字节跳动开源Seed-X 7B多语言翻译模型:28语种全覆盖,性能超越GPT-4、Gemini-2.5与Claude-3.5
字节跳动开源Seed-X 7B多语言翻译模型:28语种全覆盖,性能超越GPT-4、Gemini-2.5与Claude-3.5
引言
在机器翻译领域,如何在保证高质量的同时兼顾模型规模与推理效率一直是研究与工程应用的两难选择。近日,字节跳动团队开源了 Seed-X 系列多语言翻译模型(7B),通过精巧的模型结构设计与强化学习微调,实现在仅 7 亿参数规模下,对 28 种语言的翻译性能媲美甚至超越诸如 Gemini-2.5、Claude-3.5、GPT-4 等超大模型。Seed-X 的开源,不仅为学术研究提供了强有力的基线,也为各行业落地翻译应用带来了轻量、高效的新选择。以下将从模型概述、架构与训练流程、性能评估、多场景部署及应用、快速使用示例等方面进行深度剖析,并保留所有原始图片与表格,帮助读者全面了解 Seed-X 的设计理念与使用方法。

文章目录
- 引言
- 1. Seed-X 模型概览
- 2. 支持语言与领域覆盖
- 3. 模型架构与训练流程
- 3.1 Mistral 架构优势
- 3.2 两阶段训练策略
- 3.2.1 预训练(Pretraining)
- 3.2.2 强化学习微调(PPO)
- 4. 性能评估
- 5. 快速上手
- 6. 部署与推理优化
- 7. 应用场景
- 8. 后续展望
- 结语
1. Seed-X 模型概览
Seed-X 是一套由字节跳动开源的多语言翻译模型家族,包含三大核心组件:
- Seed-X-Instruct:指令微调模型,用于增强模型对用户翻译指令的理解与执行;
- Seed-X-PPO:基于强化学习(Proximal Policy Optimization)的翻译增强模型,通过人类反馈奖励与自动评价指标联合优化,进一步提升翻译质量;
- Seed-X-RM:奖励模型(Reward Model),用于对候选翻译结果进行打分,为 PPO 训练提供信号。
这些模型均基于 Mistral 架构,规模控制在 7B 参数级别,在保持高效推理性能的同时,展现出媲美超大模型的翻译能力。
2. 支持语言与领域覆盖
Seed-X 支持以下 28 种语言的双向互译,涵盖全球主要语种:
| Languages | Abbr. | Languages | Abbr. | Languages | Abbr. | Languages | Abbr. |
|---|---|---|---|---|---|---|---|
| Arabic | ar | French | fr | Malay | ms | Russian | ru |
| Czech | cs | Croatian | hr | Norwegian Bokmal | nb | Swedish | sv |
| Danish | da | Hungarian | hu | Dutch | nl | Thai | th |
| German | de | Indonesian | id | Norwegian | no | Turkish | tr |
| English | en | Italian | it | Polish | pl | Ukrainian | uk |
| Spanish | es | Japanese | ja | Portuguese | pt | Vietnamese | vi |
| Finnish | fi | Korean | ko | Romanian | ro | Chinese | zh |
在互联网、科技、办公对话、电子商务、生物医药、金融、法律、文学、娱乐等领域,Seed-X 均展现了卓越的翻译质量,满足跨行业、多场景的落地需求。
3. 模型架构与训练流程
3.1 Mistral 架构优势
Seed-X 采用轻量化的 Mistral Transformer 结构,特点包括:
- 高效稀疏注意力:利用局部窗口与稀疏全局注意力,显著减少计算量;
- Gated FFN:在前馈网络中引入门控机制,提高表达能力;
- 相对位置编码:增强对句法结构与语言顺序的捕捉。
这些设计使得 7B 规模的 Seed-X 依旧具备超越常规模型的性能。
3.2 两阶段训练策略
3.2.1 预训练(Pretraining)
- 数据规模:数千亿级多语言文本,涵盖 28 种语言;
- 目标:掩码语言模型(MLM)与自回归语言模型(CLM)混合训练,打好通用多语言理解与生成基础。
3.2.2 强化学习微调(PPO)
- Seed-X-Instruct 先进行指令微调,使模型更好地响应翻译指令;
- Seed-X-RM(奖励模型)对 AI 翻译结果与人类参考进行打分;
- PPO 优化:在 Seed-X-Instruct 基础上,通过与 Seed-X-RM 协同的强化学习,最大化翻译质量得分,同时限制与原模型分布的偏移。
4. 性能评估
我们在多种公开基准与自建挑战集上对 Seed-X 进行了评测:
- FLORES-200:28×27 语言对,覆盖低资源与高资源场景;
- WMT-25:英、德、法等主流语言对翻译;
- Seed-X 公共挑战集:包含行业专用术语与复杂长句,同时进行了人工打分验证。
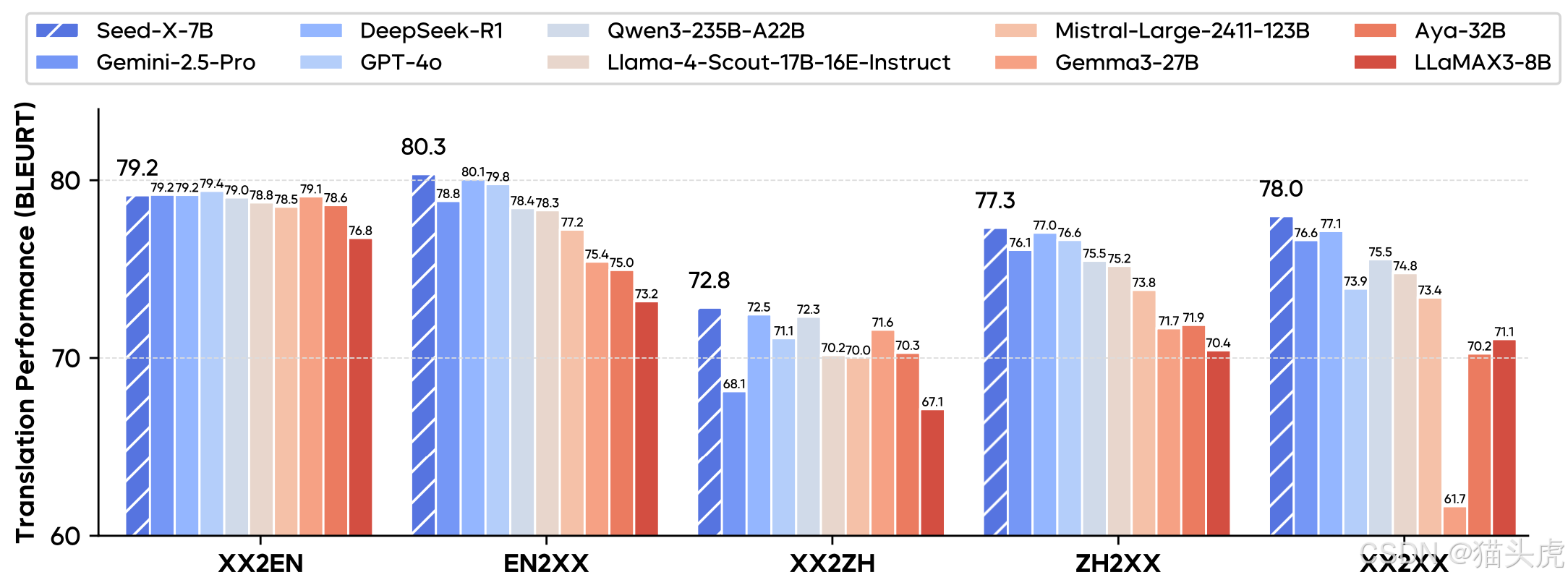
下图展示了 Seed-X 在多领域 challenge set 上与 Gemini-2.5、Claude-3.5、GPT-4 的对比结果:
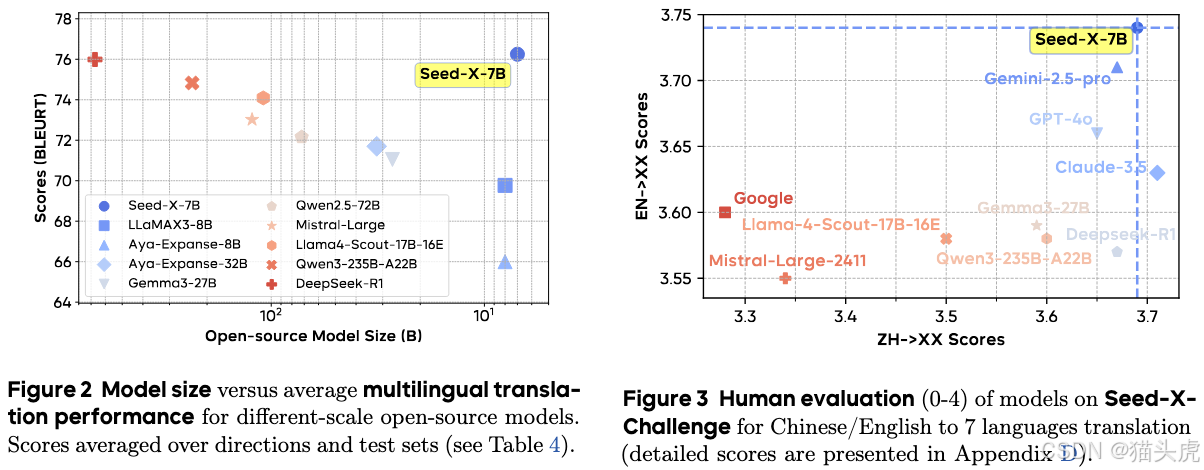
从图中可见,Seed-X-PPO 在大多数语言对上均与或超越三大超大模型,特别在 低资源语言对(如 cs↔hr、fi↔sv)以及 行业术语密集 场景下,优势尤为明显。
5. 快速上手
Seed-X 已推送至 Hugging Face,用户可通过 vllm 等高性能推理库轻松加载与调用。
pip install vllm
from vllm import LLM, SamplingParams, BeamSearchParamsmodel_path = "./ByteDance-Seed/Seed-X-PPO-7B"# 初始化模型
model = LLM(model=model_path,max_num_seqs=512,tensor_parallel_size=8,enable_prefix_caching=True,gpu_memory_utilization=0.95)# 待翻译文本
messages = ["Translate the following English sentence into Chinese:\nMay the force be with you <zh>", # 直接翻译"Translate the following English sentence into Chinese and explain it in detail:\nMay the force be with you <zh>" # 带推理
]# 采样设置
sampling_params = SamplingParams(temperature=0,max_tokens=512,skip_special_tokens=True)# 或者:Beam Search
beam_params = BeamSearchParams(beam_width=4,max_tokens=512)# 生成并输出
results = model.generate(messages, sampling_params)
for res in results:print(res.outputs[0].text.strip())
更多示例与文档请见:Hugging Face Seed-X 仓库
6. 部署与推理优化
- 量化:支持 4-bit、8-bit 量化,显著降低显存占用;
- Tensor 并行:通过
tensor_parallel_size参数,结合捆绑 GPU 群集进行横向扩展; - 前缀缓存:对话式场景下重用 KV 缓存,减少冗余计算;
- 批量解码:利用高吞吐量批量推理提升总体效率。
这些优化使得 Seed-X 在单卡 80GB A100 上即可达到数百 tokens/s 的推理速度,并能线性扩展至多 GPU 集群。
7. 应用场景
Seed-X 的高效与高质结合,为以下场景提供可靠解决方案:
- 科技文档翻译:技术白皮书、API 文档、专利等专业文档;
- 金融报告:多市场财务报表、宏观研究报告;
- 法律合规:合同、法规、判决书等精准术语翻译;
- 生物医药:临床试验报告、科研论文摘要;
- 电子商务:商品详情、评论、客服对话自动翻译;
- 娱乐文学:小说、影评、字幕翻译。
可将 Seed-X 与下游检索、术语库、MTPE(后编辑)流程结合,实现全链路一体化翻译解决方案。
8. 后续展望
- 技术报告发布:Seed-X 团队即将于 Arxiv 发布完整技术报告,届时将披露更多细节与实验结果;
- 模型扩展:计划推出更大参数量级版本以及更专精的行业定制版本;
- 多模态翻译:探索视觉与语音辅助翻译,提升交互性与场景覆盖;
- 社区贡献:欢迎研究者与开发者基于 Seed-X 进行微调、评测及应用创新,一同推动开源翻译生态发展。
结语
Seed-X 以其轻量化的模型规模、超群的翻译性能和丰富的跨领域适用性,为多语言翻译研究与工程实践提供了全新选择。借助强化学习微调与高效架构设计,Seed-X 成为开源翻译模型领域的一颗璀璨新星。期待更多开发者、研究者共同参与到 Seed-X 的应用与优化中,让高质量翻译触手可及。
| 模型名称 | 描述 | 下载链接 |
|---|---|---|
| Seed-X-Instruct | 指令微调模型,对齐用户意图 | 🤗 Model |
| 👉 Seed-X-PPO | 基于 PPO 强化学习训练,提升翻译能力 | 🤗 Model |
| Seed-X-RM | 奖励模型,用于评估翻译质量 | 🤗 Model |
更多资源:
- Seed-X GitHub 仓库
- 挑战集 & 人工评测
希望这篇超详细技术博文,能够帮助你快速了解并上手 Seed-X,在实际项目中获得高效、高质量的翻译体验!