【工具教程】PDF指定区域OCR识别重命名工具使用教程和注意事项

一、PDF 区域识别改名批量重命名或导出表格详细使用步骤
(一)选择 PDF 识别改名模式
根据待处理文件类型选择 “PDF 识别模式”。若处理的是图片型 PDF 文件,务必选择该模式,以确保软件能正确识别文件内容。

(二)设置识别区域

选择样本文件:从需要处理的 PDF 文件中挑选一份具有代表性的文件作为样本。该样本文件应能涵盖其他文件中需要识别区域的各种特征,如文字字体、字号、位置等。
框选识别区域:将样本 PDF 文件拖入软件界面,使用软件提供的区域选择工具,在 PDF 页面上框选出需要识别文字的区域。框选时,需确保框选的区域精准覆盖需要识别的文字内容,避免框选过多无关区域,以免影响识别效率和准确性。如果需要识别多个区域,可多次进行框选操作。
保存区域坐标及命名:完成每个区域的框选后,点击 “保存区域” 按钮,软件会自动记录该区域的坐标。同时,为每个框选的区域起一个有意义的名字,如 “合同编号”“患者姓名”“文件日期” 等。这些名字将作为后续导出表格的列名,方便对识别结果进行整理和分析。
(三)导入 PDF 文件
点击软件界面中的 “导入 PDF” 按钮,在弹出的文件浏览器窗口中,选择存放待处理 PDF 文件的文件夹。软件会自动加载该文件夹中的所有 PDF 文件,并显示在软件界面的文件列表中。

(四)执行识别与重命名操作
选择功能:根据需求选择 “区域识别重命名” 功能。若还需要将识别结果导出为表格进行进一步分析,也可同时选择 “区域识别导表格” 功能。
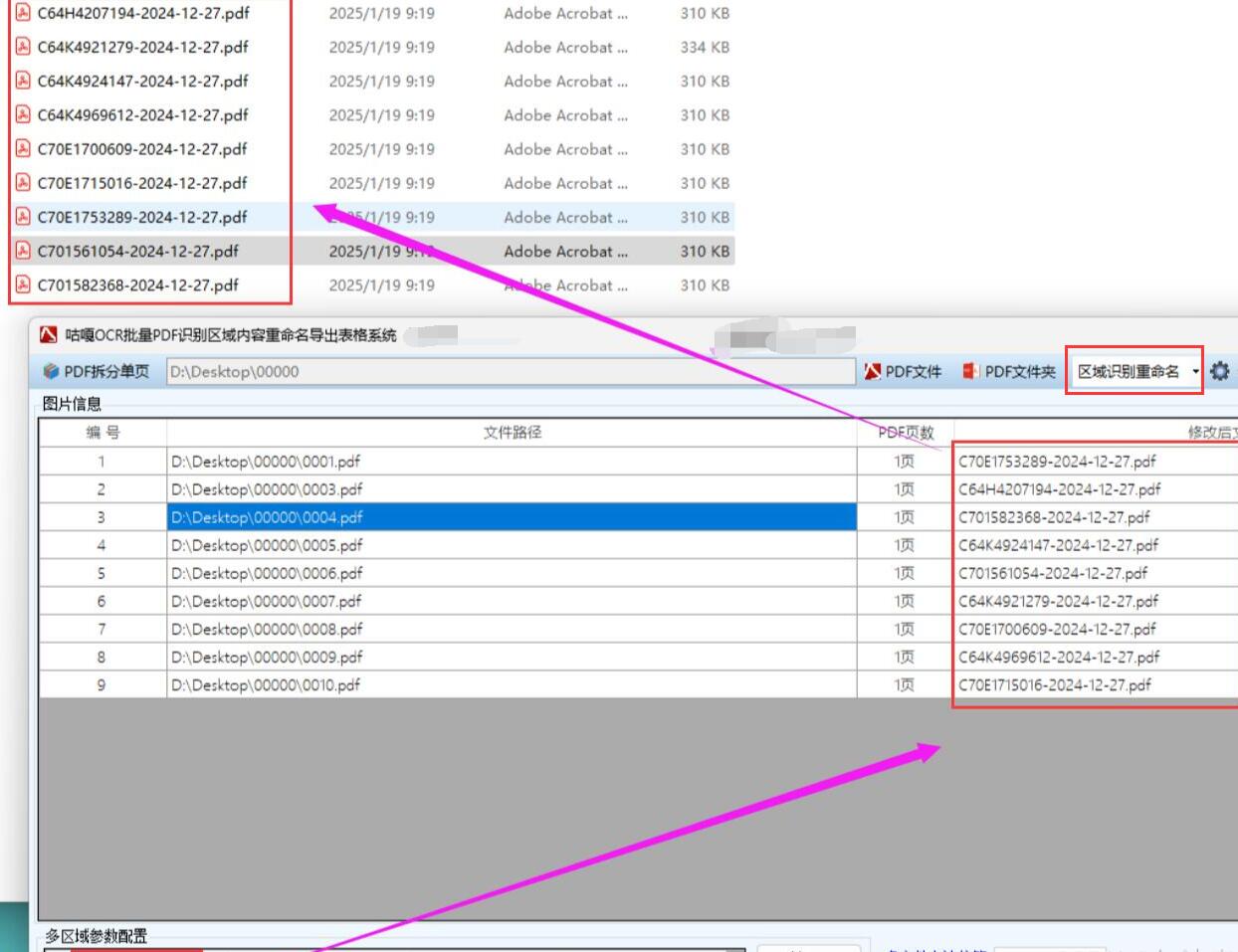
开始处理:点击 “开始处理” 按钮,软件将按照之前设置的识别区域,对所有导入的 PDF 文件进行文字识别。识别过程中,软件界面会显示识别进度条,方便用户了解识别工作的进展情况。
二、使用注意事项
(一)文件格式与质量
格式兼容性:确保导入的文件为 PDF 格式,且软件支持的 PDF 版本。不同软件对 PDF 版本的支持可能有所差异,在使用前最好查看软件的说明文档,确认其支持的 PDF 版本范围。如果遇到软件无法识别的 PDF 文件,可能是由于文件版本过低或过高导致的。此时,可以尝试使用其他 PDF 编辑工具将文件转换为软件支持的版本后再进行处理。
文件完整性:在进行识别操作前,要确保 PDF 文件的完整性。文件在传输或存储过程中可能会出现损坏的情况,损坏的文件可能导致识别失败或识别结果不准确。可以通过查看文件的属性信息,如文件大小、创建时间等,来初步判断文件是否完整。如果对文件的完整性存在疑虑,也可以使用一些文件校验工具,如计算文件的哈希值,与原始文件的哈希值进行比对,以确认文件是否完整。
文字清晰度:对于扫描生成的 PDF 文件,如果文字模糊、存在阴影或分辨率不足,会严重影响 OCR 识别的精度。在进行识别之前,建议对文件进行预处理,以提高文字的清晰度。可以使用一些专业的图像处理软件,如 Adobe Acrobat、Photoshop 等,对 PDF 文件进行优化。例如,通过调整图像的对比度、亮度、分辨率等参数,去除图像中的噪声和阴影,使文字更加清晰易读。同时,也可以对文件进行倾斜矫正,确保文字处于水平或垂直状态,提高识别准确率。
(二)识别区域设置
精准框选:在设定识别区域时,要尽可能精准地框选需要识别的文字区域。区域过大可能会包含无关信息,影响识别结果的准确性;区域过小则可能导致部分文字未被识别。在框选时,可以放大 PDF 页面,仔细调整区域的边界,确保框选的区域准确无误。对于多页 PDF 文件,若每页需要识别的区域位置和内容相同,可在设置好第一页的识别区域后,使用软件提供的 “应用到所有页面” 功能,确保每页的识别区域一致。这样可以避免重复设置识别区域,提高工作效率。
避免重叠与间隙:当需要设置多个识别区域时,要注意避免区域之间有过多的重叠或间隙。重叠区域可能会导致文字重复识别,增加处理时间,且可能产生错误的识别结果;间隙过大则可能遗漏部分需要识别的文字。在设置多个识别区域时,可以先大致规划好各个区域的位置和范围,然后逐步调整,确保区域之间既没有过多的重叠,也没有明显的间隙。同时,要注意识别区域的顺序,部分软件对识别区域的顺序有特定要求,在设定区域时需遵循该要求。若不确定软件对区域顺序的规定,可先进行少量文件的测试识别,观察识别结果是否符合预期,再根据情况调整区域顺序。
区域顺序:部分软件在处理多个识别区域时,会按照设定的区域顺序进行识别和输出结果。因此,在设定区域顺序时,要根据实际需求和后续处理的逻辑进行合理安排。例如,如果需要将识别结果按照特定的顺序填入表格或生成文件名,那么在设定识别区域时,就要确保区域顺序与后续处理的要求一致。在进行复杂的文档处理时,建议在正式处理大量文件之前,先对少数样本文件进行识别测试,检查识别区域的设置和区域顺序是否正确,识别结果是否符合预期。如果发现问题,可以及时调整识别区域的设置和顺序,避免在处理大量文件后才发现错误,造成不必要的时间浪费。
(三)重命名规则
规则一致性:在设置重命名规则时,要保持规则的一致性和逻辑性。重命名规则应根据文件的内容和管理需求进行设计,确保生成的文件名能够准确反映文件的关键信息,便于后续的查找和管理。例如,在企业档案管理中,如果需要根据合同编号、签订方和签订日期对合同文件进行重命名,可以设置重命名规则为 “合同编号_签订方_签订日期.pdf”。这样生成的文件名清晰明了,通过文件名就能快速了解文件的核心内容。同时,要注意在整个文件管理系统中,保持重命名规则的一致性,避免出现不同类型的文件采用不同的重命名规则,导致文件名混乱,难以管理。
避免非法字符:在设置重命名规则时,要避免使用系统不允许的非法字符。不同的操作系统对文件名中允许使用的字符有不同的规定,一般来说,常见的非法字符包括 “/”“\”“*”“?”“:”“<”“>”“|” 等。如果文件名中包含这些非法字符,可能会导致文件无法正常保存、移动或访问。在设置重命名规则时,可以参考操作系统的相关规定,确保生成的文件名符合系统要求。如果不确定哪些字符是非法字符,可以先在测试环境中进行尝试,观察系统的提示信息,以确定合法的字符范围。
结果校验:识别和重命名完成后,务必对处理结果进行仔细校验。检查文件名是否准确反映了文件中指定区域的文字内容,文件是否都已成功重命名,有无遗漏或重命名错误的文件。若选择了 “区域识别导表格” 功能,还需检查导出的表格内容是否完整、准确,数据是否与 PDF 文件中的识别结果一致。在进行结果校验时,可以随机抽取部分文件进行详细检查,对比文件名与文件内容,查看表格中的数据是否与 PDF 文件中的对应区域一致。如果发现错误或不符合预期的情况,应及时返回相应步骤进行修正,如调整识别区域、修改重命名规则等,然后重新执行识别和重命名操作,直至结果符合要求。