概率基础——不确定性的数学
第05篇:概率基础——不确定性的数学
写在前面:大家好,我是蓝皮怪!前几篇我们聊了统计学的基本概念、数据类型、描述性统计和数据可视化,今天我们要进入统计学的另一个重要基础——概率论。你有没有想过,为什么天气预报说"明天下雨概率60%“?为什么医生说"这个治疗方案成功率80%”?为什么保险公司能预估各种风险?这些都离不开概率的计算。今天,我们就来聊聊这个看似神秘,实则无处不在的"不确定性数学"。
🎯 这篇文章你能学到什么
- 概率的基本概念、公理和计算方法
- 条件概率与独立性的含义和应用
- 全概率公式与贝叶斯定理的实际应用
- 概率思维在生活中的应用与常见误区
1. 从生活说起:为什么要学概率?
你有没有遇到过这些场景:
🎲 玩游戏时:抽卡游戏中,“五星角色概率1.6%”,这意味着什么?
☔ 看天气预报时:“明天下雨概率70%”,到底是70%的地方会下雨,还是下雨的可能性是70%?
🏥 就医时:医生说"这个检查的假阳性率5%",如果你的检查结果是阳性,你该有多担心?
其实,概率已经渗透到我们生活的方方面面。它帮助我们在不确定的世界中做出更明智的决策,也是统计推断的理论基础。
2. 概率的核心概念与基础理论
2.1 什么是概率?
概率是对事件发生可能性的度量,用0到1之间的数值表示。概率为0表示事件不可能发生,概率为1表示事件必然发生。
概率可以从两个角度理解:
- 频率派观点:长期频率。比如抛硬币正面朝上的概率是0.5,意味着如果你抛很多次,大约一半的结果是正面。
- 贝叶斯观点:主观信念度。比如"明天下雨的概率是0.7",表示对这一事件的确信程度。
2.2 样本空间与事件
- 样本空间(S):实验中所有可能结果的集合。例如,抛一枚硬币的样本空间是S={正面,反面}。
- 事件(E):样本空间的子集,我们感兴趣的结果集合。例如,抛骰子得到偶数的事件是E={2,4,6}。
2.3 概率的公理(基本规则)
概率论建立在三个基本公理之上:
- 非负性:对任何事件A,P(A) ≥ 0
- 规范性:样本空间S的概率为1,即P(S) = 1
- 可加性:若事件A和B互斥(不能同时发生),则P(A∪B) = P(A) + P(B)
2.4 基本概率计算
对于等可能的结果(每个结果发生的可能性相同),概率计算公式为:
P ( A ) = 有利结果数 总结果数 P(A) = \frac{有利结果数}{总结果数} P(A)=总结果数有利结果数
【例子与代码】
(1)生活化例子:
从一副标准扑克牌(52张)中随机抽一张牌,求抽到红桃的概率。
- 有利结果数:13张红桃牌
- 总结果数:52张牌
- 概率 = 13/52 = 1/4 = 0.25
(2)Python代码实现:
# 计算从扑克牌中抽到红桃的概率
favorable_outcomes = 13 # 红桃牌数
total_outcomes = 52 # 总牌数
probability = favorable_outcomes / total_outcomes
print(f"抽到红桃的概率: {probability}")
输出:
抽到红桃的概率: 0.25
3. 条件概率与独立性
3.1 条件概率:已知部分信息后的概率
条件概率是指在事件B已经发生的条件下,事件A发生的概率,记作P(A|B)。
P ( A ∣ B ) = P ( A ∩ B ) P ( B ) P(A|B) = \frac{P(A \cap B)}{P(B)} P(A∣B)=P(B)P(A∩B)
其中,P(A∩B)表示事件A和B同时发生的概率。
【例子与代码】
(1)生活化例子:
某班级有60名学生,其中男生35名,女生25名。在这个班级中,喜欢数学的有30名学生,其中包括20名男生和10名女生。如果随机选择一名学生,已知这名学生是男生,求他喜欢数学的概率。
- 总学生数:60人
- 男生数:35人
- 喜欢数学的男生数:20人
- P(喜欢数学|男生) = 20/35 ≈ 0.571
(2)Python代码实现:
# 条件概率计算
total_students = 60
male_students = 35
math_loving_males = 20# 已知是男生,求喜欢数学的概率
p_math_given_male = math_loving_males / male_students
print(f"已知是男生,喜欢数学的概率: {p_math_given_male}")
输出:
已知是男生,喜欢数学的概率: 0.5714285714285714
3.2 独立性:事件之间没有影响
如果事件A的发生与事件B的发生互不影响,则称事件A和B是独立的。数学上,如果P(A|B) = P(A),或等价地,P(A∩B) = P(A)×P(B),则A和B独立。
【例子与代码】
(1)生活化例子:
连续抛两次硬币,第一次得到正面与第二次得到正面是否独立?
- 第一次得到正面的概率:P(A) = 0.5
- 第二次得到正面的概率:P(B) = 0.5
- 两次都得到正面的概率:P(A∩B) = 0.5 × 0.5 = 0.25
- 因为P(A∩B) = P(A)×P(B),所以这两个事件是独立的
(2)Python代码实现:
# 检验事件独立性
p_a = 0.5 # 第一次硬币正面概率
p_b = 0.5 # 第二次硬币正面概率
p_a_and_b = 0.25 # 两次都是正面的概率# 检验是否独立
is_independent = abs(p_a_and_b - p_a * p_b) < 1e-10
print(f"P(A∩B) = {p_a_and_b}, P(A)×P(B) = {p_a * p_b}")
print(f"这两个事件是否独立: {is_independent}")# 模拟硬币投掷,验证大数定律
import numpy as np
import matplotlib.pyplot as pltnp.random.seed(42)
n_trials = 1000 # 投掷次数
results = np.random.choice([0, 1], size=n_trials, p=[0.5, 0.5]) # 0表示反面,1表示正面
cumulative_mean = np.cumsum(results) / np.arange(1, n_trials + 1)# 绘制累积平均值随试验次数的变化
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falseplt.figure(figsize=(12, 7))
plt.plot(np.arange(1, n_trials + 1), cumulative_mean, 'b-', linewidth=2)
plt.axhline(y=0.5, color='r', linestyle='--', linewidth=2, label='理论概率 p=0.5')
plt.xscale('log')
plt.grid(True, alpha=0.3)
plt.title('硬币投掷模拟: 累积平均值随试验次数的变化', fontsize=16)
plt.xlabel('投掷次数', fontsize=14)
plt.ylabel('正面朝上比例', fontsize=14)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)# 添加文本说明
plt.text(10, 0.65, '随着试验次数增加,\n结果趋近于理论概率', fontsize=14, bbox=dict(facecolor='white', alpha=0.8))# 调整图例位置和大小
plt.legend(loc='lower right', fontsize=12)# 调整图表边距
plt.tight_layout()
plt.show()
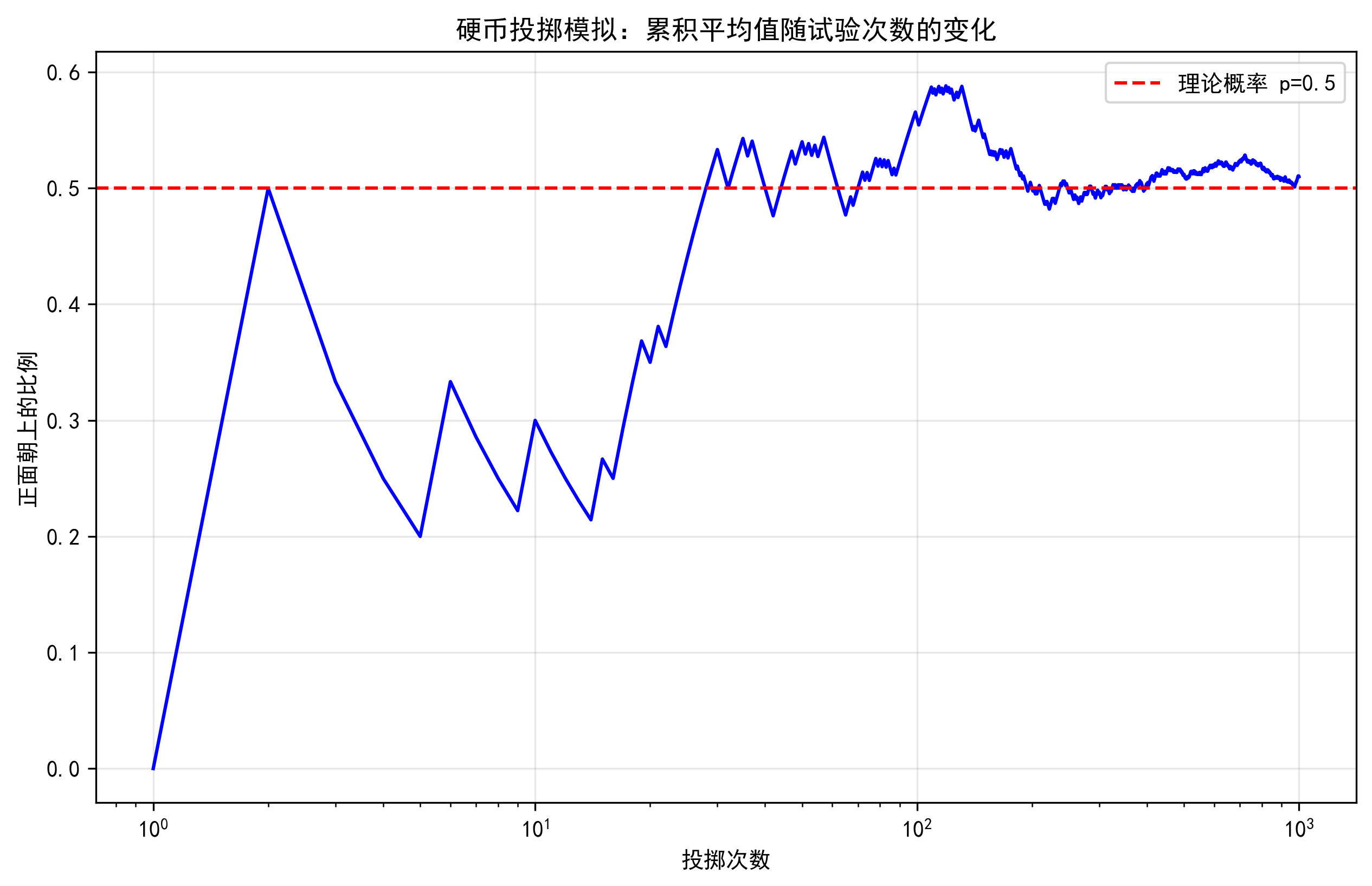
这个图展示了投掷硬币的累积平均结果如何随着试验次数的增加而趋近于理论概率0.5。图中可以看到,在试验次数较少时(如10次以内),结果可能与理论值有较大偏差;但随着试验次数增加到数百次后,结果稳定地接近理论值。这正是大数定律的直观体现,也说明了为什么我们不能从少量观察中得出可靠结论。
4. 全概率公式与贝叶斯定理
4.1 全概率公式:通过分割计算总概率
全概率公式用于计算事件A的概率,通过将样本空间分割成互斥的事件B₁, B₂, …, Bₙ,然后计算A在每个分割中的条件概率。
P ( A ) = ∑ i = 1 n P ( A ∣ B i ) × P ( B i ) P(A) = \sum_{i=1}^{n} P(A|B_i) \times P(B_i) P(A)=i=1∑nP(A∣Bi)×P(Bi)
【例子与代码】
(1)生活化例子:
某城市有三个区域,分别占总面积的50%、30%和20%。这三个区域下雨的概率分别为10%、20%和30%。求明天这个城市下雨的概率。
- 区域1:面积占比P(B₁) = 0.5,下雨概率P(A|B₁) = 0.1
- 区域2:面积占比P(B₂) = 0.3,下雨概率P(A|B₂) = 0.2
- 区域3:面积占比P(B₃) = 0.2,下雨概率P(A|B₃) = 0.3
- 全城下雨概率 = 0.5×0.1 + 0.3×0.2 + 0.2×0.3 = 0.05 + 0.06 + 0.06 = 0.17
(2)Python代码实现:
# 全概率公式计算
area_proportions = [0.5, 0.3, 0.2] # 三个区域面积占比
rain_probabilities = [0.1, 0.2, 0.3] # 各区域下雨概率# 计算全城下雨概率
total_rain_probability = sum(p_area * p_rain for p_area, p_rain in zip(area_proportions, rain_probabilities))
print(f"全城下雨概率: {total_rain_probability}")
输出:
全城下雨概率: 0.17
4.2 贝叶斯定理:逆向推理的利器
贝叶斯定理用于计算"逆向条件概率":已知结果,推测原因的概率。
P ( B ∣ A ) = P ( A ∣ B ) × P ( B ) P ( A ) P(B|A) = \frac{P(A|B) \times P(B)}{P(A)} P(B∣A)=P(A)P(A∣B)×P(B)
其中,P(B|A)是已知A发生后B的概率,P(A|B)是已知B发生后A的概率,P(B)是B的先验概率,P(A)是A的概率。
【例子与代码】
(1)生活化例子:
某种疾病在人群中的发病率为0.1%。有一种检测方法,对患病者的检测准确率为99%(敏感性),对健康人的检测准确率为98%(特异性)。如果某人检测结果为阳性,他真正患病的概率是多少?
-
患病概率(先验):P(D) = 0.001
-
健康概率:P(H) = 0.999
-
患病者检测阳性概率:P(+|D) = 0.99
-
健康人检测阳性概率:P(+|H) = 0.02(即1-特异性)
-
使用贝叶斯定理计算患病概率(后验):
P ( D ∣ + ) = P ( + ∣ D ) × P ( D ) P ( + ∣ D ) × P ( D ) + P ( + ∣ H ) × P ( H ) P(D|+) = \frac{P(+|D) \times P(D)}{P(+|D) \times P(D) + P(+|H) \times P(H)} P(D∣+)=P(+∣D)×P(D)+P(+∣H)×P(H)P(+∣D)×P(D)
P ( D ∣ + ) = 0.99 × 0.001 0.99 × 0.001 + 0.02 × 0.999 ≈ 0.047 P(D|+) = \frac{0.99 \times 0.001}{0.99 \times 0.001 + 0.02 \times 0.999} \approx 0.047 P(D∣+)=0.99×0.001+0.02×0.9990.99×0.001≈0.047
(2)Python代码实现:
# 贝叶斯定理计算
p_disease = 0.001 # 疾病先验概率
p_positive_given_disease = 0.99 # 患病者检测阳性概率
p_positive_given_healthy = 0.02 # 健康人检测阳性概率
p_healthy = 1 - p_disease # 健康概率# 计算检测阳性后患病概率
numerator = p_positive_given_disease * p_disease
denominator = p_positive_given_disease * p_disease + p_positive_given_healthy * p_healthy
p_disease_given_positive = numerator / denominatorprint(f"检测结果阳性时,真正患病的概率: {p_disease_given_positive:.4f}")# 贝叶斯定理可视化
import numpy as np
import matplotlib.pyplot as plt# 创建一个总人数为10000的模拟人群
total_population = 10000
disease_population = int(total_population * p_disease) # 患病人数
healthy_population = total_population - disease_population # 健康人数# 计算检测结果
true_positives = int(disease_population * p_positive_given_disease) # 患病且检测阳性
false_negatives = disease_population - true_positives # 患病但检测阴性
false_positives = int(healthy_population * p_positive_given_healthy) # 健康但检测阳性
true_negatives = healthy_population - false_positives # 健康且检测阴性# 检测阳性总人数
positive_tests = true_positives + false_positives# 创建柱状图数据
groups = ['患病人群', '健康人群', '检测阳性人群']
values = [disease_population, healthy_population, positive_tests]
subgroups = {'患病 (10人)': [disease_population, 0, 0],'健康 (9990人)': [0, healthy_population, 0],'检测阳性 (208人)': [0, 0, positive_tests],'真阳性 (9人)': [0, 0, true_positives],'假阳性 (199人)': [0, 0, false_positives]
}# 绘制贝叶斯定理可视化图
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falseplt.figure(figsize=(14, 8))
width = 0.5# 绘制主要人群
bottom = np.zeros(len(groups))
for label, height in subgroups.items():plt.bar(groups, height, width, label=label, bottom=bottom)bottom += height# 添加标题和标签
plt.title('贝叶斯定理可视化: 检测阳性时患病的概率', fontsize=16)
plt.ylabel('人数', fontsize=14)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)# 调整文本位置和大小
plt.text(1.5, 7500, f"阳性预测值 = 真阳性/检测阳性 = {true_positives}/{positive_tests} = {true_positives/positive_tests:.4f}", fontsize=14, bbox=dict(facecolor='white', alpha=0.8))# 调整图例位置和大小
plt.legend(loc='upper right', bbox_to_anchor=(1.15, 1), fontsize=12)# 调整图表边距
plt.tight_layout()
plt.show()
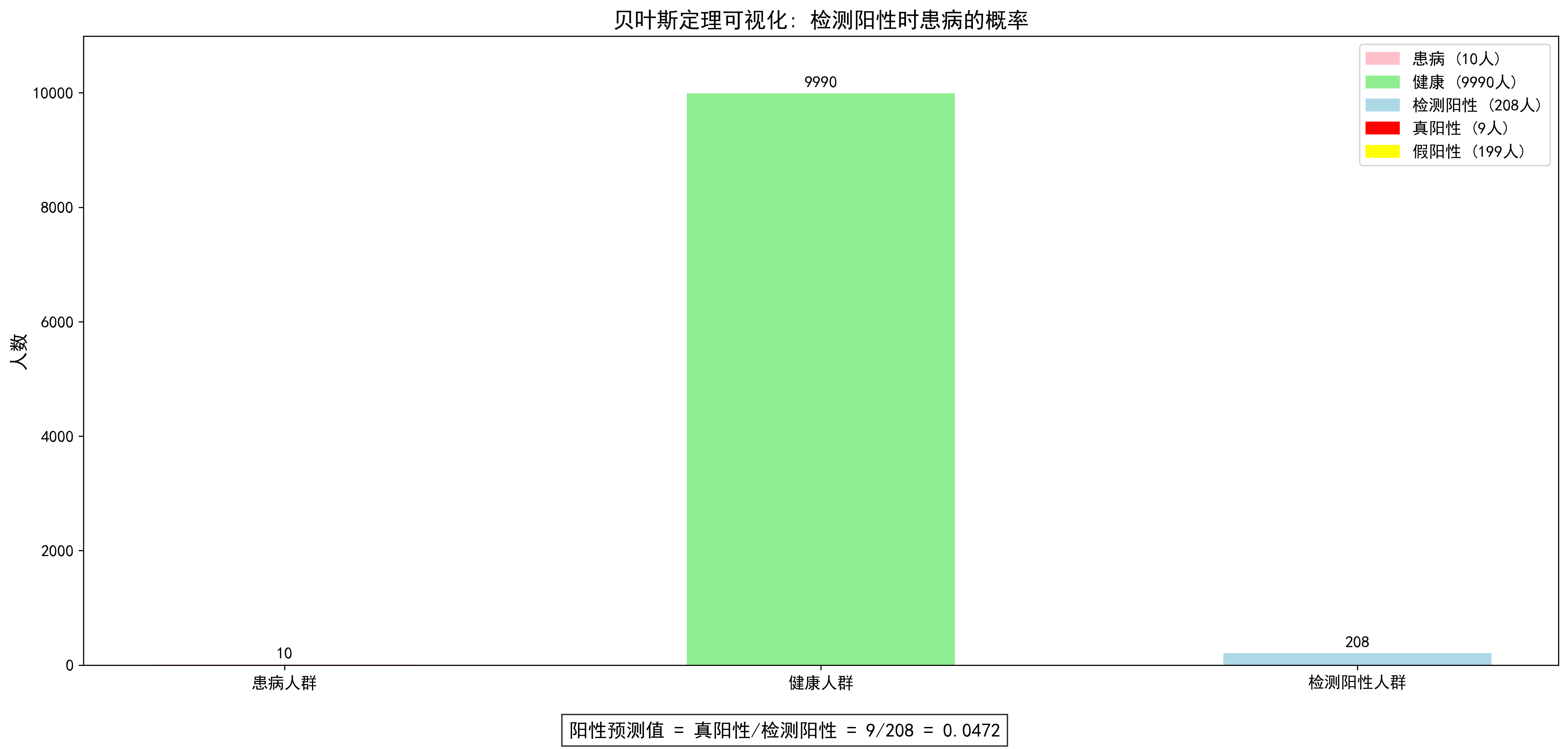
这个可视化图展示了贝叶斯定理在医学检测中的应用。在一个10000人的假设人群中,只有10人患病(发病率0.1%),而检测呈阳性的有208人。其中,真正患病且检测阳性的仅有9人,占所有阳性结果的4.72%。这直观地说明了为什么在罕见疾病的筛查中,即使是准确率很高的检测,阳性结果的预测价值也可能很低。这就是所谓的"基础概率谬误",提醒我们在解读检测结果时必须考虑疾病的基础发生率。
这个结果可能会让人惊讶:即使检测结果为阳性,真正患病的概率只有4.7%左右!这就是所谓的"基础概率谬误",我们会在后面的误区部分详细讨论。
5. 概率分布:随机变量的行为模式
5.1 随机变量与概率分布
随机变量是取决于随机试验结果的变量,可以是离散的(如骰子点数)或连续的(如身高)。概率分布描述了随机变量可能取值的概率。
常见的离散概率分布:
- 伯努利分布:描述单次试验成功或失败的概率分布
- 二项分布:描述n次独立重复试验中成功次数的概率分布
- 泊松分布:描述单位时间内随机事件发生次数的概率分布
常见的连续概率分布:
- 均匀分布:在给定区间内取值概率相等
- 正态分布:钟形曲线,自然界中最常见的分布
- 指数分布:描述事件之间等待时间的概率分布
5.2 二项分布示例
二项分布描述了n次独立重复试验中,成功次数k的概率分布。其概率质量函数为:
P ( X = k ) = ( n k ) p k ( 1 − p ) n − k P(X=k) = \binom{n}{k} p^k (1-p)^{n-k} P(X=k)=(kn)pk(1−p)n−k
其中,p是单次试验成功的概率, ( n k ) \binom{n}{k} (kn)是组合数。
【例子与代码】
(1)生活化例子:
投篮命中率为40%的球员,投10次球,恰好命中4次的概率是多少?
- n = 10(投球次数)
- p = 0.4(单次命中概率)
- k = 4(命中次数)
- P ( X = 4 ) = ( 10 4 ) 0.4 4 ( 1 − 0.4 ) 10 − 4 ≈ 0.25 P(X=4) = \binom{10}{4} 0.4^4 (1-0.4)^{10-4}\approx 0.25 P(X=4)=(410)0.44(1−0.4)10−4≈0.25
(2)Python代码实现:
import numpy as np
from scipy import stats# 二项分布计算
n = 10 # 投球次数
p = 0.4 # 单次命中概率
k = 4 # 命中次数# 使用scipy计算二项分布概率
probability = stats.binom.pmf(k, n, p)
print(f"投10次球恰好命中4次的概率: {probability:.4f}")# 绘制二项分布概率质量函数
import matplotlib.pyplot as plt# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsex = np.arange(0, n+1)
pmf = stats.binom.pmf(x, n, p)plt.figure(figsize=(12, 7))
plt.bar(x, pmf, alpha=0.7, width=0.6)
plt.plot(x, pmf, 'ro-', alpha=0.7, markersize=8)
plt.title(f'二项分布 (n={n}, p={p})', fontsize=16)
plt.xlabel('成功次数', fontsize=14)
plt.ylabel('概率', fontsize=14)
plt.xticks(x, fontsize=12)
plt.yticks(fontsize=12)
plt.grid(alpha=0.3)# 标记最大概率点
max_prob_idx = np.argmax(pmf)
plt.text(max_prob_idx-0.5, pmf[max_prob_idx]+0.02, f"P(X={max_prob_idx})={pmf[max_prob_idx]:.4f}", fontsize=14, bbox=dict(facecolor='white', alpha=0.8))# 调整图表边距
plt.tight_layout()
plt.show()
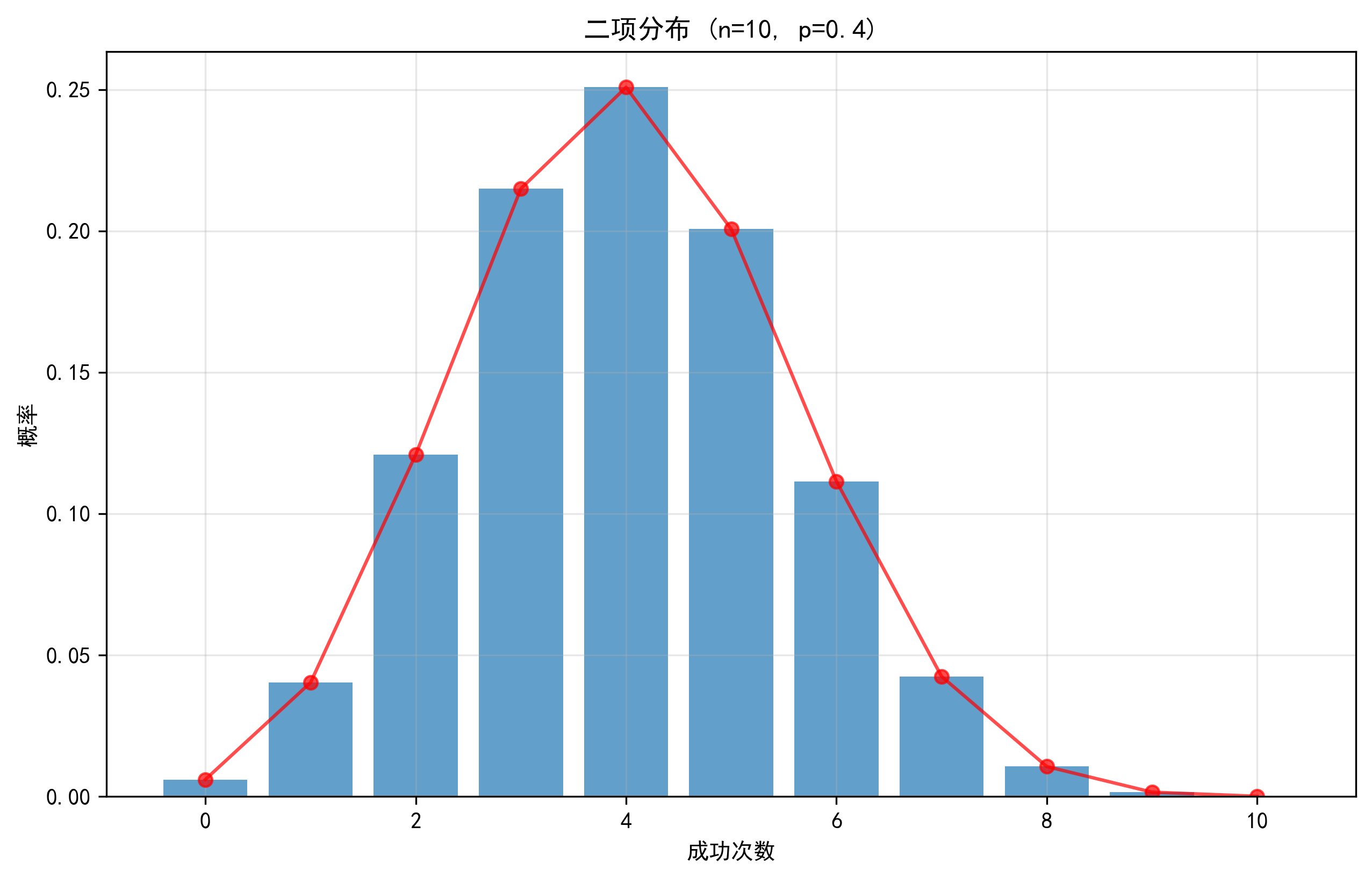
这个图展示了投10次球,命中次数的概率分布。可以看到,命中4次的概率约为0.251,是最可能发生的情况。
5.3 正态分布示例
正态分布(也称高斯分布)是连续型随机变量最重要的分布之一,其概率密度函数为:
f ( x ) = 1 σ 2 π e − ( x − μ ) 2 2 σ 2 f(x) = \frac{1}{\sigma\sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}} f(x)=σ2π1e−2σ2(x−μ)2
其中,μ是均值,σ是标准差。
【例子与代码】
(1)生活化例子:
某城市成年男性身高服从正态分布,均值μ=175cm,标准差σ=6cm。求身高超过185cm的男性比例。
(2)Python代码实现:
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt# 正态分布计算
mu = 175 # 均值
sigma = 6 # 标准差
x = 185 # 身高阈值# 计算超过185cm的比例
proportion = 1 - stats.norm.cdf(x, mu, sigma)
print(f"身高超过185cm的男性比例: {proportion:.4f}")# 绘制正态分布概率密度函数
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsex_range = np.linspace(mu - 4*sigma, mu + 4*sigma, 1000)
pdf = stats.norm.pdf(x_range, mu, sigma)plt.figure(figsize=(12, 7))
plt.plot(x_range, pdf, 'b-', linewidth=2)
plt.fill_between(x_range[x_range > 185], stats.norm.pdf(x_range[x_range > 185], mu, sigma), color='red', alpha=0.3)
plt.axvline(x=mu, color='green', linestyle='--', alpha=0.7, label=f'均值 μ={mu}')
plt.axvline(x=x, color='red', linestyle='--', alpha=0.7, label=f'阈值 x={x}')
plt.title(f'正态分布 (μ={mu}, σ={sigma})', fontsize=16)
plt.xlabel('身高 (cm)', fontsize=14)
plt.ylabel('概率密度', fontsize=14)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.grid(alpha=0.3)# 添加文本说明
plt.text(160, 0.055, f"超过185cm的比例: {proportion:.4%}", fontsize=14, bbox=dict(facecolor='white', alpha=0.8))# 调整图例位置和大小
plt.legend(loc='upper right', fontsize=12)# 调整图表边距
plt.tight_layout()
plt.show()
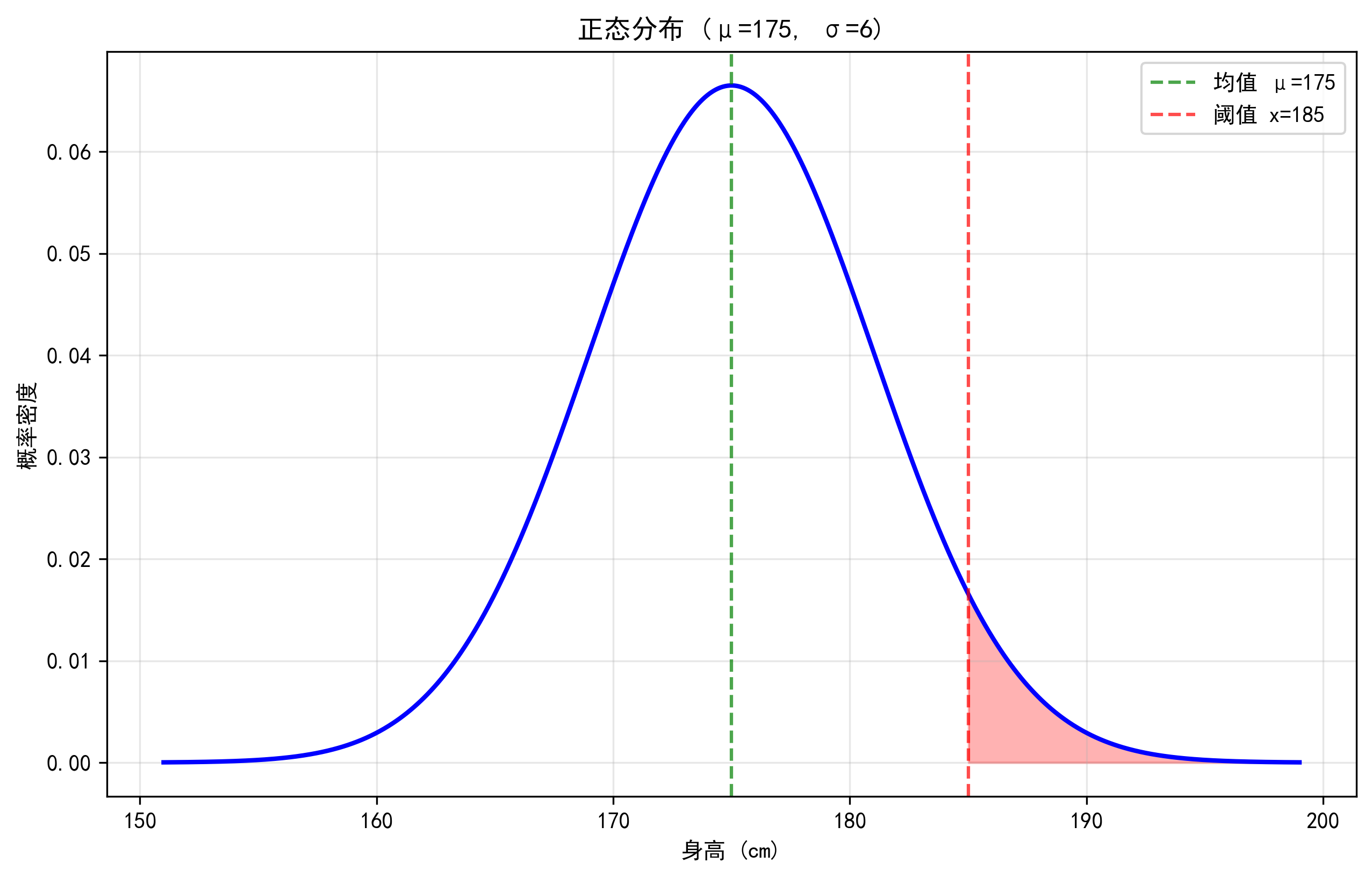
红色阴影部分表示身高超过185cm的比例,约为4.78%。
6. 别被这些误区骗了
❌ 误区1:赌徒谬误(Gambler’s Fallacy)
真相:在独立事件序列中,过去的结果不会影响未来事件的概率。这是由事件独立性的数学定义决定的。例如,公平硬币连续抛出9次正面后,第10次仍然有50%的概率是正面。这种误解源于人类对随机性的错误认知,即期望短期内的结果符合长期的概率分布,而忽视了随机波动的存在。
❌ 误区2:基础概率谬误(Base Rate Fallacy)
真相:在评估条件概率时,忽略先验概率(基础发生率)会导致严重的判断错误。如前面贝叶斯定理例子所示,对于罕见疾病(低基础发生率),即使检测准确性很高,阳性结果的预测价值仍然可能很低。这是因为根据贝叶斯定理,后验概率不仅取决于检测的灵敏度和特异性,还受基础发生率的显著影响。医学诊断、司法判决等领域尤其需要注意这一点。
❌ 误区3:代表性启发式偏误(Representativeness Heuristic Bias)
真相:人们倾向于基于对象与某类别的相似程度(代表性)来判断其属于该类别的概率,而忽略了先验概率和样本大小的影响。例如,描述一个"内向、细心、有条理"的人时,许多人会认为此人是图书管理员的概率高于农民,尽管农民在人口中的比例远高于图书管理员。这种判断违反了贝叶斯定理和概率的基本原则,因为它没有考虑基础概率(职业在人口中的分布比例)。
❌ 误区4:小数定律(Law of Small Numbers)
真相:小样本数据通常表现出较大的随机波动,其统计特性可能与大样本显著不同。根据大数定律,只有当样本量足够大时,样本统计量才会稳定地接近总体参数。例如,投掷硬币10次可能得到7次正面,这与理论概率0.5有明显偏差,但这属于正常的随机波动范围,不能据此推断硬币有问题。在科学研究和数据分析中,需要合理设定样本量并谨慎解读小样本结果。
❌ 误区5:概率混淆(Probability Confusion)
真相:条件概率P(A|B)与其逆条件概率P(B|A)是完全不同的概念,在数值上通常也不相等。例如,“患病者检测呈阳性的概率”(检测灵敏度)与"检测呈阳性者患病的概率"(检测阳性预测值)是不同的。前者是P(阳性|患病),后者是P(患病|阳性),两者之间的关系需通过贝叶斯定理转换,且受基础发生率影响。这种混淆在医学诊断、法庭证据评估等领域尤为常见且危险。
7. 实际应用建议
7.1 在日常决策中应用概率思维
- 考虑基础概率:在评估风险时,先了解事件的基础发生率
- 警惕小样本:不要从少量观察中得出结论
- 区分相关与因果:两个事件相关不一定有因果关系
- 量化不确定性:用概率表达不确定性,而不是简单的"会/不会"
7.2 在数据分析中正确使用概率
- 选择合适的概率模型:根据数据特性选择合适的概率分布
- 考虑条件概率:分析事件间的依赖关系
- 应用贝叶斯思想:结合先验知识和新证据,不断更新认知
- 警惕幸存者偏差:数据可能只来自"幸存"的样本,忽略了失败案例
8. 练习一下
基础题
- 从一副扑克牌中随机抽一张,求抽到黑桃A的概率。
- 投掷两个骰子,求点数之和为7的概率。
- 袋子里有5个红球和3个蓝球,随机取出2个球,求恰好取出1个红球和1个蓝球的概率。
思考题
- 一个家庭有两个孩子,已知其中至少有一个是女孩,求另一个也是女孩的概率。
- 某种疾病的发病率为1%,检测的敏感性为90%,特异性为95%。如果一个人检测结果为阳性,他真正患病的概率是多少?
- 为什么很多人对"检测阳性后患病概率"的直觉判断会出错?
动手题
- 用Python模拟投掷硬币1000次,验证正面朝上的概率是否接近0.5。
- 用Python生成并可视化二项分布和正态分布,观察参数变化对分布形状的影响。
- 实现一个简单的贝叶斯分类器,用于垃圾邮件过滤。
9. 重点回顾
- 概率基础:概率是对事件发生可能性的度量,取值范围为[0,1]
- 条件概率:P(A|B)表示在B发生的条件下A发生的概率
- 独立性:如果P(A∩B) = P(A)×P(B),则事件A和B是独立的
- 全概率公式:通过分割样本空间计算总概率
- 贝叶斯定理:结合先验概率和条件概率,计算后验概率
- 概率分布:描述随机变量可能取值的概率规律
- 常见误区:警惕赌徒谬误、基础概率谬误等认知陷阱
10. 下期预告
下一篇我们将深入探讨"随机变量:概率的载体"。你将学到:
- 随机变量的定义与类型
- 离散型随机变量的分布律与数字特征
- 连续型随机变量的概率密度函数与分布函数
- 随机变量的期望、方差及其性质
随机变量是连接概率论与统计学的桥梁,敬请期待!
📚 参考资料
- 盛骤等著《概率论与数理统计》,高等教育出版社
- 陈希孺著《概率论与数理统计》,中国科学技术大学出版社
- Sheldon Ross著《概率论基础》,人民邮电出版社
- 吴喜之著《统计学:从数据到结论》,中国统计出版社
写在最后:概率论是统计学的理论基础,也是理解不确定性世界的强大工具。希望这篇文章能帮助你建立概率思维,在充满不确定性的世界中做出更明智的决策。如果你有任何问题或想法,欢迎在评论区留言交流!让我们一起探索概率的奥秘!📊