MySQL笔记3
一、数据库对象
1.组成
| 对象名称 | 描述 |
|---|---|
| 表 | 基本数据存储对象,以行列形式存在,列是字段、行是记录 |
| 约束 | 执行数据校验,保障数据完整性 |
| 数据字典 | 系统表,存放数据库相关信息 |
| 视图 | 一个或多个表数据的逻辑显示 |
| 索引 | 用于提升查询性能 |
2.数据库对象的命名规则
(1)用有意义英文词汇,词汇间以下划线分隔
(2)名称由字母、数字、#、下划线、$组成,且以英文字母开头
(3)不使用 MySQL 保留字
(4)所有对象统一用小写字母,保证一致性
(5)同一数据库对象集合内对象不能同名
3.生产中对象命名规范
数据库:
(1)命名尽量不超 30 个字符
(2)一般为项目名称 + 库含义简写,如 IM 项目工作流数据库,可以是 im_flow
(3)命名用小写
表:
(1)常规表:以 t_ 开头( t 代表 table ),命名规则 t + 模块简写 + 表简写 ,如用户模块教育信息表 t_user_eduinfo
(2)临时表:(temp)前缀 + 模块 + 表 + 日期后缀,如 temp_user_eduinfo_20240520
(3)备份表:(bak)前缀 + 模块 + 表 + 日期后缀,如 bak_user_eduinfo_20231219
(4)同一模块表尽量用相同前缀,表名表达含义,多个单词以下划线分隔,常规表名尽量不超 30 字符,临时表、备份表也尽量简短,命名用小写
二、表的基本操作
1.数据类型
语句格式:create table 表名(字段名1 数据类型,字段名2 数据类型,.........)
(1)数值类型:精确存储数字,选对类型能减少空间浪费、避免精度丢失
整型(存整数):
| 类型 | 字节数 | 典型场景 |
|---|---|---|
| tinyint | 1 | 存枚举值(如性别:0=女、1=男) |
| smallint | 2 | 存商品库存(小范围数量,如<3万) |
| int | 4 | 存用户id、订单号 |
| bigint | 8 | 存超大数(如财务大额) |
| mediumint | 3 | 存储中等规模的整数(如网站文章阅读量) |
整型(N)表现形式:有时代码写法为int(10),表示数字宽度限制,要求如下:
无论N等于多少,int永远占4个字节
N表示的是显示宽度,不足则补0,超过长度则会无视长度直接显示整个数字
注:实际开发的角度,一定要为合适的列选取合适的数据类型。
浮点型(存小数):
| 类型 | 字节数 | 特点 | 典型场景 |
|---|---|---|---|
| float | 4 | 单精度,存近似值 | 存商品评分(对精度要求不极致) |
| double | 8 | 双精度,存近似值 | 存科学计算、工程数据(如卫星轨道参数) |
| decimal | 可变 | 精准存储(字符串形式) | 存金额(如19.99元,必须精准) |
注:可以使用float(M,D)、double(M,D)格式限制宽度按(M)和精度(D),如float(3,2),不指定M、D的时,会按照实际的精度来处理
(2)文本类型:存字符串、大文本、二进制数据(图片/文件),选对类型能优化存储和查询效率
固定/可变长度字符串(短文本)
| 类型 | 核心特点 | 长度限制 | 典型场景 |
|---|---|---|---|
| char(size) | 固定长度,不足补空格(查询时会去掉末尾空格) | 0~255 字符 | 手机号(11位固定)、身份证号 |
| varchar(size) | 可变长度,按需分配空间(更省空间) | 0~255 字符(超255转text) | 用户名、邮箱、短地址 |
大文本(字符型,存超长字符串)
| 类型 | 最大长度(字符数) | 适用场景 |
|---|---|---|
| tinytext | 255 | 短评、标签(极短文本) |
| text | 65,535 | 文章正文、商品描述 |
| mediumtext | 16,777,215 | 长文章、日志批量记录 |
| longtext | 4,294,967,295 | 小说全文、超长篇内容存储 |
二进制大对象(blob,存非文本数据)
| 类型 | 最大长度(字节数) | 使用场景 |
|---|---|---|
| blob | 65,535 | 小图片(头像)、PDF文档 |
| mediumblob | 16,777,215 | 中等大小文件(如报告附件) |
| longblob | 4,294,967,295 | 超大文件(视频高清图片) |
枚举与集合(限定值范围)
| 类型 | 核心规则 | 限制条件 | 典型场景 |
|---|---|---|---|
| enum(x,y,z,...) | 只能选一个预定义,无匹配值则存空 | 最多65535个候选值 | 性别(男/女)、订单支付(待支付/已支付) |
| set(x,y,z,...) | 可选多个预定义值(逗号分隔) | 最多64个候选值 | 用户标签(运动/美食/科技)、兴趣爱好 |
(3)日期/时间类型:精准记录时间,不同类型适配不同场景(存日期、存时分秒、存完整时间戳)
| 类型 | 字节数 | 格式 | 典型场景 |
|---|---|---|---|
| date | 3 | yyyy-mm-dd | 存生日、订单日期 |
| time | 3 | hh:mm:ss | 存营业时间、会议时间 |
| year | 1 | yyyy | 存年份 |
| datetime | 8 | yyyy-mm-dd hh:mm:ss | 存订单创建时间(需完整时间),时区变化不影响存储值 |
| timestamp | 4 | yyyy-mm-dd hh:mm:ss | 存相对时间戳(自动更新、跨时区适配) |
(4)常用数据类型总结:
| 分类 | 适用场景 | 包含数据类型 | 类型说明 |
|---|---|---|---|
| 二进制数据类型 | 存储非字符/文本数据(如图片等) | blob | 用于存储图像等二进制大对象 |
| 文本数据类型 | 存字母、符号、数字组合的字符数据 | char、varchar、text | char 固定长度;varchar 可变长度;text 存长文本 |
| 日期和时间 | 处理日期、时间相关数据 | time、date、datetime | time 存时间;date 存日期;datetime 存日期 + 时间 |
| 数值型数据 | 仅含数字(正负、浮点等) | int、smallint、float、double | int/smallint 存整数;float/double 存浮点数 |
| 货币数据类型 | 财务数据(需精准小数) | decimal | 定点数,避免浮点精度丢失 |
| bit数据类型 | 表示是/否的布尔逻辑数据 | bit | 存储布尔值(是/否、真/假) |
2.创建表(create)
(1)创建表语句:create table 表名 (表选项)
(2)表定义选项格式:列名1 列类型1 约束 comment 注释名, 列名2 列类型2 约束,...
(3)关键要求:
表名不能用SQL关键字
必须指定每个字段的名称+数据类型
多字段用逗号分隔
注:默认的情况是,表被创建到当前的数据库中。若表已存在、没有当前数据库或者数据库不存在,则会出现错误
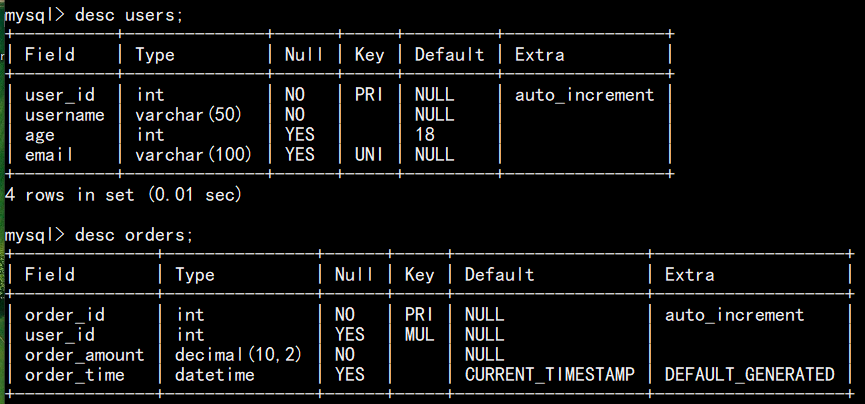
3.查看表(show/describe)
(1)查看表语句:show tables;(查看当前库的表) show tables [from 数据库名];(查看指定库的表)
(2)查看数据表中各列信息语句:describe(desc) 表名 [列名]; 或 show columns from 表名称;
字段意义:
Field :字段名称
type:字段类型
null:是否允许为空
key:索引类型
default:默认值
extra:填充
( 3)查看更全面的表信息语句:show create table 表名\G
4.删除表(drop)
(1)删除表语句:drop table 表名; 或 drop table [if exists] 表名;(避免表不存在时报错,较安全)
注:用户必须拥有执行 drop table 命令的权限,否则数据表不会被删除
5.修改表(alter)
(1)修改表名语句:alter table 表名 rename 新表名; 或 rename table 表名 to 新表名;
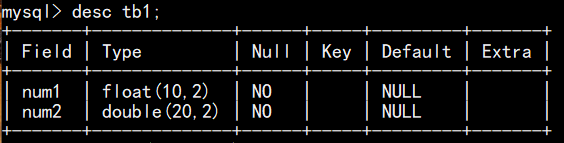
(2)添加新字段(列)语句:alter table 表名 add 新列名 列类型 [after|first] 列名;(after:在指定列之后插入新列,first:在第一列插入新列)
例如:
新增password字段(默认插在最后):

新增birthday字段,插在num1之后:

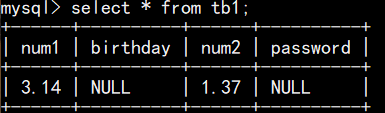
最终结果:
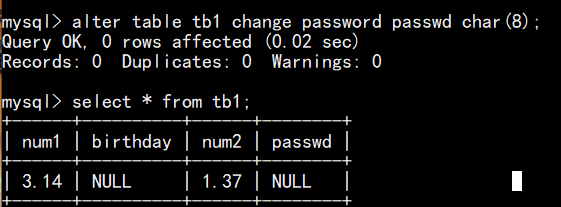
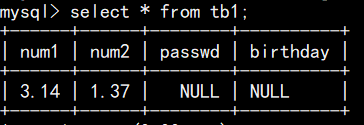
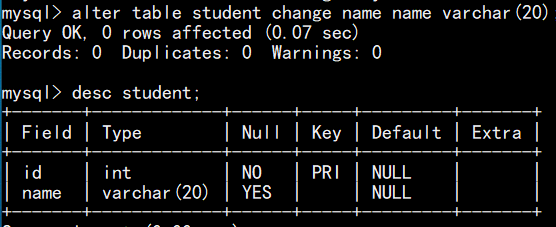
(3)修改列名语句:alter table 表名 change 旧列名 新列名 列数据类型;
如,把password改为passwd,类型不变:
(4)修改列类型语句:alter table 表名 modify 列名 列数据类型;
如,把passwd类型从char改成int
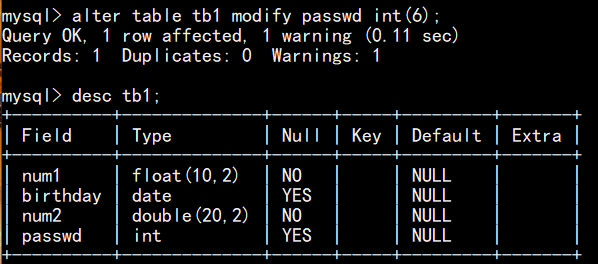
(5)修改列位置语句:alter table 表名 modify 列名 列数据类型 after 某列;
如,将birthday列移到passwd列之后:

(6)删除列语句:alter table 表名 DROP 列名;
三、表的约束
1.约束的核心价值
(1)需要约束的原因:
数据类型的限制太基础(如 INT 只保证是整数,但无法限制“年龄必须 ≥0”);
需从业务逻辑层面保证数据合法(如“身份证号必须唯一”“订单金额不能为负”);
本质是 MySQL 维护数据安全、减少误操作的机制,覆盖数据库层 + 编码层。
(2)约束是什么:约束是在表上强制执行的数据校验规则,本质上是Mysql通过限制用户操作的方式,来达到维护数据本身安全及数据完整性的一套方案
(3)数据的完整性:
| 类型 | 作用 | 示例 |
|---|---|---|
| 实体完整性 | 表中记录不能完全重复(需唯一标识) | 主键(PRIMARY KEY)保证唯一性 |
| 域完整性 | 字段值需符合“业务规则” | 年龄范围 0-120 、性别 男/女 |
| 引用完整性 | 跨表关联时,外键需匹配主表存在的值 | 员工表的“部门 ID”需在部门表中存在 |
| 用户自定义完整性 | 自定义业务规则 | “用户名唯一”“密码不能为空” |
(4)创建约束的时机:
在建表的同时创建
建表后创建(修改表)
(5)定义列级或表级约束的语法:
| 类型 | 定义位置 | 语法特点 | 适用场景 |
|---|---|---|---|
| 列级约束 | 字段定义后 | 直接跟在字段类型后 | 简单约束(非空、默认、列级主键) |
| 表级约束 | 字段列表之后 | 用constraint显示命名约束 | 复杂约束(复合主键、外键、自定义名) |
列级约束语法(非空 默认):
建表:
create table 表名 (列名 数据类型 约束类型);
create table 表名 (列名 数据类型,...,constraint 自定义约束名 约束类型(字段名));
添加/修改约束:
alter table 表名 change 列名 列名 列数据类型 约束类型;
alter table 表名 modify 列名 列数据类型 约束类型;
删除约束:
alter table 表名 modify 列名 列数据类型:
表级约束语法(约束名建议采用 表名_列名_约束类型简介):
建表:
create table 表名 (列名1 数据类型, 列名2 数据类型......, constraint 约束名 约束类型(列名1,列名2));
添加约束:
alter table 表名 add constraint 约束名 约束类型(要约束的列名);
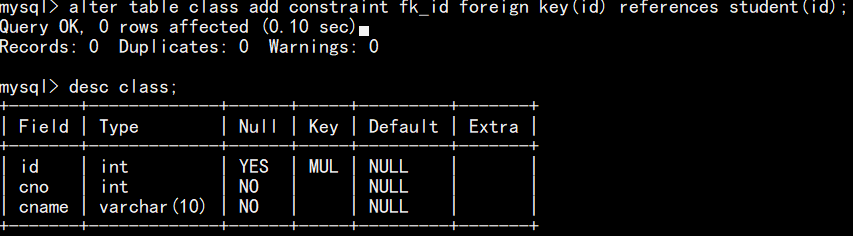
删除约束:
alter table 表名 drop constraint 约束名;

alter table 表名 drop key名;(主键primary key、外建 foreign key)
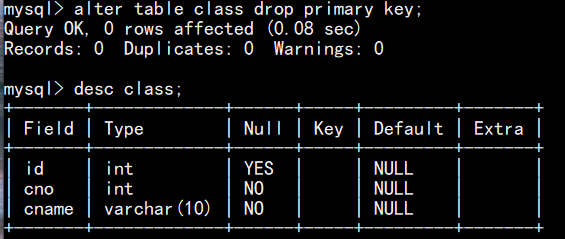
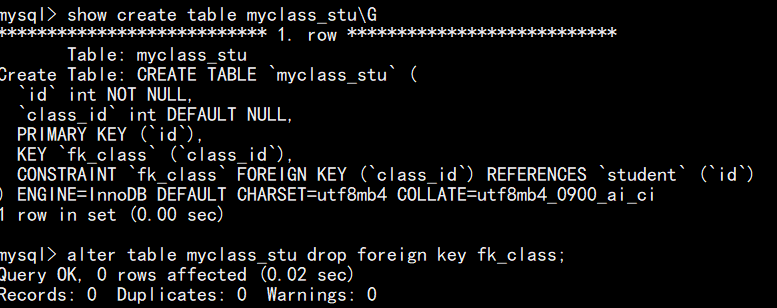
注:如果语句执行成功,但 desc 查看表结构时,还显示 MUL 是因为它存在普通索引(创建外键时,可能自动创建了索引)。外键约束本身已经删除,若想彻底清理,执行删除索引语句(alter table 表名 drop index 约束名)即可
2.非空约束(null /not null)
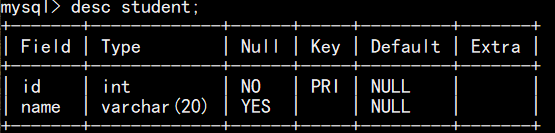
(1)作用与意义:限定字段值不允许为空( NULL ),保证业务关键数据完整性(如班级名、用户名必须填,否则无法识别业务逻辑)。所有数据类型的值都可以是NULL,空字符串不等于NULL,0也不等于NULL。
(2)非空约束的用法:
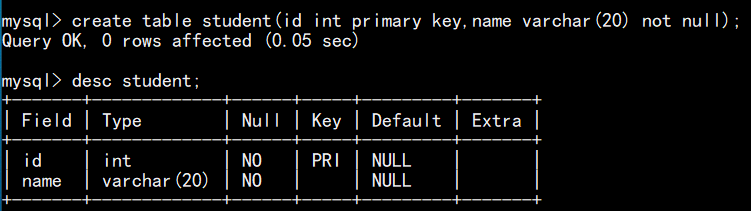
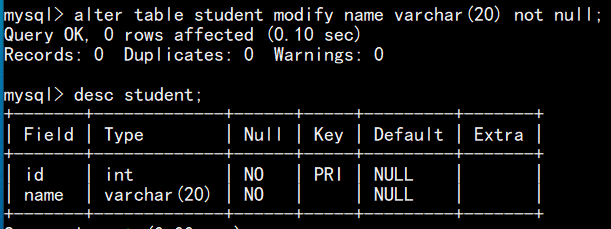
如下图, id 的约束条件为 非空, name 的约束条件为 允许为空
正常向此表插入数据时:

只插入 id 字段数据时:
![]()
只插入 name 字段数据时:(结果显示插入失败,因为这违反了 id 字段的非空约束条件)
![]()
(3)建表后,再修改非空约束的语句:alter table 表名 change column 字段名 字段名 数据类型 not null; 或 alter table 表名 modify 字段名 数据类型 not null; (modify字句中省略not null 相当于设置为可以为空)

(4)删除 not null语句:alter table 表名 modify 字段名 数据类型 null;
3.默认值约束(default)
(1)作用:为字段设置默认值,插入数据时若未显式赋值,字段自动填充为默认值,简化录入逻辑。
(2)默认值约束的用法:
如下图,创建一个 teacher 表,并将 sex 字段设置默认值约束为 女
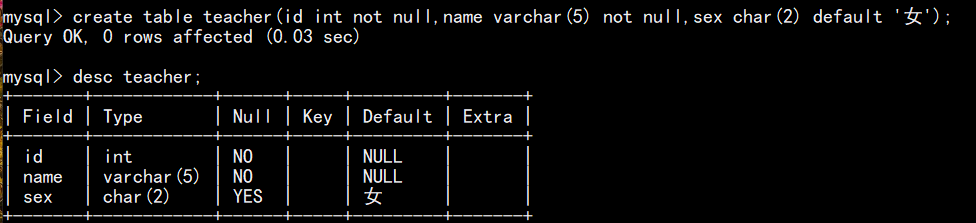
插入数据时,若不给 sex 字段赋值,表会自动填充设置的默认值 女:
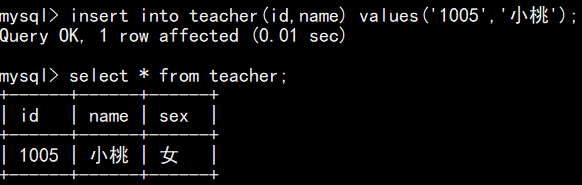
注:若某字段都设置了not null和default约束,则按照不插入时会选择默认值,插入时选择插入值,所以此时not null毫无意义
4.列描述(comment)
(1)作用:为表字段添加说明性文字,仅用于“描述字段含义”(无实际业务逻辑),类似代码注释,方便开发者/运维人员理解表结构。
(2)列描述的用法:
创建表时,在字段定义后加 comment '描述内容' , desc 查看表结构时,不显示列描述
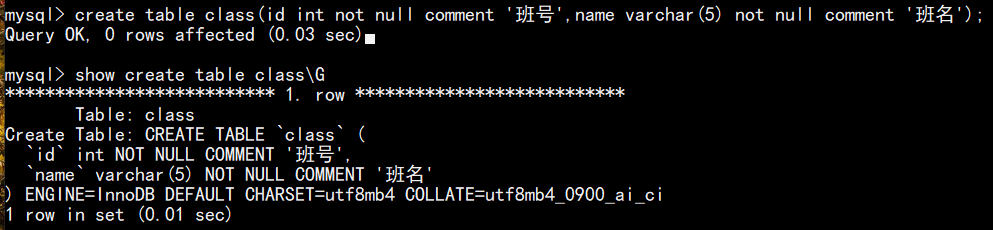
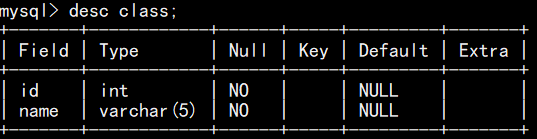
5.主键约束(primary key)
(1)作用:为表记录提供唯一标识(类似学号、身份证号),确保能精准筛选/定位单条数据。
(2)特点:not null + unique(非空且不重复);一张表最多一个主键;字段类型通常为整数(如int,利于快速查询)
注:当创建主键约束时,系统默认会在所在的列或列组合上建立对应的主键索引(就根据主键查询,效率更高)。如果删除主键约束了,主键约束对应的索引就自动删除了,需要注意的一点是,不要修改主键字段的值。因为主键是数据记录的唯一标识,如果修改了主键的值,就有可能会破坏数据的完整性。
(3)主键约束的用法:
如下图,建表时在字段名后设置主键约束:
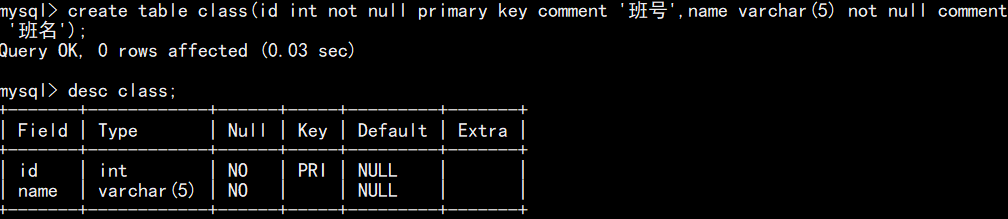
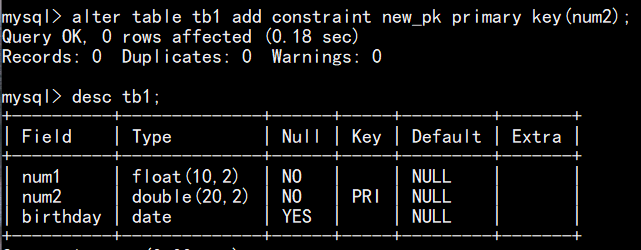
已有表时,追加主键:
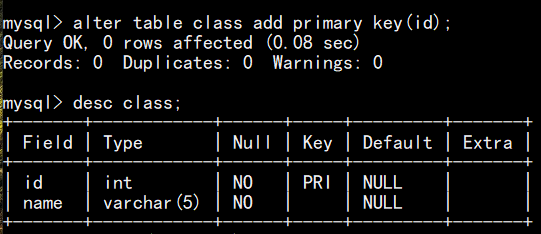
当 id 字段允许为空或有重复值时,追加不了主键:
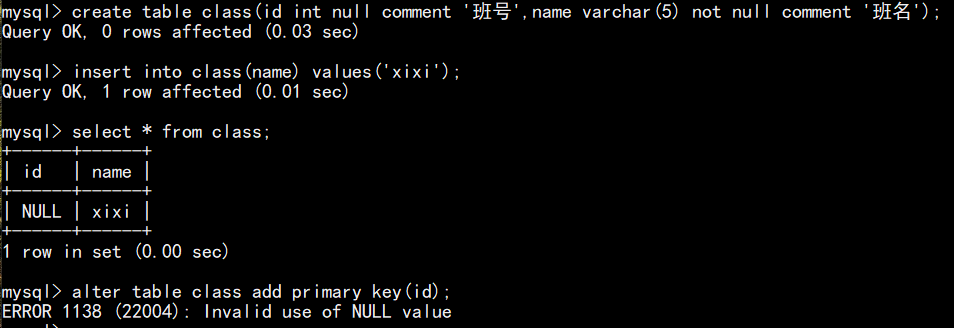
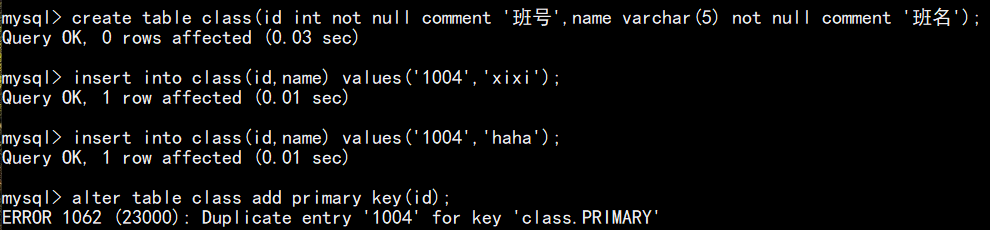
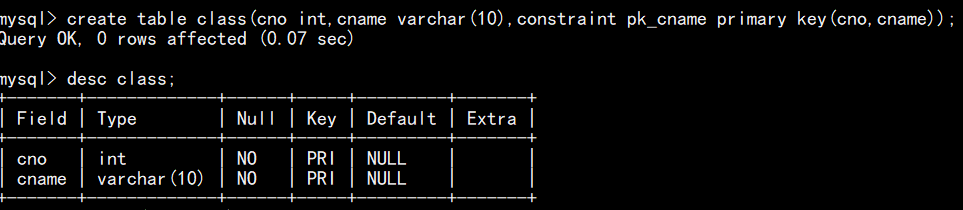
复合主键语句(有多个字段作为主键时可用):
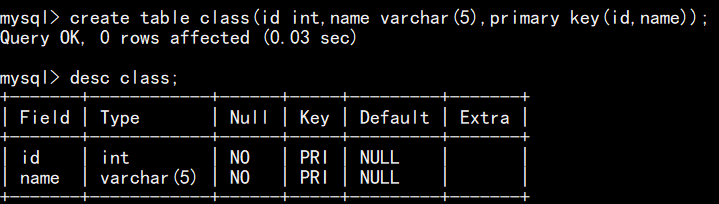
注:即这些字段合在一起是一个主键,也就是让多个字段联合在一起作为唯一标识,单个字段主键重复是没有问题的,只要不是成为复合主键的字段一起冲突就行
6.主键自增长(auto_increment)
(1)作用:让主键字段自动生成唯一值(无需手动赋值),常用于“逻辑主键”(如订单号、用户 ID )。
(2)核心机制:使用 auto_increment 修饰字段,插入数据时若未赋值,系统会从当前字段最大值 +1 生成新值(默认从 1 开始)。
(3)自增长的规则与约束:
字段要求:必须是整数类型;必须是主键/唯一键(保证值唯一);必须具备 not null 属性(自增依赖非空)
表级限制:一张表最多一个自增字段;自增字段是索引( key 栏有值,主键默认是索引)
(4)主键自增长约束的用法:
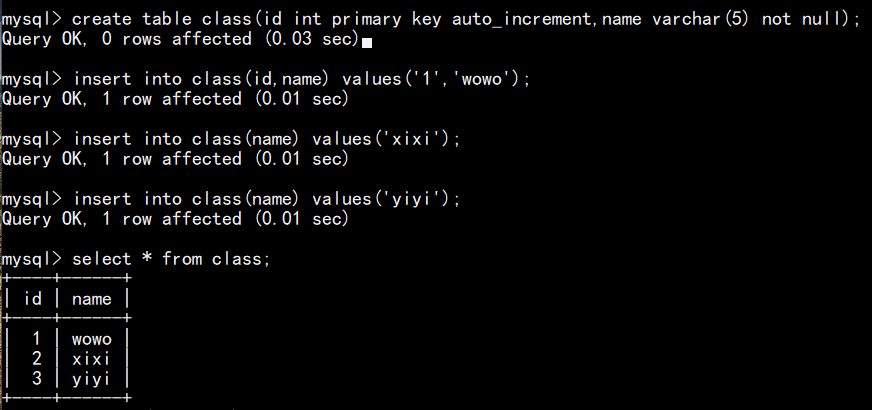
如下图,建表时给 id 字段设置自增长约束,插入数据时即使不给 id 赋值,表会进行自增行为:
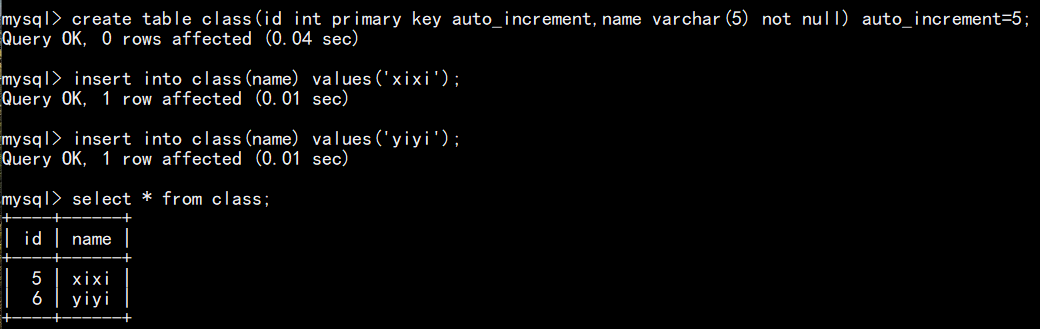
指定自增长的起始值(如果第一条记录设置了该字段的初始值,那么新增加的记录就从这个初始值开始自增 ):
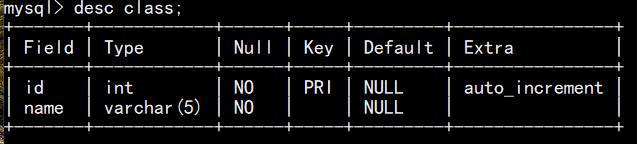
在已有的表上追加自增:

7.唯一性约束(unique)
(1)作用:表中需多个字段“值不重复”,但主键( PRIMARY KEY )只能有 1 个 → 用唯一键( UNIQUE ) 可解决多字段唯一性需求。且也可以限制字段值不重复(可空,但非空值唯一),保障业务数据完整性(如“学号不重复”“手机号不重复” )。
(2)唯一性与主键两种约束区别:
| 对比项 | 主键(primary key) | 唯一键(unique) |
|---|---|---|
| 唯一性保障 | 非空+值唯一 | 可空+值唯一 |
| 数量限制 | 一张表只能有一个 | 一张表可有多个 |
| 业务意义 | 表示记录唯一性(如“身份证号”) | 保障字段业务不重复(如“学号”) |
| 自动索引 | 默认创建主键索引 | 默认创建唯一索引 |
| 空值支持 | 字段必须非空 | 字段可空,空值不冲突 |
(3)唯一性约束的用法:
如下图,建表时给 name 设置唯一性约束条件(可允许为空):
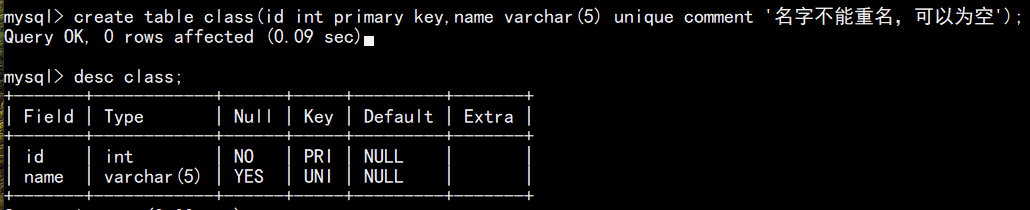
重复插入数据时,会报错,确保数据唯一性:

注:当已有自增长约束条件的字段,再为其加上唯一性约束条件后,遇到唯一键冲突清况,自增长字段值不连续
8.外键约束(foreign key)
(1)作用:保障表间引用完整性(如“学生表的班级 ID 必须存在于班级表” ),避免“脏数据”(无效关联)。
(2)核心概念:
主表(父表):被引用的表(如“班级表” ),需有主键/唯一键。
从表(子表):引用主表的表(如“学生表” ),外键字段关联主表。
外键:从表中关联主表的字段(如学生表 class_id )。
(3)外键的约束规则:
主表要求:主表被引用的字段必须有主键/唯一键(保障引用值唯一)。
从表要求:外键值必须存在于主表主键(或唯一键)中,或为 NULL (允许“未关联”场景,如学生未分配班级 )。
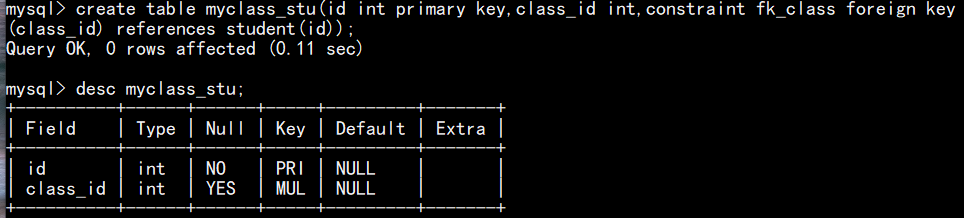
(4)外键约束的用法:
如下图,建表时定义外键(先创建主表 student ,再创建从表 class ):
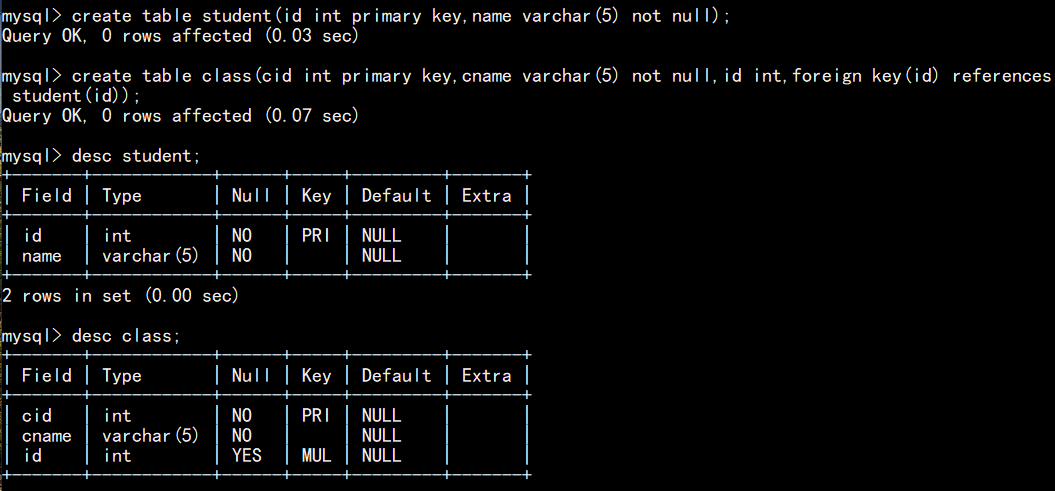
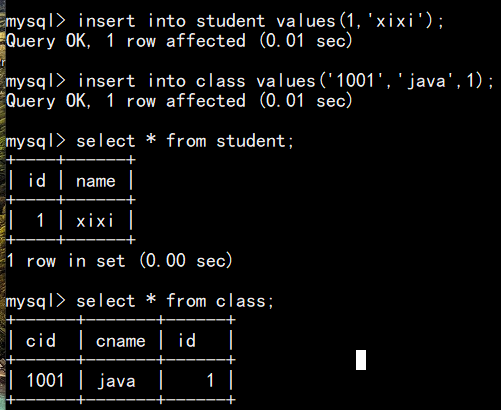
在主表和从表中正常插入数据:
若在从表中插入主表不存在的数据,会报错即外键约束失效:
![]()
外键字段可设为 null ,表示“未关联主表数据”:
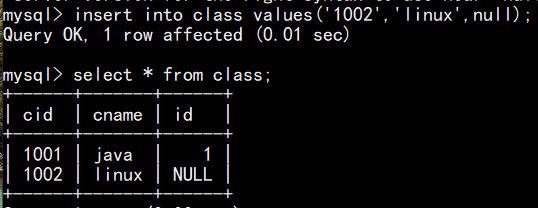
9.检查约束(check)
(1)作用:校验数据表字段值的有效性,限定值的合理范围,减少无效数据录入。
(2)特殊关联:默认值(default),非空(not null)可视为特殊检查约束
注:MySQL 8.0.16 前,CHECK 约束“写而不强制生效”(需触发器辅助);8.0.16 及后,正式支持强制校验。
(3)检查约束的用法:
如下图,建表时设置检查约束条件,为工资的范围在0~10000内:

测试,插入的工资数据不在检查约束限制的范围内时,会报错:
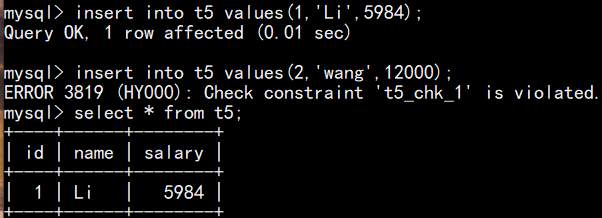

修改表时添加检查约束:
语句:alter table 表名 add constraint 检查约束名 check(检查约束条件)

10.表约束的删除语句
(1)删除非空约束:alter table 表名 modify 列名 数据类型;
(2)删除唯一性约束:alter table 表名 drop index 唯一约束名; 或 alter table 表名 drop constraint 唯一约束名
(3)删除检查约束:alter table 表名 drop constraint 检查约束名
(4)删除主键约束:alter table 表名 drop primary key
(5)删除外键约束:alter table 表名 drop foreign key 外键约束名
四、存储引擎
1.概念
存储引擎是数据库底层软件组织,为 DBMS 提供数据存储、查询、更新、删除的机制,不同引擎在存储方式、索引、锁策略等方面有差异,MySQL 支持多引擎灵活选择。
2.主流引擎及特性
| 引擎名 | 核心特点 | 适用场景 |
|---|---|---|
| MyISAM | 5.5 前默认引擎,插入/查询快;不支持事务、外键;支持全文索引、数据压缩 | 读多写少、对事务要求低的场景(如日志、报表) |
| InnoDB | 事务型首选,支持 ACID、行级锁、外键;MySQL 5.5+ 默认引擎 | 高并发、需事务保障(如订单、金融系统) |
| MEMORY | 数据存内存,读写极快;重启数据丢失,占内存与数据量正相关 | 临时缓存、高频读写小数据(如会话缓存) |
| Archive | 适合存历史记录,插入快、查询弱;数据压缩存储 | 日志归档、冷数据存储 |
| Federated | 联合多 MySQL 服务器,逻辑组成单一数据库 | 分布式应用数据整合 |
| CSV | 数据存 CSV 文件,文本存储;不支持索引 | 数据交换、简单文本存储需求 |
| BlackHole | 写入数据“消失”,用于 binlog 复制中继 | 日志记录、复制场景辅助 |
| ERFORMANCE_SCHEMA | 专用于采集数据库性能参数 | 性能监控、调优 |
3.核心功能对比
| 功能项 | MyISAM | MEMORY | InnoDB |
|---|---|---|---|
| 存储限制 | 256TB | RAM | 64TB |
| 事务支持 | No | No | Yes |
| 全文索引支持 | Yes | No | No |
| B树索引支持 | Yes | Yes | Yes |
| 哈希索引支持 | No | Yes | No |
| 集群索引支持 | No | No | Yes |
| 数据索引支持 | No | Yes | Yes |
| 数据压缩支持 | Yes | No | No |
| 空间使用率 | 低 | N/A | 高 |
| 外键支持 | No | No | Yes |
注:默认情况下, 创建表不指定表的存储引擎, 则会使用配置文件的 my.ini 中 default-storage-engine=InnoDB 指定的 InnoDB
3.查看引擎的语句
查看支持的引擎:show engines \g:
查看当前默认存储引擎:show variables like '%storage_engine%':
建表时,指定表的存储引擎:create table (...) engine=引擎名;
4.完整的建表语句
create table 表名 (列名 列数据类型 [auto_increment] [default 默认值] [列约束], ...... [表约束]) [engine=存储引擎] [default] charset=字符集;
auto_increment: 自动增尙只能是数值类型的列
charset: 设置表的字符篥