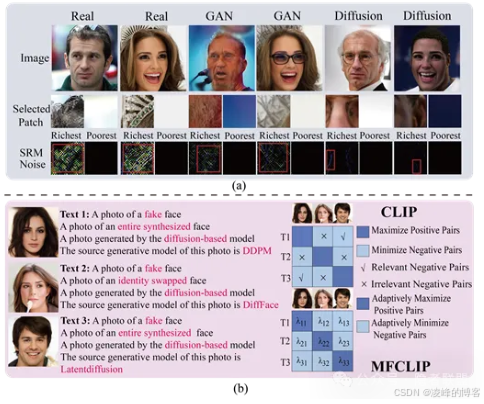
MFCLIP模型实现通用扩散人脸伪造检测
近年来,深度伪造(Deepfake)技术的迅猛发展带来了极大的安全隐患。从虚假新闻、明星换脸,到诈骗与政治操控,伪造人脸内容(Face Forgery)正在不断挑战我们的内容信任边界。在这一背景下,伪造人脸检测(Face Forgery Detection, FFD)技术正成为学术与产业界关注的焦点。
然而,现有FFD方法普遍依赖图像模态特征,并多针对GAN生成图像设计,对扩散模型(Diffusion Models)等先进生成范式的伪造样本识别效果不佳。同时,细粒度噪声、跨模态信息等潜在伪造线索尚未被有效挖掘。
为破解这些瓶颈,最近学习了一项来自齐鲁工业大学(山东省科学院)、大湾区大学、深圳大学、新加坡国立大学、天津理工大学等单位的最新研究提出了MFCLIP:Multi-modal Fine-grained CLIP,一种通用扩散人脸伪造检测模型(DFFD: Diffusion Face Forgery Detection)。该工作已被2025年**IEEE Transactions on Information Forensics and Security (TIFS)**正式接收。
论文信息:
Yaning Zhang, Tianyi Wang, Zitong Yu, et al.
MFCLIP: Multi-modal Fine-grained CLIP for Generalizable Diffusion Face Forgery Detection
IEEE Transactions on Information Forensics and Security, 2025
1. 深入噪声维度,揭示伪造痕迹
研究发现:真实与伪造人脸图像在SRM(高通滤波)噪声分布上存在显著差异,尤其是在“最丰富图像块”(Richest Patches)中,真实图像表现出更强的纹理与噪声保留,而伪造图像则表现为噪声衰减。这一发现为后续的伪造识别提供了基础。
2. 构建多模态伪造表征架构
MFCLIP模型引入三大核心模块:
-
多模态视觉编码器(MVE):由图像编码器与噪声编码器构成,分别提取空间纹理与局部噪声特征,并融合为统一伪造特征。
-
细粒度语言编码器(FLE)+文本生成器(FTG):借助层级提示(如部位、细节、生成方式等)捕捉伪造的语义特征,引导视觉对齐。
-
样本对注意力模块(SPA):灵感来自CLIP模型的对比学习机制,改进负样本处理,通过可学习的相关性权重机制,提升跨模态对齐鲁棒性。
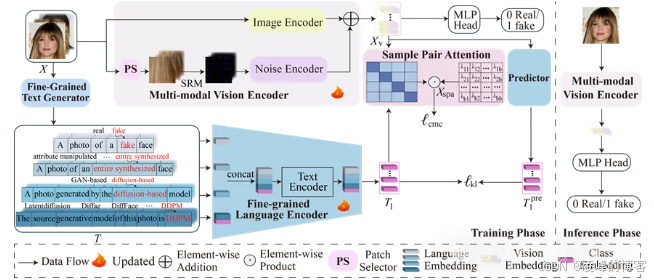
以上为论文中的模型框架图
3. 高扩展性、可解释性与强泛化能力
MFCLIP不仅支持插拔式SPA模块集成,还可视化展示视觉与文本关注区域,具备良好的可解释性。大量实验表明,模型在跨生成器、跨伪造方式、跨数据集等复杂场景下表现出极强的泛化能力,显著优于当前FFD主流模型。
模型结构简述
-
FTG → FLE:生成并编码多粒度文本提示(如“眉毛不自然”、“光影不一致”等),提供伪造语义引导。
-
图像块选择器:定位图像中最具纹理信息的区域,挖掘局部伪造痕迹。
-
MVE模块:双分支提取图像纹理与SRM噪声特征,并融合生成伪造特征表示。
-
SPA模块:增强负样本之间的语义对比,提升跨模态相似性衡量的稳定性与准确性。
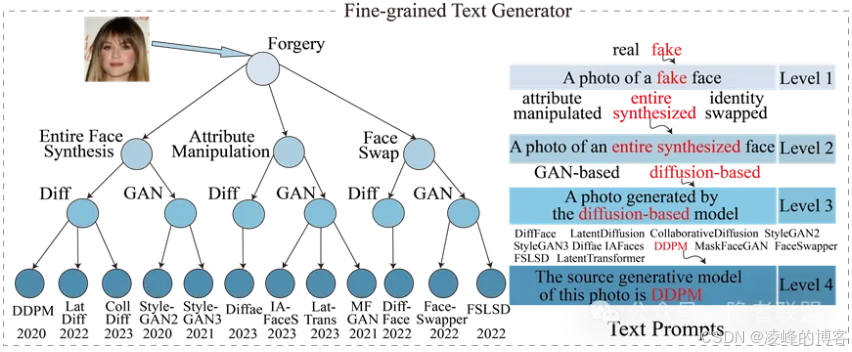
细粒度文本生成器示意图
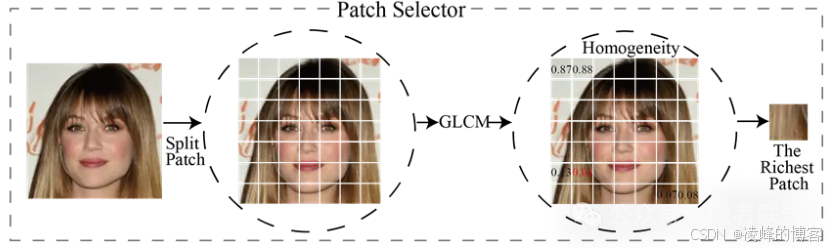
图像块选择器示意图
实验结果
在多个主流Deepfake数据集(如FF++、DFDC、WildDeepfake等)上的实证结果显示,MFCLIP在以下方面均有显著提升:
-
检测精度(Accuracy)提升
-
跨域鲁棒性更强
-
Diffusion模型样本识别性能更优
-
可视化伪造区域定位更准确