EffRes-DrowsyNet:结合 EfficientNetB0 与 ResNet50 的新型混合深度学习模型用于驾驶员疲劳检测算法实现

主要发现是什么?
-
EffRes-DrowsyNet 是一个集成了 EfficientNetB0 和 ResNet50 的混合深度学习模型,在 SUST-DDD 上实现了 97.71% 的准确率、92.73% 的 YawDD 和 95.14% 的 NTHU-DDD 的高性能。
-
该模型在不同条件下表现出很强的泛化和可靠性,在所有数据集上保持高精度和召回率。
主要发现的含义是什么?
-
混合架构在计算效率和深度视觉表示之间提供了有效的平衡,从而支持在驾驶员监控系统中进行实时部署。
-
它的稳健性和适应性使其成为集成到安全关键应用中的有前途的解决方案,有助于减少汽车和相关领域中疲劳引起的事故。
1. 引言
驾驶员疲劳是全球交通事故的重要诱因,NHTSA 和欧盟数据显示其导致大量事故与伤亡。基于计算机视觉的高级驾驶员监控系统可通过非侵入式手段检测疲劳,而深度学习驱动的视频分析技术为此提供了新路径,如 CNN 结合 LSTM 能有效分析驾驶员面部表情、头部运动等疲劳迹象。本研究提出的 EffRes-DrowsyNet 混合模型,融合 EfficientNetB0 可扩展架构与 ResNet50 残差连接优势,前者能处理不同驾驶环境的视觉数据,后者可捕获细微疲劳特征。
2. 相关研究
各种研究提出了检测驾驶员疲劳和监测注意力的不同标准和解决方案。多年来,已经进行了大量研究来检测嗜睡并提醒驾驶员降低事故率 [15,16]。
在早期阶段识别嗜睡对于预防事故至关重要,通过人工智能实现这一过程的自动化增强了有效且具有成本效益地评估更多病例的能力 [17]。在探索用于眼状态分类的 CNN 模型时,作者开发了一种名为 4D 模型的新型 CNN 模型,该模型通过分析 MRL Eye 数据集中的眼睛状态,在检测嗜睡方面表现出 97.53% 的高精度,优于 VGG16 和 VGG19 等其他预训练模型。
[18] 的作者强调了一种使用最先进的 CNN(包括 InceptionV3、VGG16 和 ResNet50)的实时驾驶员干扰监测方法,其中 ResNet50 模型表现出 93.69% 的最高准确率。该研究利用了一个独特的数据集,其中包括驾驶员的侧视图和前视图,这显著提高了系统检测驾驶员睡意的性能和实时效率。
在 [19] 中,提出了使用面部标志来监测眨眼和打哈欠来检测驾驶员睡意的有效方法,以及采用 MobileNet-V2 和 ResNet-50V2 实时分析驾驶员活动的深度学习技术。利用迁移学习,该研究实现了 97% 的显着准确率,证明了这些方法在增强打瞌睡警报系统和防止驾驶员疲劳造成的事故方面的潜力。
[20] 中的方法表明,为了对抗驾驶员疲劳,研究人员采用了人工智能,特别是 CNN,来分析驾驶员的嘴巴和眼睛的状态,计算闭眼百分比 (PERCLOS) 和打哈欠频率 (FOM) 等特征。这种方法实现了 87.5% 的显着准确率,突显了 AI 在识别和减轻与驾驶员疲劳相关的风险方面的潜力。
[21] 中的研究利用深度学习方法,通过分析从实时摄像机镜头中提取的面部标志来检测驾驶员的困倦,并使用代表不同驾驶条件的 2904 张图像的数据集。该研究通过使用基于特征的级联分类器在实时场景中识别面部特征,实现了 95% 的高准确率,展示了一种有效的驾驶员疲劳持续监测策略。
[22] 的作者介绍了一种结合 2D-CNN 和 LSTM 网络来检测驾驶员疲劳的方法,在 YawDD 数据集上显示出 95% 的显着准确性。通过 2D-CNN-LSTM 网络集成空间和时间数据的有效性凸显了其在汽车安全技术中实际应用的潜力,明显优于几种现有方法。
[23] 的研究采用了集成 CNN 和 Dlib 的 68 个地标性人脸检测器,通过研究闭眼频率和打哈欠等面部线索来分析疲劳驾驶的早期症状。集成 CNN 模型展示了卓越的准确性,与眼睛相关的线索达到 97.4%,与嘴部相关的线索达到 96.5%,表现出优于其他预训练模型的性能,并为将困倦检测系统集成到车辆中以提高驾驶员安全性提供了有前途的解决方案。
[24] 中的研究通过实施基于 Dlib 的面部特征检测算法,采用静态和自适应帧阈值方法,利用闭眼率 (ECR) 和嘴孔比 (MAR) 来评估嗜睡水平,从而推进长途驾驶员的睡意检测。特别是自适应帧阈值方法,可以动态调整表示睡意的连续帧数,达到 98.2% 的显着准确率,从而提高了在实际条件下睡意检测的精度和可靠性。
为了满足对有效的驾驶员睡意检测系统日益增长的需求以提高道路安全,许多研究采用了先进的成像和机器学习技术。表 1 总结了近年来的关键研究,突出了使用各种 CNN 模型检测驾驶员疲劳所取得的不同方法和结果。
与基于视觉的方法相比,[25] 中的研究引入了一种混合模型,该模型利用脑电图 (EEG) 信号进行嗜睡检测,将用于特征优化的快速邻域成分分析 (FNCA) 与用于分类的深度神经网络 (DNN) 相结合。使用 SEED-VIG 数据集和在受控睡眠剥夺下收集的静息态 EEG 数据集对所提出的方法进行了评估,实现了 94.29% 的峰值准确率。通过从神经活动中提取认知特征,该模型有效地识别了嗜睡状态,并在分类准确性和学习效率方面表现出出色的表现。
Table 1. Recent advances in image and video-based driver drowsiness detection systems.
| Reference | Year | Parameters Analyzed | Methodology | Implementation Details | Accuracy | Dataset Used |
|---|---|---|---|---|---|---|
| [26] | 2020 | Eye and mouth | CNN | GeForce GTX 1080 Ti (NVIDIA, Santa Clara, CA, USA); Python 3.5.2 (Python Software Foundation, Wilmington, DE, USA); Keras 2.2.4 (Chollet F., open source) | 93.62% | Driving Image Dataset from Bite Company |
| [27] | 2020 | Eye, head, mouth | 3D Convolutional Networks | Alienware R17 (Dell, Round Rock, TX, USA); Ubuntu 16.04 LTS (Canonical Ltd., London, UK); 16 GB RAM; 8 GB GPU (Not specified) | 97.3% | NTHU-DDD Public |
| [28] | 2020 | Eye | FD-NN, TL-VGG16, TL-VGG19 | NVIDIA Jetson Nano (NVIDIA, Santa Clara, CA, USA); Near-Infrared camera (Not specified); Custom CNN on Ubuntu (open source) | 95–98.15% | Self-prepared ZJU |
| [29] | 2020 | Eye and mouth | Mamdani Fuzzy Inference | Not applicable | 95.5% | 300-W Dataset |
| [30] | 2020 | Eye | Multilayer Perceptron, RF, SVM | Not applicable | 94.9% | Self-prepared (DROZY Database) |
| [31] | 2020 | Respiration (thermal camera) | SVM, KNN | Thermal camera recording at 7.5 FPS | 90%, 83% | Self-prepared Thermal Image |
| [32] | 2020 | Mouth | Cold and Hot Voxels | Ambient Temp. Control in Lab and Car | 71%, 87% | Self-prepared |
| [33] | 2020 | Facial features, Head movements | 3D CNN | Python 3.6.1, TensorFlow r1.4, reduced video resolution for training | 73.9% | NTHU-DDD Public |
| [34] | 2021 | Mouth | CNN | Not applicable | 99.35% | YawDD, Nthu-DDD, KouBM-DFD |
| [35] | 2021 | Eye, head, mouth | SVM | Not applicable | 79.84% | NTHU-DDD Public |
| [36] | 2021 | Eye and face | Deep-CNN Ensemble | Python 3.6, Jupyter Notebook, Windows 10, Intel Core i5, 8 GB RAM | 85% | NTHU-DDD Video |
| [37] | 2022 | Eye, head, mouth | CNN and SVM | Not applicable | 97.44% | Newly Created: YEC, ABD |
| [38] | 2022 | Eye and face | Dual CNN | NVIDIA Xavier, Intel NCS2; 11-62 FPS performance | 97.56–98.98% | CEW, ZJU, MRL |
| [39] | 2022 | Face | RNN and CNN | Not applicable | 60% | UTA-RLDD |
| [40] | 2023 | Eye and face | CNN | Not applicable | 98.53% | Self-prepared |
| [41] | 2023 | Eye and mouth | Dlib’s Haar Cascade | Dlib Toolkit | 98% | Self-prepared |
| [42] | 2023 | Facial expressions (eyes open, closed, yawning, no yawning) | CNN, VGG16 | 2900 images including gender, age, head position, illumination | CNN Accuracy 97%; VGG16: 74% Accuracy | Self-prepared dataset |
| [43] | 2024 | Face for signs of tiredness | ResNet50 | Model trained on Kaggle dataset, test accuracy achieved at epoch 20 | 95.02%, Loss: 0.1349 | Kaggle (Varied Dataset) |
3. 方法
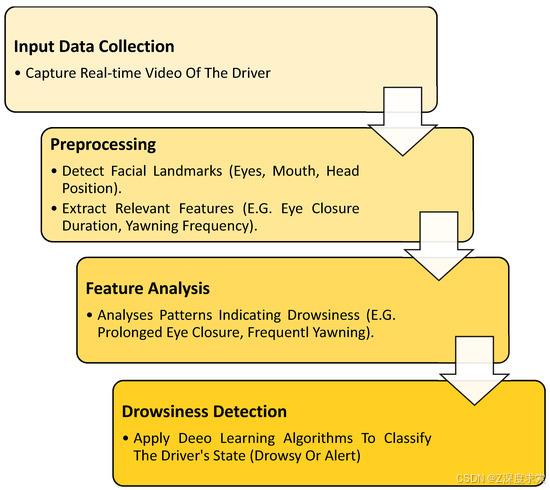
方法工作流程(参见图 1)遵循结构化过程,以准确检测驾驶员的睡意。它首先从驾驶员监控数据集中收集数据,然后对其进行预处理以分析面部特征,例如眼睛和嘴巴运动。接下来,两个深度学习模型(EfficientNetB0 和 ResNet50)从图像中提取重要细节。然后,将这些功能组合和优化以提高准确性。然后,系统会将驾驶员的状态分类为 drowsy 或 alert。最后,如果检测到困倦,输出会触发警告,有助于防止事故和改善道路安全。
3.1. 数据集描述
3.1.1. SUST-DDD 数据集
3.1.2. YawDD 数据集
3.1.3. NTHU-DDD 数据集
3.2. 数据预处理和增强
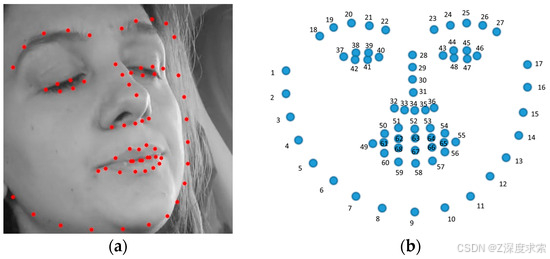
3.2.1. 用于嗜睡和非嗜睡的面部特征点检测
3.2.2. 纵横比计算
- 眼睛纵横比 (EAR)
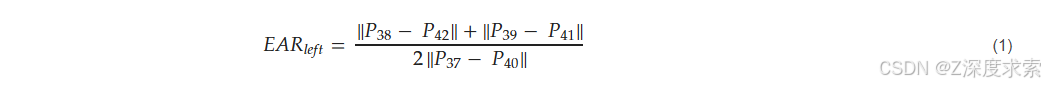
同样,右眼 EAR 由公式 (2) 给出,如下所示:

在这种方法中,根据每个视频的独特数据动态计算每个视频的眼睛纵横比 (EAR) 阈值,从而提高睡意检测的精度。如果 EAR 低于此自适应阈值,则表示闭眼,表明嗜睡;高于阈值的值表示睁开眼睛。此方法可确保检测适应单个视频中的变化,从而提高分析的可靠性。
- 嘴部纵横比 (MAR)

与 EAR 类似,嘴部纵横比 (MAR) 是使用特定嘴部特征点之间的垂直和水平距离计算的。此比率是针对每个视频动态确定的,从而提高了检测准确性。如果 MAR 超过自适应阈值,则检测到打哈欠,表明可能存在嗜睡。低于阈值的值表示没有打哈欠。此方法适用于单个视频的变化,确保可靠和精确的哈欠检测。
3.2.3. 驾驶员睡意检测中的特征融合和特征点精度
由于 EffRes-DrowsyNet 采用混合方法,将手工制作的视觉特征(特别是 EAR 和 MAR)与 EfficientNetB0 和 ResNet50 提取的深度特征相结合,因此该模型受益于低级几何线索和高级语义表示,提高了其在不同照明和面部条件下检测睡意的可靠性。
EAR 和 MAR 的有效性取决于关键面部标志的准确定位。在这项工作中,由于 Dlib 68 点模型在正面面部分析中的可靠性而被采用。但是,在实际条件下,例如头部姿势变化、遮挡(例如眼镜、手势)和可变照明,特征点的准确性可能会降低。这些因素可能会扭曲 EAR 和 MAR 计算,从而导致错误的分类。
为了减轻此类风险,我们采用了以下策略:
-
应用面部对齐以标准化方向和缩放。
-
感兴趣区域 (ROI) 提取将注意力集中在眼睛和嘴巴区域。
-
对连续帧的平均 EAR 和 MAR 值进行时间平滑处理,以减少瞬态噪声和自然闪烁的影响。
重要的是,该模型不会根据孤立的帧级变化对困倦进行分类。相反,它会随着时间的推移学习行为模式,例如持续闭眼或反复打哈欠。这些时间描述符与深度视觉特征融合,形成最终分类的统一表示。这种方法允许模型区分典型的闪烁和疲劳诱发状态。
虽然当前方法提高了稳健性,但持续的特征点不准确仍可能影响性能。作为未来工作的一部分,我们计划探索基于置信度的关键点过滤和完全端到端的架构,以减少对显式地标测量的依赖,同时保持行为可解释性。
3.2.4. 帧预处理
为了准备用于分析的人脸区域,视频帧经历了几个预处理步骤,如图 3 所示。
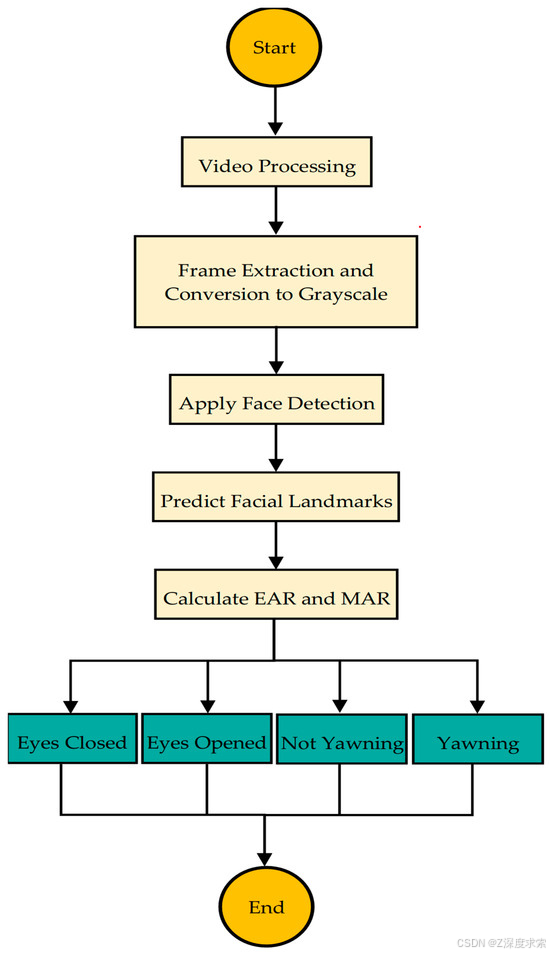
3.2.5. 视频处理和事件检测
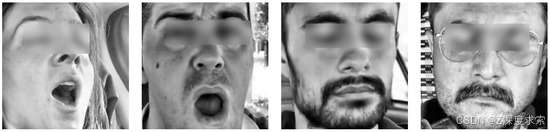
- 嗜睡视频处理:
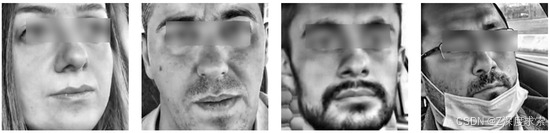
- 非嗜睡视频处理:
| Algorithm 1: Frame Count Normalization For Video Datasets | ||
| Input: | ||
| Input directory containing video frame folders, output directory, and desired number of frames per video. | ||
| Initialize Categories: Check and create the output directory if it does not exist. | ||
| Process: | ||
For Each Video Directory in the Input Directory:
| ||
| Output: | ||
| Indicate successful normalization of frame counts for all processed directories. | ||
| End Algorithm | ||
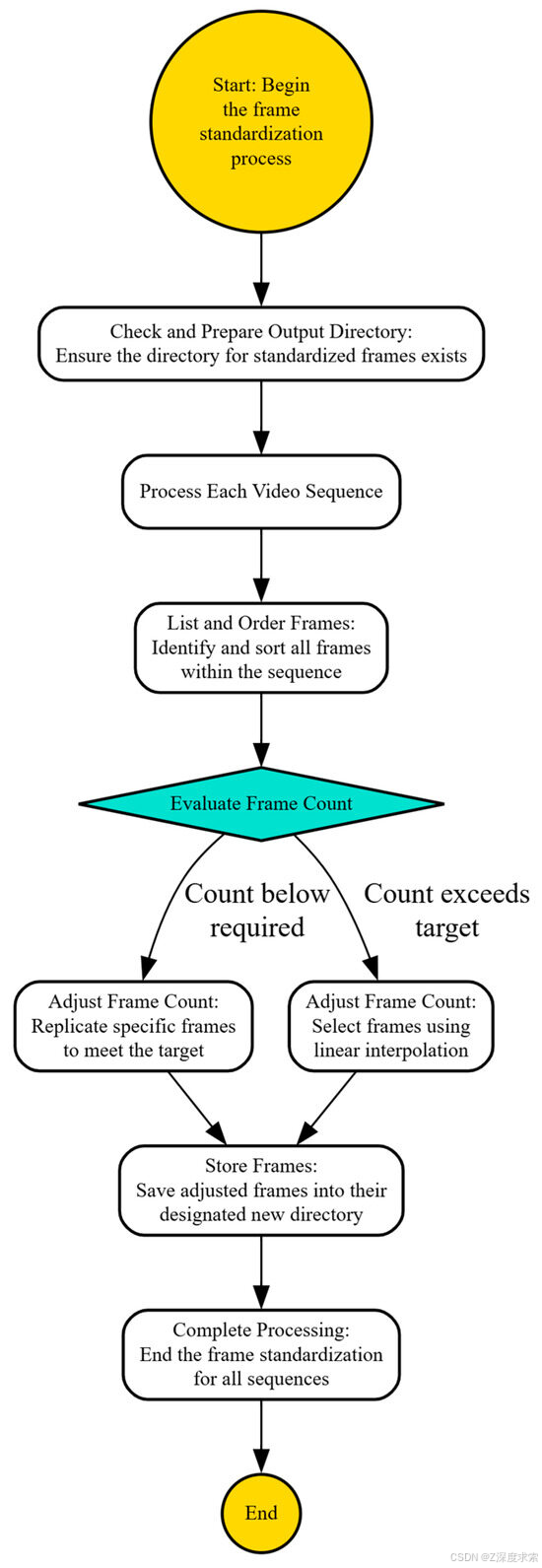
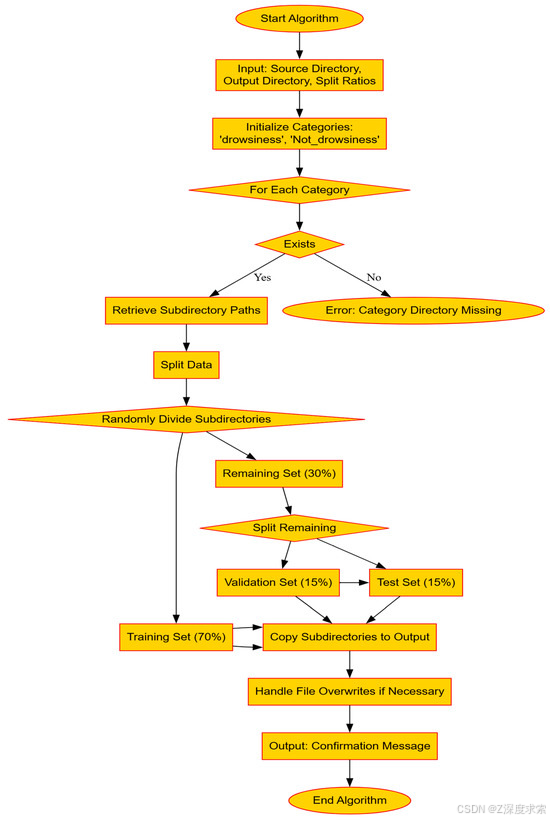
图 6 显示了确保每个视频序列包含统一数量的帧以实现机器学习模型的一致输入的系统方法,包括帧评估、选择或复制以及系统存储。
3.3. 模型架构和配置
3.3.1. 单个模型
3.3.2. 特征连接和正则化
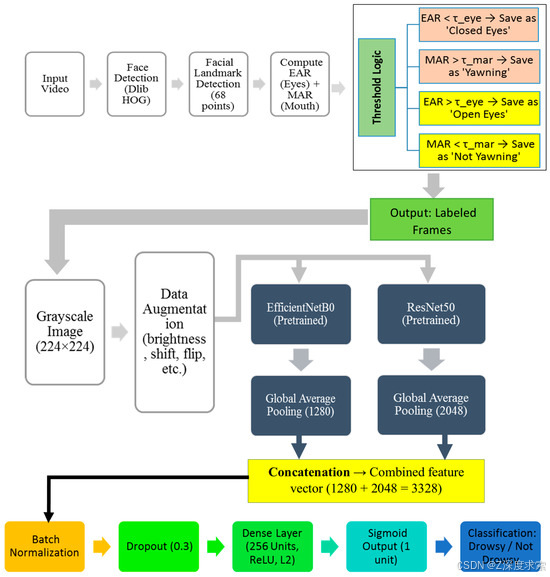
3.3.3. 模型架构
3.3.4. 编译和训练
3.3.5. 微调策略
3.3.6. 数据准备和扩充
3.3.7. 训练执行和评估
3.3.8. 实现概述
| Algorithm 2: EffRes-DrowsyNet—Hybrid Drowsiness Detection Model | ||
| Input: | ||
| ||
| Output: | ||
| ||
| Process: | ||
| (1) Preprocessing and Labeling: ○ For each frame F in video V:
(2) Data Preparation ○ Convert all labeled frames to grayscale (224 × 224) ○ Apply data augmentation: brightness shift, rotation, flipping, etc. ○ Split dataset into training, validation, and test sets (3) Hybrid CNN Model Construction (EffRes-DrowsyNet) ○ Input: Grayscale image I ∈ 𝑅224×224×1I ∈ R224×224×1 ○ EfficientPath ← EfficientNetB0 (Replicated as 3 channels) ○ ResNetPath ← ResNet50 (Replicated as 3 channels) ○ FeatureEffNet ← GlobalAveragePooling(EfficientPath) // Output: 1280-D ○ FeatureResNet ← GlobalAveragePooling(ResNetPath) // Output: 2048-D ○ FeatureVector ← Concatenate(FeatureEffNet, FeatureResNet) // 3328-D ○ x ← BatchNormalization(FeatureVector) ○ x ← Dropout (x, rate = 0.3) ○ x ← Dense (x, units = 256, activation = ‘ReLU’, regularizer = L2) ○ Output ← Dense (x, units = 1, activation = ‘Sigmoid’) (4) Training Phase ○ Compile model with Binary Cross-Entropy loss and Adam optimizer ○ Train model for max N epochs or until early stopping triggers ○ Monitor validation loss for learning rate reduction and overfitting (5) Inference ○ For each test video:
| ||
| End Algorithm | ||
4. 结果与讨论
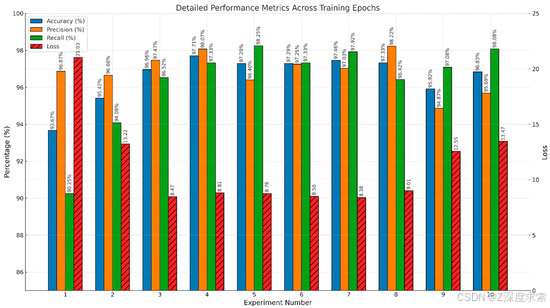
4.1. EFFRES-DrowsyNet 在 SUST-DDD 数据集上不同训练 epoch 的性能评估
| Experiment Number | Epochs | Test Accuracy | Test Precision | Test Recall | Test Loss |
|---|---|---|---|---|---|
| 1 | 10 | 93.67% | 96.87% | 90.25% | 0.2103 |
| 2 | 20 | 95.42% | 96.66% | 94.08% | 0.1322 |
| 3 | 30 | 96.96% | 97.47% | 96.52% | 0.0847 |
| 4 | 40 Early stopping at Epoch 25 | 97.71% | 98.07% | 97.33% | 0.0881 |
| 5 | 50 | 97.29% | 96.40% | 98.25% | 0.0876 |
| 6 | 60 | 97.29% | 97.25% | 97.33% | 0.0850 |
| 7 | 70 Early stopping at Epoch 36 | 97.46% | 97.03% | 97.92% | 0.0838 |
| 8 | 80 Early stopping at Epoch 32 | 97.33% | 98.22% | 96.42% | 0.0901 |
| 9 | 90 | 95.92% | 94.87% | 97.08% | 0.1255 |
| 10 | 100 Early stopping at Epoch 22 | 96.83% | 95.69% | 98.08% | 0.1347 |
图 9 描述了在 10 个不同的实验设置中,不同训练时期对关键性能指标(准确度、精密度、召回率和损失)的影响。
4.1.1. 最优纪元和泛化
4.1.2. Early Stopping 的影响
4.1.3. 长时间训练的效果
4.1.4. 精度-召回率权衡
4.1.5. SUST-DDD 数据集模型训练(40 个 epoch,提前停止在 epoch 25)的性能分析
- 训练动力学和模型优化
- 初始学习阶段
- 训练中期调整
- 学习率降低
- 收敛和提前停止
4.1.6. 最终模型评估
4.1.7. 关键要点
4.2. EFFRES-DrowsyNet 在 YawDD 数据集上不同训练时期的性能评估
4.2.1. 实验概述和方法
4.2.2. 详细结果和分析
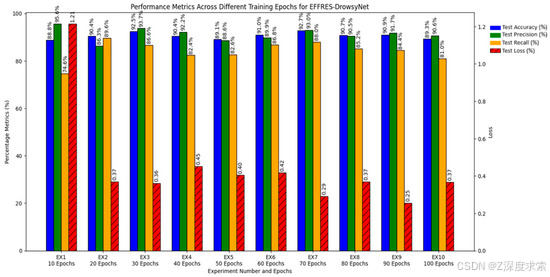
| Experiment Number | Epochs | Test Accuracy | Test Precision | Test Recall | Test Loss |
|---|---|---|---|---|---|
| 1 | 10 | 88.75% | 95.64% | 74.6% | 1.2149 |
| 2 | 20 | 90.39% | 86.32% | 89.6% | 0.3699 |
| 3 | 30 | 92.5% | 93.72% | 86.6% | 0.3614 |
| 4 | 40 | 90.39% | 92.17% | 0.824% | 0.452 |
| 5 | 50 (Early stopping at 42) | 89.06% | 88.63% | 0.826% | 0.4043 |
| 6 | 60 (Early stopping at 31) | 91.02% | 89.86% | 0.8685% | 0.4166 |
| 7 | 70 (Early stopping at 38) | 92.73% | 93.02% | 0.88% | 0.2905 |
| 8 | 80 (Early stopping at 42) | 90.7% | 90.45% | 0.852% | 0.3696 |
| 9 | 90 (Early stopping at 38) | 90.94% | 91.74% | 0.844% | 0.2543 |
| 10 | 100 (Early stopping at 37) | 89.3% | 90.6% | 0.81% | 0.3671 |
实验 1 到实验 4 显示准确率和精密度的逐渐提高,这表明训练持续时间的初始增量大大增强了模型正确识别嗜睡的能力。
实验 5 到实验 7 受益于早期停止的应用,它保留了高性能指标,同时防止了过度拟合。值得注意的是,EX7 在 38 个时期停止训练,表现出模范性能,在所有评估指标之间取得了最佳平衡。
实验 8 到实验 10 在 EX7 中建立的早期停止点之后,性能指标表现出停滞或略微回归的迹象,这表明将训练扩展到此阈值之外会产生收益递减,并可能导致模型过度训练。
4.2.3. 最佳训练配置
分析结果明确表明,训练 EFFRES-DrowsyNet 大约 70 到 80 个时期,特别是提前停止,可以优化所有指标的性能,而不会导致过拟合。实验 7 是最有效的配置,在准确率、精密度和召回率方面获得了最高分,并且损失率较低。该实验提出了一个令人信服的案例,用于设置训练 epoch 数的上限,以最大限度地提高驾驶员睡意检测的实际应用的效率和效能。
这项全面的评估不仅证实了 EFFRES-DrowsyNet 的强大功能,还强调了明智的培训管理对于实现最佳运营绩效的重要性。这一系列实验的结果将指导模型的未来实施和优化,确保 EFFRES-DrowsyNet 仍然是驾驶员安全技术领域的尖端解决方案。
4.2.4. YawDD 数据集上的模型训练(70 个 epoch 和 epoch 38 提前停止)的性能分析
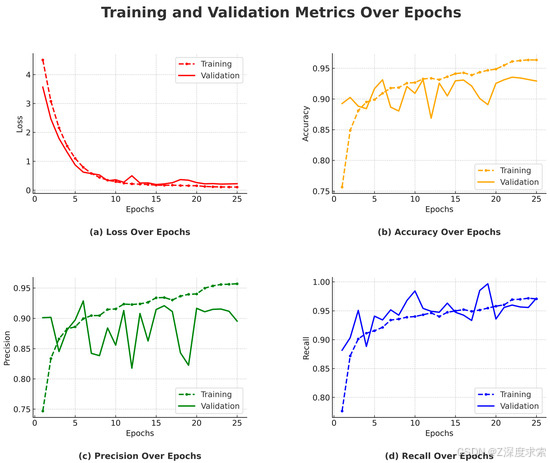
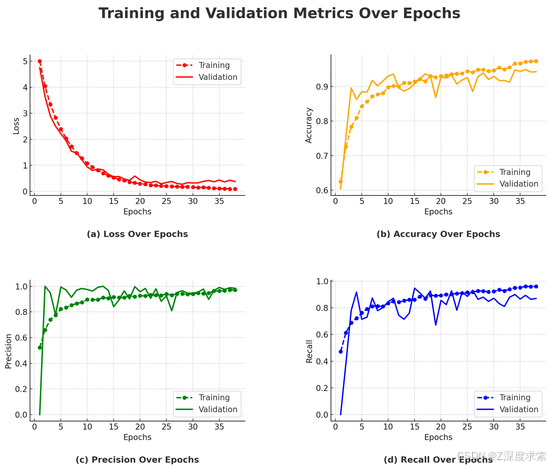
该模型被配置为训练总共 70 个时期,但由于验证性能停滞不前,因此在第 38 个时期应用了提前停止。以下是模型在训练过程中性能的详细分析,参考了准确度、精度、召回率和损失图。
-
Epoch 级性能概述
在第 1 个和第 3 个时期之间,模型显示出显著的改进,训练准确率从 62.47% 提高到 78.36%。这种快速的初始学习阶段在图 12b 中很明显,其中 accuracy 曲线急剧上升。相应地,在这些早期时期,精确率和召回率也有所提高,如图 12c,d 所示,这表明该模型很快就学会了分类所需的基本模式。在验证方面,准确率从 60.32% 显著提高到 89.60%,表明泛化能力较早。在第 4 到第 10 个时段期间,训练准确率不断提高,到第 10 个时段达到 90.79%。然而,验证准确率稳定在 89.60% 左右,如图 12b 所示,其中验证曲线在初始上升后趋于平坦。精确率仍然很高,召回率提高到 83.42%,表明模型的分类性能稳定。这些趋势在图 12c,d 中可以清楚地观察到。
4.2.5. 性能指标
- 训练精度:该模型在训练准确率方面稳步提高,最终在 Epoch 37 时达到 97.38%。然而,训练和验证准确性之间的差距越来越大( 如图 12b 中清楚地说明)表明过拟合的开始。虽然该模型继续从训练数据中学习,但它在看不见的数据上的性能并没有显示出相应的改进。
- 验证精度:如图 12b 所示,该模型在第 28 纪元达到了 94.92% 的最高验证准确率。超过这一点,没有观察到进一步的改进,这表明该模型有效地捕获了数据中的基本模式。验证曲线的稳定强调了模型在持续训练下有限的泛化收益。
- 精度和召回率:在整个训练过程中,准确率和召回率始终保持很高。准确率保持在 93% 以上,而召回率稳定在 88% 左右,这表明该模型在最大限度地减少假阳性和假阴性方面的有效性。这些趋势反映在 图 12c,d 中,这两个指标都表明在初始学习阶段之后是稳定的,只有很小的波动。
- 训练和验证损失趋势:如图 12a 所示,训练损失从 5.0042 稳步下降到 0.0884,证实了有效的模型学习。验证损失在第 28 个时段达到最小值 0.2704,与峰值验证准确度一致。验证损失的后续波动表明过拟合的早期迹象,支持了在 Epoch 38 提前停止的基本原理。
- 测试性能:最终模型评估得到测试损失 0.2905,测试准确率为 92.73%,精密率为 93.02%,召回率为 88.00%。这些结果肯定了该模型的稳健性和对以前未见过的数据的强烈泛化。
4.2.6. 提前停止的影响
4.2.7. 学习率调度
4.2.8. 测试集性能
4.3. EFFRES-DrowsyNet 在 NTHU-DDD 数据集上 40 个时期的性能评估
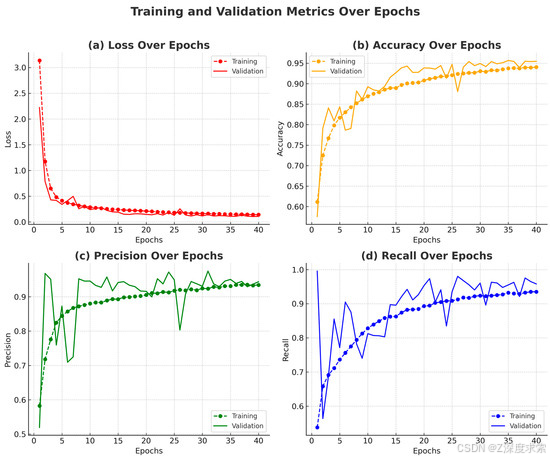
- Epoch 级性能概述
性能指标摘要
4.4. 所提出的混合深度学习模型与 SUST-DDD 和 NTHU-DDD 数据集上现有模型的比较
| Model | Accuracy (%) | Precision (%) | Recall (%) | Dataset Used | Analysis and Comparison with Proposed Hybrid Model |
|---|---|---|---|---|---|
| VGG19 + LSTM [44] | 90.53 | 91.74 | 91.28 | SUST-DDD | The VGG19 + LSTM model provides a solid baseline with high accuracy and balanced precision and recall. However, the proposed model achieves a very high accuracy of 97.71% with balanced precision and recall, while achieving a refined detection capability, expressed by precision at 98.07%. The recall also grew to 97.33%, meaning fewer misses. |
| VGG16 + LSTM [44] | 89.39 | 91.81 | 89.09 | SUST-DDD | Although VGG16 + LSTM achieves strong precision, its overall accuracy and recall fall slightly short of VGG19 + LSTM. In all metrics, the proposed hybrid model outperforms VGG16 + LSTM, hence it can be more dependable for real-time drowsiness detection. |
| AlexNet + LSTM [44] | 63.91 | 63.78 | 97.91 | SUST-DDD | AlexNet + LSTM achieves high recall, albeit with low accuracy and precision. In other words, it may produce too many false positives. The hybrid model we propose achieves much better accuracy and precision. Thus, it achieves a balance that looks more promising in being sensitive as well as specific when the sensitivity and specificity are particularly important to some real-world applications, which is suitable in scenarios where such characteristics are important. |
| VGGFaceNet + LSTM [44] | 84.94 | 83.65 | 94.92 | SUST-DDD | VGGFaceNet + LSTM shows good recall and fair accuracy but has lower precision, indicating a tendency for false positives. The proposed hybrid model outperforms it in all metrics, giving better accuracy, precision, and more robust balance—an ideal system for applications where safety is a concern. |
| EffRes-DrowsyNet (Ours) | 97.71 | 98.07 | 97.33 | SUST-DDD | The proposed hybrid model, which integrates EfficientNetB0 and ResNet50, demonstrates superior performance across all key metrics—accuracy, precision, and recall—surpassing previous models. This improvement underscores the hybrid model’s unique advantages, combining EfficientNetB0’s scalable and efficient processing with ResNet50’s deep feature extraction capabilities. The model’s high accuracy and precision significantly reduce false positives, while its elevated recall minimizes missed detections, making it highly sensitive to subtle signs of drowsiness. This balanced performance across metrics highlights the hybrid model’s potential as an optimal solution for real-world driver safety monitoring, particularly suited for real-time deployment in-vehicle systems where reliability and responsiveness are critical. |
| MobileNetV2 + 3D CNN [33] | 73.90 | Notreported | Notreported | NTHU-DDD | The MobileNetV2-based 3D CNN model offers real-time deployment advantages for mobile platforms with reasonable accuracy (73.9%) and robustness under occlusion (e.g., sunglasses). However, it lacks the detection performance of the proposed hybrid model, which significantly exceeds it in accuracy and provides complete precision-recall metrics. While the MobileNetV2 model is lightweight and deployable on devices like the Galaxy S7 with ~1 s inference time, it trades off accuracy and detection depth. The hybrid model is thus more suitable where maximum detection performance is essential, while the MobileNetV2-based solution might be preferred in low-resource or budget-constrained applications. |
| PMLDB [35] | 79.84 | Notreported | Notreported | NTHU-DDD | The PML-based handcrafted model achieves competitive accuracy through multiscale texture descriptors (LBP, HOG, COV) with PCA and Fisher Score for feature selection. Although it lacks deep learning’s dynamic adaptability and reports no precision/recall values, its balanced fusion strategy performs well under varied conditions (e.g., night, glasses). Nevertheless, the hybrid EffRes-DrowsyNet model significantly surpasses it in accuracy (+15.30%) and offers detailed evaluation metrics, making it more robust for critical deployment scenarios. PMLDB remains suitable for resource-constrained settings but not optimal for high-accuracy demands. |
| CNN Ensemble [36] | 85.00 | 86.30 | 82.00 | NTHU-DDD | The CNN ensemble model integrates four specialized CNNs (AlexNet, VGG-FaceNet, FlowImageNet, and ResNet) and uses simple averaging for decision-making. It achieves balanced and respectable performance in accuracy and precision. Compared to the hybrid EffRes-DrowsyNet, it performs lower in all metrics, particularly accuracy and recall. While the ensemble architecture offers modularity and robustness under varied lighting and gesture conditions, the proposed hybrid model provides significantly higher accuracy (95.14%) and greater consistency across all detection metrics. Thus, the hybrid model is better suited for safety-critical, real-time deployment scenarios. |
| EffRes-DrowsyNet (Ours) | 95.14 | 94.09 | 95.39 | NTHU-DDD | On the NTHU-DDD dataset, the proposed hybrid model again demonstrates excellent generalization and robust detection performance. With an accuracy of 95.14%, precision of 94.09%, and a high recall of 95.39%, it clearly surpasses previous models tested on this dataset. The close balance between precision and recall reflects its capability to detect drowsiness accurately while minimizing both false positives and false negatives. This makes it a strong candidate for real-time embedded deployment in intelligent transport systems, ensuring both safety and responsiveness in practical conditions. |
EffRes-DrowsyNet 性能的提高主要是由于其组件如何协同工作。通过结合 EfficientNetB0 和 ResNet50 两个强大的网络,该模型可以学习详细的面部模式和整体面部模式,这有助于处理面部位置、光线和表情的变化。另一个重要因素是在数据标记期间使用 EAR 和 MAR 计算。此步骤有助于仅选择有意义的帧,例如闭上眼睛或打哈欠时,使训练数据更加准确和相关。我们还应用了几种数据增强技术,使模型更加健壮并防止其过度拟合。最重要的是,dropout、批量归一化和学习率调度器的使用使模型能够更有效地训练模型。当我们把所有这些放在一起时,与其他模型相比,EffRes-DrowsyNet 始终显示出更好的准确度、精度和召回率。
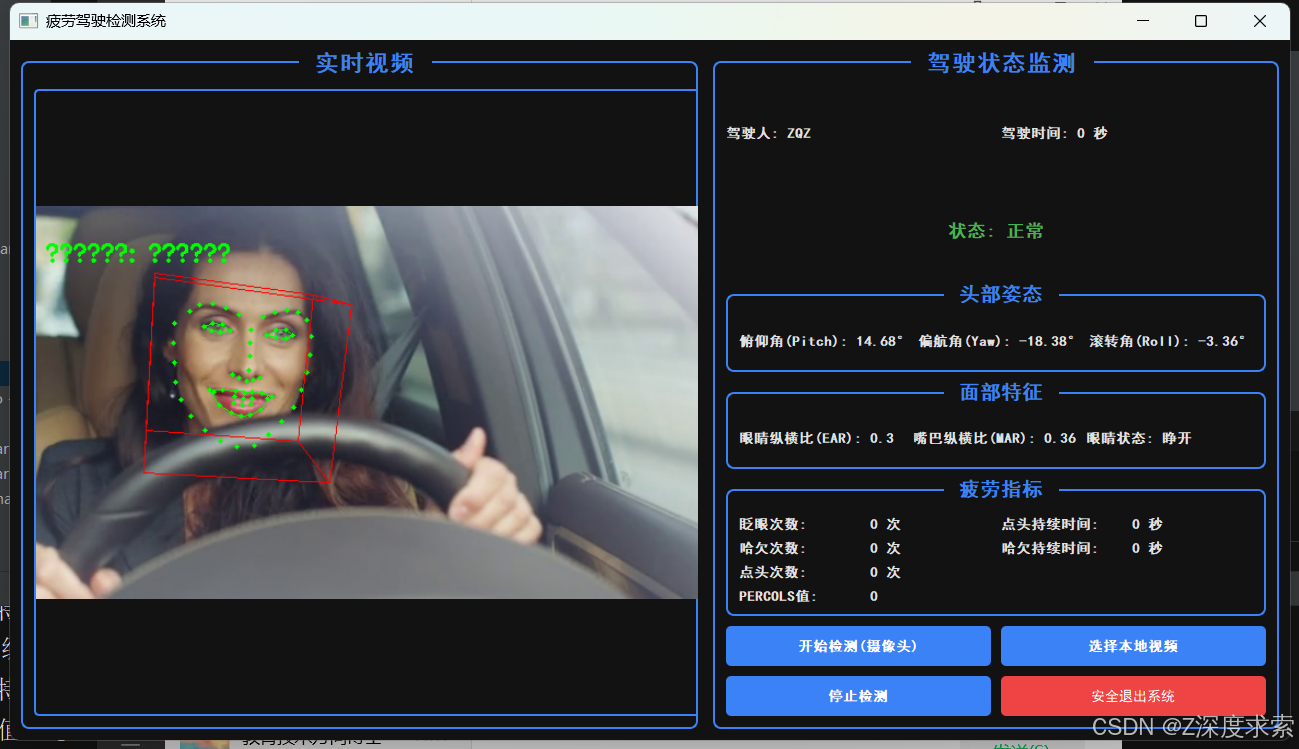
具体实现代码:点击这里
附录代码[主页联系]
def run(self):self.cap = cv2.VideoCapture(self.path)while self.running:ret, im_rd = self.cap.read()if ret:im_rd = imutils.resize(im_rd, height=480, width=640)original_img = im_rd.copy()# 灰度化图像img_gray = cv2.cvtColor(original_img, cv2.COLOR_BGR2GRAY)# 使用人脸检测器检测每一帧图像中的人脸faces = detector(img_gray, 0)# 准备信息字典用于UI更新info = {'alarm': self.alarm_flag,'driver_id': '未知','driving_time': 0,'pitch': 0,'yaw': 0,'roll': 0,'ear': 0,'mar': 0,'eyes_state': '睁开','nod_duration': 0,'yawn_duration': 0,'blinks': 0,'yawns': 0,'nods': 0,'percols': 0}if len(faces) == 1:for k, d in enumerate(faces):try:roi_gray = img_gray[d.top():d.bottom(), d.left():d.right()]roi_gray = cv2.resize(roi_gray, (92, 112))params = Eigen_Face_Model.predict(roi_gray)except:continue# 使用dlib预测器得到68点数据的坐标shape = predictor(original_img, d)shape_array = face_utils.shape_to_np(shape)if params[0] != self.last_params:# 驾驶员更换,重置计时self.driving_time = 0self.starttime = datetime.datetime.now()self.last_params = params[0]try:info['driver_id'] = names[params[0]]except:info['driver_id'] = '未识别'# 计算头部姿态reprojectdst, _, pitch, roll, yaw = HPE.get_head_pose(shape_array)info['pitch'] = round(pitch, 2)info['yaw'] = round(yaw, 2)info['roll'] = round(roll, 2)# 提取左眼、右眼和嘴巴的所有坐标leftEye = shape_array[lStart:lEnd]rightEye = shape_array[rStart:rEnd]mouth = shape_array[mStart:mEnd]# 计算EARleftEAR = ARE.eye_aspect_ratio(leftEye)rightEAR = ARE.eye_aspect_ratio(rightEye)EAR = (leftEAR + rightEAR) / 2.0info['ear'] = round(EAR, 2)# 记录EAR历史数据用于图表self.EAR_history.append(EAR)if len(self.EAR_history) > self.max_history_length:self.EAR_history.pop(0)# 眨眼检测 - 改进算法current_time = datetime.datetime.now()if EAR < self.EAR_threshold and not self.eyes_closed:# 眼睛刚闭上self.eyes_closed = Trueself.blink_start_time = current_timeself.blink_counter += 1elif EAR >= self.EAR_threshold and self.eyes_closed:# 眼睛刚睁开self.eyes_closed = Falseif self.blink_start_time and (current_time - self.blink_start_time).total_seconds() < 0.5:# 眨眼时间在合理范围内self.blinks += 1self.blink_start_time = None# 计算MARMAR = ARE.mouth_aspect_ratio(mouth)info['mar'] = round(MAR, 2)# 记录MAR历史数据self.MAR_history.append(MAR)if len(self.MAR_history) > self.max_history_length:self.MAR_history.pop(0)# 哈欠检测 - 改进算法if MAR > self.MAR_threshold and not self.mouth_open:# 嘴巴刚张开self.mouth_open = Trueself.yawn_start_time = current_timeself.yawn_counter += 1elif MAR <= self.MAR_threshold and self.mouth_open:# 嘴巴刚闭合self.mouth_open = Falseif self.yawn_start_time:yawn_duration = (current_time - self.yawn_start_time).total_seconds()if yawn_duration >= 1.0: # 哈欠持续时间超过1秒self.yawns += 1info['yawn_duration'] = int(yawn_duration)self.yawn_start_time = None# 点头检测 - 改进算法if pitch > self.pitch_threshold and not self.head_nodding:# 头部刚开始点头self.head_nodding = Trueself.nod_start_time = current_timeself.nod_counter += 1elif pitch <= self.pitch_threshold and self.head_nodding:# 头部刚结束点头self.head_nodding = Falseif self.nod_start_time:nod_duration = (current_time - self.nod_start_time).total_seconds()if nod_duration >= 0.5: # 点头持续时间超过0.5秒self.nods += 1info['nod_duration'] = int(nod_duration)self.nod_start_time = None# PERCOLS值计算 - 改进算法if params[0] in range(len(self.everybody_EAR_mean)):T1 = self.everybody_EAR_min[params[0]] + 0.2 * (self.everybody_EAR_mean[params[0]] - self.everybody_EAR_min[params[0]])T2 = self.everybody_EAR_min[params[0]] + 0.8 * (self.everybody_EAR_mean[params[0]] - self.everybody_EAR_min[params[0]])# 计算眼睛闭合程度if EAR < T1 and abs(pitch) < 15 and abs(yaw) < 25 and abs(roll) < 15:if self.P80_start_time1 is None:self.P80_start_time1 = current_timeelif self.P80_start_time1 is not None:duration = (current_time - self.P80_start_time1).total_seconds()if duration > 0:self.P80_sum_time1.append(duration)self.P80_start_time1 = Noneif EAR < T2 and abs(pitch) < 15 and abs(yaw) < 25 and abs(roll) < 15:if self.P80_start_time2 is None:self.P80_start_time2 = current_timeelif self.P80_start_time2 is not None:duration = (current_time - self.P80_start_time2).total_seconds()if duration > 0:self.P80_sum_time2.append(duration)self.P80_start_time2 = None# 计算PERCOLS值sum_t1 = sum(self.P80_sum_time1)sum_t2 = sum(self.P80_sum_time2)if sum_t2 > 0:self.f = min(round(sum_t1 / sum_t2, 2), 1.0) # 限制在0-1之间else:self.f = 0# 每60秒重置PERCOLS计算if int(self.driving_time) % 60 == 0:self.P80_sum_time1 = []self.P80_sum_time2 = []self.f = 0# 设置眼睛状态info['eyes_state'] = '闭合' if EAR < self.EAR_threshold else '睁开'info['blinks'] = self.blinksinfo['yawns'] = self.yawnsinfo['nods'] = self.nodsinfo['percols'] = self.f# 疲劳状态判断 - 改进算法# 每60秒检查一次疲劳状态if int(self.driving_time) % 60 == 0:if self.blinks >= 30:self.alarm_flag = '眨眼频率警告'elif self.yawns >= 5:self.alarm_flag = '哈欠频率警告'elif self.nods >= 3:self.alarm_flag = '点头频率警告'elif self.f > 0.6:self.alarm_flag = 'PERCOLS值警告'elif self.driving_time > self.Driving_Time_Threshold:self.alarm_flag = '长时间驾驶警告'else:self.alarm_flag = '正常'# 重置计数器self.blinks = 0self.yawns = 0self.nods = 0info['alarm'] = self.alarm_flaginfo['driving_time'] = int(self.driving_time)# 绘制特征点和姿态for i in range(68):cv2.circle(im_rd, (shape.part(i).x, shape.part(i).y), 2, (0, 255, 0), -1, 8)for start, end in self.line_pairs:cv2.line(im_rd, (int(reprojectdst[start][0]), int(reprojectdst[start][1])),(int(reprojectdst[end][0]), int(reprojectdst[end][1])), (0, 0, 255))# 绘制眼睛和嘴巴轮廓leftEyeHull = cv2.convexHull(leftEye)rightEyeHull = cv2.convexHull(rightEye)cv2.drawContours(im_rd, [leftEyeHull], -1, (0, 255, 0), 1)cv2.drawContours(im_rd, [rightEyeHull], -1, (0, 255, 0), 1)mouthHull = cv2.convexHull(mouth)cv2.drawContours(im_rd, [mouthHull], -1, (0, 255, 0), 1)# 添加疲劳状态文字提示 - 使用支持中文的字体status_color = (0, 255, 0) if self.alarm_flag == '正常' else (0, 0, 255)cv2.putText(im_rd, f"状态: {self.alarm_flag}", (10, 50),cv2.FONT_HERSHEY_SIMPLEX, 0.7, status_color, 2)elif len(faces) == 0:# 使用支持中文的字体cv2.putText(im_rd, "未检测到人脸", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)else:cv2.putText(im_rd, "检测到多个人脸", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 0, 0), 2)# 更新驾驶时间endtime = datetime.datetime.now()self.driving_time = (endtime - self.starttime).total_seconds()# 转换图像用于Qt显示rgb_image = cv2.cvtColor(im_rd, cv2.COLOR_BGR2RGB)h, w, ch = rgb_image.shapebytes_per_line = ch * wqt_image = QImage(rgb_image.data, w, h, bytes_per_line, QImage.Format_RGB888)self.change_pixmap_signal.emit(qt_image)# 发送信息更新UIself.update_info_signal.emit(info)else:# 视频结束或摄像头断开,重新打开self.reset_counters()self.cap = cv2.VideoCapture(self.path)def reset_counters(self):"""重置所有计数器"""self.driving_time = 0self.starttime = datetime.datetime.now()self.blink_counter = 0self.blinks = 0self.yawn_counter = 0self.yawns = 0self.nod_counter = 0self.nods = 0self.P80_sum_time1 = []self.P80_sum_time2 = []self.f = 0self.alarm_flag = '正常'self.eyes_closed = Falseself.mouth_open = Falseself.head_nodding = Falseself.blink_start_time = Noneself.yawn_start_time = Noneself.nod_start_time = Noneself.P80_start_time1 = Noneself.P80_start_time2 = Nonedef stop(self):self.running = Falseself.wait()if hasattr(self, 'cap') and self.cap.isOpened():self.cap.release()class FatigueDetectionApp(QMainWindow):def __init__(self):super().__init__()self.setWindowTitle('疲劳驾驶检测系统')self.setMinimumSize(1200, 700) # 增大窗口尺寸# 优化颜色方案,提高对比度self.setStyleSheet("""QMainWindow {background-color: #121212;}QLabel {color: #e0e0e0;font-size: 14px;}QPushButton {background-color: #3b82f6;color: white;border-radius: 5px;padding: 8px 15px;font-size: 14px;}QPushButton:hover {background-color: #2563eb;}QPushButton:pressed {background-color: #1d4ed8;}QGroupBox {border: 2px solid #3b82f6;border-radius: 8px;margin-top: 10px;padding-top: 15px;}QGroupBox::title {subcontrol-origin: margin;subcontrol-position: top center;padding: 0 10px;color: #3b82f6;font-weight: bold;font-size: 15px;}""")# 创建中央部件和主布局central_widget = QWidget()main_layout = QHBoxLayout(central_widget)main_layout.setSpacing(15) # 增加间距# 左侧视频显示区域video_group = QGroupBox("实时视频")video_group.setFont(title_font)video_layout = QVBoxLayout()self.video_label = QLabel("等待视频输入...")self.video_label.setAlignment(Qt.AlignCenter)self.video_label.setMinimumSize(700, 500)self.video_label.setStyleSheet("border: 2px solid #3b82f6; border-radius: 5px;")video_layout.addWidget(self.video_label)video_group.setLayout(video_layout)# 右侧信息显示区域info_group = QGroupBox("驾驶状态监测")info_group.setFont(title_font)info_layout = QVBoxLayout()info_layout.setSpacing(10) # 增加间距# 驾驶人信息driver_info_layout = QHBoxLayout()self.driver_id_label = QLabel("驾驶人: 未识别")self.driver_id_label.setFont(font)self.driving_time_label = QLabel("驾驶时间: 0 秒")self.driving_time_label.setFont(font)driver_info_layout.addWidget(self.driver_id_label)driver_info_layout.addWidget(self.driving_time_label)info_layout.addLayout(driver_info_layout)# 警告信息 - 增大尺寸和对比度self.alarm_label = QLabel("状态: 正常")self.alarm_label.setFont(alarm_font)self.alarm_label.setStyleSheet("color: #4caf50; font-size: 18px; font-weight: bold;")self.alarm_label.setAlignment(Qt.AlignCenter)self.alarm_label.setMinimumHeight(40)info_layout.addWidget(self.alarm_label)# 头部姿态pose_group = QGroupBox("头部姿态")pose_group.setFont(font)pose_layout = QHBoxLayout()self.pitch_label = QLabel("俯仰角(Pitch): 0.00°")self.pitch_label.setFont(font)self.yaw_label = QLabel("偏航角(Yaw): 0.00°")self.yaw_label.setFont(font)self.roll_label = QLabel("滚转角(Roll): 0.00°")self.roll_label.setFont(font)pose_layout.addWidget(self.pitch_label)pose_layout.addWidget(self.yaw_label)pose_layout.addWidget(self.roll_label)pose_group.setLayout(pose_layout)info_layout.addWidget(pose_group)# 面部特征face_group = QGroupBox("面部特征")face_group.setFont(font)face_layout = QHBoxLayout()self.ear_label = QLabel("眼睛纵横比(EAR): 0.00")self.ear_label.setFont(font)self.mar_label = QLabel("嘴巴纵横比(MAR): 0.00")self.mar_label.setFont(font)self.eyes_state_label = QLabel("眼睛状态: 睁开")self.eyes_state_label.setFont(font)face_layout.addWidget(self.ear_label)face_layout.addWidget(self.mar_label)face_layout.addWidget(self.eyes_state_label)face_group.setLayout(face_layout)info_layout.addWidget(face_group)# 疲劳指标fatigue_group = QGroupBox("疲劳指标")fatigue_group.setFont(font)fatigue_layout = QGridLayout()fatigue_layout.setSpacing(10) # 增加间距# 使用更清晰的标签self.blinks_label = QLabel("0 次")self.yawns_label = QLabel("0 次")self.nods_label = QLabel("0 次")self.percols_label = QLabel("0.00")self.nod_duration_label = QLabel("0 秒")self.yawn_duration_label = QLabel("0 秒")# 设置标签字体labels = [self.blinks_label, self.yawns_label, self.nods_label,self.percols_label, self.nod_duration_label, self.yawn_duration_label]for label in labels:label.setFont(font)# 优化布局fatigue_layout.addWidget(QLabel("眨眼次数:", font=font), 0, 0)fatigue_layout.addWidget(self.blinks_label, 0, 1)fatigue_layout.addWidget(QLabel("哈欠次数:", font=font), 1, 0)fatigue_layout.addWidget(self.yawns_label, 1, 1)fatigue_layout.addWidget(QLabel("点头次数:", font=font), 2, 0)fatigue_layout.addWidget(self.nods_label, 2, 1)fatigue_layout.addWidget(QLabel("PERCOLS值:", font=font), 3, 0)fatigue_layout.addWidget(self.percols_label, 3, 1)fatigue_layout.addWidget(QLabel("点头持续时间:", font=font), 0, 2)fatigue_layout.addWidget(self.nod_duration_label, 0, 3)fatigue_layout.addWidget(QLabel("哈欠持续时间:", font=font), 1, 2)fatigue_layout.addWidget(self.yawn_duration_label, 1, 3)fatigue_group.setLayout(fatigue_layout)info_layout.addWidget(fatigue_group)# 控制按钮control_layout = QGridLayout()self.start_button = QPushButton("开始检测(摄像头)")self.start_button.setFont(font)self.start_button.setMinimumHeight(40)self.stop_button = QPushButton("停止检测")self.stop_button.setFont(font)self.stop_button.setMinimumHeight(40)self.stop_button.setEnabled(False)self.local_video_button = QPushButton("选择本地视频")self.local_video_button.setFont(font)self.local_video_button.setMinimumHeight(40)self.exit_button = QPushButton("安全退出系统")self.exit_button.setFont(font)self.exit_button.setMinimumHeight(40)self.exit_button.setStyleSheet("background-color: #ef4444;")control_layout.addWidget(self.start_button, 0, 0)control_layout.addWidget(self.local_video_button, 0, 1)control_layout.addWidget(self.stop_button, 1, 0)control_layout.addWidget(self.exit_button, 1, 1)info_layout.addLayout(control_layout)info_group.setLayout(info_layout)# 将视频和信息区域添加到主布局main_layout.addWidget(video_group)main_layout.addWidget(info_group)main_layout.setStretch(0, 3) # 视频区域占3份main_layout.setStretch(1, 2) # 信息区域占2份self.setCentralWidget(central_widget)# 创建视频线程self.video_thread = VideoThread()self.video_thread.change_pixmap_signal.connect(self.update_video_frame)self.video_thread.update_info_signal.connect(self.update_info_display)# 连接信号和槽self.start_button.clicked.connect(self.start_camera_detection)self.stop_button.clicked.connect(self.stop_detection)self.local_video_button.clicked.connect(self.select_local_video)self.exit_button.clicked.connect(self.safe_exit)def start_camera_detection(self):"""开始摄像头检测"""self.start_button.setEnabled(False)self.stop_button.setEnabled(True)self.video_thread.set_video_source(0) # 0表示默认摄像头self.video_thread.running = Trueself.video_thread.start()def select_local_video(self):"""选择本地视频文件"""options = QFileDialog.Options()video_file, _ = QFileDialog.getOpenFileName(self, "选择视频文件", "","视频文件 (*.mp4 *.avi *.mov *.mkv);;所有文件 (*)",options=options)if video_file:self.start_button.setEnabled(False)self.stop_button.setEnabled(True)self.video_thread.set_video_source(video_file)self.video_thread.running = Trueself.video_thread.start()def stop_detection(self):"""停止检测"""self.start_button.setEnabled(True)self.stop_button.setEnabled(False)self.video_thread.stop()# 重置UI显示self.update_info_display({'alarm': '正常','driver_id': '未识别','driving_time': 0,'pitch': 0,'yaw': 0,'roll': 0,'ear': 0,'mar': 0,'eyes_state': '睁开','nod_duration': 0,'yawn_duration': 0,'blinks': 0,'yawns': 0,'nods': 0,'percols': 0})def safe_exit(self):"""安全退出系统"""reply = QMessageBox.question(self, '确认退出', '确定要退出系统吗?',QMessageBox.Yes | QMessageBox.No, QMessageBox.No)if reply == QMessageBox.Yes:if self.video_thread.isRunning():self.video_thread.stop()QApplication.quit()def update_video_frame(self, qt_image):"""更新视频帧"""pixmap = QPixmap.fromImage(qt_image)self.video_label.setPixmap(pixmap.scaled(self.video_label.width(), self.video_label.height(),Qt.KeepAspectRatio, Qt.SmoothTransformation))def update_info_display(self, info):"""更新信息显示"""self.driver_id_label.setText(f"驾驶人: {info['driver_id']}")self.driving_time_label.setText(f"驾驶时间: {info['driving_time']} 秒")# 根据警告类型设置不同颜色if info['alarm'] == '正常':self.alarm_label.setText(f"状态: {info['alarm']}")self.alarm_label.setStyleSheet("color: #4caf50; font-size: 18px; font-weight: bold;")else:self.alarm_label.setText(f"警告: {info['alarm']}")self.alarm_label.setStyleSheet("color: #ff5252; font-size: 18px; font-weight: bold;")self.pitch_label.setText(f"俯仰角(Pitch): {info['pitch']}°")self.yaw_label.setText(f"偏航角(Yaw): {info['yaw']}°")self.roll_label.setText(f"滚转角(Roll): {info['roll']}°")self.ear_label.setText(f"眼睛纵横比(EAR): {info['ear']}")self.mar_label.setText(f"嘴巴纵横比(MAR): {info['mar']}")self.eyes_state_label.setText(f"眼睛状态: {info['eyes_state']}")self.blinks_label.setText(f"{info['blinks']} 次")self.yawns_label.setText(f"{info['yawns']} 次")self.nods_label.setText(f"{info['nods']} 次")self.percols_label.setText(f"{info['percols']}")self.nod_duration_label.setText(f"{info['nod_duration']} 秒")self.yawn_duration_label.setText(f"{info['yawn_duration']} 秒")def closeEvent(self, event):"""关闭事件处理"""if self.video_thread.isRunning():self.video_thread.stop()event.accept()