python系列31:MLforecast入门
参考这里:https://nixtlaverse.nixtla.io/mlforecast/docs/getting-started/end_to_end_walkthrough.html
1. 测试数据
可以从这里下载数据:https://www.kaggle.com/code/lemuz90/m4-competition
读取测试数据的代码为:
import random
import tempfile
from pathlib import Path
import pandas as pd
from datasetsforecast.m4 import M4
from utilsforecast.plotting import plot_series
await M4.async_download('data', group='Hourly')
df, *_ = M4.load('data', 'Hourly')
uids = df['unique_id'].unique()
random.seed(0)
sample_uids = random.choices(uids, k=4)
df = df[df['unique_id'].isin(sample_uids)].reset_index(drop=True)
df['ds'] = df['ds'].astype('int64')
fig = plot_series(df, max_insample_length=24 * 14)
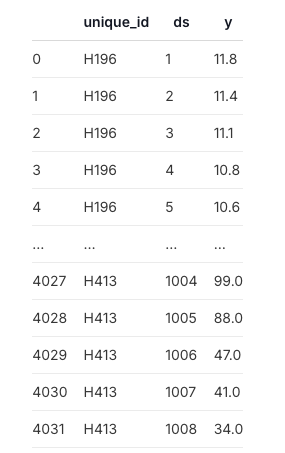
数据为:
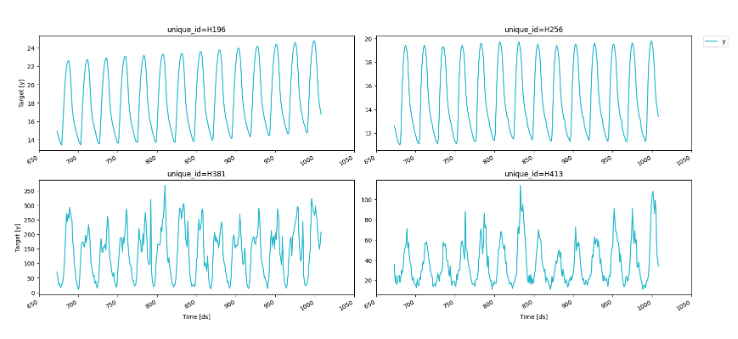
绘图为:
2. 去除季节性/日期性波动:target_transforms
比如说下面的代码,就是将每行数据减去前面第24行,得到的新数据(注意要增加freq字段):
from mlforecast import MLForecast
from mlforecast.target_transforms import Differences
fcst = MLForecast(models=[], # we're not interested in modeling yetfreq=1, # our series have integer timestamps, so we'll just add 1 in every timesteptarget_transforms=[Differences([24])],
)
prep = fcst.preprocess(df)
prep
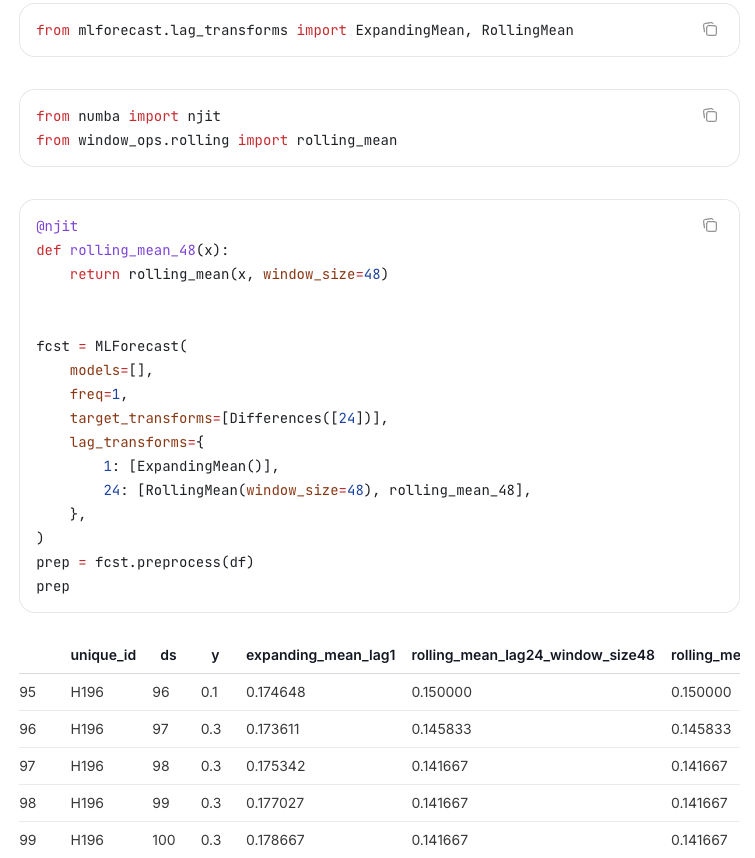
3. 增加features
3.1 lags:进行平移得到新的特征

3.2 Lag transforms:移动平均得到新的特征
3.3 Date features: 日期字段转化为特征

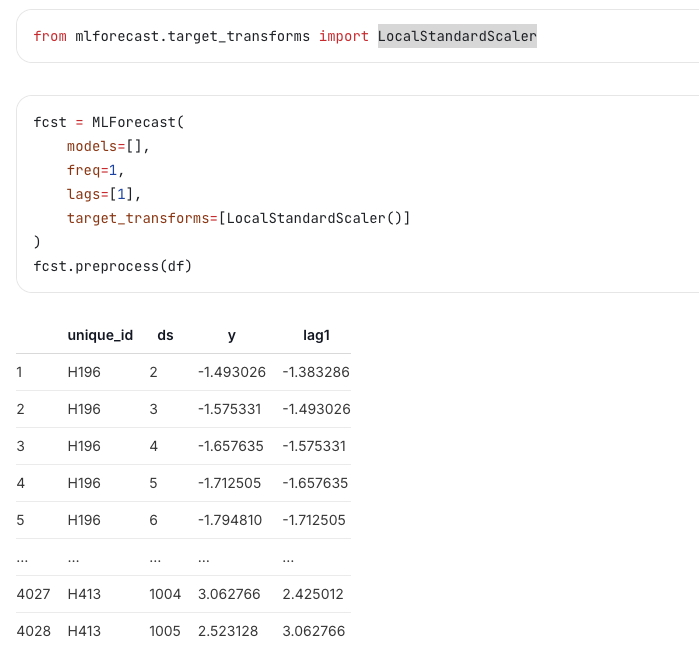
3.4 其他target_transforms
target_transforms会在生成features之前进行计算,这里补充一个LocalStandardScaler,对数据进行了标准化:
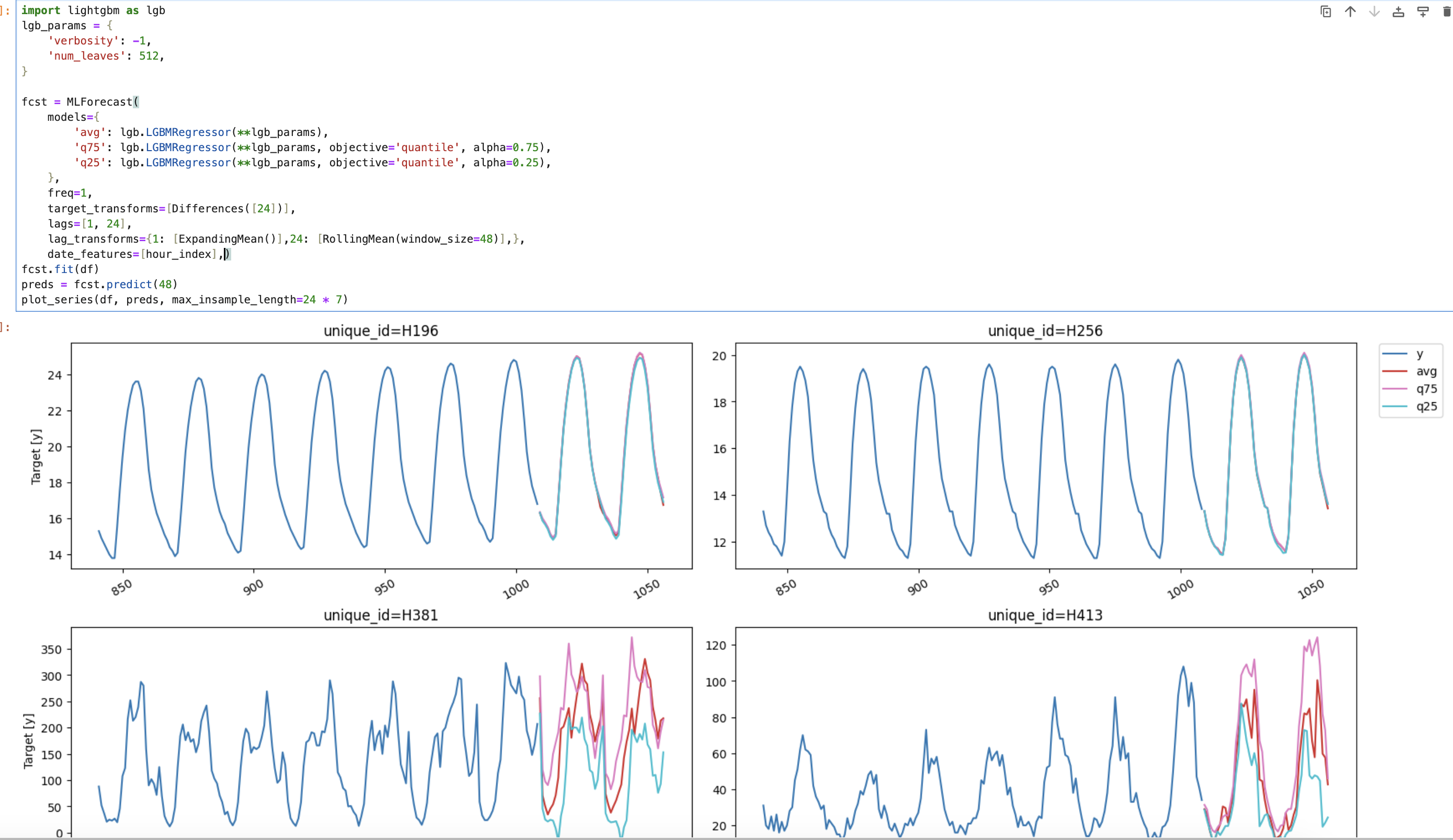
4. 进行预测
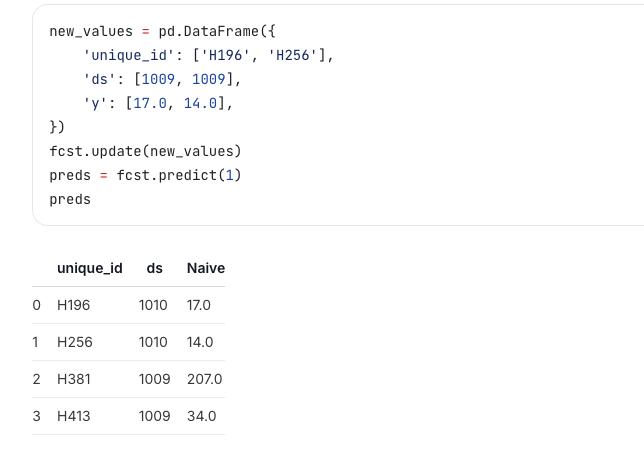
新增数据可以用下面的方法:
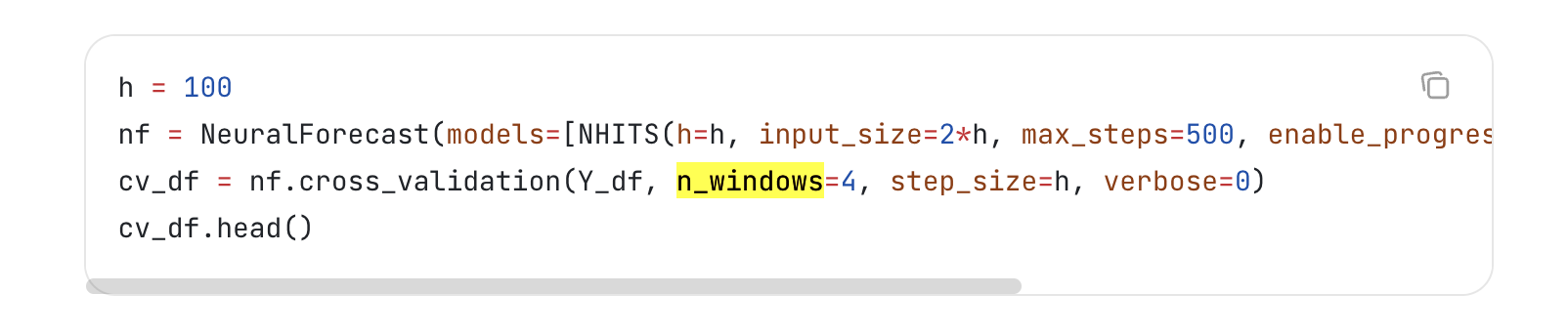
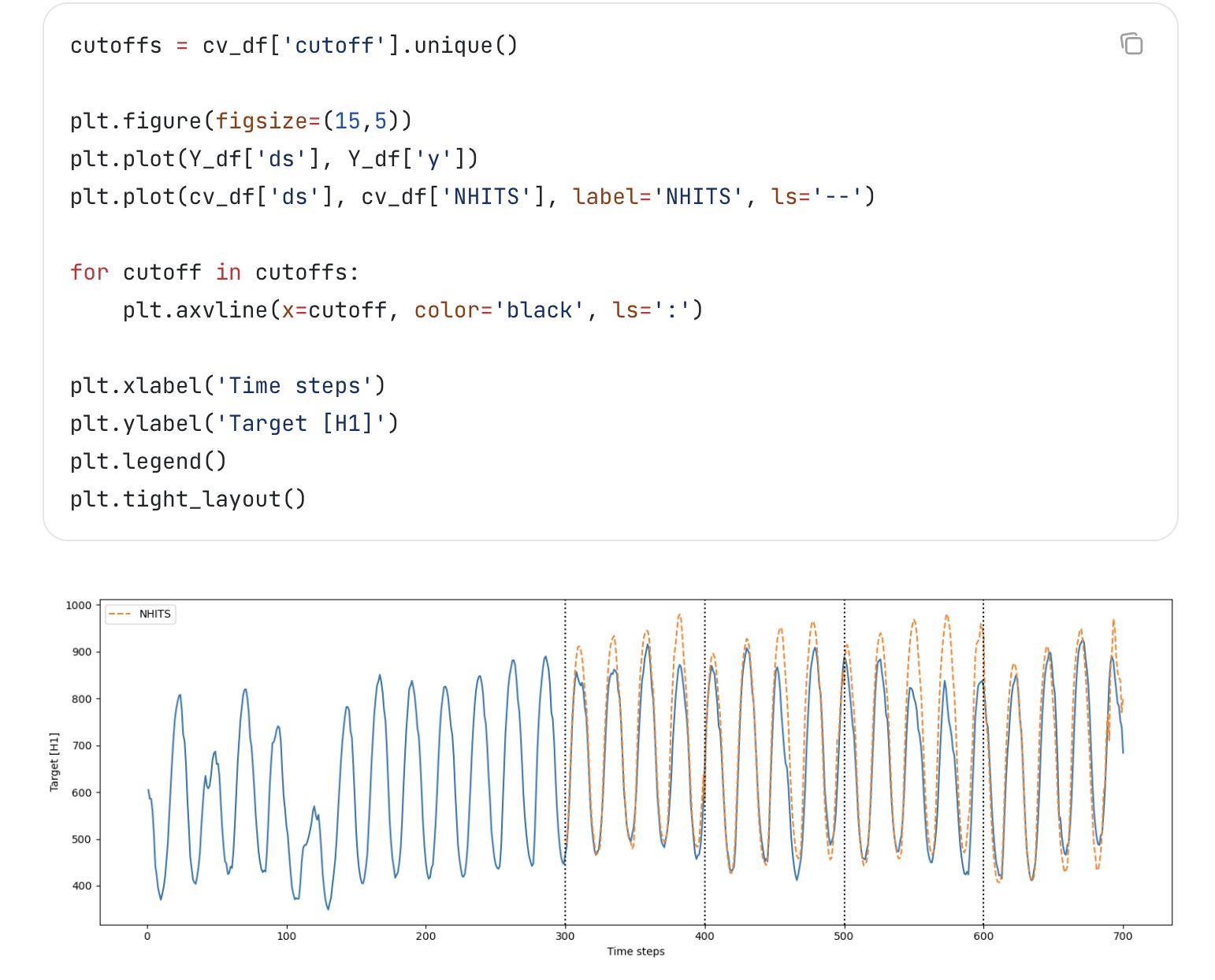
5. 交叉验证
时间序列的交叉验证有些特殊,n_windows表示从后向前划出4个窗口作为predict validation数据,每个窗口的size等于step_size. 每个窗口前的所有数据作为training data。