1)
print(df)
# 删除第0行
df = df.drop(0)
print(df)