性能监控(一)性能监控核心概念、核心指标
Monitoring监控-基本概念
核心指标
MTTD(Mean Time To Detection)平均故障检测时间
- 平均故障检测时间,表示从故障发生到被检测出来所需的时间
MTTR(Mean Time To Resolve)平均修复时间
- 平均修复时间,表示从故障被检测到最终被修复所花的时间
- 对于一个故障从发生到被修复的完整时间=MTTD+MTTR
四个黄金指标(Four Golden Signals)
- 四个黄金指标是Google提出的监控指标,适用于分布式系统
- 延迟(Latency):服务请求所需时间
- 流量(Traffic):系统处理的请求数量
- 错误(Errors):系统发生的错误请求数量
- 饱和度(Saturation):系统资源的饱和状态,比如CPU占用百分比,磁盘占用百分比。0是最佳状态,如果出现了100%饱和,意味着出现了性能瓶颈
核心网页指标(Core Web Vitals)
-
Core Web Vitals 核心网页指标是一组专注于网页用户体验的性能监控指标
-
Core Web Vitals 关注的关键指标
- LCP(Largest Contentful Paint)最大内容绘制时间
- 衡量网页主内容加载完成的时间
- INP(Interaction to Next Paint)交互到下次绘制时间
- 衡量用户与页面交互后,页面响应并开始视觉更新的时间
- CLS(Cumulative Layout Shift)累积布局偏移
- 衡量页面在加载过程中UI的意外移动程度
- LCP(Largest Contentful Paint)最大内容绘制时间
-
Core Web Vitals重要性
- 用户体验:加载慢、响应迟钝、布局跳动会严重影响用户满意度。
- SEO 排名:Google 将其作为排名因素之一,尤其在移动端。
- 业务转化:更快、更稳定的页面通常带来更高的转化率和留存率。
监控方法
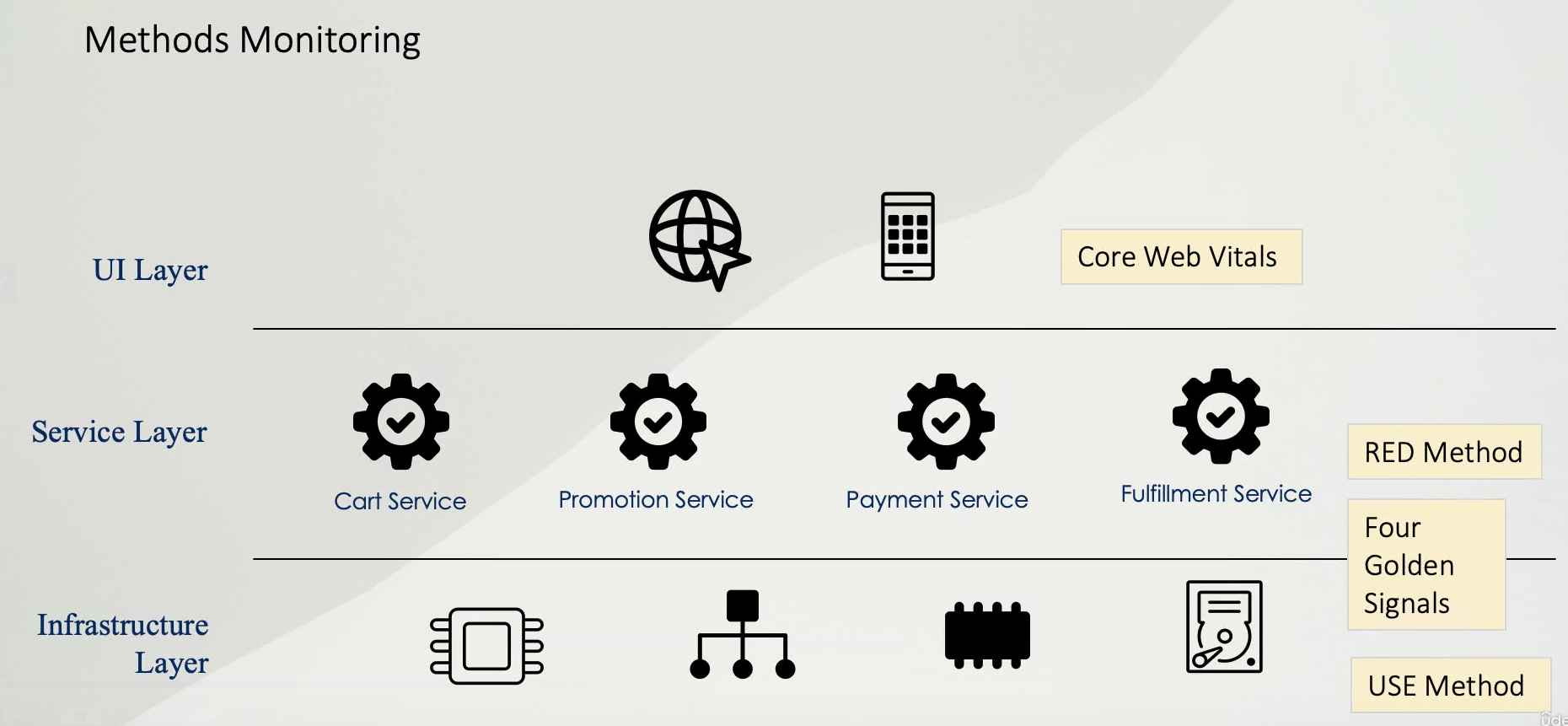
RED方法(Rate、Errors、Duration)
- RED监控方法是专门用于监控云原生应用与微服务架构,专注于服务层
- RED监控方法关注的3个关键指标
- 请求速率-Rate:每秒接收的请求数
- 请求错误-Errors:每秒发生的失败请求数
- 请求耗时-Duration:每个请求的耗时
USE方法(Utilization、Saturation、Errors)
-
USE监控方法是专门监控系统性能问题,专注于基础架构层
-
USE监控方法关注的3个关键指标
- 使用率-Utilization
- 系统资源的使用情况,如CPU、内存、网络的利用率。
- 描述的是“我占了多少”
- 举个例子,一家 8 个座位的理发店。Utilization = 被使用的座位数/总的座位数
- 饱和度-Saturation
- 描述的是“我还有多少”以及“资源是否用光,不得不排队的程度有多高”
- 举个例子,一家 8 个座位的理发店。Saturation = 正在排队的人数 或者 排队长度/等待时间
- 错误-Errors
- 使用率-Utilization
-
使用率和饱和度的关系
- 使用率和饱和度同时结合才能看出当前的体验如何,比如
- 一家 8 个座位的理发店,只有4个顾客,无人排队。 Utilization=50%;Saturation=0
- 一家 8 个座位的理发店,有8个顾客,5人排队。Utilization=100%; Saturation=5
- 一家 8 个座位的理发店,有8个顾客,15人排队。Utilization=100%; Saturation=15
- 以上,在Utilization=100%的情况下,Saturation仍然可以继续提高-排队越来越长,体验越来越差
Observability可观察性-基本概念

- Observability可观察性指的是:系统可以通过外部输出就可以推断出系统内部状态的能力,一句话概括:通过系统暴漏出来的可观测数据,快速定位系统问题并理解问题根源的能力
- Observability可观察性所需要的遥测数据:MELT
MELT
- MELT是四种核心遥测数据类型的缩写,四类数据共同构成了现代系统可观测性的基础
MELT = Metrics(指标) + Events(事件) + Logs(日志) + Traces(追踪)
- 作用:帮助开发运维团队全面了解系统运行状态、快速定位问题并优化性能
Metrics(指标)
-
定义
- 定期采集的数值型数据,反映系统或应用的性能状态
-
特点
- 结构化、易于聚合、可视化
- 存储成本低,查询效率高
- 适合构建仪表盘、趋势分析或者触发报警
-
示例
- CPU使用率
- 内存占用
- 请求速率
Events(事件)
-
定义
- 系统中发生的带有时间戳的离散型事件,表示状态变化或关键操作
-
特点
- 精确记录“发生了什么”以及“何时发生”
- 用于审计、安全监控、用户行为分析
-
示例
- 用户登录
- 服务重启
- 配置变更
- 异常报警
Logs(日志)
-
定义
- 系统在运行过程生成的文本记录,包含详细的上下文信息
-
特点
- 非结构化或半结构化(比如Json)
- 颗粒度细、信息丰富
- 用于开发者调试、错误分析、行为追踪
-
示例
- 错误堆栈
- 请求响应日志
- 系统输出
Traces(追踪)
-
定义
- 记录一个请求在分布式系统中跨服务传播的全过程
-
特点
- 有多个跨度(span)组成,每个跨度表示一次服务调用
- 可视化请求路径,快速定位性能瓶颈或问题环节
- 对分布式微服务架构极为重要
- 通过多个Trace ID串联整个请求链路
-
示例
- 比如一个用户从前端到后端数据库的全链路
收集指标的方法
- 监控系统中,Push(推)和Scrape(拉)是两种常见的指标数据收集方式,主要区别在于由谁来发起数据传输
Push 推
-
定义
- 客户端(被监测者)主动将数据发送给监控系统(如Promethus、Telegraf、Pushgateway、StatsD)
-
特点
- 客户端控制数据发送的时间和频率
- 需要一个中间组件(如 Pushgateway)缓存数据
-
缺点
- 服务端无法控制采集频率
- 数据可能丢失(网络不稳定情况)
- 难以保证数据一致性和完整性
-
适用场景
- 适用于短生命周期或不易被访问的设备(移动设备手机、IOT、边缘设备、防火墙后的设备)
- 客户端可以在事件发生时立刻上报
Scrape 拉
-
定义
- 服务端(监控系统)主动从被监听端拉取数据(比如Prometheus)
-
特点
- 服务端控制采集频率
- 客户端被监控者需要对外暴露一个接口,供服务端抓取数据调用
-
优点
- 易于统一管理
- 更适合服务器、容器、微服务架构
- 数据完整性高(服务端掌控采集)
-
缺点
- 不适用于NAT、移动网络、短生命周期设备
- 被监控者需要保持在线并可以被访问
常见场景
| 场景 | 推荐方式 | 原因 |
|---|---|---|
| 移动 App 崩溃、启动、行为日志 | Push | 手机端主动上报,服务端无法拉取 |
| 后端服务性能指标 | Scrape | 服务端可控,适合定时拉取 |
| IoT 设备、边缘计算节点 | Push | 网络不稳定或无法被访问 |
| 容器化微服务 | Scrape | Prometheus 等工具天然支持拉取 |
总结
| 对比项 | Push | Scrape |
|---|---|---|
| 主动方 | 客户端 | 服务端 |
| 控制权 | 客户端控制频率 | 服务端控制频率 |
| 网络要求 | 客户端可访问服务端 | 服务端可访问客户端 |
| 适用场景 | 移动端、IoT、短生命周期 | 后端服务、容器、微服务 |
| 数据一致性 | 较低(可能丢失) | 较高(统一采集) |