CNN(卷积神经网络)--李宏毅deep-learning(起飞!!)
以影像识别为例子:
当我们要识别猫这个图像(RGB三维图像)的时候,这里的图片由100×100×3的像素构成,我们一般把图像进行拉直成由3个100×100构成的tensor.
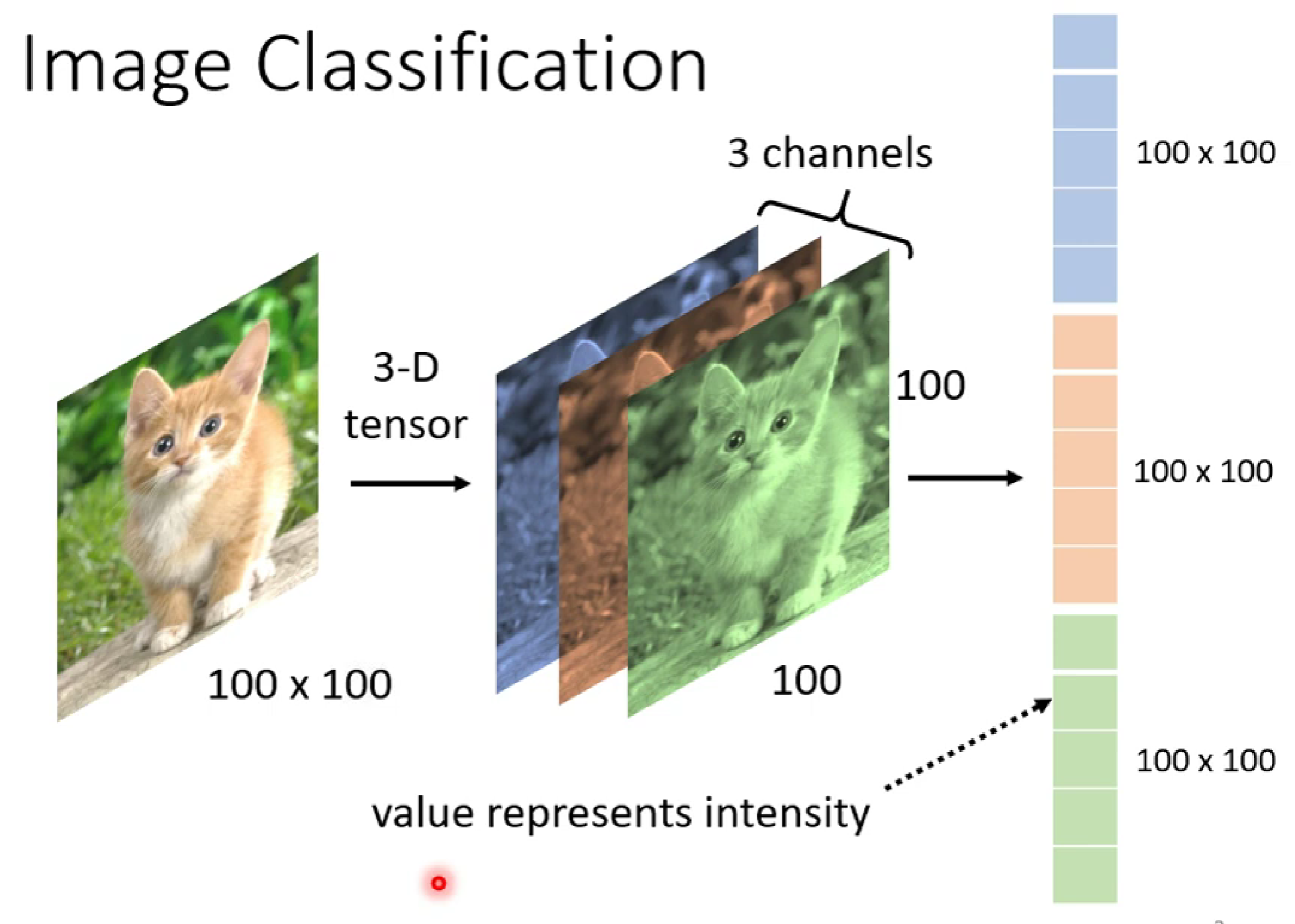
接着,我们把此tensor进行输入:
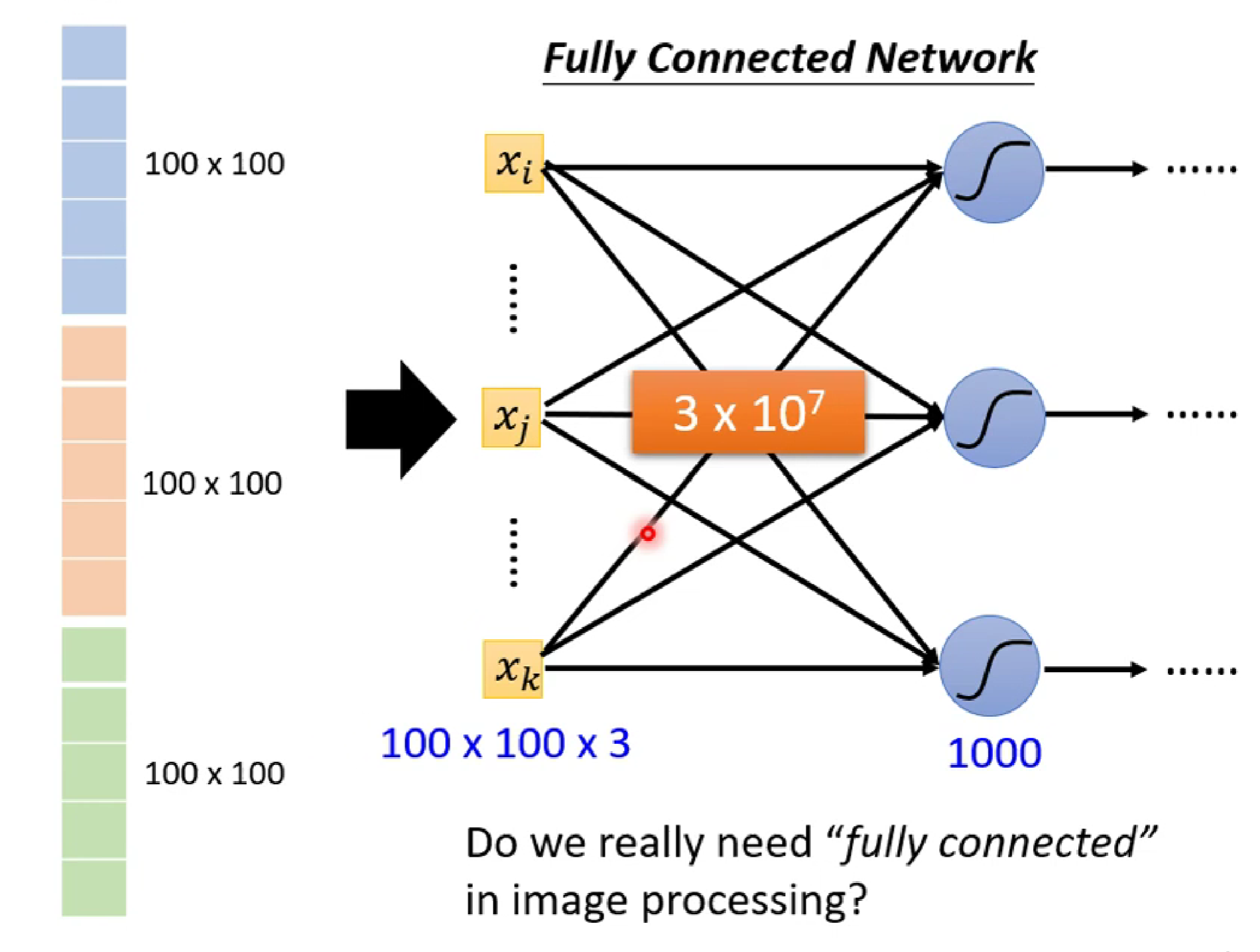
由图像可知,我们输出的x有100*100*3个,假如第一层的neuron有1000个,那么可以知道第一层的全连接输入将达到3*10^7个。这是非常大的,是有必要的吗?
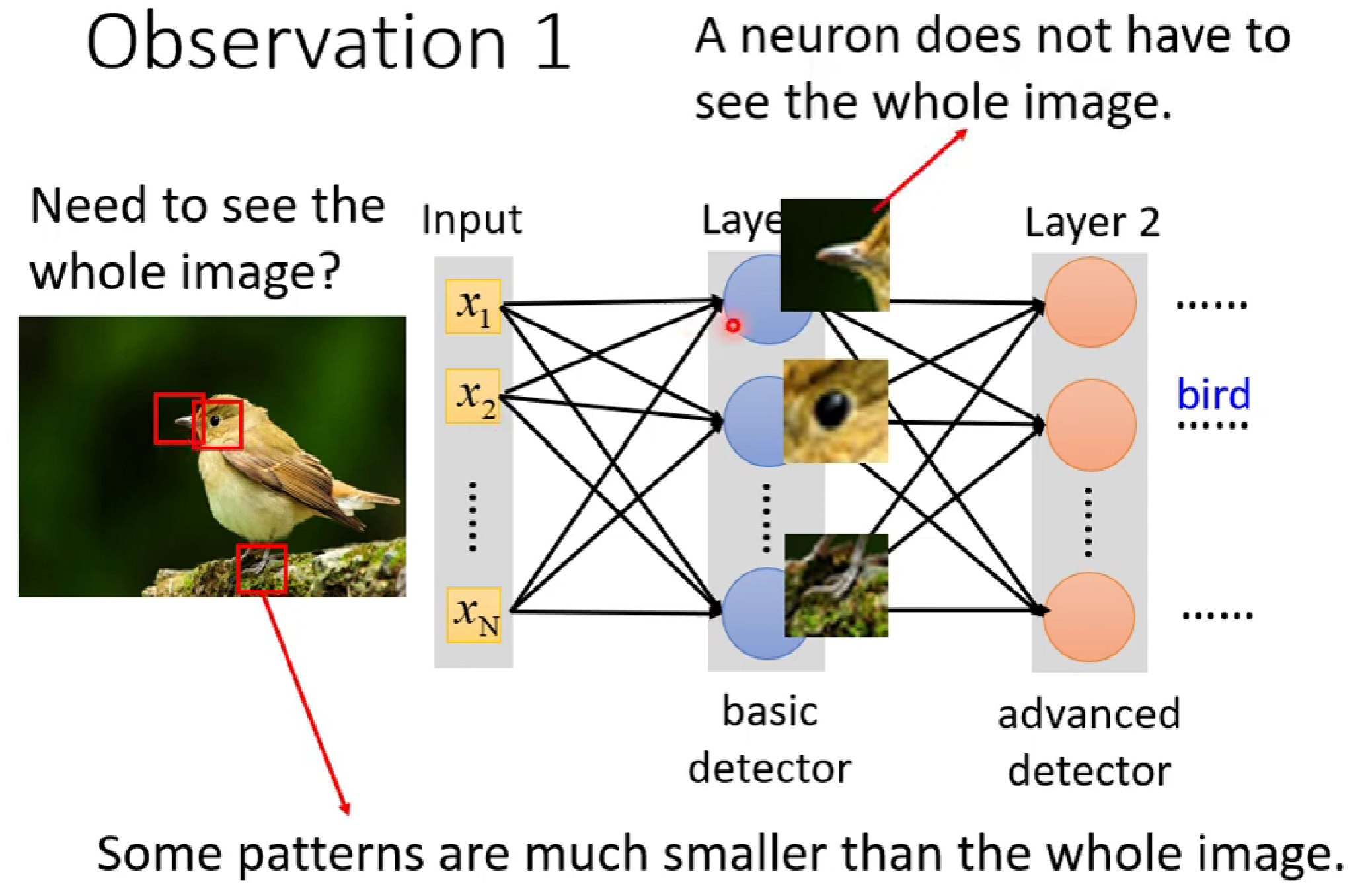
由我们人类自身的观察来看当我们识别某一物体时,我们往往只是观察某些特征点就能够识别出物体是什么。那么我们也可以让神经网络的每一个神经元去识别不同的局部特征,而不用将所有特征(tensor) 进行输入到每一个神经元。通过每一个神经元学习各自的局部特征,最后进行综合,我们应该也能做到对物体的识别(这也是和我们一开始学校deep learning的区别,不是采用数据全连接输入,同时也为引入卷积等知识奠定基础)
为此,如下图,对于上诉三维图像,我们设置一个3*3*3的局部感受野,将3*3*3的数据进行weights和加bias后输入某一neuron.
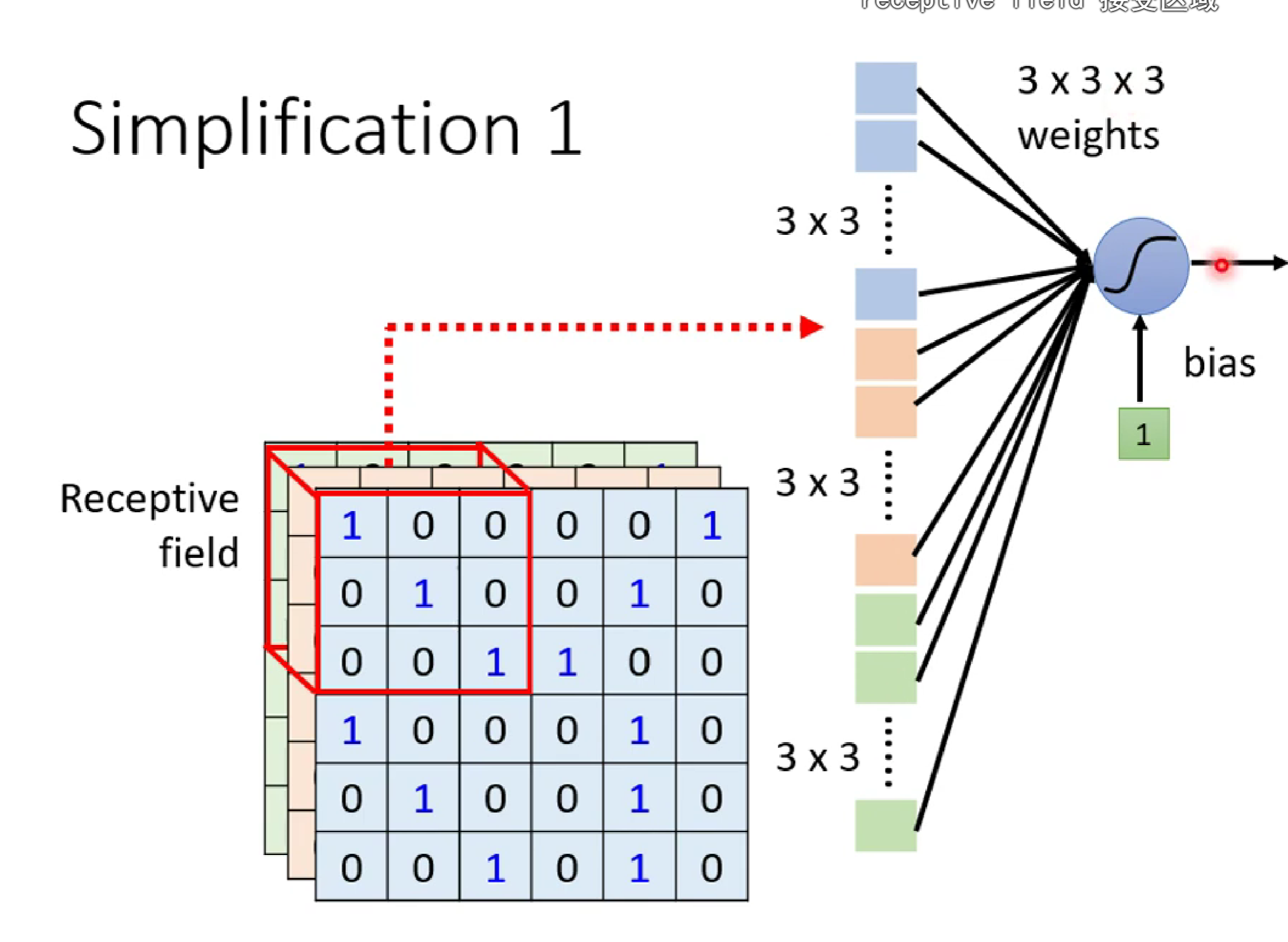
PS:这里注意,对于多个感受野,可以重叠,甚至完全重叠;感受野的大小,形状都可以自由设计。只是,我们一般用n*n的矩形感受野(也就是卷积核)
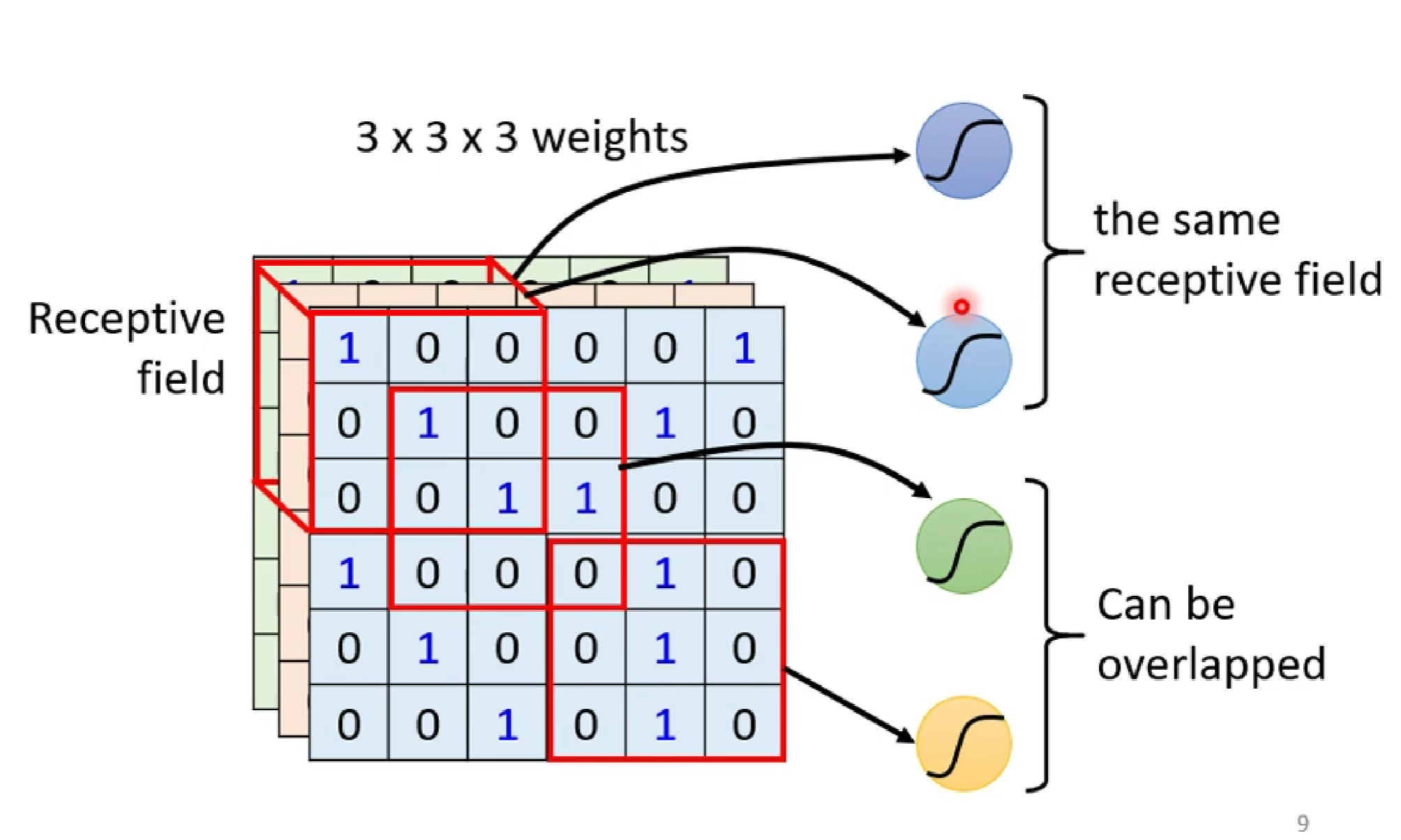
由此,我们就得到了一个经典的东东---卷积核卷积
然而,对于某一局部特征,比如鸟的嘴巴,不同的图片位置不同,所以我们需要对每一个感受野都进行数据输入到专门用来识别的neuron。所以,正是这个原因解释了为什么每个neuron的 conv kernel 需要在图像上进行扫描。
其他点的解释:
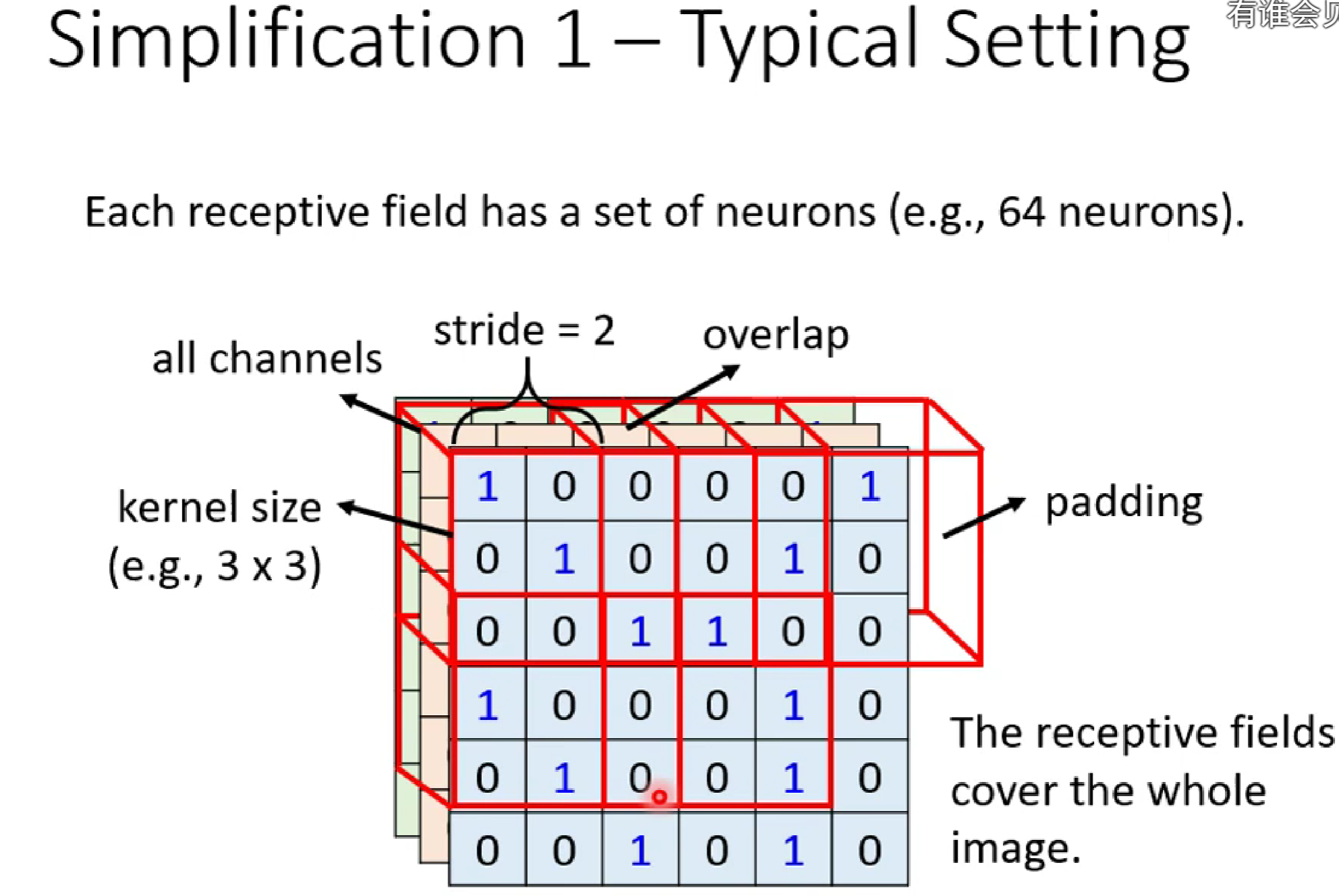
①图像中移动扫描的单位距离我们称为stride(步长)。
②图像中每一个感受野需要重叠的原因是:有利于将边缘特征也进行提取。
③当卷积核移动到超出图像时,我们需要对图像进行padding(填充),而不是丢掉,目的也是提取边缘特征。
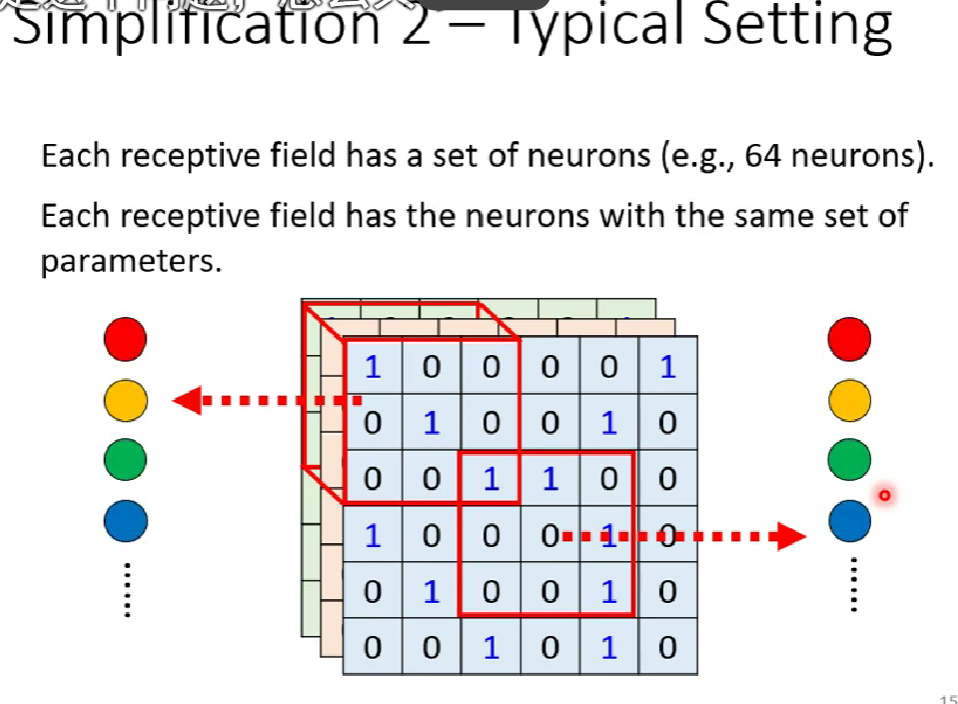
④识别某一特征的neuron,在不同感受野的,weights是一样的,这种我们称为权值共享。(也就是卷积核的值是一样的,neuron的weights)
⑤对于图像特征提取,一般默认对RGB三通道进行,所以我们一般说卷积核只用说n*n,实际上是n*n*x
所以,对于每一个感受野,会有不同的neuron的kernel对其进行卷积(不同的neuron代表发挥不同的检测识别功能,比如有些检测识别嘴,有些识别爪子)
而由多个neuron组成的通过kernel提取特征的神经元层,就叫卷积层
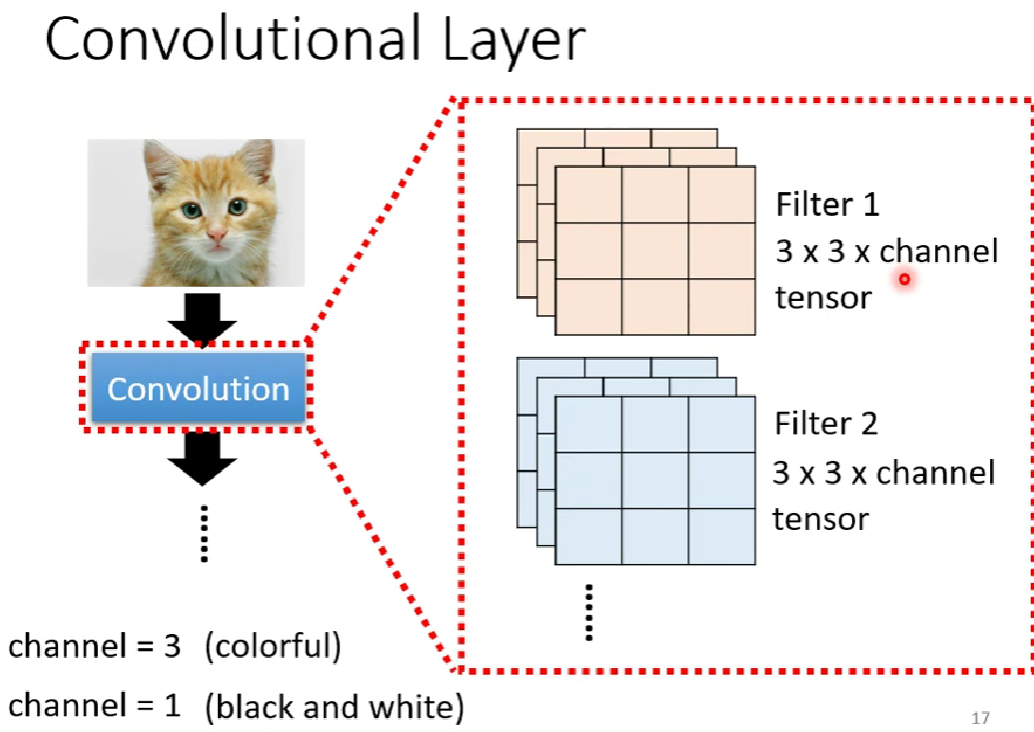
fitter(过滤器)也就是neuron。
而,现在让我们来理解,卷积层是怎么达到提取特征的呢?
这叫要和我们之前深度学习的基础知识联系在一起了,哇塞,太酷了 。
假如有一个neuron的3*3kernel是要来识别某一特征的,该特征在特征矩阵(权值)我们假定为
[1,-1,-1,-1,1,-1,-1,-1,1]
一开始,我们随机对kernel进行赋值,接着我们通过大量数据投喂,利用深度学习的前向传播-->损失值计算-->梯度优化-->反向传播,最终找到满足提取该特征的特征矩阵(也就是我们假定的那个) .
接着,我们便利用该kernei对输入图像进行卷积扫描。(ps:这里我们只考虑一维黑白图像)
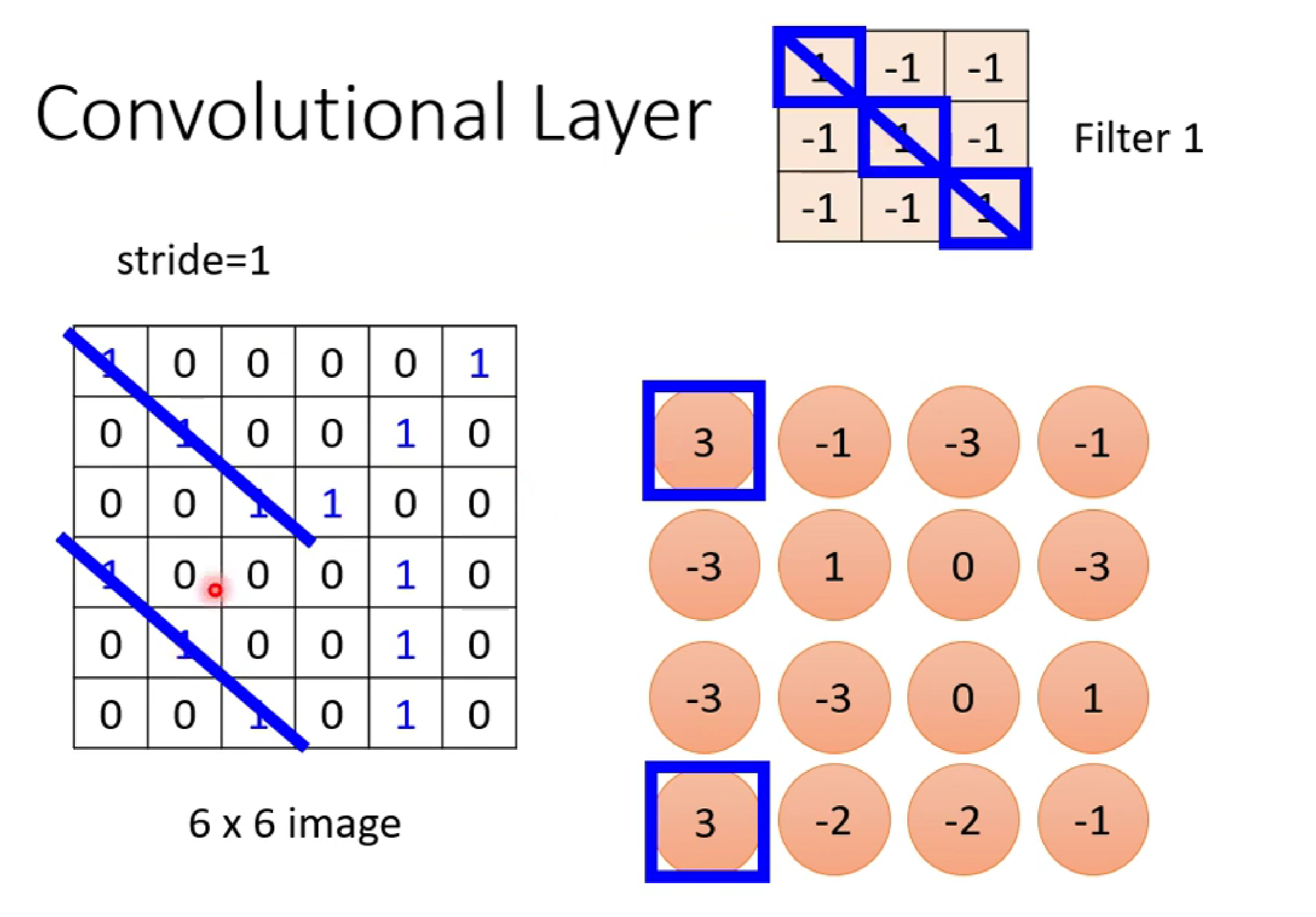
卷积出来的值是红色部分,从这里,我们看出,当卷积的值为3时,说明该处是符合我们想要识别特征的最大概率处(都有1,1,1对角),从而达到特征提取的目的。
这一步,真的醍醐灌顶啊啊啊啊
而我们知道,每一层conv layer有很多个neuron(提取不同特征),也就是很多个kernel(假如有n个),所以对于每一个感受野, 将有n个卷积特征矩阵。也就是每一个感受野都会形成n层channles.
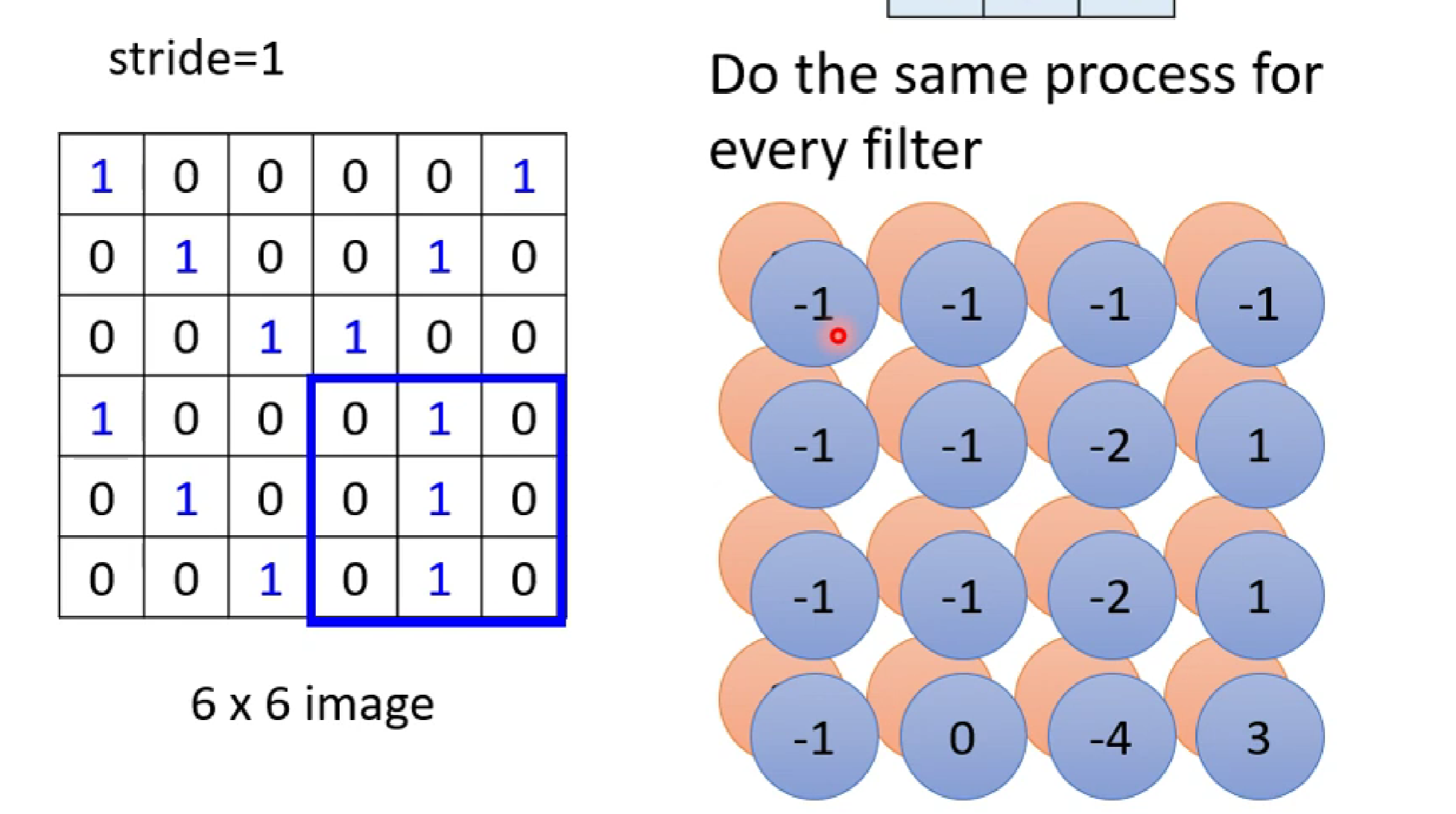
注意: 我们这里讲的是一张黑白图片(一通道),假如是RGB(三通道)图片,经过卷积后,输出的channel数量还是n层。这是因为一个kernel卷积一般是对三通道进行卷积,卷积之后会把三通道的卷积值进行相加,输出给一个输出通道(neuron)。所以n个kernel卷积后,图片输出的通道数为n。而这个多维的图片我们称之为Feature Map。
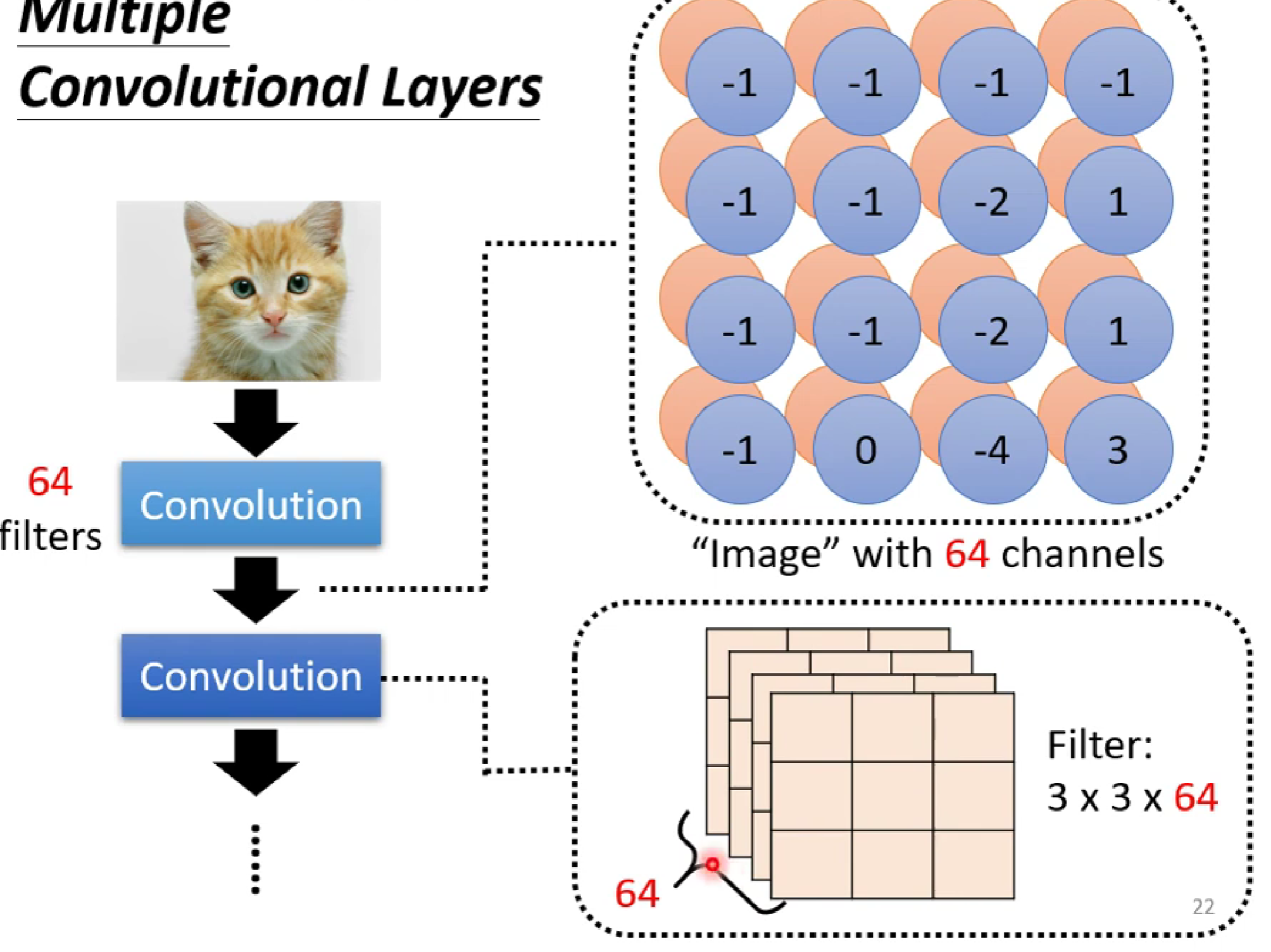
这里还要注意,卷积操作的核心是逐通道的加权求和,当多次卷积,新卷积层的输入通道数(in_channels)必须与输入特征图的通道数匹配。
也就是 Conv2d(64, 128, kernel_size=3, padding=1)当输入的图片是64通道时,Conv2d函数的第一个参数要写64.
此外,随着卷积深度的增加,特征提取的感受野是不断增大的。
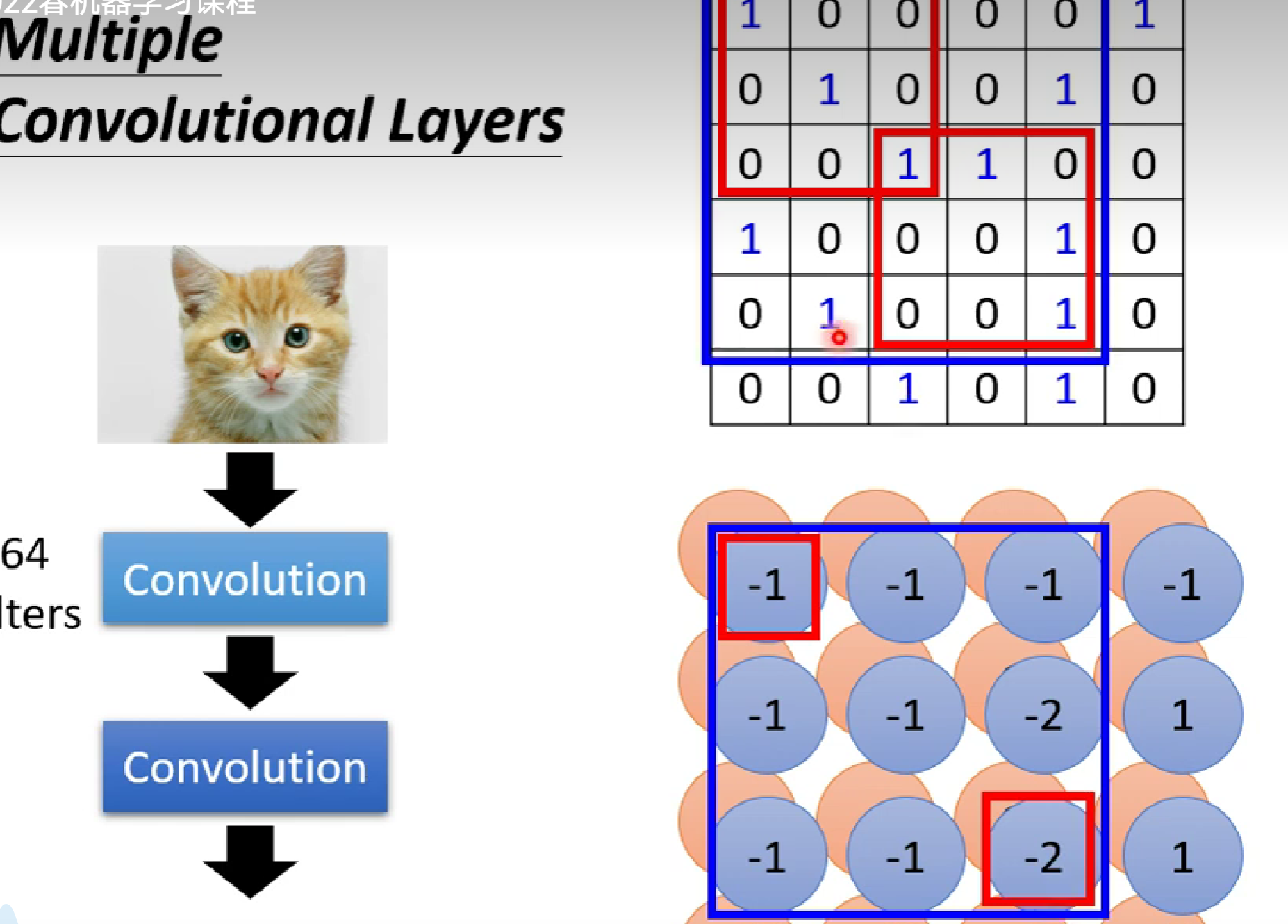
如图,虽然我们第一个卷积时的感受野是3*3,第二次卷积的感受野也是3*3,但是第二层卷积的感受野相对于第一层就是5*5.
在CNN里面,我们还用到了最大池化(Max pooling)
池化是卷积神经网络(CNN)中一个非常重要的操作,通常放在卷积层之后。它的主要目的不是为了学习特征,而是为了对卷积层输出的特征图(Feature Map)进行下采样(Downsampling)
分为最大池化,平均池化等。
池化前:
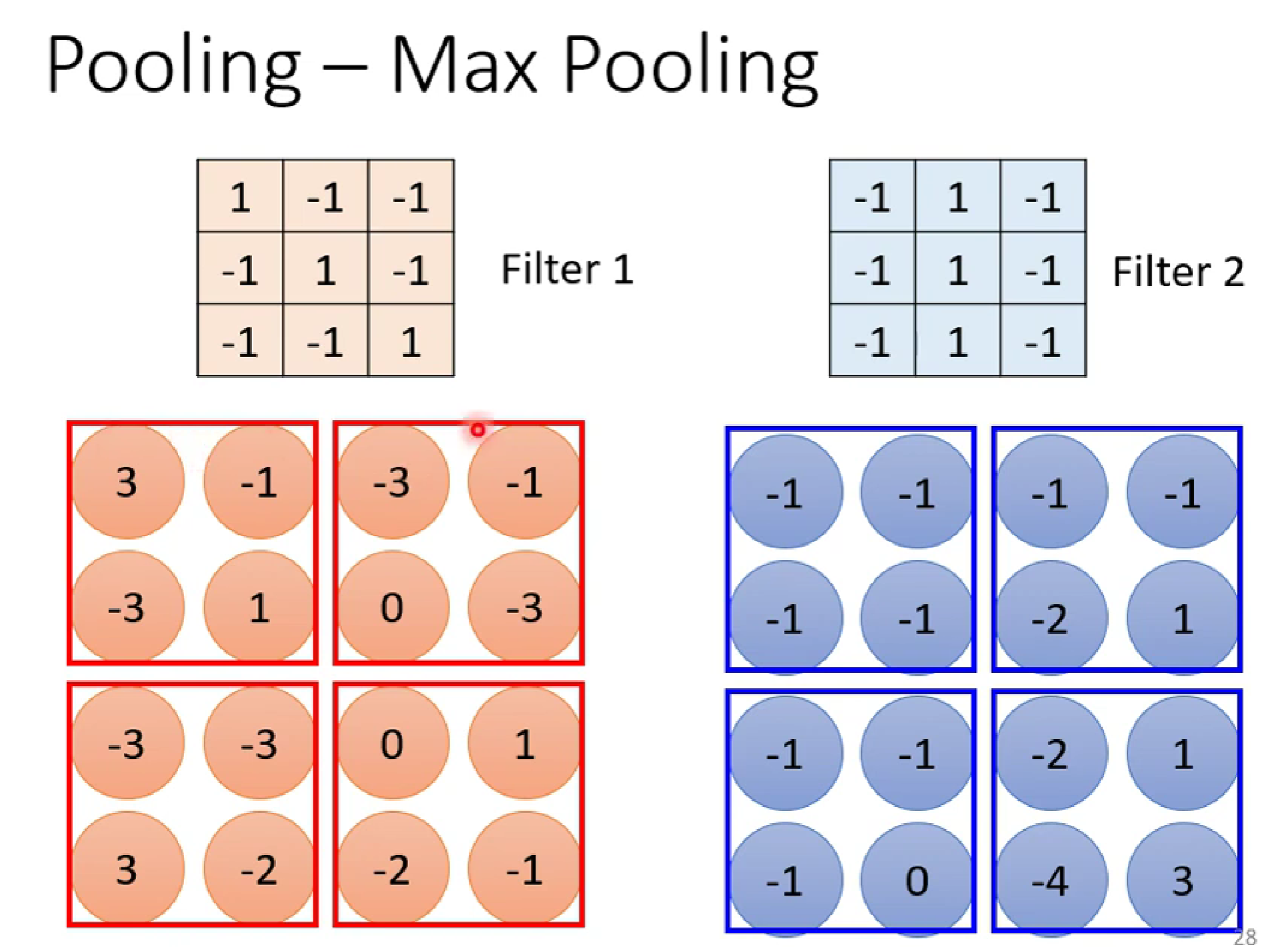
池化后:(这里用最大池化)
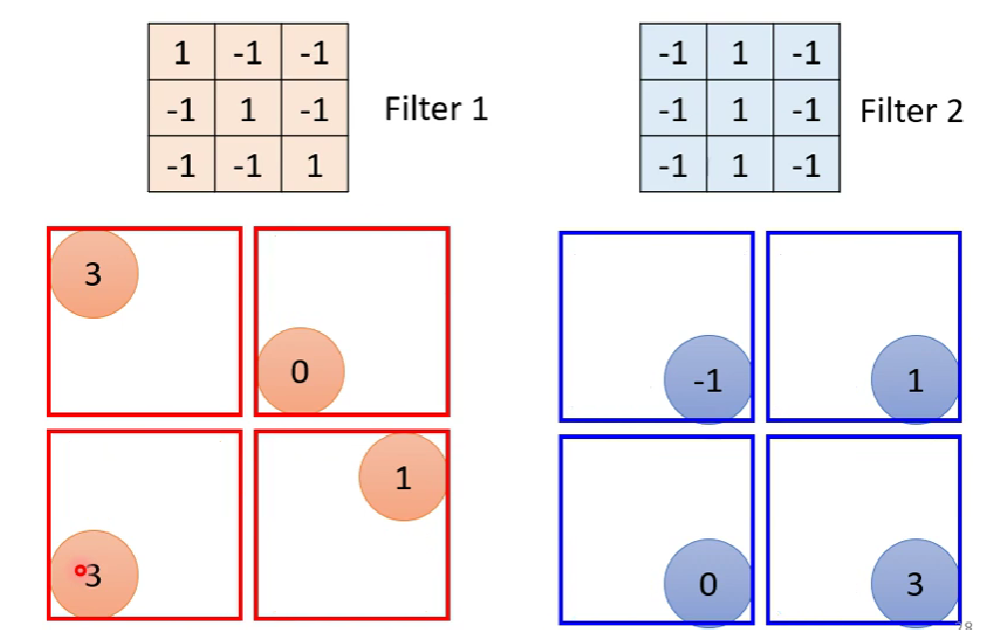
所以在CNN中,一般卷积+池化。
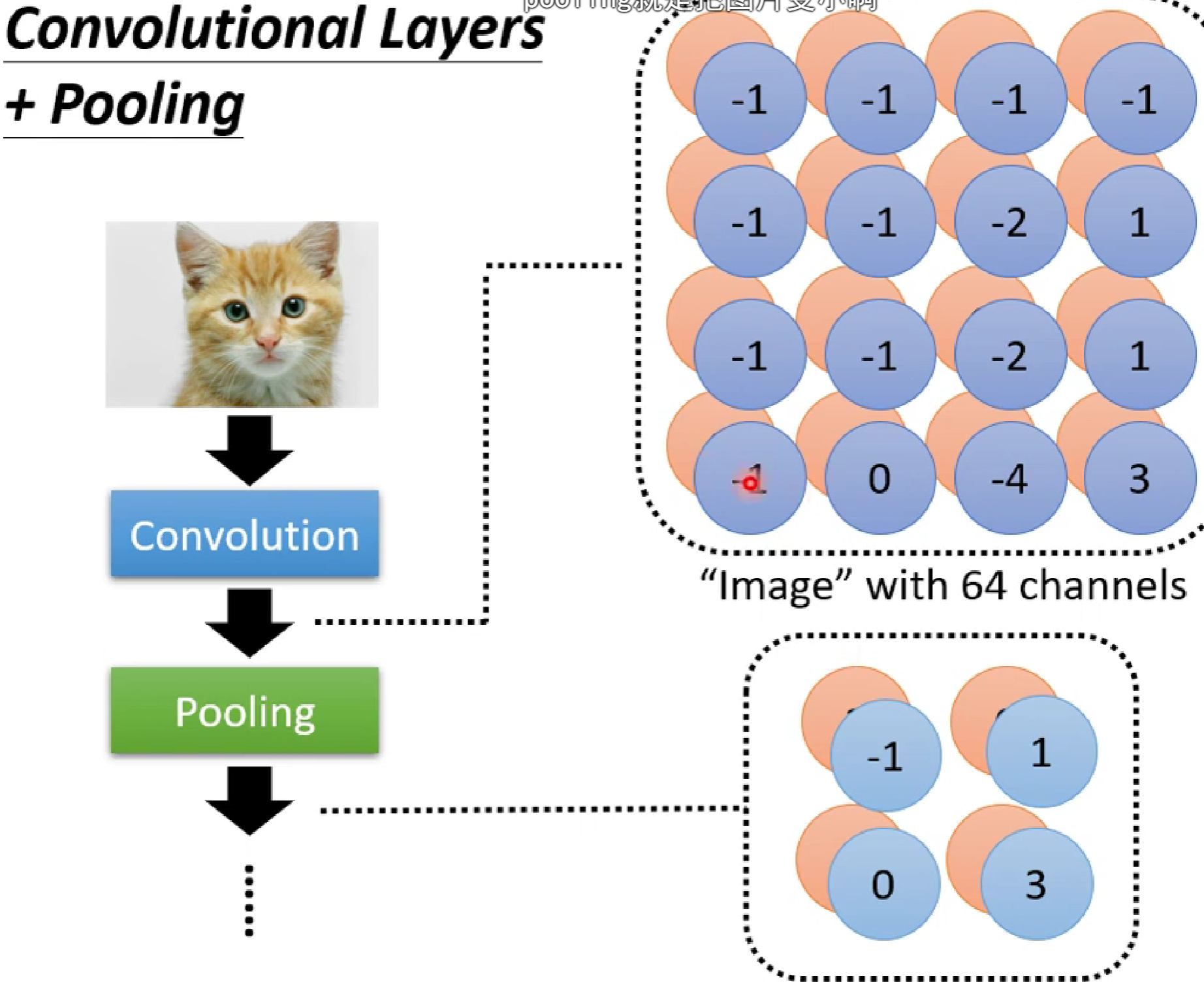
所以,一个完整的CNN如图:
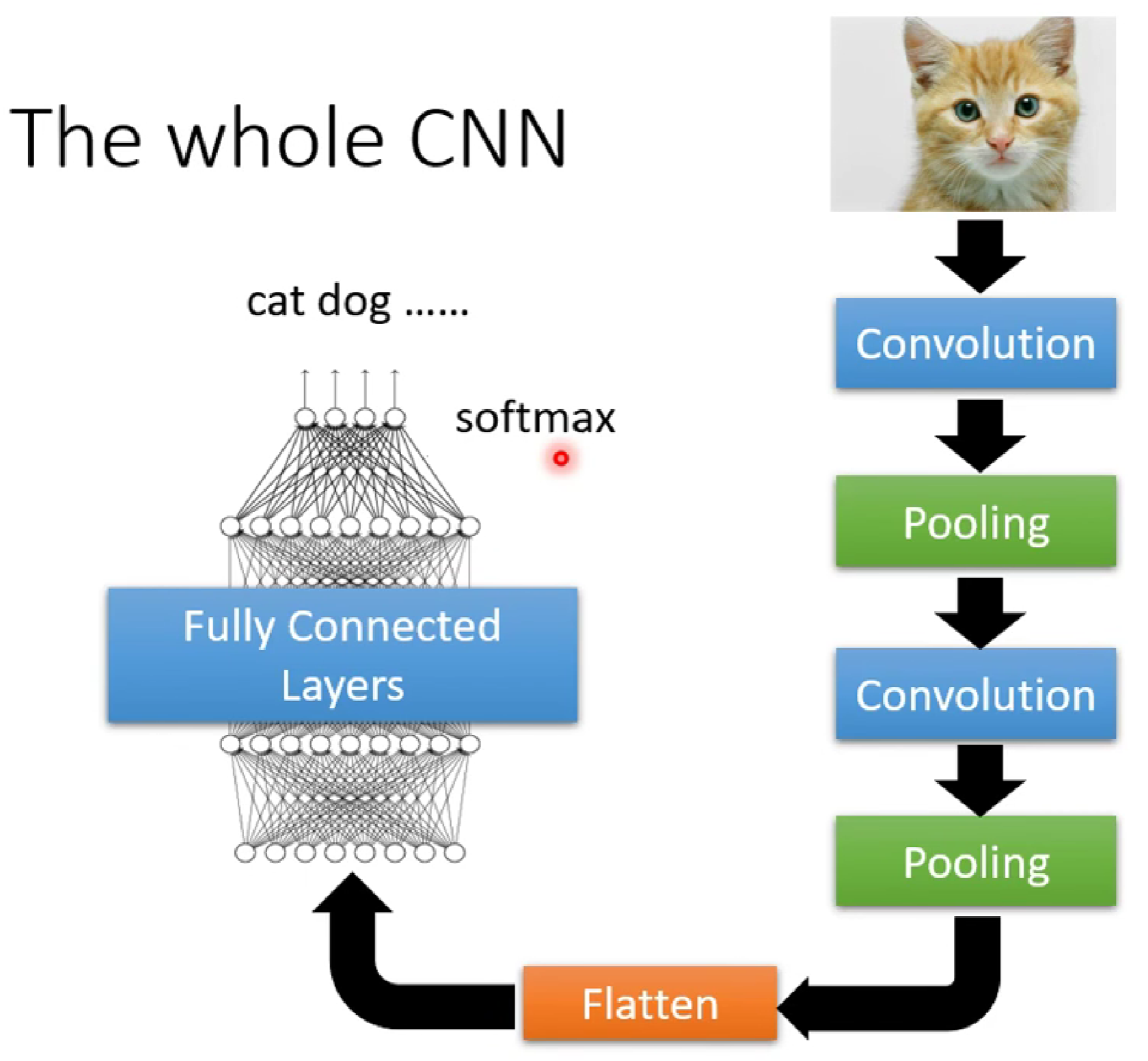
- Flatten 层:当特征图的空间尺寸(高度和宽度)减小到一定程度(例如1x1,或者仍然较大但准备输入全连接层时),需要将这个三维的特征图转换成一维的向量。这就是Flatten层的作用。它将所有通道的所有像素值按一定顺序(通常是行优先)展平成一个长向量。
- 例如,一个尺寸为 7x7x512 的特征图,经过Flatten后会变成一个长度为 7 * 7 * 512 = 25088 的向量。
- 全连接层 (Fully Connected Layers):将Flatten后的向量输入到一系列全连接层中。这些层通常用于将前面层提取到的特征进行组合和分类。最后一层全连接层通常输出分类任务的类别概率(使用Softmax激活函数)或回归任务的值。
So,这就是CNN,哇塞,神经舒畅,太爽了。
That's all.
喜欢主包的话,请追番,投币 and 点赞,谢谢~~