【2025软考高级架构师】——2024年11月架构真题解析
摘要
本文是一份关于2024年11月软件系统架构设计师考试的真题与解析资料,涵盖了综合知识、案例分析和论文写作三大部分。综合知识部分包含60道选择题,涉及信息安全、数据安全治理、软件维护、设计模式、数据库、网络等多个知识点,每题都配有详细解析。案例分析和论文写作部分则提供了具体的试题内容,但未给出详细答案或解析。整体而言,这份资料为备考者提供了丰富的练习和知识点解析,有助于其全面复习和深入理解相关概念。
1. 综合知识解析
1.1. 安全性可划分为多种特性。其中,(B)保证信息不泄露给未授权的用户、实体或过程;(D)保证信息的完整和准确,防止信息被非法修改。
A. 不可否认性
B. 机密性
C. 可控性
D. 完整性
A. 可控性
B. 不可否认性
C. 机密性
D. 完整性
答案:B D
解析:安全性(security)是指系统在向合法用户提供服务的同时能够阻止非授权用户使用的企图或拒绝服务的能力。安全性是根据系统可能受到的安全威胁的类型来分类的。安全性又可划分为机密性、完整性、不可否认性及可控性等特性。
- 机密性保证信息不泄露给未授权的用户、实体或过程;
- 完整性保证信息的完整和准确,防止信息被非法修改;
- 不可否认性是指防止发送方否认发送过信息;
- 可控性保证对信息的传播及内容具有控制的能力,防止为非法者所用。
1.2. 3.在0到1000之间有( )个整数恰好有一位数字是5。
A. 242
B. 243
C. 225
D. 224
答案:B
解析:百位为5,十位和个位除了5以外各有[012346789]这9种数码,共有9*9=81种编码。
十位为5,百位和个位除了5以外各有[012346789]9种数码,共有9*9=81种编码。【百位为0时即为两位数】
个位为5:百位和十位除了5以外各有[012346789]9种数码,共有9*9=81种编码。【百位和十位同时为0即为一位数】
1.3. 数据安全治理的目标主要包括( )三个方面。数据安全治理体系是组织达成数据安全治理目标需要具备的能力框架,其中数据分类分级属于该体系中的( )。
A. 满足用户需求、满足技术安全规范、促进数据开发利用
B. 满足合规需求、管理用户安全风险、满足数据安全规范
C. 满足用户需求、管理用户安全风险、促进数据开发利用
D. 满足合规要求、管理数据安全风险、促进数据开发利用
A. 数据全生命周期安全层
B. 访问权限控制层
C. 数据安全战略层
D. 基础安全层
答案:D D
解析:数据安全治理的目标主要有三个:满足合规要求、管理数据安全风险、促进数据开发利用。这些目标旨在确保数据安全与业务发展的双向促进,同时保障组织在数据安全方面的合规性。
1.4. 在仓库体系结构风格中,( )用于说明当前数据的状态。
A. 黑板
B. 中央数据结构
C. 独立构件
D. 知识源
答案:B
解析:仓库 (Repository) 是存储和维护数据的中心场所。在仓库风格中,有两种不同的构件:中央数据结构说明当前数据的状态以及一组对中央数据进行操作的独 立构件,仓库与独 立构件间的相互作用在系统中会有大的变化。这种风格的连接件即为仓库与独 立构件之间的交互。
1.5. 下列选项中不能作为预防死锁措施的是( )。
A. 破坏“循环等待”条件
B. 破坏“不可抢占”条件
C. 破坏“互斥”条件
D. 破坏“请求和保持”条件
答案:C
解析:死锁产生的4个必要条件:
- 互斥:某种资源一次只允许一个进程访问,即该资源一旦分配给某个进程,其他进程就不能再访问,直到该进程访问结束。
- 请求和保持:一个进程本身占有资源(一种或多种),同时还有资源未得到满足,正在等待其他进程释放该资源。
- 不可抢占:别人已经占有了某项资源,你不能因为自己也需要该资源,就去把别人的资源抢过来。
- 循环等待:存在一个进程链,使得每个进程都占有下一个进程所需的至少一种资源。
- 产生死锁需要四个条件,那么,只要这四个条件中至少有一个条件得不到满足,就不可能发生死锁了。由于互斥条件是非共享资源所必须的,不仅不能改变,还应加以保证,所以,主要是破坏产生死锁的其他三个条件。
1.6. ( )是在传输层定义的协议。
A. NFS和Telnet
B. TCP和UDP
C. FTP和SMTP
D. IP和ICMP
答案:B
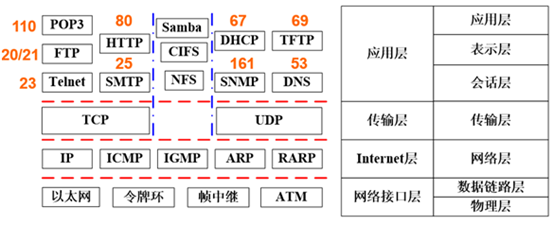
解析:如下图:NFS、Telnet、FTP和SMTP属于应用层。IP和ICMP属于网络层协议,TCP和UDP属于传输层协议,正确答案为B选项。
1.7. 当一个进程被一个更高优先级的进程抢占或其时间片用完时,其状态会从执行态转变为( )。
A. 阻塞态
B. 就绪态
C. 睡眠态
D. 挂起态
答案:B
解析:任务一旦被加载到计算机内存后,通常会处于不同的工作状态,这种状态可随着计算机运行而转变。在嵌入式操作系统中,任务的工作状态最简单的可分为三种:执行态、就绪态和阻塞态。
三种基本状态转换:
- 就绪→执行:处于就绪状态的任务,当任务调度程序为之分配了处理机后,该任务便由就绪状态转变成执行状态。
- 执行→就绪:处于执行状态的任务在其执行过程中,因分配给它的一个时间片已用完而不得不让出处理机,于是任务从执行状态转变成就绪状态。
- 执行→阻塞:正在执行的任务因等待某种事件发生而无法继续执行时,便从执行状态变成阻塞状态。
- 阻塞→就绪:处于阻塞状态的任务,若其等待的事件已经发生,于是任务由阻塞状态转变为就绪状态。
1.8. ( )不属于系统易用性关心的方面。
A. 对系统使用过程的满意程度
B. 系统的学习曲线
C. 系统修复能力
D. 完成操作的效率
答案:C
解析:易用性质量属性场景主要关注用户在使用系统时的容易程度,包括1. 系统的学习曲线、2.完成操作的效率、3. 对系统使用过程的满意程度等。答案选项C选项。
1.9. 执行本单位的任务所完成的职务发明创造,包括退休、调离原单位后或者劳动、人事关系终止后( )内作出的,与其在原单位承担的本职工作或者原单位分配的任务有关的发明创造。
A. 3个月
B. 1年
C. 6个月
D. 18个月
答案:B
解析:《中华人民共和国专利法实施细则》中规定执行本单位的任务所完成的职务发明创造,是指:
- 在本职工作中作出的发明创造;
- 履行本单位交付的本职工作之外的任务所作出的发明创造;
- 退休、调离原单位后或者劳动、人事关系终止后1年内作出的,与其在原单位承担的本职工作或者原单位分配的任务有关的发明创造。
1.10. 一项外观设计专利里面相似设计最多有( )个。
- 10
- 6
- 8
- 5
答案:A
解析:一件外观设计专利申请中的相似外观设计不得超过10项。如果超过10项,审查员会发出审查意见通知书,申请人修改后未克服缺陷的,会驳回该专利申请。
在外观设计专利申请中,相似设计指的是与基本设计具有相同或相似的设计特征,且二者之间的区别点在于局部细微变化、该类产品的惯常设计、设计单元重复排列或者仅色彩要素的变化 等情形。这些相似设计可以作为一件专利申请提出,但数量上有限制。根据《中华人民共和国专法》第三十一条第二款规定,同一产品两项以上的相似外观设计,或者用于同一类别并且成套出售或者使用的产品的两项以上外观设计,可以作为一件申请提出。同时,《专利审查指南》也指出,一件外观设计专利申请中的相似外观设计不得超过10项。
1.11. 质量属性场景是一种面向特定质量属性的需求。它由6部分组成,其中,( )用于描述在激励到达后所采取的行动;( )不属于可用性质量属性场景中的响应度量方式。
A. 响应
B. 环境
C. 制品
D. 刺激源
A. 系统可用时间
B. 故障间隔时间
C. 系统可用时间间隔
D. 数据延迟时间
答案:A D
解析:为了精确描述软件系统的质量属性,通常采用质量属性场景 (Quality Attribute Scenario) 作为描述质量属性的手段。质量属性场景是一个具体的质量属性需求,是利益相关者与系统的交互的简短陈述。
质量属性场景是一种面向特定质量属性的需求。它由6部分组成:
- 刺激源 (Source): 这是某个生成该刺激的实体(人、计算机系统或者任何其他刺激器)。
- 刺激 (Stimulus): 该刺激是当刺激到达系统时需要考虑的条件。
- 环境 (Environment): 该刺激在某些条件内发生。当激励发生时,系统可能处于过载、运行或者其他情况。
- 制品 (Artifact): 某个制品被激励。这可能是整个系统,也可能是系统的一部分。
- 响应 (Response): 该响应是在激励到达后所采取的行动。第一空选择A选项。
- 响应度量 (Measurement): 当响应发生时,应当能够以某种方式对其进行度量,以对需求进行测试。 可用性质量属性场景中的响应度量方式有:系统必须1. 可用的时间间隔、2. 可用时间、3. 系统可以在降级模式下运行的时间间隔、4. 故障修复时间,第二空选择D选项。
1.12. 数据库中有一张人员信息表包含性别属性,要求这个属性的值只能是男或者女,这属于( )。
A. 关系完整性
B. 用户定义完整性
C. 参照完整性
D. 实体完整性
答案:B
解析:关系的完整性约束共分为3类:实体完整性、参照完整性(也称引用完整性)和用户定义完整性。
- 实体完整性 (Entity Integrity)。实体完整性规则要求每个数据表都必须有主键,而作为主键的所有字段,其属性必须是唯一且非空值。
- 参照完整性 (Referential Integrity)。现实世界中的实体之间往往存在某种联系,在关系模型中实体及实体间的联系是用关系来描述的,这样自然就存在着关系与关系间的引用。
- 用户定义完整性 (User Defined Integrity)。 就是针对某一具体的关系数据库的约束条件,反映某一具体应用所涉及的数据必须满足的语义要求,由应用的环境决定。例如,银行的用户账户规定必须大于等于100000,小于999999。题目中提到的是“人员信息表包含性别属性,且这个属性的值只能是男或者女”。这是一个具体的约束条件,用于限制性别属性的取值范围。这个约束不是由数据库系统自带的,而是根据实际应用需求自定义的。
1.13. 在多道批处理系统中有P1和P2两个作业,执行顺序如下,P1(计算40ms,I/O操作60ms,计算20ms),P2(计算100ms,I/O操作40ms,计算40ms),P2比P1晚20ms到达,在不考虑调度和切换时间的情况下完成两道作业最少需要( )时间。
A. 240ms
B. 200ms
C. 260ms
D. 220ms
答案:D
解析:多道批处理操作系统允许多个作业装入内存执行,在任意一个时刻,作业都处于开始点和终止点之间。每当运行中的一个作业由于输入/输出操作需要调用外部设备时,就把CPU交给另一个等待运行的作业,从而将主机与外部设备的工作由串行改变为并行,进一步避免了因主机等待外设完成任务而浪费宝贵的CPU时间。
1.14. RUP是( )的、以体系结构为中心的、迭代和增量的软件开发过程。
A. 测试驱动
B. 领域驱动
C. 数据驱动
D. 用例驱动
答案:D
解析:RUP是用例驱动的、以体系结构为中心的、迭代和增量的软件开发过程。
- 用例驱动:RUP中的开发活动是用例驱动的,即需求分析、设计、实现和测试等活动都是用例驱动的。
- 以体系结构为中心:RUP中的开发活动是围绕体系结构展开的。软件体系结构的设计和代码设计无关,也不依赖于具体的程序设计语言。软件体系结构是软件设计过程中的一个层次,这一层次超越计算过程中的算法设计和数据结构设计。体系结构层次的设计问题包括系统的总体组织和全局控制、通信协议、同步、数据存取、给设计元素分配功能、设计元素的组织、物理分布、系统的伸缩性和性能等。
- 迭代与增量:RUP强调采用迭代和增量的方式来开发软件,把整个项目开发分为多个迭代过程。在每次迭代中,只考虑系统的一部分需求,进行分析、设计、实现、测试和部署等过程;每次迭代是在已完成部分的基础上进行的,每次增加一些新的功能实现,以此进行下去,直至最后项目的完成。
1.15. 下面关于SQL注入的说法错误的是( )。
A. 使用ORM框架可以自动处理查询和参数化输入,但无法减少SQL注入的风险
B. SQL注入是一种常见的攻击方式
C. 使用预处理语句和参数化查询是防范SQL注入的有效方法
D. 通过使用UNION关键字,攻击者可以将多个查询结果合并,从而获取数据库中的敏感信息
答案:A
解析:使用ORM框架可以减少直接编写SQL语句的需求,从而降低SQL注入的风险。
ORM(Object-Relation Mapping) 在关系型数据库和对象之间作一个映射,这样,在具体操纵数据库时,就不需要再去和复杂的 SQL语句打交道,只要像平时操作对象一样操作即可。
1.16. 以下关于SOAP协议说法错误的是( )。
A. SOAP RPC表示远程过程调用和应答的协定
B. 封装和编码规则被定义在相同的XML命名空间中,这样使得定义更加简单
C. SOAP封装定义了一个框架,描述消息中的内容是什么,是谁发送的,谁应当接受并处理它们,以及如何处理它们
D. SOAP绑定定义了SOAP使用哪种协议交换信息
答案:B
解析:教材15.4.3 SOAP 协议,P523。SOAP是在分散或分布式的环境中交换信息的简单的协议,是一个基于XML 的协议。它包括4个部分:SOAP封装 (Envelop), 定义了一个描述消息中的内容是什么,是谁发送的,谁应当接收并处理它以及如何处理它们的框架;SOAP编码规则 (Encoding Rules),用于表示应用程 序需要使用的数据类型的实例;SOAP RPC表示(RPC Representation)是远程过程调用和应答的协定;SOAP绑定(Binding)是使用底层协议交换信息。 虽然这4个部分都作为SOAP的一部分,作为一个整体定义的,但它们在功能上是相交的、 彼此独 立的。特别地,信封和编码规则是被定义在不同的XML命名空间(Namespace) 中,这样使得定义更加简单。SOAP的两个主要设计目标是简单性和可扩展性,这就意味着有一些传统消息系统或分布式对象系统中的某些性质将不是SOAP规范的一部分。例如,分布式垃圾收集 (Distributed Garbage Collection)、成批传送消息、对象引用和对象激活等。
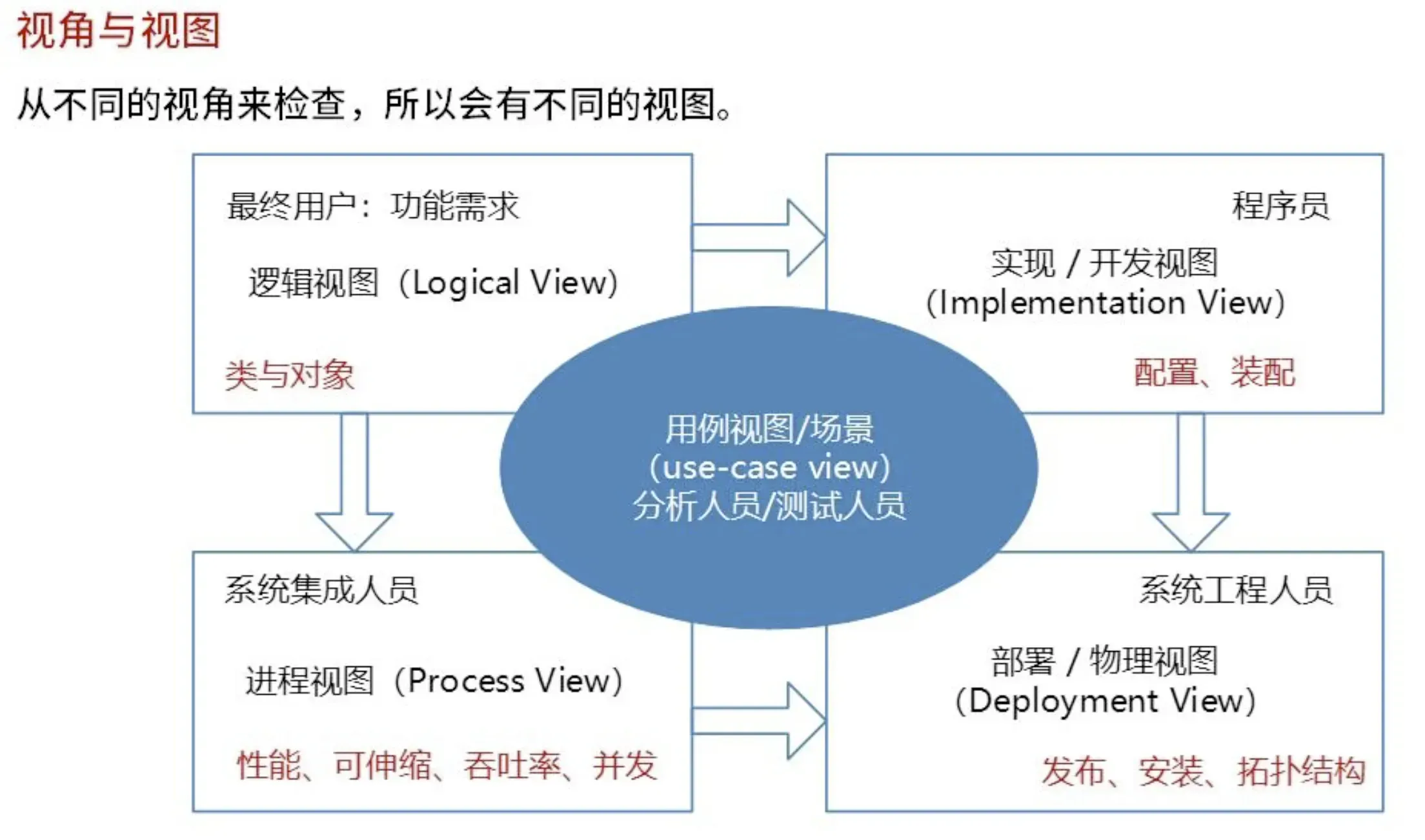
1.17. 在体系结构描述中,典型的4+1视图模型包括( )。
A. 逻辑视图、进程视图、开发视图、物理视图和场景
B. 逻辑视图、进程视图、开发视图、部署视图和场景
C. 逻辑视图、进程视图、开发视图、物理视图和类视图
D. 逻辑视图、进程视图、开发视图、物理视图和部署视图
答案:A
解析:把体系结构描述语言和多视图结合起来描述系统的体系结构,使系统更易于理解,方便系统相关人员之间进行交流,并且有利于系统的一致性检测以及系统质量属性的评估。学术界已经提出若干多视图的方案,典型的包括4+1模型(逻辑视图、进程视图、开发视图、物理视图,加上统一的场景)。
1.18. 路由器工作在OSI体系结构中的( )层。
A. 网络
B. 传输
C. 数据链路
D. 物理
答案:A
解析:路由器工作在OSI体系结构中的网络层,它可以在多个网络上交换和路由数据包。路由器可通过在相互独 立网络中交换路由信息以生成路由表来达到数据包的路径选择。路由表包含网络地址、连接信息、路径信息和发送代价等属性。路由器通常用于广域网或广域网与局域网的互连。
1.19. 在软件架构评估中,( )方法采用效用树这一工具来对质量属性进行分类和优先级排序。效用树的结构包括:( )。
A. SAEM
B. ATAM
C. SAAM
D. CBAM
A. 树根——质量属性——属性分类——质量属性场景(叶子节点)
B. 树根——属性分类——属性描述——质量属性场景(叶子节点)
C. 树根——质量属性——属性描述——质量属性场景(叶子节点)
D. 树根——功能需求——需求描述——质量属性场景(叶子节点)
答案:B A
解析:ATAM 方法采用效用树这一工具来对质量属性进行分类和优先级排序。效用树的结构包括:树根—质量属性—属性分类—质量属性场景(叶子节点)。需要注意的是,ATAM主要关注4类质量属性:性能、安全性、可修改性和可用性,这是因为这4个质量属性是利益相关者最为关心的。
1.20. 有100人,其中会打篮球的有45人,会打乒乓球的有53人,会踢足球的有55人,既会打篮球也会打乒乓球的有28人,既会打篮球也会踢足球的有32人,既会打乒乓球也会踢足球的有35人,三种球都会的有20人,那么三种球都不会的有( )人。
A. 22
B. 23
C. 21
D. 20
答案:A
1.21. 某项目包括A、B、C、D四道工序,各道工序之间的衔接关系、正常进度下各工序所需的时间和直接费用、赶工进度下所需的时间和直接费用如下表所示。该项目每天需要的间接费用为2万元。根据此表,以最短时间完成该项目需要的成本最少为( )万元。
A. 140
B. 150
C. 145
D. 132
答案:D
解析:题目要求计算最短时间完成项目所需要的成本,根据表格可以算出关键路径为ACD,工期11天,此时可以选择压缩ACD中赶工费用最低的工序,分别计算出ABCD赶工1天的费用为:
A:(25*1-5*3)/(3-1)=5
B:(10*5-5*7)/(7-5)=7.5
C:(15*2-5*3)/(3-2)=15
D:(10*2-2*5)/(5-2)=10/3
ACD中赶工费用最低的工序为D,D工序赶工1天之后关键路径有两条分别为AB与ACD,工期10天,此时选择A工序赶工、BC工序同时赶工或者BD工序同时赶工都可以改变关键路径,A工序赶工1天的费用为5,BC工序同时赶工1天的费用为22.5,BD工序同时赶工1天的费用为32.5/3,此时赶工费用最低的方案是A工序赶工,A工序赶工2天之后,此时选择BD工序同时赶工,BD工序最多可以同时赶工2天,BD工序赶工2天之后关键路径最短,为6天。 此时A、B、D活动已经压缩至最少时间,无法继续压缩,而C活动单独并不会缩短项目工期,所以无需对C继续压缩。
综上,最终A赶工2天,D赶工3天,B赶工2天,总费用为间接费用+正常进度的直接费用+赶工所增加的直接费用=(2*6)+(3*5+5*7+3*5+5*2)+(2*5+10/3*3+7.5*2)=122。
(真题本身存在问题,没有正确答案,只能选择最接近的D选项)
1.22. 白盒测试也称为结构测试,主要用于软件单元测试阶段,( )不属于白盒测试。
A. 功能测试(黑盒测试流程)
B. 控制流分析
C. 数据流分析
D. 程序变异测试
答案:A
解析:白盒测试主要是借助程序内部的逻辑和相关信息,通过检测内部动作是否按照设计规格说明书的设定进行,检查每一条通路能否正常工作。白盒测试是从程序结构方面出发对测试用例进行设计。主要用于检查各个逻辑结构是否合理,对应的模块独立路径是否正常以及内部结构是否有效。常用的白盒测试法有控制流分析、数据流分析、路径分析、程序变异等。根据测试用例的覆盖程度,分为语句覆盖、判定覆盖、分支覆盖和路径覆盖等。综上,答案选择A选项。
1.23. 在白盒测试中,关于覆盖标准描述错误的是( )。
A. 判定覆盖比语句覆盖强
B. 满足条件组合覆盖的测试用例一定满足判定/条件覆盖
C. 路径覆盖不能代替条件覆盖和条件组合覆盖
D. 条件覆盖一定包含判定覆盖
答案:D
解析:A选项正确。判定覆盖要求每个判定的每个可能结果(真或假)至少被执行一次。这意味着每个if语句或类似的逻辑判断都需要被测试到其所有分支。语句覆盖只要求程序中的每个可执行语句至少被执行一次,不考虑逻辑分支。因此,判定覆盖在覆盖程度上比语句覆盖更为严格。
B选项正确。条件组合覆盖要求每个判定中的每个条件的所有可能组合至少被执行一次。这意味着它不仅覆盖了每个条件的每个结果(真或假),还考虑了这些条件之间的所有可能组合。由于它包含了每个条件的所有可能结果,因此自然满足判定/条件覆盖,后者要求每个判定中的每个条件至少有一个结果为真和至少有一个结果为假的测试用例。
C选项正确。路径覆盖要求至少执行一次程序中所有可能的路径。虽然路径覆盖在覆盖程度上非常严格,但它并不保证所有条件和条件组合都被测试到。例如,一个复杂的判定结构可能有多个条件和条件组合,而路径覆盖可能只通过其中一些路径,忽略了其他路径中特定条件和条件组合的情况。
D选项错误。条件覆盖要求每个判定中的每个条件至少有一个结果为真和至少有一个结果为假的测试用例。虽然这看似覆盖了判定中的每个条件,但并不保证每个判定的每个结果(即整个判定为真或为假)都被覆盖。
1.24. 在软件的使用过程中,用户往往会对软件提出新的功能与性能要求。为了满足这些要求,需要修改或再开发软件,以扩充软件功能、增强软件性能、改进加工效率、提高软件的可维护性。这种情况下进行的维护活动称为(C)。
A. 预防性维护
B. 适应性维护
C. 完善性维护
D. 改正性维护
答案:C 解析:
- 正确性维护【修BUG】:识别和纠正软件错误/缺陷,测试不可能发现所有错误。
- 适应性维护【应变】:指使应用软件适应环境变化【外部环境、数据环境】而进行的修改。
- 完善性维护【新需求】:扩充功能和改善性能而进行的修改。
- 预防性维护【针对未来】:为了适应未来的软硬件环境的变化,应主动增加预防性的新的功能,以使系统适应各类变化而不被淘汰。经典实例:【专用】改【通用】。
1.25. 以下关于设计模式描述正确的是( )。
A. 解释器模式和代理模式属于同一类型模式
B. 观察者模式属于结构型模式
C. 装饰器模式属于行为型模式
D. 原型模式属于创建型模式
答案:D
解析:设计模式主要有三大类型:创建型模式、结构型模式、行为型模式;
- 创建型设计模式:描述对象如何创建,是为了将对象的创建与使用分离。包括五种:单例、原型、工厂方法、抽象工厂、构建器。
- 结构型模式:描述类或对象如何组织成更大结构,包括7种:代理、适配器、桥接、装饰、外观、享元、组合。
- 行为型模式:描述类或对象之间如何协作完成任务,包括11种:模板方法、策略、命令、职责链、状态、观察者、中介者、迭代器、访问者、备忘录、解释器。
1.26. ( )是对对象实例化过程的抽象,它通过采用抽象类所定义的接口,封装了系统中对象如何创建、组合等信息。
A. 结构型模式
B. 组合型模式
C. 创建型模式
D. 行为型模式
答案:C
解析:设计模式主要有三大类型:创建型模式、结构型模式、行为型模式;
- 创建型设计模式:描述对象如何创建,是为了将对象的创建与使用分离。包括五种:单例、原型、工厂方法、抽象工厂、构建器。
- 结构型模式:描述类或对象如何组织成更大结构,包括7种:代理、适配器、桥接、装饰、外观、享元、组合。
- 行为型模式:描述类或对象之间如何协作完成任务,包括11种:模板方法、策略、命令、职责链、状态、观察者、中介者、迭代器、访问者、备忘录、解释器。
1.27. 有两个关系R(a,b,c)和S(b,c,d),将R和S进行自然连接,得到的结果包含( )列。
A. 4
B. 6
C. 2
D. 5
答案:A
解析:题目所讲的是自然连接,自然连接规则是:
(1)把参与运算的两个关系模式R与S的相同名称列找出来。即:b与c。
(2)针对R与S做b与c属性的等值连接。
这样产生的结果记录为:(a,b,c,d),所以得到的结果包含4列,答案选A。
1.28. 关系操作中,操作的对象和结果都是( )。
A. 元组
B. 记录
C. 集合
D. 列
答案:C
解析:关系操作的特点是操作对象和操作结果都是集合。关系代数运算符有4类:集合运算符、专门的关系运算符、算术比较符和逻辑运算符。
1.29. 给出关系模式R(A,B,C,D)和其属性之间的函数依赖(B→D,AB→C),则R的码是( )。
A. B
B. D
C. AB
D. A
答案:C 解析:从图中可以很直观地看出,入度为零的节点是A与B,从这两个节点的组合出发,能遍历全图,所以AB组合键为候选码。
1.30. 下面关于体系结构风格说法正确的是( )。
A. 管道-过滤器体系结构风格中,过滤器可以并行执行
B. 批处理体系结构风格中,构件可以并行执行
C. 批处理体系结构风格中,数据是增量传输的
D. 黑板体系结构风格和管道-过滤器风格属于数据流体系风格的子风格
答案:A
解析:A选项正确,管道-过滤器风格是一种常见的数据流模型,其中每个处理步骤被封装成一个过滤器组件,组件之间通过数据流管道连接。在这种风格中,过滤器确实可以设计为并行执行,特别是在数据可以被分割成独立部分进行并行处理的情况下。
B选项错误。批处理风格通常指的是一种顺序处理模式,其中数据被成批处理,并且通常按顺序通过一系列处理步骤。这种风格并不强调并行处理,而是侧重于批量处理大量数据。因此,这个选项是不正确的。
C选项错误,在批处理风格中,数据通常是以整个批次的形式传输和处理的,而不是增量传输。
D选项错误,黑板体系结构风格不属于数据流体系风格的子风格。
1.31. 在架构设计中,提高加密级别可以提高安全性,但可能要耗费更多的处理时间,影响系统性能。如果某个机密消息的处理有严格的时间延迟要求,则加密级别可能就会成为架构评估中的一个( )。
A. 权衡点
B. 敏感点
C. 风险点
D. 非风险点
答案:A
解析:敏感点和权衡点是关键的架构决策。敏感点是一个或多个构件(和/或构件之间的关系)的特性。研究敏感点可使设计人员或分析员明确在搞清楚如何实现质量目标时应注意什么。权衡点是影响多个质量属性的特性,是多个质量属性的敏感点。例如,改变加密级别可能会对安全性和性能产生非常重要的影响。提高加密级别可以提高安全性,但可能要耗费更多的处理时间,影响系统性能。如果某个机密消息的处理有严格的时间延迟要求,则加密级别可能就会成为一个权衡点。
1.32. 在用户界面设计过程中,可以分别使用UML( )表示用户界面元素与界面的跳转关系。
A. 类图和顺序图
B. 用例图和顺序图
C. 类图和活动图
D. 用例图和活动图
答案:A
解析:用户界面设计模型的UML表示: 用UML类图表示用户界面元素、用UML顺序图表示用户界面跳转关系。
1.33. 体系结构需求一般来自三个方面,分别是( )。
A. 系统的质量目标、系统的商业目标和系统开发人员的商业目标
B. 系统的功能需求、系统的质量目标和系统的商业目标
C. 系统的质量目标、系统的商业目标和系统开发人员的质量目标
D. 系统的功能需求、系统的商业目标和系统开发人员的商业目标
答案:A
解析:体系结构需求一般来自3个方面,分别是系统的质量目标、系统的商业目标和系统开发人员的商业目标。软件体系结构需求获取过程主要是定义开发人员必须实现的软件功能,使得用户能完成他们的任务,从而满足业务上的功能需求。与此同时,还要获得软件质量属性,满足一些非功能需求。
1.34. 在企业集成技术架构层次中,自下而上依次为(C )。其中,数据集成主要有三种模式,分别为( A)。
A. 网络集成、数据集成、应用集成和会聚集成
B. 网络集成、会聚集成、数据集成和应用集成
C. 网络集成、数据集成、会聚集成和服务集成
D. 网络集成、会聚集成、数据集成和服务集成
A. 数据复制、数据转换和数据融合
B. 数据复制、数据融合和数据抽取
C. 数据联邦、数据复制和基于接口的数据集成
D. 数据抽取、数据复制和数据测试
答案:C A
解析:
企业集成技术架构通常分为四个层次,自下而上依次是:
- 网络集成(Network Integration):提供基础通信与连接层,解决“网络互通”问题。
- 数据集成(Data Integration):解决数据共享与一致性问题,实现不同系统之间的数据交互。
- 会聚集成(Convergence Integration):也称为应用集成(Application Integration)或业务集成层,通过中间件或总线(如 ESB)实现系统间流程与功能的整合。
- 服务集成(Service Integration):提供统一的服务接口(如 SOA、微服务架构),支持业务层面的灵活组合与复用。
其中数据集成主要有以下三种模式:数据联邦、数据复制和基于接口的数据集成。
(1)数据联邦
数据联邦是指不同的应用共同访问一个全局虚拟数据库,通过全局虚拟数据库管理系统为不同的应用提供全局信息服务,实现不同的应用和数据源之间的信息共享和数据交换,其具体实现由客户端应用、全局信息服务和若干个局部数据源三部分组成。
(2)数据复制模式
在数据复制模式中,通过底层应用数据源之间的一致性复制来实现(访问不同数据库的)不同应用之间的信息共享和互操作,其实现的关键是必须能够提供在两个或多个数据库系统之间实现数据转换和传输的基础结构(以屏蔽不同数据库间数据模型的差异)。
(3)基于接口的数据集成模式
在基于接口的数据集成模式中,不同的应用系统之间利用适配器(或接口代理)提供的应用编程接口来实现相互调用。应用适配器或接口代理通过其开放或私有接口将业务信息从其所封装的具体应用系统中提取出来,进而实现不同的应用系统之间业务数据的共享与互交换。接口调用的方式可以采用同步调用方法,也可以采用基于消息中间件的异步方法来实现。
1.35. 复用的基本过程主要包括三个阶段:( )、管理可复用资产,以及使用可复用资产。
A. 重新包装可复用的软件资产
B. 分析可复用的软件资产
C. 分解可复用的软件资产
D. 构造/获取可复用的软件资产
答案:D
解析:软件复用是指在软件开发过程中重复使用相同或相似软件元素的过程,是在软件开发中避免重复劳动的解决方案,它使得应用系统的开发不再采用一切从零开始的模式,而是以已有的工作模式为基础,充分利用过去应用系统开发中积累的知识和经验,从而将开发的重点集中于应用的特有构成成分。软件复用过程的主要阶段按顺序分为构造/获取可复用的软件资产、管理可复用资产和使用可复用资产。答案选择D选项。
1.36. 一个模块内的处理元素是相关的,而且必须以特定次序执行,则称为( )。
A. 通信内聚
B. 逻辑内聚
C. 过程内聚
D. 时间内聚
答案:C
解析:软件模块的内容,从高到低分别为:
- 功能内聚:完成一个单一功能,各个部分协同工作,缺一不可。
- 顺序内聚:处理元素相关,而且必须顺序执行。
- 通信内聚:所有处理元素集中在一个数据结构的区域上。
- 过程内聚:处理元素相关,而且必须按特定的次序执行。
- 瞬时内聚(时间内聚):所包含的任务必须在同一时间间隔内执行。
- 逻辑内聚:完成逻辑上相关的一组任务。
- 偶然内聚(巧合内聚):完成一组没有关系或松散关系的任务。
1.37. 软件测试过程中的系统测试主要是为了发现( )阶段的错误。
A. 编码
B. 需求分析(系统测试)
C. 概要设计(集成测试)
D. 详细设计(单元测试)
答案:B
解析:一般情况下,系统测试采用黑盒测试,以此来检查该系统是否符合软件需求。
可以根据V模型来理解,V模型测试贯穿于始终。
其中系统测试和验收测试是针对于需求分析,集成测试针对于概要设计,单元测试针对于详细设计,软件实现应该是针对于编码部分。
本题选择B选项。
1.38. 在UML用例图中,参与者之间存在(C)关系。
A. 聚合
B. 包含
C. 继承
D. 扩展
答案:C
解析:用例图展现了一组用例、参与者以及它们之间的关系。用例图通常包括用例和参与者以及它们之间的关系。
- 用例之间有扩展关系和包含关系,
- 参与者和用例之间有关联关系,
- 用例与用例、参与者与参与者之间有泛化关系(继承关系)。
参与者(Actor):表示系统外部与系统交互的角色(人或系统)。
表示系统提供给参与者的一项功能或服务。
- 体现系统“能做什么”;
- 通常以动宾结构命名,如“登录系统”、“查询余额”、“提交订单”;
- 表示系统与外部交互产生的功能性需求。
1.39. 在进程通信体系结构风格中,连接件是(D)。
A. 独立的过程
B. 消息队列
C. 事件
D. 消息传递
答案:D
解析:在进程通信结构体系结构风格中,构件是独 立的过程,连接件是消息传递。这种风格的特点是构件通常是命名过程,消息传递的方式可以是点到点、异步或同步方式及远程过程调用等。
1.40. 脚本是一组测试工具执行的指令集合,数据驱动脚本是指将测试输入存储在( )中,针对不同的数据输入实现多个测试用例。
A. 程序文件
B. 数据文件
C. 脚本文件
D. 指令文件
答案:B
解析:自动化测试工具主要使用脚本技术来生成测试用例,测试脚本不仅可以在功能测试上模拟用户的操作,比较分析,而且可以用在性能测试、负载测试上。虚拟用户可以同时进行相同的、不同的操作,给被测软件施加足够的数据和操作,检查系统的响应速度和数据吞吐能力。
线性脚本,是录制手工执行的测试用例得到的脚本,这种脚本包含所有的击键、移动、输入数据等,所有录制的测试用例都可以得到完整的回放。
结构化脚本,类似于结构化程序设计,具有各种逻辑结构、函数调用功能。
共享脚本,共享脚本是指可以被多个测试用例使用的脚本,也允许其他脚本调用。共享脚本可以在不同主机、不同系统之间共享,也可以在同一主机、同一系统之间共享。
数据驱动脚本,将测试输入存储在独立的(数据)文件中,而不是存储在脚本中。可以针对不同数据输入实现多个测试用例。
关键字驱动脚本,关键字驱动脚本是数据驱动脚本的逻辑扩展。它将数据文件变成测试用例的描述,采用一些关键字指定要执行的任务。
1.41. Web服务描述语言WSDL描述了Web服务的三个基本属性,包括( )。
A. 谁要访问服务、如何访问服务和服务位于何处
B. 服务做什么、谁要访问服务和服务位于何处
C. 服务做什么、如何访问服务和谁要访问服务
D. 服务做什么、如何访问服务和服务位于何处
答案:D
解析:WSDL(Web Services Description Language,Web服务描述语言),是一个用来描述Web服务和说明如何与Web服务通信的XML语言。它是 Web服务的接口定义语言,由Ariba、Intel、IBM和 M S等共同提出,通过WSDL, 可描述Web服务的三个基本属性。
- 服务做些什么——服务所提供的操作(方法)。
- 如何访问服务——和服务交互的数据格式以及必要协议。
- 服务位于何处——协议相关的地址,如URL。
1.42. 操作系统定义了两种程序执行模式(用户模式和内核模式),应用程序在用户模式下使用特权指令引起的中断是( )。
A. 溢出中断
B. 外部中断
C. 访管中断
D. 信号中断
答案:C
解析:A.溢出中断:这通常是由于指令执行过程中的条件满足(如算术溢出等)而引发的中断。它与用户程序在用户态下使用特权指令引起的中断不同,因此可以排除。
B.外部中断:这是由外部事件引发的中断,如硬件设备的输入输出、定时器到达等。用户程序在用户态下使用特权指令引起的中断不属于外部事件引发的情况,因此也可以排除。
C.访管中断:这是一种特殊的中断,用于在用户态下请求操作系统内核提供服务或执行特权操作。当用户程序需要执行特权指令时,它会通过发起访管中断来请求操作系统执行这些操作。
D.信号中断:这个选项在操作系统中断的常规分类中并不常见,且不符合题目描述的情境。信号通常用于进程间的通信或通知进程某些事件的发生,而不是由于用户程序在用户态下使用特权指令引起的中断。
综上所述,正确答案是C,即访管中断。因为在用户模式下,应用程序无法直接执行特权指令,必须通过访管中断来请求操作系统内核提供服务或执行特权操作。
1.43. 安全审计涉及4个基本要素,分别是( )。
A. 控制目标、控制过程、控制措施和安全测试
B. 控制目标、安全漏洞、控制措施和安全测试
C. 控制目标、安全漏洞、控制措施和控制测试
D. 控制目标、控制过程、控制措施和控制测试
答案:C
解析:安全审计涉及四个基本要素: 控制目标、安全漏洞、控制措施和控制测试。
- 控制目标:这是安全审计的首要要素,它明确了审计的目的和期望达到的安全效果。例如,可能的目标是确保数据的保密性、完整性或系统的可用性。
- 安全漏洞:这是审计过程中需要重点关注的要素。安全漏洞是指系统中可能存在的、能被恶意用户利用以破坏系统安全性的弱点。
- 控制措施:针对发现的安全漏洞,需要采取相应的措施进行修复或预防。这些措施可能包括技术性的(如加密、防火墙等)和管理性的(如安全政策、培训等)。
- 控制测试:这是验证控制措施是否有效执行的关键步骤。通过测试,可以评估控制措施是否达到了预期的效果,从而确保系统的安全性。
1.44. ( )是指重用不同应用领域中的软件元素,例如数据结构、分类算法和人机界面构件等。
A. 结构重用
B. 纵向重用
C. 交叉重用
D. 横向重用
答案:D
解析:软件重用是指在两次或多次不同的软件开发过程中重复使用相同或相似软件元素的过程。按照重用活动是否跨越相似性较少的多个应用领域,软件重用可以区别为横向重用和纵向重用。横向重用是指重用不同应用领域中的软件元素,例如数据结构、分类算法和人机界面构建等。标准函数是种典型的、原始的横向重用机制。纵向重用是指在一类具有较多公共性的应用领域之问进行软部件重用。纵向重用活动的主要关键点是域分析:根据应用领域的特征及相似性预测软部件的可重用性。
1.45. 下面关于ATAM效用树中优先级的说法不正确的是( )。
A. 系统安全性场景属于高优先级场景
B. 效用树中的优先级基于相对排名:高(H),中(M)和低(L)
C. 效用树沿着两个维度排列优先顺序:每个场景对系统成功的重要性以及实现该场景(从架构师的角度来看)的难度估计
D. (H,L)的场景代表该场景对系统成功的重要性较高,该场景的实现难度较低
答案:A
解析:效用树沿着两个维度排列优先顺序:每个场景对系统成功的重要性以及实现该场景的难度估计,其中优先级基于相对排名:高(H),中(M)和低(L),所以BCD说法都是正确的。A选项错误。虽然系统安全性通常非常重要,但在效用树中,场景的优先级是基于多个因素的综合考量,包括系统成功的重要性以及实现的难度。因此,不是所有的安全性场景都会自动被归为高优先级。
1.46. 与通常软件开发过程不同的是,N版本程序设计增加了三个新的阶段,分别是( )。
A. 相异成分规范评审、相同性确认和背对背测试
B. 相异成分规范评审、相异性确认和面对面测试
C. 相同成分规范评审、相同性确认和背对背测试
D. 相异成分规范评审、相异性确认和背对背测试
答案:D
解析:N版本开发与通常软件开发过程的区别:与通常软件开发过程不同的是,N版本程序设计增加了三个新的阶段分别是:相异成分规范评审、相异性确认和背对背测试:
(1)相异成分评审:每个版本的工作组均接收到一份相同的SRS。为了保证相异性,这些工作组之间不允许进行任何形式的交流,有关SRS的问题只能在工作组和项目管理人员之间进行交换,这种交换是通过问题单的形式进行的。对于各工作组提出的问题,由项目管理人员组成的SRS评审委员会对每个问题单进行研究。若是对SRS理解不正确,则向有关工作组进行解释;若是SRS本身问题,则修改SRS,并通知所有工作组。
(2)相异性确认:相异性确认在相异成分详细设计后进行,其目的是对相异性进行评估。
(3)背对背测试:使用同样的测试数据对N版本程序进行测试,将N个版本程序的运行结果进行比较,用以发现版本中的软件故障。
1.47. 下面关于MD5(Message Digest Algorithm 5)说法错误的是( )。
A. 无论输入的数据有多长,MD5都会生成一个长度为128位的哈希值
B. MD5常用于文件完整性的校验
C. MD5是单向的,无法通过哈希值直接逆推出原始数据
D. MD5完全抗碰撞,不存在同样的输入生成相同哈希值的可能性
答案:D
解析:A选项正确。MD5算法的特点之一是将任意长度的输入数据(消息)映射到一个固定长度(128位)的哈希值。
B选项正确。MD5由于其固定输出长度和计算效率,经常被用于文件完整性校验。通过比较文件的MD5哈希值,可以验证文件是否被篡改或损坏。
C选项正确。MD5是一个单向哈希函数,意味着从哈希值几乎不可能反推出原始输入数据。这是哈希函数安全性的一个重要特征。
D选项错误。MD5的一个重要安全缺陷是存在碰撞的可能性。碰撞是指两个不同的输入数据可以生成相同的哈希值。MD5算法存在碰撞问题,即不同的输入可能产生相同的哈希值。
1.48. 分段允许程序员把内存视为由这个地址空间或段组成,其中段的大小是( )。
A. 固定的
B. 不可变的
C. 相等的
D. 动态可变的
答案:D
解析:段的大小是可变的。在段式存储管理系统中,段的大小可以根据需要动态改变。与分页管理不同,分页管理中的页大小通常是固定的。
1.49. 为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,( )。
A. 可以不经软件著作权人许可,不向其支付报酬
B. 可以向著作权人申请,支付较少的报酬
C. 需要向著作权人支付相应的报酬
D. 经软件著作权人许可,可以不向其支付报酬
答案:A
解析:《计算机软件保护条例》规定:为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可以不经软件著作权人许可,不向其支付报酬。
1.50. (C )不属于调用/返回体系结构风格的子风格。
A. 层次型体系结构风格
B. 主程序/子过程体系结构风格
C. 黑板体系结构风格
D. 面向对象体系结构风格
答案:C
解析:调用/返回风格是指在系统中采用了调用与返回机制。利用调用-返回实际上是一种分而治之的策略,其主要思想是将一个复杂的大系统分解为若干子系统,以便降低复杂度,并且增加可修改性。程序从其执行起点开始执行该构件的代码,程序执行结束,将控制返回给程序调用构件。调用/返回体系结构风格主要包括主程序/子程序风格、面向对象风格、层次型风格以及客户端/服务器风格。
1.51. 以下关于事件驱动架构(Event-Driven Architecture,EDA)描述正确的是( )。
A. 事件触发消息在独立的、耦合的模块之间传递
B. 事件触发消息在独立的、非耦合的模块之间传递
C. 事件触发消息在非独立的、耦合的模块之间传递
D. 事件触发消息在非独立的、非耦合的模块之间传递
答案:B
解析:事件驱动体系架构(event-driven architecture,EDA)是一种设计和构建应用的方法,其中事件触发消息在独立的非耦合模块之间(它们之间不需要知道对方)传递。事件源通常发送消息到中间件或消息代理,订阅者就可订阅这个消息。由于事件消息用发布/订阅方式通过消息代理传输,一个事件便可传送给多个需要者。
1.52. 配置管理不是( )中的重要组成部分。
A. CMMI
B. UML
C. PMBOK
D. ISO9000
答案:B
解析:UML(Unified Modeling Language,统一建模语言)是一种用于对软件密集系统进行可视化建模的标准语言。UML主要用于需求分析、系统设计、编码实现等阶段的建模工作,它并不直接涉及配置管理。UML提供了类图、用例图、活动图等多种图形化表示方法,但配置管理不是UML的核心内容。
1.53. 螺旋模型是在( )的基础上扩展而成的。
A. 快速原型模型
B. 喷泉模型
C. V模型
D. 增量模型
答案:A
解析:螺旋模型是在快速原型的基础上扩展而成。也有人把螺旋模型归到快速原型,实际上,它是生命周期模型与原型模型的结合。这种模型把整个软件开发流程分成多个阶段,每一个阶段都由4部分组成,分别是:目标设定、风险分析、开发和有效性验证、评审。
1.54. 信道容量是信道的最大传输速率,可以通过( )提升信道容量。
A. 使用较大的带宽,升高信噪比
B. 使用较小的带宽,降低信号功率
C. 使用较大的带宽,降低信噪比
D. 使用较小的带宽,降低信噪比
答案:C
解析:本题考查通信相关概念。
信道容量就是信道的最大传输速率,可通过香农公式计算得到。
提升信道容量可以使用比较大的带宽,降低信噪比;也可以使用比较小的带宽,升高信噪比。
1.55. 信息化需求包含三个层次,即(B)。
A. 战略需求、运作需求和信息资源开发
B. 战略需求、运作需求和技术需求
C. 战略需求、信息资源开发和技术需求
D. 信息资源开发、运作需求和技术需求
答案:B
解析:一般说来,信息化需求包含3个层次,即:战略需求、运作需求和技术需求。
一是战略需求。组织信息化的战略需求的目标是提升组织的竞争能力、为组织的可持续发展提供一个支持环境。从某种意义上来说,信息化对组织不仅仅是服务的手段和实现现有战略的辅助工具;信息化可以把组织战略提升到一个新的水平,为组织带来新的发展契机。特别是对于企业,信息化战略是企业竞争的基础。
二是运作需求。组织信息化的运作需求是组织信息化需求非常重要且关键的一环,它包含三方面的内容
一是实现信息化战略目标的需要;二是运营策略的需要;三是人才培养的需要。
三是技术需求。由于系统开发时间过长等问题在信息技术层面上对系统的完善、升级、集成和整合提出了需求。也有的组织,原来基本上没有大型的信息系统项目,有的也只是一些单机应用,这样的组织的信息化需求,一般是从头开发新的系统。
1.56. 在ATAM中,利益相关者需要头脑风暴的场景是( )。
A. 用例场景、增长场景、环境场景
B. 用例场景、增长场景、探索场景
C. 增长场景、探索场景、环境场景
D. 用例场景、探索场景、环境场景
答案:B
解析:利益相关者需要使用头脑风暴的三种场景:
用例场景:在这种情况下,利益相关者就是最终用户。
增长情景:代表了架构发展的方式。
探索性场景:代表架构中极端的增长形式。
1.57. 基于度量的评估方法建立在软件架构度量的基础上的,涉及三个基本活动,首先需要建立质量属性和度量之间的映射原则,然后从软件架构文档中获取度量信息,最后根据映射原则分析推导出系统的( )。
A. 质量属性
B. 架构决策
C. 功能需求
D. 架构元素
答案:A
解析:教材8.2系统架构评估,P277。
基于度量的评估方法。它是建立在软件架构度量的基础上的,涉及3个基本活动,首先需要建立质量属性和度量之间的映射原则,然后从软件架构文档中获取度量信息,最后根据映射原则分析推导出系统的质量属性。
1.58. 基于内容的推荐是信息过滤技术的延续与发展,不属于该方法优点的是
- 能推荐新的或不是非常流行的项目,没有新项目问题
- 能为具有特殊兴趣爱好的用户进行推荐
- 不需要其它用户的数据,与他人的行为无关
- 能够为新用户产生推荐
答案:D
解析:基于内容的推荐系统 (Content-based Recommendation System)是一种个性化推荐技术,其核心原理是利用物品的内容特征和用户的历史行为来预测用户可能感兴趣的物品。
基于内容的推荐方法的优点主要包括:
- 不依赖其他用户的数据:基于内容的推荐不依赖于其他用户的评分或行为数据,因此不存在冷启动问题和稀疏问题。
- 个性化推荐:能够为具有特殊兴趣爱好的用户进行推荐,因为推荐是基于用户对特定内容特征的兴趣
- 推荐新项目:能推荐新的或不是很流行的项目,没有新项目问题。
- 透明度高:由于推荐理由通常是基于用户已知的兴趣点,因此用户更容易理解为什么这些项目被推荐给他们。
综上,可以得出选项ABC 都是基于内容推荐方法的优点,而选项D不是,因为新用户没有历史数据基础,基于内容的推荐方法无法产生推荐。
1.59. 专家系统一般采用人工智能中的( )来模拟通常由该领域专家才能解决的复杂问题。
A. 知识推理和注意力机制
B. 知识表示和知识推理技术
C. 知识获取和注意力机制
D. 知识表示和注意力机制
答案:B
解析:专家系统是早期人工智能的一个重要分支,它可以看作是一类具有专门知识和经验的计算机智能程序系统,一般采用人工智能中的知识表示和知识推理技术来模拟通常由领域专家才能解决的复杂问题。
一般来说,专家系统=知识库+推理机,因此专家系统也被称为基于知识的系统。一个专家系统必须具备三要素:
(1)领域专家级知识
(2)模拟专家思维
(3)达到专家级的水平
1.60. 体系结构演化是使用系统演化步骤去修改应用,以满足新的需求。主要包括以下步骤,需求变化归类,制定体系结构演化计划,修改、增加或删除构件,( ),构件组装与测试,以及技术评审。
A. 更新构件的相互作用
B. 构件版本管理
C. 分析已有构件
D. 分析构件间的关系
答案:A
解析:体系结构演化是使用系统演化步骤去修改应用,以满足新的需求。主要包括以下6个步骤。 (1)需求变化归类
首先必须对用户需求的变化进行归类,使变化的需求与已有构件对应。对找不到对应构件的变动,也要做好标记,在后续工作中,将创建新的构件,以对应这部分变化的需求。
(2)制订体系结构演化计划
在改变原有结构之前,开发组织必须制订一个周密的体系结构演化计划,作为后续演化开发工作的指南。
(3)修改、增加或删除构件
在演化计划的基础上,开发人员可根据在第1步得到的需求变动的归类情况,决定是否修改或删除存在的构件、增加新构件。最后,对修改和增加的构件进行功能性测试。
(4)更新构件的相互作用
随着构件的增加、删除和修改,构件之间的控制流必须得到更新。
(5)构件组装与测试
通过组装支持工具把这些构件的实现体组装起来,完成整个软件系统的连接与合成,形成新的体系结构。然后对组装后的系统整体功能和性能进行测试。
(6)技术评审
对以上步骤进行确认,进行技术评审。评审组装后的体系结构是否反映需求变动、符合用户需求。如果不符合,则需要在第2到第6步之间进行迭代。
1.61. 下面关于DSSA(Domain Specific Software Architecture)说法正确的是( )。
A. DSSA的建立过程是并发的、递归的和反复进行的
B. 在DSSA中,定义领域特定的元素阶段的重点是确定什么在感兴趣的领域中以及本过程到何时结束,这个阶段的一个主要输出是领域中的应用需要满足一系列用户的需求
C. 定义领域模型和体系结构阶段的目标是为DSSA增加构件,使它可以被用来产生问题域中的新应用
D. 在不同的领域中,DSSA的创建和使用过程完全相同
答案:A
解析:因所在的领域不同,DSSA 的创建和使用过程也各有差异,Tract曾提出一个通用的DSSA应用过程,这些过程也需要根据所应用到的领域来进行调整。
DSSA的建立过程分为5个阶段,每个阶段可以进一步划分为一些步骤或子阶段。每个阶段包括一组需要回答的问题,一组需要的输入,一组将产生的输出和验证标准。本过程是并发的 (Concurrent)、递归的 (Recursive)、反复的(Iterative)。或者可以说,它是螺旋模型(Spiral)。完成本过程可能需要对每个阶段经历几遍,每次增加更多的细节。
(1)定义领域范围。本阶段的重点是确定什么在感兴趣的领域中以及本过程到何时结束。这个阶段的一个主要输出是领域中的应用需要满足一系列用户的需求。
(2)定义领域特定的元素。本阶段的目标是编译领域字典和领域术语的同义词词典。在领域工程过程的前一个阶段产生的高层块圈将被增加更多的细节,特别是识别领域中应用间的共同性和差异性。
(3)定义领域特定的设计和实现需求约束。本阶段的目标是描述解空间中有差别的特性。不仅要识别出约束,并且要记录约束对设计和实现决定造成的后果,还要记录对处理这些问题时产生的所有问题的讨论。
(4)定义领域模型和体系结构。本阶段的目标是产生一般的体系结构,并说明构成它们的模块或构件的语法和语义。
(5)产生、搜集可重用的产品单元。本阶段的目标是为DSSA增加构件,使它可以被用来产生问题域中的新应用。
DSSA 的建立过程是并发的、递归的和反复进行的。
1.62. 数据库的三级模式结构中,描述局部数据的逻辑结构和特征的是( )。
A. 逻辑模式
B. 外模式
C. 内模式
D. 概念模式
答案:B
解析:数据库系统结构:
三级模式:
外模式:数据的局部逻辑结构和特征的描述
模式:数据的全局逻辑结构和特征的描述
内模式:是数据物理结构和存储方式的描述,数据在数据库内部的表示方式
二级映像
外模式/模式映像:
当模式改变时,数据库管理员修改有关的外模式/模式映象,使外模式保持不变
模式/内模式映像:
当数据库的存储结构改变时,数据库管理员修改有关的模式内模式映像,使模式保持不变
1.63. 以下关于数据流图的说法错误的是( )。
A. 加工是对数据进行处理的单元,接收一定的数据输入,对其进行处理后产生输出
B. 子图的输入输出数据流同父图相应加工的输入输出数据流必须一致
C. 对大型复杂系统,可采用自顶向下逐层分解的方式,绘出分层数据流图
D. 数据流反映了系统“做什么”,以及加工的执行顺序
答案:D
解析:数据流图(DFD)中的数据流主要反映了系统“做什么”,而不是加工的执行顺序。所以D选项说法错误。
在数据流图中,加工(也称为处理)是对数据进行处理的单元。A选项说法正确。
子图是父图中某个加工的详细展开,为了保证数据流图的一致性和完整性,子图的输入输出数据流必须同父图相应加工的输入输出数据流保持一致。B选项说法正确。
对于大型复杂系统,由于涉及的数据和处理过程非常多,如果直接绘制一个完整的数据流图,会导致图面过于复杂,难以理解和维护。因此,通常采用自顶向下逐层分解的方式,先绘制顶层数据流图,展示系统的总体功能和主要数据流,然后逐步将顶层图中的加工分解为更详细的子加工,绘制出下一层的数据流图,以此类推,直到能够清晰地描述系统的各个细节。这种方法可以有效地管理复杂系统的数据流图绘制。C选项说法正确。
1.64. 基于软件系统的生命周期,可以将软件系统的质量属性分为开发期质量属性和运行期质量属性两个部分。其中,( )关注软件因适应新需求或需求变化而增加新功能的能力;( )是关注软件系统同时兼顾向合法用户提供服务,以及阻止非授权使用的能力。
A. 安全性
B. 可扩展性
C. 性能
D. 可重用性
A. 可测试性
B. 安全性
C. 可移植性
D. 可用性
答案:B B
解析:软件系统质量属性 (Quality Attribute) 是一个系统的可测量或者可测试的属性,用来描述系统满足利益相关者 (Stakeholders) 需求的程度。基于软件系统的生命周期,可以将软件系统的质量属性分为开发期质量属性和运行期质量属性2个部分。
1.开发期质量属性 开发期质量属性主要指在软件开发阶段所关注的质量属性,主要包含6个方面。
(1)易理解性:指设计被开发人员理解的难易程度。
(2)可扩展性:软件因适应新需求或需求变化而增加新功能的能力,也称为灵活性。
(3)可重用性:指重用软件系统或某一部分的难易程度。
(4)可测试性:对软件测试以证明其满足需求规范的难易程度。
(5)可维护性:当需要修改缺陷、增加功能、提高质量属性时,识别修改点并实施修改的 难易程度。
(6)可移植性:将软件系统从一个运行环境转移到另一个不同的运行环境的难易程度
2.运行期质量属性 运行期质量属性主要指在软件运行阶段所关注的质量属性,主要包含7个方面。
(1)性能:性能是指软件系统及时提供相应服务的能力,如速度、吞吐量和容量等的要求。
(2)安全性:指软件系统同时兼顾向合法用户提供服务,以及阻止非授权使用的能力。
(3)可伸缩性:指当用户数和数据量增加时,软件系统维持高服务质量的能力。例如,通 过增加服务器来提高能力。
(4)互操作性:指本软件系统与其他系统交换数据和相互调用服务的难易程度。
(5)可靠性:软件系统在一定的时间内持续无故障运行的能力。
(6)可用性:指系统在一定时间内正常工作的时间所占的比例。可用性会受到系统错误, 恶意攻击,高负载等问题的影响。
(7)鲁棒性:是指软件系统在非正常情况(如用户进行了非法操作、相关的软硬件系统发 生了故障等)下仍能够正常运行的能力,也称健壮性或容错性。
2024年11月第71-75题
Blackboard architecture, also known as the blackboard system, is a problem-solving approach that utilizes a modular and( )framework. It effectively solves complex problems that( )a well-defined algorithm or a pre-determined architecture. Blackboard architecture is inspired by human experts collaborating and solving difficult problems by( )and contributing their expertise. The architecture is based on how people work together around a( ). Each person would sit around the board and a problem would be written on it. When a person can solve the problem, they would go to the board and add the( )solution they know how to do. This process is repeated until a collective solution is found.
A. conceptualized
B. centralized
C. decentralized
D. controlled
A. use
B. create
C. improve
D. lack
A. getting information
B. improving abilities
C. discussing problems
D. sharing information
A. computer
B. paper
C. table
D. blackboard
A. defined
B. possible
C. partial
D. experimental
答案:C D D D C
解析:
原文:https://www.geeksforgeeks.org/system-design/blackboard-architecture/
黑板架构,也称为黑板系统,是一种利用模块化和分散化的框架解决问题的方法。它有效地解决了缺乏明确算法或预先确定的架构的复杂问题。黑板架构的灵感来自人类专家通过共享信息和贡献他们的专业知识来协作和解决难题。该架构基于人们如何围绕黑板协同工作。每个人都会坐在黑板旁,上面会写一个问题。当一个人能解决问题时,他们会走到黑板前,添加他们知道如何做的部分解决方案。这个过程会重复,直到找到一个集体解决方案。
A.概念化 B.集中 C.分散 D.受控
A.使用 B.创建 C.改进 D.缺乏
A.获取信息 B.提高能力 C.讨论问题 D.共享信息
A.计算机 B.纸张 C.桌子 D.黑板
A.定义 B.可能 C.部分 D.实验性
2. 案例分析
2.1. 试题一:质量属性
阅读以下关于面向质量属性的软件架构设计的叙述,回答问题1和问题2。 【说明】 某公司拟开发一个基于大语言模型的智能系统,该系统将通过多个大语言模型来协作处理用户提交的任务请求,任务求解过程的状态数据将被记录在任务板中,各个大语言模型根据任务板上任务的实时求解状态,来确定它们当前是否需要被调用以进一步处理该任务,并在处理完成之后将任务的最新状态更新到任务板上。 基于该系统的开发任务,公司召开项目讨论会。会上,项目组介绍了系统需求,主要包括: (a)系统可支持用户在任务板上查看任务的状态和结果,并允许用户多次调用大型语言模型以进一步优化处理结果。 (b)系统可支持任务数据的导入导出,数据导入导出在1分钟内完成 (c)在数据服务器发生故障时,系统应能够立刻切换到备份服务器,并保证数据同步,以确保系统的不间断的服务。 (d)在系统正常负荷情况下,用户在任务板上查询任务状态和结果的响应时间应在2秒内。 (e)系统应确保用户数据和操作记录的安全,防止未经授权的访问。 (f)系统需要支持多语言接口,并提供查询词自动补全和搜索关联功能。 (g)系统应支持扩容,以容纳更多的用户和任务。扩容需求的实现应在两名运维人员工作的情况下在5天内完成。 (h)系统部署在云服务器上。当云服务器出现故障时,系统应在1分钟内检测出故障,并在1小时之内恢复。 (i)系统支持根据用户任务类型调用相应的大语言模型对任务进行处理。 (j)用户可以在任务板上搜索历史任务和结果,搜索结果应在3秒内返回。
【问题1】(14分) 为了辅助架构师张工完成系统架构设计,首先需要对上述需求进行分析。请分析需求(a)~(j),补充完善下表中(1)~(7)的空白处。
【问题2】(11分) 针对需求可用性需求(h),张工提出可采用ping/echo策略完成故障检测,但李工认为从系统资源利用率的角度出发,采用心跳策略完成故障检测更优。 (1)请分别说明如何采用ping/echo策略和心跳策略来完成可用性的故障检测; (2)请解释李工认为心跳策略更优的原因。
答案:
【问题1】
(1)性能
(2)性能
(3)安全性
(4)功能性
(5)可修改性
(6)功能性
(7)性能
【问题2】
(1)ping/echo策略通过定期发送ping请求并等待响应来检测故障,而心跳策略则是通过定期交换心跳消息来确认服务状态。
(2)李工之所以认为心跳策略相较于ping/echo策略更为优越,是因为心跳策略能够显著减少资源的消耗,它通过被监控组件主动发送简短的心跳消息来表明运行状态,无需监控组件频繁发送请求并等待回应。此外,心跳策略还能有效降低网络的负载,因为心跳消息通常较短且发送频率较低,对网络带宽的占用也相应减少。最后,心跳策略能够更快速地检测到故障或失联的节点,一旦节点出现故障或无法发送心跳消息,监控组件便能立即察觉并采取措施,从而提高了故障检测的效率。
解析:
【问题2】
(1)ping/echo故障检测:ping/echo通过发送ping请求报文给目标主机,并等待其回应来检测网络连通性。如果收到回应,则表明网络通路正常;如果未收到回应或超时,则可能表示网络存在问题或目标主机不可达。
心跳故障检测:心跳机制通过节点间定期发送心跳信号来检测各节点的状态。如果连续一段时间内未收到某个节点的心跳信号,则判定该节点出现故障或失联,并触发相应的故障恢复或切换操作。这种方式常用于分布式系统中,以确保系统的高可靠性和稳定性。
(2)资源消耗较少:心跳模式通常是由被监控组件主动、周期性地向监控组件发送简短的消息,以表明其正在正常运行。这种方式相比ping echo更为高效,因为ping echo需要监控组件定时向被监控组件发送请求,并等待回应,这增加了网络流量和处理器资源的消耗。另外心跳模式使用的是长连接,而ping使用的是短连接。
降低网络负载:由于心跳消息通常较短且发送频率相对较低(根据系统需求设定),因此它们对网络带宽的占用较少。相比之下,ping echo可能需要更频繁地发送和接收消息,从而增加了网络的负载。
故障检测效率更快:心跳模式能够更快速地检测到故障或失联的节点。因为心跳消息是周期性发送的,所以一旦某个节点出现故障或无法发送心跳消息,监控组件就能立即察觉并采取相应的措施。而ping/echo虽然也能用于故障检测,但其响应时间和检测效率可能受到网络延迟和消息丢失等因素的影响。
2.2. 试题二:数据库cache-aside架构
阅读下列关于数据库设计的说明,回答问题1至问题3。
【说明】
为了提升某购物网站的用户使用体验,采用数据库缓存技术将经常访问的商品信息存储在一个临时高速数据存储层中,这个临时存储层使得未来对这些数据的请求响应比通过访问主数据库更快。为了确保快速、及时获取最新数据,项目组决定采用缓存数据技术开展项目设计,经讨论,决定采用Cache-Aside策略作为缓存手段。
【问题1】(10分)
使用Cache-Aside缓存策略,当用户查询商品信息时,此请求会从应用程序服务器发送请求到数据库服务器,通过缓存系统处理,然后返回所请求的信息,请补充完善图1中(1)~(5)处的内容,协助设计师完成缓存系统中的数据读取模块的设计方案。
【问题2】(6分)
使用Cache-Aside缓存策略,当用户更新商品信息时,此请求会从应用服务器发至数据库服务器,并进行缓存处理,请补充完善图2中(1)和(2)处的内容,协助工程师完成缓存系统中的数据更新模块的设计方案。
【问题3】(9分)
李工设计了多线程并发数据访问方案,采用线程1执行数据更新,线程2执行数据读取。王工认为这样的设计方案会存在数据不一致现象,请说明李工所设计的方案为什么会出现数据库与缓存中的数据不一致的情况,并给出3种或以上的解决方案。
答案:
【问题1】
(1)向缓存请求读取该商品信息
(2)若命中则返回该商品信息
(3)若未命中则访问数据库查询该商品信息
(4)将查询到的数据库数据更新到缓存
(5)将查询到的数据库目标数据返回
【问题2】
(1)更新数据库中的目标商品信息
(2)删除对应商品的缓存信息
【问题3】
原因:
(1)非原子操作:【更新DB -> 删除Cache】不是一个原子操作,中间可被其他线程打断。
(2)执行顺序不确定性:并发环境下,【读操作】和【写操作】的各个步骤(读DB、读Cache、写DB、写Cache)可以任意交错执行。
解决方案:
(1)异步队列方式同步,可采用消息中间件处理
(2)通过数据库插件完成数据同步
(3)利用触发器进行缓存同步
(4)锁机制
(5)延时双删
(6)设置缓存过期策略
(7)订阅Binlog进行失效
注意:该题的答案并不唯一,能写出三种合理的方案即可,使用Qwen和DeepSeek多学习下。
解析:
针对线程1写数据、线程2读缓存时可能出现的数据不一致问题,以下是三种解决方案的详细解析:
(1)异步队列方式同步,可采用消息中间件处理:此方案利用消息中间件(如Kafka)来确保数据的一致性。当线程1更新数据库后,会发送一个消息到消息队列中。线程2或另一个消费者线程会监听这个队列,并在收到消息后执行相应的缓存更新或删除操作。
(2)通过数据库插件完成数据同步:一些数据库插件或工具(如MySQL的binlog监听工具)可以监听数据库的更新操作,并在数据发生变化时自动更新缓存。
(3)利用触发器进行缓存同步:在数据库中设置触发器,当数据表发生INSERT、UPDATE或DELETE操作时,触发器会自动执行相应的缓存更新或删除操作。
(4)锁机制。比如:通过引入读写锁机制,可以确保在数据更新时,没有其他线程可以读取数据。这可以防止线程2在线程1更新数据库时读取到旧数据。在数据更新完成后,再释放读锁,允许其他线程读取数据。
2.3. 试题三:嵌入式
阅读以下关于嵌入式系统机器人操作系统的相关技术叙述,回答问题1至问题3。
【说明】
随着机器人、智前化技术的快速发展,机器人操作系统(Robot Operating System,ROS)被广泛应用。某公司长期从事机器人产品研制工作,随着人工智能技术的成热,公司产品智能化改造得到公司领导层的高度重视。张工为公司提供了一份产品升级改造方案。
【问题1】(12分)
在改造方案中,张工提到:关于软件平台的选型,鉴于公司长期使用开源ROS框架作为产品的软件平台,这次升级仍然需要保持开发人员习惯,使用ROS1的升级版ROS2支持智能化的需求。而王工提出不同意见,指出前期使用段ROS1时,已存在了众多不满足产品研制的问题,比如Master中心节点管理不合理、通信效率低等问题。张工逐一解释了ROS2主要改进点。
(1)请概要说明ROS定义和特点。
(2)请说明ROS2相对ROS1主要在哪些方面做了改进?
【问题2】(8分)
ROS2提供了四种通信模型,即:话题(topic)通信、服务通信、动作通信和参数服务(见图1)。分析下列对四种通信模型的功能描述,请说明(1)~(4)的功能描述分别属于哪种通信模型?
图1 ROS2 常用的四种通信模型
(1)是一种基于共享的通信模型,在通信双方中,服务端可以设置数据,而客户端可以连接服务端并操作服务端数据。
(2)是一种单向通信模型,在通信双方中,发布方发布数据,订阅方订阅数据,数据流单方向的由发布方传输到订阅方。
(3)是一种带有连续反馈的通信模型,在通信双方中,客户端发送请求数据到服务端,服务端响应结果给客户端,但是在服务端接收到请求到产生最终响应的过程中,会发送中间连续的反馈(进度)信息到客户端。
(4)是一种基于请求响应的通信模型,在通信双方中,客户端发送请求数据到服务端,服务端响应结果给客户端。
【问题3】(5分)
图2给出了ROS2的软件架构,请简要说明ROS2软件架构各层的主要功能。
图2 ROS2软件架构
答案:
【问题1】
ROS的定义和特点:
定义:是一个专为机器人软件开发设计的开源的元级操作系统。它提供类似于传统操作系统的功能,如硬件抽象、底层设备控制、进程间消息传递和程序包管理等,并包含一系列工具和库,支持多语言编程,用于实现多机融合的程序开发和执行。
ROS的特点主要包括:采用分布式架构实现模块化和可扩展性;支持多种编程语言以满足不同开发需求;提供丰富的工具集提高开发效率;拥有庞大的开源社区支持,促进共享和发展等。
主要改进点:
- 通信机制:ROS1使用基于TCP/IP的自定义协议(TCPROS/UDPROS),而ROS2则采用了DDS(Data Distribution Service)作为通信中间件。DDS支持去中心化的发布/订阅模型,提高了系统的可靠性和稳定性。
- 支持平台:ROS1主要支持Linux系统,而ROS2则扩展到了Windows、macOS以及RTOS等多个操作系统,提供了更广阔的开发空间。
- 实时性:ROS2在实时性方面进行了优化,包括引入更高效的通信机制和减少系统开销等,使得ROS2在实时性方面有了显著提升。
- 安全性:ROS2加强了安全性方面的考虑,引入了加密机制等安全措施,提高了机器人在网络通信中的安全性。
- 数据类型和序列化:ROS2使用了DDS的数据类型系统(IDL定义),支持更复杂的数据结构和数据类型,包括嵌套结构、枚举类型和位字段等。
- 节点组织:在ROS2中,节点可以是独立的进程,也可以是共享同一进程的多个节点。这种设计减少了进程间通信的开销,提高了效率。
【问题2】
(1)参数服务
(2)话题通信
(3)动作通信
(4)服务通信
【问题3】
ROS2的软件架构各层主要功能如下:
Application Layer:提供基于ROS2的应用程序和服务,利用ROS2的中间件功能实现特定的机器人功能或任务。
ROS2 Client Layer:提供ROS2的核心功能和API,包括节点管理、消息通信、服务调用等,是应用程序与底层通信机制之间的桥梁。
Abstract DDS Layer:为ROS2提供与数据分发服务(DDS)无关的抽象接口,屏蔽DDS实现的细节,提高系统的灵活性和可扩展性。
DDS Implementation Layer:提供具体的DDS实现,负责数据的发布、订阅和服务调用等通信操作,是实现ROS2通信机制的关键部分。
OS Layer:为ROS2提供底层的操作系统支持,包括进程管理、内存管理、网络通信等,是ROS2运行的基础。
解析:
【问题1】
(1)定义和特点
1)定义:
是一个专为机器人软件开发设计的开源的元级操作系统。它提供类似于传统操作系统的功能,如硬件抽象、底层设备控制、进程间消息传递和程序包管理等,并包含一系列工具和库,支持多语言编程,用于实现多机融合的程序开发和执行。
2)特点:
分布式架构:ROS采用分布式架构,允许机器人系统中的各个模块(节点)在独 立的进程中运行,并通过消息传递进行通信。这种架构使得ROS具有很好的模块化和可扩展性。
多语言支持:ROS支持多种编程语言,如C++、Python等,使得开发人员可以根据自己的喜好和项目需求选择合适的编程语言。
丰富的工具集:ROS提供了一套丰富的工具集,包括代码生成工具、可视化工具、调试工具等,大大提高了机器人开发的效率。
开源社区支持:ROS拥有一个庞大的开源社区,社区成员可以共享代码、经验和资源,为ROS的发展提供了强大的支持。
(2)ROS2与ROS1相比,在多个方面进行了改进。几个主要改进点:
通信机制:ROS1使用基于TCP/IP的自定义协议(TCPROS/UDPROS),而ROS2则采用了DDS(Data Distribution Service)作为通信中间件。DDS支持去中心化的发布/订阅模型,提高了系统的可靠性和稳定性。
支持平台:ROS1主要支持Linux系统,而ROS2则扩展到了Windows、macOS以及RTOS等多个操作系统,提供了更广阔的开发空间。
实时性:ROS2在实时性方面进行了优化,包括引入更高效的通信机制和减少系统开销等,使得ROS2在实时性方面有了显著提升。
安全性:ROS2加强了安全性方面的考虑,引入了加密机制等安全措施,提高了机器人在网络通信中的安全性。
数据类型和序列化:ROS2使用了DDS的数据类型系统(IDL定义),支持更复杂的数据结构和数据类型,包括嵌套结构、枚举类型和位字段等。
节点组织:在ROS2中,节点可以是独 立的进程,也可以是共享同一进程的多个节点。这种设计减少了进程间通信的开销,提高了效率。
【问题2】
(1)描述的是参数服务。在参数服务中,参数可以在整个ROS2系统中被多个节点共享和访问。节点可以获取和设置这些参数,从而实现基于共享数据的通信。因此,参数服务可以被视为一种基于共享的通信模型。
(2)描述的是话题(Topic)通信。在话题通信中,发布方发布数据,订阅方订阅数据,数据流是单向的,由发布方传输到订阅方。
(3)描述的是动作通信。在动作通信中,客户端发送请求数据到服务端,服务端在接收到请求到产生最终响应的过程中,会发送中间连续的反馈(进度)信息到客户端,这是一种带有连续反馈的通信模型。
(4)描述的是服务通信。在服务通信中,客户端发送请求数据到服务端,服务端响应结果给客户端,这是一种基于请求响应的通信模型。
【问题3】
ROS2的软件架构从上到下分为以下几个层次,每个层次都有其特定的主要功能:
应用层(Application Layer):主要功能是提供基于ROS2的应用程序和服务。这些应用程序和服务利用ROS2的中间件功能来实现特定的机器人功能或任务。
ROS2客户端层(ROS2 Client Layer):提供ROS2的核心功能和API,包括节点管理、消息通信、服务调用等。这一层是应用程序与底层通信机制之间的桥梁,使得应用程序能够方便地使用ROS2的通信和同步机制。
抽象DDS层(Abstract DDS Layer):为ROS2提供与数据分发服务(DDS)无关的抽象接口。这一层屏蔽了DDS实现的细节,使得ROS2能够与不同的DDS实现进行交互,从而提高了系统的灵活性和可扩展性。
DDS实现层(DDS Implementation Layer):提供具体的DDS实现,负责数据的发布、订阅和服务调用等通信操作。这一层是实现ROS2通信机制的关键部分,它利用DDS的高效通信能力来确保数据的实时性和可靠性。
操作系统层(OS Layer):为ROS2提供底层的操作系统支持,包括进程管理、内存管理、网络通信等。这一层是ROS2运行的基础,它提供了必要的系统资源和接口,使得ROS2能够在不同的操作系统上运行。
2.4. 试题四:Web应用
Web Elasticsearch分词的商品推荐系统(微信小程序接入)
【问题1】Standard, Simple, Whitespace, Keyword分词引擎的特点差异(几种分词器怎么分词)(6分)
【问题2】系统架构图填空,从给出的选项中选出对应的选项填入对的位置。(12分) 分层:接入层、显示层、网络层、应用层、业务逻辑层、控制层、数据层。 技术:Mybatis、 Nginx、 Flink、 Javascript、 Node js、 RESTful、 Elasticsearch、Kafka
【问题3】RESTful 架构有什么特点,是如何实现前后端分离的。(7分)
答案:
【问题1】
1.Standard分词器:特点:是默认的分词器,对于英文,它按照单词进行切分,并将大写字母转换为小写;对于中文,则简单地将中文文本拆分为单个汉字。
2.Simple分词器:特点:按照非字母字符(如标点符号、数字、特殊字符等)进行切分,同时会将大写字母转换为小写,并过滤掉这些非字母字符。
3.Whitespace分词器:特点:仅仅按照空白字符(如空格、制表符等)进行切分,不会进行小写转换,也不会过滤掉任何字符(包括标点符号和数字)。
4.Keyword分词器:特点:不进行任何切分,将输入的整个字符串作为一个单独的词(或称为“关键词”)来处理。
【问题2】题目出自ProcessOn的模版,不是很严谨。
(1)显示层 (2)控制层 (3)Javascript (4)Restful (5)业务逻辑层
(6)数据层 (7)MyBatis (8)Nginx
【问题3】
RESTful架构通过定义一套规范来实现前后端分离。以下是实现前后端分离的关键点:
(1)资源定义与URL规范:在RESTful架构中,每种URL代表一种资源。通过不同的HTTP请求方法(如GET、POST、PUT、DELETE)对同一URL进行操作,可以实现对该资源的不同功能,如获取、添加、修改和删除。
(2)请求方式与响应格式:客户端使用标准的HTTP方法(GET、POST、PUT、DELETE)对服务器上的资源进行操作。服务器响应通常以JSON格式返回数据,这样前端可以轻松地解析和处理这些数据。
(3)前后端职责分离:前端主要负责用户界面与用户体验,包括页面展示、渲染速率和效果。前端通过发送Ajax请求与后端进行交互,并接收JSON格式的数据进行展示。后端专注于业务逻辑处理与数据存储。后端接收前端的请求,处理业务逻辑,然后返回相应的数据给前端。
(4)前后端交互规范:前后端通过RESTful规范进行数据交互。这意味着双方需要遵循相同的接口定义、请求方法和响应格式。这种规范使得前后端可以独立开发和维护,提高了团队的协作效率和系统的可扩展性。
2.5. 试题五:软件开发
阅读以下关于软件系统设计与建模的叙述,回答问题1至问题3。
【说明】
胰岛素泵是一个模拟胰腺运转的医疗系统,它从传感器收集数据,控制泵输送指定剂量的胰岛素给糖尿病患者。根据糖尿病患者使用仪器测量的血糖值,计算所需要注射的胰岛素剂量,该系统的使用为糖尿病患者提供了个性化、精准化治疗体验,极大地改善了患者的生活质量,并降低了糖尿病并发症产生的风险。
【问题1】(10分)
在安全关键系统开发过程中进行安全需求分析十分重要,请说明危险驱动的安全分析过程中有哪4个步骤,并分别对每个步骤进行简要说明。
【问题2】(9分)
胰岛素泵系统是一个安全关键系统,它的失效可能会导致患者受伤甚至死亡。
在该系统中存在3种情况可以导致不正确的胰岛素剂量使用,分别为:
(a)血糖值水平测量不准确、(b)传送系统失效、(c)在错误的时间传送预定的剂量。
这3种情况分别是由
(d)血糖传感器失效、(e)泵信号不正确、(f)定时器失效、
(g)血糖计算错误、(h)胰岛素计算错误、(i)算法错误和(j)计算错误造成。
图1给出了胰岛素泵系统中软件相关危险的故障树,请分析题干中(a)~(j)的描述,补充完善图1中事件(1)~(9)的名称。
【问题3】(6分)
请说明在安全关键系统开发中使用形式化方法和软件测试技术各自的特点。
答案:
【问题1】危险驱动的安全分析过程中有哪4个步骤包括:危险识别、风险分析、安全需求制定和安全需求验证。
首先,通过危险识别,深入理解系统及其运行环境,分析功能和相互作用,以找出所有可能的危险。
接着,进行风险分析,评估每个危险的发生概率和后果严重性,确定风险等级,从而确定哪些危险需要优先关注和处理。
然后是安全需求制定,基于风险分析的结果,制定具体、明确的安全需求,这些需求旨在防止或减轻已识别的危险及其潜在后果,并指导系统的设计和实现。
最后,通过安全需求验证,对系统进行测试、仿真或实际运行,以确保其符合安全需求的要求,检查系统的故障响应、冗余功能、数据完整性等方面,确保系统能够在各种情况下保持安全。
【问题2】
备注:感觉出自某个教材,但没找到出处。
关键词:Fault Tree Analysis — Insulin Delivery System
(1)在错误的时间传送预定的剂量。
(2)传送系统失效
(3)定时器失效
(4)泵信号不正确
(5)胰岛素计算错误
(6)算法错误
(7)计算错误造成
(8)血糖传感器失效
(9)血糖计算错误
【问题3】
在安全关键系统开发中,形式化方法和软件测试技术各具特色。形式化方法基于数学和逻辑,具有精确性、可验证性和早期发现错误的能力,但要求较高的数学和逻辑素养,且验证过程可能复杂耗时。而软件测试技术则通过实际运行系统来评估质量和性能,具有实践性、灵活性和及时反馈的特点,但可能无法覆盖所有可能的输入和状态,且测试结果的解释具有主观性。
解析:
【问题1】
在危险驱动的安全分析过程中,通常包含以下四个步骤:
危险识别:此步骤的目标是确定系统中可能存在的所有危险。它涉及对系统的深入理解,包括其运行环境、操作模式、潜在故障模式等。通过分析系统各个组成部分的功能和相互作用,以及它们可能引发的危害,来识别出潜在的危险。
风险分析:在识别出危险之后,需要对每个危险进行风险分析。这包括评估危险发生的可能性(概率)以及如果发生将造成的后果(严重性)。通过综合考虑这两个因素,可以确定每个危险的风险等级,从而确定哪些危险需要优先关注和处理。
安全需求制定:基于风险分析的结果,需要制定安全需求。这些需求旨在防止或减轻已识别的危险及其潜在后果。安全需求应该具体、明确,并能够指导系统的设计和实现。它们可能包括各种安全措施、故障处理策略、系统冗余设计等。
安全需求验证:最后一步是验证安全需求是否得到有效满足。这通常涉及对系统进行测试、仿真或实际运行,以确保其符合安全需求的要求。验证过程可能包括检查系统的故障响应、冗余功能、数据完整性等方面,以确保系统能够在各种情况下保持安全。
【问题3】
1.形式化方法:形式化方法是一种基于数学和逻辑的技术,用于对系统进行精确的描述、分析和验证。它的主要特点包括:
精确性:形式化方法使用严格的数学语言来描述系统,避免了自然语言中的模糊性和歧义性。
可验证性:通过形式化验证,可以证明系统是否满足特定的安全属性和规范,从而确保系统的正确性。
早期发现错误:形式化方法可以在系统设计的早期阶段就发现潜在的错误和漏洞,降低了后期修复的成本和风险。
然而,形式化方法也存在一些挑战,如需要较高的数学和逻辑素养、验证过程可能非常复杂和耗时等。
2.软件测试技术:软件测试技术是通过运行系统或系统的组件来评估其质量和性能的一种方法。它在安全关键系统开发中的主要特点包括:
实践性:软件测试技术注重实践,通过实际的测试活动来发现系统中的缺陷和错误。
灵活性:可以根据不同的测试目标和需求,设计不同的测试用例和测试策略。
反馈及时:测试过程中发现的错误和问题可以及时反馈给开发人员,以便及时修复和改进。
但是,软件测试技术也面临一些限制,如无法覆盖所有可能的输入和状态、测试结果的解释可能具有主观性等。
3. 论文写作
3.1. 试题一:论软件维护及其应用
请围绕“论软件维护及其应用”论题,依次从以下三个方面进行论述。
1、概要叙述你参与分析设计的软件项目以及你在其中所承担的主要工作。
2、请介绍软件维护的内容有哪些,以及常见提高可维护性的技术或方法。
3、在软件维护中,你遇到什么问题,你是用什么技术手段处理,以及处理后的效果如何。
解析:
论文素材参考:
软件维护的类型:
(1)改正性维护:改正性维护旨在修复软件中在开发阶段遗留的错误。这些错误可能是由于需求分析不全面、设计缺陷、编码错误等原因导致的。例如,在一个金融交易系统中,如果在计算利息时出现错误,导致用户账户金额不准确,这就需要进行改正性维护。这种类型的维护通常是在软件运行过程中出现故障或异常时触发,需要开发人员根据错误信息和相关的代码逻辑进行问题定位和修复。
(2)适应性维护:随着软件运行环境的变化,适应性维护变得必不可少。环境变化包括硬件设备的更新、操作系统的升级、数据库管理系统的变更等。例如,当企业将服务器硬件升级后,作系统从WindowsServer2016升级到WindowsSever2019,运行在其上的业务软件可能会出现兼容性问题,如某些功能无法正常使用或性能下降。此时,就需要对软件进行适应性维护,调整软件与新环境的适配关系,确保软件能够正常运行。
(3)完善性维护:为了满足用户不断增长的需求和提高软件的性能,完善性维护发挥着重要作用。它主要涉及对软件功能的扩充、性能的优化以及用户体验的提升。比如,在一款电商购物软件中,根据用户反馈和市场趋势,增加商品推荐功能、优化搜索算法以提高搜索结果的准确性和相关性、改进界面设计以提高用户操作的便捷性等都属于完善性维护的范法。这种维护可以增强软件的竞争力,提高用户满意度。
(4)预防性维护:预防性维护是一种前瞻性的维护策略,它是在软件还未出现明显问题时,为了预防潜在的故障和提高软件的可维护性而进行的操作。例如,对软件代码进行定期审查,发现并修复可能存在的逻辑漏洞、代码异味(如复杂度过高、耦合度过大等问题)。通过对软件架构的优化,如将紧密耦合的模块进行解耦,增加软件的可扩展性和灵活性,以便更好地应对未来可能的变化。
软件维护的方法:
(1)软件配需管理:软件配置管理是软件维护的基础。它通过对软件项目中的各种文档(如雲求文档、设计文档、测试文档等)、代码数据等进行标识、版本控制、变更管理和配置审计等操作,确保软件在维护过程中的完整性和一致性。例如,使用Git等版本控制工具开发人员可以方便地记录软件每次的变更内容、时间和人员,方便回溯和管理不同版本的软件。在进行维护操作时,可以基于版本控制系统创建分支,在不影响主版本的情况下进行修改和测试,完成后再合并回主版本。
(2)软件再工程:软件再工程包括对现有软件进行读向工程、重构和正向工程等步骢,逆向工程是从已有的软件代码和文档中提取系统设计和需求信息,帮助维护人员理解软件的结构和功能。重构则是在不改变软件外部行为的前提下,对软件的内部结构进行改进,提高代码的可读性、可维护性和可扩展性。例如,将一个大型的、复杂的函数拆分成多个功能单一、结构清晰的小函数。
正向工程是基于重构后的软件结构,重新生成新的软件系统,可能会使用更先进的技术和设计模式,进一步提升软件质量。
(3)软件测试:在软件维护过程中,测试是保证软件质量的关键环节。包括回归测试、功能测试、性能测试等多种类型。回归测试用于检查软件在修改后是否引入新的问题,确保原有功能不受影响。例如,当对一个软件模块进行功能扩充后,需要运行之前的测试用例来验证没有破坏原有的功能罗辑。功能测试则是针对新添加或修改的功能进行的测试,确保其满足预期的功能需求。性能测试用于评估软件在维护后的性能指标,如响应时间、吞叶是等是否满足要求,特别是在对软件进行性能优化的维护操作后,需要通过性能测试来验证优化效果。
(4)用户反馈收集与分析:用户是软件的直接使用者,他们在使用过程中遇到的问题和提出的建议是软件维护的重要依据。通过建立多样化的用户反馈渠道,如在线客服系统、用户论坛、问卷调查等,收集用户反馈信息。对这些反馈进行深入分析,可以发现软件中存在的问题和需要改进的方向。例如,如果大量用户反馈某个功能操作复杂或容易出错,维护人员就需要对该功能进行针对性的检查和优化。
软件维护应用案例分析:
(1)案例背景:某企业资源规划(ERP)软件维护
某制造企业使用的ERP软件已经运行了数年,在使用过程中出现了一些问题,同时企业业务发展也对软件提出了新的需求。
(2)维护过程中的方法应用
改正性维护:企业财务人员反映在生成财务报表时,有时会出现数据不一致的问题。维护团队通过对软件的日志文件分析和代码调试,发现是在财务数据汇总模块中存在一个编码错误,导致部分数据重复计算。通过修改代码中的错误逻辑,并经过严格的单元测试和回归测试,成功解决了数据不一致的问题,保证了财务报表的准确性。
适应性维护:企业决定将数据库从 Oracle11g升级到 Oracle19c,同时对服务器硬件讲行了升级。ERP软件在新的数据库环境下出现了一些兼容性问题,如某些查询功能运行缓慢。维护团队通过分析数据库的性能指标和软件与数据库的交互代码,对相关的 SQL查询语句进行优化,调整了软件与数据库的连接参数,并对部分依赖于旧数据库特性的代码进行了修改。同时,针对新的硬件环境,对软件的配置参数进行了调整,以充分利用硬件资源,提高软件的性能,确保ERP 软件在新环境下能够稳定、高效地运行。
完善性维护:根据企业生产部门和销售部门的反馈,希望在 ERP软件中增加生产计划的可视化功能和销售数据分析功能。维护团队首先进行了详细的需求分析,然后对软件架构进行了适当调整,在不影响原有功能的基础上,添加了新的模块。在开发过程中,采用了软件再工程的方法,对部分相关代码进行了重构,提高代码的可读性和可维护性。新功能开发完成后,通过功能测试、性能测试和用户试用,确保新功能满足业务需求且不会对原有功能产生负面影响。
预防性维护:为了提高ERP软件的可维护性和应对未来可能的变化,维护团队定期对软件代码进行审查。利用代码分析工具发现了一些代码存在的潜在问题,如部分模块之间的耦合度过高、代码的重复率较高等。针对这些问题,对软件进行了重构,将高耦合的模块进行解耦,提取公共代码形成独立的函数或类,降低了代码的复杂度。同时,对软件的文档进行了更新和完善,包括对软件架构、模块功能、接口设计等方面的详细描述,方便后续维护人员理解和操作。
(3)效果分析
通过上述软件维护工作,该 ERP软件在企业中的运行状况得到了显著改善。软件的稳定性和可靠性提高,减少了因软件问题导致的业务中断风险。新功能的添加满足了企业业务发展的需求,提高了企业的运营效率和管理水平。软件的可维护性增强,降低了后续维护的难度和成本,为软件的长期使用和持续改进奠定了良好的基础。
软件维护面临的挑战与应对策略:
(1)挑战
软件复杂性增加:随着软件系统功能的不断扩充和技术的发展,软件的复杂性呈指数级增长。大型软件系统可能包含大量的模块、复杂的业务逻辑和众多的技术组件,这使得维护人员很难全面掌握软件的结构和功能,增加了维护的难度。例如,一些复杂的企业级软件系统可能涉及多种不同的技术领域,如数据库技术、网络技术、人工智能技术等,维护人员需要具备广泛的知识和技能。
技术更新换代快:信息技术领域的发展日新月异,新的技术、框架和工具不断涌现。软件维护人员需要不断学习和适应这些新技术,以便在维护过程中能够运用最新的技术手段解决问题。例如,当软件需要从传统的架构向微服务架构转型时,维护人员需要掌握微服务相关的技术,如容器化技术(Docker、Kuberetesa等)、服务治理技术等,这对维护人员的学习能力和知识更新速度提出了很高的要求。
维护成本控制:软件维护需要投入大量的人力、物力和财力资源,包括维护人员的薪酬、硬件设备的更新、软件工具的采购等。随着软件规模的扩大和维护周期的延长,维护成本可能会不断增加,企业需要在保证软件质量的同时,合理控制维护成本,避免维护成本过高影响企业的经 济效益。
(2)应对策略
加强知识管理与人员培训: 建立企业内部的软件知识管理体系,对软件的开发文档、维护记录、技术资料等进行有效的管理和共享,方便维护人员学习和查询。同时,定期为维护人员提供技术培训,包括新技术、新方法的培训以及针对特定软件系统的业务培训,提高维护人员的专业素养和业务能力。鼓励维护人员之间的交流和经验分享,形成良好的学习氛围。
采用先进的维护工具和技术:利用现代化的软件维护工具,如自动化测试工具(Selenium、JUnit 等)、代码分析工具(SonarQube等)、配置管理工具(Git、SVN等),提高维护工作的效率和质量。在技术更新时,采用渐讲式的汗移策略,例如在将传统软件向微服务架构转型时,可以先将部分功能模块进行微服务化改造,逐步积累经验,降低技术更新的风险。同时,关注行业内的最佳实践案例,积极引进和应用先进的维护技术和方法。
成本效益分析与优化:在进行软件维护决策时,进行详细的成本效益分析。根据软件对企业业务的重要性、维护成本、潜在收益等因素制定合理的维护计划。对于一些对业务影响较小且维护成本高昂的功能,可以考虑进行替代或优化。例如,如果某个软件模块的维护成本过高且其功能可以通过其他方式实现,可以评估是否停用该模块或采用第三方软件替代。同时,优化维护流程,减少不必要的工作环节提高维护资源的利用效率。
3.2. 试题二:论面向服务的架构设计
请围绕“论面向服务的架构设计”,依次从以下三个方面进行论述。
1、概要叙述你参与分析设计的软件项目以及你在其中所承担的主要工作。
2、论面向服务的架构设计基于WebService的面向服务架构实现过程,SOA具有哪些特征,支撑软件功能重用。
3、具体阐述你参与的软件项目是如何以面向服务的架构为指导实施的,在实施过程中遇到哪些问题,是如何解决的。
解析:
解题思路:
我参与分析和开发的项目是一个大型的电商平台,该平台拥有数亿用户和海量数据。为了应对业务快速发展和需求变更,我们采用了面向服务架构(SOA)来设计和开发系统。我主要负责系统架构只设计和技术方案制定。
SOA的主要技术和标准包括:
Web服务:一种基于XML的标准,用于在互联网上进行数据交换。
WSDL:Web服务描述语言,用于描述Web服务的功能和接口。
SOAP:简单对象访问协议,用于在Web服务之间进行消息传递。
UDDI:通用描述、发现和集成,用于注册和查找Web服务。
ESB:企业服务总线,用于提供服务路由、消息转换等功能。
我们在构建SOA架构时遇到了以下问题:服务粒度划分:如何划分服务粒度是SOA架构设计中的关键问题,服务粒度划分过大,会导致服务过于复杂,难以维护;服务粒度划分过小,会导致服务数量过多,增加系统复杂度。服务接口设计:服务接口设计需要考虑服务的易用性、可扩展性等因素。服务安全性:SOA架构中,服务之间通过网络进行通信,因此需要考虑服务安全问题。服务治理:SOA架构中,需要对服务进行有效地管理,包括服务注册、发现、调用、监控等。
通过采用SOA架构,我们有效地提高了系统的灵活性、可扩展性和可维护性。具体实施效果如下:提高了系统的灵活性:SOA架构使得我们可以快速地添加、修改和删除服务,以满足业务需求的变化。提高了系统的可扩展性:SOA架构使得我们可以很容易地扩展系统以满足业务发展需求。提高了系统的可维护性:SOA架构使得我们可以更容易地维护系统,降低了维护成本。
面向服务架构是一种有效的软件架构设计方法,可以有效地提高系统的灵活性、可扩展性和可维护性。在实际应用中,需要根据具体情况选择合适的SOA技术和标准,并解决好SOA架构设计和实施过程中遇到的问题。在未来的工作中,我们将继续研究和实践面向服务架构,不断提高SOA架构设计和实施水平。
论文素材参考:
面向服务的架构(SOA)概念和特征
概念:面向服务的架构是一种分布式计算架构,它将企业的业务功能抽象为一系列相互独立、可复用的服务。这些服务通过明确定义的接口进行通信,并可以在不同的应用程序和系统中被调用。SOA的核心思想是将业务逻辑从具体的技术实现中分离出来,以服务的形式对外提供,实现业务功能的灵活组合和复用。
特点:
松耦合性:服务之间通过接口进行交互,彼此之间的依赖关系较弱。这种松耦合的特性使得服务可以独立开发、部署和更新,不会因为某个服务的变化而对其他服务产生重大影响。例如,在一个电商企业中,订单服务和库存服务是松耦合的,当订单服务升级以适应新的促销策略时,库存服务可以保持不变。
可复用性:服务是独立的业务功能单元,可以在多个不同的业务流程和应用场景中被重复使用。比如,用户认证服务可以在企业的多个系统(如内部办公系统、客户服务系统等)中使用,减少了重复开发的工作量,提高了开发效率。
互操作性:SOA支持不同平台、不同编程语言和不同技术架构的系统之间的交互。通过使用标准的通信协议(如HTTP、SOAP等)和数据格式(如XML、JSON等),服务可以被各种类型的客户端调用,促进了企业内部和企业间的系统集成。
灵活性和适应性:企业业务经常面临变化,SOA架构可以轻松地对业务流程进行重新组合和调整。通过增加、修改或删除服务,可以快速响应市场变化和业务需求的调整。例如,当企业推出新的业务模式时,可以通过组合现有的服务或开发新的服务来满足新的业务流程。
面向服务的架构关键技术
(1)服务描述语言:常用的服务描述语言有WSDL(WebServicesDescriptionLanguage)等。WSDL用于描述服务的功能、接口、输入输出参数以及调用方式等信息,使服务使用者能够清楚地了解服务的内容和使用方法。它是实现服务互操作性的重要基础,为服务的发布和调用提供了标准化的描述。
(2)服务注册与发现:服务注册中心是SOA的关键组件之一,例如UDDI(UniversalDescription,Discovery,andIntegration)。服务提供者将服务的描述信息注册到服务注册中心,服务使用者可以在注册中心查找所需的服务。这种机制方便了服务的管理和查找,提高了服务的利用率。
(3)消息传递机制:在SOA中,服务之间的诵信通常通过消息传诺来实现、可以使用SOAP(SimpleObiectAccessProtocl)或RES(RepresentationalStateTransfer)等方式。SOAP是一种基于XML的协议,它提供了一种标准化的方法在不同的系统之间交换信息,REST则是一种轻量级的架构风格,利用HTTP协议的方法(如GET、POST、PUT、DELETE)来实现资源的操作和信息传递,更适合于简单的Web应用场景。
面向服务的架构设计原则
(1)业务驱动原则:SOA设计应以企业业务需求为出发点,将业务流程分解为一系列可管理的服务。首先要深入理解企业的业务模型和业务流程,识别出核心业务功能和业务规则,然后将这些业务功能抽象为服务。例如,在金融企业中,贷款审批流程可以分解为客户信息查询、信用评估、风险分析等服务。
(2)服务粒度适中原则:服务粒度的选择至关重要。如果服务粒度过细,会导致系统过于复杂,增加服务管理和调用的成本;如果粒度过粗,则会降低服务的复用性。需要根据业务功能的性质和使用频率来确定合适的服务粒度。例如,在一个物流企业中,货物跟踪服务可以是一个相对独立且合适粒度的服务,而不是将货物的所有信息查询和操作都合并在一个大的服务中。
(3)分层架构原则:采用分层的架构设计可以提高系统的可维护性和可扩展性。一般可以分为表现层、业务逻辑层和数据访问层等。表现层负责与用户的交豆,业务逻辑层包含了各种业务服务,数据访问层负责与底层数据库的交互。每个层次都有明确的职责,通过接口进行通信。例如,在一个企业资源规划(ERP)系统中,用户在表现层提交订单,业务逻辑层的订单服务处理订单逻辑,数据访问层负责将订单数据存储到数据库中。
面向服务的架构设计案例分析:
(1)案例背景
某大型制造企业拥有多个生产基地和销售部门,其原有的信息系统是基于传统的单体架构构建的,随着业务的拓展和企业规模的扩大,系统面临着升级困难、功能扩展不便、与外部合作伙伴系统集成复杂等问题。因此,企业决定采用面向服务的架构对信息系统进行重构。
(2)SOA设计过程
业务分析与服务识别:通过与企业各部门的深入沟通和对业务流程的详细梳理,识别出了一系列核心服务,包括生产计划服务、原材料采购服务、订单处理服务、产品库存服务、客户管理服务等。例如,生产计划服务根据销售订单和库存情况制定生产计划,涉及到多个部门的业务数据和流程。
服务设计与接口定义:针对每个服务,设计其功能和接口。以订单处理服务为例,其接口定义了订单创建、订单查询、订单修改和订单删除等操作,使用XML格式来描述订单数据结构,并采用REST风格的接口实现服务的调用。同时,考虑到服务的复用性和互操作性遵循了行业标准和企业内部的规范。
服务实现与部署:根据设计好的服务和接口,采用合适的技术实现服务。例如,订单处理服务可以使用Java语言和Soring框架来实现将服务部署在企业的服务器集群上。在部署过程中,要考虑服务的性能、可靠性和安全性等因素,配置相应的服务器资源和安全策略。
服务注册与调用:建立企业级的服务注册中心,使用开源的UDD!实现感自定义的注册机制,服务提供者将服务信息注册到注册中心后其他应用程序和系统可以在注册中心查找并调用所需的服务。例如,销售部门的订单管理系统可以通过注册中心查找并调用订单处理服务来处理客户订单,
(3)效果分析
通过实施面向服务的架构设计,该制造企业的信息系统得到了显著的改善。首先,系统的灵活性大大提高,当企业推出新的产品或调整业务流程时,可以快速地通过组合或修改现有服务来适应变化。其次,服务的复用性减少了重复开发的工作量,提高了开发效率。例如,原材料采购服务可以在多个不同的生产项目中使用。此外,与外部合作伙伴系统的集成变得更加容易,通过标准的接口和协议,可以与供应商、物流企业等合作伙伴的系统进行无缝对接,提升了企业的整体运营效率。
SOA设计面临的挑战与应对策略:
(1)挑战
服务治理问题:随着服务数量的增加,服务的管理和协调变得复杂。包括服务的版本控制、服务的依赖关系管理、服务的性能监控等如果服务治理不当,可能会导致服务之间的冲突、系统性能下降等问题
安全问题:SOA环境下,服务的分布式和开放性特点增加了安全风险。服务之间的通信可能会受到攻击,企业的核心数据可能会因服务的漏洞而泄露。需要考虑服务的身份认证、授权、数据加密等安全措施。
性能问题:服务之间的通信开销、服务的响应时间等可能会影响整个系统的性能。特别是在高并发的业务场景下,如何保证服务的高效运行是一个挑战。
(2)应对策略
建立完善的服务治理框架:通过建立服务治理框架,对服务进行统一管理。包括使用版本管理工具来管理服务的版本,通过配置管理数据库(CMDB)来记录服务的依赖关系,利用性能监控工具实时监测服务的性能指标,并根据监控结果及时调整服务。
加强安全设计:在SOA架构设计的各个环节融入安全设计。采用安全的通信协议(如HTTPS),实施服务的身份认证机制(如OAuthJWT等),对服务的访问进行严格的授权控制,对敏感数据进行加密处理。同时,定期进行安全审计和漏洞扫描,确保系统的安全。
性能优化措施:从服务的设计、实现和部署等方面进行性能优化。在设计阶段,合理规划服务粒度和服务接口,减少不必要的通信开销;在实现阶段,优化服务代码,提高代码质是和执行效率:在部署阶段,根据服务的负载情况合理分配服务器资源,采用缓存技术、负载均衡技术等提高服务的响应速度。
3.3. 试题三:论多源异构数据集成方法
请围绕“论多源异构数据集成方法”论题,依次从以下三个方面进行论述。
1、概要叙述你参与分析设计的软件项目以及你在其中所承担的主要工作。
2、多源异构数据集成的主要内容,以及实现异构数据源集成的技术路线。
3、具体阐述你参与的软件项目是如何做到多源异构数据集成,过程中遇到哪些问题,是如何解决的,以及处理后的效果如何。
解析:
论文素材参考:
在当今数字化时代,企业和组织内部的数据来源日益多样化,包括关系数据库、文件系统、XML文档、Web服务等多种形式,这些数据在结构、语义和存储方式上存在显著差异,即多源异构数据。有效地集成这些数据对于企业的数据分析、决策支持和业务流程优化至关重要。然而,多源异构数据集成面临着诸多复杂的问题,需要合适的方法来解决。
多源异构数据集成的重要性与挑战:
(1)重要性
支持全面的决策分析:企业的决策需要综合考虑来自各个业务部门和不同系统的数据。例如,在企业资源规划ERP)中,需要整合财务数据、生产数据、销售数据等多源异构数据,才能准确分析企业的运营状况,制定合理的战略决策,如优化生产计划、调整销售策略等。
提升业务流程效率:通过集成多源异构数据,可以打破不同业务系统之间的信息孤岛,实现业务流程的自动化和优化。比如在供应链管理中,集成供应商数据、物流数据和库存数据,可以使采购、运输和存储等环节更加协同,减少库存积压和缺货现象,提高供应链的整体效率。
挖掘数据潜在价值:不同来源的数据可能蕴含着互补的信息。将客户关系管理(CRM)系统中的客户行为数据与企业的产品数据集成,可以通过数据挖掘技术发现客户需求与产品特征之间的关联,为产品创新和个性化营销提供依据,从而挖掘出数据的潜在价值。
(2)挑战
数据结构差异:多源异构数据在结构上存在巨大差异,包括关系型数据的表格结构、XML的层次结构、JSON的键值对结构以及文本文件的无结构形式等。例如,将结构化的数据库数据与半结构化的XML文档数据集成时,需要解决如何统一表示和处理这些不同结构数据的问题。
语义异构性:即使数据结构相似,不同数据源中的数据可能具有不同的语义。相同的术语在不同的业务领域或系统中可能有不同的含义或者不同的术语可能表示相同的概念。例如,在一个企业中,“客户”在销售系统和售后服务系统中的定义和包含的信息可能不完全相同这就需要进行语义的统一和映射。
数据质量问题:不同数据源的教据质量参差不齐,可能存在数据缺失、错误、重复等问题,这些问题在集成讨程中会相互影响,增加了数据处理的复杂性。例如,从多个传感器采集的数据可能由于设备故障或环境干扰而存在误差,在与其他业务数据集成时需要进行数据清洗和质量提升。
数据源的动态变化:数据源可能会随着时间发生变化,包括数据内容的更新、数据模式的修改、新数据源的加入和旧数据源的删除等。数据集成系统需要具备足够的灵活性和适应性来应对这些变化,确保集成数据的准确性和及时性。
多源异构数据集成方法:
(1)数据仓库方法
原理:数据仓库方法是将各个数据源的数据抽取、转换和加载(ETL)到一个集中的数据仓库中。在ETL过程中,对数据进行清洗、转换和集成,使其符合数据仓库的统一数据模型。数据仓库通常采用多维数据模型,如星型模型或雪花型模型,以便于进行数据分析和查询。
优点:数据在存储前经过了预处理,数据质量较高,有利于提高查询和分析效率;数据仓库提供了统一的数据视图,便于用户使用;可以使用成熟的商业智能工具进行数据分析和挖掘。
缺点:ETL过程复杂且耗时,特别是当数据源频繁变化时,需要重新设计和执行ETL流程;数据仓库的数据更新存在一定延迟,不能实时反映数据源的变化;需要大量的存储空间来存储预处理后的集成数据。
(2)中间件方法
原理:中间件方法是在数据源和应用程序之间插入一个中间件层。中间件通过包装器(Wrapper)对不同数据源的数据进行访问和处理将数据源的本地数据格式和操作转换为统一的接口形式。应用程序通过这个统一接口与中间件交互,实现对多源异构数据的访问和集成,
优点:对数据源的影响较小,不需要对数据源进行大量修改;具有较好的灵活性和适应性,可以快速集成新的数据源;能够实时或近实时地访问数据源数据,适用于对数据时效性要求较高的应用。
缺点:中间件的设计和实现复杂,需要处理不同数据源的多种协议和数据格式;由于需要实时访问数据源,可能会对数据源的性能产生一定影响;在数据一致性和完整性方面可能存在一定挑战,因为数据没有经过集中的预处理。
(3)联邦数据库方法
原理:联邦数据库方法是将多个异构数据库系统联合在一起,形成一个虚拟的、统一的数据库系统。在联邦数据库中,各个参与的数据库系统仍然保持其自治性,同时通过全局模式和映射机制实现对多个数据库的统一访问。全局模式定义了联邦数据库的逻辑结构,映射机制将全局模式与各个数据源的本地模式相连接。
优点:保留了数据源的自治性,各数据源可以独立管理和更新;对已有数据库系统的改动较小,适用于集成现有数据库系统;可以在一定程度上实现数据的共享和互操作,提高数据的利用率。
缺点:全局模式的设计和维护复杂,需要处理不同数据库之间的语义差异和结构差异;查询处理可能较为复杂,因为需要在多个数据源之间进行协调和数据整合;数据一致性维护困难,尤其是当不同数据源之间存在并发更新时。
多源异构数据集成方法应用案例分析:
(1)案例背景:某大型制造企业的数据集成项目
某大型制造企业拥有多个生产基地和业务部门,其数据来源包括生产管理系统(关系数据库)、设备监控系统(实时数据采集系统)、质量检测系统(XML文件和关系数据库混合)等,企业需要整合这些数据用于生产决策、质量控制和供应链优化。
(2)方法选择与应用过程
数据仓库方法应用于生产决策:对于生产决策分析,采用数据仓库方法。从各个生产基地的生产管理系统中抽取生产计划、产量、工时等数据,从设备监控系统中抽取设备运行参数和故障信息,从质量检测系统中抽取产品质量数据。通过ETL过程对这些数据进行清洗、转换和集成,构建了以生产订单为核心的星型数据模型的数据仓库。企业管理人员可以使用商业智能工具从数据仓库中快速获取不同维度(如时间、生产基地、产品类型等)的生产数据报表和分析结果,为生产计划调整和资源分配提供决策依据。
中间件方法应用于实时质是监控:在质是控制方面,为了实时监控产品质量,采用中间件方法。中间件通过包装器与质量检测系统中的XML文件和关系数据库建立连接,将质量数据的访问接口统一。质量监控应用程序通过中间件实时获取最新的质量检测数据,包括原材料检验数据、生产过程中的半成品检验数据和成品检验数据。当检测到质量异常时,可以及时发出警报并采取相应的措施,确保产品质量的稳定性。
联邦数据库方法应用于供应链优化:对于供应链优化,采用联邦数据库方法。将企业内部的采购数据库、库存数据库和物流合作伙伴的数据库联合起来。通过设计全局模式,将采购订单、库存信息和物流运输信息进行统一表示。在这个虚拟的联邦数据库中,企业可以方便地查询和分析整个供应链上的货物流动情况,实现采购、库存和物流的协同优化,减少库存成本和运输时间。
(3)效果分析
通过综合应用不同的数据集成方法,该制造企业成功实现了多源异构数据的有效集成。在生产决策方面,数据仓库提供了高质量、全面的数据分析支持,提高了决策的准确性和效率,中间件方法在实时质量监控中保证了数据的时效性,及时发现和处理质量问题,降低了产品次品率,联邦数据库方法优化了供应链管理,提高了供应链的协同性和灵活性,降低了运营成本。
多源异构数据集成实施的关键因素和应对策略:
(1)关键因素
数据模型设计:合理的数据模型是数据集成的基础。无论是数据仓库的多维数据模型、中间件的统一接口模型还是联邦数据库的全局模式,都需要准确地反映数据源的数据结构和语义关系,同时考虑到数据的扩展性和易用性。
数据质量保障:在集成过程中,要重视数据质量问题。包括数据清洗、去重、补全和数据一致性检查等措施。需要建立数据质量评估标准和监控机制,确保集成后的数据能够满足业务需求。
性能优化:数据集成系统的性能直接影响到用户体验和业务应用的效果。需要考虑数据抽取、转换、加载的效率,中间件的访问性能以及联邦数据库的查询性能等。优化数据存储结构、查询算法和网络通信等方面,提高系统的整体性能。
安全与隐私保护:在集成多源异构数据时,可能涉及企业的核心数据和敏感信息。需要建立严格的安全机制,包括数据访问控制、加密传输和存储等措施,保护数据的安全和隐私。
(2)应对策略
选代式开发与模型改进:由于数据源的复杂性和业务需求的动态变化,数据集成项目通常难以一次性完成。采用迭代式开发方法,根据业务需求的优先级逐步集成数据源,并不断改进数据模型,以适应新的数据和业务变化。
自动化与智能化的数据处理:利用数据清洗、数据质量评估和性能优化Q的自动化工具,提高数据处理的效率和质量。同时,可以探索智能化技术,如机器学习四算法在数据清洗、数据四配和语义映射中的应用,进一步优化数据集成过程。
建立安全管理体系:制定全面的安全策略和管理制度,包括用户身份认证、授权管理、数据加密标准和安全审计等内容,定期对数据集成系统进行安全检查和漏洞扫描,确保数据的安全和隐私不受侵犯。
(3)总结
多源导构数据集成是企业和组织在数字化发展过程中面临的重要挑战,数据仓库、中间件和联邦数据库等方法各有优缺点,在不同的应用场景中发挥着独特的作用。在实施数据集成时,需要综合考虑数据模型设计、数据质量保障、性能优化和安全与隐私保护等关键因素,并采取相应的应对策略。通过合理选择和应用数据集成方法,企业可以有效地整合多源异构数据,挖掘数据的潜在价值,提升业务决策水平和运营效率,从而在激烈的市场竞争中获得优势。
3.4. 试题四:论分布式事务及其解决方案
请围绕“论分布式事务及其解决方案”论题,依次从以下三个方面进行论述。
1、概要叙述你参与分析设计的软件项目以及你在其中所承担的主要工作。
2、请介绍4种分布式事务的解决方案及简单说明。
3、具体阐述你参与的软件项目是如何做到分布式事务的,过程中遇到哪些问题,是如何解决的。
解析:
论文素材参考:
分布式事务背景和面临的挑战:
(1)概念
分布式事务是指在分布式系统中,涉及多个数据源(如不同的数据库、消息队列等)或多个服务的操作,这些操作需要作为一个整体来执行,要么全部成功,要么全部失败,以保证数据的一致性。例如,在电商系统中,下单操作可能涉及库存系统扣减库存、订单系统创建订单、支付系统处理支付等多个子系统的操作,这些操作构成了一个分布式事务。
(2)产生背景
数据分散存储:随着业务的发展,数据往往被存储在多个不同的数据库或存储系统中,以满足不同的功能需求和性能只要求。例如,一个大型企业可能有多个分公司,每个分公司都有自己的本地数据库,而总公司需要对这些数据进行统一管理和业务操作,这就导致了分布式事务的需求。
微服务架构的兴起:微服务架构Q将一个大型应用拆分成多个独立的小服务,每个服务都有自己的数据库。当一个业务流程需要多个微服务协同完成时,就会产生分布式事务。比如,在一个基于微服务的金融系统中,贷款审批服务可能需要调用客户信息服务、信用评估服务和风险控制服务等,这些服务之间的操作需要保证事务的一致性。
(3)面临的挑战
网络通信问题:分布式系统中的节点通过网络进行通信,网络的不可靠性(如延迟、丢包、中断等)可能导致事务消息的丢失或延迟,从而影响事务的正常执行。例如,在两阶段提交过程中,协调者与参与者之间的通信故障可能导致参与者无法及时收到决策信息,陷入等待状态。
数据一致性问题:在分布式事务中,要保证多个数据源的数据在任何时候都保持一致是非常困难的。不同节点的数据更新可能由于各种原因(如部分节点故障、网络分区等)不能同步进行,从而导致数据不一致,例如,在一个跨数据库的转账事务中,如果一个数据库更新成功,另一个数据库更新失败,就会出现数据不一致的情况。
性能问题:分布式事务的处理通常需要额外的协调和通信开销,这可能会对系统的性能产生较大影响。特别是在高并发场景下,频繁的事务协调可能导致系统响应时间延长,吞叶是降低。例如,两阶段提交协议需要多次网络交互,在大量事务同时执行时,会占用大量的网络资源和计算资源。
分布式事务解决方案:
(1)两阶段提交(2PC)
原理:2PC协议将分布式事务的提交过程分为两个阶段:准备阶段和提交阶段。在准备阶段,协调者向所有参与者发送准备请求,参与者执行本地事务操作,但不提交,然后向协调者反馈准备结果。如果所有参与者都准备成功,协调者在提交阶段向所有参与者发送提交请求,参与者提交本地事务;否则,协调者发送回滚请求,参与者回本地事务。
优点:实现原理相对简单,能够保证事务的强一致性,适用于对数据一致性要求极高的场景,如银行转账等核心金融业务。
缺点:存在单点故障问题,协调者故障可能导致整个事务阻塞;性能较差,由于多次网络交互和等待,在高并发场景下可能成为系统性能瓶颈;可能出现数据不一致问题,如在提交阶段协调者发送的提交请求部分参与者未收到时,这些参与者可能会自行决定回滚或等待,导致数据不一致。
(2)三阶段提交(3PC)
原理:3PC在2PC的基础上增加了一个预提交阶段。在预提交阶段,协调者询问参与者是否可以提交事务,参与者进行本地事务的预处理并反馈结果。如果大多数参与者反馈可以提交,协调者进入准备阶段,后续流程与2PC类似。这个预提交阶段可以减少参与者在等待协调者决策时的阻赛时间。
优点:相比2PC,在一定程度上降低了参与者的阻塞范围和时间,减少了协调者单点故障对事务的影响,提高了系统的可用性
缺点:实现复杂度增加,性能仍然受到多次网络交互的影响,目仍然不能完全避免数据不一致的情况,只是降低了发牛的概率
(3)补偿事务(TCC)
原理:TCC将分布式事务拆分为三个阶段:Try、Confimm和Cancel。Try阶段主要是对业务资源的检查和预留,如冻结库存、预留资金等,但不进行实际的业务操作。Confrm阶段在所有参与者都Try成功的情况下,执行真正的业务操作,如扣减库存、完成转账等。Cancel阶段则在事务需要回滚时,对Try阶段预留的资源进行释放,恢复到事务前的状态。
优点:具有较好的灵活性和可扩展性,对业务的侵入性相对较小,可以根据不同的业务逻辑定制Try、Confrm和Cance!操作。适用于长事务和对性能要求较高的场景。
缺点:业务实现复杂度高,需要开发人员手动编写大量的补偿逻辑,对开发人员的要求较高;如果补偿逻辑编写不当,可能会导致数据不致或业务异常。
(4)本地消息表
原理:在本地消息表方案中,每个参与事务的服务都有一个本地消息表。当一个服务执行本地事务时,同时将需要其他服务执行的操作以消息的形式插入本地消息表。然后通过一个后台任务不断扫描本地消息表,将消息发送给其他服务。其他服务收到消息后执行相应操作。并反馈执行结果。如果执行成功,删除本地消息表中的消息;如果执行失败,可以进行重试或人工干预。
优点:避免了分布式事务协调器的单点故障问题,提高了系统的可靠性;对业务代码的侵入性相对较小,实现相对简单;适用于对最终致性要求较高的场景。
缺点:消息可能会堆积,需要合理设计消息处理机制和重试策略;可能存在消息丢失的风险,需要增加额外的机制(如消息持久化和确认机制)来保证消息的可靠性。
(5)消息队列的最终一致性
原理:基于消息队列实现分布式事务时,业务操作首先向消息队列发送一条消息,消息队列保证消息的可靠存储和传说。其他服务从消息队列中获取消息并执行相应的业务操作。通过消息的重试机制和补偿机制来保证即使在出现部分失败的情况下,系统最终能够达到一致性状态。这种方案不要求所有操作在同一时间点完成,允许一定的时间延迟来实现最终一致性。
优点:具有很高的性能和可扩展性,适合高并发的分布式系统;通过消息队列的异步处理方式,可以降低系统的耦合度,提高系统的灵活性;可以根据业务需求灵活调整消息的处理策略和重试次数。
缺点:实现最终一致性可能需要较长的时间,在这个过程中系统可能处于一种不一致的中间状态;需要处理消息的重复消费问题,防止因消息重复执行导致业务异常。
3.5. 分布式事务解决方案应用案例分析:
(1)案例背景:某电商系统的分布式事务处理
某电商系统采用微服务架构,包括订单服务、库存服务、支付服务等多个微服务,每个微服务都有自己的数据库。在用户下单、支付等业务流程中涉及分布式事务问题。
(2)解决方案选择与应用
订单创建与库存扣减:对于订单创建和库存扣减这两个操作,由于对数据一致性要求较高,采用了TCC方案。在Try阶段,库存服务冻结用户购买商品的数量,订单服务创建一个临时订单(状态为待支付)。如果用户成功支付(Confrm阶段),库存服务扣减冻结的库存,订单服务将订单状态更新为已支付;如果支付失败(Cancel阶段),库存服务释放冻结的库存,订单服务删除临时订单。
支付外理与议单状态思新:支付外理洗及支付服务与认单服务之间的不口,这里买用了不地消县美方案。当支付成功时,支付服条将支付成功的消息插入本地消息表,同时更新自己的支付记录。后台有一个消息处理任务,不断扫描本地消息表,将支付成功的消息发送给订单服务。订单服务收到消息后更新订单状态。如果消息发送失败,会进行重试。
物流信息更新与订单状态同步:物流信息更新与订单状态同步对实时性要求不是特别高,采用了消息队列的最终一致性方案。物流服务在处理物流信息更新时向消息队列发送消息,订单服务从消息队列中获取消息后更新订单的物流状态。通过消息的重试机制和去重机制,保证即使在网络不稳定或物流服务短暂故障的情况下,最终订单的物流状态能够与实际物流情况一致。
(3)效果分析
通过合理选择和应用不同的分布式事务解决方案,该电商系统在保证业务数据一致性的前提下,提高了系统的性能和可扩展性。TCC方案保证了关键业务操作(如订单创建和库存扣减)的强一致性,本地消息表方案有效地协调了支付和订单状态更新的操作,消息队列的最终一致性方案满足了物流信息更新的灵活性和高并发处理需求。同时,系统在面对网络故障、部分服务故障等情况时,能够通过相应的机制保证业务的正常运行和数据的最终一致性。
选择和实施分布式事务解决方案的考虑因素:
(1)业务需求
根据业务对一致性的要求来选择解决方案。如果业务对数据一致性要求极高,如金融核心业务,可能需要选择强一致性的方案(如2PC、3PC);如果对性能和灵活性要求较高,且可以接受一定的不一致时间窗口,则可以选择最终一致性方案(如本地消息表、消息队列最终一致性等)。
(2)系统性能
考虑不同解决方案对系统性能的影响,特别是在高并发场景下。例如,2PC和3PC在高并发时可能会导致性能瓶颈,而基于消息队列的方案通常具有更好的性能表现,但可能需要处理消息的重复消费和消息堆积等问题。
(3)开发难度和成本
不同的解决方案对开发人员的要求和开发成本不同。TCC方案雲要开发人员编写复杂的补偿罗辑,开发难度较大:而本地消息表和消息队列方案相对简单,但需要考虑更多的异常处理和消息管理问题。需要综合评估企业的技术实力和开发资源来选择合适的方案。
(4)系统的可靠性和可用性
考虑方案在面对网络故障、节点故障等异常情况时的应对能力。例如,2PC存在协调者单点故障问题,而本地消息表和消息队列方案可以通过几余和重试机制提高系统的可靠性和可用性。
分布式事务是分布式系统中一个复杂而关键的问题,其解决方案多种多样,各有优缺点和适用场景。在设计分布式系统架构时,需要根据业务需求、系统性能、开发难度和系统可靠性等多方面因素综合考虑,选择合适的分布式事务解决方案。通过合理的解决方案,可以在保证数据一致性的同时,提高分布式系统的性能、可扩展性和可用性,确保分布式系统能够稳定、高效地运行,满足企业业务发展的需求。