篇章五 系统性能优化——资源优化——CPU优化(1)
资源优化策略
CPU优化:优化算法,减少不必要的计算。
内存优化:合理管理内存,避免内存泄漏。
网络优化:优化网络配置,减少网络延迟。
资源优化示例
CPU优化:使用多线程或线程池来处理并发请求。
内存优化:使用内存池技术,减少频繁的内存分配和回收。
网络优化:使用高效的网络协议(如HTTP/2、WebSocket)来减少网络延迟。
以下是针对高并发场景下CPU优化的完整技术方案,包含多线程与线程池的深度实践指南
目录
1.CPU优化
1.1 线程池架构设计
1.2 核心优化策略
1. 线程池参数黄金法则
1.1 为什么这样配置?
1.2 示例:根据最优线程数公式调整配置
1.3 总结
2. 异步非阻塞改造
2.1 异步非阻塞改造的目的
2.2 WebFlux 响应式编程示例
2.3 与 CPU 优化的关系
1.什么是IO
1.1 网络通信
1.2 本地文件操作
1.3 数据库操作
1.4 其他外部设备
2.IO操作的类型和特点
2.1 同步IO
2.2 异步IO
2.3 阻塞和非阻塞
2.4 异步处理框架
2.5 使用WebFlux而不用CompletableFuture的原因
1.WebFlux 的优势
1.1 完整的响应式编程支持
1.2 集成 Spring 生态系统
2). 什么是Spring Data
2.1 统一的 Repository 抽象
2.2 自动化 CRUD 操作:
2.3 声明式查询方法:
2.4 基于注解的查询:
2.5 分页和排序支持:
2.6 对多种数据存储技术的支持:
2.7 减少样板代码:
2.8 典型应用场景:
3).为什么用MyBatis而不用Spring Data
3.1 核心差异对比
3.2 选择MyBatis的核心原因
3.3 Spring Data JPA的适用场景
4.非阻塞 I/O
5).Netty、Tomcat与Servlet
5.1 核心概念与定位
5.2 Netty 与 Tomcat 核心区别
5.3三者技术联系
5.4 如何选择
6. 错误处理和回压支持
7.CompletableFuture 的局限性
8.选择 CompletableFuture 的场景
9.总结
2.6 消息队列与这种异步处理的区别
1.为什么在某些场景下不使用消息队列?
1.1 消息队列主要用于以下场景:
1.2 WebFlux 和 Servlet 3.0 异步支持的适用场景
1.3 为什么在某些场景下不使用消息队列
1.4 总结
2.Servlet中的DeferredResult中为什么会有CompletableFuture
3.WebAsyncTask为什么没有用 CompletableFuture
3.1 总结
2.7 在 Spring Boot 中,使用 Servlet 3.0 或 WebFlux
1.使用 Servlet 3.0
2.使用 WebFlux
3.如何选择
4.总结
2.8 Servlet 3.0 和 WebFlux 通常不能直接一起使用
1.为什么不能一起使用?
2.如何解决冲突?
2.1 方案一:明确指定应用类型
2.2 方案二:分离配置类
2.3 方案三:适配器模式
2.4 方案四:维护兼容性中间件
3.总结
2.9 响应式编程与传统编程的对比
1.区别
2.响应式编程的典型应用场景
3.实际应用注意事项
4. 理解数据流、操作符和线程模型
4.1 数据流(Reactive Streams)
4.2 操作符(Operators)
4.3 线程模型(Schedulers)
5. 线程池选了Schedulers.boundedElastic()
5.1 关于线程池选择的 "矛盾" 解释
5.2 最佳实践建议
2.10 回调(Callback)与监听(Listener)的区别解析
1.回调(Callback)
1.1 定义:
1.2 特点:
1.3 同步回调
1.4 异步回调
1.5 在异步回调机制中,主线程和工作线程的执行关系取决于具体实现方式
2.监听
2.1 定义
2.2 特点
2.3 示例
2.4 Java 中两者的核心区别
2.5 Java 中的典型应用场景
2.6 高级对比:Lambda 表达式与函数式接口
2.7 总结
3. 监听系统
3.1 监听系统中的线程管理
3.2.异步服务
3.3 监听系统
3.4 主线程(事件循环线程)
3.5 输出示例
3.6 理解监听系统中的线程管理
3.7 总结
1.CPU优化
1.1 线程池架构设计
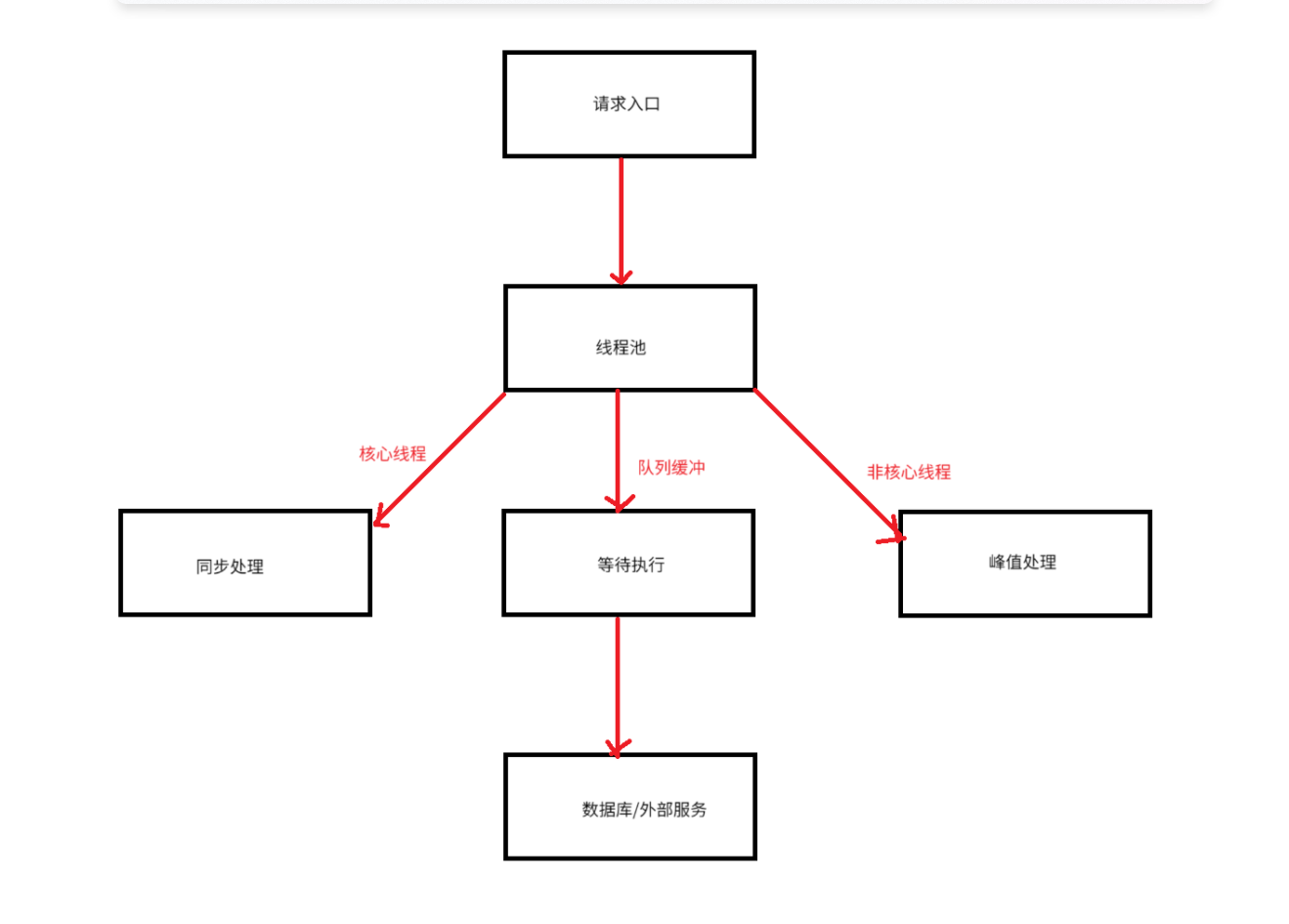
1.2 核心优化策略
1. 线程池参数黄金法则
如果 I/O 阻塞时间较长,可以适当增加线程数,以提高系统的吞吐量。
// 最优线程数计算公式 (N为CPU核心数)
int optimalThreads = N * (1 + WT/ST)
// WT: 平均等待时间(如IO阻塞)
// ST: 平均计算时间// Spring Boot默认配置调优
@Bean
public ThreadPoolTaskExecutor taskExecutor() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();executor.setCorePoolSize(Runtime.getRuntime().availableProcessors());executor.setMaxPoolSize(64);executor.setQueueCapacity(1000);executor.setKeepAliveSeconds(60);executor.setThreadNamePrefix("api-worker-");executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());executor.initialize();return executor;
}配置参数解析setCorePoolSize:
核心线程数。这是线程池中始终保持的线程数量。
设置为 Runtime.getRuntime().availableProcessors(),即 CPU 核心数。这是基于 CPU 核心数的默认值,适用于计算密集型任务。setMaxPoolSize:
最大线程数。这是线程池中允许的最大线程数量。
设置为 64,表示在高并发情况下,线程池最多可以扩展到 64 个线程。setQueueCapacity:
任务队列容量。当核心线程数已满时,新任务会被放入任务队列中。
设置为 1000,表示任务队列最多可以容纳 1000 个任务。setKeepAliveSeconds:
非核心线程的空闲存活时间。如果非核心线程在指定时间内没有任务可执行,它们将被回收。
设置为 60 秒,表示非核心线程在空闲 60 秒后会被回收。setThreadNamePrefix:
线程名称前缀。用于标识线程池中的线程。
设置为 "api-worker-",表示线程名称将以 "api-worker-" 开头。setRejectedExecutionHandler:
拒绝执行处理器。当任务队列已满且线程池已达到最大线程数时,新任务将被拒绝。
使用 ThreadPoolExecutor.CallerRunsPolicy(),表示如果任务被拒绝,将在调用者的线程中执行任务。initialize:
初始化线程池。确保线程池在启动时立即初始化。
这个方法是用于配置 Spring Boot 中的线程池(
ThreadPoolTaskExecutor),以优化多线程任务的执行。线程池是 Java 中用于管理线程的工具,可以提高系统的性能和资源利用率。通过合理配置线程池的参数,可以确保系统在高并发场景下能够高效地处理任务。
1.1 为什么这样配置?
-
核心线程数:
-
核心线程数设置为 CPU 核心数,适用于计算密集型任务。如果任务主要是 I/O 阻塞,可以根据公式适当增加线程数。
-
-
最大线程数:
-
最大线程数设置为 64,这是一个合理的上限,可以应对高并发场景,但不会过度消耗系统资源。
-
-
任务队列容量:
-
任务队列容量设置为 1000,可以缓冲一定量的任务,避免任务直接被拒绝。
-
-
非核心线程的空闲存活时间:
-
设置为 60 秒,可以快速回收空闲线程,节省系统资源。
-
-
拒绝执行处理器:
-
使用
CallerRunsPolicy,确保任务不会被丢弃,而是由调用者线程执行,避免任务丢失。
-
1.2 示例:根据最优线程数公式调整配置
假设你的应用主要是 I/O 阻塞任务,平均 I/O 阻塞时间为 100 毫秒,平均计算时间为 1 毫秒。假设 CPU 核心数为 8。
根据公式: optimalThreads=8×(1+1100)=8×101=808
显然,808 个线程可能过多,可以适当调整。例如,将最大线程数设置为 128 或 256,根据实际需求调整。
@Bean
public ThreadPoolTaskExecutor taskExecutor() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();executor.setCorePoolSize(Runtime.getRuntime().availableProcessors());executor.setMaxPoolSize(128); // 调整最大线程数executor.setQueueCapacity(1000);executor.setKeepAliveSeconds(60);executor.setThreadNamePrefix("api-worker-");executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());executor.initialize();return executor;
}1.3 总结
这个方法用于配置 Spring Boot 的线程池,以优化多线程任务的执行。通过合理设置核心线程数、最大线程数、任务队列容量等参数,可以确保系统在高并发场景下能够高效地处理任务。根据任务的性质(计算密集型或 I/O 阻塞型),可以使用最优线程数公式调整线程池的配置。
2. 异步非阻塞改造
2.1 异步非阻塞改造的目的
异步非阻塞改造的主要目的是提高系统的并发处理能力和响应速度,特别是在高并发场景下。通过减少线程阻塞和资源等待时间,系统可以更高效地处理更多的请求。
2.2 WebFlux 响应式编程示例
@GetMapping("/users/{id}")
public Mono<User> getUser(@PathVariable String id) {return Mono.fromCallable(() -> userService.getById(id)).subscribeOn(Schedulers.boundedElastic()) // 阻塞操作专用线程池.timeout(Duration.ofSeconds(3));
}代码解析
Mono.fromCallable:
将一个阻塞操作(如 userService.getById(id))包装为一个响应式流。fromCallable 方法允许你将同步的阻塞代码转换为响应式流。
subscribeOn(Schedulers.boundedElastic()):指定在哪个线程池中执行阻塞操作。
boundedElastic 是一个动态调整大小的线程池,适用于处理阻塞任务。
这样可以避免阻塞操作阻塞主线程,从而提高系统的响应速度。timeout(Duration.ofSeconds(3)):
设置超时时间,如果操作在 3 秒内没有完成,将自动取消。2.3 与 CPU 优化的关系
虽然这些代码主要关注的是异步处理和非阻塞 I/O,但它们也与 CPU 优化有间接关系:
减少线程阻塞:
通过将阻塞操作移到后台线程池,主线程可以继续处理其他请求,从而提高 CPU 的利用率。
减少线程阻塞可以避免 CPU 空闲等待,提高系统的整体性能。
动态调整线程池大小:
使用如
boundedElastic这样的线程池,可以根据实际负载动态调整线程数量,避免过多线程消耗过多资源。
1.什么是IO
IO(Input/Output)指的是计算机与外部环境之间的数据交换过程,包括输入和输出。
包括:
1.1 网络通信
如果服务是通过网络进行通信的,例如使用HTTP、WebSocket等协议与远程服务器进行数据交换,这属于IO操作。因为这些协议涉及到数据的输入和输出,包括从网络读取数据和向网络发送数据。
1.2 本地文件操作
如果服务是通过本地文件系统进行操作的,例如读写文件,这也属于IO操作。因为文件系统是外部存储设备的一部分,涉及到数据的输入和输出。
1.3 数据库操作
如果服务是通过数据库进行数据存储和检索的,这也属于IO操作。因为数据库操作通常涉及到数据的读写操作。
1.4 其他外部设备
如果服务是通过其他外部设备(如打印机、扫描仪等)进行操作的,这也属于IO操作。因为这些设备需要进行数据的输入和输出。
2.IO操作的类型和特点
2.1 同步IO
程序在发起IO请求后会等待操作完成,期间不能执行其他任务。这种模型在传统的网络编程中常见,例如使用Socket进行通信
2.2 异步IO
程序在发起IO请求后可以继续执行其他任务,不需要等待操作完成。这种模型可以提高程序的并发性能
2.3 阻塞和非阻塞
阻塞是指程序在等待IO操作完成时不能执行其他任务;非阻塞是指程序在等待IO操作时可以继续执行其他任务
2.4 异步处理框架
-
WebFlux:(WebFlux 适用于响应式编程)
-
WebFlux 是 Spring 5 引入的响应式编程框架,专门用于构建非阻塞的 Web 应用。
-
它基于 Reactor 库,提供了完整的响应式编程支持。
-
-
Servlet 3.0 异步支持:(Servlet 3.0 异步支持适用于传统应用的异步改造)
-
Servlet 3.0 引入了异步处理支持,允许在后台线程中处理请求,而不会阻塞主线程。
-
这是一种标准的 Java EE 异步处理机制。
-
2.5 使用WebFlux而不用CompletableFuture的原因
1.WebFlux 的优势
1.1 完整的响应式编程支持
WebFlux 是 Spring 5 引入的响应式编程框架,基于 Reactor 库,提供了完整的响应式编程支持。它支持非阻塞 I/O 和响应式流(Reactive Streams),能够处理复杂的异步数据流。
@GetMapping("/users/{id}")
public Mono<User> getUser(@PathVariable String id) {return userService.getUserById(id).timeout(Duration.ofSeconds(3)).switchIfEmpty(Mono.error(new UserNotFoundException("User not found")));
}Mono 和 Flux:WebFlux 提供了 Mono 和 Flux 两种响应式类型,分别用于单个值和多个值的异步处理。timeout:可以设置超时时间,自动取消长时间运行的操作。switchIfEmpty:可以处理空值的情况,提供默认值或抛出异常。1.2 集成 Spring 生态系统
WebFlux 与 Spring 生态系统深度集成,包括 Spring Data、Spring Security、Spring Web 等。这意味着你可以无缝地使用 Spring 的各种功能,而不需要额外的适配。
@Service
public class UserService {private final ReactiveMongoTemplate mongoTemplate;public UserService(ReactiveMongoTemplate mongoTemplate) {this.mongoTemplate = mongoTemplate;}public Mono<User> getUserById(String id) {return mongoTemplate.findById(id, User.class);}
}ReactiveMongoTemplate:WebFlux 与 Spring Data MongoDB 集成,支持响应式操作。2). 什么是Spring Data
Spring Data 是 Spring 生态系统中一个强大的子项目,它的核心目标是:简化 Java 应用程序与各种数据存储技术(数据库、NoSQL、云存储等)交互的过程。 它通过提供一套统一的、基于 Repository 抽象概念的编程模型来实现这一目标。
以下是 Spring Data 的关键特性和解释:
2.1 统一的 Repository 抽象
- Spring Data 的核心是
Repository接口(通常使用其子接口如CrudRepository、PagingAndSortingRepository、JpaRepository)。 - 开发人员只需定义一个接口,继承自这些 Spring Data 提供的 Repository 接口,并声明所需的数据操作方法(包括查询方法签名)。
- Spring Data 会在运行时自动为你生成该接口的具体实现类(所谓的“代理对象”)。 开发者无需编写繁琐的 DAO 实现代码。
2.2 自动化 CRUD 操作:
- 基础的 CRUD(创建、读取、更新、删除)操作被内置在
CrudRepository等接口中(如save(),findById(),findAll(),deleteById(),count()等)。你只需要继承这些接口,这些方法就立即可用,无需任何实现代码。
2.3 声明式查询方法:
- 最具特色的功能之一。 你可以在 Repository 接口中定义方法,仅通过遵循特定的命名约定来声明查询。
- 例如:定义一个方法
List<User> findByLastName(String lastName);。Spring Data 解析方法名(findBy+ 属性名LastName+ 查询条件),并将其转换为底层的查询语言(如 JPQL/SQL)。 - 这极大地减少了编写查询代码(JPQL, SQL)或 Criteria API 代码的工作量。
2.4 基于注解的查询:
- 对于更复杂的查询,或者命名约定无法满足需求时,可以使用
@Query注解直接在 Repository 方法上手动定义查询(支持 JPQL 或原生 SQL)。 - 例如:
@Query("SELECT u FROM User u WHERE u.email = ?1") User findByEmailAddress(String emailAddress);
2.5 分页和排序支持:
PagingAndSortingRepository提供了开箱即用的分页(Pageable参数)和排序(Sort参数)功能。- 例如:
Page<User> findAll(Pageable pageable); - 开发者可以轻松实现数据的分页加载和排序
2.6 对多种数据存储技术的支持:
- Spring Data 提供了一系列模块,针对不同的数据存储技术提供了统一的编程模型:
- 关系型数据库: Spring Data JPA (基于 JPA/Hibernate), Spring Data JDBC
- NoSQL 数据库:
- 文档型:Spring Data MongoDB
- 键值型:Spring Data Redis
- 列族型:Spring Data Cassandra
- 图数据库:Spring Data Neo4j
- 搜索引擎: Spring Data Elasticsearch
- 其它: Spring Data REST (将 Repository 暴露为 RESTful API), Spring Data Gemfire 等。
- 核心价值: 无论底层使用哪种数据库,你操作数据的编程模型(Repository 接口、方法命名查询、
@Query注解、分页参数等)都是高度一致的。
2.7 减少样板代码:
- 这是 Spring Data 最显著的优势之一。它自动处理了资源管理(连接)、事务边界管理、异常转换等繁琐的基础设施代码,让开发者专注于领域逻辑和查询声明。
Spring Data 的核心价值总结:
- 简化: 显著减少访问各种数据存储所需编写的模板代码。
- 抽象: 提供一致的数据访问编程模型,屏蔽不同数据存储底层实现的差异(在 API 层面)。
- 生产力: 通过自动化 Repository 实现和声明式查询,大大提高开发效率。
- 可扩展性: 模块化设计,支持广泛的流行数据存储技术。
2.8 典型应用场景:
假设你有一个 User 实体类(带有 @Entity 注解或映射元数据),你需要对它进行数据库操作。
1.创建一个 Repository 接口:
public interface UserRepository extends JpaRepository<User, Long> { // Long 是主键类型// 自动继承了大量 CRUD 方法 (save, findById, findAll, deleteById...)// 声明式查询方法:根据 lastName 查找List<User> findByLastName(String lastName);// 复杂查询使用 @Query@Query("SELECT u FROM User u WHERE u.email LIKE %?1%")List<User> findByEmailContains(String emailFragment);// 分页查询Page<User> findByFirstName(String firstName, Pageable pageable);
}
2.在 Service 或 Controller 中注入并使用
@Service
public class UserService {@Autowiredprivate UserRepository userRepository;public User getUserById(Long id) {return userRepository.findById(id).orElse(null); // 使用自动生成的 findById}public List<User> findUsersByLastName(String lastName) {return userRepository.findByLastName(lastName); // 使用声明式方法}// ... 使用其他方法
}
总之,Spring Data 是构建现代 Java 数据访问层的事实标准工具包。它以 Spring 的编程模型为基础,通过强大的 Repository 抽象和自动化实现机制,极大地简化了与各种数据存储交互的复杂性,让开发者能够专注于业务逻辑本身。
3).为什么用MyBatis而不用Spring Data
在Java持久层框架选择上,MyBatis的流行度高于Spring Data(尤其是Spring Data JPA),主要源于以下核心差异及适用场景:
3.1 核心差异对比
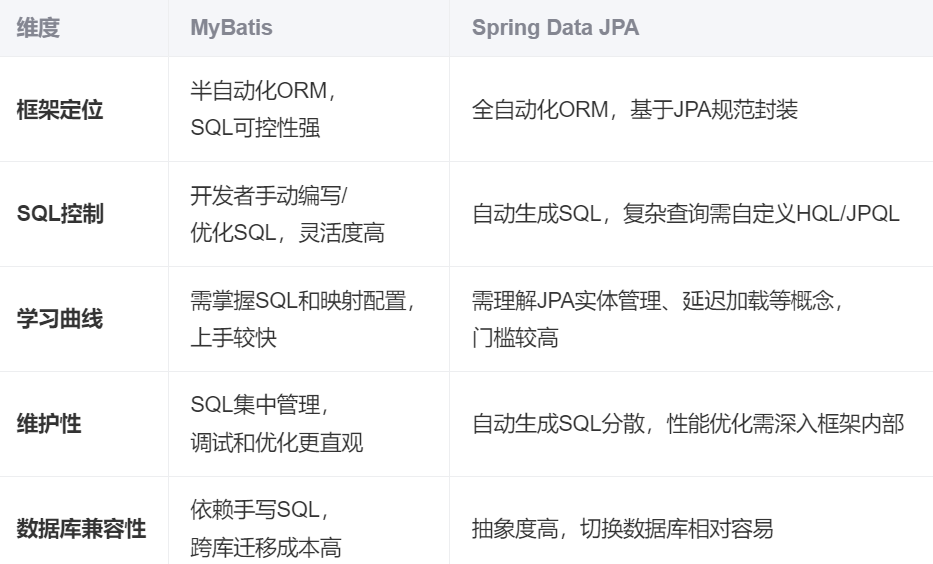
3.2 选择MyBatis的核心原因
1.灵活控制SQL性能
- MyBatis支持手写复杂SQL、批量操作、存储过程调用,可直接针对数据库特性优化(如索引提示、分页语法)。
- Spring Data JPA自动生成的SQL可能低效,复杂查询需额外学习HQL或Native SQL,灵活性受限
2.适应快速迭代需求
- 互联网项目常需调整SQL逻辑(如字段增减、查询条件变更),MyBatis的XML/注解配置修改直观,无需重构接口方法。
- Spring Data JPA的接口方法名约定在复杂查询时难以满足需求,且方法名过长影响可读性
3.降低团队协作成本
- SQL显式声明在Mapper文件中,便于DBA审核、性能监控和问题定位。
- Spring Data JPA的自动化机制导致SQL隐藏在框架内部,排查慢查询或逻辑错误较困难
4.无缝整合遗留系统
- 已有复杂SQL或存储过程可快速迁移到MyBatis,避免重写。
- Spring Data JPA需将SQL转换为JPQL或Entity操作,重构成本高
5.生态工具增强
- MyBatis Plus等插件提供代码生成、分页优化等功能,进一步简化开发。
- Spring Data JPA的扩展能力依赖于Hibernate特性,定制化难度较大
3.3 Spring Data JPA的适用场景
- 简单CRUD应用:方法命名约定和自动查询大幅提升基础操作效率。
- 快速原型验证:无需关注SQL细节,加速产品迭代初期开发。
- 多数据库兼容项目:抽象层支持轻松切换数据源(如MySQL→PostgreSQL
MyBatis在需要深度SQL优化、高频迭代的互联网项目中更受欢迎;而Spring Data JPA更适合数据库操作标准化、追求开发速度的传统应用。框架选择本质是控制力 vs 开发效率的权衡,
MyBatis的灵活性更契合当前高性能、可维护性优先的技术趋势。
4.非阻塞 I/O
WebFlux 基于 Netty,支持非阻塞 I/O,能够高效地处理高并发请求。这使得 WebFlux 在处理大量并发连接时比传统的阻塞 I/O 模型(如 Servlet)更具优势。
@GetMapping("/users")
public Flux<User> getAllUsers() {return userService.getAllUsers();
}Flux:用于处理多个值的响应式流,支持非阻塞 I/O。5).Netty、Tomcat与Servlet
5.1 核心概念与定位

5.2 Netty 与 Tomcat 核心区别
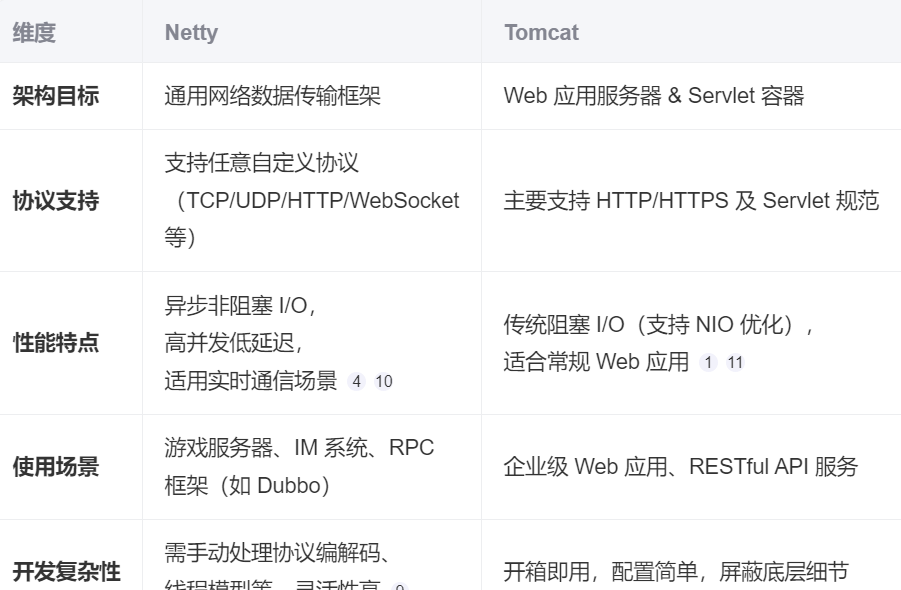
- Tomcat 是 Servlet 容器,本质是基于 HTTP 的 Web 服务器;
- Netty 是网络框架,可构建任意协议的通信层(包括 HTTP 服务器)
5.3三者技术联系
-
Netty 与 Tomcat
- 功能重叠:Netty 可替代 Tomcat 的 HTTP 服务能力(如通过
HttpServerCodec处理 HTTP 协议)。 - 本质差异:
- Tomcat 是完整的 Web 应用服务器(含会话管理、安全等);
- Netty 是底层通信框架,需额外开发才能实现类似功能
- 功能重叠:Netty 可替代 Tomcat 的 HTTP 服务能力(如通过
-
Netty 与 Servlet
- Netty 不直接支持 Servlet 规范,但可通过扩展(如
netty-servlet桥接)模拟 Servlet 容器。 - 若需在 Netty 中运行 Servlet,需自行实现请求解析、线程映射等逻辑,成本较高。
- Netty 不直接支持 Servlet 规范,但可通过扩展(如
-
Servlet 与 Tomcat
- Servlet 是 Java 定义的接口规范(如
HttpServlet),定义了处理 HTTP 请求的标准方式。 - Tomcat 实现了 Servlet 规范,提供运行时环境(容器),管理 Servlet 生命周期、线程池等 。
- 示例:Spring MVC 的
DispatcherServlet最终由 Tomcat 调用执行。
- Servlet 是 Java 定义的接口规范(如
- Tomcat 依赖 Servlet 规范实现 Web 功能;
- Netty 可选择性支持 HTTP/Servlet,但非核心能力
5.4 如何选择
1.选 Tomcat
当:需快速部署标准 Web 应用(如 Spring Boot)、依赖 Servlet/JSP 生态、无需深度定制协议
2.选 Netty
当:开发高性能中间件(MQ/RPC)、需自定义二进制协议(如游戏)、追求极致吞吐与低延迟
注意:Tomcat 从 8.5+ 已全面转向 NIO 模型,性能差距缩小,但 Netty 在协议定制化上仍有压倒性优势
6. 错误处理和回压支持
WebFlux 提供了强大的错误处理机制和回压支持,能够更好地处理异步数据流中的异常情况。
@GetMapping("/users/{id}")
public Mono<User> getUser(@PathVariable String id) {return userService.getUserById(id).onErrorResume(UserNotFoundException.class, ex -> Mono.empty()).switchIfEmpty(Mono.error(new UserNotFoundException("User not found")));
}onErrorResume:捕获特定类型的异常并提供替代值。
switchIfEmpty:处理空值的情况,提供默认值或抛出异常。7.CompletableFuture 的局限性
虽然 CompletableFuture 是 Java 8 引入的异步编程模型,但它有一些局限性,特别是在处理复杂的异步数据流时:
1. 缺少响应式流支持
CompletableFuture 本身不支持响应式流(Reactive Streams),这使得它在处理复杂的异步数据流时不够灵活。
public CompletableFuture<User> getUser(String id) {return CompletableFuture.supplyAsync(() -> userService.getById(id));
}CompletableFuture:适用于简单的异步任务,但不支持复杂的流处理。2.缺少非阻塞 I/O 支持
CompletableFuture 本身不支持非阻塞 I/O,需要结合其他框架(如 Netty)来实现非阻塞 I/O。
public CompletableFuture<User> getUser(String id) {return CompletableFuture.supplyAsync(() -> userService.getById(id), threadPool);
}threadPool:需要手动管理线程池,以实现非阻塞 I/O。3.错误处理不够灵活
CompletableFuture 的错误处理机制相对简单,不如 WebFlux 提供的响应式错误处理机制灵活。
public CompletableFuture<User> getUser(String id) {return CompletableFuture.supplyAsync(() -> userService.getById(id)).exceptionally(ex -> {if (ex instanceof UserNotFoundException) {return null;}throw new RuntimeException(ex);});
}exceptionally:捕获异常并提供替代值,但不如 WebFlux 的 onErrorResume 灵活。8.选择 CompletableFuture 的场景
尽管 WebFlux 有诸多优势,但在某些场景下,CompletableFuture 仍然是一个合适的选择:
1. 简单的异步任务
如果任务相对简单,不需要复杂的响应式流处理,CompletableFuture 是一个轻量级的选择。
public CompletableFuture<User> getUser(String id) {return CompletableFuture.supplyAsync(() -> userService.getById(id));
}2.与现有代码集成
如果现有代码已经大量使用了 CompletableFuture,继续使用 CompletableFuture 可以减少重构成本。
public CompletableFuture<User> getUser(String id) {return CompletableFuture.supplyAsync(() -> userService.getById(id)).exceptionally(ex -> {if (ex instanceof UserNotFoundException) {return null;}throw new RuntimeException(ex);});
}9.总结
WebFlux:
适用于高并发、复杂的响应式编程场景。
提供完整的响应式编程支持、非阻塞 I/O、错误处理和回压支持。
与 Spring 生态系统深度集成。
CompletableFuture:
适用于简单的异步任务。
轻量级,易于与现有代码集成。
在实际应用中,你可以根据具体需求选择合适的工具。如果需要处理高并发和复杂的异步数据流,WebFlux 是更好的选择;如果任务简单且不需要复杂的响应式流处理,CompletableFuture 也是一个不错的选择。
2.6 消息队列与这种异步处理的区别
消息队列主要用于 异步消息传递 和 系统间解耦,而 WebFlux 和 Servlet 3.0 异步支持主要用于 异步处理 和 非阻塞 I/O。它们可以同时存在于一个系统中,用于解决不同的问题。
1.为什么在某些场景下不使用消息队列?
1.1 消息队列主要用于以下场景:
系统间解耦:允许不同的系统组件之间通过消息进行通信,而不需要直接调用。
异步任务处理:将任务放入队列,由消费者异步处理,提高系统的响应速度。
缓冲和负载均衡:通过队列缓冲消息,平滑处理突发流量。
1.2 WebFlux 和 Servlet 3.0 异步支持的适用场景
WebFlux 和 Servlet 3.0 异步支持主要用于以下场景:
-
高并发处理:通过非阻塞 I/O 和异步处理,提高系统的并发处理能力。
-
响应式编程:支持复杂的异步数据流处理,适合处理复杂的业务逻辑。
-
快速响应:减少线程阻塞,提高系统的响应速度。
1.3 为什么在某些场景下不使用消息队列
1. 性能考虑
消息队列引入额外的延迟:消息队列需要将消息从生产者发送到队列,再从队列发送到消费者,这会引入额外的网络延迟。
直接异步处理更快:如果任务可以直接在内存中异步处理,使用 WebFlux 或 Servlet 3.0 异步支持可以更快地响应请求,而不需要通过消息队列进行中转。
2. 系统复杂性
引入消息队列增加复杂性:消息队列需要额外的配置和维护,增加了系统的复杂性。
轻量级异步处理:如果任务相对简单,使用 WebFlux 或 Servlet 3.0 异步支持可以更简单地实现异步处理,而不需要引入消息队列。
3. 适用场景不同
消息队列适用于异步任务和解耦:如果需要将任务放入队列,由消费者异步处理,或者需要解耦系统组件,消息队列是合适的选择。
WebFlux 和 Servlet 3.0 异步支持适用于高并发和快速响应:如果需要处理高并发请求,减少线程阻塞,提高系统的响应速度,WebFlux 和 Servlet 3.0 异步支持是更好的选择。
1.4 总结
-
消息队列:
-
适用于异步任务处理和系统间解耦。
-
引入额外的延迟和复杂性,但提供了高可靠性和解耦能力。
-
-
WebFlux 和 Servlet 3.0 异步支持:
-
适用于高并发处理和快速响应。
-
提供非阻塞 I/O 和异步处理能力,适合处理复杂的业务逻辑。
-
在实际应用中,你可以根据具体需求选择合适的工具。如果需要处理复杂的异步任务和解耦系统组件,消息队列是合适的选择;如果需要处理高并发请求和快速响应,WebFlux 和 Servlet 3.0 异步支持是更好的选择。在某些情况下,也可以将它们结合起来使用,以充分发挥各自的优势。
2.Servlet中的DeferredResult中为什么会有CompletableFuture
DeferredResult 是一个低级别的工具,用于支持异步处理。它允许你在后台线程中完成异步操作,并在操作完成后设置结果。DeferredResult 本身并不管理线程池,因此你需要自己管理线程池来执行后台任务。
@RestController
public class AsyncController {@GetMapping("/testDeferredResult")public DeferredResult<String> testDeferredResult() {DeferredResult<String> deferredResult = new DeferredResult<>();// 使用 CompletableFuture 在后台线程中执行异步任务CompletableFuture.runAsync(() -> {try {Thread.sleep(5000); // 模拟耗时操作deferredResult.setResult("Async operation completed");} catch (Exception e) {deferredResult.setErrorResult(e);}});return deferredResult;}
}CompletableFuture.runAsync:
CompletableFuture.runAsync 是 Java 8 引入的异步编程模型,用于在后台线程中执行异步任务。它可以将任务提交到默认的线程池(ForkJoinPool.commonPool())中执行。在任务完成后,通过 deferredResult.setResult 设置异步操作的结果。
CompletableFuture:负责在后台线程中执行具体的异步任务。
DeferredResult:负责管理异步响应,确保在后台线程完成任务后能够正确地返回结果。
3.WebAsyncTask为什么没有用 CompletableFuture
WebAsyncTask 是一个高级别的工具,用于支持异步处理。它封装了线程池和任务执行逻辑,因此你不需要自己管理线程池。WebAsyncTask 内部使用了 TaskExecutor 来执行任务,这使得它比 DeferredResult 更简单易用。
-
WebAsyncTask内部已经封装了线程池和任务执行逻辑:-
WebAsyncTask内部使用了TaskExecutor来执行任务,你不需要手动管理线程池。 -
WebAsyncTask提供了超时处理机制,任务在指定时间内没有完成会自动取消。
-
-
简化代码:
-
使用
WebAsyncTask可以直接实现异步任务,而不需要额外引入CompletableFuture。 -
这使得代码更加简洁,减少了复杂性。
-
3.1 总结
在实际应用中,你可以根据具体需求选择合适的工具。如果任务相对复杂,需要更灵活的线程池管理,可以使用
DeferredResult结合CompletableFuture。如果任务相对简单,可以直接使用WebAsyncTask。
2.7 在 Spring Boot 中,使用 Servlet 3.0 或 WebFlux
1.使用 Servlet 3.0
当你使用 Servlet 3.0 处理异步请求时,Spring Boot 默认使用 Tomcat 作为嵌入式服务器。Tomcat 是一个传统的 Servlet 容器,支持 Servlet 3.0 的异步特性。
启动类配置
@SpringBootApplication
public class Servlet3Application {public static void main(String[] args) {SpringApplication.run(Servlet3Application.class, args);}
}Servlet 配置
@WebServlet(urlPatterns = "/async", asyncSupported = true)
public class AsyncServlet extends HttpServlet {@Overrideprotected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {AsyncContext asyncContext = req.startAsync();asyncContext.setTimeout(30000);CompletableFuture.runAsync(() -> {try {Thread.sleep(5000);resp.getWriter().write("Async operation completed");} catch (Exception e) {e.printStackTrace();} finally {asyncContext.complete();}});}
}2.使用 WebFlux
当你使用 WebFlux 处理异步请求时,Spring Boot 默认使用 Netty 作为嵌入式服务器。Netty 是一个高性能的非阻塞 I/O 框架,非常适合处理高并发的异步请求。
启动类配置
@SpringBootApplication
public class WebFluxApplication {public static void main(String[] args) {SpringApplication.run(WebFluxApplication.class, args);}
}WebFlux 控制器
@RestController
public class WebFluxController {@GetMapping("/users/{id}")public Mono<String> getUser(@PathVariable String id) {return Mono.fromCallable(() -> {Thread.sleep(5000); // 模拟耗时操作return "User " + id;}).subscribeOn(Schedulers.boundedElastic());}
}3.如何选择
-
使用 Servlet 3.0:
-
适用于传统的 Web 应用,需要支持 Servlet 3.0 的异步特性。
-
使用
spring-boot-starter-web,默认运行在 Tomcat 上。
-
-
使用 WebFlux:
-
适用于响应式 Web 应用,需要支持非阻塞 I/O 和高并发的异步请求。
-
使用
spring-boot-starter-webflux,默认运行在 Netty 上。
-
4.总结
-
Servlet 3.0:
-
使用 Tomcat 作为嵌入式服务器。
-
适用于传统的 Web 应用,支持 Servlet 3.0 的异步特性。
-
-
WebFlux:
-
使用 Netty 作为嵌入式服务器。
-
适用于响应式 Web 应用,支持非阻塞 I/O 和高并发的异步请求
-
在实际应用中,你可以根据具体需求选择合适的框架和服务器。如果需要处理高并发的异步请求,建议使用 WebFlux 和 Netty;如果需要支持传统的 Servlet 3.0 特性,可以使用 Spring MVC 和 Tomcat。
2.8 Servlet 3.0 和 WebFlux 通常不能直接一起使用
1.为什么不能一起使用?
-
Servlet 3.0:
-
基于传统的 Servlet API,运行在 Servlet 容器(如 Tomcat)中。
-
使用同步阻塞 I/O 模型。
-
-
WebFlux:
-
基于响应式编程模型,运行在非阻塞 I/O 容器(如 Netty)中。
-
使用非阻塞 I/O 和事件驱动模型。
-
当同时引入 spring-boot-starter-web 和 spring-boot-starter-webflux 时,Spring Boot 的自动配置机制会尝试同时启用两种不同的 Web 框架,导致以下问题:
-
Bean 定义冲突:例如
requestMappingHandlerMapping的 Bean 重复定义。 -
配置冲突:Spring MVC 和 Spring WebFlux 的配置相互干扰,导致请求路由混乱
2.如何解决冲突?
2.1 方案一:明确指定应用类型
在 application.properties 或 application.yml 文件中,明确指定应用的 Web 类型
spring.main.web-application-type=reactive # 使用 WebFlux
# 或
spring.main.web-application-type=servlet # 使用 Spring MVC2.2 方案二:分离配置类
为 Spring MVC 和 WebFlux 分别创建独立的配置类,避免 Bean 定义冲突:
// MVC 配置类
@Configuration
@EnableWebMvc
public class WebMvcConfig implements WebMvcConfigurer {// MVC 相关配置
}// WebFlux 配置类
@Configuration
@EnableWebFlux
public class WebFluxConfig implements WebFluxConfigurer {// WebFlux 相关配置
}2.3 方案三:适配器模式
通过定义一个通用的控制器接口,实现适配器模式,将 WebFlux 和 Spring MVC 的请求处理统一到一个通用接口上:
public interface CommonController {Mono<String> handleRequest(ServerRequest request);
}public class WebFluxControllerAdapter implements CommonController {private final WebFluxController webFluxController;public WebFluxControllerAdapter(WebFluxController webFluxController) {this.webFluxController = webFluxController;}@Overridepublic Mono<String> handleRequest(ServerRequest request) {return webFluxController.handle(request);}
}public class WebMvcControllerAdapter implements CommonController {private final WebMvcController webMvcController;public WebMvcControllerAdapter(WebMvcController webMvcController) {this.webMvcController = webMvcController;}@Overridepublic Mono<String> handleRequest(ServerRequest request) {return Mono.fromCallable(() -> webMvcController.handle(request.toHttpServletRequest()));}
}2.4 方案四:维护兼容性中间件
在 WebFlux 和 Spring MVC 之间引入一个中间层,用于处理两者之间的兼容性问题
@RestController
public class UnifiedController {private final WebFluxController webFluxController;private final WebMvcController webMvcController;public UnifiedController(WebFluxController webFluxController, WebMvcController webMvcController) {this.webFluxController = webFluxController;this.webMvcController = webMvcController;}@RequestMapping("/unified")public Mono<String> handleRequest(ServerRequest request) {if (isWebFluxRequest(request)) {return webFluxController.handle(request);} else {return Mono.fromCallable(() -> webMvcController.handle(request.toHttpServletRequest()));}}private boolean isWebFluxRequest(ServerRequest request) {// 判断请求是否为 WebFlux 请求return request.attribute("org.springframework.web.reactive.HandlerMapping.bestMatchingHandler").isPresent();}
}3.总结
虽然 Spring MVC 和 WebFlux 不能直接一起使用,但可以通过以下方式解决冲突:
-
明确指定应用的 Web 类型。
-
分离配置类,避免 Bean 定义冲突。
-
使用适配器模式,统一请求处理接口。
-
引入兼容性中间件,处理两者之间的兼容性问题。
在实际应用中,建议根据具体需求选择合适的解决方案。如果项目主要是基于 Spring MVC 开发的,建议使用 Spring MVC;如果需要处理高并发的异步请求,建议使用 WebFlux。
2.9 响应式编程与传统编程的对比
1.区别
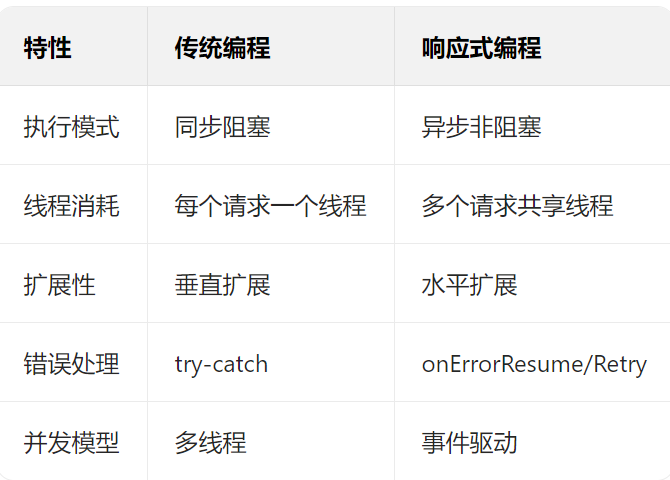
2.响应式编程的典型应用场景
- 高并发系统:如电商秒杀、消息推送系统
- 微服务通信:服务间的异步调用
- 实时数据处理:如股票行情、物联网数据
- 资源受限环境:在有限资源下处理大量请求
3.实际应用注意事项
-
响应式生态系统:
- 需要使用响应式数据源(如 R2DBC、WebClient)
- 避免在响应式链中使用阻塞操作
-
学习曲线:
- 响应式编程模型与传统编程差异较大
- 需要理解数据流、操作符和线程模型
-
性能调优:
- 合理选择线程池
- 监控背压和资源使用情况
-
调试挑战:
- 异步执行栈追踪复杂
- 需要专用的调试工具和技巧
4. 理解数据流、操作符和线程模型
4.1 数据流(Reactive Streams)
数据流是响应式编程的基础,它代表一系列按时间顺序产生的事件或值。在 Spring WebFlux 中,主要有两种数据流类型:
-
Mono:表示 0-1 个元素的异步序列
- 常用于返回单个结果的操作(如查询单个用户)
- 支持异步操作完成 / 错误 / 取消的通知
-
Flux:表示 0-N 个元素的异步序列
- 常用于返回多个结果的操作(如查询用户列表)
- 支持背压机制(消费者可以控制生产者的速度)
数据流的特点:
- 异步处理:数据在产生时被处理,无需等待整个数据集
- 非阻塞:不会阻塞调用线程
- 可组合:可以通过操作符进行链式处理
数据在产生时被处理,无需等待整个数据集?
异步处理与数据流的实时性解析:
1.异步处理的核心本质
异步处理的关键在于数据处理与数据产生的解耦,
即:数据无需等待全部生成后再统一处理,而是随生随处理。
这就像流水线作业 —— 原材料(数据)每到达一个工位(处理环节)就立即被加工,而不是等所有原材料堆积完成后再启动生产线。
2.Flux 与 Mono 的异步处理差异
Flux 的 “流式处理” 特性
Flux 代表 0-N 个元素的序列,数据会按时间顺序逐个产生。例如:
- 从数据库查询 100 条用户记录时,Flux 会在获取到第 1 条数据后立即开始处理(如转换格式、过滤条件),同时继续获取第 2 条、第 3 条……
- 处理逻辑(如
map、filter操作符)会随数据产生而实时执行,无需等待所有 100 条数据全部返回。Mono 的 “单值处理” 特性
Mono 代表 0-1 个元素,数据要么不存在,要么是一个完整的单值。例如:
- 查询单个用户时,Mono 会在获取到完整用户对象后才触发处理逻辑(如校验权限、序列化响应)。
- 由于数据是 “一次性” 交付的,不存在 “分批次产生” 的过程,因此无需体现 “随生随处理” 的特性,但依然属于异步处理(获取数据的过程是非阻塞的)。
3.异步处理的核心优势
资源利用率更高:
无需为等待全部数据而占用线程资源(如传统同步编程中List<T>需等所有数据加载完才处理),线程可在数据产生间隙处理其他任务。响应更及时:
前端用户能更快看到部分数据结果(如分页加载时先显示前 10 条,同时加载后 10 条),而非白屏等待整个数据集返回。支持背压(Backpressure):
当数据产生速度超过处理速度时,消费者可通知生产者减缓发送,避免内存溢出(如 Flux 处理大文件流时)。通过这种设计,响应式编程既能处理 “海量数据流” 的实时响应,也能兼顾 “单值操作” 的异步优化,最终实现系统的高吞吐量和低延迟。
4.2 操作符(Operators)
操作符是处理数据流的工具,它们允许你转换、过滤、组合和处理数据流中的元素。常见的操作符包括:
-
转换操作:
map:将每个元素转换为另一个值flatMap:将每个元素转换为一个新的数据流,并合并结果transform:应用一个自定义的转换函数
-
过滤操作:
filter:根据条件过滤元素take:只取前 N 个元素skip:跳过前 N 个元素
-
组合操作:
concat:连接多个数据流merge:合并多个并行的数据流zip:将多个数据流的元素配对
-
错误处理:
onErrorReturn:发生错误时返回默认值onErrorResume:发生错误时提供备用数据流retry:发生错误时重试操作
-
副作用操作:
doOnNext:对每个元素执行副作用操作doOnComplete:在完成时执行副作用操作doOnError:在发生错误时执行副作用操作
4.3 线程模型(Schedulers)
线程模型决定了响应式操作在哪个线程或线程池中执行。在 Spring WebFlux 中,主要有以下几种调度器:
-
Schedulers.immediate():
- 在当前线程中立即执行
- 不切换线程上下文
-
Schedulers.single():
- 使用单个线程执行所有任务
- 适合需要顺序执行的操作
-
Schedulers.parallel():
- 使用固定大小的线程池(默认 CPU 核心数)
- 适合计算密集型操作
-
Schedulers.boundedElastic():
- 使用可伸缩的线程池(最大线程数为 10000)
- 适合可能阻塞的 IO 操作
- 线程会在空闲 60 秒后回收
-
Schedulers.fromExecutorService():
- 使用自定义的 ExecutorService
- 适合需要精细控制线程池参数的场景
5. 线程池选了Schedulers.boundedElastic()
避免在响应式链中使用阻塞操作为啥选了Schedulers.boundedElastic():适用于可能阻塞的 IO 操作这不是矛盾吗?
5.1 关于线程池选择的 "矛盾" 解释
return Mono.fromCallable(() -> userService.getById(id)).subscribeOn(Schedulers.boundedElastic()) // 阻塞操作专用线程池.timeout(Duration.ofSeconds(3));
这里的设计实际上是一种 "策略性阻塞",原因如下:
业务逻辑的现实:
- 在实际项目中,我们经常需要调用一些不可避免的阻塞 API(如传统的 JDBC、第三方同步 API 等)
- 完全避免阻塞在某些场景下是不现实的
隔离策略:
boundedElastic()线程池的设计初衷就是为了隔离阻塞操作- 它不会影响主事件循环(如 Netty 的 EventLoop 线程)
- 确保阻塞操作不会导致整个系统失去响应
资源控制:
boundedElastic()线程池有最大线程数限制(默认 10000)- 当达到最大线程数时,新任务会进入队列等待
- 防止无限制创建线程导致系统崩溃
过渡策略:
- 这是从传统同步代码迁移到响应式编程的一种过渡策略
- 随着项目演进,可以逐步替换为真正的响应式实现
5.2 最佳实践建议
-
优先使用响应式 API:
- 尽可能使用响应式数据源(如 R2DBC、WebClient)
- 避免在响应式链中使用阻塞 API
-
隔离阻塞操作:
- 如果必须使用阻塞 API,使用
boundedElastic()隔离 - 不要在主事件循环中执行阻塞操作
- 如果必须使用阻塞 API,使用
-
设置超时和背压:
- 为阻塞操作设置合理的超时时间
- 对可能产生大量数据的操作实现背压机制
-
监控和调优:
- 监控线程池使用情况
- 根据实际负载调整线程池参数
-
逐步迁移:
- 对于大型项目,采用渐进式迁移策略
- 先隔离阻塞操作,再逐步替换为响应式实现
2.10 回调(Callback)与监听(Listener)的区别解析
1.回调(Callback)
1.1 定义:
回调是一种函数式编程模式,允许一个对象(调用者)将函数(回调函数)传递给另一个对象(被调用者),当特定事件发生时,被调用者执行该回调函数。
1.2 特点:
- 同步 / 异步均可:回调可以是同步的(立即执行)或异步的(稍后执行)
- 主动调用:被调用者主动调用回调函数
- 一对一关系:通常一个操作对应一个回调
- 代码嵌入:回调逻辑直接嵌入调用者代码中
1.3 同步回调
// 回调接口
interface CalculatorCallback {void onResult(int result);
}// 被调用者
class Calculator {public void calculate(int a, int b, CalculatorCallback callback) {int result = a + b;callback.onResult(result); // 主动调用回调}
}// 调用者
public class Main {public static void main(String[] args) {Calculator calculator = new Calculator();// 定义并传递回调calculator.calculate(5, 3, result -> {System.out.println("计算结果: " + result);});}
}Java中回调机制与Lambda表达式的结合使用(1)回调接口定义interface CalculatorCallback {void onResult(int result); // 抽象方法:用于接收计算结果
}
作用:定义回调规范,约定结果处理方式(类似JavaScript的回调函数)。
关键点:单方法接口(SAM),可被Lambda简化。(2)被调用者(Calculator)
class Calculator {public void calculate(int a, int b, CalculatorCallback callback) {int result = a + b;callback.onResult(result); // 触发回调}
}(3)调用者(Main)
calculator.calculate(5, 3, result -> {System.out.println("计算结果: " + result);
});传统写法(匿名内部类):
calculator.calculate(5, 3, new CalculatorCallback() {@Overridepublic void onResult(int result) {System.out.println("计算结果: " + result);}
});Lambda简化:直接以(参数) -> {逻辑}替代匿名类,代码更简洁。Java编译器自动推断result为int类型(因CalculatorCallback.onResult(int)已定义参数类型)设计思想与优势
1.解耦计算与处理
Calculator只负责计算,不关心结果如何被使用(如打印、存储、网络发送等)。
2.灵活扩展
调用者可通过不同Lambda实现不同处理逻辑(如替换为result -> saveToDatabase(result))。
3.函数式编程特性
将代码作为参数传递,符合"行为参数化"思想。注意事项
接口限制:Lambda仅适用于单方法接口(如Runnable、Comparator等)。
变量捕获:Lambda可访问外部final或等效final的局部变量(Java 8+隐式final)。确保线程安全性和变量值的一致性(Lambda可能在不同线程中执行)实例变量不受限:Lambda可直接访问和修改类的成员变量(非局部变量)。
并发风险:若Lambda捕获可变变量,多线程下可能引发数据竞争值捕获:Lambda捕获的是变量的值副本,而非变量本身,因此需保证值不变性。线程安全:强制不可变性避免多线程环境下的竞态条件
调试复杂性:Lambda的堆栈跟踪可能比匿名类更难阅读。5. 扩展应用场景
异步编程:结合CompletableFuture实现非阻塞回调。
事件监听:GUI开发中(如Android点击事件)。
集合操作:Java Stream API的forEach()、map()等方法均依赖Lambda。1.4 异步回调
class AsyncService {public void processAsync(AsyncCallback callback) {// 模拟异步操作new Thread(() -> {try {Thread.sleep(1000);callback.onSuccess("操作完成");} catch (Exception e) {callback.onError(e);}}).start();}
}interface AsyncCallback {void onSuccess(String result);void onError(Exception e);
}在这段代码中,调用方(Caller)是指使用AsyncService并实现AsyncCallback接口的代码。被调用方 AsyncService 类 提供异步执行能力,触发回调调用方 实现AsyncCallback接口并调用processAsync()的类 定义业务逻辑,处理成功/失败结果调用方示例代码
public class Main {public static void main(String[] args) {AsyncService service = new AsyncService();// 调用方实现回调接口service.processAsync(new AsyncCallback() {@Overridepublic void onSuccess(String result) {System.out.println("成功: " + result); // 调用方处理成功逻辑}@Overridepublic void onError(Exception e) {System.err.println("失败: " + e.getMessage()); // 调用方处理错误逻辑}});System.out.println("异步操作已启动,主线程继续执行...");}
}Lambda简化:调用方可用Lambda替代匿名类(需Java 8+)
service.processAsync(result -> System.out.println("成功: " + result),error -> System.err.println("失败: " + error));设计思想
控制反转(IoC):调用方通过回调接口将处理逻辑注入被调用方。
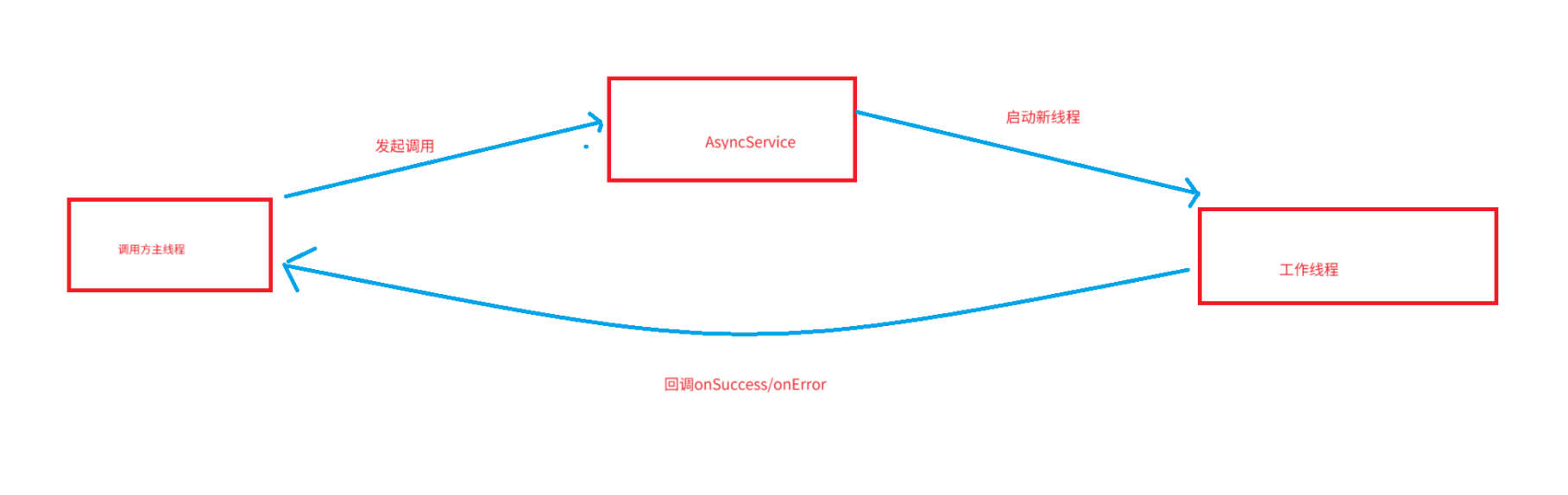
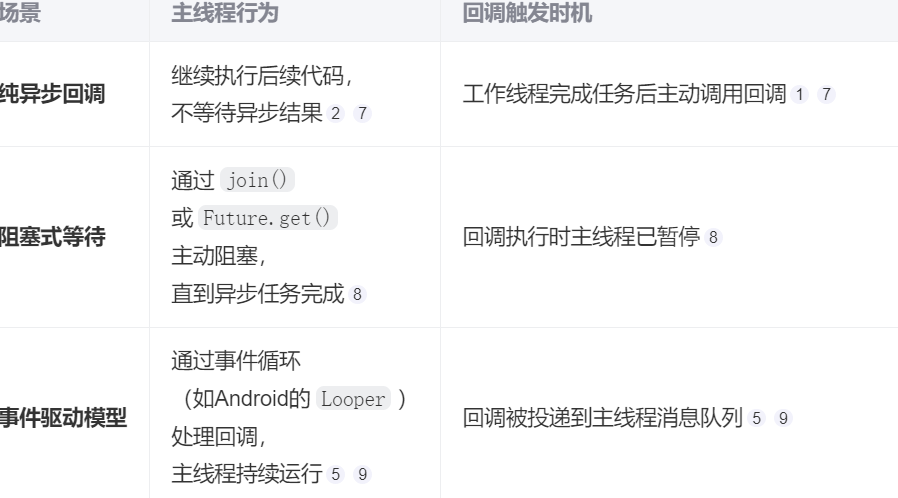
异步解耦:调用方无需阻塞等待结果,适合IO密集型操作。1.5 在异步回调机制中,主线程和工作线程的执行关系取决于具体实现方式
1. 线程执行模型
2.基于回调的异步调用
在这种方式中,调用方需要提供一个回调接口的实现,以便在异步操作完成时被调用
public interface Callback {void onComplete(String result);
}public class AsyncService {public void doAsyncWork(Callback callback) {new Thread(() -> {// 模拟耗时操作try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}// 操作完成,调用回调callback.onComplete("操作完成");}).start();}
}public class Main {public static void main(String[] args) {AsyncService service = new AsyncService();// 调用方实现回调接口service.doAsyncWork(new Callback() {@Overridepublic void onComplete(String result) {System.out.println("回调结果: " + result);}});System.out.println("主线程继续执行...");}
}在这个例子中,调用方必须实现Callback接口,以便接收异步操作的结果。
3.基于Future的异步调用
在这种方式中,调用方不需要实现任何接口,而是通过Future对象来获取异步操作的结果。
import java.util.concurrent.*;public class AsyncService {public Future<String> doAsyncWork() {return Executors.newSingleThreadExecutor().submit(() -> {// 模拟耗时操作Thread.sleep(2000);return "操作完成";});}
}public class Main {public static void main(String[] args) throws ExecutionException, InterruptedException {AsyncService service = new AsyncService();// 调用异步方法,获取Future对象Future<String> future = service.doAsyncWork();// 主线程继续执行其他逻辑System.out.println("主线程继续执行...");// 等待异步操作完成并获取结果String result = future.get();System.out.println("异步操作结果: " + result);}
}在这个例子中,调用方不需要实现任何接口,而是通过Future对象来获取异步操作的结果。
4.基于CompletableFuture的异步调用
CompletableFuture是Java 8引入的一种更强大的异步编程工具,支持链式调用和组合操作
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;public class AsyncService {public CompletableFuture<String> doAsyncWork() {return CompletableFuture.supplyAsync(() -> {// 模拟耗时操作try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}return "操作完成";});}
}public class Main {public static void main(String[] args) throws ExecutionException, InterruptedException {AsyncService service = new AsyncService();// 调用异步方法,获取CompletableFuture对象CompletableFuture<String> future = service.doAsyncWork();// 主线程继续执行其他逻辑System.out.println("主线程继续执行...");// 等待异步操作完成并获取结果String result = future.get();System.out.println("异步操作结果: " + result);}
}在这个例子中,调用方同样不需要实现任何接口,而是通过CompletableFuture对象来处理异步操作的结果。5.基于事件监听的异步调用
在这种方式中,调用方需要注册一个监听器来接收事件通知,但监听器的实现可以是独立的。
public interface EventListener {void onEvent(String event);
}public class EventSource {private List<EventListener> listeners = new ArrayList<>();public void registerListener(EventListener listener) {listeners.add(listener);}public void triggerEvent(String event) {for (EventListener listener : listeners) {listener.onEvent(event);}}
}public class Main {public static void main(String[] args) {EventSource eventSource = new EventSource();// 调用方实现监听器接口EventListener listener = new EventListener() {@Overridepublic void onEvent(String event) {System.out.println("收到事件: " + event);}};// 注册监听器eventSource.registerListener(listener);// 触发事件eventSource.triggerEvent("事件发生");}
}在这个例子中,调用方需要实现EventListener接口,但这个实现可以是独立的,不一定需要在调用方法时直接提供。6.总结
-
基于回调的异步调用:调用方必须实现回调接口。
-
基于Future或CompletableFuture的异步调用:调用方不需要实现任何接口,而是通过Future或CompletableFuture对象来处理异步结果。
-
基于事件监听的异步调用:调用方需要实现监听器接口,但实现可以是独立的。
因此,是否需要实现调用接口取决于具体的异步调用机制和设计模式。
2.监听
2.1 定义
监听是观察者模式的实现,通过注册监听器到事件源,当事件发生时,事件源通知所有已注册的监听器。
2.2 特点
- 纯异步:基于事件驱动,事件发生时才触发
- 被动通知:监听器被动接收事件,不关心事件何时发生
- 一对多关系:一个事件源可以有多个监听器
- 松耦合:通过接口或抽象类解耦
2.3 示例
// 事件类
class Event {private String message;public Event(String message) {this.message = message;}public String getMessage() {return message;}
}// 事件监听器接口
interface EventListener {void onEvent(Event event);
}// 事件源
class EventSource {private List<EventListener> listeners = new ArrayList<>();// 注册监听器public void addListener(EventListener listener) {listeners.add(listener);}// 移除监听器public void removeListener(EventListener listener) {listeners.remove(listener);}// 触发事件public void fireEvent(Event event) {for (EventListener listener : listeners) {listener.onEvent(event); // 通知所有监听器}}
}// 使用监听
public class Main {public static void main(String[] args) {EventSource source = new EventSource();// 注册多个监听器source.addListener(event -> System.out.println("监听器1: " + event.getMessage()));source.addListener(event -> System.out.println("监听器2: " + event.getMessage()));// 触发事件source.fireEvent(new Event("事件发生"));}
}2.4 Java 中两者的核心区别
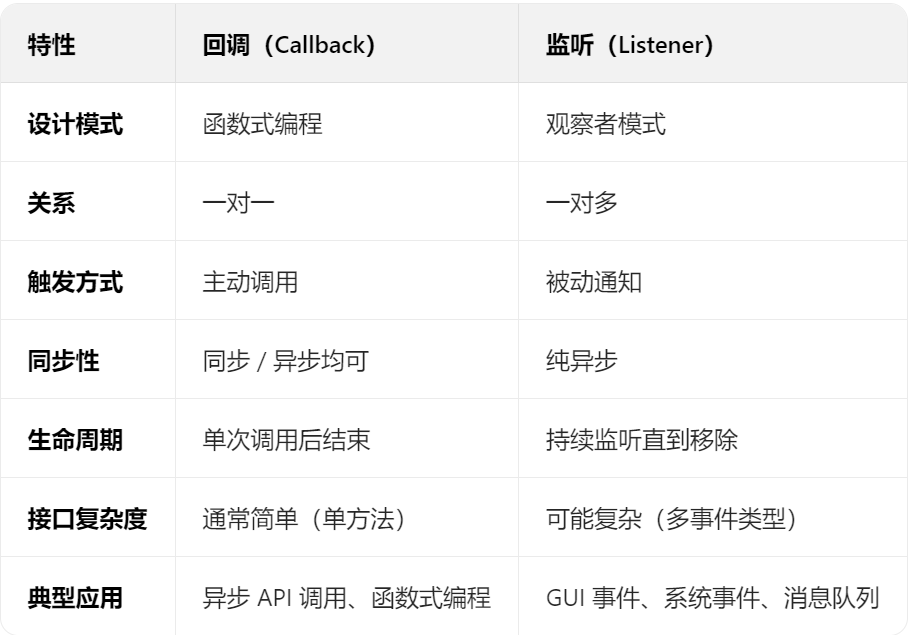
2.5 Java 中的典型应用场景
-
回调的应用:
- Java 8 的函数式接口(如
Runnable、Callable) CompletableFuture的回调方法(thenApply、whenComplete)- Spring 的
JdbcTemplate回调(RowMapper) - 单元测试中的
Mockito回调
- Java 8 的函数式接口(如
-
监听的应用:
- Java Swing/AWT 的事件监听器(如
ActionListener) - Spring 的事件机制(
ApplicationListener) - Java NIO 的选择器(
SelectionKey.OP_READ) - 消息队列的消费者(如 RabbitMQ 的
Channel.basicConsume)
- Java Swing/AWT 的事件监听器(如
2.6 高级对比:Lambda 表达式与函数式接口
Java 8 引入 Lambda 表达式后,回调和监听的语法变得更加相似,但本质区别仍然存在:
// 回调示例(使用函数式接口)
Consumer<String> callback = result -> System.out.println("结果: " + result);
processDataAsync(callback);// 监听示例(使用事件接口)
button.addActionListener(event -> {System.out.println("按钮被点击");
});2.7 总结
-
回调适合:
- 简单的异步操作结果处理
- 需要返回值或状态的场景
- 函数式编程风格的 API 设计
-
监听适合:
- 复杂的事件驱动系统
- 多组件间的松散耦合通信
- 需要支持事件过滤和广播的场景
在实际开发中,两者常结合使用。例如,一个监听系统可能使用回调来处理特定事件的响应逻辑。理解它们的区别有助于选择更合适的设计模式。
3. 监听系统
监听系统中,通常希望主线程能够继续执行其他任务,而不是被阻塞。因此,使用非阻塞回调(如 thenAccept 或 thenApply)是更合适的选择。这样,主线程可以在异步任务完成之前继续处理其他事件或任务。
3.1 监听系统中的线程管理
在监听系统中,通常会有一个主线程(如事件循环线程)负责监听事件并分发任务。为了不阻塞主线程,可以将异步任务提交到后台线程池中执行,而主线程继续处理其他事件。
代码示例
以下是一个完整的示例,展示如何在监听系统中使用非阻塞回调,让主线程继续执行。
3.2.异步服务
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.TimeUnit;public class AsyncService {public CompletableFuture<String> handleEvent(String event) {return CompletableFuture.supplyAsync(() -> {// 模拟耗时操作try {TimeUnit.SECONDS.sleep(5);} catch (InterruptedException e) {throw new RuntimeException(e);}return "Event " + event + " handled successfully";});}
}3.3 监听系统
public class EventListener {private final AsyncService asyncService;public EventListener(AsyncService asyncService) {this.asyncService = asyncService;}public void onEvent(String event) {// 启动异步任务CompletableFuture<String> future = asyncService.handleEvent(event);// 使用回调函数处理异步任务的结果future.thenAccept(result -> {System.out.println("异步任务结果: " + result);// 执行后续操作performPostProcessing();});// 主线程继续执行System.out.println("主线程继续执行...");}private void performPostProcessing() {System.out.println("执行后续操作...");}
}3.4 主线程(事件循环线程)
public class Main {public static void main(String[] args) {AsyncService asyncService = new AsyncService();EventListener eventListener = new EventListener(asyncService);// 模拟事件循环while (true) {// 模拟接收到事件String event = "event1";System.out.println("接收到事件: " + event);// 处理事件eventListener.onEvent(event);// 主线程继续处理其他事件try {Thread.sleep(1000); // 模拟主线程继续处理其他任务} catch (InterruptedException e) {e.printStackTrace();}}}
}3.5 输出示例
假设主线程的名称是 main,后台线程的名称是 ForkJoinPool.commonPool-worker-1,运行上述代码可能会输出:
接收到事件: event1
主线程继续执行...
异步任务结果: Event event1 handled successfully
执行后续操作...
接收到事件: event1
主线程继续执行...
...3.6 理解监听系统中的线程管理
-
主线程(事件循环线程):
-
主线程负责监听事件并分发任务。
-
主线程在调用
onEvent方法后,不会等待异步任务完成,而是立即继续处理其他事件。
-
-
异步任务:
-
异步任务在后台线程中执行,不会阻塞主线程。
-
异步任务完成后,回调函数会在任务完成的线程中执行。
-
-
回调函数:
-
回调函数在异步任务完成的线程中执行,而不是主线程。
-
回调函数可以执行后续操作,如日志记录、通知等。
-
3.7 总结
在监听系统中,使用非阻塞回调(如 thenAccept 或 thenApply)是更合适的选择,因为这样可以避免阻塞主线程,让主线程继续处理其他事件。通过合理使用回调函数,可以实现高效的异步编程,提高系统的并发处理能力和响应速度。