FlashAttention:突破Transformer内存瓶颈的革命性注意力优化技术
Transformer模型的内存困境
在当今人工智能领域,Transformer架构已成为自然语言处理、计算机视觉等任务的事实标准。然而,随着模型规模的不断扩大和序列长度的持续增长,传统注意力机制暴露出严重的内存瓶颈问题。标准注意力机制的时间和内存复杂度与序列长度呈平方关系(),这极大限制了Transformer模型处理长序列的能力(扩展阅读:初探 Transformer-CSDN博客、Transformer 是未来的技术吗?-CSDN博客)。
FlashAttention应运而生,它是一种IO感知的精确注意力算法,通过重新设计注意力计算流程,显著减少了GPU内存层次之间的数据传输,实现了在不牺牲模型质量的前提下大幅提升计算效率。这项由斯坦福大学Tri Dao等人提出的技术,已成为当今大模型训练和推理的核心组件之一,被GPT-4、Llama等顶尖模型采用(扩展阅读:初探注意力机制-CSDN博客、Transformer 中的注意力机制很优秀吗?-CSDN博客)。
本文将深入剖析FlashAttention的技术原理、实现细节及其与传统注意力机制的差异,并通过代码示例和性能对比展示其卓越优势,最后探讨该技术的未来发展方向。
FlashAttention产生的背景与动机
传统注意力机制的内存瓶颈
传统Transformer模型中的自注意力机制存在两个主要性能瓶颈:内存占用高和计算效率低。当处理长度为N的序列时,标准注意力需要存储一个N×N的注意力矩阵,这对于长序列任务(如处理长文档、高分辨率图像或视频)来说,内存需求会迅速变得不可承受。例如,处理一个长度为64K的序列时,单精度浮点数的注意力矩阵将占用约16GB内存,这已经接近高端GPU的显存容量。
更严重的是,标准注意力实现中存在大量的内存读写操作(扩展阅读:来聊聊Q、K、V的计算-CSDN博客)。计算流程通常包括:从高带宽内存(HBM)加载Q、K矩阵;计算并存储;从HBM重新加载S计算softmax得到P;再从HBM加载P和V计算最终输出O1。这种反复的HBM访问成为性能的主要瓶颈,因为现代GPU的计算单元增速远超内存带宽增速。
GPU内存层次结构的利用不足
现代GPU具有复杂的内存层次结构(扩展阅读:聊聊 GPU 与 CPU的那些事-CSDN博客),从快速的片上SRAM(静态随机存取存储器)到相对较慢的高带宽内存(HBM)。以NVIDIA A100为例,其HBM带宽为1.5-2.0TB/s,而SRAM带宽估计约为19TB/s,速度快了近10倍,但容量小得多(每108个流处理器共享192KB SRAM)。传统注意力实现未能有效利用这一层次结构,大部分计算依赖HBM而非更快的SRAM。
近似注意力方法的局限性
为缓解内存问题,先前的研究提出了各种近似注意力方法,如稀疏注意力、低秩近似等。但这些方法往往需要在模型质量和计算效率之间做出妥协,且许多方法在实际硬件上未能实现预期的速度提升,因为它们主要关注减少FLOPs(浮点运算次数)而忽视了内存访问(IO)开销。
FlashAttention的核心技术原理
整体架构与设计思想
FlashAttention是一种硬件感知的精确注意力算法,其核心思想是通过分块计算和核融合技术,最大限度地减少GPU HBM和SRAM之间的内存读写次数。与标准注意力不同,FlashAttention将整个注意力计算过程融合到单个CUDA核中,避免存储庞大的中间注意力矩阵,将显存复杂度从降至
。
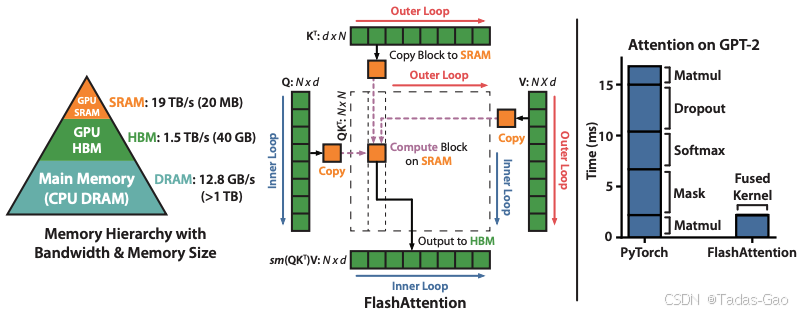
该技术的关键创新点包括:
-
分块计算(Tiling):将大型矩阵运算分解为适合SRAM的小块操作
-
重计算(Recomputation):在反向传播时重新计算注意力矩阵而非存储
-
核融合(Kernel Fusion):将多个操作融合为单一GPU核,减少内存访问
-
IO复杂度优化:精心设计算法以减少HBM访问次数
分块计算与内存高效管理
FlashAttention的核心在于将输入序列分成小块进行处理。具体来说,它将Q、K、V矩阵划分为多个较小的块,每次只将一个小块从HBM加载到SRAM中计算。这种分块策略面临的主要挑战是softmax操作需要全局信息(需要知道所有元素的指数和进行归一化),而分块后无法直接获得完整的行信息。
为解决这一问题,FlashAttention采用了分块softmax技术。它维护两个额外的统计量:每行的最大值和指数和
。在处理每个块时,它先计算当前块的局部softmax,然后与之前块的统计量结合,逐步更新全局的softmax结果。具体公式如下:
对于向量分为
个块
,全局softmax可表示为:
其中是全局最大值,
是第
块的最大值,
是第
块的指数和。
这种技术允许FlashAttention在仅使用SRAM的情况下,通过迭代方式计算出精确的softmax结果,而无需存储完整的N×N注意力矩阵。
前向传播流程
FlashAttention的前向传播可分为以下步骤:
初始化:将输出矩阵O、统计量l(指数和)和m(最大值)初始化为0或-∞
外循环:遍历K和V的块,每次将一个块从HBM加载到SRAM
内循环:对于每个K、V块,遍历Q的块:
- 加载
和
块到SRAM
- 计算当前块的注意力分数
- 计算当前块的局部
- 更新统计量
和
- 重新缩放之前的结果并累加当前块的贡献
写回结果:将更新后的写回HBM
这一流程确保所有中间计算都在SRAM中完成,仅将最终结果写回HBM,大幅减少了内存访问次数。
反向传播优化
传统注意力实现需要在反向传播时使用前向传播中计算的N×N注意力矩阵P和S。FlashAttention通过重计算技术避免了存储这些大型矩阵。在前向传播时,它仅存储统计量m和l,在反向传播时,利用这些统计量在SRAM中快速重新计算注意力矩阵的分块。
虽然这会增加一些计算量(FLOPs),但由于避免了大量的HBM访问,整体运行时间反而显著减少。实验表明,FlashAttention的前向+后向传递时间比标准实现快4.7倍。
FlashAttention与传统注意力的对比
计算流程差异
标准注意力实现通常遵循以下步骤:
# 标准注意力实现
def attention(Q, K, V):d_k = Q.size(-1)scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(d_k))attention = torch.softmax(scores, dim=-1)output = torch.matmul(attention, V)return output这个过程需要在HBM中存储完整的注意力矩阵,并涉及多次内存读写:
-
从HBM加载Q、K,计算
,将S写回HBM
-
从HBM加载S,计算
,将P写回HBM
-
从HBM加载P、V,计算
,将O写回HBM
相比之下,FlashAttention的实现(简化版)如下:

# FlashAttention简化实现
def flash_attention(Q, K, V, block_size=32):batch_size, seq_len, hidden_dim = Q.size()d_k = hidden_dimoutput = torch.zeros_like(Q)l = torch.zeros(batch_size, seq_len, 1) # 存储指数和m = torch.full((batch_size, seq_len, 1), -float('inf')) # 存储最大值for j in range(0, seq_len, block_size):K_j = K[:, j:j+block_size, :]V_j = V[:, j:j+block_size, :]for i in range(0, seq_len, block_size):Q_i = Q[:, i:i+block_size, :]O_i = output[:, i:i+block_size, :]m_i = m[:, i:i+block_size, :]l_i = l[:, i:i+block_size, :]# 计算当前块的注意力分数S_ij = torch.matmul(Q_i, K_j.transpose(-2, -1)) / torch.sqrt(torch.tensor(d_k))# 计算当前块的局部softmaxm_ij = torch.max(S_ij, dim=-1, keepdim=True)[0]m_new = torch.maximum(m_i, m_ij)P_ij = torch.exp(S_ij - m_new)l_ij = torch.sum(P_ij, dim=-1, keepdim=True)l_new = torch.exp(m_i - m_new) * l_i + l_ij# 更新输出O_i = (l_i * torch.exp(m_i - m_new) * O_i + torch.matmul(P_ij, V_j)# 更新统计量和输出m[:, i:i+block_size, :] = m_newl[:, i:i+block_size, :] = l_newoutput[:, i:i+block_size, :] = O_i / l_newreturn output性能对比分析
FlashAttention与传统注意力在多个维度上存在显著差异:
| 特性 | 传统注意力 | FlashAttention |
|---|---|---|
| 内存复杂度 | O(N²) | O(N) |
| HBM访问次数 | O(N²d) | O(N²d²/M),M为SRAM大小 |
| 中间矩阵存储 | 需要存储S和P | 不存储中间矩阵 |
| 计算精度 | 精确 | 精确 |
| 实现复杂度 | 简单 | 复杂,需要CUDA核优化 |
| 适用序列长度 | 短序列(≤1K) | 长序列(可达64K+) |
| 主要瓶颈 | 内存带宽 | 计算单元 |
从实际性能看,FlashAttention在GPT-2模型上比PyTorch标准实现快7.6倍,端到端训练(前向+后向)速度快4.7倍。在A100 GPU上,FlashAttention-2甚至能达到标准注意力9倍的加速比。
数值稳定性优势
传统softmax在长序列上容易遇到数值溢出问题,因为指数函数增长极快。FlashAttention采用safe softmax技术,在处理每个块时都减去最大值,确保数值稳定性。这种方法不仅解决了溢出问题,还能处理比float32/bfloat16表示范围更大的输入值。
FlashAttention的演进与优化
FlashAttention-2的主要改进
FlashAttention发布一年后,其作者Tri Dao推出了重大升级版本FlashAttention-2,在算法、并行化和工作分区等方面进行了显著优化。主要改进包括:
-
减少非矩阵乘法运算:现代GPU有专门的矩阵乘法单元(如Tensor Core),非矩阵乘法运算(如softmax)相对较慢。FlashAttention-2重写了在线softmax技巧,减少重新缩放操作和边界检查。
-
改进并行化策略:FlashAttention-1在batch size和头数量上并行化,当这些维度较小时(如长序列情况)GPU利用率低。FlashAttention-2增加了序列长度维度的并行化,更好地利用GPU多处理器。
-
优化工作分区:改进了线程块内warp之间的工作划分,减少同步和共享内存读写。将Q而非K/V分割到不同warp,避免中间结果的通信。
-
支持更大头维度:头维度从128扩展到256,支持更多模型如GPT-J、StableDiffusion 1.x等。
-
支持多查询注意力(MQA)和分组查询注意力(GQA):这些变体可减少推理时KV缓存大小,提高推理吞吐量(扩展阅读:MTP、MoE还是 GRPO 带来了 DeepSeek 的一夜爆火?-CSDN博客)。
这些优化使FlashAttention-2在A100 GPU上达到230 TFLOPs/s,是前一代的2倍,是PyTorch标准实现的9倍。在端到端GPT类模型训练中,模型FLOPs利用率高达72%,相比优化良好的基线实现仍有1.3倍加速。
FlashAttention-3的新特性
针对新一代Hopper架构GPU(如H100),FlashAttention-3进一步优化:
-
利用WGMMA张量核心:比Ampere架构更高的矩阵乘法吞吐量
-
使用TMA(张量内存加速器):加速全局内存与共享内存间数据传输
-
支持FP8精度:使张量核心吞吐量翻倍
-
生产-消费异步流水线:重叠计算与内存操作
-
隐藏softmax延迟:将softmax与GEMM操作交错执行
这些优化使FlashAttention-3在H100上实现了更高的计算利用率,支持更长的上下文长度。
Flash-Decoding:推理优化
针对大模型推理场景,FlashAttention团队提出了Flash-Decoding技术,专门优化解码阶段的注意力计算。关键创新是在键/值序列长度上新增并行维度,即使batch size很小时也能充分利用GPU。
Flash-Decoding分为三步:
-
将K/V分成小块
-
并行计算查询与每个K/V块的注意力
-
归约所有块的结果得到最终输出
在CodeLlama-34B上的测试显示,对于64K长序列,Flash-Decoding比标准实现快8倍,比FlashAttention v2快50倍。这使得处理超长上下文(如整本小说或大型代码库)变得可行。
实际应用与性能表现
在主流模型中的应用效果
FlashAttention系列技术已被广泛应用于各种大型Transformer模型,带来了显著的性能提升:
-
BERT-large(序列长度512):相比MLPerf 1.1训练速度记录提升15%
-
GPT-2(序列长度1K):训练速度提升3倍
-
长范围竞技场(序列长度1K-4K):速度提升2.4倍
-
Path-X挑战(序列长度16K):准确率61.4%,首次超越偶然表现
-
Path-256(序列长度64K):准确率63.1%
这些提升不仅加快了训练速度,还使模型能够处理更长的上下文,从而生成更高质量的输出。例如,GPT-2的困惑度提升了0.7点,长文档分类准确率提升了6.4点。
端到端训练加速
FlashAttention对整体模型训练速度的提升同样显著。在GPT类模型的端到端训练中:
-
FlashAttention-1:比优化基线快2-4倍
-
FlashAttention-2:达到225 TFLOPs/s(72%模型FLOPs利用率),比FlashAttention-1再快1.3倍
-
在H100 GPU上:运行相同实现可达335 TFLOPs/s(不使用特殊硬件指令)
这意味着使用FlashAttention-2可以用相同的成本训练上下文长度翻倍的模型,或者用更少的时间和资源训练相同规模的模型。
长上下文处理能力
FlashAttention最显著的优势之一是支持超长序列处理:
-
传统注意力:通常限于1K-2K长度(如原始GPT-3)
-
FlashAttention:支持16K-64K长度(Path-X、Path-256)
-
结合Flash-Decoding:在推理时高效处理64K+序列
这使得许多新应用成为可能,如:
-
长文档理解和摘要(书籍、法律文件)
-
高分辨率图像和视频处理
-
整个代码库的分析和生成
-
长对话历史维护
未来发展与研究方向
硬件适配优化
随着GPU架构持续演进,FlashAttention需要不断适配新硬件特性:
-
充分利用新一代Tensor Core:如Hopper的WGMMA和TMA
-
低精度计算支持:FP8、INT8等格式的优化
-
多GPU扩展:跨节点长序列注意力计算
-
其他AI加速器支持:如TPU、AMD GPU等
算法进一步优化
尽管已取得显著进展,FlashAttention仍有优化空间:
-
逼近理论峰值FLOPs:当前H100上仅达到35%
-
动态序列长度支持:更灵活处理变长输入
-
稀疏注意力结合:与稀疏化、低秩近似等技术互补
-
自适应块大小选择:根据输入特征动态调整
应用场景扩展
FlashAttention技术可进一步扩展到更广泛的应用场景:
-
多模态模型:统一处理文本、图像、音频的长序列
-
图神经网络:大型图结构的注意力计算优化
-
科学计算:长程依赖的物理模拟
-
边缘设备:内存受限环境下的部署优化
结论
FlashAttention代表了注意力机制优化的重大突破,通过深入理解硬件特性和精心设计算法,成功解决了Transformer模型的内存瓶颈问题。其核心创新——分块计算、核融合和IO优化——在不改变数学模型的前提下,大幅提升了注意力计算的效率和可扩展性。
从FlashAttention到FlashAttention-2和Flash-Decoding,这一技术系列持续演进,推动了大模型处理更长上下文的能力,为AI应用开辟了新可能。随着模型规模不断扩大和序列长度持续增长,FlashAttention相关技术将继续发挥关键作用,成为训练和部署大型Transformer模型的基石之一。
未来,随着硬件架构的发展和算法创新的结合,我们有望看到更多突破性的注意力优化技术出现,进一步释放Transformer架构的潜力,推动人工智能向更强大、更高效的方向发展。